













ハイバーネイト
ハイバーネイト自体はフルテキスト検索を完全にサポートしていません。データベースエンジンのサポートやサードパーティ製ソリューションに依存する必要があります。
拡張機能であるHibernate SearchはApache LuceneやElasticsearch(OpenSearchとの統合もあります)と統合されています。
Postgres
Postgresはバージョン7.3からフルテキスト検索機能を備えています。ElasticsearchやLuceneのような検索エンジンとは競合できませんが、語幹抽出、ランキング、インデックス作成などの機能を提供し、アプリケーションユーザーの期待に応えるのに十分な柔軟で堅牢なソリューションを提供しています。
ここでは、Postgresでフルテキスト検索を行う方法を簡単に説明します。詳細については、Postgresのドキュメントを参照してください。基本的なテキストマッチングにおいて最も重要なのは、数学演算子@@です。
これは、ドキュメント(tsvector型のオブジェクト)がクエリ(tsquery型のオブジェクト)と一致する場合にtrueを返します。
演算子にとって順序は重要ではありません。そのため、ドキュメントを演算子の左側に、クエリを右側に置くか、その逆であるかは問題ではありません。
より良い説明のために、tweetという名前のデータベーステーブルを使用します。
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)このようなデータがあります:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');それぞれのレコードについて、short_content列のtsvectorオブジェクトがどのようになっているか見てみましょう。
SELECT id, to_tsvector('english', short_content) FROM tweet;出力:
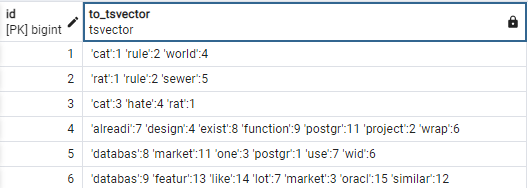
出力は、to_tsvectorがテキスト列を’english‘テキスト検索構成のtsvectorオブジェクトに変換する方法を示しています。
テキスト検索構成
上記の例でto_tsvector関数に渡された最初のパラメータは、テキスト検索構成の名前でした。その場合、それは”english“でした。Postgresのドキュメントによると、テキスト検索構成は以下の通りです:
…フルテキスト検索機能には、他にも多くのことができる能力が含まれています:特定の単語(ストップワード)のインデックスをスキップしたり、同義語を処理したり、複雑な解析を使用したり、例えば、空白だけでなく基づいて解析したり。この機能はテキスト検索構成によって制御されます。
そう、設定はプロセスの重要な部分であり、フルテキスト検索結果にとって不可欠です。異なる設定によって、Postgresエンジンは異なる結果を返すことがあります。これは、異なる言語の辞書において必ずしも当てはまるわけではありません。例えば、同じ言語に対して2つの異なる設定を持つことができますが、そのうちの1つは数字を含む名前(例えば、いくつかのシリアル番号)を無視するものです。もし、特定のシリアル番号を検索するクエリを渡すと(これは必須です)、数字を含む単語を無視する設定では、そのようなレコードは見つかりません。データベースにそのようなレコードが存在していてもです。詳細については、設定ドキュメントを参照してください。
テキストクエリ
テキストクエリは、& (AND)、| (OR)、! (NOT)、そして<-> (FOLLOWED BY)などの演算子をサポートしています。最初の3つの演算子については詳しい説明は不要です。<->演算子は、単語が存在するかどうか、そして特定の順序で配置されているかどうかをチェックします。例えば、クエリ “rat <-> cat” では、”cat” という単語が存在し、その後に “rat” が続くことを期待します。
例
- rat と cat: を含むコンテンツ:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- database と market, そして market が “database” の後に3番目の単語であるコンテンツ:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- database を含むが Postgres: を含まないコンテンツ:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- 内容にPostgres や Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');
ラッパー関数
が含まれています。この記事ですでに触れられているラッパー関数の一つに、テキストクエリを作成するto_tsqueryがあります。このような関数には他にも次のようなものがあります:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
plainto_tsqueryは、渡されたすべての単語を& (AND) 演算子で結合したクエリに変換します。例えば、plainto_tsquery('english', 'Rat cat')はto_tsquery('english', 'Rat & cat')と同等です。
次の使用例では:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');以下の結果が得られます:

phraseto_tsquery
phraseto_tsqueryは、渡されたすべての単語を<-> (FOLLOW BY) 演算子で結合したクエリに変換します。例えば、phraseto_tsquery('english', 'cat rule')はto_tsquery('english', 'cat <-> rule')と同等です。
次の使用例では:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');以下の結果が得られます:

websearch_to_tsquery
websearch_to_tsqueryは、代替構文を使用して有効なテキストクエリを作成します。
- 無引用テキスト:
plainto_tsqueryと同様に構文の一部を変換します - 引用テキスト:
phraseto_tsqueryと同様に構文の一部を変換します - OR: “
|” (OR) 演算子に変換します - “
-“: “!” (NOT) 演算子と同じです
例えば、websearch_to_tsquery('english', '"cat rule" or database -Postgres') の同等物は to_tsquery('english', 'cat <-> rule | database & !Postgres') です。
次の使用法に対して:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');以下の結果が得られます:

PostgresとHibernateのネイティブサポート
記事で述べたように、Hibernateだけではフルテキスト検索サポートが完全ではありません。データベースエンジンのサポートに頼る必要があります。つまり、以下の例のようにネイティブSQLクエリを実行できることを意味します:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}posjsonhelperライブラリを使用したHibernate
posjsonhelperライブラリは、PostgreSQLのJSON関数およびフルテキスト検索のためのHibernateクエリをサポートするオープンソースプロジェクトです。
Mavenプロジェクトにおいて、以下の依存関係を追加する必要があります:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>posjsonhelperライブラリ内のコンポーネントを使用するためには、Hibernateコンテキストにそれらを登録する必要があります。
これは、特定のorg.hibernate.boot.model.FunctionContributorの実装が存在しなければならないことを意味します。ライブラリはこのインターフェースの実装を持っており、それがcom.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributorです。
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
posjsonhelperのコンポーネントを登録する別の方法もあり、それはプログラムによって行うことができます。その方法を知るためには、こちらのリンクを確認してください。
さて、Hibernateクエリでフルテキスト検索演算子を使用できるようになりました。
PlainToTSQueryFunction
これは、plainto_tsquery関数をラップするコンポーネントです。
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}'english'という値を持つ設定の場合、以下のステートメントが生成されるコードです:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
このコンポーネントはphraseto_tsquery関数をラップしています。
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}設定値'english'での構成の場合、以下のステートメントが生成されます:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
このコンポーネントはwebsearch_to_tsquery関数をラップしています。
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}設定値'english'での構成の場合、以下のステートメントが生成されます:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)HQLクエリ
上記のすべてのコンポーネントはHQLクエリで使用できます。その方法を確認するには、こちらのリンクをクリックしてください。
Hibernateでネイティブなアプローチを使用できるのに、なぜposjsonhelperライブラリを使用するのか?
HQLまたはSQLクエリとして意図された文字列を動的に連結することは簡単かもしれませんが、述語を実装する方が良い実践であり、特にAPIからの動的属性に基づく検索条件を処理する必要がある場合にはそうです。
結論
前回の記事で述べたように、Postgresの全文検索サポートは、ElasticsearchやLuceneのような大規模な検索エンジンの良い代替案になることがあります。これにより、技術スタックに第三者のソリューションを追加する決定から私たちを救い、さらに複雑さと追加コストを増やすことからも私たちを救うことができます。
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6