













Elasticsearchとは何か?
Elasticsearchは、Apache Lucene検索ライブラリの上に構築された高度にスケーラブルで分散型の検索および分析エンジンです。これは、大容量の構造化、半構造化、非構造化データを処理するように設計されており、検索エンジン、ログ分析、eコマース、セキュリティ分析など、広範なユースケースに適しています。
Elasticsearchは、クラスタ内の複数のノードにわたって大量のデータを保存および処理することを可能にする分散型アーキテクチャを使用しています。データはシャードにインデックス化されて保存され、ノード間で分散されているため、スケーラビリティと障害耐性が向上します。Elasticsearchはまた、リアルタイムの検索と分析をサポートし、ユーザーがほぼリアルタイムでデータを照会および分析できるようにします。
Elasticsearchの主要な機能の一つは、強力な検索機能です。フルテキスト検索、地理空間検索など、広範な検索クエリをサポートしています。また、集計、メトリクス、データ可視化などの高度な分析機能のサポートも提供しています。
Elasticsearchは、データ収集および処理のためのLogstashや、データ可視化および分析のためのKibanaなど、Elastic Stackの他のツールと組み合わせてよく使用されます。これらのツールを一緒に使用することで、広範なアプリケーションやユースケースのための包括的な検索および分析ソリューションが提供されます。
Apache Luceneとは何か?
Apache Luceneは、強力なテキスト検索およびインデックス作成機能を提供するオープンソースの検索ライブラリです。開発者や組織によって、検索エンジンからECプラットフォームまで、様々な検索アプリケーションの構築に広く使用されています。
Luceneは、文書のテキストコンテンツをインデックス化し、効率的に検索可能な構造化フォーマットでインデックスを保存することで機能します。インデックスは、用語とそれを含む文書の間のマッピングを提供する一連の逆インデックスで構成されています。検索クエリが送信されると、Luceneはインデックスを使用してクエリに一致する文書を迅速に取得します。
コアの検索およびインデックス作成機能に加えて、Luceneはぼやけた検索や空間検索のサポートなど、幅広い高度な機能を提供しています。また、検索結果のハイライトや、関連性に基づいた検索結果のランキングを行うツールも提供しています。
Luceneは、Elasticsearchを含む、幅広い組織やプロジェクトによって使用されています。その豊富な機能、柔軟性、拡張性から、あらゆる種類の検索アプリケーション構築の人気の選択肢となっています。
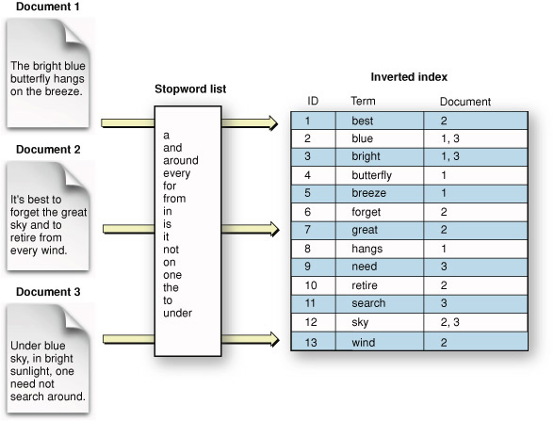
逆インデックスとは何ですか?
Luceneの逆インデックスは、文書のコレクションからテキストデータを効率的に検索および取得するために使用されるデータ構造です。逆インデックスはLuceneの中心的な特徴であり、インデックスを構成する用語とそれらに関連付けられた文書を保存するために使用されます。
逆インデックスは、他の検索戦略に比べていくつかの利点を提供します。まず、検索語句に基づく文書の迅速かつ効率的な検索が可能です。次に、膨大な量のテキストデータを処理できるため、大量の文書コレクションを持つユースケースに適しています。最後に、ぼやけたマッチングやステミングなど、検索結果の精度や関連性を向上させる幅広い高度な検索機能をサポートしています。
Elasticsearchを使う理由は何ですか?
Elasticsearchが検索および分析アプリケーションの構築において人気の選択肢である理由はいくつかあります:
簡単にスケール可能(分散型): Elasticsearchは、オープンソースのもとで水平方向に拡張可能に構築されています。容量を増やす必要があるときは、ノードを追加するだけで、クラスタが自動的に新しいハードウェアを活用するように再編成されます。
1つのサーバは、1つ以上のインデックスの1つ以上の部分を保持でき、新しいノードがクラスタに導入されると、それらは単にパーティに追加されるだけです。このようなインデックス、またはその一部は、シャードと呼ばれ、Elasticsearchのシャードはクラスタ内で非常に簡単に移動できます。
すべてが1つのJSONコールで手に入る(RESTful API): ElasticsearchはAPI駆動型です。ほとんどのアクションは、JSONとHTTPを使用したシンプルなRESTful APIを介して実行できます。応答は常にJSON形式です。
ルーシーンの潜在能力を解放: エラスティックサーチは内部でルーシーンを使用して最先端の分散検索および分析機能を構築しています。ルーシーンは安定した、実証済みの技術であり、絶えず新機能やベストプラクティスが追加されているため、エラスティックサーチを動かす基盤となるエンジンとしてルーシーンを持つことは重要です。
優れたクエリDSL: REST APIは非常に複雑で機能的なクエリDSLを公開し、それを使用するのが非常に簡単です。どのクエリも実質的に任意のタイプのクエリ、あるいは複数のクエリを組み合わせたものを含むことができるJSONオブジェクトです。フィルタリングされたクエリを使用し、一部のクエリをルーシーンフィルタとして表現することで、キャッシングを活用し、一般的なクエリや再利用可能な部分を持つ複雑なクエリを高速化できます。
マルチテナンシー: 1つのエラスティックサーチインストール(ノードまたはクラスタ)に複数のインデックスを保存できます。素晴らしい点は、1つの簡単なクエリで複数のインデックスを照会できることです。
高度な検索機能(全文)への対応: エラスティックサーチは内部でルーシーンを使用して、オープンソース製品で利用可能な最も強力な全文検索機能を提供しています。検索には多言語サポート、強力なクエリ言語、地理的位置サポート、コンテキスト認識の「あなたはこれを探していませんか」の提案、オートコンプリート、検索スニペットが含まれています。フィルターとスコアリングでのスクリプトサポート。
設定可能で拡張可能: エラスティックサーチの多くの設定は、エラスティックサーチが実行中でも変更できますが、一部は再起動が必要であり(場合によっては、インデックスの再構築も必要です)、ほとんどの設定はREST APIを使用して変更できます。
ドキュメント指向: Elasticsearchでは、複雑な現実世界のエンティティを構造化されたJSONドキュメントとして保存します。デフォルトですべてのフィールドがインデックス化され、1つのクエリですべてのインデックスを使用して、驚異的な速度で結果を返すことができます。
スキーマフリー: Elasticsearchでは簡単に始めることができます。JSONドキュメントを送信するだけで、データ構造を検出し、データをインデックス化して検索可能にすることを試みます。
コンフリクト管理: 必要に応じて楽観的なバージョン管理を使用して、複数のプロセスからの競合する変更によりデータが失われることを保証します。
アクティブなコミュニティ: コミュニティは素晴らしいツールやプラグインを作成するだけでなく、非常に役立ち支援的です。全体的な雰囲気は素晴らしく、これはOSSプロジェクトの重要な指標です。また、コミュニティメンバーによって現在書かれている書籍や、ネット上の多くのブログ記事が、経験と知識を共有しています。
Elasticsearchアーキテクチャ
Elasticsearchアーキテクチャの主なコンポーネントは次のとおりです。
ノード: ノードは、データを保存し、検索とインデックス作成機能を提供するElasticsearchのインスタンスです。ノードはマスターノードまたはデータノード、またはその両方に設定できます。マスターノードはクラスタ全体の管理を担当し、データノードはデータを保存し、検索操作を実行します。
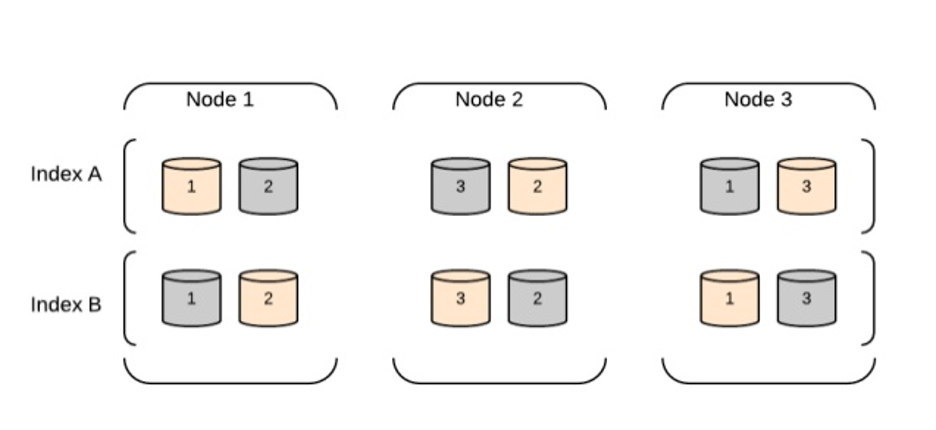
クラスタ: クラスタは、1つ以上のノードが連携してデータの保存と処理を行うグループです。クラスタは複数のインデックス(ドキュメントのコレクション)とシャード(複数のノード間でデータを分散する方法)を含むことができます。
インデックス: インデックスは、類似した構造を持つ文書の集まりです。各文書はJSONオブジェクトとして表され、1つ以上のフィールドを含んでいます。Elasticsearchはデフォルトですべてのフィールドをインデックス化します。これにより、データの検索と分析が容易になります。
シャード: インデックスは複数のシャードに分割でき、これらは基本的にインデックスの小さなサブセットです。シャーディングにより、データの並列処理と複数ノード間での分散ストレージが可能になります。
レプリカ: Elasticsearchは各シャードのレプリカを作成でき、これにより障害耐性と高可用性が提供されます。レプリカは元のシャードのコピーであり、異なるノードに配置されることができます。
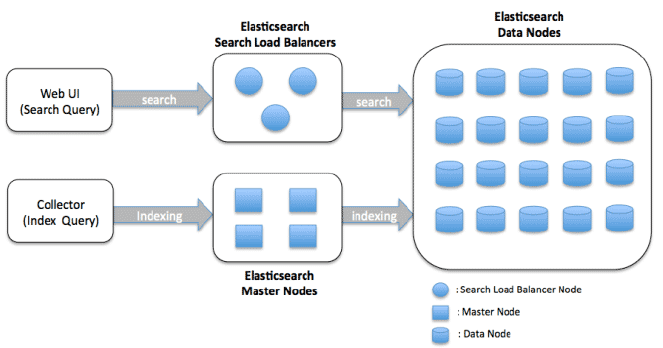
データノードクラスタアーキテクチャ
データノードは、データの保存とインデックス作成、検索および集約操作の実行を担当します。アーキテクチャはスケーラブルで分散型に設計されており、クラスタにより多くのノードを追加することで水平スケーリングが可能です。
Elasticsearchデータノードクラスタアーキテクチャの主なコンポーネントは以下の通りです。
データノード: ノードはElasticsearchのインスタンスであり、データを保存し、検索とインデックス作成の機能を提供します。データノードクラスタでは、各ノードがインデックスデータの一部を保存し、そのデータに対する検索クエリをサーブする役割を担います。
クラスタ状態: クラスタ状態は、クラスタに関する情報を含むデータ構造であり、ノード、インデックス、シャード、それらの場所のリストを含んでいます。マスターノードはクラスタ状態を維持し、クラスタ内の他のすべてのノードに配布する責任を持っています。
発見と輸送: Elasticsearchクラスタ内のノードは、発見と輸送の2つのプロトコルを使用して互いに通信します。発見プロトコルは、クラスタに参加している新しいノードや、クラスタから離れたノードを発見するために使用されます。輸送プロトコルは、ノード間でデータを送受信するために使用されます。
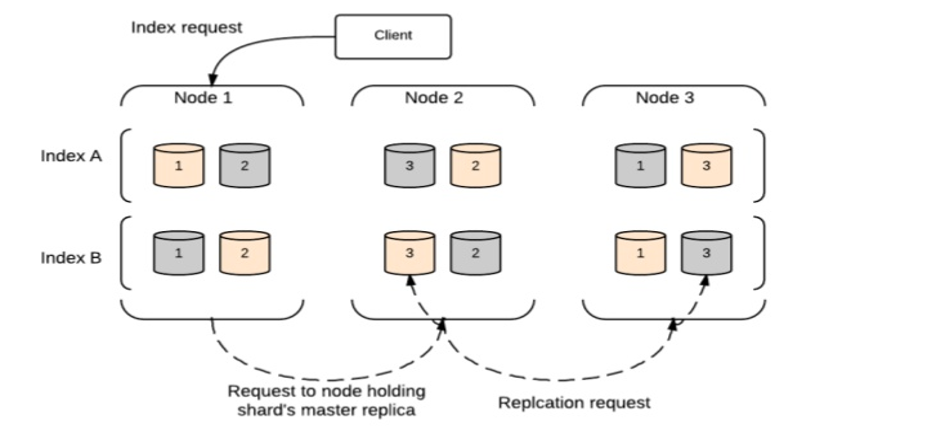
インデックス要求
インデックス要求は、Elasticsearchで以下のブロック図のように実行されます。
Elasticsearchを使用しているのは誰ですか?
Elasticsearchを使用している企業や組織:
Netflix: NetflixはElasticsearchを使用して検索エンジンとレコメンデーションエンジンを強化し、ユーザーが迅速に視聴するコンテンツを見つけることができるようにしています。
GitHub: GitHubはElasticsearchを使用して、コードリポジトリ、問題、プルリクエスト全体で高速かつ効率的な検索機能を提供しています。
Uber: UberはElasticsearchを使用してリアルタイムの分析プラットフォームを強化し、リアルタイムで乗車サービスのデータを追跡および分析できるようにしています。
Wikipedia: WikipediaはElasticsearchを使用して検索エンジンを強化し、ユーザーに迅速かつ正確な検索結果を提供しています。
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1