













ステータス:非推奨
この記事は非推奨で、もはやメンテナンスされていません。
理由
このチュートリアルの手順はまだ機能しますが、現在は不必要にメンテナンスが難しい構成を生成します。
代わりに以下を参照してください
この記事は参考としては依然として有用かもしれませんが、ベストプラクティスに従っていないかもしれません。より新しい記事の使用を強く推奨します。
はじめに
Kubernetesの観測スタックには、トレースとログ記録に加えて、監視とアラートが不可欠なコンポーネントです。DigitalOcean Kubernetesクラスターの監視を設定すると、リソース使用状況を追跡し、アプリケーションのエラーを分析およびデバッグすることができます。
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
人気のある監視ソリューションの1つは、オープンソースのPrometheus、Grafana、およびAlertmanagerスタックです。これは、kube-state-metricsおよびnode_exporterと共に展開され、クラスターレベルのKubernetesオブジェクトメトリクスやCPU、メモリ使用状況などのマシンレベルのメトリクスを公開します。
この監視スタックをKubernetesクラスターに展開するには、個々のコンポーネント、マニフェスト、Prometheusメトリクス、およびGrafanaダッシュボードを設定する必要がありますが、これには時間がかかる場合があります。DigitalOcean Kubernetes Cluster Monitoring Quickstartは、DigitalOceanコミュニティデベロッパーエデュケーションチームによってリリースされ、Prometheus-Grafana-Alertmanagerクラスター監視スタックの完全に定義されたマニフェスト、事前に設定されたアラート、およびGrafanaダッシュボードのセットを含んでいます。これにより、迅速に立ち上げることができ、観測スタックを構築するための堅固な基盤が提供されます。
このチュートリアルでは、この事前設定されたスタックをDigitalOcean Kubernetesに展開し、Prometheus、Grafana、およびAlertmanagerインターフェースにアクセスし、カスタマイズ方法を説明します。
前提条件
始める前に、DigitalOcean Kubernetes クラスターを利用できるようにしておく必要があります。また、ローカル開発環境に次のツールがインストールされている必要があります:
- ローカルマシンにインストールされ、クラスターに接続するように設定されている
kubectlコマンドラインインターフェース。kubectlのインストールと設定については、kubectlの公式ドキュメントを参照してください。(公式ドキュメントで詳細を読む) - ローカルマシンにインストールされているバージョン管理システムgit。Ubuntu 18.04にgitをインストールする方法については、「Ubuntu 18.04にGitをインストールする方法」を参照してください。(詳細を学ぶ)
- ローカルマシンにインストールされているCoreutilsのbase64ツール。Linuxマシンを使用している場合、これはおそらくすでにインストールされています。OS Xを使用している場合は、デフォルトでインストールされている
openssl base64を使用できます。
<$>[note]
注意: クラスターモニタリングクイックスタートは、DigitalOcean Kubernetesクラスターでのみテストされています。他のKubernetesクラスターでクイックスタートを使用する場合は、マニフェストファイルにいくつかの修正が必要になる場合があります。
<$>
ステップ1 — GitHubリポジトリのクローンと環境変数の設定
まず、Gitを使用してDigitalOcean KubernetesクラスターモニタリングGitHubリポジトリをローカルマシンにクローンします:
次に、リポジトリに移動します:
以下のディレクトリ構造が表示されます:
OutputLICENSE
README.md
changes.txt
manifest
manifestディレクトリには、監視スタックのすべてのコンポーネント(サービスアカウント、デプロイメント、StatefulSets、ConfigMapsなど)のKubernetesマニフェストが含まれています。これらのマニフェストファイルの詳細とそれらの設定方法については、監視スタックの設定に進んでください。
もしも、すぐに始めたい場合は、APP_INSTANCE_NAME と NAMESPACE の環境変数を設定してください。これらは、スタックのコンポーネントに一意の名前を設定し、スタックを展開するNamespaceを構成するために使用されます。
このチュートリアルでは、APP_INSTANCE_NAME を sammy-cluster-monitoring に設定します。これにより、監視スタックのすべての Kubernetes オブジェクト名の先頭に接頭辞が付加されます。監視スタックに固有の記述的な接頭辞に置き換えてください。また、Namespace を default に設定します。監視スタックを default 以外のNamespaceに展開する場合は、まずクラスタにそれを作成してください。
以下の出力が表示されます。
Outputnamespace/sammy created
この場合、NAMESPACE 環境変数が sammy に設定されていました。チュートリアルの残りの部分では、NAMESPACE が default に設定されていると仮定します。
今、安全な Grafana パスワードを base64 エンコードするために base64 コマンドを使用してください。 your_grafana_password の部分には、選択したパスワードを置き換えてください。
macOS を使用している場合は、デフォルトでインストールされている openssl base64 コマンドを使用できます。
この時点で、スタックの Kubernetes マニフェストを取得し、必要な環境変数を構成したので、Kubernetes マニフェストファイルに構成済みの変数を置き換えて、Kubernetes クラスタにスタックを作成する準備が整いました。
ステップ2 — モニタリングスタックの作成
デジタルオーシャン Kubernetes モニタリングクイックスタートリポジトリには、以下のモニタリング、スクレイピング、および可視化コンポーネントのマニフェストが含まれています:
- Prometheusは、メトリクスエンドポイントをポーリングし、これらのエンドポイントが公開するデータをスクレイピングおよび処理することによって動作する時系列データベースおよびモニタリングツールです。これを使用して、PromQLと呼ばれる時系列データクエリ言語を使用してこのデータをクエリできます。Prometheusは、2つのレプリカを使用するStatefulSetとしてクラスタにデプロイされ、デジタルオーシャンのブロックストレージを使用する永続ボリュームが含まれています。さらに、事前に設定された一連のPrometheusアラート、ルール、およびジョブがConfigMapとして保存されます。これらの詳細については、「モニタリングスタックの設定」のPrometheusセクションに進んでください。
- Alertmanagerは、通常、Prometheusと共に展開され、スタックのアラートレイヤーを形成し、Prometheusによって生成されたアラートを処理し、重複を削除し、グループ化し、メールやPagerDutyなどの統合にルーティングします。Alertmanagerは、2つのレプリカを持つStatefulSetとしてインストールされます。Alertmanagerについて詳しくは、Prometheusのドキュメントのアラート を参照してください。
- Grafanaは、データの可視化および分析ツールであり、メトリクスデータのダッシュボードやグラフを構築できます。Grafanaは、1つのレプリカを持つStatefulSetとしてインストールされます。さらに、kubernetes-mixinによって生成された事前に構成されたダッシュボードのセットがConfigMapとして保存されます。
- kube-state-metricsは、Kubernetes APIサーバーを監視し、DeploymentsやPodsなどのKubernetesオブジェクトの状態に関するメトリクスを生成するアドオンエージェントです。これらのメトリクスは、HTTPエンドポイントでプレーンテキストとして提供され、Prometheusによって消費されます。kube-state-metricsは、1つのレプリカを持つ自動スケーラブルなDeploymentとしてインストールされます。
- node-exporterは、クラスターノード上で実行され、CPUやメモリの使用状況などのOSおよびハードウェアメトリクスをPrometheusに提供するPrometheusエクスポーターです。これらのメトリクスも、HTTPエンドポイントでプレーンテキストとして提供され、Prometheusによって消費されます。node-exporterは、DaemonSetとしてインストールされます。
デフォルトでは、node-exporter、kube-state-metrics、および上記にリストされている他のコンポーネントが生成したメトリクスをスクレイピングするように、Prometheus は次のコンポーネントからメトリクスをスクレイピングするように構成されます:
- kube-apiserver、Kubernetes API サーバー。
- kubelet、ノード上の Pod とコンテナを管理するために kube-apiserver と対話する主要なノード エージェントです。
- cAdvisor、実行中のコンテナを検出し、それらの CPU、メモリ、ファイルシステム、およびネットワークの使用状況のメトリクスを収集するノード エージェントです。
これらのコンポーネントと Prometheus スクレイピング ジョブの構成について詳しく学ぶには、監視スタックの構成に進んでください。これで、前のステップで定義した環境変数をリポジトリのマニフェスト ファイルに置換し、個々のマニフェストを単一のマスター ファイルに連結します。
awkとenvsubstを使用して、リポジトリのマニフェストファイル内のAPP_INSTANCE_NAME、NAMESPACE、GRAFANA_GENERATED_PASSWORD変数を埋めます。変数の値を代入した後、ファイルは結合され、sammy-cluster-monitoring_manifest.yamlという名前のマスターマニフェストファイルに保存されます。
このファイルをバージョン管理に保存して、モニタリングスタックの変更を追跡し、以前のバージョンに戻すことができるようにしてください。これを行う場合は、Grafanaパスワードをファイルから削除して、バージョン管理にチェックインしないようにしてください。
マスターマニフェストファイルを生成したので、kubectl apply -fを使用してマニフェストを適用し、構成したNamespaceにスタックを作成します。
次のような出力が表示されます:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
kubectl get allを使用してスタックの展開状況を追跡できます。すべてのスタックコンポーネントがRUNNINGになったら、Grafanaウェブインターフェイスを介して事前構成済みのGrafanaダッシュボードにアクセスできます。
ステップ3 — Grafanaへのアクセスとメトリクスデータの探索
Grafanaサービスマニフェストは、GrafanaをClusterIPサービスとして公開しています。これは、クラスター内部のIPアドレス経由でのみアクセス可能であることを意味します。Kubernetesクラスターの外部からGrafanaにアクセスするには、kubectl patchを使用してサービスをNodePortやLoadBalancerなどの公開型に更新するか、kubectl port-forwardを使用してローカルポートをGrafanaポッドポートに転送することができます。このチュートリアルではポートを転送しますので、Grafanaサービスにアクセスするためのローカルポートの転送に進んでください。次のセクションでは、Grafanaを外部に公開する方法についての説明が含まれています。
ロードバランサーを使用してGrafanaサービスを公開する(オプション)
Grafanaのために外部の公開IPを持つDigitalOceanロードバランサーを作成したい場合は、既存のGrafanaサービスをLoadBalancerサービスタイプに更新するためにkubectl patchを使用してください:
kubectl patchコマンドを使用すると、オブジェクトを再デプロイすることなく、変更を加えることができます。また、マスターマニフェストファイルを直接変更して、Grafanaサービスの仕様にtype: LoadBalancerパラメーターを追加することもできます。 kubectl patchおよびKubernetesサービスタイプについて詳しくは、公式Kubernetesドキュメントのkubectl patchを使用してAPIオブジェクトをインプレースで更新するおよびサービスリソースを参照してください。
上記のコマンドを実行した後、次のように表示されます:
Outputservice/sammy-cluster-monitoring-grafana patched
ロードバランサーを作成し、それにパブリックIPを割り当てるには数分かかる場合があります。変更を監視するには、次のコマンドを-wフラグとともに使用します:
デジタルオーシャンのロードバランサーが作成され、外部IPアドレスが割り当てられたら、次のコマンドを使用して外部IPを取得できます:
これで、http://SERVICE_IP/に移動してGrafana UIにアクセスできます。
Grafanaサービスにアクセスするためのローカルポートの転送
Grafanaサービスを外部に公開したくない場合は、kubectl port-forwardを使用してローカルポート3000を直接クラスターに転送することもできます。
以下の出力が表示されるはずです:
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
これにより、ローカルポート3000がGrafana Pod sammy-cluster-monitoring-grafana-0のcontainerPort3000に転送されます。 Kubernetesクラスターにポートを転送する詳細については、クラスター内のアプリケーションにアクセスするためのポート転送を使用するを参照してください。
Webブラウザでhttp://localhost:3000にアクセスします。次のGrafanaログインページが表示されます:

ログインするには、デフォルトのユーザー名admin(admin-userパラメーターを変更していない場合)と、ステップ1で設定したパスワードを使用します。
以下のホームダッシュボードに移動します:
左側のナビゲーションバーで、ダッシュボードボタンを選択し、管理をクリックします:
次のダッシュボード管理インターフェースが表示され、dashboards-configmap.yamlマニフェストで構成されたダッシュボードがリストされます:
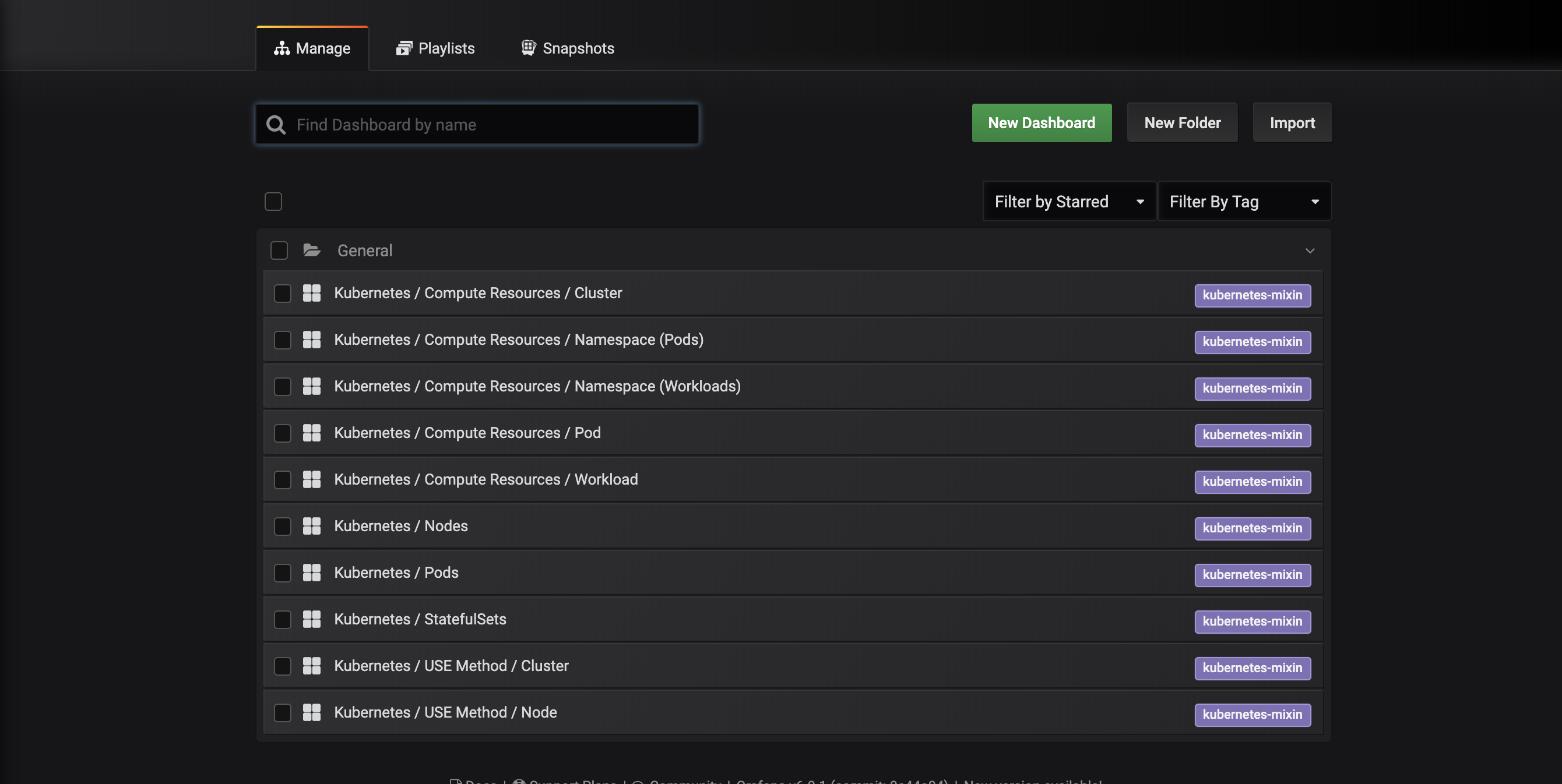
これらのダッシュボードは、kubernetes-mixinによって生成されています。これは、クラスター監視のための標準化されたセットのGrafanaダッシュボードとPrometheusアラートを作成するためのオープンソースプロジェクトです。詳細については、kubernetes-mixin GitHubリポジトリを参照してください。
Kubernetes / Nodesダッシュボードにアクセスしてください。これは、特定のノードのCPU、メモリ、ディスク、およびネットワーク使用状況を視覚化します。
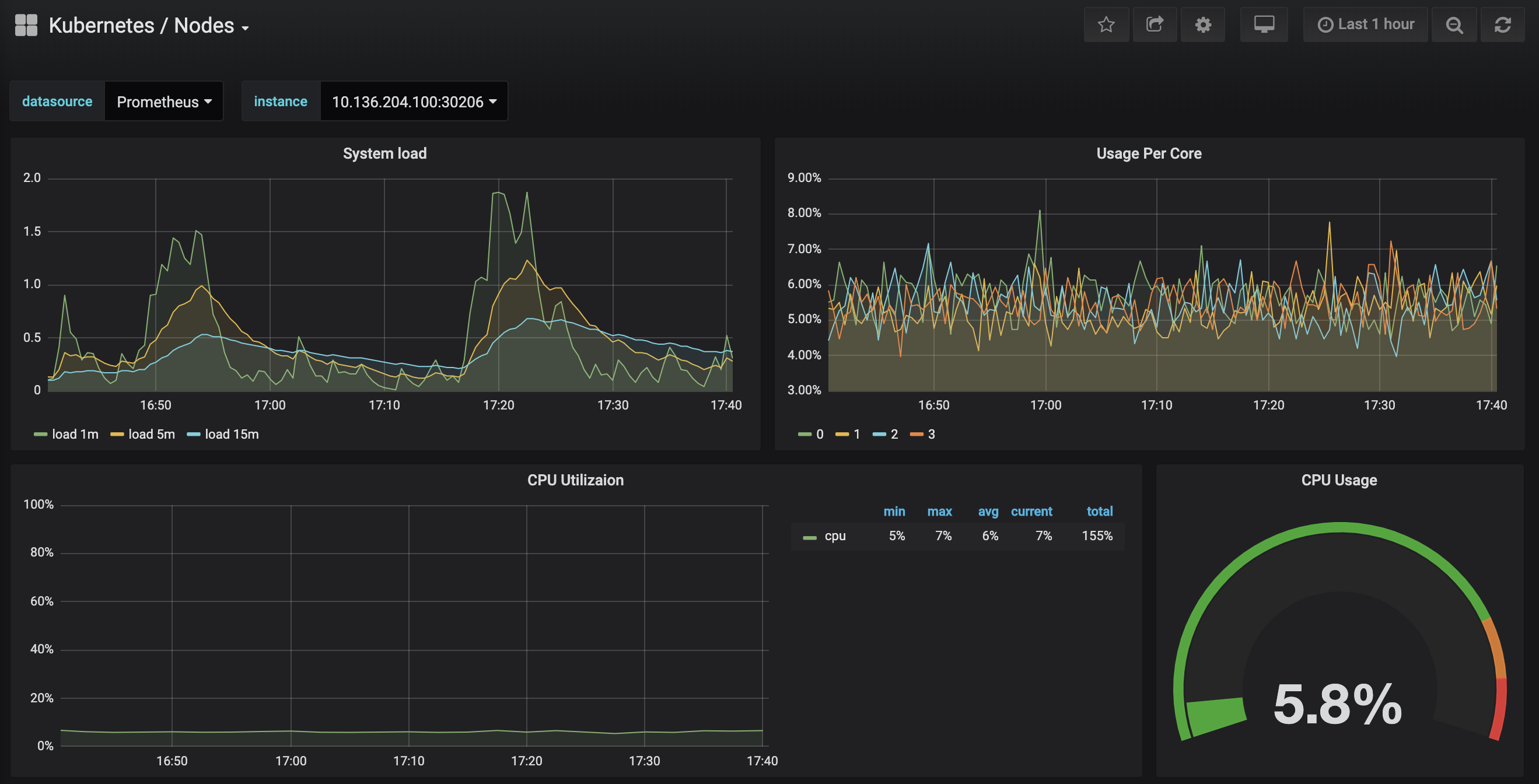
これらのダッシュボードの使用方法を説明することは、このチュートリアルの範囲外ですが、詳細については以下のリソースを参照できます。
- システムのパフォーマンスを分析するためのUSEメソッドについて詳しくは、Brendan GreggのThe Utilization Saturation and Errors (USE) Methodページを参照してください。
- GoogleのSRE Bookも有益なリソースです。特に第6章:Monitoring Distributed Systemsをご覧ください。
- 独自のGrafanaダッシュボードを構築する方法については、GrafanaのGetting Startedページを参照してください。
次のステップでは、Prometheus監視システムに接続して探索するための類似したプロセスに従います。
ステップ4 — PrometheusとAlertmanagerへのアクセス
Prometheus Podsに接続するには、ローカルポートに転送するためにkubectl port-forwardを使用できます。Grafanaの探索が完了したら、CTRL-Cを押してポートフォワードトンネルを閉じることができます。または、新しいシェルを開いて新しいポートフォワード接続を作成することもできます。
defaultネームスペースで実行中のPodをリストアップすることから始めます:
以下のPodが表示されます:
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
ローカルポート9090をsammy-cluster-monitoring-prometheus-0 Podのポート9090に転送します:
次の出力が表示されます:
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
これにより、ローカルポート9090がPrometheus Podに正常に転送されていることが示されます。
ウェブブラウザでhttp://localhost:9090にアクセスしてください。次のPrometheus グラフページが表示されます:

ここから、Prometheusクエリ言語であるPromQLを使用して、データベースに保存されている時系列メトリックを選択および集約できます。PromQLについて詳しくは、公式のPrometheusドキュメントのQuerying Prometheusを参照してください。
表現フィールドにkubelet_node_nameと入力して、実行をクリックしてください。Kubernetesクラスター内のノードを報告するkubelet_node_nameメトリックの時系列リストが表示されます。メトリックラベルには、どのノードがメトリックを生成し、どのジョブがメトリックをスクレイプしたかが表示されます:

最後に、トップナビゲーションバーでステータスをクリックし、ターゲットをクリックして、Prometheusがスクレイプするように構成されたターゲットのリストを表示します。最初のステップ2で説明した監視エンドポイントのリストに対応するターゲットのリストが表示されます。
Prometheusおよびクラスターメトリックのクエリについて詳しくは、公式のPrometheusドキュメントを参照してください。
Alertmanagerに接続するには、Prometheusに接続する際と同様のプロセスに従います。 一般的には、PrometheusのトップナビゲーションバーでアラートにクリックしてAlertmanagerアラートを探索できます。
Alertmanagerポッドに接続するには、再びkubectl port-forwardを使用してローカルポートに転送します。 Prometheusの探索を終了した場合は、ポートフォワードトンネルを閉じるか、CTRL-Cを押して新しい接続を作成するために新しいシェルを開くことができます。
ローカルポート9093をsammy-cluster-monitoring-alertmanager-0ポッドのポート9093に転送します:
次の出力が表示されます:
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
これにより、ローカルポート9093がAlertmanagerポッドに正常に転送されていることが示されます。
ウェブブラウザでhttp://localhost:9093を開いてください。次のAlertmanagerアラートページが表示されます:
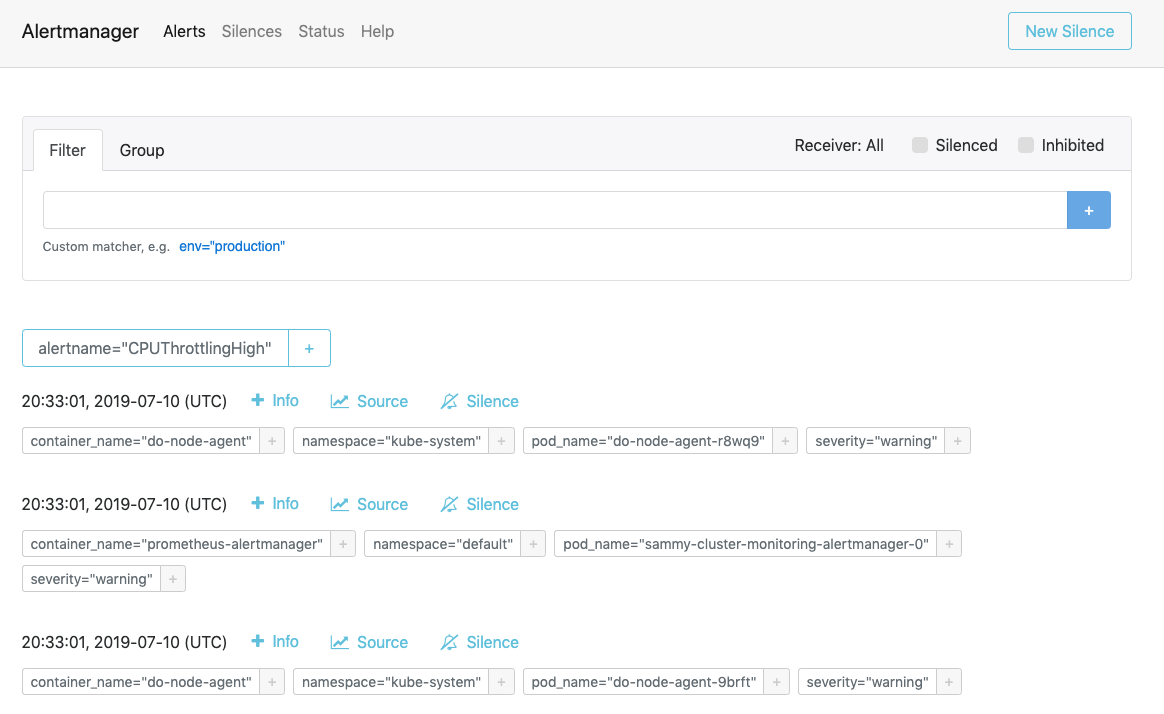
ここから、アラートの発生を調査し、必要に応じてそれらを無効にすることができます。Alertmanagerについて詳しくは、公式Alertmanagerドキュメントを参照してください。
次のステップでは、モニタリングスタックの一部のコンポーネントをオプションで設定およびスケーリングする方法を学びます。
ステップ6 — モニタリングスタックの設定(オプション)
DigitalOcean Kubernetes Cluster Monitoring Quickstartリポジトリに含まれるマニフェストを変更して、異なるコンテナイメージ、異なるポッドレプリカの数、異なるポート、およびカスタマイズされた設定ファイルを使用するように変更できます。
このステップでは、各マニフェストの目的の概要を提供し、次に、マスターマニフェストファイルを変更してPrometheusを3つのレプリカにスケーリングする方法を示します。
始めに、リポジトリ内のmanifestsサブディレクトリに移動し、ディレクトリの内容をリストします:
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
ここには、異なる監視スタックのコンポーネントのマニフェストがあります。マニフェスト内の特定のパラメータについて詳しく知るには、リンクに移動してYAMLファイル全体に含まれるコメントを参照してください:
Alertmanager
-
alertmanager-0serviceaccount.yaml:Alertmanagerのサービスアカウント。これは、AlertmanagerポッドにKubernetesのアイデンティティを与えるために使用されます。Pod用のサービスアカウントの詳細については、Pod用のサービスアカウントの構成を参照してください。 -
alertmanager-configmap.yaml:alertmanager.ymlと呼ばれる最小限のAlertmanager構成ファイルを含むConfigMap。Alertmanagerの設定はこのチュートリアルの範囲外ですが、Alertmanagerのドキュメントの構成セクションを参照することで詳細を学ぶことができます。 -
alertmanager-operated-service.yaml: 現在の2レプリカの高可用性構成でAlertmanagerポッド間のリクエストのルーティングに使用されるAlertmanagerのmeshサービス。 -
alertmanager-service.yaml:アラートマネージャーwebサービスは、以前のステップで行ったかもしれないアラートマネージャーのWebインターフェースへのアクセスに使用されます。 -
alertmanager-statefulset.yaml:アラートマネージャーのStatefulSetは、2つのレプリカで構成されています。
Grafana
-
dashboards-configmap.yaml:事前に構成されたJSON Grafanaモニタリングダッシュボードを含むConfigMap。ゼロからダッシュボードとアラートの新しいセットを生成することは、このチュートリアルの範囲を超えていますが、詳細についてはkubernetes-mixin GitHubリポジトリを参照してください。 -
grafana-0serviceaccount.yaml:Grafanaサービスアカウント。 -
grafana-configmap.yaml:デフォルトの最小限のGrafana設定ファイルを含むConfigMap。 -
grafana-secret.yaml:Grafana管理者ユーザーとパスワードを含むKubernetes Secret。Kubernetes Secretsについて詳しくは、Secretsを参照してください。 -
grafana-service.yaml:Grafanaサービスを定義するマニフェスト。 -
grafana-statefulset.yaml: Grafana StatefulSet は、1 つのレプリカで構成され、スケーラブルではありません。Grafana のスケーリングは、このチュートリアルの範囲外です。高可用性の Grafana セットアップの作成方法については、公式 Grafana ドキュメントの 高可用性の Grafana セットアップ方法 を参照してください。
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: kube-state-metrics のサービスアカウントと ClusterRole です。ClusterRoles について詳しくは、Kubernetes ドキュメントの Role と ClusterRole を参照してください。 -
kube-state-metrics-deployment.yaml:メインの kube-state-metrics デプロイメントマニフェスト、1 つの動的にスケーラブルなレプリカを使用してaddon-resizerが構成されています。 -
kube-state-metrics-service.yaml:kube-state-metrics デプロイメントを公開するサービス。
ノードエクスポーター
-
node-exporter-0serviceaccount.yaml: ノードエクスポーターのサービスアカウント。 -
node-exporter-ds.yaml: ノードエクスポーターのデーモンセットマニフェスト。ノードエクスポーターはデーモンセットなので、クラスター内の各ノードでノードエクスポーターポッドが実行されます。
###Prometheus
-
prometheus-0serviceaccount.yaml: Prometheusのサービスアカウント、ClusterRole、およびClusterRoleBinding。 -
prometheus-configmap.yaml: 3つの設定ファイルを含むConfigMap:alerts.yaml:kubernetes-mixinによって生成された事前構成されたアラートのセットを含みます(これはGrafanaダッシュボードを生成するためにも使用されました)。アラートルールの設定について詳しくは、Prometheusのドキュメントからアラートルールを参照してください。prometheus.yaml: Prometheusのメイン設定ファイルです。Prometheusはステップ2の冒頭にリストされているすべてのコンポーネントをスクレイプするように事前に設定されています。Prometheusの設定については、この記事の範囲を超えますが、詳細については公式のPrometheusドキュメントから設定を参照してください。rules.yaml: Prometheusのレコーディングルールのセットで、Prometheusが頻繁に必要な、または計算上高価な式を計算し、その結果を新しい時系列のセットとして保存できるようにします。これらもkubernetes-mixinによって生成され、それらの設定はこの記事の範囲を超えます。詳細については、公式のPrometheusドキュメントからレコーディングルールを参照してください。
-
prometheus-service.yaml: Prometheus StatefulSetを公開するサービス。 -
prometheus-statefulset.yaml: 2つのレプリカで構成されたPrometheus StatefulSet。このパラメータは、必要に応じてスケーリングできます。
例: Prometheusのスケーリング
監視スタックを変更する方法を示すために、Prometheusのレプリカ数を2から3にスケーリングします。
お好みのエディタを使用して、sammy-cluster-monitoring_manifest.yamlマスターマニフェストファイルを開きます:
マニフェストのPrometheus StatefulSetセクションにスクロールします:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
レプリカの数を2から3に変更します:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
ファイルを保存して閉じると完了です。
kubectl apply -f を使用して変更を適用します。
進行状況は kubectl get pods を使用して追跡できます。この同じテクニックを使用して、この観測スタックの多くの Kubernetes パラメータや構成の更新を行うことができます。
結論
このチュートリアルでは、DigitalOcean Kubernetes クラスターに標準のダッシュボード、Prometheus ルール、およびアラートを備えた Prometheus、Grafana、および Alertmanager モニタリングスタックをインストールしました。
このモニタリングスタックを Helm Kubernetes パッケージマネージャーを使用してデプロイすることもできます。詳細については、Helm と Prometheus を使用した DigitalOcean Kubernetes クラスターモニタリングの設定方法を参照してください。同様のスタックを実行する別の方法は、現在ベータ版で提供されている DigitalOcean マーケットプレイスの Kubernetes モニタリングスタックソリューションを使用することです。
デジタルオーシャンのKubernetesクラスタモニタリングクイックスタートリポジトリは、Google Cloud Platformのクリックして展開するPrometheusソリューションをベースに大幅に変更されています。オリジナルのリポジトリからの変更と変更の完全なマニフェストは、クイックスタートリポジトリのchanges.mdファイルにあります。