













Java HashMapは、Javaで最も人気のあるCollectionクラスの1つです。Java HashMapはハッシュテーブルベースの実装です。Java HashMapはMapインターフェースを実装するAbstractMapクラスを拡張しています。
Java HashMap
 Java HashMapに関する重要なポイントのいくつかは次のとおりです。
Java HashMapに関する重要なポイントのいくつかは次のとおりです。
- Java HashMapはnullキーとnull値を許容します。
- HashMapは順序付けられたコレクションではありません。HashMapのエントリはキーのセットを通じて反復処理できますが、HashMapに追加された順序であることは保証されません。
- HashMapはHashtableとほぼ同じですが、非同期であり、nullキーと値を許容します。
- HashMapは、マップエントリを格納するために内部クラスNode<K,V>を使用します。
- HashMapは、バケットまたはビンと呼ばれる複数の単方向リンクリストにエントリを格納します。デフォルトのビンの数は16であり、常に2の累乗です。
- HashMapは、getおよびput操作においてキーのhashCode()メソッドとequals()メソッドを使用します。そのため、HashMapキーオブジェクトはこれらのメソッドの適切な実装を提供する必要があります。これが、不変クラスがキーに適している理由です。例えば、StringやIntergerです。
- Java HashMapはスレッドセーフではなく、マルチスレッド環境ではConcurrentHashMapクラスを使用するか、
Collections.synchronizedMap()メソッドを使用して同期されたマップを取得する必要があります。
Java HashMapのコンストラクタ
Java HashMapには4つのコンストラクタがあります。
- public HashMap(): 一番よく使用されるHashMapのコンストラクタです。このコンストラクタは、デフォルトの初期容量16と負荷係数0.75の空のHashMapを作成します。
- public HashMap(int initialCapacity): このHashMapのコンストラクタは、初期容量と負荷係数0.75を指定するために使用されます。HashMapに格納されるマッピングの数を事前に知っている場合、再ハッシュを回避するのに役立ちます。
- public HashMap(int initialCapacity, float loadFactor): このHashMapのコンストラクタは、指定された初期容量と負荷係数の空のHashMapを作成します。HashMapに格納される最大のマッピング数を知っている場合に使用できます。一般的なシナリオでは、負荷係数0.75はスペースと時間のコストのバランスが良いため、これを避けるべきです。
- public HashMap(Map<? extends K, ? extends V> m): 指定されたマップと同じマッピングを持つMapを作成し、負荷係数0.75を使用します。
Java HashMapのコンストラクタの例
以下のコードスニペットは、上記のすべてのコンストラクタを使用したHashMapの例を示しています。
Map<String, String> map1 = new HashMap<>();
Map<String, String> map2 = new HashMap<>(2^5);
Map<String, String> map3 = new HashMap<>(32,0.80f);
Map<String,String> map4 = new HashMap<>(map1);
Java HashMapのメソッド
JavaのHashMapの重要なメソッドを見てみましょう。
- public void clear(): このHashMapのメソッドは、すべてのマッピングを削除し、HashMapが空になります。
- public boolean containsKey(Object key): このメソッドは、指定されたキーが存在する場合には’true’を返し、存在しない場合には ‘false’を返します。
- public boolean containsValue(Object value): このHashMapのメソッドは、指定された値が存在する場合には’true’を返し、存在しない場合には’false’を返します。
- public Set<Map.Entry<K,V>> entrySet(): このメソッドは、HashMapのマッピングのSetビューを返します。このセットはマップによってバックアップされるため、マップの変更はセットに反映され、その逆もまた同様です。
- public V get(Object key): 指定されたキーにマップされた値を返します。キーに対するマッピングが存在しない場合はnullを返します。
- public boolean isEmpty(): キーと値のマッピングが存在しない場合にtrueを返すユーティリティメソッドです。
- public Set<K> keySet(): このマップに含まれるキーのSetビューを返します。セットはマップによってバックアップされるため、マップの変更はセットに反映され、その逆もまた同様です。
- public V put(K key, V value): このマップに指定されたキーと値を関連付けます。マップが以前にキーのマッピングを含んでいた場合、古い値は置き換えられます。
- public void putAll(Map<? extends K, ? extends V> m): このマップに指定されたマップのすべてのマッピングをコピーします。これらのマッピングは、このマップが現在指定されたマップ内のいずれかのキーに対して持っているマッピングを置き換えます。
- public V remove(Object key): 指定されたキーに対応するマッピングを、このマップから削除します。
- public int size(): このマップのキーと値のマッピングの数を返します。
- public Collection<V> values(): このマップに含まれる値のコレクションビューを返します。このコレクションはマップによってバックアップされるため、マップの変更はコレクションに反映され、その逆もまた然りです。
Java 8でHashMapには多くの新しいメソッドが導入されました。
- public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction): 指定されたキーがまだ値に関連付けられていない場合(またはnullにマップされている場合)、このメソッドは指定されたマッピング関数を使用してその値を計算し、HashMapに入力します(nullの場合は除く)。
- public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): 指定されたキーに対して値が存在し、nullでない場合、現在のキーとその現在のマッピング値を使用して新しいマッピングを計算しようとします。
- public V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): このHashMapメソッドは、指定されたキーとその現在のマッピング値に対してマッピングを計算しようとします。
- public void forEach(BiConsumer action): このメソッドは、このマップ内の各エントリに対して指定されたアクションを実行します。
- public V getOrDefault(Object key, V defaultValue): 指定されたキーに対するマッピングが見つからない場合に、getと同じくdefaultValueが返されます。
- public V merge(K key, V value, BiFunction remappingFunction): 指定されたキーがまだ値と関連付けられていないか、nullと関連付けられている場合は、指定された非null値と関連付けます。それ以外の場合は、指定されたリマッピング関数の結果で関連付けられた値を置き換え、結果がnullの場合は削除します。
- public V putIfAbsent(K key, V value): 指定されたキーがまだ値と関連付けられていない場合(またはnullにマップされている場合)は、指定された値と関連付けます。nullを返します。それ以外の場合は、現在の値を返します。
- public boolean remove(Object key, Object value): 指定されたキーに対応するエントリを、現在指定された値にマップされている場合にのみ削除します。
- public boolean replace(K key, V oldValue, V newValue): 指定されたキーに対応するエントリを、現在指定された値にマップされている場合にのみ置換します。
- public V replace(K key, V value): 指定されたキーに対応するエントリを、現在いくつかの値にマップされている場合にのみ置換します。
- public void replaceAll(BiFunction function): 各エントリの値を、そのエントリに対して指定された関数を呼び出した結果で置換します。
Java HashMapの例
ここには、一般的に使用されるHashMapの簡単なJavaプログラムがあります。
package com.journaldev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1"); // put example
map.put("2", "2");
map.put("3", "3");
map.put("4", null); // null value
map.put(null, "100"); // null key
String value = map.get("3"); // get example
System.out.println("Key = 3, Value = " + value);
value = map.getOrDefault("5", "Default Value");
System.out.println("Key = 5, Value=" + value);
boolean keyExists = map.containsKey(null);
boolean valueExists = map.containsValue("100");
System.out.println("keyExists=" + keyExists + ", valueExists=" + valueExists);
Set<Entry<String, String>> entrySet = map.entrySet();
System.out.println(entrySet);
System.out.println("map size=" + map.size());
Map<String, String> map1 = new HashMap<>();
map1.putAll(map);
System.out.println("map1 mappings= " + map1);
String nullKeyValue = map1.remove(null);
System.out.println("map1 null key value = " + nullKeyValue);
System.out.println("map1 after removing null key = " + map1);
Set<String> keySet = map.keySet();
System.out.println("map keys = " + keySet);
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.clear();
System.out.println("map is empty=" + map.isEmpty());
}
}
以下は、上記のJava HashMapの例のプログラムの出力です。
Key = 3, Value = 3
Key = 5, Value=Default Value
keyExists=true, valueExists=true
[null=100, 1=1, 2=2, 3=3, 4=null]
map size=5
map1 mappings= {null=100, 1=1, 2=2, 3=3, 4=null}
map1 null key value = 100
map1 after removing null key = {1=1, 2=2, 3=3, 4=null}
map keys = [null, 1, 2, 3, 4]
map values = [100, 1, 2, 3, null]
map is empty=true
JavaでのHashMapの動作原理は?
HashMapは、マッピングを格納するために内部クラスNode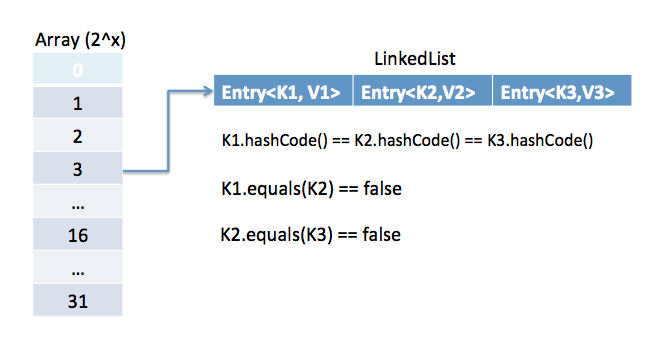 おすすめの読み物: JavaにおけるhashCodeとequalsメソッドの重要性
おすすめの読み物: JavaにおけるhashCodeとequalsメソッドの重要性
Java HashMapのロードファクター
ロードファクターは、HashMapが再ハッシュ化され、バケットサイズが増加するタイミングを決定するために使用されます。バケットまたは容量のデフォルト値は16で、ロードファクターは0.75です。再ハッシュのための閾値は、容量とロードファクターを乗算して計算されます。したがって、デフォルトの閾値値は12になります。したがって、HashMapに12以上のマッピングがある場合、再ハッシュが行われ、ビンの数が次の2の累乗である32に増加します。なお、HashMapの容量は常に2の累乗です。デフォルトのロードファクター0.75は、スペースと時間の複雑さの間の良いトレードオフを提供します。ただし、要件に応じて異なる値に設定することもできます。スペースを節約したい場合は、値を0.80または0.90に増やすこともできますが、その場合、get/put操作にはより多くの時間がかかります。
Java HashMapのkeySet
Java HashMapのkeySetメソッドは、HashMap内のキーのSetビューを返します。このSetビューはHashMapによってバックアップされ、HashMapの変更はSetに反映され、逆もまた同様です。以下は、HashMapのkeySetの例と、マップにバックアップされていないkeySetを取得する方法を示す簡単なプログラムです。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class HashMapKeySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
Set<String> keySet = map.keySet();
System.out.println(keySet);
map.put("4", "4");
System.out.println(keySet); // keySet is backed by Map
keySet.remove("1");
System.out.println(map); // map is also modified
keySet = new HashSet<>(map.keySet()); // copies the key to new Set
map.put("5", "5");
System.out.println(keySet); // keySet is not modified
}
}
上記のプログラムの出力は、keySetがマップによってバックアップされていることを明確に示します。
[1, 2, 3]
[1, 2, 3, 4]
{2=2, 3=3, 4=4}
[2, 3, 4]
Java HashMapの値
Java HashMapのvaluesメソッドは、Map内の値のコレクションビューを返します。このコレクションはHashMapによって支えられているため、HashMapの変更はvaluesコレクションにも反映され、その逆も同様です。以下のシンプルな例は、HashMapのvaluesコレクションのこの動作を確認します。
package com.journaldev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
public class HashMapValuesExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", null);
map.put("4", null);
map.put(null, "100");
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.remove(null);
System.out.println("map values after removing null key = " + values);
map.put("5", "5");
System.out.println("map values after put = " + values);
System.out.println(map);
values.remove("1"); // changing values collection
System.out.println(map); // updates in map too
}
}
上記プログラムの出力は以下の通りです。
map values = [100, 1, 2, null, null]
map values after removing null key = [1, 2, null, null]
map values after put = [1, 2, null, null, 5]
{1=1, 2=2, 3=null, 4=null, 5=5}
{2=2, 3=null, 4=null, 5=5}
Java HashMapのentrySet
Java HashMapのentrySetメソッドは、マッピングのSetビューを返します。このentrySetはHashMapによって支えられているため、マップの変更はエントリーセットにも反映され、その逆も同様です。以下のHashMapのentrySetの例プログラムをご覧ください。
package com.journaldev.examples;
import java.util.AbstractMap;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapEntrySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
Set<Entry<String,String>> entrySet = map.entrySet();
Iterator<Entry<String, String>> iterator = entrySet.iterator();
Entry<String, String> next = null;
System.out.println("map before processing = "+map);
System.out.println("entrySet before processing = "+entrySet);
while(iterator.hasNext()){
next = iterator.next();
System.out.println("Processing on: "+next.getValue());
if(next.getKey() == null) iterator.remove();
}
System.out.println("map after processing = "+map);
System.out.println("entrySet after processing = "+entrySet);
Entry<String, String> simpleEntry = new AbstractMap.SimpleEntry<String, String>("1","1");
entrySet.remove(simpleEntry);
System.out.println("map after removing Entry = "+map);
System.out.println("entrySet after removing Entry = "+entrySet);
}
}
上記プログラムによって生成される出力は以下の通りです。
map before processing = {null=100, 1=1, 2=null}
entrySet before processing = [null=100, 1=1, 2=null]
Processing on: 100
Processing on: 1
Processing on: null
map after processing = {1=1, 2=null}
entrySet after processing = [1=1, 2=null]
map after removing Entry = {2=null}
entrySet after removing Entry = [2=null]
Java HashMapのputIfAbsent
A simple example for HashMap putIfAbsent method introduced in Java 8.
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapPutIfAbsentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
System.out.println("map before putIfAbsent = "+map);
String value = map.putIfAbsent("1", "4");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
System.out.println("map before putIfAbsent = "+map);
value = map.putIfAbsent("3", "3");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
}
}
上記プログラムの出力は以下です。
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null}
putIfAbsent returns: 1
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null, 3=3}
putIfAbsent returns: null
Java HashMapのforEach
Java 8でHashMapのforEachメソッドが導入されました。このメソッドは、与えられたアクションをマップ内の各エントリに対して実行し、すべてのエントリが処理されるか、アクションが例外をスローするまで続けます。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class HashMapForEachExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
BiConsumer action = new MyBiConsumer();
map.forEach(action);
//ラムダ式の例
System.out.println("\nHashMap forEach lambda example\n");
map.forEach((k,v) -> {System.out.println("Key = "+k+", Value = "+v);});
}
}
class MyBiConsumer implements BiConsumer {
@Override
public void accept(String t, String u) {
System.out.println("Key = " + t);
System.out.println("Processing on value = " + u);
}
}
上記のHashMap forEachの例のプログラムの出力は次のとおりです。
Key = null
Processing on value = 100
Key = 1
Processing on value = 1
Key = 2
Processing on value = null
HashMap forEach lambda example
Key = null, Value = 100
Key = 1, Value = 1
Key = 2, Value = null
Java HashMap replaceAll
HashMapのreplaceAllメソッドは、与えられた関数をそのエントリに対して呼び出した結果で各エントリの値を置き換えるために使用できます。このメソッドはJava 8で追加され、このメソッドの引数にはラムダ式を使用できます。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapReplaceAllExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "100");
System.out.println("map before replaceAll = " + map);
BiFunction function = new MyBiFunction();
map.replaceAll(function);
System.out.println("map after replaceAll = " + map);
//ラムダ式を使用したreplaceAll
map.replaceAll((k, v) -> {
if (k != null) return k + v;
else return v;});
System.out.println("map after replaceAll lambda expression = " + map);
}
}
class MyBiFunction implements BiFunction {
@Override
public String apply(String t, String u) {
if (t != null)
return t + u;
else
return u;
}
}
上記のHashMap replaceAllのプログラムの出力は次のとおりです。
map before replaceAll = {null=100, 1=1, 2=2}
map after replaceAll = {null=100, 1=11, 2=22}
map after replaceAll lambda example = {null=100, 1=111, 2=222}
Java HashMap computeIfAbsent
HashMapのcomputeIfAbsentメソッドは、キーがマップに存在しない場合にのみ値を計算します。値を計算した後、それがnullでない場合はマップに追加されます。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
public class HashMapComputeIfAbsent {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
Function function = new MyFunction();
map.computeIfAbsent("3", function); //key not present
map.computeIfAbsent("2", function); //key already present
//ラムダ式の方法
map.computeIfAbsent("4", v -> {return v;});
map.computeIfAbsent("5", v -> {return null;}); //null value won't get inserted
System.out.println(map);
}
}
class MyFunction implements Function {
@Override
public String apply(String t) {
return t;
}
}
上記のプログラムの出力は次のとおりです。
{null=100, 1=10, 2=20, 3=3, 4=4}
Java HashMapのcomputeIfPresentメソッド
Java HashMapのcomputeIfPresentメソッドは、指定されたキーが存在し、値がnullでない場合に値を再計算します。関数がnullを返す場合、マッピングは削除されます。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapComputeIfPresentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
map.put("10", null);
System.out.println("map before computeIfPresent = " + map);
BiFunction<String, String, String> function = new MyBiFunction1();
for (String key : map.keySet()) {
map.computeIfPresent(key, function);
}
System.out.println("map after computeIfPresent = " + map);
map.computeIfPresent("1", (k,v) -> {return null;}); // mapping will be removed
System.out.println("map after computeIfPresent = " + map);
}
}
class MyBiFunction1 implements BiFunction<String, String, String> {
@Override
public String apply(String t, String u) {
return t + u;
}
}
HashMapのcomputeIfPresentの例で生成される出力は、次のとおりです。
map before computeIfPresent = {null=100, 1=10, 2=20, 10=null}
map after computeIfPresent = {null=null100, 1=110, 2=220, 10=null}
map after computeIfPresent = {null=null100, 2=220, 10=null}
Java HashMapのcompute
キーと値に基づいてすべてのマッピングに関数を適用する場合は、computeメソッドを使用する必要があります。このメソッドを使用してマッピングが存在しない場合、compute関数では値はnullになります。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapComputeExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
System.out.println("map before compute = "+map);
for (String key : map.keySet()) {
map.compute(key, (k,v) -> {return k+v;});
}
map.compute("5", (k,v) -> {return k+v;}); //key not present, v = null
System.out.println("map after compute = "+map);
}
}
HashMapのcomputeの例の出力は、次のとおりです。
map before compute = {null=10, 1=1, 2=2, 10=null}
map after compute = {null=null10, 1=11, 2=22, 5=5null, 10=10null}
Java HashMapのmerge
指定されたキーが存在しないか、nullに関連付けられている場合は、それを指定された非nullの値で関連付けます。それ以外の場合は、与えられたリマッピング関数の結果で関連付けられた値を置き換えるか、結果がnullの場合は削除します。
package com.journaldev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class HashMapMergeExample {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
for (Entry entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
//キーまたは値がnullの場合、マージはNullPointerExceptionをスローします。
if(key != null && value != null)
map.merge(entry.getKey(), entry.getValue(),
(k, v) -> {return k + v;});
}
System.out.println(map);
map.merge("5", "5", (k, v) -> {return k + v;}); // key not present
System.out.println(map);
map.merge("1", "1", (k, v) -> {return null;}); // method return null, so remove
System.out.println(map);
}
}
上記のプログラムの出力は、次のとおりです。
{null=10, 1=11, 2=22, 10=null}
{null=10, 1=11, 2=22, 5=5, 10=null}
{null=10, 2=22, 5=5, 10=null}
それでJavaのHashMapについての説明は以上です。大切な情報が抜けていないことを願っています。もし気に入ったなら他の人とも共有してください。参考文献:APIドキュメント
Source:
https://www.digitalocean.com/community/tutorials/java-hashmap