













たとえば、Node.js(または他のプラットフォーム)で開発されたアプリケーションがあるとします。このアプリケーションは、本に対する評価(星の数とコメント)を保存するためにMongoDBデータベース(NoSQL)に接続します。また、Java(またはPython、C#、TypeScript…なんでも)で開発された別のアプリケーションがあり、このアプリケーションはタイトル、出版年、ページ数などの書籍カタログを管理するためにMariaDBデータベース(SQL、リレーショナル)に接続します。
各書籍のタイトルと評価情報を表示するレポートを作成するよう依頼されました。MongoDBデータベースには書籍のタイトルが含まれておらず、リレーショナルデータベースには評価が含まれていません。NoSQLアプリケーションによって作成されたデータをSQLアプリケーションによって作成されたデータと組み合わせる必要があります。
A common approach to this is to query both databases independently (using different data sources) and process the data to match by, for example, ISBN (the id of a book) and put the combined information in a new object. This needs to be done in a programming language like Java, TypeScript, C#, Python, or any other imperative programming language that is able to connect to both databases.
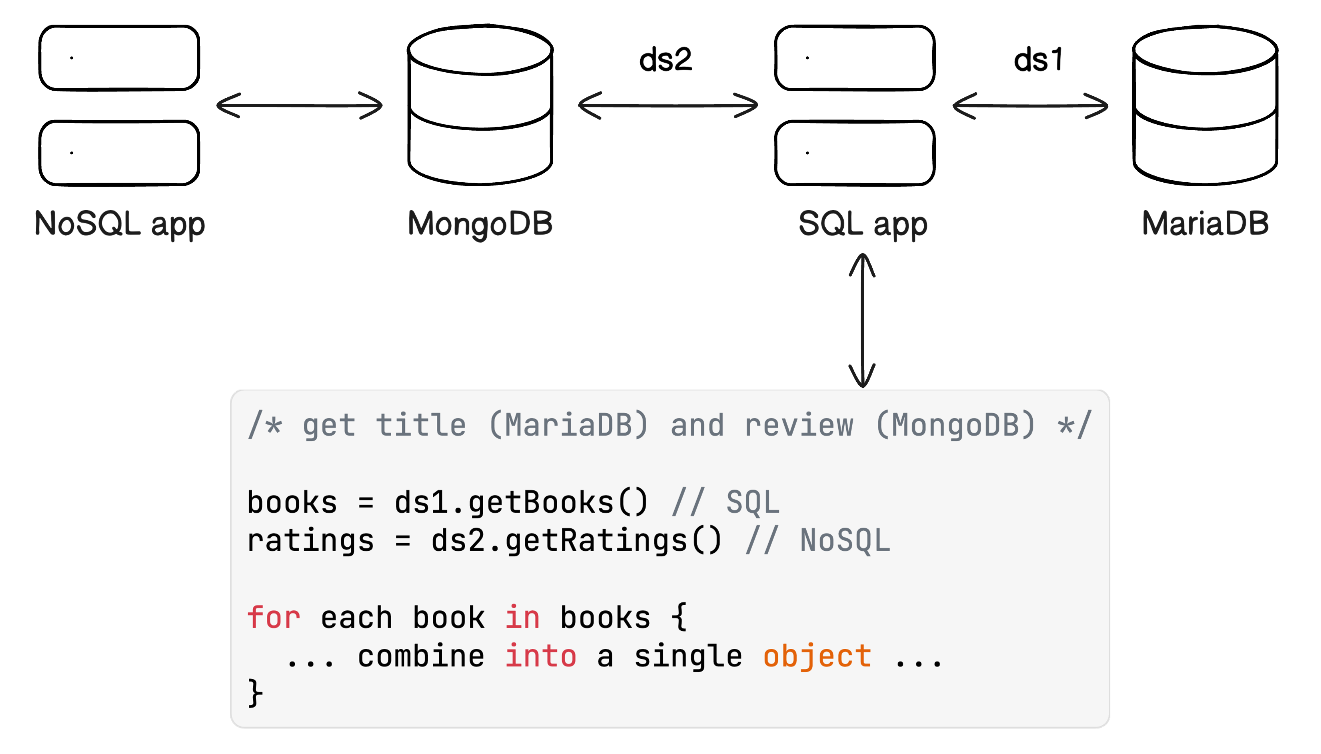
A polyglot application
このアプローチは機能しますが、データの結合はデータベースの仕事です。この種のデータ操作のために作られています。また、このアプローチでは、SQLアプリケーションはもはやSQL専用のアプリケーションではなくなり、データベースポリグロットとなり、保守が難しくなります。
データベースプロキシ として MaxScale のようなものを使用することで、SQLというデータのための最良の言語を使って、データベースレベルでこのデータを結合できます。SQLアプリケーションはポリグロットになる必要はありません。
これにはインフラストラクチャに追加要素が必要ですが、データベースプロキシが提供するすべての機能も得られます。自動フェイルオーバー、透過的なデータマスキング、トポロジーの分離、キャッシュ、セキュリティフィルターなどがそれです。
MaxScaleは、SQLだけでなくNoSQLも理解する強力でインテリジェントなデータベースプロキシです。また、Kafka(CDCまたはデータ取り込みのため)も理解していますが、それは別の機会の話題です。要するに、MaxScaleを使えば、NoSQLアプリケーションを完全にACID準拠のリレーショナルデータベースに接続し、他のSQLアプリケーションが使用するテーブルと隣接してデータを保存できます。
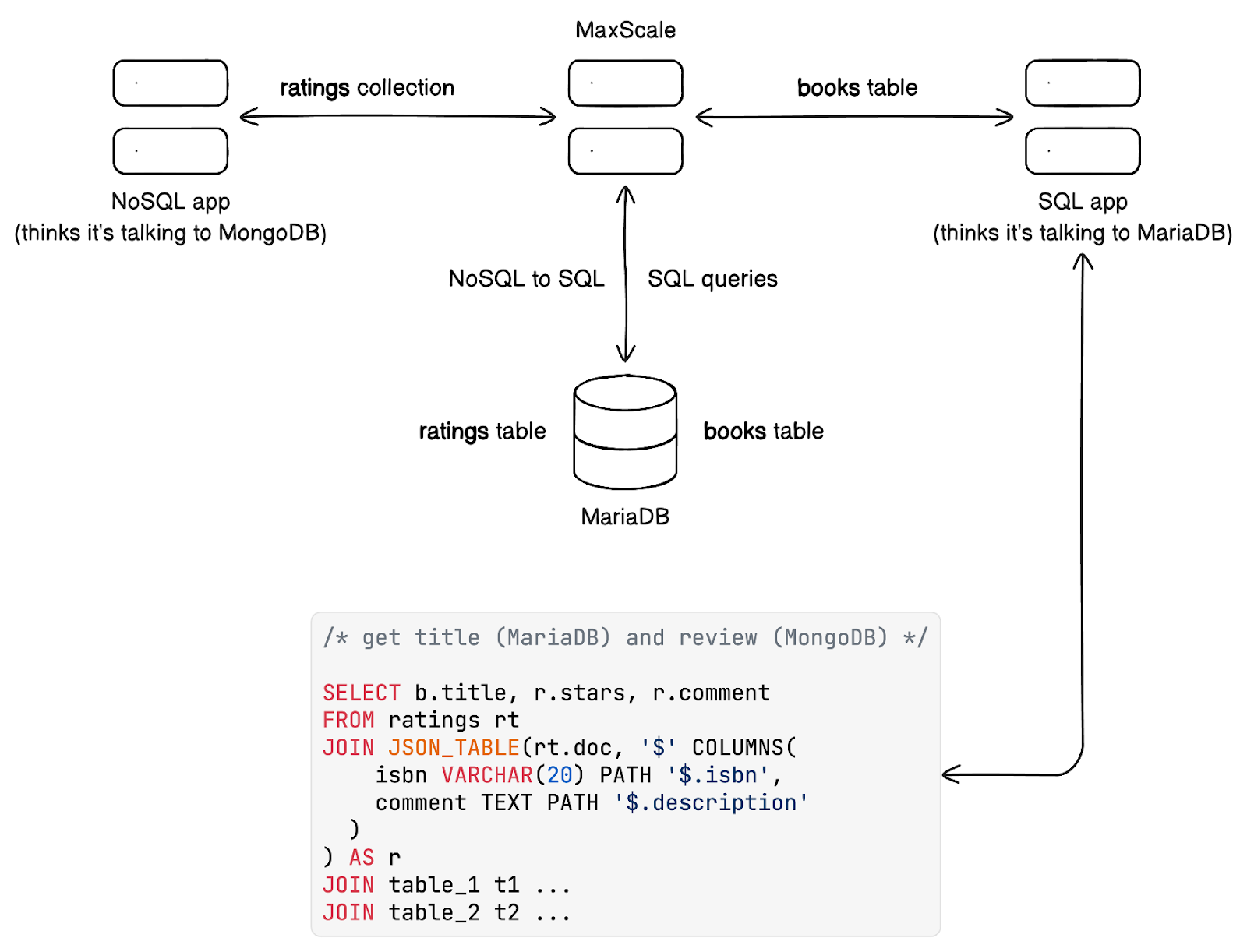
MaxScaleを使用すると、SQLアプリケーションがNoSQLデータを消費できます。
最後のアプローチをMaxScaleで簡単に試す実験をしてみましょう。コンピュータには以下がインストールされている必要があります:
MariaDBデータベースの設定
プレーンテキストエディタを使用して、新しいファイルを作成し、docker-compose.ymlという名前で保存します。ファイルには以下の内容が含まれている必要があります:
version: "3.9"
services:
mariadb:
image: alejandrodu/mariadb
environment:
- MARIADB_CREATE_DATABASE=demo
- MARIADB_CREATE_USER=user:Password123!
- MARIADB_CREATE_MAXSCALE_USER=maxscale_user:MaxScalePassword123!
maxscale:
image: alejandrodu/mariadb-maxscale
command: --admin_host 0.0.0.0 --admin_secure_gui false
ports:
- "3306:4000"
- "27017:27017"
- "8989:8989"
environment:
- MAXSCALE_USER=maxscale_user:MaxScalePassword123!
- MARIADB_HOST_1=mariadb 3306
- MAXSCALE_CREATE_NOSQL_LISTENER=user:Password123!これはDocker Composeファイルです。Dockerによって作成されるサービスのセットを記述しています。私たちは2つのサービス(またはコンテナ)— MariaDBデータベースサーバーとMaxScaleデータベースプロキシを作成しています。これらは、あなたのマシン上でローカルに実行されますが、実稼働環境では、それらを別々の物理マシンに配置するのが一般的です。これらのDockerイメージは本番環境に適していません!彼らはクイックデモやテストに適していることを意図しています。これらのイメージのソースコードはGitHubで見つけることができます。MariaDBの公式Dockerイメージについては、Docker HubのMariaDBページにアクセスしてください。
前のDocker Composeファイルは、demoという名前のデータベース(またはスキーマ;MariaDBでは同義語)を持つMariaDBデータベースサーバーを構成します。また、userというユーザー名とパスワードPassword123!を作成します。このユーザーはdemoデータベースに適切な権限を持っています。さらに、maxscale_userという名前とパスワードMaxScalePassword123!を持つ追加のユーザーがあります。これはMaxScaleデータベースプロキシがMariaDBデータベースに接続するために使用するユーザーです。
Docker Composeファイルはまた、データベースプロキシを構成します。これには、HTTPSを無効にする(本番環境ではこれを行わないでください!)、一連のポートを公開する(これについてはすぐ後で説明します)、およびデータベースユーザーとMariaDBデータベースプロキシの場所を構成することが含まれます(通常はIPアドレスですが、ここではDockerファイルで以前に定義されたコンテナ名を使用できます)。最後の行は、デフォルトのポート(27017)でMongoDBクライアントとして接続するために使用するNoSQLリスナーを作成します。
コマンドラインを使用してサービス(コンテナ)を開始するには、Docker Composeファイルを保存したディレクトリに移動し、以下を実行します:
docker compose up -dすべてのソフトウェアをダウンロードし、コンテナを起動した後、MariaDBデータベースとMaxScaleプロキシが、この実験のために事前に構成されています。
MariaDBでSQLテーブルを作成する
リレーショナルデータベースに接続しましょう。コマンドラインで次のように実行します:
mariadb-shell --dsn mariadb://user:'Password123!'@127.0.0.1確認して、demoデータベースが見えること:
show databases;
demoデータベースに切り替える:
use demo;
MariaDB Shellを使用してデータベースに接続します。
booksテーブルを作成する:
CREATE TABLE books(
isbn VARCHAR(20) PRIMARY KEY,
title VARCHAR(256),
year INT
);データを挿入します。私は自分の書籍を挿入することにします:
INSERT INTO books(title, isbn, year)
VALUES
("Vaadin 7 UI Design By Example", "978-1-78216-226-1", 2013),
("Data-Centric Applications with Vaadin 8", "978-1-78328-884-7", 2018),
("Practical Vaadin", "978-1-4842-7178-0", 2021);書籍がデータベースに保存されていることを確認するために実行します:
SELECT * FROM books;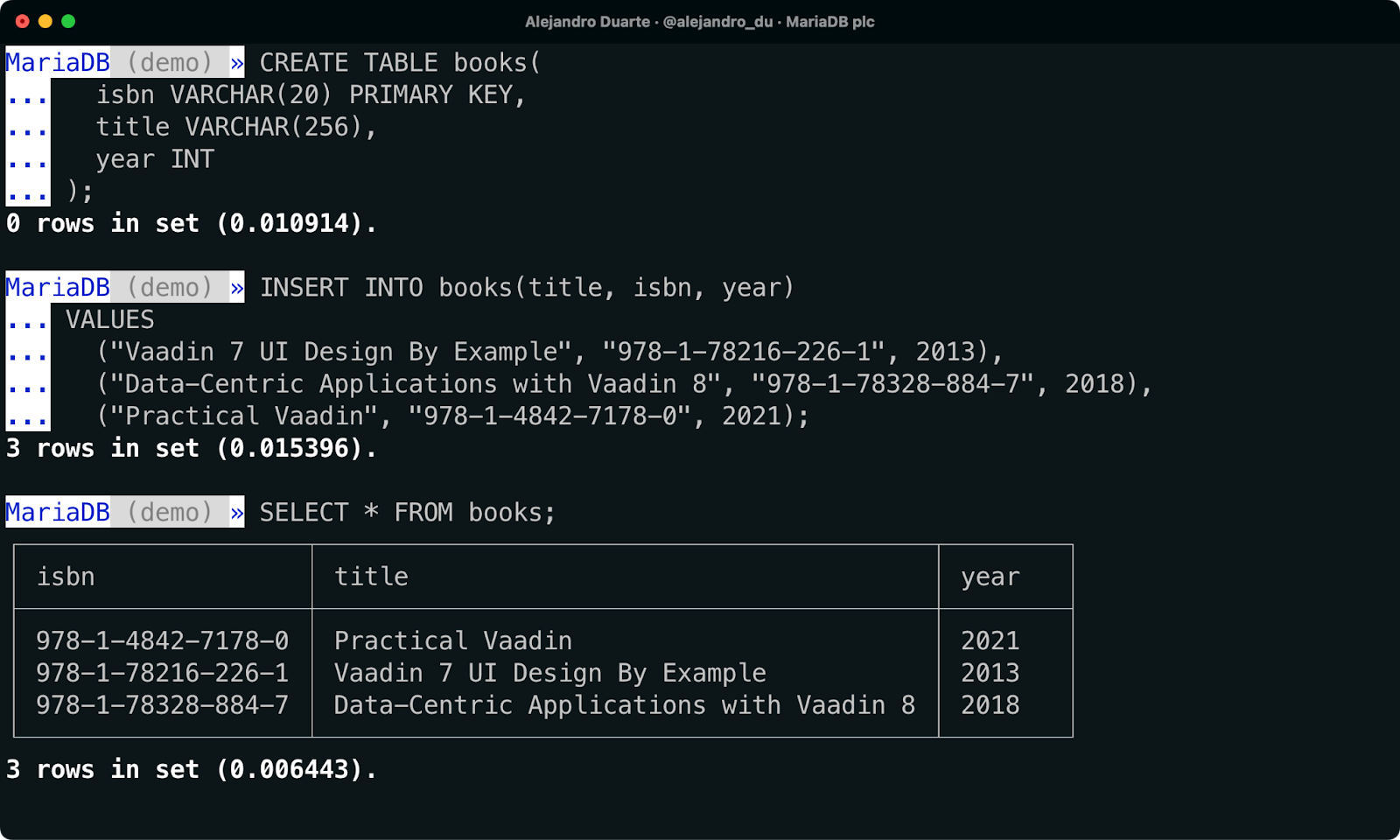
MariaDB Shellを使用してデータを挿入します。
MariaDBでJSONコレクションを作成する
私たちはまだMongoDBをインストールしていませんが、MongoDBクライアント(またはアプリケーション)を使用して、MongoDBを使用しているかのようにコレクションとドキュメントを作成することができます。ただし、データは完全にACID準拠でスケーラブルなリレーショナルデータベースに保存されます。それを試してみましょう!
コマンドラインで、MongoDBシェルツールを使用してMongoDBに接続します…待って…実はMariaDBデータベースです!次のコマンドを実行します:
mongosh
デフォルトでは、このツールはローカルマシン(127.0.0.1)でデフォルトのポート(20017)を使用してMongoDBサーバー(今回はMariaDBである)に接続しようとします。すべてが順調に行けば、次のコマンドを実行したときにdemoデータベースがリストされるはずです:
show databases
demoデータベースに切り替える:
use demo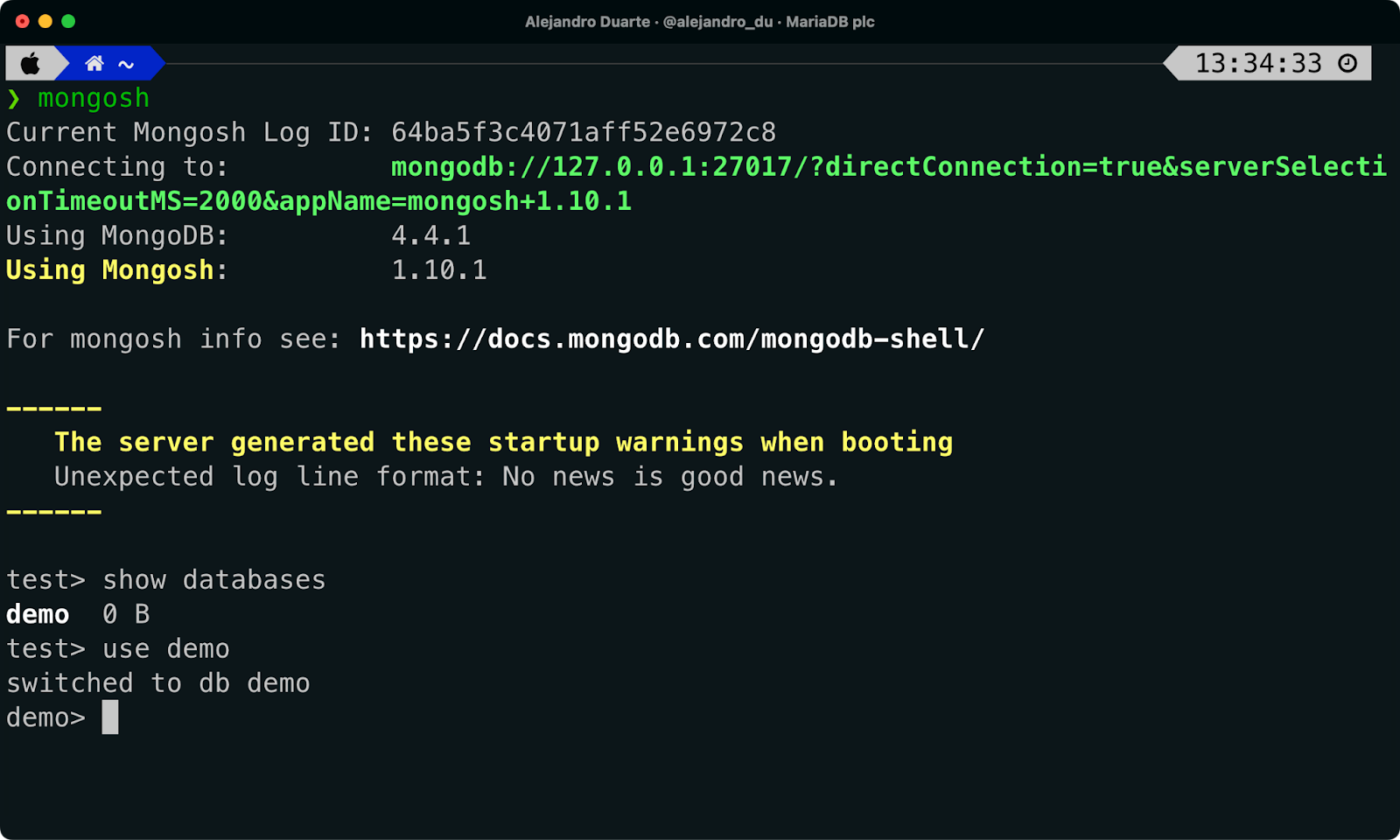
Mongo Shellを使用してMariaDBに接続します。
非リレーショナルクライアントからリレーショナルデータベースに接続しています!ratingsコレクションを作成し、そこにデータを挿入しましょう:
db.ratings.insertMany([
{
"isbn": "978-1-78216-226-1",
"starts": 5,
"comment": "A good resource for beginners who want to learn Vaadin"
},
{
"isbn": "978-1-78328-884-7",
"starts": 4,
"comment": "Explains Vaadin in the context of other Java technologies"
},
{
"isbn": "978-1-4842-7178-0",
"starts": 5,
"comment": "The best resource to learn web development with Java and Vaadin"
}
])データベースに評価が保持されていることを確認します:
db.ratings.find()
Mongo Shellを使用してMariaDBデータベースをクエリする。
MariaDBでのJSON関数の使用
この時点で、外部から見るとNoSQL(MongoDB)データベースとリレーショナル(MariaDB)データベースのように見える単一のデータベースがあります。同じデータベースに接続し、MongoDBクライアントとSQLクライアントからデータの書き込みと読み取りができます。すべてのデータはMariaDBに保存されているため、MongoDBクライアントやアプリケーションからのデータとMariaDBクライアントやアプリケーションからのデータをSQLで結合できます。MaxScaleがMariaDBにMongoDBデータ(コレクションとドキュメント)を保存する方法を探りましょう。
mariadb-shellのようなSQLクライアントを使用してデータベースに接続し、デモスキーマのテーブルを表示します:
show tables in demo;booksとratingsの両方のテーブルがリストされているはずです。ratingsはMongoDBコレクションとして作成されました。MaxScaleはMongoDBクライアントから送信されたコマンドを翻訳し、データをテーブルに保存するためのテーブルを作成しました。このテーブルの構造を見てみましょう:
describe demo.ratings;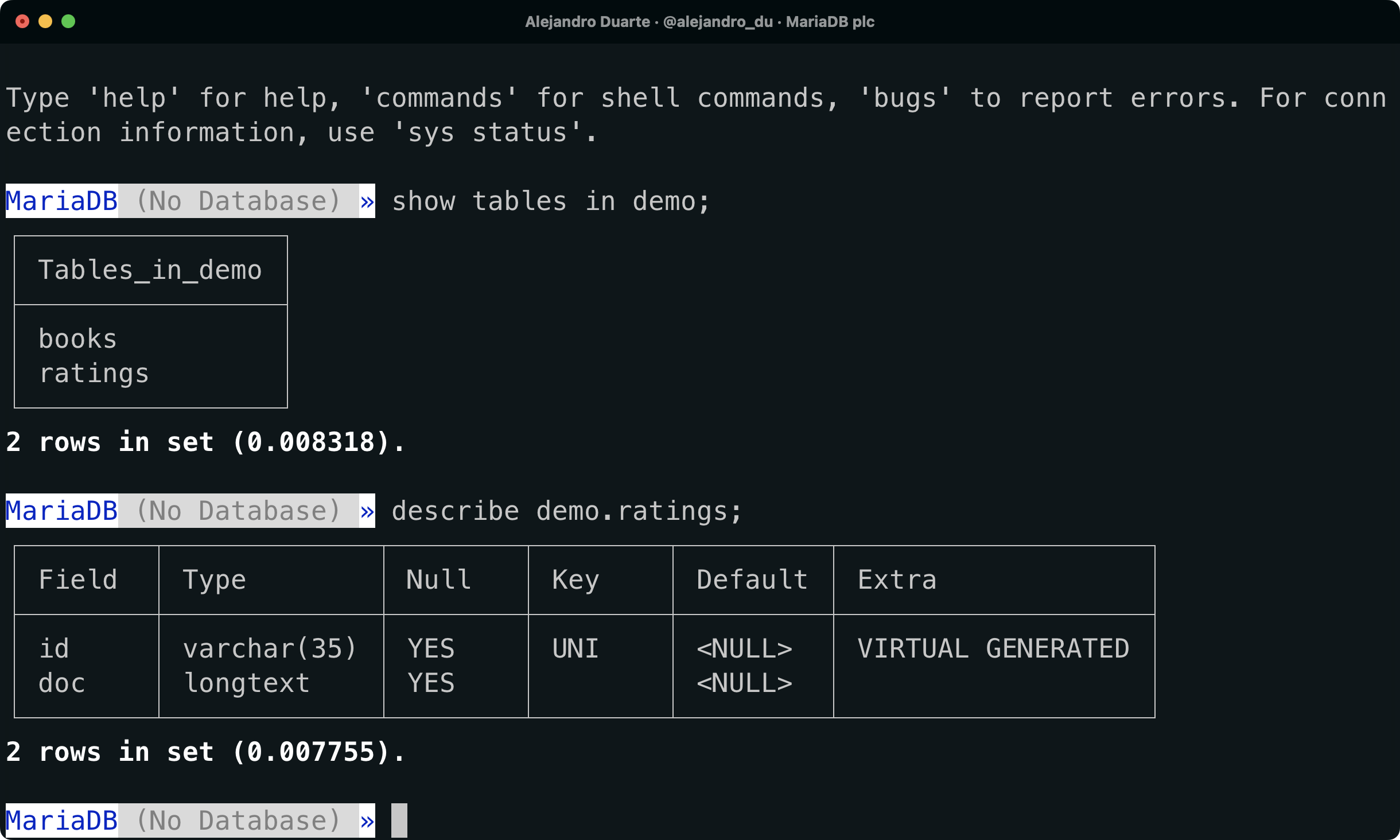
A NoSQL collection is stored as a MariaDB relational table.
ratingsテーブルには2つの列が含まれています:
id: オブジェクトID。doc: JSON形式のドキュメント。
テーブルの内容を調べると、すべての評価に関するデータがJSON形式でdoc列に保存されていることがわかります:
SELECT doc FROM demo.ratings \G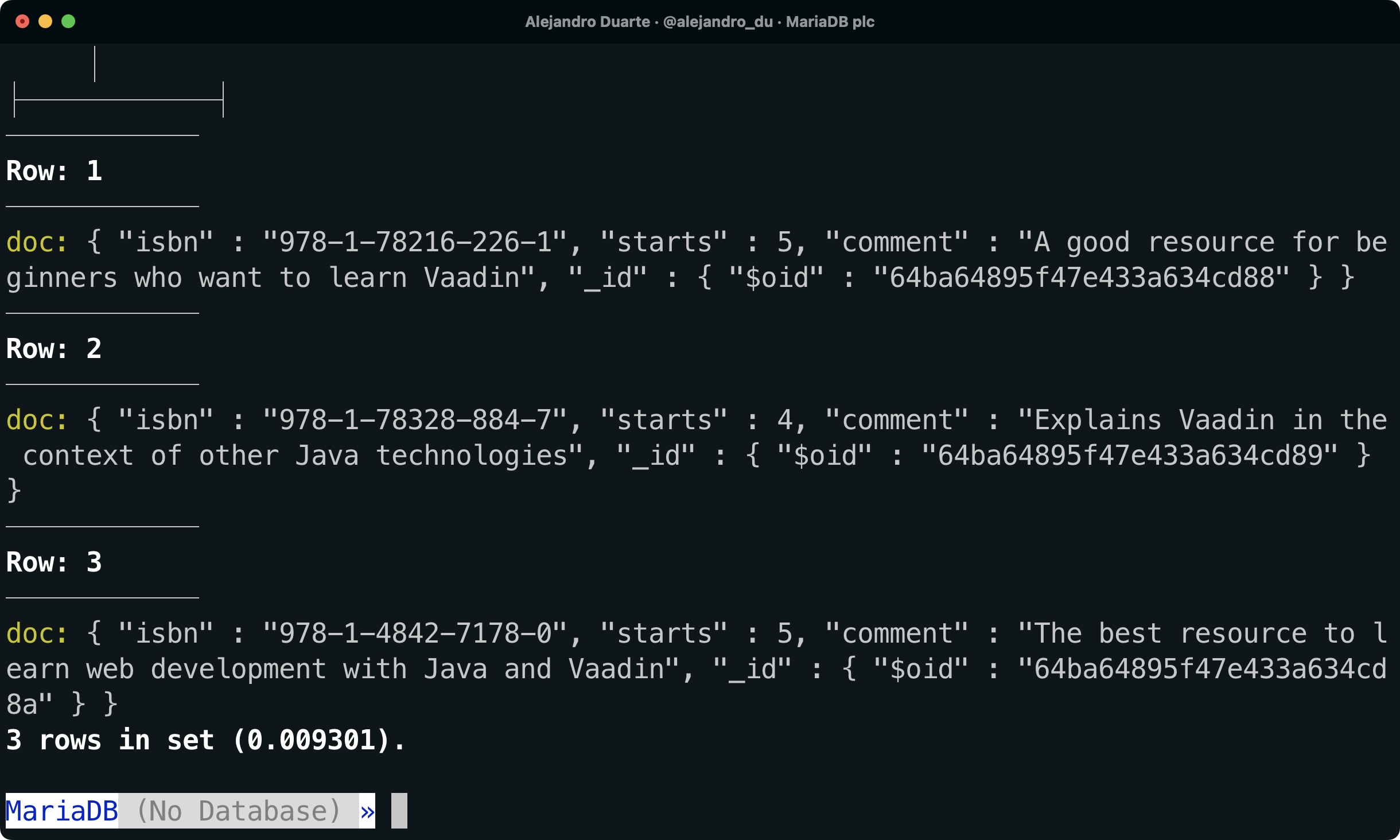
NoSQLドキュメントはMariaDBデータベースに保存されています。
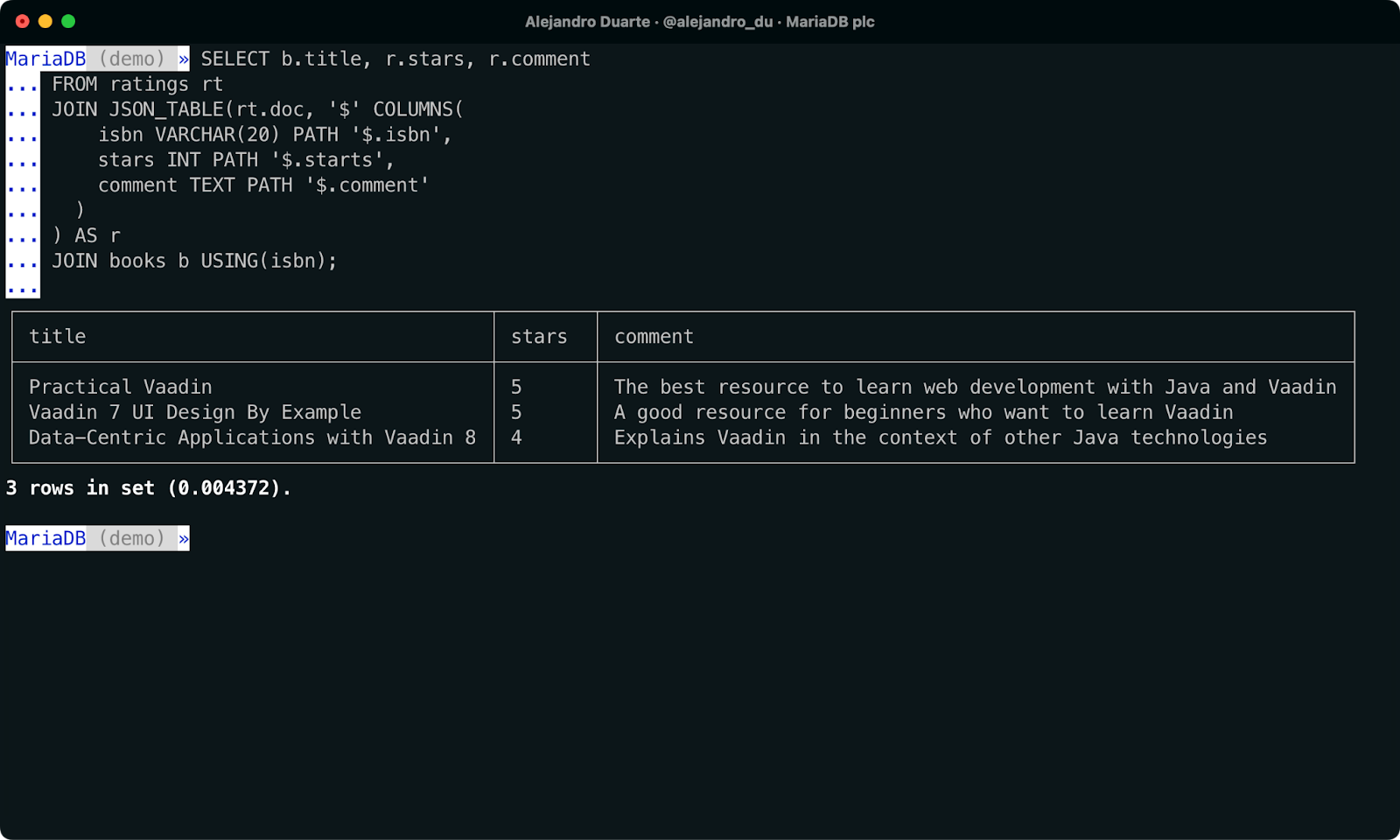
元の目的に戻りましょう――評価情報付きの書籍タイトルを表示します。以下はそのケースではないが、一瞬ratingsテーブルがstarsとcommentの列を持つ通常のテーブルだったと想定してみましょう。その場合、このテーブルをbooksテーブルと結合するのは簡単で、私たちの仕事は終わったことになります:
/* this doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings r
JOIN books b USING(isbn)現実に戻ります。実際のratingsテーブルのdoc列を、クエリで新しいテーブルとして使用できるリレーショナル表現に変換する必要があります。このようなものです:
/* this still doesn’t work */
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN ...something to convert rt.doc to a table... AS r
JOIN books b USING(isbn)その何かはJSON_TABLE関数です。MariaDBには、JSON文字列を操作するための包括的なJSON関数セットが含まれています。doc列をリレーショナル形式に変換し、SQL結合を実行できるようにするためにJSON_TABLE関数を使用します。JSON_TABLE関数の一般的な構文は次のとおりです:
JSON_TABLE(json_document, context_path COLUMNS (
column_definition_1,
column_definition_2,
...
)
) [AS] the_new_relational_tableここで:
json_document:使用するJSONドキュメントを返す文字列または式。context_path: a JSON Path expression that defines the nodes to be used as the source of the rows.
そして、列定義(column_definition_1、column_definition_2、など…)は以下の構文を持つ:
new_column_name sql_type PATH path_in_the_json_doc [on_empty] [on_error]この知識を組み合わせると、私たちのSQLクエリは以下のようになる:
SELECT b.title, r.stars, r.comment
FROM ratings rt
JOIN JSON_TABLE(rt.doc, '$' COLUMNS(
isbn VARCHAR(20) PATH '$.isbn',
stars INT PATH '$.starts',
comment TEXT PATH '$.comment'
)
) AS r
JOIN books b USING(isbn);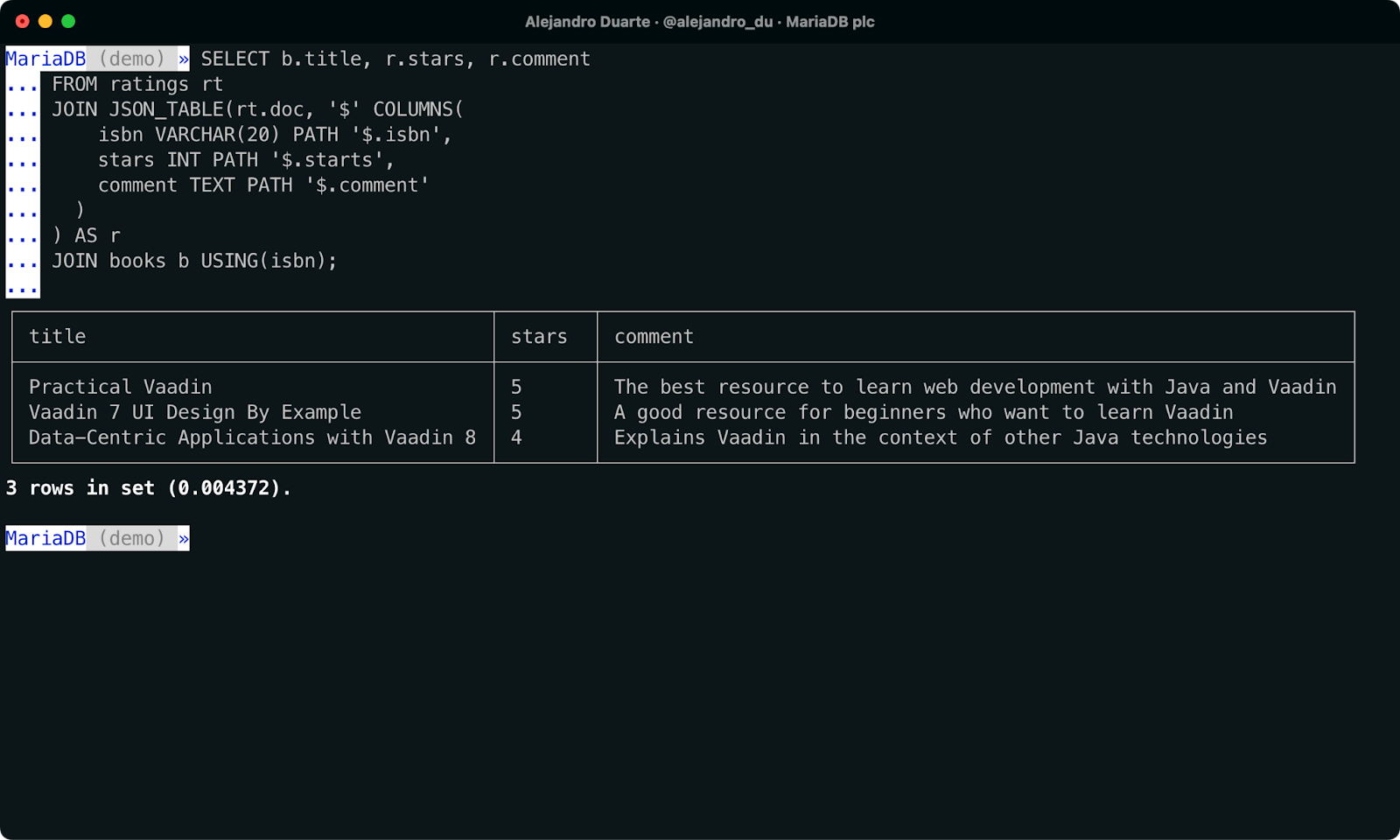
NoSQLとSQLデータを単一のSQLクエリで結合する。
ISBN値をMongoDBのObjectIDとして使用し、それに応じてratingsテーブルのid列として使用することもできましたが、それはあなたに練習問題として残します(ヒント:MongoDBクライアントまたはアプリでデータを挿入する際に_idをisbnの代わりに使用してください)。
A Word on Scalability
リレーショナルデータベースは水平方向にスケール(ノードを追加)できないという誤解がありますが、NoSQLデータベースはできるというものです。しかし、リレーショナルデータベースはACID特性を犠牲にすることなくスケールすることができます。MariaDBは異なるワークロードに合わせた複数のストレージエンジンを備えています。例えば、Spiderの助けを借りてデータシャーディングを実装することでMariaDBデータベースをスケールアップできます。また、テーブルごとに異なるワークロードを処理するためのさまざまなストレージエンジンを使用することもできます。エンジン間の結合も単一のSQLクエリで可能です。
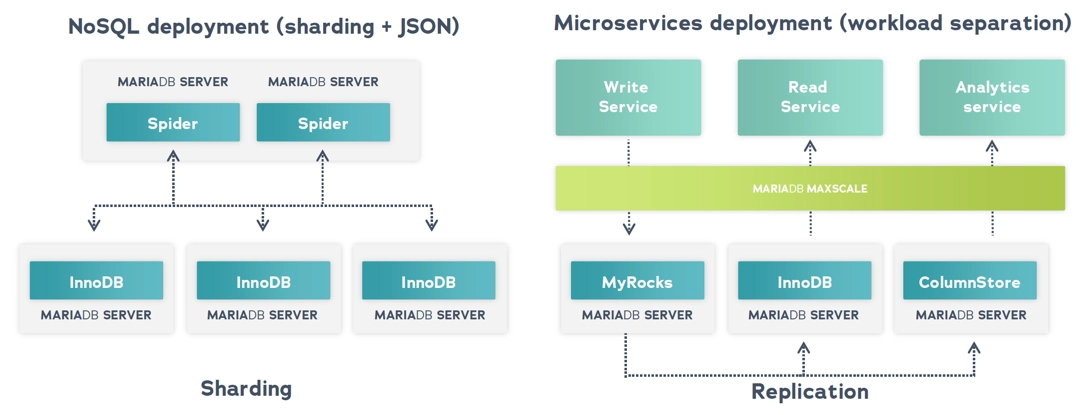
単一の論理MariaDBデータベースで複数のストレージエンジンを組み合わせる。
もう一つのより現代的な代替案は、分散型SQLとMariaDB Xpandです。分散型SQLデータベースは、透過的なシャーディングを通じてアプリケーションに対して単一の論理的リレーショナルデータベースとして現れます。読み取りと書き込みの両方をスケーリングできる、共有しないアーキテクチャを採用しています。
A distributed SQL database deployment.
結論
ここでの私たちの仕事は終わりです! これで、あなたのシステムは、SQLまたはNoSQLアプリケーションによって作成されたかどうかに関係なく、ACID準拠のスケーラブルな360度のデータのビューを持つことができます。NoSQLからSQLへのアプリの移行や、SQLアプリをデータベースポリグロットにする必要性が少なくなります。MaxScaleの他の機能についてさらに学びたい場合は、このビデオを見るか、ドキュメントを訪れてください。
Source:
https://dzone.com/articles/mixing-sql-and-nosql-with-mariadb-and-mongodb