













ビッグデータは2000年代後半の発足以来、大きく進化しました。多くの組織はこのトレンドに迅速に適応し、Apache Hadoopのようなオープンソースツールを使用してビッグデータプラットフォームを構築しました。その後、これらの企業は急速に進化するデータ処理ニーズの管理に苦労するようになりました。彼らはスキーマレベルの変更、パーティションスキームの進化、データを過去に遡って見ることに関する課題に直面しました。
私は2010年代に大手テクノロジー企業とヘルスケア顧客のために大規模な分散システムを設計する際に、同様の課題に直面しました。いくつかの業界では、銀行、金融、ヘルスケアの規制に従うためにこれらの機能が必要です。Netflixのようなデータ駆動型の企業も同様の課題に直面しました。彼らは「アイスバーグ」と呼ばれるテーブルフォーマットを発明し、既存のデータファイルの上に位置し、そのアーキテクチャを活用して重要な機能を提供します。これはデータコミュニティで急速に関心を集め、すぐに主要なASFプロジェクトとなりました。この記事では、例と図を交えて、トップ5のApache Icebergの主要機能を探ります。
1. タイムトラベル

図1: Apache Icebergテーブルフォーマットにおけるタイムトラベル(画像は著者作成)
この機能により、任意の時点でのデータを照会することができます。これにより、データおよびビジネスアナリストがトレンドを理解し、データが時間とともにどのように進化したかを把握する新しい可能性が開かれます。エラーが発生した場合でも、以前の状態に簡単に戻すことができます。この機能は、特定の時点でデータを分析することを可能にすることで、監査チェックを促進します。
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. スキーマの進化
Apache Icebergのスキーマ進化により、大きな労力や高コストの移行なしにスキーマを変更できます。ビジネスニーズが進化するにつれて、次のことができます:
- ダウンタイムやテーブルの書き換えなしで列を追加または削除する。
- 列を更新する(幅を広げる)。
- 列の順序を変更する。
- 既存の列の名前を変更する。
これらの変更は、基礎データを書き換えることなく、メタデータレベルで処理されます。
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. パーティションの進化
Apache Icebergテーブルフォーマットを使用することで、基礎テーブルを書き換えたり、新しいテーブルにデータを移行したりすることなく、テーブルのパーティショニング戦略を変更できます。これは、クエリがApache Hadoopのようにパーティション値を直接参照しないため可能です。Icebergは、各パーティションバージョンのメタデータ情報を別々に保持します。これにより、データを照会する際にスプリットを簡単に取得できます。たとえば、テーブルがパーティション列として月を使用している間(以前)、日を新しいパーティション列(後)として使用している場合、日付範囲に基づいてテーブルを照会することができます。これはスプリットプランニングと呼ばれます。以下の例を参照してください。
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. ACIDトランザクション
Icebergは、原子性、一貫性、隔離性、耐久性(ACID)に関してトランザクションの強力なサポートを提供します。これにより、データの一貫性を損なうことなく、重いデータ集約型ジョブで高いスループットを実現するための複数の同時書き込み操作が可能になります。
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Iceberg内のすべての操作はトランザクショナルであり、データが失敗や同時のデータ変更にもかかわらず一貫性を保つことを意味します。
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
また、異なる隔離レベルをサポートしており、要件に基づいてパフォーマンスと一貫性のバランスを取ることができます。
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
以下は、Icebergが行レベルの更新および削除をどのように処理するかを示す要約です。
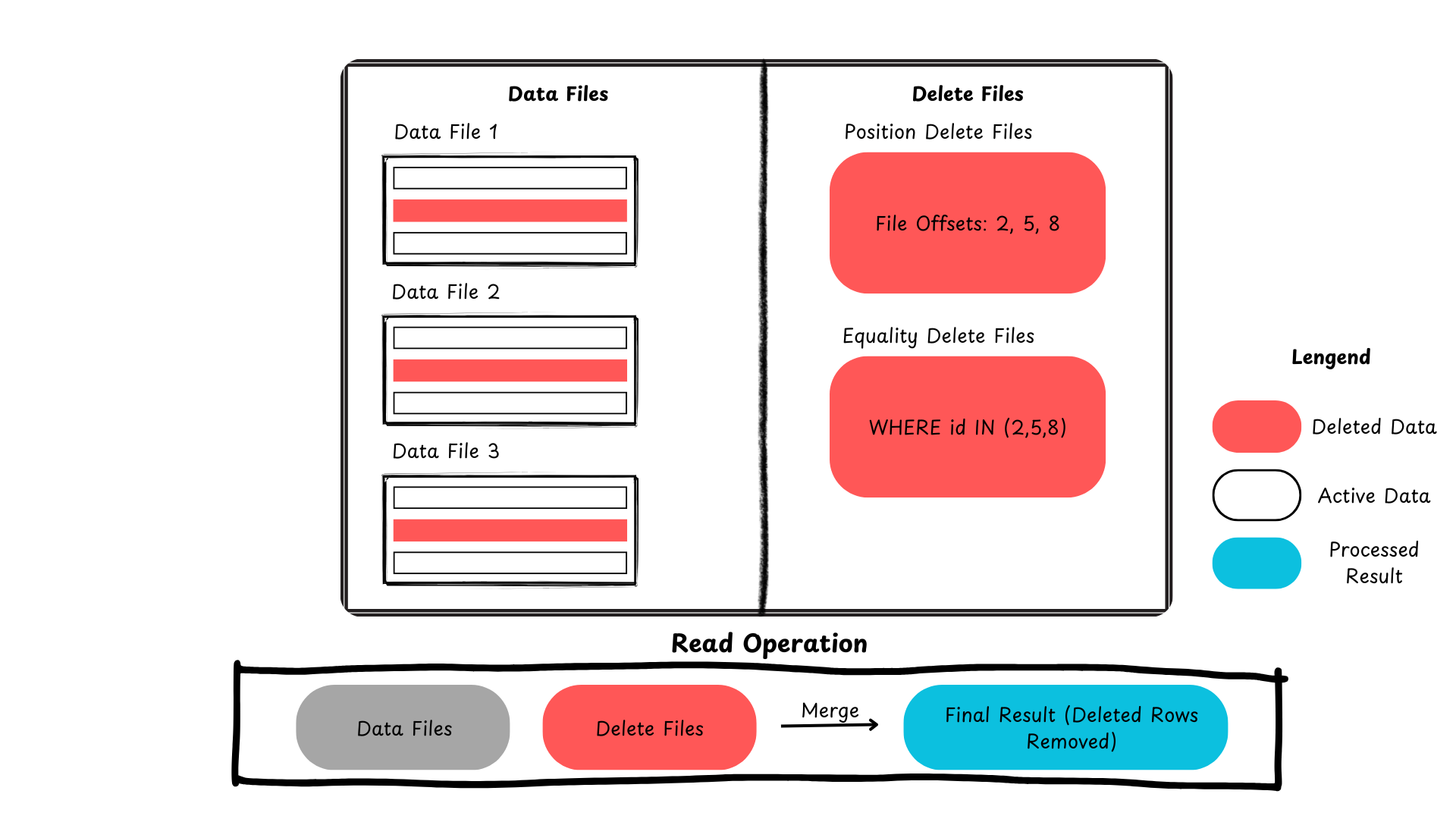
図2: Apache Icebergにおけるレコード削除プロセス(著者による画像)
5. 高度なテーブル操作
Icebergは、次のような高度なテーブル操作をサポートしています:
- テーブルスナップショットの作成/管理: これにより、堅牢なバージョン管理が可能になります。
- 最適化されたメタデータによる迅速なクエリ計画と実行
- コンパクションや孤立ファイルのクリーンアップなど、テーブルメンテナンスのための組み込みツール
Icebergは、AWS S3、GCS、Azure Blob Storageなどの主要なクラウドストレージと連携するように設計されています。また、IcebergはSpark、Presto、Trino、Hiveなどのデータ処理エンジンと簡単に統合できます。
最終的な考え
これらの強調された機能により、企業は時間旅行が可能で、スキーマ変更を容易に処理し、ACIDトランザクションをサポートし、パーティションの進化を実現する、現代的で柔軟性があり、スケーラブルで効率的なデータレイクを構築できます。
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes