













Linuxの学習は、技術業界で最も価値のあるスキルの一つです。これは、より速く効率的に物事を完了するのを助けることができます。世界の多くの強力なサーバーとスーパーコンピューターはLinux上で運行しています。
現在の役割であなたを活性化させるだけでなく、Linuxの学習は、DevOps、サイバーセキュリティ、クラウドコンピューティングなどの他の技術職業への移行も助けることができます。
このハンドブックで、Linuxのコマンドラインの基本を学び、その後、シェルスクリプティングやシステム管理などの高度なトピックに移行することができます。Linuxに新しいところからいるか、数年間使用しているところからでも、この本书には皆さんにとって何かがあることでしょう。
重要な注意:この本书のすべての例は、Ubuntu 22.04.2 LTS (Jammy Jellyfish)で示されています。他のディストリビューションでは、ほとんどのコマンドラインツールが同じです。しかし、GUIアプリケーションとコマンドが、他のLinuxディストリビューションで作業を行っている場合には異なるかもしれません。
目次
第1編:Linuxの入门
1.1. Linuxを始める
Linuxは何か?
Linuxは開発されているオープンソースのオペレーティングシステムであり、Unixオペレーティングシステムに基づいています。1991年にLinus Torvaldsによって作成されました。
オープンソースは、オペレーティングシステムのソースコードを一般市民に公開することを意味します。これにより、誰もが原始的なコードを修正、カスタマイズし、新しいオペレーティングシステムを潜在のユーザーに配布することができます。
なぜLinuxについて学ぶ必要があるのでしょうか?
今日のデータセンターの LANDSCAPE では、LinuxとMicrosoft Windowsが主要な竞争者として引き抜かれており、Linuxが大きな市場シェアを持っています。
Linuxを学ぶいくつかの説得力ある理由があります。
-
Linux ホスティングの普及に伴い、アプリケーションが Linux 上でホスティングされる可能性が高いため、開発者として Linux を学ぶことは益々価値がある。
-
クラウドコンピューティングが標準となっているため、クラウドのインスタンスが Linux に基づいている可能性が高いです。
-
Linuxは、インターネットのものすごい(IoT)とモバイルアプリケーションの多くのオペレーティングシステムの基盤として機能しています。
-
ITの分野では、Linuxのスキルがある人には多くの機会があります。
Linuxがオープンソースのオペレーティングシステムであることを何によるのか?
最初に、オープンソースとは何か?オープンソースソフトウェアは、ソースコードが無料で公開されており、誰もが利用、修正、及び配布することができるソフトウェアです。
ソースコードが作成されるたびに、著作権保護されており、著作権所有者がソフトウェアライセンスを通じて配布を支配します。
オープンソースとは対照的に、所有権のあるまたはクローズドソースソフトウェアは、ソースコードのアクセスを制限しており、作成者だけが参照、修正、または配布することができます。
Linuxは主にオープンソースであり、これはソースコードが無料で公開されていることを意味します。誰もが参照、修正、及び配布することができます。世界中の開発者が改善に貢献できます。これはオープンソースソフトウェアの重要な侧面である協力の基盤を提供します。
この協力型の取り組みは、Linuxをサーバー、デスクトップ、嵌入式システム、モバイルデバイスなどで広く采用させました。
Linuxがオープンソースである最も興味深い側面は、所有権の制約なしに、開発者が独自の需要に合わせてオペレーティングシステムを調整することができることです。
Chrome OSはChromebooksで使用され、globally powers many smartphonesのAndroidもLinuxに基づいています。
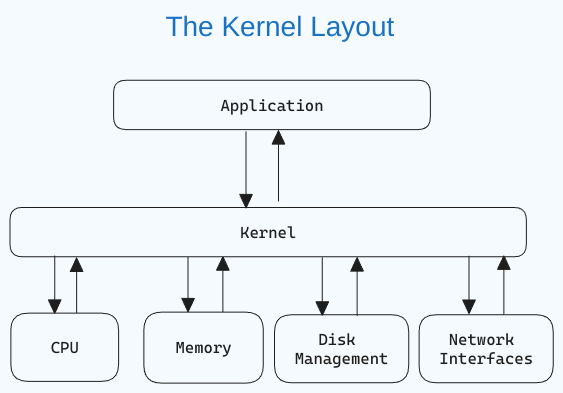
Linux Kernelとは何か?
カーネルは、オペレーティングシステムの中心部分で、コンピュータとそのハードウェア操作を管理するコンポーネントです。メモリ操作とCPU時間を処理します。
カーネルは、アプリケーションとハードウェアレベルのデータ処理を介してインタープロセス通信とシステムコールを使用して橋として機能します。
カーネルは、オペレーティングシステムが起動する際に最初にメモリに読み込まれ、システムが停止するまでそこに保持されます。カーネルは、ディスク管理、タスク管理、メモリ管理などの業務を担当します。
Linuxカーネルがどのようなものか好奇心がある方は、ここにGitHubのリンクがあります。
Linuxディストリビューションとは何でしょう?
この段階で、Linuxカーネルのコードを再利用し、修正し、新しいカーネルを作成することができることを知っています。さらに、異なるユーティリティやソフトウェアを組み合わせて、全新のオペレーティングシステムを作成することもできます。
Linuxディストリビューションやディストリビューションは、Linuxオペレーティングシステムのバージョンで、Linuxカーネル、システムユーティリティ、その他のソフトウェアを含んでいます。オープンソースなので、Linuxディストリビューションは、複数の独立したオープンソース開発コミュニティが協力して開発されるものです。
ディストリビューションが「派生」しているという意味は何でしょう?ディストリビューションが「派生」していると言うと、新しいディストリビューションは元のディストリビューションのベースや基础上に構築されています。この派生には、同じパッケージ管理システム(この点について後で説明)を使用し、カーネルのバージョンを同じにすることも、時に同じ設定ツールを使用することも含まれます。
今日、Linuxディストリビューションは数千のものがあり、それぞれに独自のゴールと基準を持って、ディストリビューションに提供されているソフトウェアを選択してサポートしています。
ディストリビューションはお互いに異なりますが、一般的に共通の特徴がいくつかあります。
-
ディストリビューションにはLinuxカーネルが含まれています。
-
ユーザースペースのプログラムをサポートしています。
-
ディストリビューションは小さくて目的を持たれたものであったり、何千ものオープンソースのプログラムを含んだものもあります。
-
ディストリビューションとそのコンポーネントのインストールと更新方法が提供されている必要があります。
Linuxディストリビューションのタイムラインを見ると、2つの主要なディストロがあります:SlackwareとDebian。いくつかのディストリビューションはこれらから派生したものです。たとえば、UbuntuとKaliはDebianから派生したものです。
派生の利点は何でしょうか? 派生ディストリビューションには様々な利点があります。派生ディストリビューションは、親ディストリビューションの安定性、安全性、大規模なソフトウェアリポジトリを利用することができます。
既存の基盤に基づいて構築する場合、開発者は新しいディストリビューションの特化した機能に集中し、努力を注ぎ込むことができます。派生ディストリビューションのユーザーは、親ディストリビューションに既に存在する文書、コミュニティサポート、リソースから利益を受けることができます。
有名なLinuxディストリビューションには以下があります:
-
Ubuntu
: もっともよく使われていて人気のあるLinuxディストリビューションです。使用者にとって親切で、初心者に推奨されています。Ubuntuについてもっと詳しくいただけます。
-
Linux Mint: Ubuntuの基础上に立ち上げ、マルチメディアサポートに焦点を当てたユーザーが亲切な体験を提供します。Linux Mintについてもっと詳しくいただけます。
-
Arch Linux: 経験豊富なユーザーの間で人気のある軽量且つ柔軟性のあるディストリビューションです。DIYアプローチを好むユーザーに向けています。Arch Linuxについてもっと詳しくいただけます。
-
Manjaro:Arch Linuxをベースに、Manjaroは予めインストールされたソフトウェアと簡単なシステム管理ツールで使いやすい体験を提供します。Manjaroについて詳しくはこちら。
-
Kali Linux:Kali Linuxは包括的なセキュリティツールのスイートを提供し、主にサイバーセキュリティとハッキングに焦点を当てています。Kali Linuxについて詳しくはこちら。
Linuxのインストールとアクセス方法
学ぶには、概念を実際に適用することが最も効果的です。このセクションでは、マシンにLinuxをインストールして、一緒に進めるようにする方法を学びます。また、WindowsマシンでLinuxにアクセスする方法も学びます。
このセクションで述べられている方法のいずれかを選んでLinuxにアクセスし、一緒に進めることをおすすめします。
プライマリOSとしてLinuxをインストールする
LinuxをプライマリOSとしてインストールすることは、マシンのフルパワーを活用できる最も効率的な方法です。
このセクションでは、最も人気のあるLinuxディストリビューションの1つであるUbuntuのインストール方法を学びます。今のところ他のディストリビューションは省いていますが、簡単にするためです。Ubuntuに慣れてきたら、いつでも他のディストリビューションを試すことができます。
-
ステップ1 – UbuntuのISOファイルをダウンロードします: 公式のウェブサイトにアクセスして、ISOファイルをダウンロードします。安定したリリースであり、”LTS”とラベル付けされたものを選択してください。LTSはLong Term Supportの略で、通常5年間の無料のセキュリティとメンテナンスのアップデートを受けることができます。
-
ステップ2 – ブート可能なUSBドライブを作成します: ブート可能なUSBドライブを作成するための多くのソフトウェアがあります。使いやすいため、Rufusをおすすめします。ここからダウンロードできます:こちら。
-
USBドライブからブートする:
ブート可能なUSBドライブを準備したら、それを挿入してUSBドライブからブートしてください。ブートメニューは、あなたのラップトップによって異なります。あなたは、ラップトップモデルのブートメニューをGoogleしてください。
-
手順4: 指示に従います。ブートプロセスが開始した後、
try or install ubuntuを選択してください。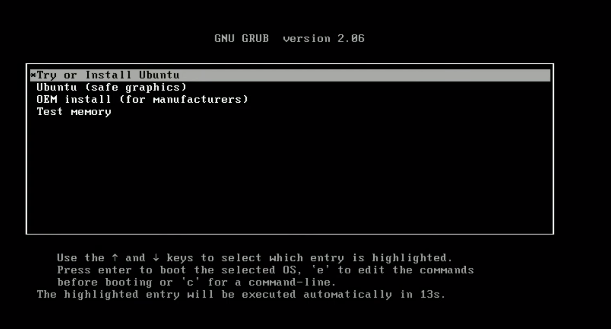
このプロセスにはいくらか時間がかかります。GUIが表示された後、言語とキーボードのレイアウトを選択して進みます。ログインと名前を入力してください。これらの情報を覚えておいてください、因为这将是您登录系统并访问完全权限所需的凭据。インストールが完了するのを待ってください。
-
手順5: リスタートする:今すぐリスタートをクリックして、USBドライブを取り出してください。
-
Step 6 – ログイン:
先ほど入力した情報でログインしてください。
これで完了です!今度はアプリをインストールし、デスクトップをカスタマイズすることができます。

高度なインストールについては、以下のトピックについて探りましょう:
-
ディスク分割。
-
スワップメモリの設定(休止状態の有効化)。
ターミナルにアクセスする
この手順書の重要な部分は、すべてのコマンドを実行し、魔法が起こる場所であるターミナルを学ぶことです。「Windows」キーを押して「terminal」と入力することでターミナルを探すことができます。ターミナルをドックにピン留めすることができます。他のアプリと同じ場所にあり、簡単にアクセスできます。
💡 ターミナルを開く快捷键は
ctrl+alt+t
また、フォルダー内からターミナルを開くこともできます。現在の場所を右クリックし、「ターミナルで開く」を選択します。これにより、同じパスのターミナルを開きます。
Windows マシンで Linux を使用する方法
時には、Linux と Windows を side by side で実行する必要があるかもしれません。幸运にも、異なるコンピュータを各OSに対して取得する代わりに、両方の世界を取得するのに最適な方法があることになります。
この節では、Windows マシンで Linux を使用するいくつかの方法を探ります。其中のいくつかは、ブラウザーベースまたはクラウドベースで、使用前にOSのインストールを必要としません。
オプション1: Linux + Windowsのデュアルブートデュアルブートを使用すると、您的电脑上にLinuxとWindowsを並列にインストールすることができ、起動時にどのオペレーティングシステムを使用するかを選択することができます。
これには、ハードディスクを分割する必要があり、Linuxを別の分割にインストールする必要があります。この方法では、一度に一度だけのオペレーティングシステムを使用することができます。
オプション2: Windows Subsystem for Linux (WSL)を使用するWindows Subsystem for Linuxは、Linuxの二進制実行ファイルをWindows上でネイティブに実行することができるコンパタビリティ層を提供します。
WSLを使用する利点があります。WSLのセットアップは簡単で、時間を要することはありません。VMと比較して、ホストマシンからリソースを割り当てる必要がないため、軽量です。Linuxマシン用のISOまたは仮想ディスクイメージをインストールする必要はないですが、これらは一般的に大きなファイルです。WindowsとLinuxを横並びで使用することができます。
WSL2をインストールする方法
まず、設定でWindows Subsystem for Linuxのオプションを有効にします。
-
スタートをクリックし、”Windows 機能のオンまたはオフ”をSearchしてください。
-
Windows Subsystem for Linuxのオプションを未にない場合にチェックしてください。
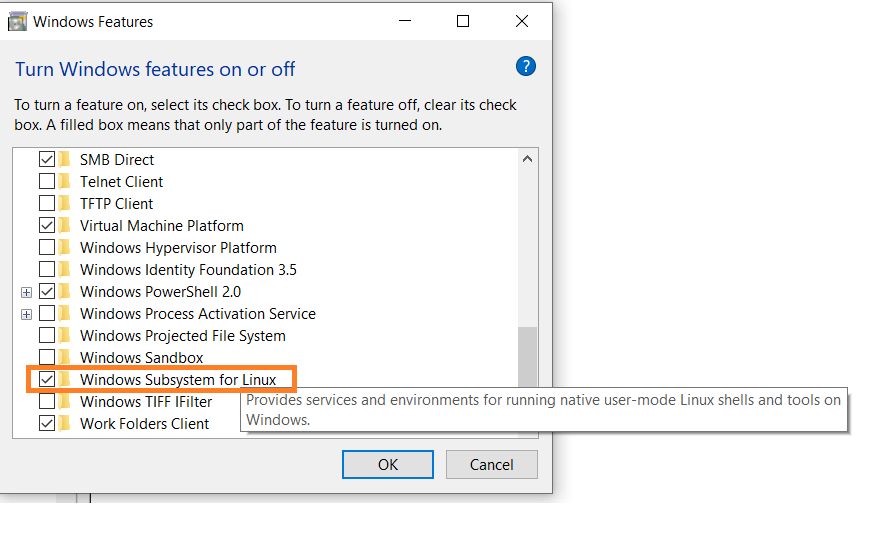
-
次に、コマンドプロンプトを開いて、インストールコマンドを提供します。
-
管理者权限でコマンドプロンプトを開く:

-
以下のコマンドを実行してください:
wsl --install
これは出力結果です:
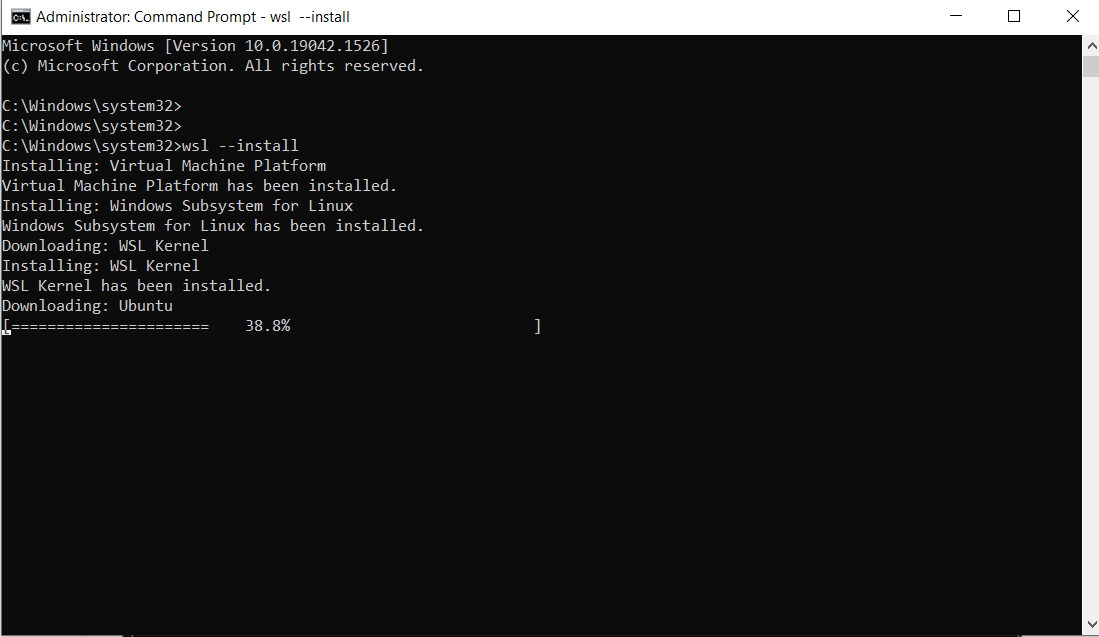
注意: デフォルトでは、Ubuntuがインストールされます。
- インストールが完了すると、Windowsマシンを再起動する必要があります。したがって、Windowsマシンを再起動してください。
再起動後、このようなウィンドウを表示されるかもしれません:
Ubuntuのインストールが完了すると、ユーザー名とパスワードを入力するように提示されます。

そして、それで完了です! 您はUbuntuを使用する準備ができました。
スタートメニューからUbuntuを検索して起動します。
これで、Ubuntuのインスタンスを起動しました。

オプション3: 仮想マシン(VM)を使用する
仮想マシン(VM)は、 physical computer systemのソフトウェアエミュレーションです。一度の物理的なマシン上で複数のオペレーティングシステムやアプリケーションを同時に実行することができます。
Oracle VirtualBoxやVMwareなどの仮想化ソフトウェアを使用して、Windows環境内にLinuxを実行する仮想マシンを作成することができます。これにより、Windowsと並行してLinuxをゲストオペレーティングシステムとして実行することができます。
仮想化ソフトウェアは、CPUコア、メモリ、ディスクスペース、ネットワーク帯域など、各VMに対するハードウェアリソースの割り当てと管理を提供します。これらの割り当ては、ゲストOSやアプリケーションの要求に基づいて調整することができます。
以下は、一般的な仮想化に使用されるいくつかのオプションです:
オプション4: ブラウザベースのソリューションを使用する
ブラウザベースのソリューションは、Linuxがインストールされていないデバイスからの迅速なテスト、学習、Linux環境へのアクセスに特に便利です。
オンラインコードエディターやWebベースの端末を使用してLinuxにアクセスすることができます。これらの場合、通常完全な管理権限を持たないことに注意してください。
オンラインコードエディタ
オンラインコードエディタは、内蔵のLinux端末を提供するエディタを提供します。主要な用途はコーディングであるため、Linux端末を使って命令を実行し、作業を行うこともできます。
Replitは、コードを書いて同時にLinuxのシェルにアクセスできるオンラインコードエディタの一例です。
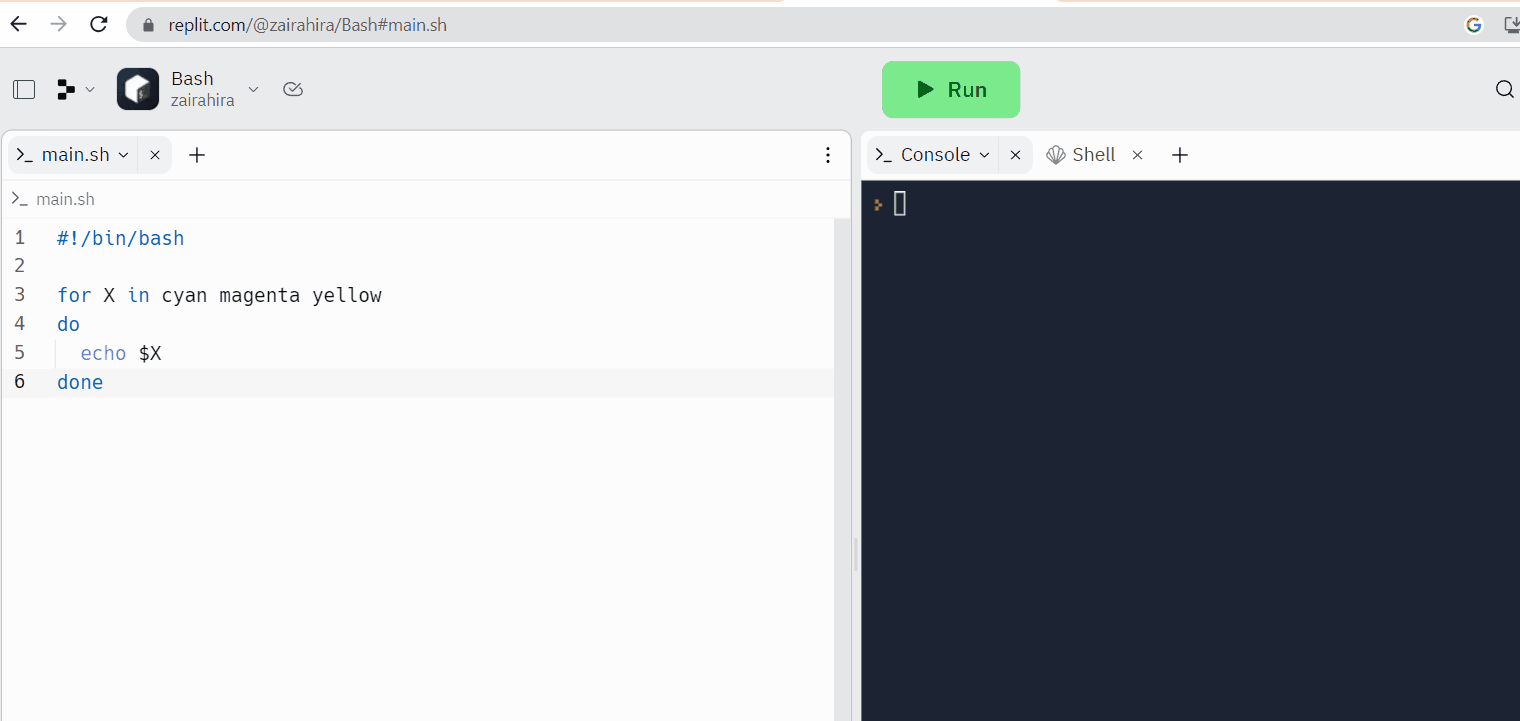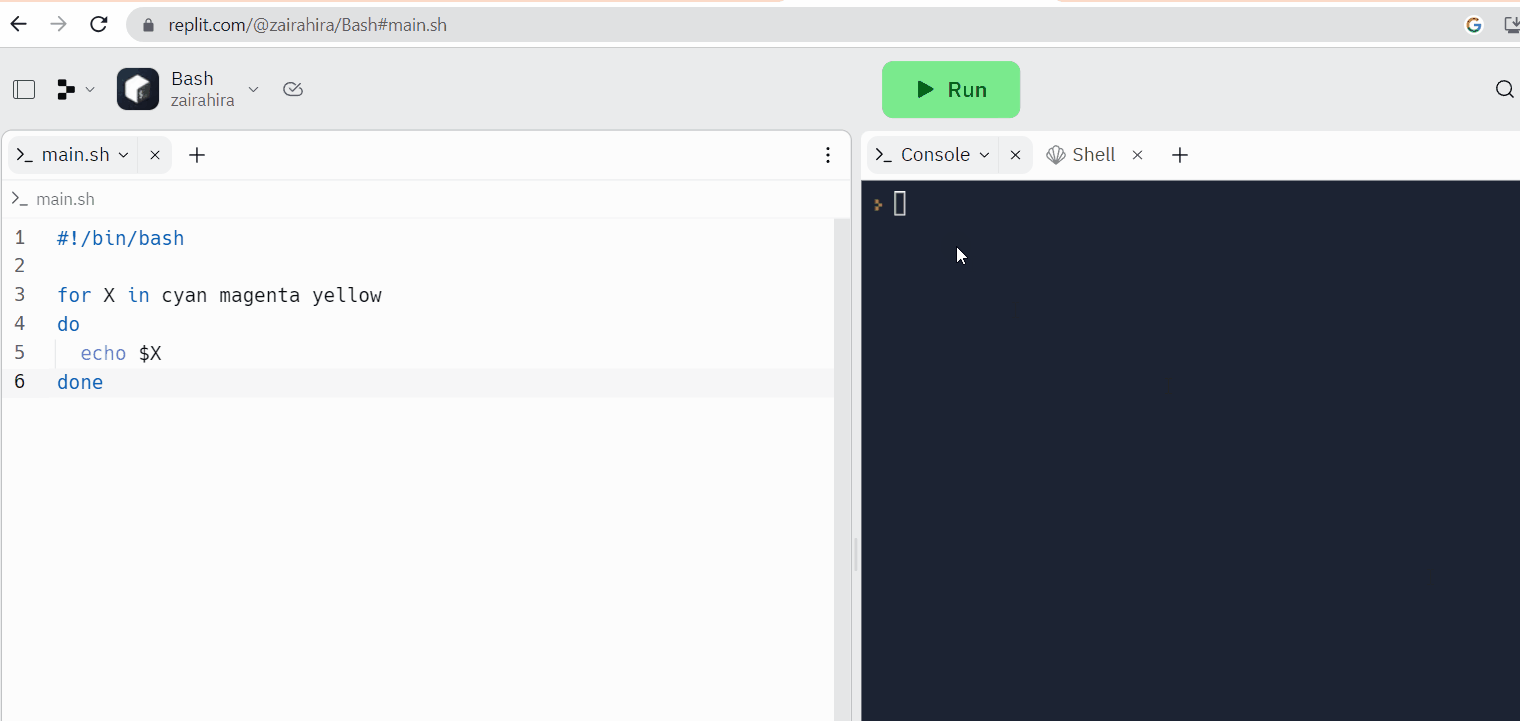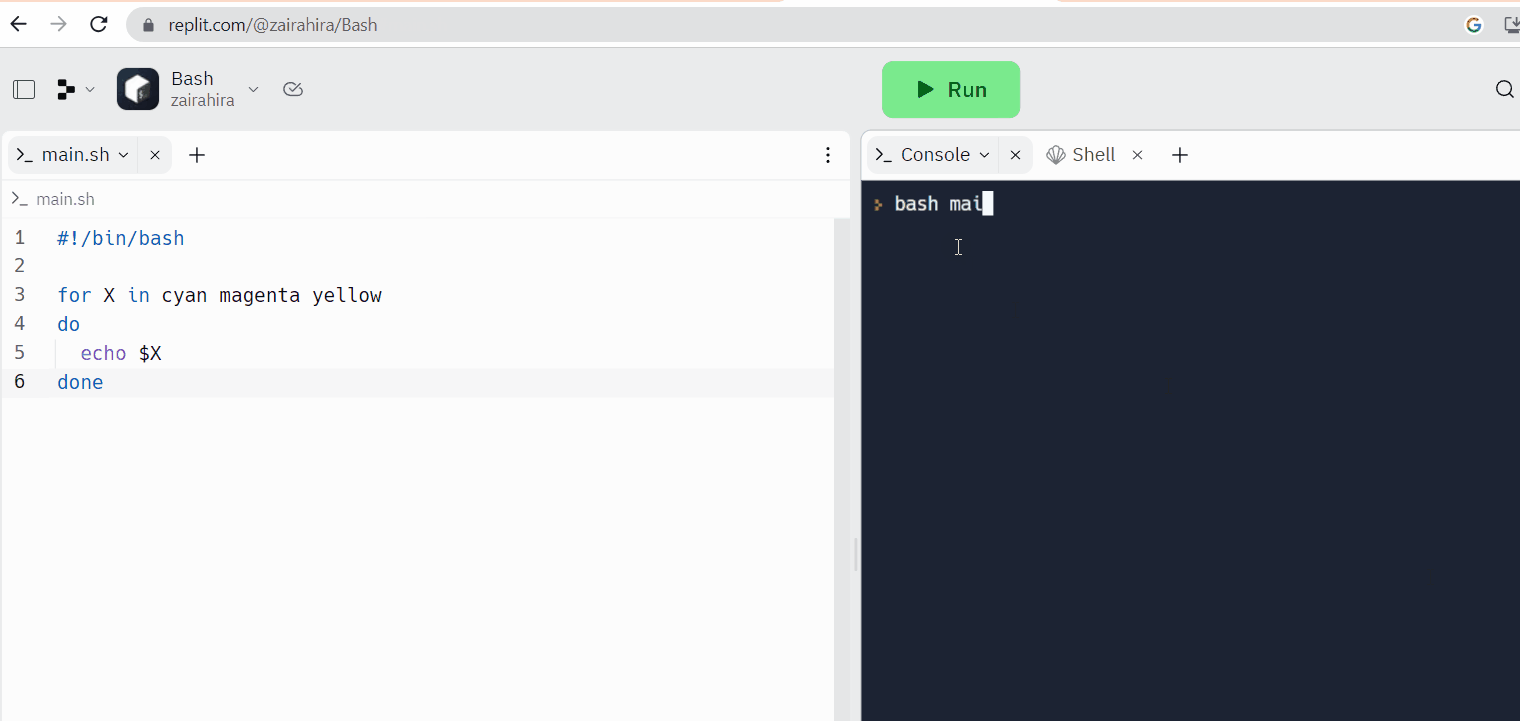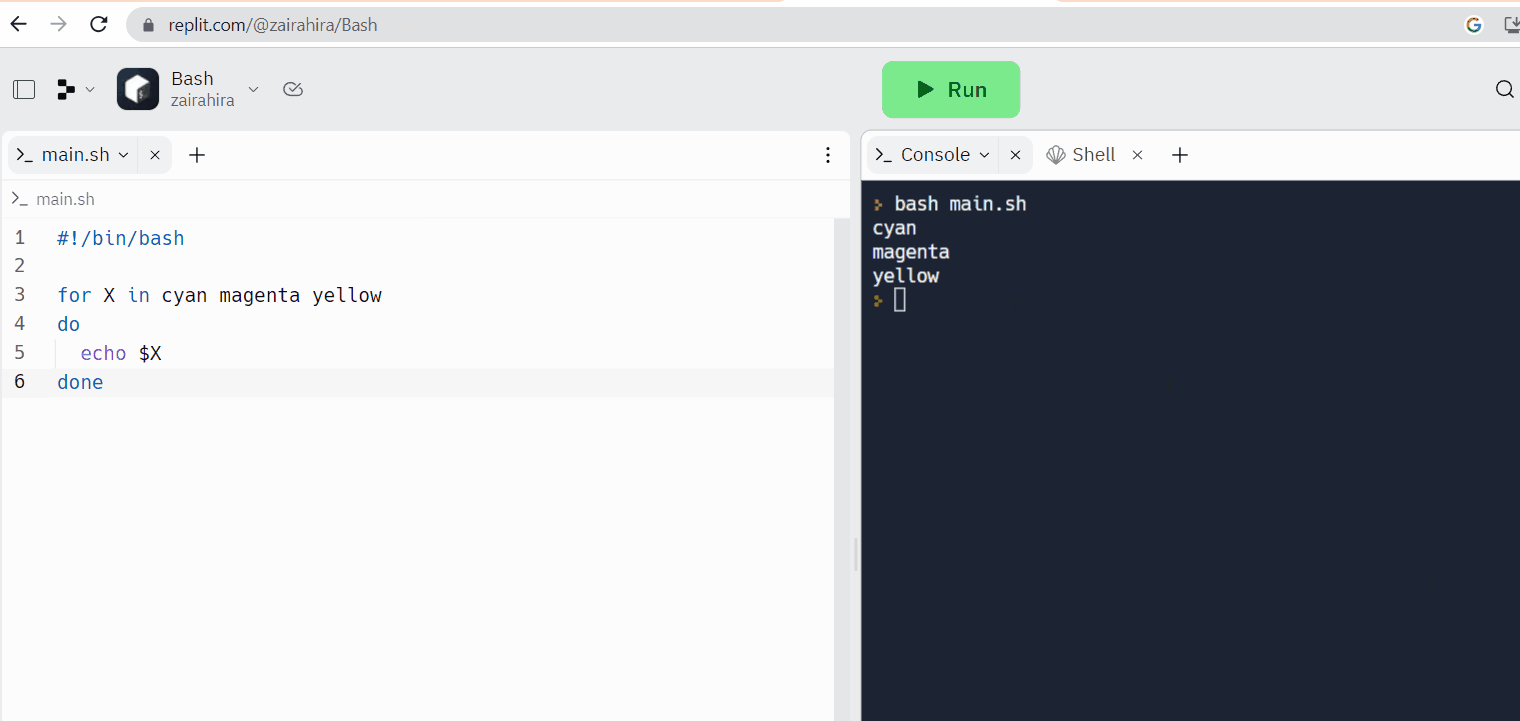
ウェブベースのLinux端末:
オンラインのLinux端末は、ブラウザから直接Linuxのコマンドラインインターフェースにアクセスすることができます。これらの端末は、Linuxシェルに対するウェブベースのインターフェースを提供し、コマンドの実行やLinuxユーティリティーとの作業が可能です。
その一例はJSLinuxです。以下のスクリーンショットは、立ち上げ準備の完了したLinux環境を示しています。
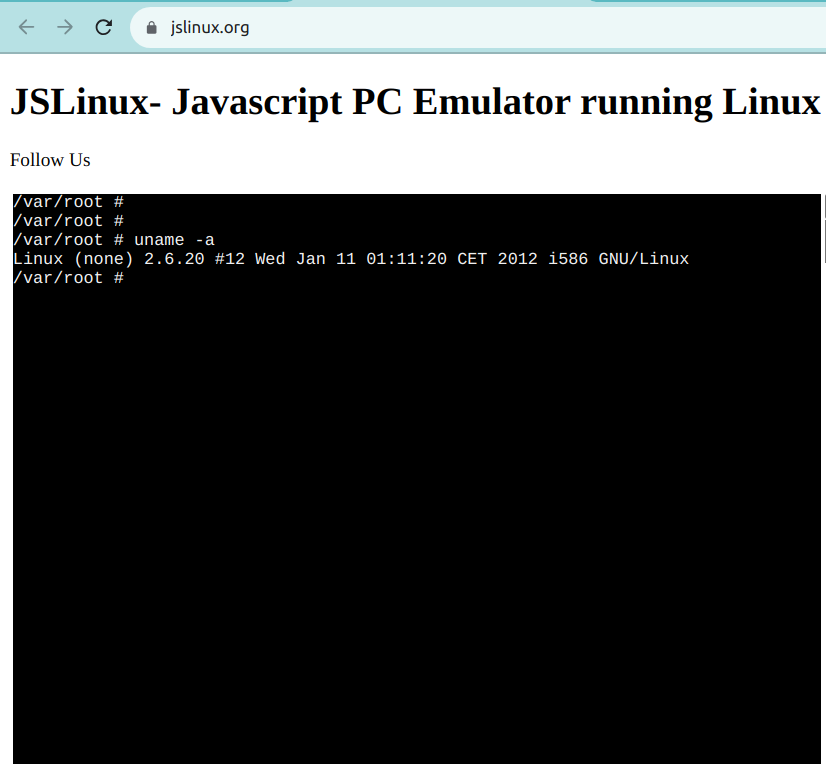
オプション5: クラウドベースのソリューションを使用する
Windowsマシン上で直接Linuxを実行する代わりに、クラウドベースのLinux環境や仮想プライベートサーバー(VPS)を使用して、リモートからLinuxにアクセスして作業することを考慮してください。
Amazon EC2、Microsoft AzureまたはDigitalOceanなどのサービスは、Windowsコンピュータから接続できるLinuxインスタンスを提供します。これらのサービスの中には無料のチャージを提供するものもありますが、長期的には無料ではありません。
第2節: Bashシェルとシステムコマンドについての入門
2.1. Bashシェルを使い始める
Bashシェルについての説明
Linuxのコマンドラインは、シェルと呼ばれるプログラムで提供されています。年月の経過に伴い、シェルプログラムはさまざまなオプションに対応するよう進化しました。
異なるユーザーは、異なるシェルを使用するように設定することができます。しかし、ほとんどのユーザーは現在のデフォルトのシェルを使い続けることを好みます。多くのLinuxディストロのデフォルトのシェルはGNU Bourne-Again Shell (bash)です。BashはBourneシェル(sh)に続いています。
現在のシェルを確認するためには、端末を開いて以下のコマンドを入力します:
echo $SHELL
コマンドの分解:
-
echoコマンドは、端末に印刷するために使用されます。 -
$SHELLは、現在のシェルの名前を保持する特別な変数です。
私の設定では、出力は/bin/bashです。これは、bashシェルを使用していることを意味します。
# 出力
echo $SHELL
/bin/bash
Bashは非常に強力で、GUI(またはグラフィカルユーザーインターフェース)で効率的に行うのが難しい特定の操作を簡素化することができます。ほとんどのサーバーにGUIがないことを覚えておいて、コマンドラインインターフェース(CLI)の力を学ぶのがベストです。
端末とシェルの違い
“端末”と”シェル”という用語は、しばしば互いに交換しながら使用されますが、これらはコマンドラインインターフェースの異なる部分を参照しています。
ターミナルは、シェルと対話するためのインターフェースです。シェルは、コマンドを処理して実行するコマンドインタプリタです。ハンドブックのパート6でシェルについて詳しく学びます。
プロンプトとは何ですか?
シェルが対話的に使用される場合、ユーザーからのコマンドの入力を待っているときに$が表示されます。これはシェルプロンプトと呼ばれます。
[ユーザー名@ホスト ~]$
シェルがrootとして実行されている場合(後でrootユーザーについて詳しく説明します)、プロンプトは#に変更されます。
[root@ホスト ~]#
2.2. コマンド構造
コマンドは、特定の操作を実行するプログラムです。シェルへのアクセスが可能になったら、$の後に任意のコマンドを入力して、その出力をターミナル上で確認することができます。
一般的に、Linuxのコマンドは次の構文に従います。
command [options] [arguments]
上記の構文の詳細は以下の通りです:
-
command: 実行したいコマンドの名前です。ls(リスト)、cp(コピー)、rm(削除)は一般的なLinuxのコマンドです。 [オプション]:ハイフン(-)やダブルハイフン(–)で始まるオプションやフラグは、コマンドの動作を変更します。これらはコマンドの動作を変更することができる。例えば、ls -aは-aオプションを使ってカレントディレクトリの隠しファイルを表示する。[引数]:引数は、1つを必要とするコマンドのための入力です。これらは、ファイル名、ユーザー名、またはコマンドが作用する他のデータかもしれません。例えば、cat access.logというコマンドでは、catがコマンドで、access.logが入力です。その結果、catコマンドはaccess.logファイルの内容を表示する。
オプションと引数はすべてのコマンドに要求されるわけではありません。いくつかのコマンドはオプションや引数なしで実行できますが、他のコマンドは正しく機能するために1つまたは両方を必要とするかもしれません。コマンドのマニュアルを参照して、そのコマンドがサポートしているオプションや引数を確認することができます。
💡ヒント: コマンドのマニュアルを参照するには、man コマンドを使用できます。
lsのマニュアルページを参照するには、man lsを使用し、以下のように表示されます:

マニュアルページは、ドキュメントに素早くアクセスするのに役立つ優れた方法です。最もよく使うコマンドについてのmanページを参照することを強くお勧めします。
2.3. Bashコマンドとキーボードショートカット
ターミナルで作業を行う際、ショートカットを使用して作業を迅速に行うことができます。
以下は、最も一般的なターミナルショートカットの一部です:
| 操作 | ショートカット |
| 前のコマンドを探す | 上矢印キー |
| 前の単語の先頭に移動 | Ctrl+左矢印キー |
| カーソルからコマンドラインの末尾までの文字を消去 | Ctrl+K |
| コマンド、ファイル名、オプションを自動的に補完 | Tabキーを押す |
| コマンドラインの先頭に移動 | Ctrl+A |
| 前のコマンドの一覧を表示 | history |
2.4. 自分自身を特定する:whoami コマンド
ログインしているユーザー名を取得するには、whoami コマンドを使用できます。このコマンドは、異なるユーザー間を切り替えていて、現在のユーザーを確認したい時に便利です。
$記号の直後に whoami と入力し、Enterを押します。
whoami
これが私が得た出力です。
zaira@zaira-ThinkPad:~$ whoami
zaira
Part 3: Linuxシステムを理解する
3.1.OSとスペックを知る
unameコマンドを使ってシステム情報を出力する
unameコマンドから詳細なシステム情報を得ることができます。
-aオプションを指定すると、全てのシステム情報を出力します。
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 GNU/Linux
上記の出力では、
Linux: オペレーティングシステムを示します。zaira:マシンのホスト名を表す。-
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2:カーネルバージョン、ビルド日、いくつかの追加情報を提供します。
x86_64 x86_64 x86_64: システムのアーキテクチャを示します。GNU/Linux:オペレーティングシステムのタイプを表します。
CPUアーキテクチャの詳細をlscpuコマンドで見つける
Linuxのlscpuコマンドは、CPUアーキテクチャに関する情報を表示するために使用されます。ターミナルでlscpuを実行すると、以下のような詳細情報が提供されます:
-
CPUのアーキテクチャ(例:x86_64)
-
CPUの動作モード(例:32ビット、64ビット)
-
バイトオーダー(例:リトルエンディアン)
-
CPU(CPUの数)など
それでは試してみましょう:
lscpu
# 出力
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
これはたくさんの情報ですが、役に立つ情報もあります!関連する情報を特定のフラグを使用してスキムすることができます。man lscpuでコマンドマニュアルを参照してください。
第4部:コマンドラインからのファイル管理
4.1. Linuxのファイルシステム階層
Linuxにおいてすべてのファイルは、ファイルシステムに格納されます。これは根が最上位にあるため、逆木構造になっています。
/はルートディレクトリであり、ファイルシステムの開始地点です。ルートディレクトリには、システム上の他のすべてのディレクトリとファイルが含まれています。/文字は、パス名間のディレクトリセパレータとしても使用されます。たとえば、/home/aliceは完全なパスを形成します。
以下はファイルシステムの完全な階層结构を示しています。各ディレクトリは特定の目的に使用されます。
これは完全なリストではありません。異なるディストリビューションには異なる設定がある可能性があります。
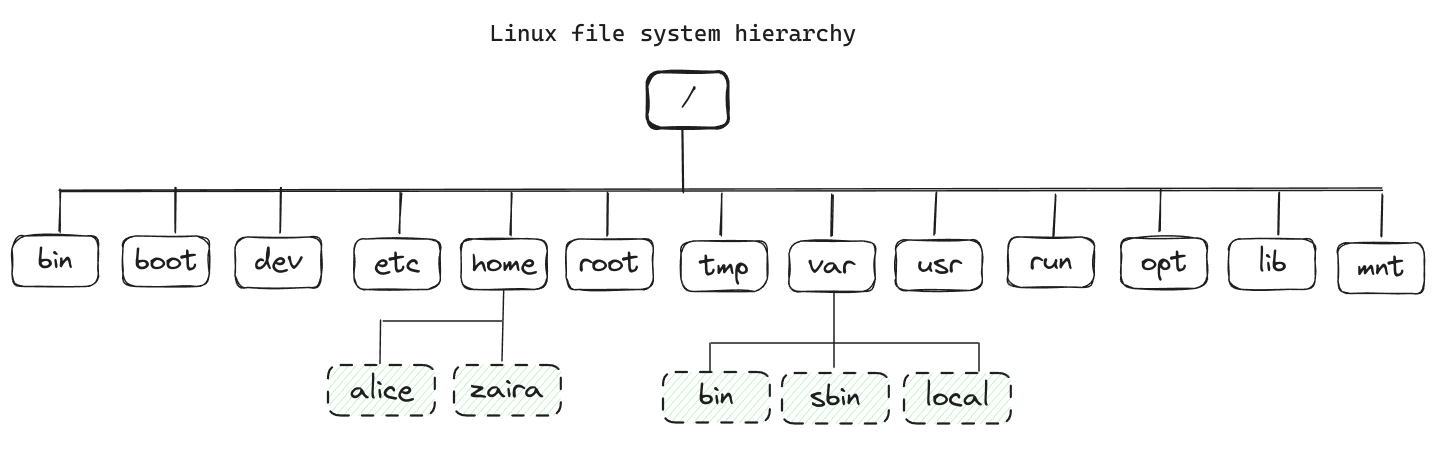
以下は各ディレクトリの用途を示すテーブルです。
| 場所 | 用途 |
| /bin | 基本のコマンドのバイナリ |
| /boot | ブートローダーの静的ファイル。ブートプロセスを開始するために必要です。 |
| /etc | ホスト固有のシステム設定 |
| /home | ユーザーのホームディレクトリ |
| /root | 管理者のルートユーザーのホームディレクトリ |
| /lib | 基本の共有ライブラリとカーネルモジュール |
| /mnt | 一時的にファイルシステムをマウントする場所 |
| /opt | アドオンのアプリケーションソフトのパッケージ |
| /usr | インストールされたソフトウェアと共有ライブラリ |
| /var | ブート間に持続する変数データ |
| /tmp | すべてのユーザーがアクセスできる一時ファイル |
💡 Tip: man hier コマンドを使用してファイルシステムについての詳細を学ぶことができます。
tree -d -L 1 コマンドを使用してあなたのファイルシステムを確認することができます。-L フラグを変更することで树の深さを変更することができます。
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
このリストは総括的ではありません。異なるディストリビューションやシステムによって、構成が異なる場合があります。
4.2. Linuxファイルシステムの操作
絶対パスと相対パス
絶対パスはルートディレクトリからファイルまたはディレクトリへの完全なパスです。常に/で始まります。たとえば、/home/john/documentsです。
一方、相対パスは現在のディレクトリから目的のファイルまたはディレクトリへのパスです。/で始まりません。たとえば、documents/work/projectです。
現在のディレクトリをpwdコマンドで確認する
Linuxのファイルシステムで迷子になることがありますが、特にコマンドラインに慣れていない場合です。pwdコマンドを使用して現在のディレクトリを確認できます。
以下は例です:
pwd
# 出力
/home/zaira/scripts/python/free-mem.py
cdコマンドを使用してディレクトリを変更する
ディレクトリを変更するコマンドはcdで、それは”change directory”の略です。cdコマンドを使用して別のディレクトリに移動できます。
相対パスまたは絶対パスを使用できます。
たとえば、以下のようなファイル構造を移動する場合(赤い線に沿って):
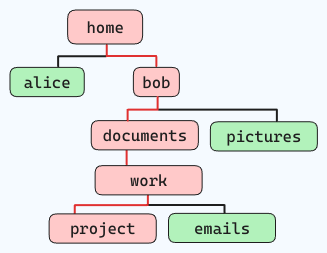
現在”home”にいるとします。その場合のコマンドは以下のようになります:
cd home/bob/documents/work/project
他によく使われるcdのショートカットコマンド:
| コマンド | 説明 |
cd .. |
ディレクトリを一つ上に移動 |
cd ../.. |
ディレクトリを二つ上に移動 |
cd または cd ~ |
ホームディレクトリに移動 |
cd - |
前のパスに移動 |
4.3. ファイルとディレクトリの管理
ファイルとディレクトリを操作する際には、コピー、移動、削除、新しいファイルとディレクトリの作成が必要になることがあります。以下は、これらの操作を行うためのいくつかのコマンドです。
💡ヒント: ls -lの出力の最初の文字で、ファイルとディレクトリを区別することができます。'-'はファイルを、'd'はディレクトリを表します。
mkdirコマンドを使用して新しいディレクトリの作成
mkdirコマンドを使用して空のディレクトリを作成することができます。
# 現在のフォルダー内に空のディレクトリ"foo"を作成します
mkdir foo
また、-pオプションを使用して再帰的にディレクトリを作成することもできます。
mkdir -p tools/index/helper-scripts
# treeの出力
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
touchコマンドを使用して新しいファイルの作成
touchコマンドは空のファイルを作成します。以下のように使用できます:
# 現在のフォルダー内に空のファイル"file.txt"を作成します
touch file.txt
一度のコマンドで複数のファイルを作成する場合、ファイル名を連結することができます。
現在のフォルダーに空のファイル "file1.txt"、"file2.txt"、および"file3.txt" を作成します
touch file1.txt file2.txt file3.txt
rm と rmdir コマンドを使用してファイルとディレクトリを削除します
rm コマンドを使用して、ファイルと空でないディレクトリの両方を削除できます
| コマンド | 説明 |
rm file.txt |
ファイル file.txt を削除します |
rm -r directory |
ディレクトリ directory とその内容を削除します |
rm -f file.txt |
確認のためのプロンプトを表示せずにファイル file.txt を削除します |
rmdir directory |
空のディレクトリを削除します |
🛑 -f フラグを使用する際には注意してください。ファイルを削除する前に確認はされません。また、root フォルダーで rm コマンドを実行する際には、重要なシステムファイルを削除する可能性があるため、注意が必要です
cp コマンドを使用してファイルをコピー
Linuxでファイルをコピーするには、cp コマンドを使用します
- ファイルをコピーする構文:
cp ソースファイル ファイルの宛先
このコマンドは、file1.txt という名前のファイルを新しいファイルの場所 /home/adam/logs にコピーします
cp file1.txt /home/adam/logs
cp コマンドは、指定された名前で1つのファイルのコピーを作成することもできます
このコマンドは、file1.txtというファイルを同じフォルダ内の別のファイルfile2.txtにコピーします。
cp file1.txt file2.txt
ファイルやフォルダを移動して名前を変更するmvコマンド
mvコマンドは、ファイルやフォルダを1つのディレクトリから別のディレクトリに移動するために使用されます。
ファイルを移動する構文:mv ソースファイル ディレクトリの宛先
例: ファイルfile1.txtをbackupというディレクトリに移動する:
mv file1.txt backup/
ディレクトリとその内容を移動するには:
mv dir1/ backup/
Linuxでファイルやフォルダの名前を変更する場合も、mvコマンドを使用します。
ファイルの名前を変更する構文:mv 古い名前 新しい名前
例: ファイルをfile1.txtからfile2.txtに名前を変更する:
mv file1.txt file2.txt
ディレクトリをdir1からdir2に名前を変更する:
mv dir1 dir2
4.4. findコマンドを使用してファイルやフォルダを検索する
findコマンドを使用すると、効率的にファイル、フォルダ、およびキャラクタデバイスとブロックデバイスを検索できます。
findコマンドの基本構文は以下の通りです:
find /path/ -type f -name file-to-search
ここで、
-
/pathはファイルが見つかることが期待されるパスです。これはファイルを検索するための開始点です。パスは/または.であっても構いません。それぞれルートと現在のディレクトリを表します。 -
-typeは、ファイル記述子を表します。以下のいずれかを持っていることができます。
f– 通常のファイルです。テキストファイル、画像、および隠しファイルなどです。
d– ディレクトリです。これらは、考慮されるフォルダです。
l– シンボリックリンクです。シンボリックリンクは、短縮機能と似たような、ファイルを指し示すものです。
c– 文字装置です。文字装置にアクセスするためのファイルは、文字装置ファイルと呼ばれます。ドライバーは、文字(バイト、オクテット)を送信して受信することで、文字装置とやり取りを行います。例えば、キーボード、サウンドカード、マウスなどです。
b– ブロック装置です。ブロック装置にアクセスするためのファイルは、ブロック装置ファイルと呼ばれます。ドライバーは、ブロック装置とやり取りするために、データのブロックを送信して受信します。例えば、USBとCD-ROMなどです。 -nameは、探したいファイルの名前を表します。
名前または拡張子でファイルを探す方法
例えば、名前に”style”を含むファイルを探す必要があったとします。この場合、このコマンドを使用します。
find . -type f -name "style*"
#output
./style.css
./styles.css
ここで、特定の拡張子.htmlを持つファイルを探す必要があったとします。この場合、コマンドを以下のように修正します。
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
隠しファイルを探す方法
ファイル名の先頭にの点は隠しファイルを表します。通常は隠していますが、ls -aを使用して現在のディレクトリ内で表示することができます。
以下のようにfindコマンドを変更することで、隠しファイルを搜索することができます。
find . -type f -name ".*"
隠しファイルの一覧と探し方
ls -la
# フォルダの内容
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# findの出力
./.bash_logout
./.bashrc
./.bash_history
上では、私のホームディレクトリ内の隠しファイルの一覧が表示されています。
ログファイルと設定ファイルを搜索する方法
ログファイルには.logという拡張子が一般的で、このように搜索することができます。
find . -type f -name "*.log"
同様に、設定ファイルをこのように搜索することができます。
find . -type f -name "*.conf"
他の種類のファイルをどのように搜索するか
字符型のファイルを搜索するために-typeにcを与えることができます。
find / -type c
同様に、デバイスブロック型のファイルをbを使用して搜索することができます。
find / -type b
ディレクトリを搜索する方法
以下の例では、-type dフラグを使用してフォルダを搜索しています。
ls -l
# フォルダの内容の一覧
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# findDirectoryの出力
.
./webp
./images
./style
./hosts
ファイルの大きさに基づいて搜索する方法
findコマンドの非常に便利な使い方は、特定の大きさのファイルに基づいてファイルを一覧表示することです。
find / -size +250M
ここでは、250MBを超える大きさのファイルを一覧表示しています。
其他の単位には以下があります。
-
G: ギガバイト。 -
M: メガBYTE。 -
K: キロBYTE -
c: BYTE。
適切な単位に置き換えてください。
find <directory> -type f -size +N<Unit Type>
modification time でファイルを search する方法
`-mtime` フラグを使用することで、変更時間に基づいてファイルとフォルダを絞り込むことができます。
find /path -name "*.txt" -mtime -10
例えば、
-
-mtime +10 は、10日前に変更されたファイルを探すことを意味します。
-
-mtime -10 は、10日以下のものを意味します。
-
-mtime 10 + や – を省略した場合、正確に10日の意味を持ちます。
4.5. ファイルを表示するための基本コマンド
`cat` コマンドを使用してファイルを結合して表示します。
Linuxの`cat`コマンドは、ファイルの内容を表示するために使用されます。また、ファイルを結合し、新しいファイルを作成することもできます。
`cat`コマンドの基本的なスyntaxは以下の通りです。
cat [options] [file]
`cat`コマンドを使用する最も簡単な方法は、オプションや引数を使用しないことです。これは、端末上でファイルの内容を表示します。
以下のコマンドを使用することで、file.txtという名前のファイルの内容を表示することができます。
cat file.txt
これにより、ファイルの内容が一度に端末上に表示されます。
lessとmoreを使用したテキストファイルの対話的な表示
catはファイル全体を一度に表示しますが、lessとmoreを使用するとファイルの内容を対話的に表示できます。これは大きなファイルをスクロールしたり特定の内容を探したりする場合に便利です。
lessコマンドの構文は以下の通りです。
less [options] [file]
moreコマンドはlessに似ていますが、機能が少ないです。これは1画面ごとにファイルの内容を表示するために使用されます。
moreコマンドの構文は以下の通りです。
more [options] [file]
どちらのコマンドでも、スペースバーを使用して1ページ下にスクロールし、Enterキーを使用して1行下にスクロールし、qキーを使用してビューアを終了できます。
後方に移動するにはbキー、前方に移動するにはfキーを使用できます。
tailを使用したファイルの最後の部分の表示
時には、ファイル全体を表示する代わりに、ファイルの最後の数行だけを表示したい場合があります。
たとえば、tail file.txtはデフォルトでfile.txtの最後の10行を表示します。
# ファイル file.txt の最後の50行を表示する
tail -n 50 file.txt
💡Tip: tail の別の使い方は、-f オプションです。このオプションを使用すると、ファイルの内容が書き込まれるのを実時間で見ることができます。これは、リアルタイムでログファイルを表示したり監視するのに便利なツールです。
Linuxでheadを使用してファイルの先頭を表示する
tailがファイルの最後の部分を表示するのと同様に、headコマンドを使用することで、ファイルの先頭を表示することができます。
例えば、head file.txtはデフォルトでfile.txtの最初の10行を表示します。
表示する行数を変更するには、-nオプションを使用して、表示したい行数を指定することができます。
wcを使用して単語、行、文字数を数える
ファイルに単語、行、文字数を数えることができます。wcコマンドを使用します。
たとえば、wc syslog.logを実行すると以下のような出力が得られます。
1669 9623 64367 syslog.log
上の出力では、
-
1669はsyslog.logファイルにある行の数を表します。 -
9623はsyslog.logファイルにある単語の数を表します。 -
64367はsyslog.logファイルの文字数を表します。
したがって、wc syslog.logコマンドはsyslog.logファイルに1669行、9623単語、64367文字を数えました。
diffコマンドの基本構文は以下の通りです。
diff [options] file1 file2
以下はhello.pyとalso-hello.pyの2つのファイルをdiffコマンドを使用して比較するための例です。
# hello.pyの内容
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# also-hello.pyの内容
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
diff -q hello.py also-hello.py
# 出力
Files hello.py and also-hello.py differ
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- 上記の出力では、
--- hello.py 2024-05-24 18:31:29.891690478 +0500は比較されているファイルとそのタイムスタンプを示しています。+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500は比較されている別のファイルとそのタイムスタンプを示しています。@@ -3,4 +3,5 @@は変更が発生する行番号を示しています。この場合、元のファイルの3行から4行が変更され、修正されたファイルでは3行から5行に変更されていることを示しています。user = input(Enter your name: )は元のファイルの一行です。print(greet(user))は元のファイルの別の行です。
+print("Nice to meet you")は修正されたファイルの追加行です。
diff -y hello.py also-hello.py
サイドバイサイド形式での差分を表示するには、-yフラグを使用できます。
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# 出力
- 出力では:
- 両方のファイルで同じ行が並んで表示されます。
異なる行は、片方のファイルにのみ存在することを示す>記号で表示されます。
パート5: Linuxでのテキスト編集の基礎
コマンドラインを使用したテキスト編集のスキルは、Linuxで最も重要なスキルの1つです。このセクションでは、Linuxで2つの人気のあるテキストエディタであるVimとNanoの使用方法を学びます。
選んだテキストエディタをマスターし、それに固執することをお勧めします。これにより、時間が節約され、生産性が向上します。Vimとnanoは、ほとんどのLinuxディストリビューションに搭載されているため、安全な選択肢です。
5.1. Vimのマスタリング: 完全ガイド
Vimの紹介
- Vimは、コマンドライン用の人気のあるテキスト編集ツールです。Vimには次のような利点があります: パワフルでカスタマイズ可能で速いです。Vimを学ぶべき理由のいくつかは次のとおりです。
- ほとんどのサーバーはCLI経由でアクセスされるため、システム管理ではGUIの贅沢をする必要はありません。しかし、Vimはあなたをサポートしてくれます – 常にそこにいます。
- Vimはキーボード中心のアプローチを使用しています。マウスなしで使用することが設計されているため、キーボードショートカットを学習すると編集タスクを大幅に高速化することができます。これにより、GUIツールよりも高速化されます。
- Linuxの一部のユーティリティ、例えばcronジョブの編集など、Vimと同じ編集形式で動作します。
Vimは初心者から上級者まで適しています。Vimは複雑な文字列の検索、検索のハイライト表示などをサポートしています。プラグインを介して、Vimは開発者やシステム管理者にコード補完、構文のハイライト表示、ファイル管理、バージョン管理などの拡張機能を提供しています。
Vimには2つのバリエーションがあります:Vim(vim)とVim tiny(vi)。Vim tinyはVimの一部の機能が欠けた小さなバージョンです。
vimの使い方
vim your-file.txt
このコマンドでVimを使用できます:
your-file.txtは新しいファイルまたは編集したい既存のファイルのいずれかです。
Vimの操作:移動とコマンドモードのマスタリング
CLIの初期の日々、キーボードに矢印キーがありませんでした。したがって、ナビゲーションは利用可能なキーセットで行われ、hjklがその一つでした。
キーボード中心の操作で、hjklキーを使うことでテキスト編集作業を大幅に加速させることができます。
注意:矢印キーは完全に問題ないですが、hjklキーでのナビゲーションを試すことができます。これによるナビゲーションが効率的だと感じる人もいます。

💡ヒント:hjklのシーケンスを覚えるために、これを使います:hを後ろに、jを下に、kを上に、lを前に飛びます。
3つのVimモード
- Vimの3つの操作モードを知っておく必要があり、それら間で切り替える方法を把握する必要があります。キーストロークは各コマンドモードで異なる動作をすることがあります。3つのモードは以下の通りです:
- コマンドモード。
- 編集モード。
視覚モード。
コマンドモード。Vimを起動すると、デフォルトでコマンドモードになります。このモードでは、他のモードにアクセスすることができます。
⚠他のモードに切り替えるには、まずコマンドモードにいなければなりません
編集モード
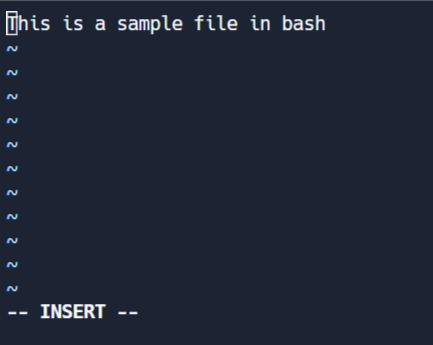
このモードでは、ファイルに変更を加えることができます。編集モードに入るには、コマンドモードでIを押します。スクリーンの端に'-- INSERT'が表示されることに注意してください。
ビジュアルモード
- このモードでは、1文字、テキストのブロック、またはテキストの行に作業することができます。簡単な手順に分解してみましょう。下記のコンビネーションは、コマンドモードで使用してください。
Shift + V→ 複数の行を選択。Ctrl + V→ ブロックモード
V → 文字モード
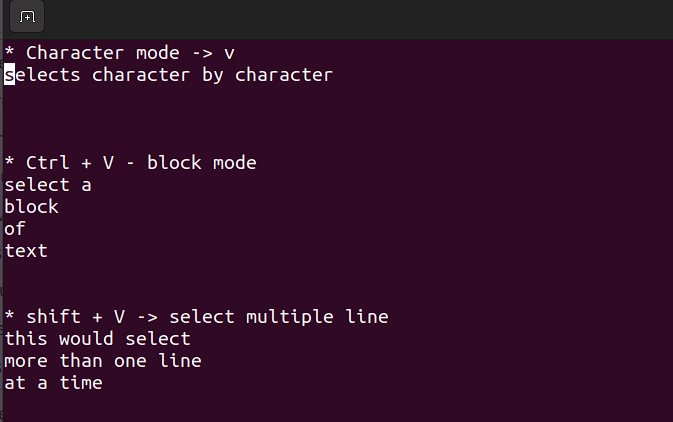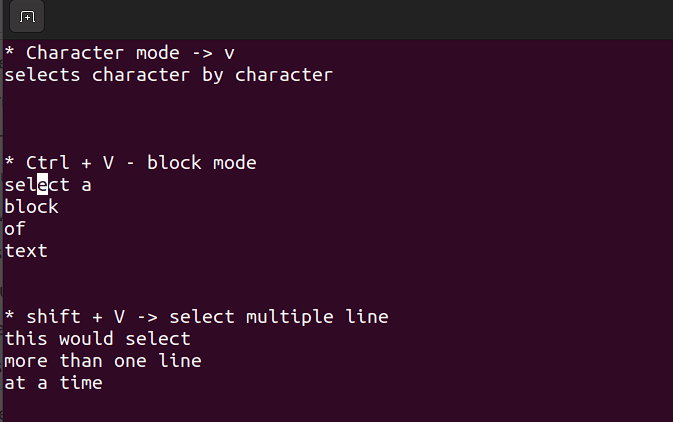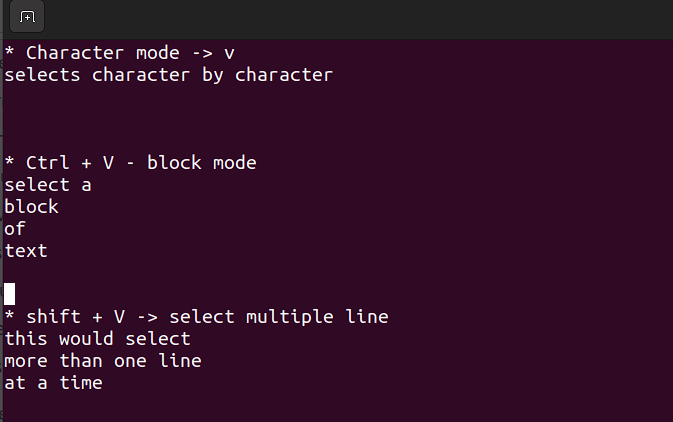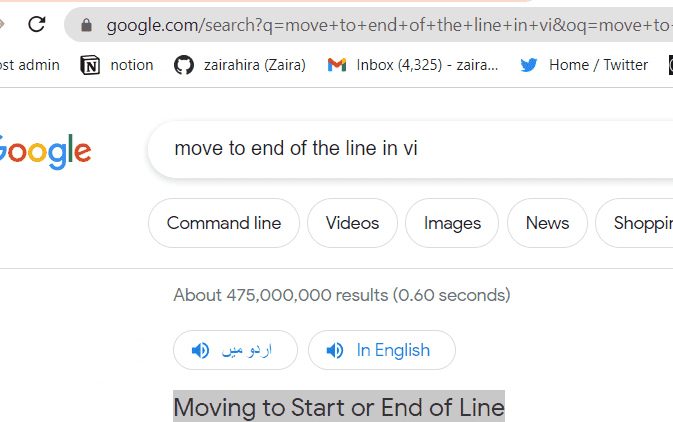
ビジュアルモードは、一括で行をコピーしたり、貼り付けたり編集する必要があるときに便利です。
拡張コマンドモード。
拡張コマンドモードでは、検索、行番号の設定、テキストのハイライトなど、高度な操作を行うことができます。拡張モードについては次のセクションで説明します。
どうすれば正しいモードに留まることができますか?現在のモードを忘れた場合は、ESCを2回押すと、コマンドモードに戻ります。
Vimで効率的に編集する: コピー/貼り付けと検索
1. Vimでのコピーと貼り付けの方法
- コピーと貼り付けは、Linuxの用語では ‘yank’ と ‘put’ として知られています。コピーと貼り付けるには、以下の手順に従ってください:
- ビジュアルモードでテキストを選択。
'y'を押してコピー/ yank。
マウスカーソルを必要な位置に移動して'p'を押下してください。
Vimでテキストを検索する方法
Vimのコマンドモードで/を使用して任意の文字列シーケンスを検索できます。検索するには、/検索したい文字列を使用します。
コマンドモードで:set hlsと入力し、enterを押します。これにより/検索したい文字列で検索を行うと、検索結果がハイライト表示されます。
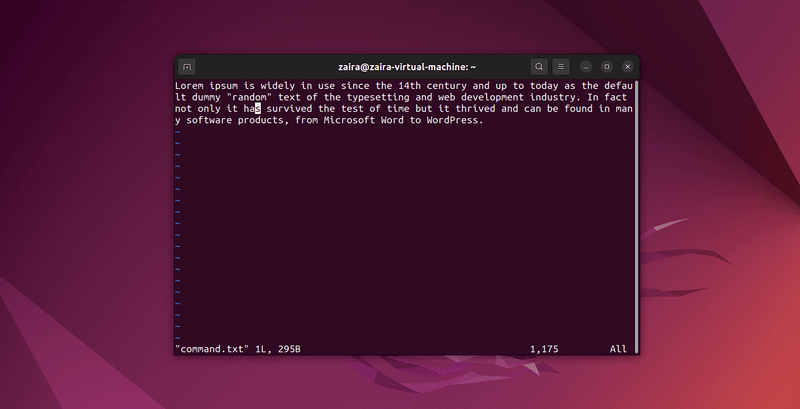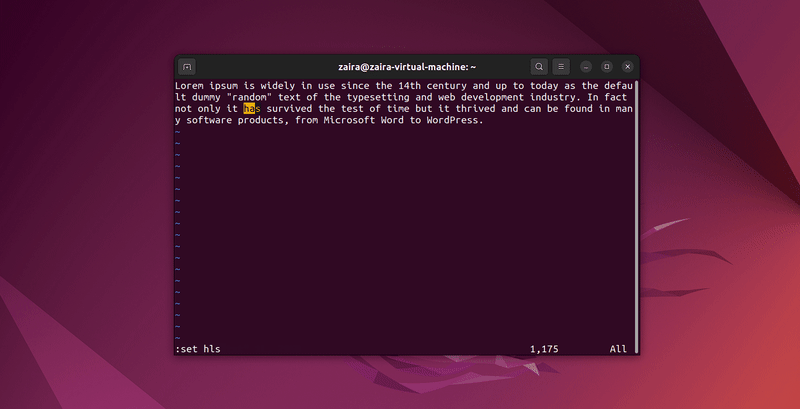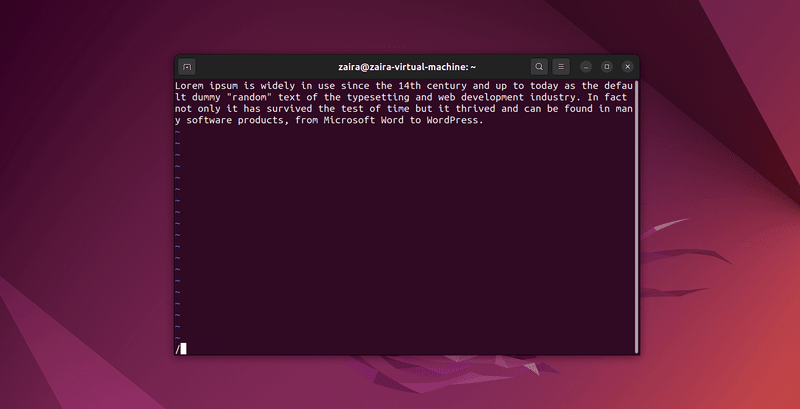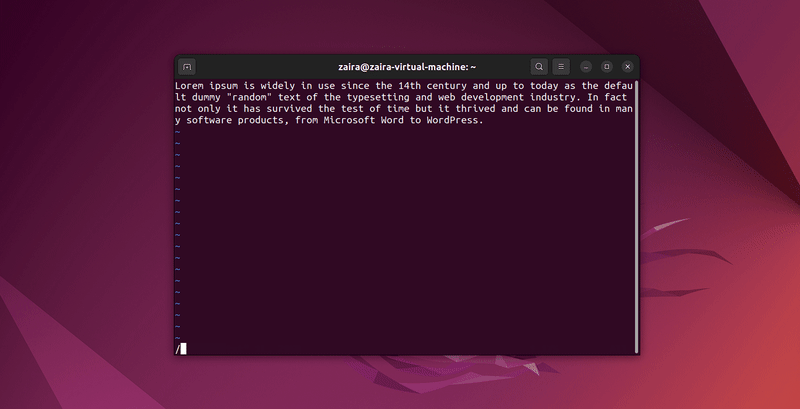
いくつかの文字列を検索してみましょう。
Vimを終了する方法
- 最初にコマンドモードに移動します(Escを2回押下)。その後、以下のフラグを使用します。
- 保存せずに終了する →
:q!
保存して終了する → :wq!
Vimのショートカット:編集を迅速にする
- 注記:これらのショートカットはすべてコマンドモードでのみ動作します。
Ctrl+u: 半ページ上に移動P: カーソルの上に貼り付けます:%s/old/new/g: ファイル内のすべてのoldをnewに置換:q!: 保存せずに終了
Ctrl+w に続けて h/j/k/l: 分割ウィンドウ間を移動
5.2. Nanoのマスタリング
Nanoの始め方: ユーザーフレンドリーなテキストエディタ
Nanoは、使いやすく、初心者に最適なユーザーフレンドリーなテキストエディタです。ほとんどのLinuxディストリビューションには既にインストールされています。
nano
Nanoを使って新しいファイルを作成するには、以下のコマンドを使用します:
nano filename
Nanoで既存のファイルを編集し始めるには、以下のコマンドを使用します:
Nanoのキーバインディング一覧
Nanoで最も重要なキーバインディングを学びましょう。これらのキーバインディングを使って、保存、終了、コピー、貼り付けなど、さまざまな操作を行います。
ファイルに書き込みと保存
一度nanoコマンドを使用してNanoを開いたら、テキストの書き込みを始めることができます。ファイルを保存するには、Ctrl+Oを押します。ファイル名を入力するよう促されます。ファイルを保存するにはEnterを押します。
Nanoを終了する
Nanoを終了するには、Ctrl+Xを押します。保存されていない変更がある場合、Nanoは終了前に変更を保存するよう促します。
コピーと貼り付け
領域を選択するにはALT+Aを使用します。マーカーが表示されます。矢印キーを使用してテキストを選択します。選択後、ALT+^でマーカーを終了します。
選択したテキストをコピーするには、Ctrl+Kを押します。コピーしたテキストを貼り付けるには、Ctrl+Uを押します。
切り取りと貼り付け
領域をALT+Aで選択します。選択後、テキストをCtrl+Kで切り取ります。切り取ったテキストを貼り付けるには、Ctrl+Uを押します。
ナビゲーション
ファイルの先頭に移動するにはAlt \を使用します。
ファイルの末尾に移動するにはAlt /を使用します。
行番号の表示
nano -l filenameでファイルを開くと、ファイルの左側に行番号が表示されます。
検索
特定の行番号を検索するにはALt + Gを使用します。プロンプトに行番号を入力し、Enterを押します。
You can also start searching for a string with CTRL + W and press Enter. If you want to search backwards, you can press Alt+W after initiating the search with Ctrl+W.
- Nanoのキーバインド概要
Ctrl+G: ヘルプテキストを表示Ctrl+J: 現在のパラグラフを整形Ctrl+V:1ページ下にスクロールCtrl+\:検索と置換
Alt+E: 元に戻した最後の操作を再実行する
第6部:Bashスクリプティング
6.1. Bashスクリプトの定義
Bashスクリプトは、bashプログラムによって1行ごとに実行される一連のコマンドを含むファイルです。これにより、特定のディレクトリに移動したり、フォルダーを作成したり、コマンドラインを使用してプロセスを起動するような一連のアクションを実行することができます。
スクリプト内にコマンドを保存することで、同じ手順のシーケンスを何度も繰り返し実行することができ、スクリプトを実行することで実行できます。
6.2. Bashスクリプティングの利点
Bashスクリプティングは、Unix/Linuxシステムでのシステム管理タスクの自動化、システムリソースの管理、その他の日常的な作業を行う強力で汎用性の高いツールです。
- シェルスクリプティングの利点には以下があります:
- 自動化: シェルスクリプトを使用することで、繰り返しの作業やプロセスを自動化でき、手動実行時に発生する可能性のあるエラーを減らしながら時間を節約できます。
- ポータブル性: シェルスクリプトは、Unix、Linux、macOS、さらにはエミュレーターや仮想マシンを使用するWindowsでも実行可能な様々なプラットフォームやオペレーティングシステム上で実行できます。
- 柔軟性: シェルスクリプトは高度にカスタマイズ可能で、特定の要求に合わせて簡単に修正できます。また、他のプログラミング言語やユーティリティと結合することで、より強力なスクリプトを作成することができます。
- アクセス性: シェルスクリプトは書くのが簡単で、特別なツールやソフトウェアを必要としません。テキストエディタを使用して編集でき、ほとんどのオペレーティングシステムには内蔵のシェルインタプリタがあります。
- 統合: シェルスクリプトは他のツールやアプリケーションと統合でき、データベース、ウェブサーバー、クラウドサービスなどに結合し、より複雑な自動化とシステム管理作业を実行できます。
デバッグ: シェルスクリプトは簡単にデバッグできます。ほとんどのシェルには内蔵のデバッグとエラー報告ツールがあり、問題の特定と迅速な修正を助けます。
6.3 バシュシェルとコマンドラインインターフェースの概要
「シェル」と「バシ」はよくよく使われるが、两者間には微妙な違いがあります。
「シェル」とは、オペレーティングシステムとのやり取りを行うコマンドラインインターフェースを提供するプログラムのことを指します。バシ(Bourne-Again SHell)は最も一般的に使われるUnix/Linuxのシェルの1つであり、多くのLinuxディストリビューションでデフォルトのシェルです。
まだ今まで入力してきたコマンドは基本的には「シェル」に入力されていました。
バシはシェルの1つのタイプであるにも関わらず、他にもKorn shell(ksh)、C shell(csh)、Z shell(zsh)などの他のシェルが利用可能です。各シェルには独自の構文と機能のセットがあるが、すべてがオペレーティングシステムとのやり取りを行うコマンドラインインターフェースを提供する共通の目的を持っています。
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
psコマンドを使用して、シェルのタイプを決定することができます。
要約すると、「シェル」はコマンドラインインターフェースを提供するあらゆるプログラムを指し、「バシ」はUnix/Linuxシステムで幅広く使用される特定のタイプのシェルを指します。
注意:この節では「bash」シェルを使用します。
6.4. Bashスクリプトの作成と実行方法
スクリプト名の慣例
スクリプト名の慣例によると、bashスクリプトは「.sh」を末尾に付けることが一般的です。しかし、「sh」エクステンションを持たないともbashスクリプトは完全に機能します。
シェバングの追加
Bashスクリプトはshebangで始まります。Shebangはbash #とbang !の組み合わせに、bashシェルのパスが続くものです。これはスクリプトの最初の行です。Shebangはシェルにbashシェルを通じて実行するよう指示します。Shebangは単にbashインタプリタへの絶対パスです。
#!/bin/bash
以下はshebang文の例です。
which bash
bashシェルのパス(上記とは異なる場合もあります)を以下のコマンドで見つけることができます:
最初のbashスクリプトの作成
最初のスクリプトは、ユーザーにパスを入力するよう促し、その内容を一覧表示します。
vim run_all.sh
好みのエディタでrun_all.shという名前のファイルを作成してください。
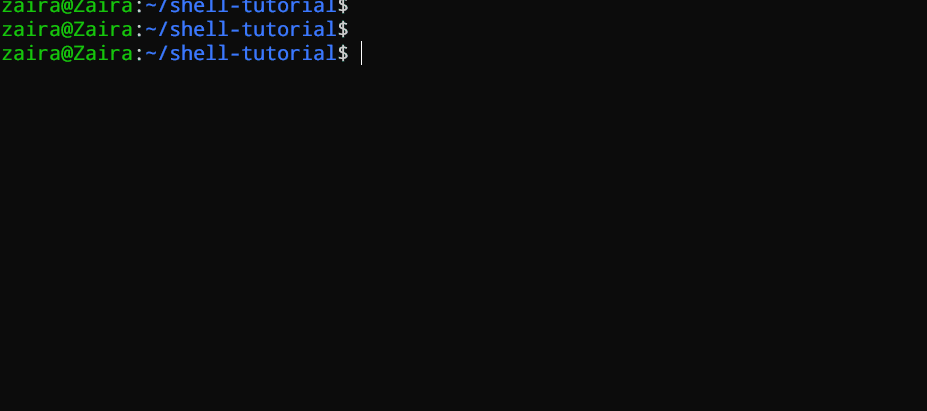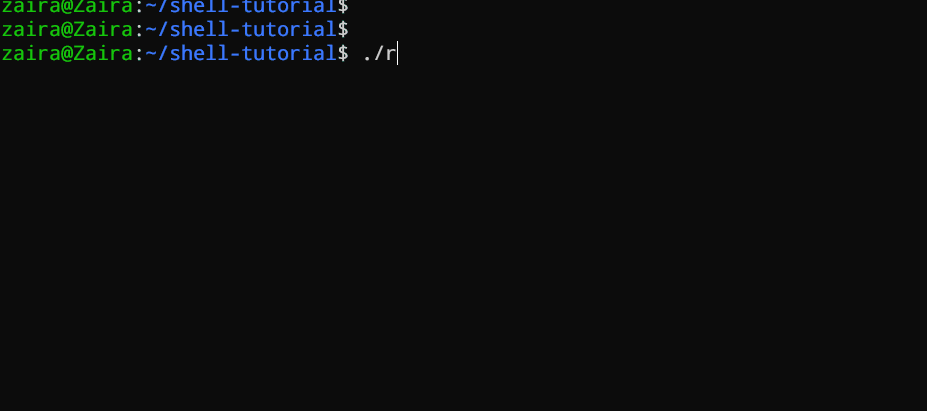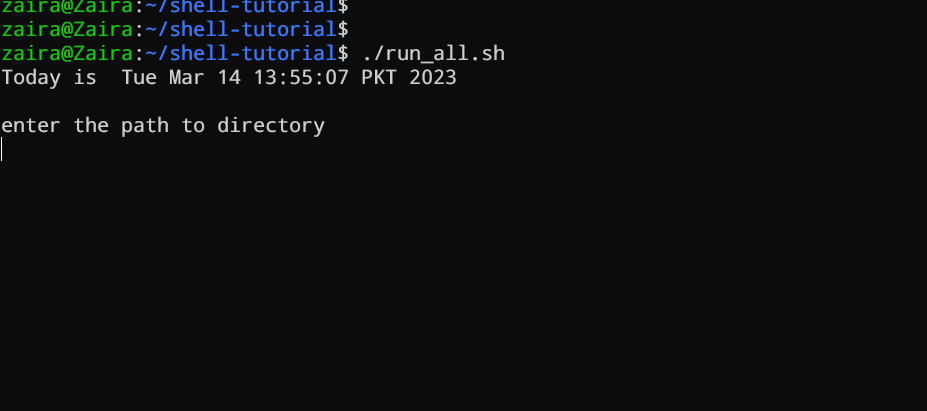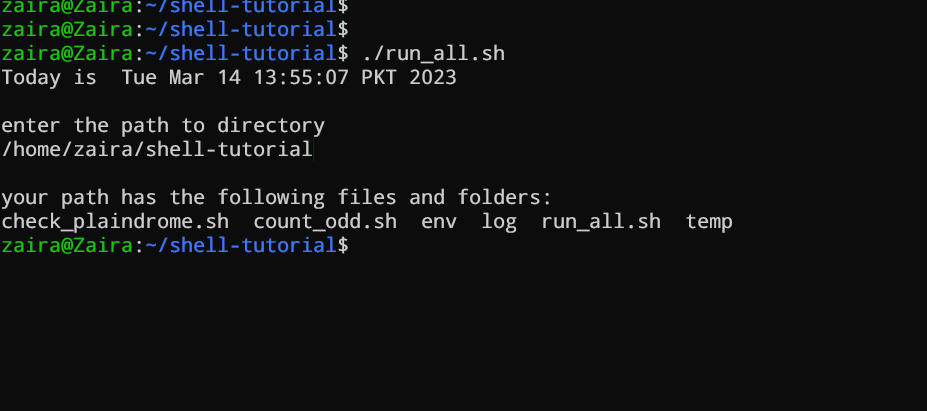
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
以下のコマンドをファイルに追加して保存してください:
1 スクリプトを行ごとに深く見ていきましょう。今度は行番号を付けて同じスクリプトを再度表示します。
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- 行#1: shebang (
#!/bin/bash)はbashシェルのパスを指しています。 - 行#2:
echoコマンドは現在の日付と時刻を端末上に表示します。dateがバックティック内にあることに注意してください。 - 行#4: ユーザーに有効なパスを入力するよう促します。
- 行番号5:
readコマンドは入力を読み取り、それを変数the_pathに格納します。
行番号8: lsコマンドは格納されたパスを持つ変数を取得し、現在のファイルとフォルダーを表示します。
bashスクリプトの実行
chmod u+x run_all.sh
スクリプトを実行可能にするために、以下のコマンドを使用して実行権限をユーザーに割り当てます。
- ここで、
chmodは現在のユーザーの所有者権を変更します:u</code。+xは現在のユーザーに実行権を追加します。これは、所有者となるユーザーが今やスクリプトを実行できることを意味します。
run_all.shは実行したいファイルです。
- スクリプトを実行するには、以下のいずれかの方法で実行できます:
sh run_all.shbash run_all.sh
./run_all.sh
実行中の動作を見てみましょう 🚀
6.5. Bashスクリプト基礎
Bashスクリプトのコメント
Bashスクリプトでは、コメントは # で始まります。つまり、# で始まる行はコメントであり、インタプリタによって無視されます。
コメントはコードのドキュメント作成に非常に役立ち、他の人がコードを理解するのを助けるために追加するのが良い習慣です。
以下はコメントの例です:
# これはコメントの例です
# これらの行はどちらもインタプリタによって無視されます
Bashでの変数とデータ型
変数を使用するとデータを保存できます。変数を使用してスクリプト全体でデータを読み取り、アクセス、操作できます。
Bashにはデータ型がありません。Bashでは、変数は数値、個々の文字、または文字列を保存できます。
- Bashでは、変数の値を以下の方法で使用および設定できます:
country=Netherlands
直接値を割り当てる:
same_country=$country
プログラムまたはコマンドの出力に基づいて値を割り当てる場合、コマンドの置換を使用します。既存の変数の値にアクセスするには$が必要です。
これにより、countryの値が新しい変数same_countryに割り当てられます。
country=Netherlands
echo $country
変数の値にアクセスするには、変数名の末尾に$を追加します。
Netherlands
new_country=$country
echo $new_country
出力
Netherlands
出力
上記は、変数に値を割り当てて印刷する例です。
変数命名の規則
- Bashスクリプトでは、以下のような変数命名の規則があります:
- 変数名は文字かアンダースコア (
_) で始まる必要があります。 - 変数名には文字、数字、およびアンダースコア (
_) を含めることができます。 - 変数名は大文字と小文字を区別します。
- 変数名にはスペースや特殊文字を含めることはできません。
- 変数の目的を反映する説明的な名前を使用します。
if、then、else、fiなどの予約済みキーワードを変数名として使用しないようにします。
name
count
_var
myVar
MY_VAR
以下はBashで有効な変数名の例です:
以下は無効な変数名の例です:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
不正な変数名
これらの命名規則に従うことで、Bash スクリプトをより読みやすく保守しやすくすることができます。
Bash スクリプトの入出力
入力の取得
- このセクションでは、スクリプトに入力を提供するいくつかの方法を議論します。
ユーザーの入力を読んで変数に格納する
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
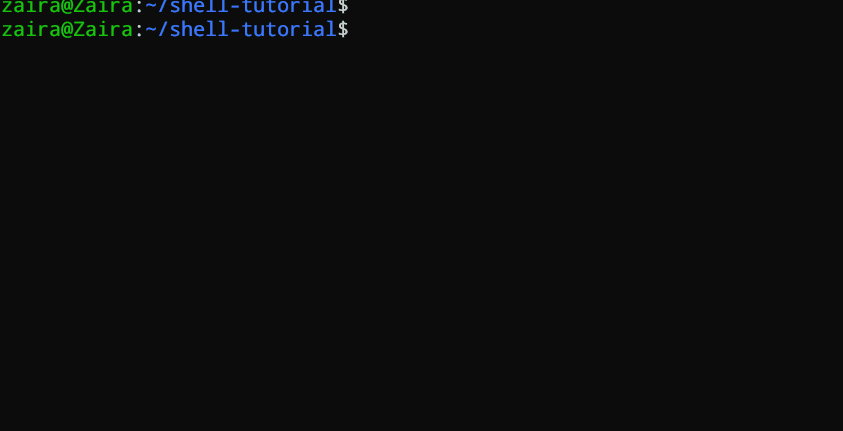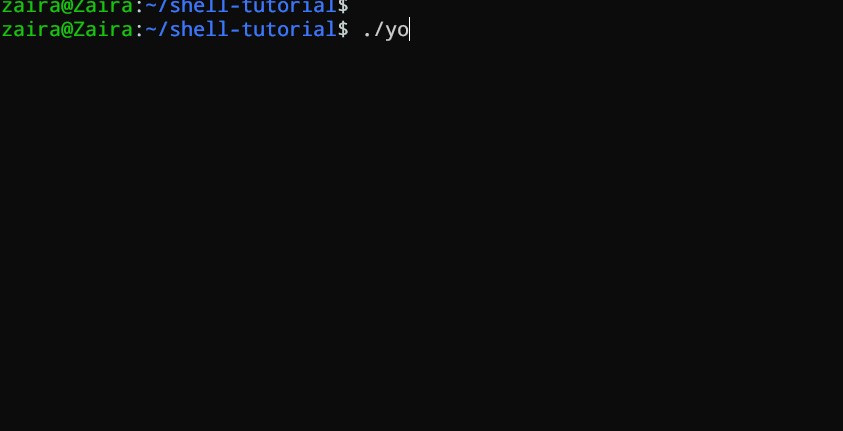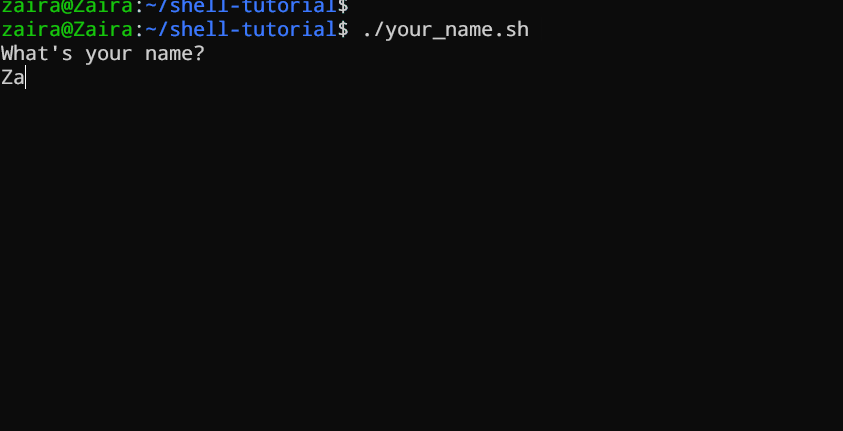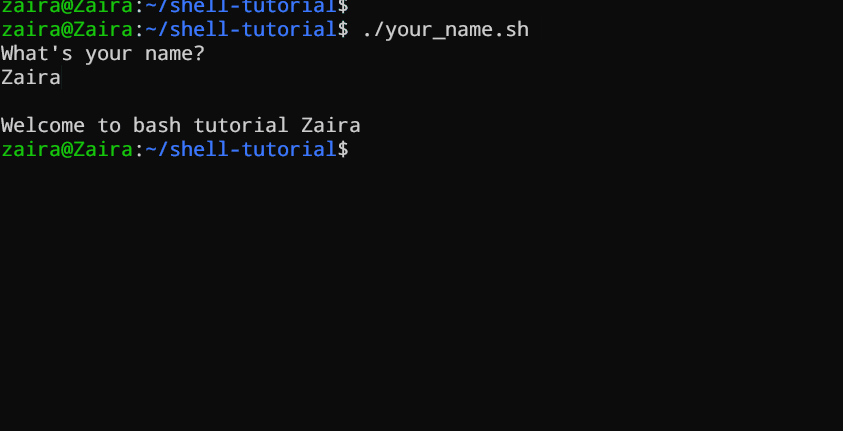
ユーザーの入力をreadコマンドを使用して読むことができます。
2. ファイルからの読み取り
while read line
do
echo $line
done < input.txt
このコードはinput.txtという名前のファイルから各行を読み取り、端末に出力します。後でこのセクションでwhileループを学びます。
3. コマンドライン引数
Bash スクリプトや関数で、$1は最初の引数を表し、$2は2番目の引数を表します。
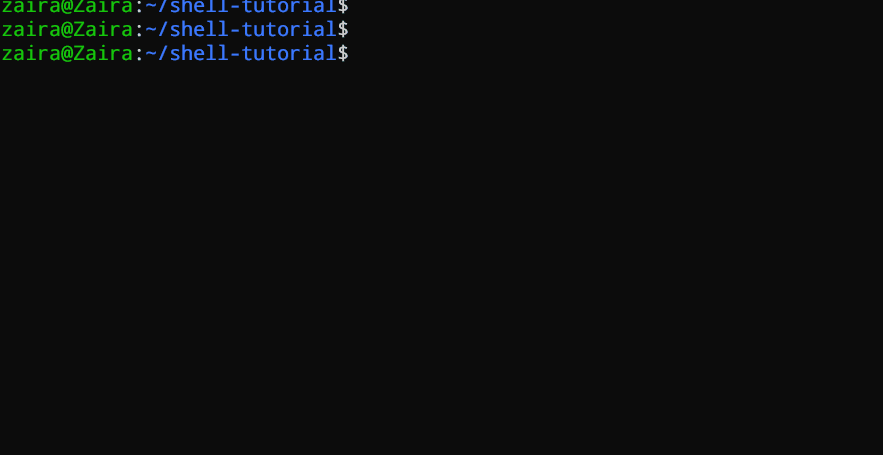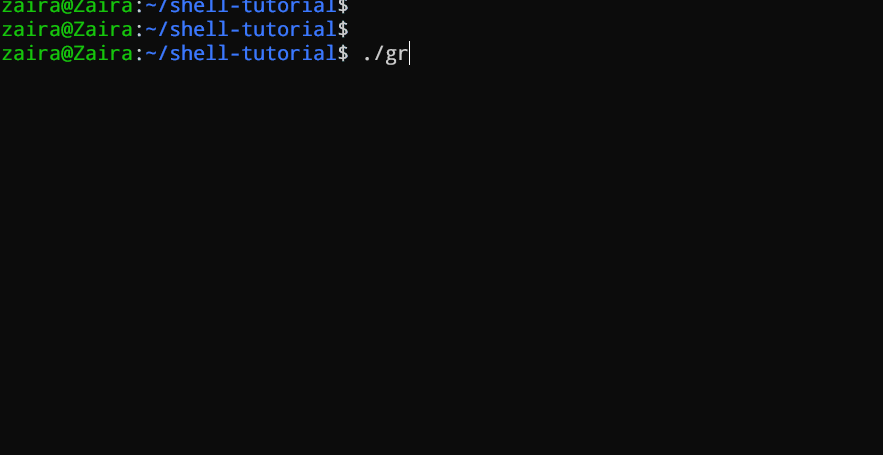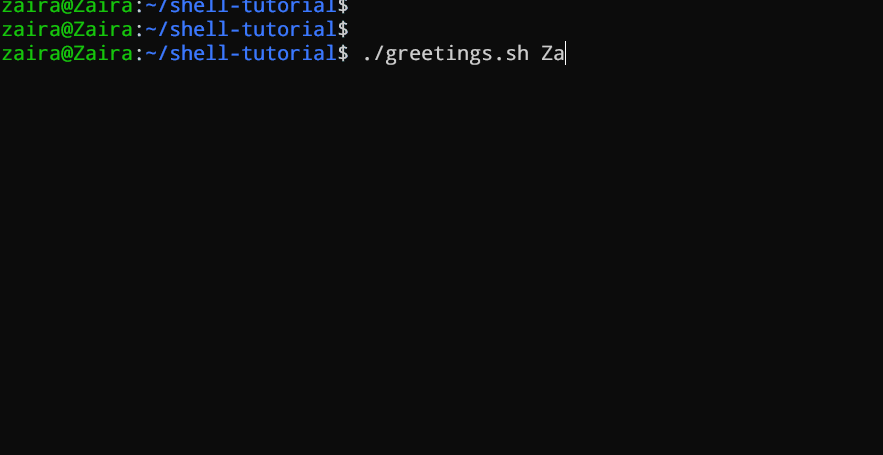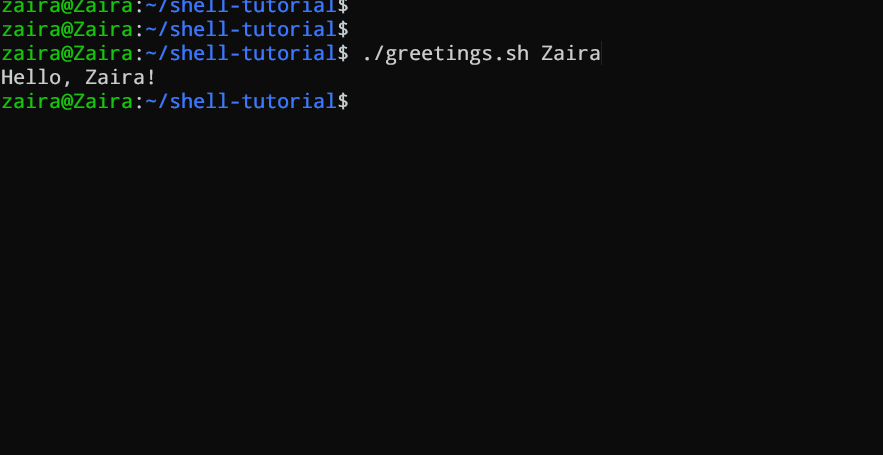
#!/bin/bash
echo "Hello, $1!"
このスクリプトは名前をコマンドライン引数として受け取り、個人用の挨拶を出力します。
スクリプトにZairaを引数として渡しました。
出力:
出力の表示
- ここでは、スクリプトから出力を受け取るいくつかの方法を議論します。
echo "Hello, World!"
端末への印刷:
これは”Hello, World!”というテキストを端末に印刷します。
echo "This is some text." > output.txt
2. ファイルへの書き込み:
これは”これは何らかのテキストです。”というテキストをoutput.txtという名前のファイルに書き込みます。>演算子は既に内容がある場合にファイルを上書きします。
echo "More text." >> output.txt
3. ファイルへの追記:
このアプリは、output.txtファイルの末尾に”More text.”というテキストを追加します。
ls > files.txt
4. 出力のリダイレクト:
これは現在のディレクトリ内のファイルを列挙し、出力をfiles.txtという名前のファイルに書き込みます。この方法で、任意のコマンドの出力をファイルにリダイレクトすることができます。
8.5節では、出力のリダイレクトの詳細について学びます。
条件分岐(if/else)
真と假に分岐する boolean 型の式を条件と呼びます。条件を評価する方法は、if、if-else、if-elif-else、及び嵌套条件などいくつかあります。
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
構文:
Bash 条件分岐の構文
if [ $a -gt 60 -a $b -lt 100 ]
論理演算子として AND -a および OR -o を使用して、より重要な比較を行うことができます。
このステートメントは、両方の条件がtrueかどうかをチェックします: aが60以上かつbが100以下かどうかです。
#!/bin/bash
Bashスクリプトの一例を見てみましょう。このスクリプトはif、if-else、if-elif-elseステートメントを使用して、用户が入力した数字が正しい、負しい、またはゼロかどうかを決定します。
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# 数が正しい、負しい、またはゼロかどうか決定するスクリプト
ユーザーに数字を入力するように要求し、その数字が0以上であるかをif文で確認するスクリプトがあります。数字が0以上であれば、スクリプトは数字が正しいと出力します。数字が0以上でない場合は、次のステートメントに移行し、ここではif-elif文を使用します。
ここで、スクリプトは数字が0以下であるかを確認します。数字が0以下であれば、スクリプトは数字が負であると出力します。
最終的に、数字が0以上でもない場合、スクリプトはelse文を使用して、数字がゼロであると出力します。
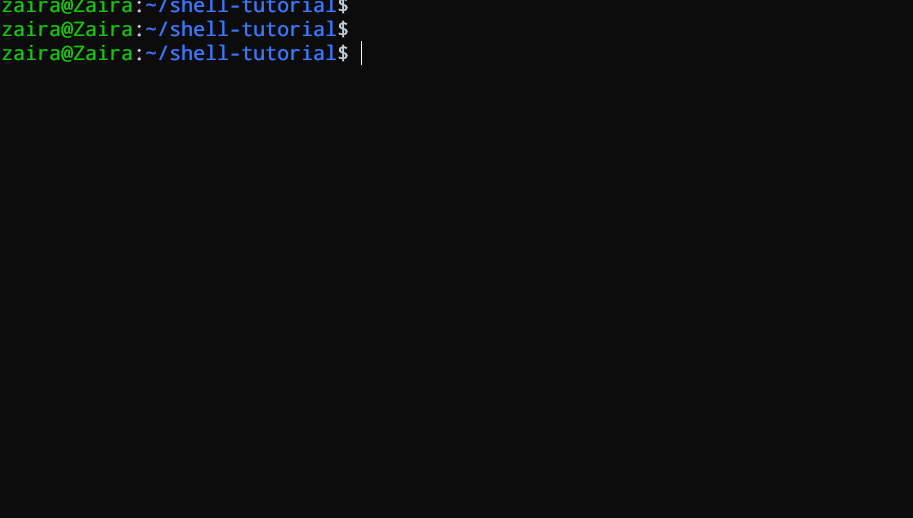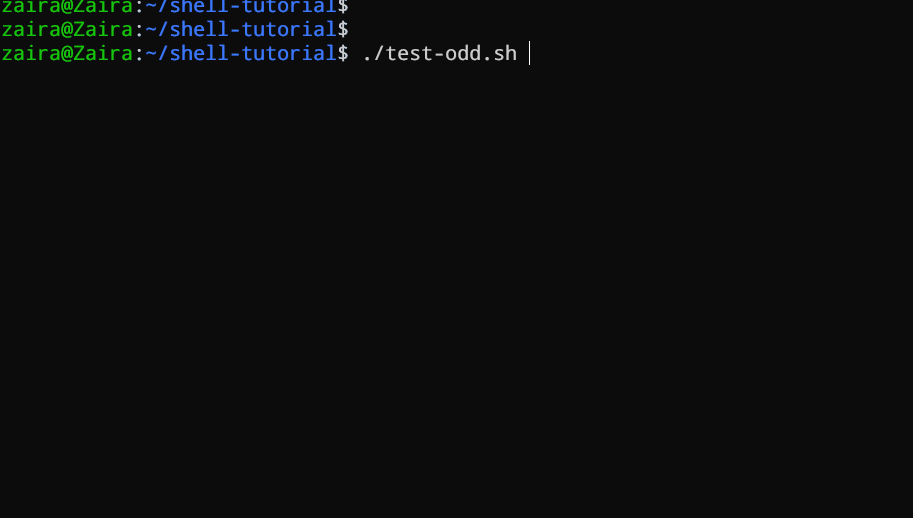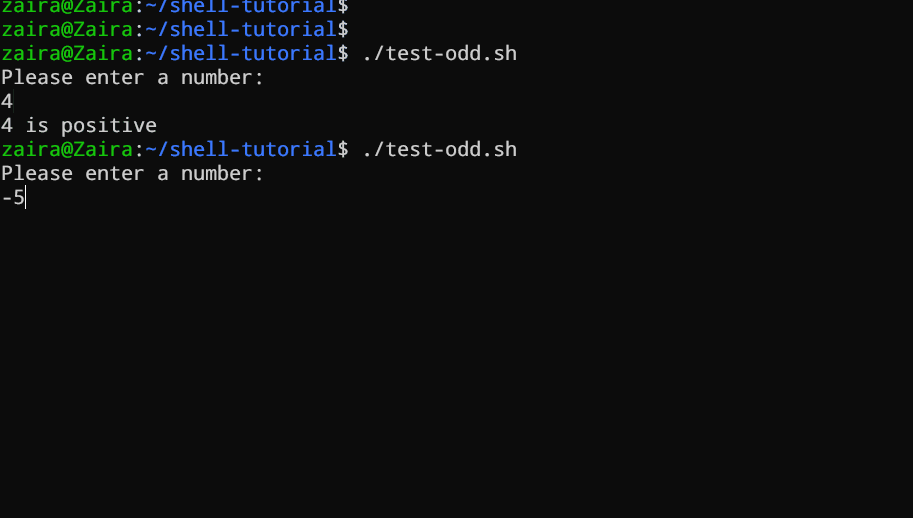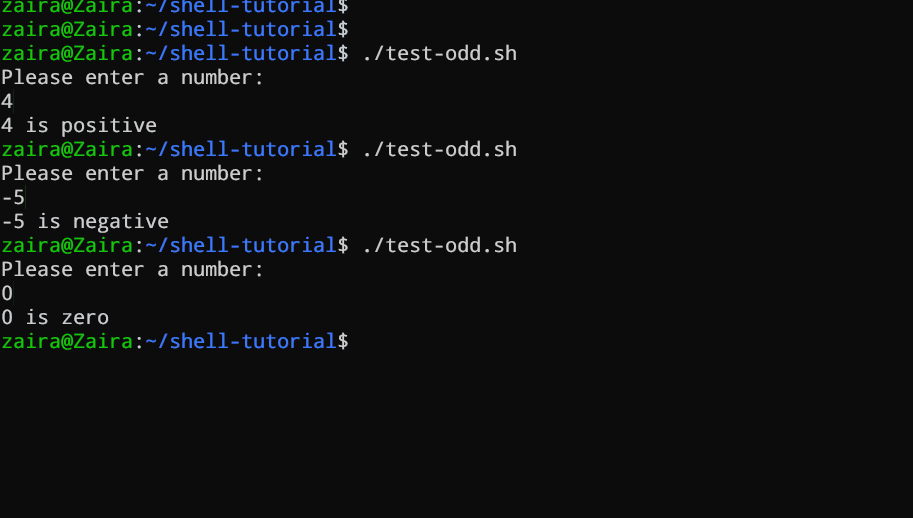
実際の動作を見てみよう 🚀
Bash内のループと分岐
Whileループ
Whileループは条件を確認し、条件がtrueであるまでループします。ループの実行を制御するカウンターステートメントを提供する必要があります。
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
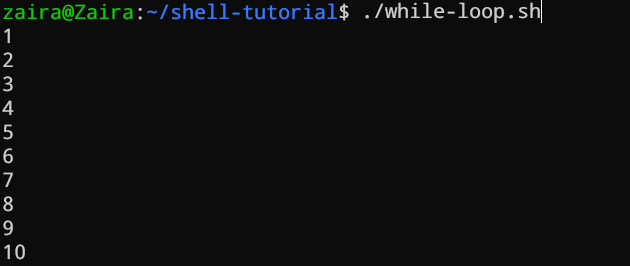
以下の例では、(( i += 1 ))はカウンターステートメントであり、iの値を Increment します。このループは正確に10回実行されます。
Forループ
forループはwhileループと同様に、特定の回数でステートメントを実行することができます。各ループは構文や使用方法が異なります。
#!/bin/bash
for i in {1..5}
do
echo $i
done

以下の例では、ループは5回iterate します。
Case文
case expression in
pattern1)
Bashでは、case文を使用して与えられた値をパターンのリストと比較し、最初にマッチするパターンに基づいてコードブロックを実行します。Bashのcase文の構文は次のとおりです:
;;
pattern2)
# expressionがpattern1にマッチする場合に実行するコード
;;
pattern3)
# expressionがpattern2にマッチする場合に実行するコード
;;
*)
# expressionがpattern3にマッチする場合に実行するコード
;;
esac
# 上記のパターンにexpressionがマッチしない場合に実行するコード
ここで、「expression」は比較したい値であり、「pattern1」、「pattern2」、「pattern3」といったものは比較したいパターンです。
セミコロン「;;」は各パターンごとに実行するコードブロックを区切ります。アスタリスク「*」はデフォルトのケースを表し、指定されたパターンがいずれもexpressionにマッチしない場合に実行されます。
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
以下に例を示します:
この例では、fruitの値がappleであるため、最初のパターンがマッチし、This is a red fruit.と表示されます。もしfruitの値がbananaであった場合、2番目のパターンがマッチし、This is a yellow fruit.と表示されます。
fruitの値が指定されたパターンと一致しない場合、デフォルトのケースが実行され、Unknown fruit.と表示されます。
パート7:Linuxでのソフトウェアパッケージの管理
Linuxにはいくつかの内置のプログラムが含まれています。しかし、あなたのニーズに基づいて新しいプログラムをインストールする必要があるかもしれません。既存のアプリケーションをアップグレードする必要もあるかもしれません。
7.1. パッケージとパッケージ管理
パッケージとは何でしょうか?
パッケージは、一緒に結合されたファイルのコレクションです。これらのファイルは、特定のプログラムの実行に必要です。これらのファイルには、プログラムの実行可能ファイル、ライブラリ、その他のリソースが含まれます。
プログラムの実行に必要なファイルだけでなく、パッケージにはインストールスクリプトも含まれています。これらのスクリプトは、ファイルを必要な場所にコピーします。プログラムは多くのファイルと依存性を持っていることがあります。パッケージを使用すると、すべてのファイルと依存性を一度に管理することができます。
ソースと二進法の違いは何でしょうか?
プログラマはプログラミング言語でソースコードを書きます。このソースコードは、コンピュータが理解できるマシンコードにコンパイルされます。コンパイルされたコードは二進コードと呼ばれます。
パッケージをダウンロードすると、ソースコードまたは二進コードを取得することができます。ソースコードは、人間が読むことができるコードで、二進コードにコンパイルされることができます。二進コードは、コンピュータが理解できるコードにコンパイルされたコードです。
正しくコンパイルされると、ソースパッケージはどのようなマシンのタイプにも使用できます。しかし、二進法は、特定のマシンまたはアーキテクチャに特化したコンパイルされたコードです。
uname -m
マシンのアーキテクチャをuname -mコマンドで確認することができます。
x86_64
# 出力
パッケージ依存性
プログラムは通常、ファイルを共有します。これらのファイルを各パッケージに含める代わりに、独自のパッケージを用いて全てのプログラムに提供することができます。
これらのファイルを必要とするプログラムをインストールするには、それらを含むパッケージもインストールする必要があります。これはパッケージ依存性と呼ばれます。依存性を指定することによって、重複を削減してパッケージを小さく、簡潔にすることができます。
プログラムをインストールする際、その依存性もインストールする必要があります。多くの必要な依存性は既にインストールされている可能性が高いですが、いくつかの追加の依存性が必要かもしれません。ただ、選択したパッケージとともに他の複数のパッケージがインストールされることに驚かないでください。これらは必要な依存性です。
パッケージ管理
Linuxには、ソフトウェアのインストール、アップグレード、設定、および削除を行うことができる完全なパッケージ管理システムが提供されています。
パッケージ管理を使用することで、組織化された数千人のソフトウェアパッケージのベースにアクセスすることができ、依存性の解決やソフトウェアの更新を確認することもできます。
パッケージの管理は、システム管理者が簡単に自動化できるコマンドラインのユーティリティを使用するか、グラフィカルインターフェースを通じて行います。
ソフトウェアチャンネル/リポジトリ
⚠️ パッケージ管理は、異なるディストリビューションごとに異なります。ここでは、Ubuntuを使用しています。
Linuxでのソフトウェアのインストールは、WindowsやMacと比較して少し異なります。
Linuxはリポジトリを使用してソフトウェアパッケージを格納します。リポジトリは、パッケージ管理器を通じてインストールできるソフトウェアパッケージのコレクションです。
パッケージマネージャは、レポから利用可能なすべてのパッケージの索引を格納します。時には、索引が再構築され、最新であることを確認し、最後に確認した後にチャンネルに追加またはアップグレードされたパッケージを知るために使います。
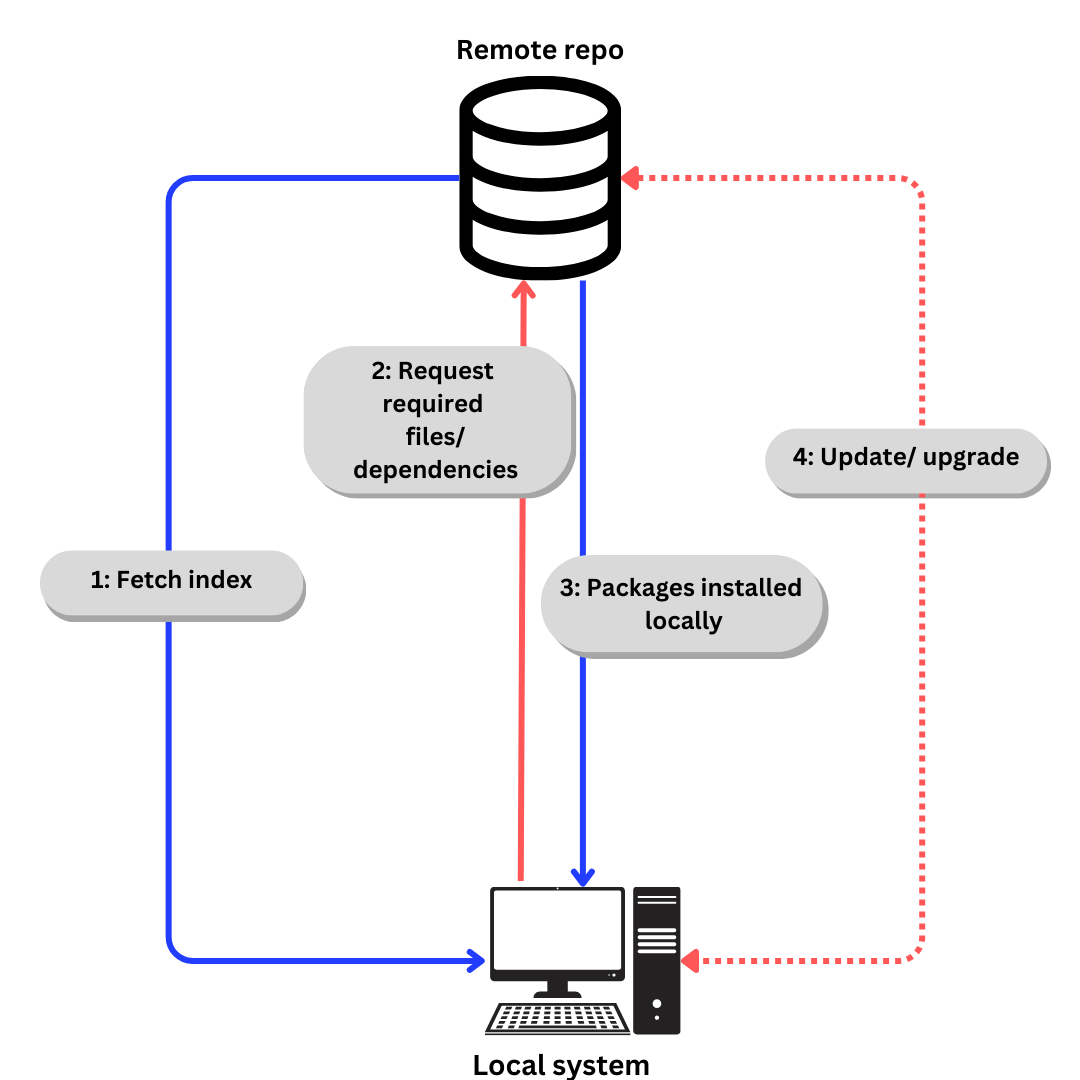
レポからソフトウェアをダウンロードする一般的なプロセスは、以下のようになります:
- Ubuntuに特化して話すと、
- 索引は
apt updateを使って取得されます。aptについては次のセクションで説明します。 - インデックスに基づいて必要なファイル/依存関係を
apt installを使って要求します - 必要なパッケージと依存関係をローカルにインストールします。
必要であれば、apt updateとapt upgradeを使って依存関係とパッケージを更新します
Debianベースのディストロにおいては、レポのリストを/etc/apt/sources.listに記述できます。
7.2. コマンドラインからのパッケージのインストール
aptコマンドは、Ubuntuの「Advanced Packaging Tool (APT)」で動作する強力なコマンドラインツールです。
aptとその付属コマンドは、新しいソフトウェアパッケージのインストール、既存のソフトウェアパッケージのアップグレード、パッケージリストインデックスの更新、そしてアップグレードするための整个的なUbuntuシステムのインストールを可能にする手段を提供します。
aptを使用してインストールされたのログを表示するには、/var/log/dpkg.logファイルを参照することができます。
以下はaptコマンドの使用法です。
パッケージのインストール
sudo apt install htop
たとして、htopパッケージのインストールには以下のコマンドを使用できます。
パッケージリストインデックスの更新
sudo apt update
パッケージリストインデックスは、リポジトリーにあるすべてのパッケージのリストです。以下のコマンドを使用して、ローカルのパッケージリストインデックスを更新することができます。
パッケージのアップグレード
システム上にインストールされたパッケージは、バグ修正、セキュリティパッチ、新しい機能などを含む更新を取得することができます。
sudo apt upgrade
以下のコマンドを使用して、パッケージをアップグレードすることができます。
パッケージの削除
sudo apt remove htop
以下のコマンドを使用して、htopなどのパッケージを削除することができます。
7.3. 高度なグラフィカルメソッドを使用してパッケージをインストールする – Synaptic
コマンドラインを使うのが適切でない場合は、パッケージをインストールするGUIアプリケーションを使用することができます。同様の結果をコマンドラインと同様に得ることができますが、グラフィカルインターフェースを使用します。
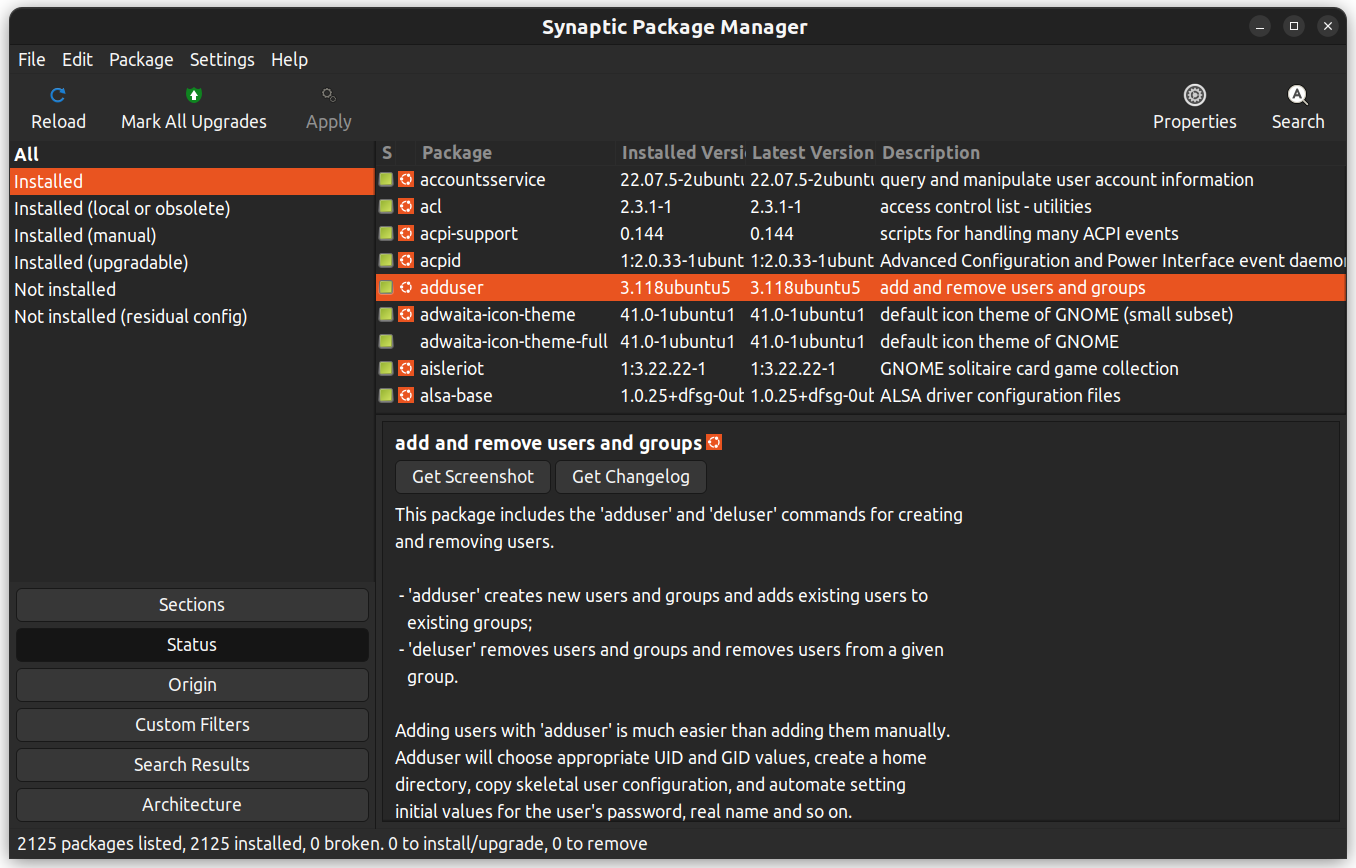
Synapticは、インストールされたパッケージの一覧、そのステータス、待機中の更新などを表示するGUIパッケージ管理アプリケーションです。カスタムフィルターを提供して、検索結果を絞り込むことができます。
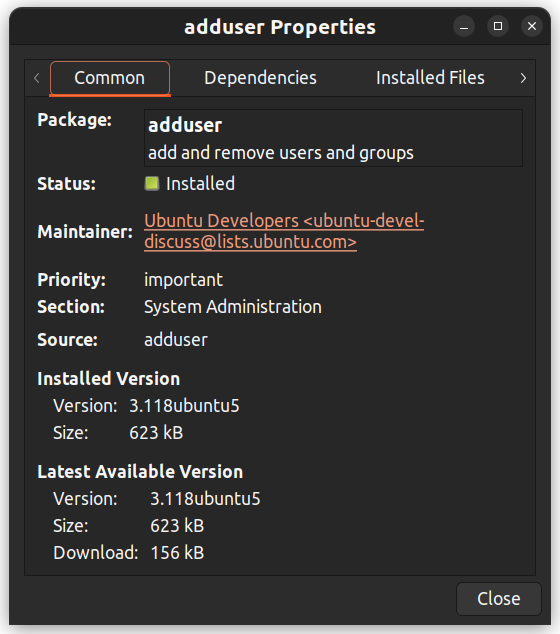
パッケージを右クリックすることで、依存関係、メンテナ、サイズ、インストールされたファイルなどの詳細情報を表示することもできます。
7.4. Webサイトからダウンロードしたパッケージのインストール
ソフトウェアリポジトリからではなく、Webサイトからダウンロードしたパッケージをインストールしたい場合があります。これらのパッケージは.debファイルと呼ばれます。
cd directory
sudo dpkg -i package_name.deb
パッケージのインストールにdpkgを使用する:dpkgはパッケージをインストールするためのコマンドラインツールです。dpkgでパッケージをインストールするには、ターミナルを開き、以下のように入力します。
注意: “directory”をパッケージが保存されているディレクトリに置き換え、”package_name”をパッケージのファイル名に置き換えます。
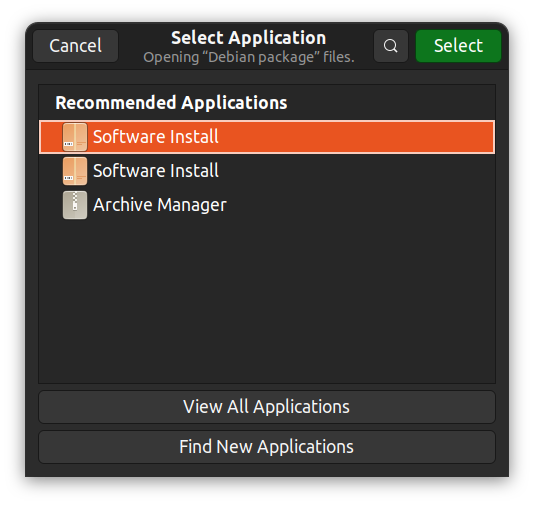
あるいは、右クリックして「他のアプリケーションで開く」を選択し、お好みのGUIアプリを選ぶこともできます。
💡 ヒント: Ubuntuでは、dpkg --listでインストールされたパッケージの一覧を見ることができます。
第8部: 高度なLinuxのトピック
8.1. ユーザー管理
システムには、異なるアクセスレベルの複数のユーザーが存在することができます。Linuxでは、ルートユーザーが最も高いアクセスレベルを持ち、システム上でどんな操作も行うことができます。一般的なユーザーは限定されたアクセスがあり、許可された操作のみを行うことができます。
ユーザーとは何ですか?
ユーザーアカウントは、異なる人やプログラム間の操作を区別するためのものです。
人間は名前でユーザーを特定しますが、名前は扱い易いからです。しかし、システムはユーザーID (UID)と呼ばれるユニークな番号でユーザーを特定します。
ユーザーは提供されたユーザー名でログインする際、パスワードを使用して自分自身を認証する必要があります。
ユーザーアカウントはシステムセキュリティの基盤を形成します。ファイルの所有権もユーザーアカウントと関連付けられており、ファイルへのアクセス制御を強制します。すべてのプロセスは、管理者による制御の一層を提供する関連付けられたユーザーアカウントを持っています。
- ユーザーアカウントには主に3種類があります:
- スーパーユーザー:スーパーユーザーはシステムへの完全なアクセス権を持っています。スーパーユーザーの名前は
rootで、UIDは0です。 - システムユーザー:システムユーザーはシステムサービスを実行するためのユーザーアカウントを持っています。これらのアカウントはシステムサービスを実行するために使用され、人間とのやりとりを意図していません。
一般ユーザー:一般ユーザーはシステムにアクセスできる人間のユーザーです。
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
idコマンドは現在のユーザーのユーザーIDとグループIDを表示します。
id username
他のユーザーの基本情報を表示するには、idコマンドにユーザー名を引数として渡します。
ps -u
プロセスに関連するユーザー情報を表示するには、psコマンドに-uフラグを使用します。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# 出力
デフォルトでは、システムは/etc/passwdファイルを使用してユーザー情報を格納します。
root:x:0:0:root:/root:/bin/bash
/etc/passwdファイルの一行を以下に示します:
/etc/passwdファイルには、各ユーザーについて以下の情報が含まれています:- ユーザー名:
root– ユーザーアカウントのユーザー名。 - パスワード:
x– ユーザーアカウントの暗号化されたパスワード。セキュリティ上の理由で、/etc/shadowファイルに格納されています。 - ユーザーID (UID):
0– ユーザーアカウントの一意の数値識別子。 - グループID (GID):
0– ユーザーアカウントの主要なグループ識別子。 - ユーザー情報:
root– ユーザーアカウントの本名。 - ホームディレクトリ:
/root– ユーザーアカウントのホームディレクトリです。
シェル: /bin/bash – ユーザーアカウントのデフォルトシェルです。システムユーザーの場合、対話型ログインが許可されていない場合は/sbin/nologinを使用することがあります。
グループとは何ですか?
グループは、アクセスとリソースを共有するユーザーアカウントの集まりです。グループにはグループ名があり、これによって識別されます。システムはグループを一意の番号であるグループID(GID)で識別します。
デフォルトでは、グループに関する情報は/etc/groupファイルに保存されます。
adm:x:4:syslog,john
/etc/groupファイルのエントリの例を以下に示します。
- 与えられたエントリのフィールドの詳細は以下のとおりです。
- グループ名:
adm– グループの名前です。 - パスワード:
x– グループのパスワードはセキュリティ上の理由から/etc/gshadowファイルに保存されます。パスワードはオプションで、設定されていない場合は空になります。 - グループID (GID):
4– グループの一意の数値識別子。
グループメンバー: syslog,john – グループのメンバーのユーザー名のリスト。この場合、グループ adm には2人のメンバーがいます:syslog と john。
この特定のエントリにおいて、グループ名は adm であり、グループIDは 4 であり、グループには2人のメンバーがいます:syslog と john。パスワードフィールドは通常、x に設定され、これはグループパスワードが /etc/gshadow ファイルに格納されていることを示します。
- グループはさらに ‘主要’ と ‘補助’ の2種類に分けられます。
- 主要グループ: 各ユーザーはデフォルトで1つの主要グループが割り当てられます。このグループは通常、ユーザー名と同じ名前を持ち、ユーザーアカウント作成時に作成されます。ユーザーが作成したファイルやディレクトリは通常、この主要グループに所有されます。
补足的なグループ: これらはユーザーが主なグループに加えて所属できる追加のグループです。ユーザーは複数の補足的なグループに所属することができます。これらのグループを通じて、同じグループ間で共有されるリソースに対する権限を持つことができます。これにより、システムのファイル権限を変更せずに共有リソースにアクセスを提供し、安全性を保ちます。ユーザーは主なグループに所属する必要がありますが、補足的なグループに所属することはオプションです。
アクセスコントロール: ファイル権限の探求と理解
ファイルの所有者は、ls -lコマンドを使用して表示できます。ls -lの出力の最初の列は、ファイルの権限を示します。他の列は、ファイルの所有者とファイルが属しているグループを示します。

次に、mode列に注意してください:
- モードには2つのことが定義されています:
- ファイルタイプ: ファイルタイプは、ファイルに含まれるデータの性質を定義します。単純なデータを含む通常のファイルの場合は、
-となります。他の特殊なファイルタイプには、異なるシンボルが使用されます。ディレクトリという特殊なファイルには、dが使用されます。OSによって特殊ファイルは別に扱われます。
アクセス権限クラス: 次の文字セットは、それぞれユーザー、グループ、その他のアクセス権限を定義します。
– ユーザー: ファイルの所有者であり、ファイルの所有者はこのクラスに属します。
– グループ: ファイルのグループのメンバーはこのクラスに属します
– その他: ユーザーやグループクラスに属していないすべてのユーザーはこのクラスに属します。
💡ヒント: ディレクトリの所有権はls -ldコマンドで表示することができます。
シンボリック権限またはrwx権限の読み方
rwx表現は、権限のシンボリック表現として知られています。権限のセットで、rはread(読み取り)を表しており、トライアドの最初の文字で示されます。wはwrite(書き込み)を表しており、トライアドの2番目の文字で示されます。
xはexecution(実行)を表しており、トライアドの3番目の文字で示されます。
Read:
通常のファイルにおいて、読み取り権限はファイルを開くことと、読み取ることだけを許可します。ユーザーはファイルを修正することはできません。
同様に、ディレクトリにおいて、読み取り権限はディレクトリの内容を一覧表示することだけを許可しますが、ディレクトリの内容を修正することはできません。
Write:
ファイルに書き込み権限がある場合、ユーザーはファイルを修正(編集、削除)し、保存することができます。
フォルダーにおいては、書き込み権限はユーザーに対してその内容を修正(その中のファイルを作成、削除、名前変更)し、書き込み権限を持っているファイルの内容を修正することができます。
Linuxの権限の例
- 権限を読み取る方法を理解したので、いくつかの例を見てみましょう。
-
-rw-rw-r--: 所有者とグループによる変更が可能で、他人には不可能なファイル。
drwxrwx---: 所有者とグループによる変更が可能なディレクトリ。
実行:
ファイルには実行許可があると、ユーザーは実行可能なスクリプトを実行できます。ディレクトリには、ユーザーはアクセスでき、ディレクトリ内のファイルに関する詳細情報にアクセスできます。
Linuxでchmodとchownを使用してファイルのパーミッションと所有者を変更する方法
所有者とパーミッションの基本について既に理解したので、chmodコマンドを使用してパーミッションを変更する方法を見てみましょう。
chmod permissions filename
chmodの構文:
- Where,
permissionsは、読み取り、書き込み、実行、またはそれらの組み合わせになります。
filenameは、パーミッションを変更する必要があるファイルの名前です。このパラメータは、一括でパーミッションを変更するファイルのリストにもなります。
- 2つのモードを使用してパーミッションを変更することができます:
- シンボリックモード: この方法は、所有者、グループ、その他のアクセス権を
u、g、oという記号で表します。読み取り、書き込み、実行の権限はそれぞれr, w, xで表されます。権限を変更するには+、-、=を使用できます。
絶対モード: この方法は権限を0から7までの3桁の8進数で表します。
では、詳しく見ていきましょう。
シンボリックモードでの権限変更方法
| 以下の表はユーザー表現の要約です: | ユーザー表現 |
| u | 説明 |
| g | 所有者/ユーザー |
| o | グループ |
その他
| 算術演算子を使用して権限を追加、削除、代入できます。以下の表はその要約です: | 演算子 |
| 説明 | + |
| ファイルやディレクトリに権限を追加します | – |
| 権限を削除します | \= |
权限を設定し、既に設定されている場合は上書きします。
例:
スクリプトがあり、ファイルの所有者zairaに実行可能にしたいとする。

現在のファイルの権限は以下のようになっています:
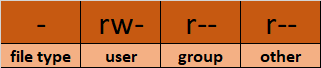
権限を以下のように分割しましょう:
chmod u+x mymotd.sh
symbolic モードを使用して所有者 (u) に実行権限 (x) を追加するために、以下のコマンドを使用できます。
出力:
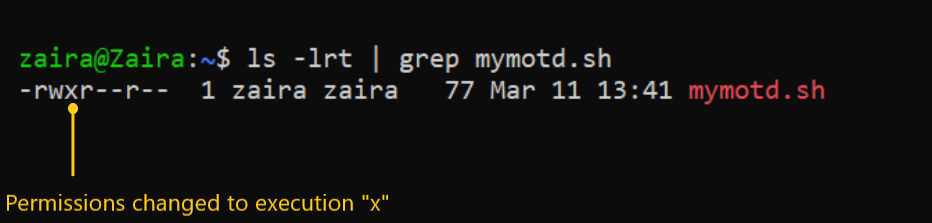
今や、所有者zairaに実行権限が追加されていることがわかります。
- Symbolic 方法を使用して権限を変更する追加の例:
- グループや他の人々に対する
readとwrite権限の削除:chmod go-rw。 - 他の人々に対する
read権限の削除:chmod o-r。
グループに対するwrite権限の割り当てと既存の権限の上書き: chmod g=w。
絶対モードを使用して権限を変更する方法
絶対モードは権限を表現するための数値と、それらを変更するための数学的な演算子を使用します。
| 以下の表は、どのように权限を割り当てることができるかを示しています。 | 権限 |
| 割り当てる権限 | read |
| add 4 | write |
| add 2 | execute |
add 1
| 権限は引き算を使用して取り消すことができます。以下の表は、どのように权限を取り消すことができるかを示しています。 | 権限 |
| 取り消す権限 | read |
| subtract 4 | write |
| subtract 2 | execute |
subtract 1
- 例:
userにread (add 4)を、グループにはread (add 4)とexecute (add 1)、他の人にはただexecute (add 1)だけを設定する。
chmod 451 file-name
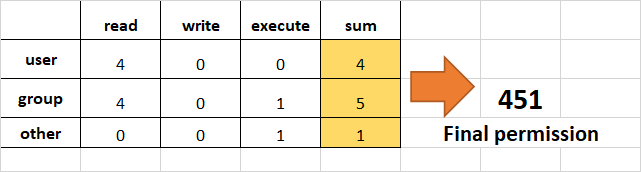
これは計算を行う方法です。
- 注意してください、これは
r--r-x--xと同じです。
otherとgroupからexecution権限を取り消す。
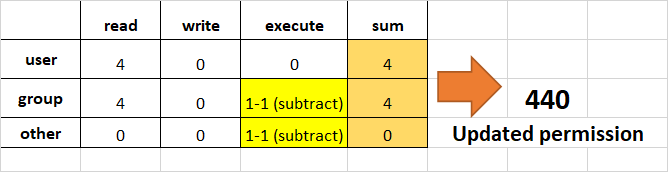
otherとgroupからexecuteを取り消すために、最後の2Byteの実行部分から1を引き算します。
userにread、write、executeを割り当て、groupにreadとexecuteを割り当て、他のユーザーにはreadのみを割り当てます。

これはrwxr-xr--と同じです。
chownコマンドを使用して所有権を変更する方法
次に、ファイルの所有権を変更する方法について学びます。ファイルやフォルダーの所有権を変更するには、chownコマンドを使用できます。所有権の変更には場合によってはsudo権限が必要です。
chown user filename
chownの構文:
chownを使用してユーザー所有権を変更する方法
所有権をユーザーzairaからユーザーnewsに移動します。

chown news mymotd.sh
所有権を変更するコマンド:sudo chown news mymotd.sh。

出力:
ユーザーとグループの所有権を同時に変更する方法
chown user:group filename
chownを使用してユーザーとグループを同時に変更することもできます。
ディレクトリ所有権を変更する方法
chown -R admin /opt/script
ディレクトリ内のコンテンツの所有権を再帰的に変更できます。以下の例では、/opt/scriptフォルダーの所有権をユーザーadminに変更します。
グループ所有権を変更する方法
chown :admins /opt/script
グループ所有者のみを変更する必要がある場合は、グループ名の前にコロン:を付けてchownを使用できます。
ユーザー間を切り替える方法
[user01@host ~]$ su user02
Password:
[user02@host ~]$
suコマンドを使用して、ユーザー間を切り替えることができます。
スーパーユーザーアクセスを取得する方法
スーパーユーザーまたはルートユーザーは、Linuxシステム上で最も高い権限を持つユーザーです。ルートユーザーは、システム上でどんな操作も行うことができます。ルートユーザーは全てのファイルとディレクトリにアクセスでき、ソフトウェアをインストールまたは削除し、またはシステム設定を変更または上書きすることができます。
大きな権力には大きな責任が伴います。ルートユーザーが侵害されると、それぞれがシステムの完全なコントロールを得ることができます。必要でない場合は、ルートユーザーアカウントを使用することを推奨します。
[user01@host ~]$ su
Password:
[root@host ~]ユーザー名を省略すると、suコマンドはデフォルトでルートユーザーアカウントに切り替えます。
#
suコマンドの別のバリエーションはsu -です。suコマンドはルートユーザーアカウントに切り替えますが、環境変数を変更しません。su -コマンドはルートユーザーアカウントに切り替えし、対象のユーザーの環境変数に変更します。
sudoコマンドでコマンドを実行する
rootユーザーとしてコマンドを実行したいけれど、rootユーザーアカウントに切り替えたくない場合、sudoコマンドを使用することができます。sudoコマンドは、強化された権限でコマンドを実行することができます。
sudoコマンドを使用してコマンドを実行することは、rootユーザーとしてコマンドを実行するよりも安全です。なぜなら、sudoでコマンドを実行する権限を与えることができるのは特定のユーザー集合だけであり、これは/etc/sudoersファイルで定義されています。
すべてのsudoを使って実行されたコマンドはログに記録され、誰がどのコマンドをいつ実行したかの監査トレイルを提供します。
cat /var/log/auth.log | grep sudo
Ubuntuでは、監査ログはここで見つけることができます:
user01 is not in the sudoers file. This incident will be reported.
sudoへのアクセスがないユーザーには、以下のようなメッセージがログに記録されます:
ローカルユーザーアカウントの管理
コマンドラインからのユーザー作成
sudo useradd username
新しいユーザーを追加するためのコマンドは以下の通りです:
このコマンドは、ユーザーのホームディレクトリを設定し、ユーザー名によって指定される個人グループを作成します。現在、このアカウントには有効なパスワードがないため、パスワードを作成するまで、ユーザーはログインできません。
既存ユーザーの変更
既存のユーザーを変更するためにusermodコマンドが使用されます。以下は、usermodコマンドと共によく使われるオプションです:
usermodコマンドのLinuxでの例は以下の通りです:- ユーザーのログイン名を変更する:
- ユーザーのホームディレクトリを変更:
- ユーザーを追加グループに追加:
- ユーザーのシェルを変更:
- ユーザーのアカウントをロック:
- ユーザーアカウントの解除ロック:
- ユーザーアカウントの有効期限を設定:
- ユーザーのUIDを変更:
- ユーザーの主なグループを変更:
補助グループからユーザーを削除する:
ユーザーの削除
userdelコマンドは、ユーザーアカウントと関連するファイルをシステムから削除するために使われます。sudo userdel username:/etc/passwdからユーザーの詳細を削除しますが、ユーザーのホームディレクトリを保持します。
sudo userdel -r usernameコマンドは、/etc/passwdからユーザーの詳細を削除し、またユーザーのホームディレクトリも削除します。
ユーザーパスワードの変更
passwdコマンドは、ユーザーのパスワードを変更するために使われます。
sudo passwd username: usernameの初期パスワードを設定するか、既存のパスワードを変更します。また、現在ログインしているユーザーのパスワードを変更するのにも使われます。
8.2 SSH経由でリモートサーバーに接続する
plaintext
リモートサーバーにアクセスすることは、システム管理者にとって必須の任務です。SSHを使用して、さまざまなサーバーに接続したり、ローカルマシンを通じてデータベースにアクセスしたり、コマンドを実行することができます。
SSHプロトコルとは何ですか?
SSHはSecure Shellの略で、2つのシステム間の安全な通信を可能にする暗号化ネットワークプロトコルです。
SSHのデフォルトのポートは22です。
- SSHを通じて通信を行う2つの参加者は以下の通りです:
- サーバー:アクセスしたいマシンです。
クライアント:サーバーにアクセスするシステムです。
- サーバーへの接続は以下の手続きを踏んで行います:
- 接続の開始:クライアントはサーバーに接続要求を送信します。
- 鍵の交換:サーバーは自分の公開鍵をクライアントに送信し、暗号化方法を合意します。
- セッション鍵の生成:クライアントとサーバーは、ディフィー・ヘルマン鍵交換を使用して共有のセッション鍵を作成します。
- クライアント認証:クライアントはパスワード、秘密鍵、または他の方法でサーバにログインします。
安全な通信:認証後、クライアントとサーバは暗号化された安全な通信を行います。
SSHを使用してリモートサーバに接続する方法は何ですか?
sshコマンドはLinuxに組み込まれたユーティリティであり、デフォルトのものです。これにより、サーバへのアクセスが非常に簡単かつ安全になります。
ここでは、クライアントがサーバに接続する方法について説明します。
- サーバに接続する前に、以下の情報を持っている必要があります:
- サーバのIPアドレスまたはドメイン名。
- サーバのユーザー名とパスワード。
サーバ内でアクセス可能なポート番号。
ssh username@server_ip
sshコマンドの基本構文は以下の通りです:
ssh [email protected]
たとえば、ユーザー名がjohnで、サーバのIPが192.168.1.10の場合、コマンドは以下のようになります:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ その後、秘密のパスワードを入力するよう促されます。画面は以下のように表示されます:
# コマンドを入力してください
今、あなたはサーバー 192.168.1.10 に対する関連のあるコマンドを実行することができます。
ssh -p port_number username@server_ip
⚠️ SSHのデフォルトのポートは 22 ですが、ここは攻撃者が最初にアタックを試みるかもしれません。あなたのサーバーは別のポートを露出し、アクセスを共有することができます。異なるポートに接続するためには、-p フラグを使用します。
8.3. 高度なログ解析と分析
設定された場合、システムはいくつかの有用な理由からログファイルを生成します。これらはシステムイベントの追跡、システムパフォーマンスの監視、そして問題の解決に使用できます。特に、アプリケーションエラー、ネットワークイベント、およびユーザー活動を追跡するために、システム管理者にとって非常に有用です。
以下はログファイルの例です。
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# サンプルログファイル
- ログファイルは通常以下のような列を含みます。
- Timestamp: イベントが発生した日時。
- Log Level: イベントの严重性 (INFO, DEBUG, WARN, ERROR)。
- Component: イベントを生成したシステムのコンポーネント (Startup, Config, Database, User, Security, Network, Email, API, Session, Shutdown)。
- メッセージ:発生したイベントの説明。
追加情報:イベントに関連する追加情報。
リアルタイムシステムでは、ログファイルは通常秒ごとに生成され、何千行にもなることがあります。設定によっては非常に詳細になることがあります。ログファイルの各列は問題を追跡するための情報です。これはログファイルを手動で読んで理解するのが困難になる原因です。
これこそログ解析が必要な場所です。ログ解析とは、ログファイルから有用な情報を抽出するプロセスです。これにはログファイルをより小さくて管理しやすいピースに分割し、関連する情報を抽出することが含まれます。
抽出された情報は、アラート、レポート、ダッシュボードの作成にも有益です。
このセクションでは、Linuxでログファイルを解析するいくつかの技術を探ります。
grepを使用したテキスト抽出
Grepは内蔵のbashユーティリティです。”global regular expression print”の略で、ファイル内の文字列を照合するために使用されます。
grepの一般的な使用方法:- このコマンドは、ファイル名が
filenameの中で「search_string」を検索します。 - このコマンドは、指定したディレクトリとそのサブディレクトリ内のすべてのファイルで「search_string」を検索します。
- このコマンドは、ファイル名が
filenameの中で「search_string」を大文字小文字を無視して検索します。 - このコマンドは、名前が
filenameのファイル内の一致する行に行番号を表示します。 - このコマンドは、名前が
filenameのファイル内の”search_string”を含む行の数をカウントします。 - このコマンドは、
filenameという名前のファイル内に”search_string”を含んでいないすべての行を表示します。 - このコマンドは、
filenameという名前のファイル内に単語全体の”word”を検索します。
このコマンドは、filenameという名前のファイル内でより複雑なパターンマッチングに拡張正規表現を使用できるようにします。
💡Tip: フォルダ内に複数のファイルがある場合、以下のコマンドを使用して望ましい文字列を含むファイルの一覧を見つけることができます。
grep -l "String to Match" /path/to/directory
# 望ましい文字列を含むファイルの一覧を見つける
sedを使用したテキストの抽出
sedは「ストリームエディタ」を意味します。これはデータをストリーム単位で処理し、一度に1行ずつデータを読み込みます。 sedを使用すると、パターンを検索し、そのパターンに一致する行に対してアクションを実行することができます。
sedの基本構文:
sed [options] 'command' file_name
sedの基本構文は次のとおりです:
ここで、commandはテキストデータに対して置換、削除、挿入などの操作を実行するために使用されます。ファイル名は処理したいファイルの名前です。
sed使用法:
1. 置換:
sed 's/old-text/new-text/' filename
sフラグはテキストを置換するために使用されます。old-textがnew-textに置き換えられます:
sed 's/error/warning/' system.log
例えば、ログファイルsystem.log内のすべての「error」を「warning」に変更するには:
2. 特定のパターンを含む行の表示:
sed -n '/pattern/p' filename
sedを使用して特定のパターンに一致する行をフィルタリングして表示するために使用する:
sed -n '/ERROR/p' system.log
例えば、「ERROR」を含むすべての行を検索するには:
3. 特定のパターンを含む行の削除:
sed '/pattern/d' filename
出力から特定のパターンに一致する行を削除することができます:
sed '/DEBUG/d' system.log
例えば、「DEBUG」を含むすべての行を削除するには:
4. ログ行から特定のフィールドを抽出する:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
正規表現を使用して行の一部を抽出することができます。各ログ行は「YYYY-MM-DD」の形式で始まる日付で始まると仮定します。各行から日付のみを抽出することができます。
awkによるテキストの解析
awkは各行をフィールドに簡単に分割する機能を持っています。ログファイルのような構造化されたテキストの処理に適しています。
awkの基本構文
awk 'pattern { action }' file_name
awkの基本構文は次のとおりです:
ここで、patternはactionが実行されるために満たされる必要がある条件です。パターンが省略された場合、アクションはすべての行で実行されます。
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- 次の例では、次のログファイルを例として使用します:
awkを使用した列へのアクセス
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
awkのフィールド(デフォルトではスペースで区切られています)は、$1、$2、$3などを使用してアクセスできます。
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# 出力
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # 出力
awk '/ERROR/ { print $0 }' logfile.log
特定のパターン(例:ERROR)を含む行を出力する
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# 出力
- これは「ERROR」を含むすべての行を出力します。
awk '{ print $1, $2 }' logfile.log
最初のフィールド(日付と時刻)を抽出する
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# 出力
- これにより、各行から最初の2つのフィールド、つまり日付と時刻が抽出されます。
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
各ログレベルの発生回数を集計する
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# 出力
- 出力は各ログレベルの出現回数の要約になります。
awk '{ $3="INFO"; print }' sample.log
特定のフィールドをフィルタリングします(たとえば、3番目のフィールドがINFOの場合)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# 出力
このコマンドは、3番目のフィールドが「INFO」のすべての行を抽出します。
💡 ヒント: awk のデフォルトの区切り文字はスペースです。ログファイルが異なる区切り文字を使用している場合、-F オプションを使用して指定することができます。たとえば、ログファイルがコロンを区切り文字として使用している場合、awk -F: '{ print $1 }' logfile.log を使用して最初のフィールドを抽出することができます。
cut を使用してログファイルを解析する
cut コマンドは、入力の各行からテキストのセクションを抽出するために使用されるシンプルかつ強力なコマンドです。ログファイルは構造化されており、各フィールドはスペース、タブ、またはカスタムの区切り文字などによって区切られているため、cut は特定のフィールドを抽出するのに非常に適しています。
cut [options] [file]
cut コマンドの基本的な構文は次のとおりです:
- cut コマンドの一般的に使用されるオプション:
-d: フィールドの区切り文字を指定します。-f: 表示するフィールドを選択します。
-c : 文字位置を指定します。
cut -d ' ' -f 1 logfile.log
たとえば、以下のコマンドはログファイルの各行から最初のフィールド(スペース区切り)を抽出します。
ログ解析にcutを使用する例
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
以下のように構成されたログファイルがあると仮定します。ここでフィールドはスペースで区切られます。
cutは以下のように使用できます。
cut -d ' ' -f 2 system.log
各ログエントリから時間を抽出:
08:23:01
08:24:15
08:25:02
...
# 出力
- このコマンドはスペースをデリミタとして、各ログエントリの時間部分である2番目のフィールドを選択します。
cut -d ' ' -f 4 system.log
ログからIPアドレスを抽出:
192.168.1.10
192.168.1.10
10.0.0.5
# 出力
- このコマンドは各ログエントリの4番目のフィールド、つまりIPアドレスを抽出します。
cut -d ' ' -f 3 system.log
ログレベル(INFO, WARNING, ERROR)を抽出:
INFO
WARNING
ERROR
# 出力
- これはログレベルを含む3番目のフィールドを抽出します。
他のコマンドとcutを組み合わせる:
grep "ERROR" system.log | cut -d ' ' -f 1,2
他のコマンドの出力をcutコマンドにパイプできます。ログを切る前にフィルタリングしたいときは、たとえば"ERROR"を含む行をgrepで抽出し、それらの行から特定の情報をcutで取得します。
2024-04-25 08:25:02
# 出力
- このコマンドは最初に「ERROR」を含む行をフィルタリングし、次にこれらの行から日付と時刻を抽出します。
複数のフィールドを抽出:
cut -d ' ' -f 1,2,3 system.log`
範囲またはカンマ区切りのフィールドのリストを指定することで、一度に複数のフィールドを抽出できます:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# 出力
上記のコマンドは、各ログエントリから日付、時刻、およびログレベルの最初の3つのフィールドを抽出します。
sortおよびuniqを使用したログファイルの解析
ソートと重複の削除は、ログファイルを扱う際に一般的な操作です。sortおよびuniqコマンドは、それぞれ入力をソートし、重複を削除するための強力なコマンドです。
sortの基本的な構文
sort [options] [file]
sortコマンドは、テキスト行をアルファベット順または数値順に整理します。
- sortコマンドのいくつかの主要なオプション:
-n: 内容が数値であると仮定してファイルをソートします。-r: ソートの順序を逆にします。-k: ソートするキーまたは列番号を指定します。
-u: ソートして重複する行を削除します。
uniqコマンドは、ファイル内の重複行をフィルタリングしたり、計数して報告するために使用されます。
uniq [options] [input_file] [output_file]
uniqの構文は以下の通りです。
uniqコマンドの主要なオプションには以下の通りです。-c: 行ごとに出現回数を前方に付けます。-d: 重複行だけを表示します。
-u: 独特な行だけを表示します。
sortとuniqを一緒に使用してログ解析の例
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- 以下の例のログエントリを使用してこれらのデモンストレーションを行います。
sort system.log
ログエントリを日付でソートする:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 出力
- これはログエントリをアルファベット順にソートしますが、日付が最初のフィールドである場合は効果的に日付でソートします。
sort system.log | uniq
ソートして重複を削除する:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# 出力
- このコマンドはログファイルをソートし、
uniqにパイプして重複行を削除します。
sort system.log | uniq -c
各行の出現回数を計数する:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# 出力
- ログエントリをソートしてから、各ユニークな行を計数します。出力によると、行
'2024-04-25 INFO User logged in successfully.'がファイルに2回出現したことがわかります。
sort system.log | uniq -u
固有のログエントリを特定する:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# 出力
- このコマンドは固有の行を表示します。
sort -k2 system.log
ログレベルで並べ替える:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# 出力
ログレベルを第二フィールドとして、エントリを並べ替えます。
8.4. コマンドラインを通じてLinuxのプロセスを管理する
- プロセスは、プログラムの実行中のインスタンスです。プロセスは以下のような内容を持ちます:
- 割り当てられたメモリのアドレス空間。
- プロセスの状態。
所有者、セキュリティ属性、リソース使用量などのプロパティ。
- プロセスには、以下のような環境もあります:
- 局所変数とグローバル変数
- 現在のスケジューリングコンテキスト
ネットワークポートやファイルディスクリプターなどの割り当てられたシステムリソース。
ls -lコマンドを実行すると、オペレーティングシステムはそのコマンドを実行する新しいプロセスを作成します。プロセスにはID、状態があり、コマンドが完了するまで実行されます。
プロセスの作成とライフサイクルを理解する
Ubuntuでは、すべてのプロセスはsystemdと呼ばれる初期のシステムプロセスから起源します。これは、カーネルが起動中に最初に開始するプロセスです。
systemdプロセスはプロセスID(PID)1であり、システムの初期化、他のプロセスの開始与管理、およびシステムサービスの処理に責任があります。システム上の他のすべてのプロセスはsystemdの子孫です。
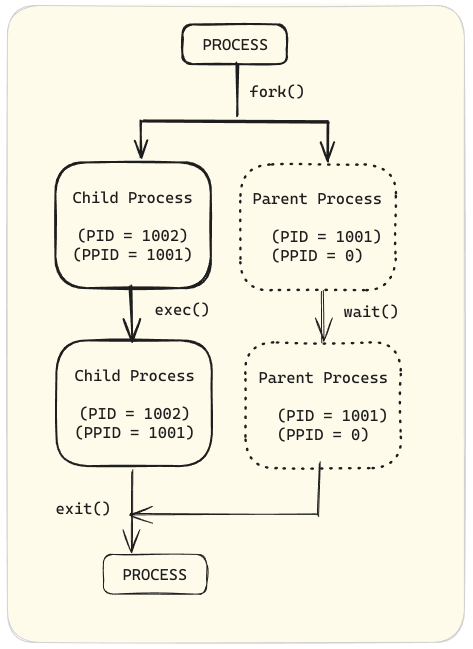
親プロセスは自分自身のアドレススペース(fork)を複製して新しい(子)プロセス構造を作成します。新しいプロセスには、追跡と安全性のために唯一のプロセスID(PID)が割り当てられます。PIDと親プロセスのプロセスID(PPID)は新しいプロセス環境の一部です。どのプロセスも子プロセスを作成することができます。
forkルーチンを通じて、子プロセスは安全なID、前のと現在のファイル記述子、ポートとリソース権限、環境変数、およびプログラムコードを親プロセスから继承します。その後、子プロセスは自分用のプログラムコードを実行することができます。
一般的に、親プロセスは子プロセスが実行される間休止し、子が完了すると通知を受け取るための要求(wait)を設定します。
終了時に、子プロセスはリソースを閉じたり破棄した後になります。子プロセスの最後のリソースとして知られるゼンビー(zombie)というのは、プロセステーブルのエントリーとして残ります。子が終了した際に親が苏ると、子のエントリーをプロセステーブルからクリーンアップし、子プロセスの最後のリソースを解放します。親プロセスはその後自分のプログラムコードを続けて実行します。
プロセスの状態を理解すること。

Linuxのプロセスはそのライフサイクルの中で様々な状態を持ち替えます。プロセスの状態は、現在プロセスが何をしているか、それがシステムとどのように interacts しているかを示します。プロセスは、その実行状態とシステムのスケジューリングアルゴリズムに基づいて状態間で移行します。
| Linuxシステムのプロセスは以下のうちの一つの状態にあります。 | 状態 |
| 説明 | (新規) |
| fork システムコールを通じてプロセスを作成した際の初期状態です。 | 実行可能 (準備中) (R) |
| 実行可能な状態であり、CPUに割り当てられるのを待っています。 | 実行中 (ユーザー) (R) |
| ユーザーモードで実行中であり、ユーザーアプリケーションを実行しています。 | 実行中 (カーネル) (R) |
| カーネルモードで実行中であり、システムコールやハードウェア割り込みを処理しています。 | 休止 (S) |
| 特定のイベント(例えば、I/O操作)の完了を待っている休止状態で、簡単に起こし得分ることができます。 | 休止 (割り込み不可) (D) |
| 特定の状態(通常是I/O)の完了を待てる割り込み不可の休止状態であり、シグナルによる割り込みは受け付けません。 | 休止 (ディスク休止) (K) |
| ディスクI/O操作の完了を待っている状態です。 | 休止 (空闲) (I) |
| 作业をしていませんが、特定のイベントが発生するのを待っている状態です。 | 停止(T) |
| プロセスの実行が停止されており、後で再開できます。通常、シグナルによって停止されます。 | ゾンビ(Z) |
プロセスは実行を完了したが、プロセステーブルにまだエントリがあり、親プロセスが終了ステータスを読むのを待っています。
| これらの状態間でプロセスは以下のように状態遷移します: | 遷移 |
| 説明 | Fork |
| 親プロセスから新しいプロセスを作成し、(新規)から実行可能(準備中)(R)に状態遷移します。 | スケジュール |
| スケジューラーが実行可能なプロセスを選択し、実行中(ユーザ)または実行中(カーネル)状態に遷移させます。 | 実行 |
| プロセスは実行が予定されると、実行可能(準備中)(R)から実行中(カーネル)(R)に状態遷移します。 | プリエンプションまたは再スケジュール |
| プロセスはプリエンプションまたは再スケジュールされる可能性があり、実行可能(準備中)(R)状態に戻ります。 | Syscall |
| プロセスはシステムコールを行い、実行中(ユーザ)(R)から実行中(カーネル)(R)に遷移します。 | リターン |
| プロセスはシステムコールを完了して、実行中(ユーザ)(R)に戻ります。 | 待機 |
| プロセスはイベントを待機し、実行中(カーネル)(R)からスリープ状態(S、D、K、またはI)のいずれかに遷移します。 | イベントまたはシグナル |
| プロセスはイベントやシグナルによって起こされ、スリープ状態から実行可能(準備完了)(R)に移行します。 | 中断 |
| プロセスは中断され、実行中(カーネル)または実行可能(準備完了)から停止(T)に移行します。 | 再開 |
| プロセスは再開され、停止(T)から実行可能(準備完了)(R)に移行します。 | 終了 |
| プロセスは終了し、実行中(ユーザー)または実行中(カーネル)からゾンビ(Z)に移行します。 | 回収 |
親プロセスはゾンビプロセスの終了ステータスを読み取り、プロセステーブルから削除します。
プロセスの表示方法
zaira@zaira:~$ ps aux
Linuxシステム上のプロセスを表示するには、psコマンドをオプションの組み合わせとともに使用することができます。 ps auxのように使用すると、システム上で実行中のすべてのプロセスが表示されます。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# 出力
- 上記の出力はシステム上で現在実行中のプロセスのスナップショットを示しています。各行は次の列を持つプロセスを表しています:
USER: プロセスの所有者のユーザー。PID: プロセスID。%CPU: プロセスのCPU使用率。%MEM: プロセスのメモリ使用量。VSZ: プロセスの仮想メモリサイズ。RSS: レジデントセットサイズ。これは、タスクが使用したスワップされない物理メモリの量です。TTY: プロセスの制御端末。?は制御端末がないことを示します。Ss:セッションリーダー。セッションを開始したプロセスであり、プロセスのグループのリーダーであり、端末シグナルを制御できます。最初のSはスリープ状態を示し、2番目のsはセッションリーダーであることを示します。START:プロセスの開始時刻または日付。TIME:累積CPU時間。
コマンド: プロセスを開始したコマンド。
背景と前台プロセス
この節で、背景または前台で実行することでジョブを制御する方法を学びます。
ジョブは、シェルによって開始されるプロセスです。ターミナルでコマンドを実行すると、それがジョブとして考えられます。ジョブは前台または背景で実行することができます。
- 制御を示すために、まず3つのプロセスを作成し、その後背景で実行します。その後、プロセスを一覧表示し、前台と背景間で切り替えます。スリープまたは完全に終了させる方法を見ます。
3つのプロセスを作成する
ターミナルを開いて、3つの長時間运行するプロセスを開始します。sleepコマンドを使用し、特定の秒数を保持してプロセスを运行させます。
sleep 300 &
sleep 400 &
sleep 500 &
# sleepコマンドを300、400、500秒ごとに実行する
&が各コマンドの末尾にあることで、プロセスを背景に移動します。
背景ジョブを表示する
jobs
jobsコマンドを使用し、背景ジョブの一覧を表示します。
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- 出力はこんな風になるはずです:
前台に背景ジョブを移す
fg %1
背景ジョブを前台に移すには、fgコマンドを使用し、ジョブ番号を続けます。たとえば、最初のジョブ(sleep 300)を前台に移すには:
- これにより、ジョブ
1が前台に移動します。
前台ジョブを背景に戻す
前台で実行中のジョブを一時停止するには、Ctrl+Z を押すことでジョブを一時停止し、背景に移動することができます。
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
一時停止されたジョブは以下のように表示されます。
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# ジョブを一時停止しました
ここで、ID 1のジョブを背景で再開するためにbgコマンドを使用します。
# Ctrl+Z を押して前台ジョブを一時停止します
bg %1
- # そして、背景で再開します
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
ジョブの状態を再度表示します
- この演習で、以下のことを行いました。
- スリープコマンドを使用して三つの背景プロセスを開始しました。
- ジョブを使用して背景ジョブのリストを表示しました。
fg %job_numberを使用してジョブを前台に引き出しました。Ctrl+Zを使用してジョブを一時停止し、bg %job_numberを使用して背景に移動しました。
ジョブを再度使用して背景ジョブの状態を確認しました。
これでジョブの管理方法を学びました。
プロセスの杀死
非反応的なまたは不要なプロセスをkillコマンドを使用して終了させることができます。killコマンドは、プロセスIDに信号を送信し、終了を要求します。
killコマンドには多くのオプションが利用可能です。
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# killコマンドの利用可能なオプション
- 以下は、Linuxでの
killコマンドのいくつかの例です。 - このコマンドは、PID 1234のプロセスにデフォルトの
SIGTERM信号を送信し、終了を要求します。 - このコマンドは、指定された名前のすべてのプロセスにデフォルトの
SIGTERM信号を送信します。 - このコマンドはPID 1234のプロセスに
SIGKILL信号を送信し、強制終了させます。 - このコマンドはPID 1234のプロセスに
SIGSTOP信号を送信し、それを停止します。
このコマンドは指定されたユーザーの所有するすべてのプロセスにデフォルトのSIGTERM信号を送信します。
これらの例は、Linux環境でプロセスを管理するためにkillコマンドを使用するさまざまな方法を示しています。
以下はkillコマンドのオプションとシグナルについての情報で、タブレーション形式で表示されています:この表は、Linuxでプロセス管理のために使用される最も一般的なkillコマンドのオプションとシグナルを概要しています。 |
コマンド / オプション | シグナル |
| 説明 | kill |
SIGTERM |
プロセスを一般的に終了させるためのシグナルであるSIGTERMを要求します。 |
kill -9 |
SIGKILL |
清理を行わずにすぐにプロセスを終了させるためのSIGKILLを強制します。 |
kill -SIGKILL |
SIGKILL |
清理を行わずにすぐにプロセスを終了させるためのSIGKILLを強制します。 |
kill -15 |
SIGTERM |
SIGTERMシグナルを明示的に送信して一般的な終了を要求します。 |
kill -SIGTERM |
SIGTERM |
SIGTERMシグナルを明示的に送信して一般的な終了を要求します。 |
kill -1 |
SIGHUP |
| 「 hang up 」として伝統的な意味があり、構成ファイルを再読み込みするために使用できます。 | kill -SIGHUP |
SIGHUP |
| 伝統的な意味では「吊るしたり」;設定ファイルを再読み込むために使用可能。 | kill -2 <pid> |
SIGINT |
プロセスを終了する要求(终端でCtrl+Cを押すと同様)。 |
kill -SIGINT <pid> |
SIGINT |
プロセスを終了する要求(终端でCtrl+Cを押すと同様)。 |
kill -3 <pid> |
SIGQUIT |
| プロセスを終了し、デバッグ用のコアダンプを生成する。 | kill -SIGQUIT <pid> |
SIGQUIT |
| プロセスを終了し、デバッグ用のコアダンプを生成する。 | kill -19 <pid> |
SIGSTOP |
| プロセスを一時停止。 | kill -SIGSTOP <pid> |
SIGSTOP |
| プロセスを一時停止。 | kill -18 <pid> |
SIGCONT |
| 一時停止されたプロセスを再開。 | kill -SIGCONT <pid> |
SIGCONT |
| 一時停止されたプロセスを再開。 | killall <name> |
異なる |
| 与えられた名前のすべてのプロセスに信号を送信。 | killall -9 <name> |
SIGKILL |
| 指定された名前のすべてのプロセスを強制的に終了します。 | pkill <pattern> |
異なります |
| パターンに一致するプロセスにシグナルを送信します。 | pkill -9 <pattern> |
SIGKILL |
| パターンに一致するすべてのプロセスを強制的に終了します。 | xkill |
SIGKILL |
対応するプロセスを終了するためにウィンドウをクリックできるグラフィカルユーティリティです。
8.5. Linuxの標準入出力ストリーム
- 入力の読み取りと出力の書き込みは、コマンドラインとシェルスクリプトを理解するための重要な部分です。Linuxでは、すべてのプロセスには3つのデフォルトストリームがあります:
stdinのファイルディスクリプタは0です。- 標準出力 (
stdout): プロセスが出力を書き込むデフォルトのストリームです。デフォルトでは、標準出力は终端機です。出力をファイルまたは他のプログラムにリダイレクトすることもできます。stdoutのファイルデスクリプターは1です。
標準エラー (stderr): プロセスがエラーメッセージを書き込むデフォルトのストリームです。デフォルトでは、標準エラーは终端機です。stdoutがリダイレクトされているときでも、エラーメッセージを表示することができます。stderrのファイルデスクリプターは2です。
リダイレクションとパイプライン
リダイレクション: エラーと標準出力ストリームをファイルまたは他のコマンドにリダイレクトすることができます。たとえば:
ls > output.txt
# 標準出力をファイルにリダイレクト
ls non_existent_directory 2> error.txt
# 標準エラーをファイルにリダイレクト
ls non_existent_directory > all_output.txt 2>&1
# 標準出力と標準エラーをファイルに両方にリダイレクト
- 最後のコマンドで、
- 非存在するディレクトリーの内容を表示します。non_existent_directoryという名前のディレクトリーは存在しないため、lsコマンドはエラーメッセージを生成します。
- all_output.txtに内容を書き込む: The
>記号は、lsコマンドの標準出力(stdout)をall_output.txtファイルに引き継ぐために使用されます。ファイルが存在しない場合、新たに作成されます。既存の場合、内容は上書きされます。
2>&1:: ここで、2は標準エラー(stderr)のファイルディスクリプターを表し、&1は標準出力(stdout)のファイルディスクリプターを表します。&記号は、1がファイル名ではなくファイルディスクリプターであることを指定します。
>So, 2>&1 means “redirect stderr (2) to wherever stdout (1) is currently going,” which in this case is the file all_output.txt. Therefore, both the output (if there were any) and the error message from ls will be written to all_output.txt.
Pipelines:
ls | grep image
You can use pipes (|) to pass the output of one command as the input to another:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Output
8.6 Linuxの自動化 – Cron Jobでのタスク自動化
Cronは、Unix-likeオペレーティングシステムで利用可能な強力なジョブスケジューリングユーティリティです。cronを設定することで、一日ごと、一週間ごと、一ヶ月ごと、その他特定の時間に自動的に実行されるジョブを設定することができます。cronが提供する自動化機能は、Linuxシステム管理において非常に重要な役割を果たしています。
crondデーモン(バックグラウンドで実行されるコンピュータープログラムの一種)がcronの機能を可能にします。cronは、crontab(cronテーブル)を読み込んで、定義済みのスクリプトを実行します。
特定の構文を使用することで、cron jobを設定して、スクリプトや他のコマンドを自動的に実行する予定を作成することができます。
Linuxのcron jobとは何ですか?
crontabを通じてスケジュールしたタスクは、cron jobと呼ばれます。
では、cron jobがどのように動作するのか見ていきましょう。
crontabへのアクセスを制御する方法
cron jobを使用するためには、管理者は/etc/cron.allowファイルでユーザーにcron jobを追加することを許可する必要があります。
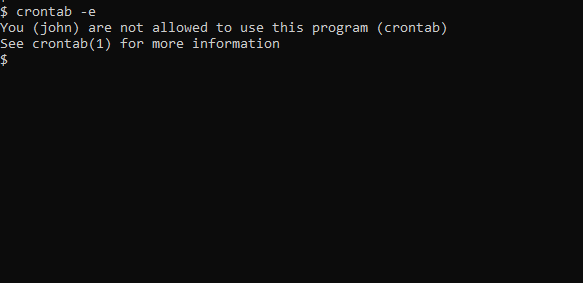
もし以下のようなプロンプトが表示されると、cronを使用する権限がないことを意味します。
![]()
Johnがcronを使用できるようにするには、彼の名前を/etc/cron.allowに含めます。ファイルが存在しない場合は作成します。これにより、Johnがcronジョブを作成および編集できるようになります。
ユーザーは、彼らのユーザー名を/etc/cron.d/cron.denyファイルに記述することでcronジョブへのアクセスを拒否されることもあります。
Linuxでcronジョブを追加する方法
まず、cronジョブを使用するためにはcronサービスの状態を確認する必要があります。cronがインストールされていない場合は、パッケージマネージャを使用して簡単にダウンロードできます。以下を使用して確認します:
sudo systemctl status cron.service
# Linuxシステム上のcronサービスを確認
Crontabの構文
- crontabにcronジョブを追加や一覧表示するために以下のフラグが使用されます:
crontab -e: cronジョブを追加、削除、編集するためにcrontabエントリを編集します。crontab -l: 現在のユーザーのすべてのcronジョブを一覧表示します。crontab -u username -l: 別のユーザーのcronを一覧表示します。
crontab -u username -e: 別のユーザーのcronを編集します。
crontabを一覧表示し、cronが存在する場合は、以下のようなものが表示されます:
* * * * * sh /path/to/script.sh
# Cronジョブの例
- 上の例では、
*は分(分間)、時(時間)、日(日付)、月(月)、週の日(週の日付)をそれぞれ表しています。これらの値の詳細については以下を参照してください。 |
値 | |
| 説明 | 分 | 0-59 |
| 特定の分にコマンドを実行します。 | 時 | 0-23 |
| 特定の時間にコマンドを実行します。 | 日 | 1-31 |
| この月のこれらの日にコマンドを実行します。 | 月 | 1-12 |
| タスクを実行する必要がある月。 | 週の日 | 0-6 |
- コマンドが実行される曜日。ここで、0は日曜日です。
shはスクリプトがBashスクリプトであり、/bin/bashから実行されるべきであることを表します。
/path/to/script.shはスクリプトのパスを指定します。
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
以下はCronジョブの構文の概要です。
Cronジョブの例
| 以下はCronジョブのスケジューリングのいくつかの例です。 | スケジュール |
| スケジュールされた値 | 5 0 * 8 * |
5 4 * * 6 |
|
| At 04:05 on Saturday. | 0 22 * 1-5 |
At 22:00 on every day of week from Monday through Friday.
一度に把握できなくても大丈夫です。
#!/bin/bash
echo `date` >> date-out.txt
date-script.shという、システムの日付と時刻を表示してファイルに追加するスクリプトを作成します。
chmod 775 date-script.sh
2.スクリプトに実行権限を与えて実行可能にする。
3.crontab -eを使ってスクリプトをcrontabに追加する。
*/1 * * * * /bin/sh /root/date-script.sh
ここでは、1分ごとに実行するようにスケジュールしている。
cat date-out.txt
4.ファイルdate-out.txtの出力をチェックする。
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# output
How to troubleshoot crons
cronsは本当に便利ですが、いつも意図したとおりに動くとは限りません。幸い、トラブルシューティングに使える効果的な方法がいくつかあります。
1.スケジュールをチェックする。
最初に、cronに設定されているスケジュールを確認してみてください。上記のセクションで見た構文でできます。
2. クロンログを確認します。
まず、クロンが意図した時間に実行されたかどうかを確認する必要があります。Ubuntuでは、/var/log/syslogにあるクロンログからこれを確認できます。
これらのログに正しい時刻にエントリがある場合、クロンは設定したスケジュールに従って実行されたことを意味します。
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
以下は、クロンジョブの例のログです。タイムスタンプを示す最初の列に注意してください。スクリプトのパスも行の末尾に記載されています。1行目、3行目、5行目はスクリプトが意図した通りに実行されたことを示しています。
3. クロンの出力をファイルにリダイレクトします。
クロンの出力をファイルにリダイレクトして、可能なエラーをチェックすることができます。
* * * * * sh /path/to/script.sh &> log_file.log
# クロンの出力をファイルにリダイレクト
8.7. Linuxネットワーキングの基礎
Linuxには、ネットワークに関連する情報を表示するためのいくつかのコマンドがあります。このセクションでは、いくつかのコマンドについて簡単に説明します。
ifconfigでネットワークインターフェースを表示する
ifconfig
ifconfigコマンドはネットワークインターフェースに関する情報を提供します。以下は例です:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 出力
ifconfigコマンドの出力では、システムに設定されたネットワークインターフェースやIPアドレス、MACアドレス、パケットの統計情報などの詳細が表示されます。
これらのインターフェースは物理的なデバイスまたは仮想デバイスのいずれかです。
IPv4アドレスとIPv6アドレスを抽出するには、それぞれip -4 addrおよびip -6 addrを使用できます。
ネットワーク活動を見るにはnetstat
netstatコマンドは以下の情報を提供することでネットワーク活動と統計を表示します:
netstatコマンドをコマンドラインで使用する例がいくつか以下にあります:- すべての待機中と非待機中のソケットを表示する:
- 待機中のポートのみを表示する:
- ネットワーク統計を表示する:
- ルーティングテーブルを表示する:
- TCP接続を表示する:
- UDP接続を表示する:
- ネットワークインターフェースを表示する:
- PIDとプログラム名を表示する:
- 特定のプロトコル(例:TCP)の統計を表示する:
拡張情報の表示:
2台のデバイス間のネットワーク接続をpingを使用して確認
ping google.com
pingは2台のデバイス間のネットワーク接続をテストするために使用されます。これはターゲットデバイスにICMPパケットを送信し、応答を待ちます。
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
pingはタイムアウトしないで応答を受け取ることができるかをテストします。
— google.com ping統計 —
Ctrl + Cで応答を停止できます。
curlコマンドでエンドポイントをテスト
curlコマンドは”client URL”の略で、サーバーとの間でデータを転送するために使用されます。これはAPIエンドポイントをテストしてシステムとアプリケーションエラーのトラブルシューティングにも使用できます。
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- 例として、
http://www.official-joke-api.appspot.com/を使用してcurlコマンドを実験することができます。
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
オプションなしのcurlコマンドはデフォルトでGETメソッドを使用します。
curl -oは指定されたファイルに出力を保存します。
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# 出力をrandom_joke.jsonに保存
curl -Iはヘッダーのみを取得します。
8.8. Linuxのトラブleshooting: ツールと技術
sarによるシステム活動レポート
Linuxのsarコマンドは、システム活動情報の収集、報告、保存を行う強力なツールです。sysstatパッケージの一部であり、システムの性能を時間にわたってモニターするために広く使用されています。
sarを使用するには、最初にsysstatをインストールする必要があります。sudo apt install sysstatを使用してください。
インストール後、以下のコマンドでサービスを開始します。sudo systemctl start sysstat
ステータスを確認するには、sudo systemctl status sysstatを使用します。
sar [options] [interval] [count]
ステータスがアクティブになったら、システムはさまざまな統計を開始し、それらを使用して履歴データにアクセスし分析することができます。詳細は後で見ます。
sar -u 1 3
sarコマンドの構文は以下の通りです。
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
たとえば、sar -u 1 3は3回CPU利用率の統計を毎秒表示します。
# 出力
sarコマンドの一般的な使用例と使い方の例を以下に示します。
sarは様々な目的で使用できます。
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. メモリ使用量
メモリ使用量(空きと使用中)を確認するには、以下を使用します。
このコマンドは、3回に渡って毎秒メモリ統計を表示します。
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. スワップ空間の使用率
スワップ空間の使用率の統計を表示するには、以下を使用します。
このコマンドは、スワップ使用状況を監視するのに役立ち、物理メモリーを使い果たしているシステムには重要です。
sar -d 1 3
3. I/Oデバイスの負荷
ブロックデバイスとブロックデバイスのパーティションの活動を報告するには:
このコマンドは、ブロックデバイスに対するデータ転送の詳細な統計情報を提供し、I/Oのボトルネックの診断に役立ちます。
sar -n DEV 1 3
5. ネットワーク統計
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
ネットワークインターフェースによって受信(送信)されたパケット数のようなネットワーク統計を表示するには:
# -n DEVはsarにネットワークデバイスインターフェースを報告させる
これは、3秒間隔でネットワーク統計を表示し、ネットワークトラフィックの監視に役立ちます。
- 6. 過去のデータ
- # “true” と “false” が有効な値です。他の値は使用しないでください、
- データ収集間隔を設定します: cron ジョブの設定を編集してデータ収集間隔を設定します。
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
日付を表示するために<DD>を月の日付に置き換えてください。
以下のコマンドで、/var/log/sysstat/sa04は現在の月の4日目の統計を提供します。
sar -I SUM 1 3
7. リアルタイムCPU割り込み
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
CPUが1秒間に処理する割り込み数を観察するには、このコマンドを使用してください:
# 出力
このコマンドは、CPUが割り込みを処理する頻度を監視し、それはリアルタイムパフォーマンス調整に重要です。
これらの例は、sarを使用してシステムパフォーマンスの様々な側面を監視する方法を示しています。sarの定期的な使用は、システムのボトルネックを特定し、アプリケーションが効率的に動作を続けることを保証するのに役立ちます。
8.9. サーバーの一般的なトラブルシューティング戦略
モニタリングを理解する必要は何でしょうか?
システム監視はシステム管理の重要な側面です。重要なアプリケーションは、失敗を防止し、アウトレージの影響を減らすための非常に積極的な対応が必要です。
Linuxはシステムの健全性を測定する非常に強力なツールを提供しています。このセクションでは、システムの健全性を確認し、ボトルネックを特定するために利用可能な様々な方法を学びます。
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
ロードアベレージとシステムのアップタイムを確認する
システムの再起動が発生し、時には設定が乱れることがあります。マシンが稼動している時間を確認するには、uptimeコマンドを使用します。アップタイムに加え、このコマンドはロードアベレージも表示します。
ロードアベレージは過去1分、5分、15分のシステムの負荷です。迅速な確認でシステムの負荷が時間とともに増加または減少しているかどうかがわかります。
注意:理想的なCPUキューは0です。これはCPUの待機キューがない場合にのみ可能です。
lscpu
各CPUの負荷は、ロードアベレージを利用可能なCPUの総数で割ることで計算できます。
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
CPUの数を見つけるためには、lscpuコマンドを使用します。
# 出力
負荷平均が上昇して下がらないとき、CPUは過剰に使用されている可能性があります。卡住しているプロセスがあるか、メモリ泄漏が発生しているかもしれません。
free -mh
空きメモリを計算する
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
時には、高いメモリ使用率が問題を引き起こすことがあります。利用可能なメモリと使用中のメモリを確認するために、freeコマンドを使用してください。
# 出力
ディスクスペースを計算する
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
システムが健全であることを保証するために、ディスクスペースを忘れずにください。以下のコマンドを使用して、利用可能なマウントポイントとそれぞれの使用率を一覧表示します。理想的には、利用されているディスクスペースは80%を超えてはならません。
dfコマンドはディスクスペースを詳細に表示します。
プロセス状態の決定
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
プロセス状態を監視することで、高メモリやCPU使用率の卡住したプロセスを見つけることができます。
前回にも述べたように、psコマンドはプロセスについての有用な情報を提供します。CPUとMEM列を見てください。
リアルタイムシステム監視
リアルタイム監視は、システムのリアルタイム状態を見る窓を提供します。
これを行うためのユーティリティーとして、topコマンドを使用できます。
topコマンドは、システムのプロセスの動的なビューを表示し、サマリーヘッダーを表示してからプロセスまたはスレッドの一覧を表示します。静的なpsの代わりに、topはシステムのステータスを持续的に更新します。
topを使用すると、コンパクトなウィンドウで整然とした詳細情報を確認できます。topには、いくつかのフラグ、ショートカット、およびハイライト方法があります。
topを使用してプロセスをkillすることもできます。その場合、kを押し、プロセスIDを入力します。
ログの解釈
システムとアプリケーションログには、システムが経験していることに関する多くの情報が含まれています。これらには、エラーを指す有用的な情報とエラーコードが含まれています。ログでエラーコードを検索することで、問題の特定と修正にかかる時間を大幅に短縮できます。
ネットワークポートの分析
ネットワークの問題はよくあり、システムとトラフィックの流れに影響を与える可能性があります。一般的なネットワーク問題には、ポートの枯渇、ポートの窒息、解放されていないリソースなどがあります。
| このような問題を特定するためには、ポートの状態を理解する必要があります。 | いくつかのポート状態について簡単に説明します: |
| 状態 | 説明 |
| LISTEN | 任意のリモートTCPからの接続要求を待機しているポートを表します。 |
| ESTABLISHED | 開いている接続を表し、受信したデータを宛先に配信できます。 |
| TIME WAIT | 接続終了要求の認識を確実にする待機時間を表します。 |
FIN WAIT2
リモートTCPからの接続終了要求を待機しています。
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Linuxでのポート関連情報の分析を探ることにしましょう。
ポート範囲: システム内部で定義されているポート範囲は、必要に応じて増やしたり減らすことができます。以下のスニペットでは、15000から65000までの範囲があり、これにより50000(65000 – 15000)の利用可能なポートがあります。利用されたポートがこの限界に達するか超えると、問題が発生します。
このような場合に記録されるログエラーは、ポートに結合失敗や接続が多すぎますです。
パケットの損失を识別する
システム監視では、送信と受信の通信が完璧に行われていることを確認する必要があります。
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
便利なコマンドはpingです。pingは目的地のシステムに対して要求を送り、応答を待ちます。統計情報の最後の数行を見て、パケットの損失率と時間を確認してください。
# ping 目的地のIP
パケットを runtime でキャプチャーするためにはtcpdumpが利用できます。後で詳細に見ていきます。
問題の原因を特定するためのデータ収集
- 常に、後で役立つと思われる統計情報を収集するのは良い慣習です。通常、システムの再起動やサービスの再起動の後、以前のシステムのスナップショットとログを失います。
以下は、システムスナップショットを取得するいくつかの方法です。
- ログのバックアップ
変更を行う前に、ログファイルを別の場所にコピーしてください。これは、問題の发生時にシステムがどのような状態だったかを理解するために非常に重要です。他の実行時の統計は失われる場合もありますが、ログファイルは過去のシステム状態についての唯一の窓となります。
sudo tcpdump -i any -w
TCPダンプ
Tcpdumpは、入力と出力のネットワークトラフィックを捕獲し、分析することができるコマンドラインツールです。主に、ネットワークの問題解決を助けるために使用されます。システムのトラフィックが影響を受けていると感じる場合、以下のようにtcpdumpを取ります。
# どこで、
# -i anyはすべてのインターフェースからのトラフィックを捕获します
# -wは出力ファイル名を指定します
# 数分後にコマンドを止めることで、ファイルサイズが増えるのを防いでください
# ファイルの拡張子を.pcapとして使用してください
一旦tcpdumpが捕まえられると、Wiresharkのようなツールを使用して、視覚的にトラフィックを分析することができます。
結論
この本を読んだことに感謝します。有益だった場合は、他の人に共有していただけると嬉しいです。
しかし、この本はここで終わりません。将来的には、改善して新しい材料を追加していく予定です。何か問題が発見されたり、改善すべき所があると感じる場合、PR/Issueを開けてください。
- 学びの旅を続けて、コネクションを保ちましょう!
-
LinkedIn: 技術に関する記事と投稿をそこに共有しています。LinkedInで推薦をしてくださいと、関連スキルにてエンドORSをしていただけます。
独自のコンテンツにアクセスする:1対1のヘルプと独自のコンテンツにはここを参照してください。
独自のコンテンツにアクセスする:1対1のヘルプと独自のコンテンツにはここを参照してください。
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/