













データ生成の指数的増加が特徴の時代において、組織は競争優位を維持するためにこの膨大な情報を効果的に活用しなければなりません。顧客データの効率的な検索と分析 — 例えば、映画の推薦に対するユーザーの好みを特定したり、感情分析を行ったりすること — は、情報に基づいた意思決定を促進し、ユーザー体験を向上させる上で重要な役割を果たします。例えば、ストリーミングサービスは、ベクトル検索を用いて、個々の視聴履歴や評価に基づいて映画を推薦することができ、また小売ブランドは顧客の感情を分析してマーケティング戦略を微調整することができます。
データエンジニアとして、私たちはこれらの高度なソリューションを実装する任務を担い、組織が膨大なデータセットから実行可能な洞察を引き出せるようにします。本記事では、Elasticsearchを使用したベクトル検索の複雑さを探求し、パフォーマンスを最適化するための効果的な技術とベストプラクティスに焦点を当てます。パーソナライズされたマーケティングのための画像検索や顧客の感情クラスタリングのためのテキスト分析に関するケーススタディを検討することで、ベクトル検索の最適化が顧客とのインタラクションの改善や重要なビジネス成長につながる方法を示します。
ベクトル検索とは何ですか?
ベクトル検索は、高次元空間にデータポイントをベクトルとして表現することで、データポイント間の類似性を特定する強力な手法です。このアプローチは、属性に基づいて類似アイテムを迅速に取得する必要があるアプリケーションに特に便利です。
ベクトル検索の説明
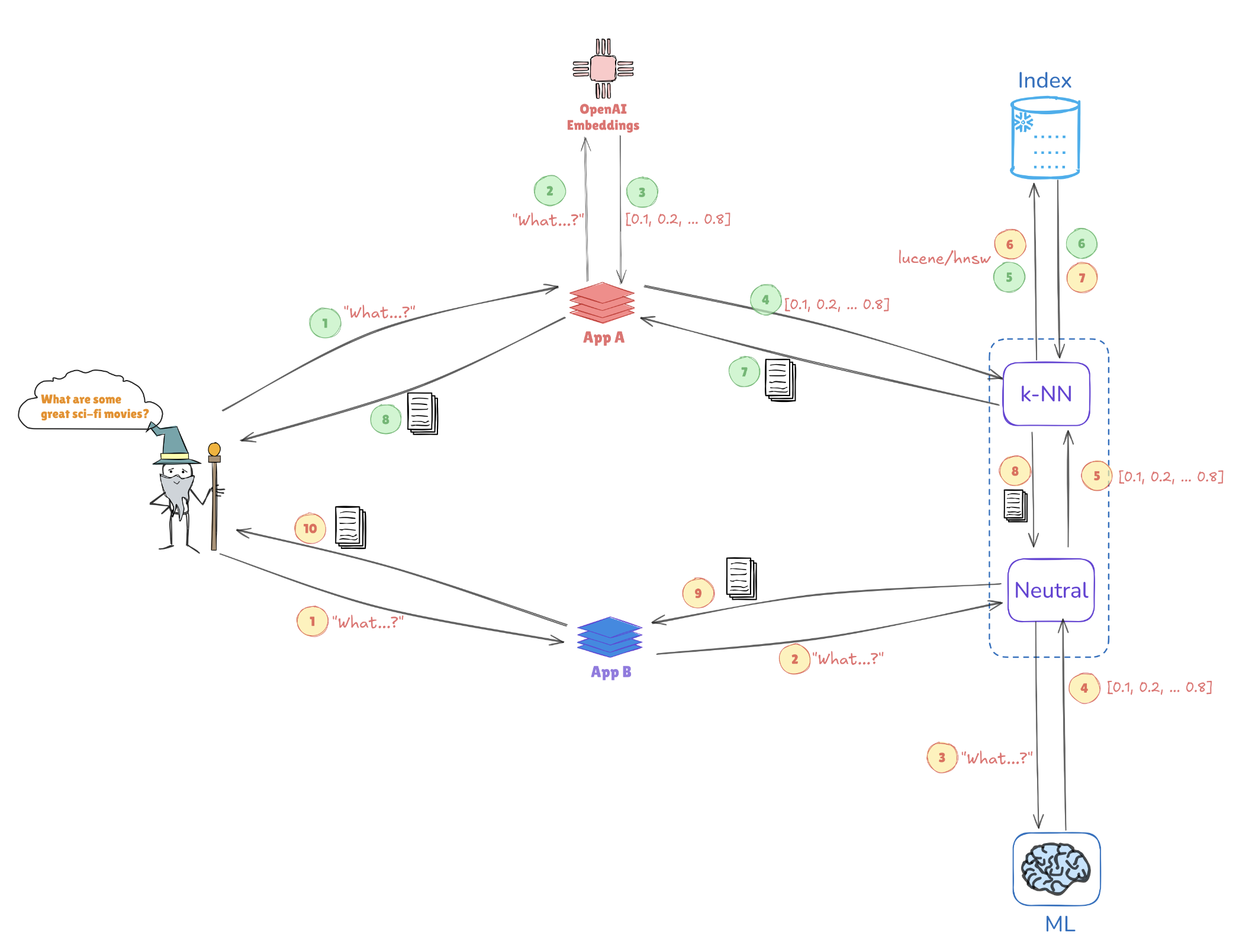
以下の図は、ベクトル表現がどのように類似検索を可能にするかを示しています:
- クエリ埋め込み:「素晴らしいSF映画は何ですか?」というクエリが、[0.1, 0.2, …, 0.4]のようなベクトル表現に変換されます。
- インデックス作成:このベクトルは、Elasticsearchに保存された事前インデックスされたベクトル(AppAやAppBのようなアプリケーションからのもの)と比較され、類似のクエリやデータポイントを見つけます。
- k-NN検索:k-NN(k-Nearest Neighbors)のようなアルゴリズムを使用して、Elasticsearchはインデックスされたベクトルからトップマッチを効率的に取得し、最も関連性の高い情報を迅速に特定します。
このメカニズムにより、Elasticsearchは、文脈や類似性を理解することが重要なレコメンデーションシステム、画像検索、自然言語処理などのユースケースで優れたパフォーマンスを発揮します。
Elasticsearchによるベクトル検索の主な利点
高次元サポート
Elasticsearchは、AIおよび機械学習アプリケーションに不可欠な複雑なデータ構造の管理に優れています。この能力は、画像やテキストデータなどの多面的なデータタイプを扱う際に重要です。
スケーラビリティ
そのアーキテクチャは水平スケーリングをサポートしており、組織がパフォーマンスを犠牲にすることなく、ますます拡大するデータセットを処理できるようにしています。データ量が増え続ける中で、これは重要です。
統合
ElasticsearchはElasticスタックとシームレスに連携し、データの取り込み、分析、可視化のための包括的なソリューションを提供します。この統合により、データエンジニアはさまざまなデータ処理タスクのために統一されたプラットフォームを活用できます。
ベクトル検索パフォーマンスを最適化するためのベストプラクティス
1. ベクトル次元の削減
ベクトルの次元を削減することで、検索パフォーマンスを大幅に向上させることができます。PCA(主成分分析)やUMAP(均一多様体近似および射影)などの手法は、データ構造を簡素化しながら重要な特徴を維持するのに役立ちます。
例:PCAによる次元削減
Scikit-learnを使用してPythonでPCAを実装する方法は次のとおりです:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. 効率的にインデックスを作成する
近似最近傍(ANN)アルゴリズムを活用することで、検索時間を大幅に短縮できます。次のことを検討してください:
- HNSW(Hierarchical Navigable Small World):性能と精度のバランスで知られています。
- FAISS(Facebook AI Similarity Search):大規模データセット向けに最適化され、GPUアクセラレーションを利用可能です。
例:ElasticsearchでHNSWの実装
ElasticsearchでHNSWを利用するために、インデックス設定を次のように定義できます:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. バッチクエリ
効率を向上させるために、複数のクエリを1つのリクエストでまとめて処理することでオーバーヘッドを最小限に抑えます。これは、ユーザートラフィックが高いアプリケーションに特に有用です。
例:Elasticsearchでのバッチ処理
バッチクエリには_msearchエンドポイントを使用できます:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. キャッシュの使用
頻繁にアクセスされるクエリのためにキャッシュ戦略を実装して、計算負荷を減らし、応答時間を改善します。
5. パフォーマンスのモニタリング
定期的にパフォーマンスメトリクスを分析することは、ボトルネックの特定に重要です。Kibanaのようなツールを使用して、これらのデータを視覚化し、Elasticsearch構成の適切な調整を可能にします。
強化されたパフォーマンスのためのHNSWのチューニングパラメータ
HNSWの最適化には、特定のパラメータを調整して大規模データセットでより優れたパフォーマンスを実現する必要があります:
M(最大接続数):この値を増やすと再現率が向上しますが、より多くのメモリが必要になるかもしれません。EfConstruction(構築中の動的リストサイズ):高い値はより正確なグラフをもたらしますが、インデックス作成時間が増加する可能性があります。EfSearch(検索中の動的リストサイズ):これを調整することで、速度と精度のトレードオフに影響します。大きな値はリコールを向上させますが、計算に時間がかかります。
例:HNSWパラメータの調整
インデックス作成時にHNSWパラメータを次のように調整できます:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
ケーススタディ:顧客データアプリケーションにおける次元削減がHNSWパフォーマンスに与える影響
パーソナライズされたマーケティングのための画像検索
次元削減技術は、顧客データアプリケーション内の画像検索システムの最適化において重要な役割を果たします。ある研究では、研究者が主成分分析(PCA)を適用して次元を削減し、階層的にナビゲート可能な小世界(HNSW)ネットワークを使用して画像をインデックス化しました。PCAは、顧客データの大量処理に不可欠な検索速度の顕著な向上を提供しましたが、情報の削減に伴うわずかな精度の損失がありました。これに対処するために、研究者は均一多様体近似と射影(UMAP)を代替手段として検討しました。UMAPは、パーソナライズされたマーケティング推奨に必要な複雑な詳細を維持しつつ、ローカルデータ構造をより効果的に保持しました。UMAPはPCAよりも多くの計算能力を必要としましたが、検索速度と高精度のバランスを取り、精度が重要なタスクに適した選択肢となりました。
顧客の感情クラスタリングのためのテキスト分析
顧客感情分析の領域では、異なる研究がUMAPがPCAよりも類似のテキストデータのクラスタリングにおいて優れていることを発見しました。UMAPはHNSWモデルが顧客の感情をより高い精度でクラスタリングすることを可能にし、顧客のフィードバックを理解し、より個別化された応答を提供する上での利点となりました。UMAPの使用により、HNSWでのEfSearch値が小さくなり、検索速度と精度が向上しました。この改善されたクラスタリング効率により、関連する顧客の感情を迅速に特定でき、ターゲットを絞ったマーケティング活動や感情に基づく顧客セグメンテーションが強化されました。
自動最適化技術の統合
次元削減およびHNSWパラメータの最適化は、顧客データシステムの性能を最大化するために不可欠です。自動最適化技術は、この調整プロセスを効率化し、選択された構成が多様なアプリケーションで効果的であることを保証します:
- グリッドおよびランダムサーチ: これらの方法は、幅広く体系的なパラメータ探索を提供し、適切な構成を効率的に特定します。
- ベイズ最適化: この手法は、評価を少なくして最適なパラメータに絞り込み、計算リソースを節約します。
- クロスバリデーション: クロスバリデーションは、さまざまなデータセットにわたってパラメータを検証し、異なる顧客データコンテキストへの一般化を保証します。
自動化における課題への対処
次元削減とHNSWワークフロー内での自動化の統合は、計算要求の管理や過学習の回避といった課題を導入する可能性があります。これらの課題を克服する戦略には次のものがあります:
- 計算オーバーヘッドの削減:ワークロードを分散させるために並列処理を使用することで、最適化時間を短縮し、ワークフローの効率を向上させます。
- モジュラー統合:モジュラーなアプローチは、既存のワークフローに自動化システムをシームレスに統合し、複雑さを減らします。
- 過学習の防止:クロスバリデーションを通じた強固な検証により、最適化されたパラメータがデータセット全体で一貫して機能することを確認し、過学習を最小限に抑え、顧客データアプリケーションのスケーラビリティを向上させます。
結論
Elasticsearchでベクトル検索のパフォーマンスを最大限に活用するためには、次元削減、効率的なインデクシング、慎重なパラメータチューニングを組み合わせた戦略を採用することが不可欠です。これらの手法を統合することで、データエンジニアは高速で正確なデータ検索システムを構築することができます。自動化された最適化手法はこのプロセスをさらに向上させ、検索パラメータやインデクシング戦略を継続的に改良することが可能となります。組織が巨大なデータセットからのリアルタイムインサイトにますます依存する中、これらの最適化は意思決定能力を大幅に向上させ、より迅速で関連性の高い検索結果を提供します。このアプローチを取り入れることで、将来のスケーラビリティと改善されたレスポンス性が可能となり、検索機能が進化するビジネス要求とデータ成長に適合します。
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch