













はじめに
Apache Kafkaは、クラスターに接続するためには認証された personnelと应用程序だけに接続できるよう、さまざまなセキュリティプロトコルと認証ワークフローをサポートしています。デフォルトの設定では、Kafkaはすべての人にアクセスを許可していますが、安全性のチェックは有効にはしていません。これは探索や開発に便利ですが、本番環境のデプロイメントは、外部に露出する前に適切に保護されなければならないです。また、このような環境は、スムーズな操作を保証し、可能な失敗を防ぐために監視する必要があります。
このチュートリアルで、TLSトラフィックの暗号化とSASL認証を設定して、標準的なユーザー名とパスワードのログイン流程を提供することで、Kafkaのインストールを強化します。提供されたプロデューサーとコンシューマースクリプトを設定し、保護されたクラスターに接続する方法を学びます。その後、Kafkaの指標をエクスポートし、Grafanaで可视化する方法を学びます。また、AKHQによって提供されるwebベースのインターフェースを使用して、クラスターのノードとトピックにアクセスする方法も学びます。
前提条件
このチュートリアルを完了するためには、以下が必要です:
- 至少有4GB RAM和2个CPU的Droplet。在Ubuntu服务器的情况下,请遵循初始服务器设置以获取设置说明。
- 已经在您的Droplet上安装并配置了Apache Kafka。为了获取设置说明,请参阅Kafka简介教程。您只需完成第1步和第2步。
- 了解Java如何处理密钥和证书。更多信息,请访问Java Keytool Essentials: Working with Java Keystores教程。
- Grafana已安装在您的服务器或本地机器上。请参阅如何在Ubuntu上安装和安全配置Grafana教程以获取说明。您只需要完成前四个步骤。
- 一个完全注册的域名指向您的Droplet。本教程将使用
your_domainthroughout and will refer to the same domain name as the Grafana prerequisite throughout。您可以在Namecheap上购买域名,或者在Freenom上免费获得一个,也可以使用您选择的域名注册商。
ステップ1 – Kafkaセキュリティプロトコルの設定
標準設定では、Kafkaはリクエストの起源を確認せず、誰にでも接続を許可しています。これは、デフォルトではクラスターが誰にでもアクセス可能であることを意味します。テストには問題ありませんが、ローカルマシンやプライベートインストールにおけるメンテナンスの負担を軽減します。しかし、本番環境や公開されたKafkaインストールでは、不正アクセスを防ぐためにセキュリティ機能を有効にする必要があります。
このステップでは、Kafkaブローカーを設定し、ブローカーとコンシューマー間のトラフィックにTLS暗号化を使用します。また、クラスターに接続する際に証明書を検証するためにSASLを認証フレームワークとして設定します。
TLS証明書とストアの生成
TLSを設定するために必要な証明書とキーを生成するには、Confluent Platform Security Toolsリポジトリからスクリプトを使用します。まず、以下のコマンドを実行してホームディレクトリにクローンします:
それに移動します:
スクリプトの名前はkafka-generate-ssl-automatic.shです。このスクリプトは、国、州、組織、都市を環境変数として提供する必要があります。これらのパラメーターは、証明書の作成に使用されますが、内容は重要ではありません。また、パスワードも提供する必要があります。これは、生成されるJavaの信頼とキーストアを保護するために使用されます。
以下のコマンドを実行して、必要な環境変数を設定します。your_tls_passwordをあなたの望む値に置き換えてください。
注意してください、PASSWORDは少なくとも6文字以上である必要があります。
スクリプトに実行可能な権限を与えるために以下のコマンドを実行します。
次に、必要なファイルを生成するためにスクリプトを実行します。
多くの出力が表示されます。完了したら、ディレクトリ内のファイルを一覧表示します。
出力はこのようになります。
証明書、信頼、キーストアが正常に作成されていることがわかります。
KafkaのTLSとSASLの設定
TLS暗号化を有効にする必要なファイルを持った後、Kafkaを使用してそれらを適用し、SASLを使用してユーザーを認証する設定を行います。
インストールディレクトリの下の config/kraft にある server.properties ファイルを修正します。あなたは、前提条件の一部としてホームディレクトリの kafka にインストールしたことでしょう。以下のコマンドで移動します:
メインの設定ファイルを編集するために開きます:
nano config/kraft/server.properties
以下の行を探します:
これらを以下のように修正し、PLAINTEXT を BROKER に置き換えます:
次に、listener.security.protocol.map 行を探します:
BROKER を SASL_SSL にマッピングするために、値の前に定義を追加します:
ここで、BROKER エイリアスの定義を追加しました。これは侦听器で使用しているもので、SASL_SSL に対応づけています。これにより、SSL(TLSの古い名前)およびSASLの両方が使用されることを示しています。
次に、ファイルの末尾に移動し、以下の行を追加します。
まず、生成された信頼とキーストアの場所とパスワードを定義します。ssl.client.auth パラメーターを required に設定し、Kafkaに対して有効なTLS証明書を提出しない连接を許可しないよう指示します。その後、SASLメカニズムを PLAIN に設定し、有効にします。PLAIN はPLAINTEXT とは異なり、暗号化された接続を必要とし、そして両者はユーザー名とパスワードの証明情報の組み合わせに依存します。
最後に、StandardAuthorizer を認証器クラスとして設定します。これは、作成する設定ファイルに基づいてクレデンシャルを確認します。そして、allow.everyone.if.no.acl.found パラメーターを false に設定し、適切な証明情報を持っていない接続にアクセスを制限します。また、admin ユーザーをスーパーユーザーとして指定します。なぜなら、クラスター内で管理任务を行うために少なくとも1人のスーパーユーザーが必要ですからです。
最後に、your_tls_password を、前のセクションでスクリプトに渡したパスワードで置き換え、そしてファイルを保存し閉じます。
設定が完了したKafkaについて、接続時に許可された資格情報を定義するファイルを作成する必要があります。Kafkaは、認証ワークフローを実装するためのフレームワークであるJava Authentication and Authorization Service (JAAS)をサポートし、JAAS形式の資格情報定義を受け入れます。
それらをconfig/kraft配列の下にkafka-server-jaas.confという名前のファイルに保存します。編集するために作成および開くには、以下のコマンドを実行します:
以下の行を追加します:
usernameとpasswordは、複数のノードが存在するクラスター内でインターボローカムミュニケーションに使用される主要な資格情報を定義します。 user_admin行は、ユーザー名がadminでパスワードがadminのユーザーを定義し、ブローカーから外部から接続できるようにします。編集が完了したら、ファイルを保存して閉じます。
Kafkaは、メイン設定を補完するkafka-server-jaas.confファイルを認識する必要があります。 kafka systemdサービス設定を変更し、それに参照を渡す必要があります。サービスを編集するために以下のコマンドを実行します:
--fullを渡すことで、サービスの完全な内容にアクセスできます。ExecStart行を見つけます:
以下の行をそれの上に追加して、このように見えるようにします:
この設定では、設定ファイル内のjava.security.auth.login.configパラメーターをJAAS設定ファイルのパスに設定し、それをメインのKafka設定から分離します。これが完了したら、ファイルを保存して閉じます。サービス定義を再読み込みするために以下を実行してください:
その後、Kafkaを再起動します:
これで、KafkaインストールにTLS暗号化とSASL認証の両方を設定しました。次に、提供されているコンソールスクリプトを使用して接続する方法を学びます。
ステップ2 – セキュアクラスターへの接続
このステップでは、提供されているコンソールスクリプトとJAAS設定ファイルを使用してセキュアなKafkaクラスターに接続する方法を学びます。
トピックの操作やメッセージの生成・消費に使用される提供されているスクリプトも内部でJavaを使用しており、信頼ストアおよびキーストアの場所、そしてSASLクレデンシャルを詳細に含むJAAS設定を受け入れます。
その設定をホームディレクトリーにあるclient-jaas.confという名前のファイルに保存します。以下のコマンドで作成し編集を開始します:
以下の行を追加します:
以前と同様に、プロトコルをSASL_SSLに設定し、作成したキーと信頼ストアのパスとパスワードを提供します。その後、SASLメカニズムをPLAINに設定し、adminユーザーの資格情報を提供します。ssl.endpoint.identification.algorithmパラメーターを明示的にクリアして、接続問題を防ぐ必要があります。なぜなら、最初のスクリプトは実行されるマシンのホスト名を証明書エンドポイントとして設定しているため、正しくない可能性があります。
適切な値にyour_tls_passwordを置き換え、ファイルを保存し閉じてください。
このファイルをスクリプトに渡すために、--command-configパラメーターを使用します。次のコマンドでクラスター内に新しいトピックを作成してみてください。
このコマンドは成功적행するはずです。
作成されたかどうかを確認するには、以下のコマンドを実行します。
出力はnew_topicが存在することを示します。
この節で、KafkaのインストールをTLSエンryptionをトラフィックに使用し、ユーザー名とパスワードを組み合わせて認証を行うSASLを使用する設定を行いました。次に、Prometheusを使用してJMX経由でKafkaのさまざまなメトリックをエクスポートする方法を学びます。
手順3 – Prometheusを使用してKafka JMXメトリックを監視する
このセクションでは、Prometheusを使用してKafkaのメトリクスを収集し、Grafanaでクエリ可能にします。これには、KafkaのJMXエクスポーターを設定し、Prometheusに接続することが含まれます。
[Java Management Extensions (JMX)は、Javaアプリケーションのフレームワークで、開発者がアプリケーションの実行時に一般的なカスタムメトリクスを標準化された形式で収集することができます。KafkaはJavaで書かれており、JMXプロトコルをサポートしており、トピックやブローカーの状態など、カスタムメトリクスをそれを通じて公開します。
KafkaとPrometheusの設定
進む前に、Prometheusをインストールする必要があります。Ubuntuマシンでは、aptを使用できます。以下を実行してリポジトリを更新します:
その後、Prometheusをインストールします:
他のプラットフォームの場合は、公式ウェブサイトのインストール手順に従ってください。
インストール後、Prometheus用のJMXエクスポーターライブラリをKafkaインストール先に追加する必要があります。リリースページに移動し、名前にjavaagentが含まれる最新のリリースを選択してください。執筆時点では、利用可能な最新バージョンは0.20.0でした。以下のコマンドを使用して、Kafkaがインストールされているlibs/ディレクトリにダウンロードしてください:
JMXエクスポーターライブラリは今後Kafkaによって読み込まれます。
エクスポーターを有効にする前に、Prometheusに報告するメトリックを定義する必要があります。その設定をKafkaインストール先のconfig/ディレクトリにjmx-exporter.ymlという名前のファイルに保存します。JMXエクスポータープロジェクトは適切なデフォルト設定を提供しています。以下のコマンドを実行して、jmx-exporter.ymlとしてKafkaインストール先のconfig/ディレクトリに保存してください:
次に、エクスポーターを有効にするために、Kafkaのsystemdサービスを変更する必要があります。エクスポーターやその設定を含むようにKAFKA_OPTS環境変数を変更する必要があります。サービスを編集するために以下のコマンドを実行してください:
Environment行を以下のように変更してください:
ここでは、-javaagent引数を使用して、JMXエクスポーターを設定とともに初期化します。
設定が完了したらファイルを保存し閉じ、Kafkaを再起動するために以下を実行してください:
1分後に、JMXエクスポーターが実行されていることを確認するために、ポート7075が使用されているかどうかを照会してください:
この行は、ポート7075がKafkaサービスによって起動されたJavaプロセスによって使用されていることを示しています。これはJMXエクスポーターを指しています。
今から、Prometheusを設定してエクスポートされたJMXメトリクスを監視します。その主要な設定ファイルは/etc/prometheus/prometheus.ymlにありますので、編集を開始しましょう:
以下の行を見つけてください:
scrape_configsの下に、Prometheusがどのエンドポイントを監視するかを指定する設定の中に、Kafkaメトリクスをスクレイピングする新しいセクションを追加してください:
kafkaジョブには、JMXエクスポーターエンドポイントを指す1つのターゲットがあります。
your_domainをあなたのドメイン名で置き換えて、ファイルを保存して閉じます。その後、Prometheusを以下を実行して再起動します:
ブラウザで、あなたのドメインのポート9090にアクセスします。PrometheusのUIにアクセスします。ステータスの下にあるターゲットをクリックしてジョブを一覧表示します:
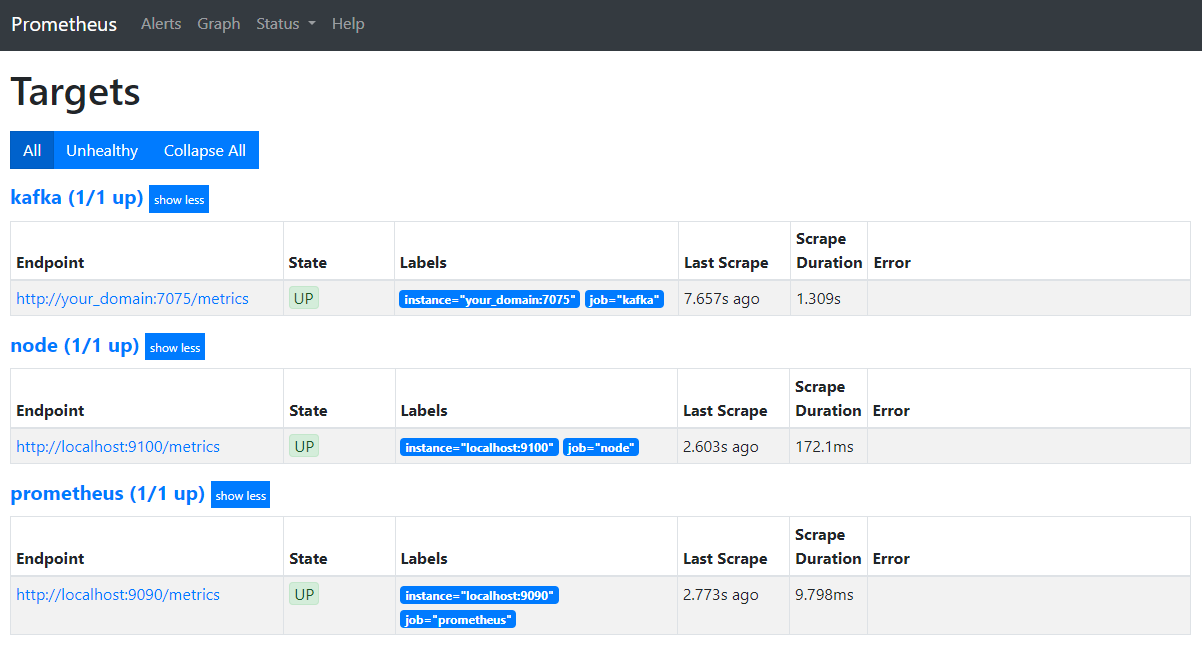
Prometheusがkafkaジョブを受け入れ、メトリクスのスクレイピングを開始したことに注意してください。次に、Grafanaでそれらにアクセスする方法を学びます。
Grafanaでメトリクスの照会
前提条件の一部として、GrafanaをDropletにインストールし、your_domainで公開しています。ブラウザでそれに移動し、サイドバーの接続にある新しい接続の追加を押し、検索フィールドにPrometheusと入力してください。
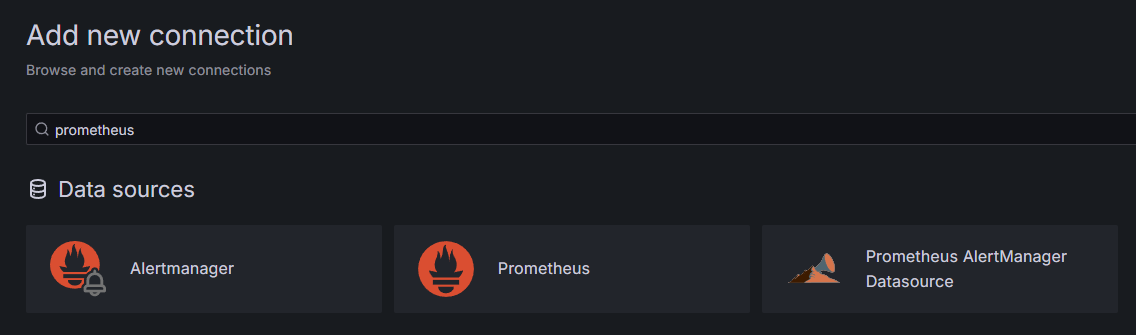
Prometheusを押し、右上の新しいデータソースの追加ボタンをクリックしてください。Prometheusインスタンスのアドレスを入力するよう求められます:
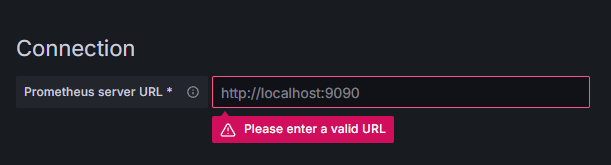
http://your_domain_name:9090に入力し、実際のドメイン名に置き換え、下にスクロールして保存&テストを押してください。成功メッセージを受け取るべきです:

Prometheus接続がGrafanaに追加されました。サイドバーの探索を押し、メトリックを選択するよう促されます。例えば、kafka_と入力すると、クラスタに関連するすべてのメトリックをリストアップできます:
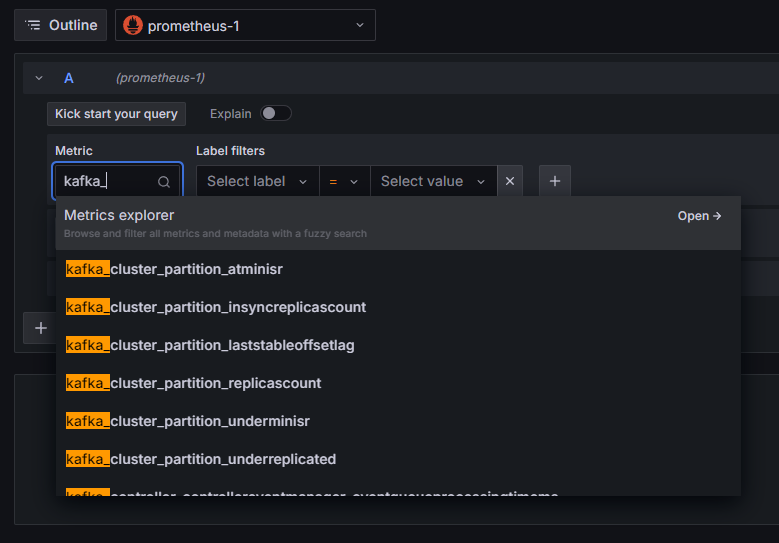
例えば、kafka_log_log_sizeメトリックを選択し、これはディスク上の内部ログの各パーティションにおける大きさを示します。その後、右上角のクエリの実行を押してください。利用可能な各トピックに対して、時間とともに変わるサイズを見ることができます:
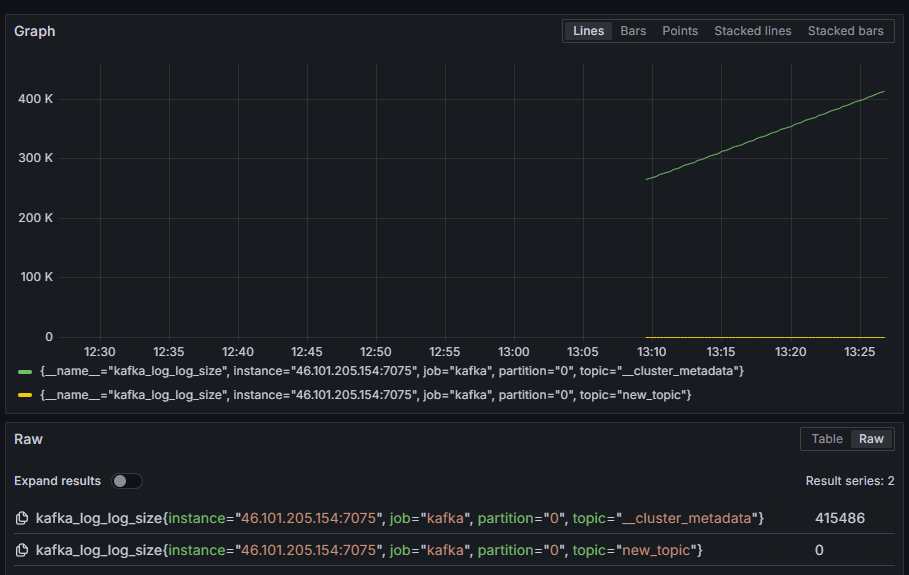
この手順で、Kafkaが提供するJMXメトリクスのエクポートを設定し、Prometheusをそれらをスクレイピングするように構成しました。そして、Grafanaからそれに接続し、Kafkaメトリクスに対するクエリを実行しました。ここで、webインターフェースを使用してKafkaクラスターを管理する方法を学びます。
手順4 – AKHQを使用したKafkaクラスター管理
この手順で、Kafkaクラスターを管理するwebアプリケーションAKHQの設定と使用方法を学びます。これにより、トピック、パーティション、コンシューマーグループや設定パラメーターを一括してリスト表示し、操作することができます。また、一度の場所からトピックからメッセージを生成したり、消費したりすることもできます。
実行可能ファイルとその設定をakhqという名前のディレクトリに保存します。このディレクトリを、以下のコマンドを実行してホームディレクトリに作成します:
それに移動します:
ブラウザで公式リリースページを訪れ、最新リリースのJARファイルのリンクをコピーします。執筆時点で、最新のバージョンは0.24.0でした。次のコマンドを実行して、それをホームディレクトリに下载します:
これでAKHQをダウンロードしました。次に、クラスターに接続するための設定をakhq-config.ymlという名前のファイルに保存します。このファイルを作成し、編集するために以下のコマンドを実行します:
以下の行を追加します:
これは基本的なAKHQ設定です。localhost:9092にある1つのクラスタを指定し、付随するSASLとTLSパラメータを指定しています。複数のクラスタを同時にサポートしており、必要なだけ接続を定義できます。これにより、AKHQはKafkaの管理に非常に柔軟です。設定が完了したら、ファイルを保存して閉じます。
次に、AKHQをバックグラウンドで実行するためのsystemdサービスを定義する必要があります。systemdサービスは、一貫して起動、停止、再起動できます。
サービス設定をcode-server.serviceという名前のファイルに保存し、/lib/systemd/systemディレクトリに配置します。systemdがサービスを保存する場所です。テキストエディタを使用して作成します:
以下の行を追加します:
まず、サービスの説明を指定します。次に、[Service]セクションでサービスのタイプ(simpleはコマンドを単純に実行することを意味します)を定義し、実行されるコマンドを提供します。また、実行ユーザーをkafkaとし、サービスが終了した場合に自動的に再起動されるよう指定します。
[Install]セクションでは、systemdにサーバーにログインしたときにこのサービスを起動するよう指示します。設定が完了したら、ファイルを保存して閉じます。
サービス設定を以下のコマンドを実行して読み込みます:
以下のコマンドを実行してAKHQサービスを起動します:
次に、ステータスを確認して、正しく起動されたかどうかを確認します:
出力は以下のようになります:
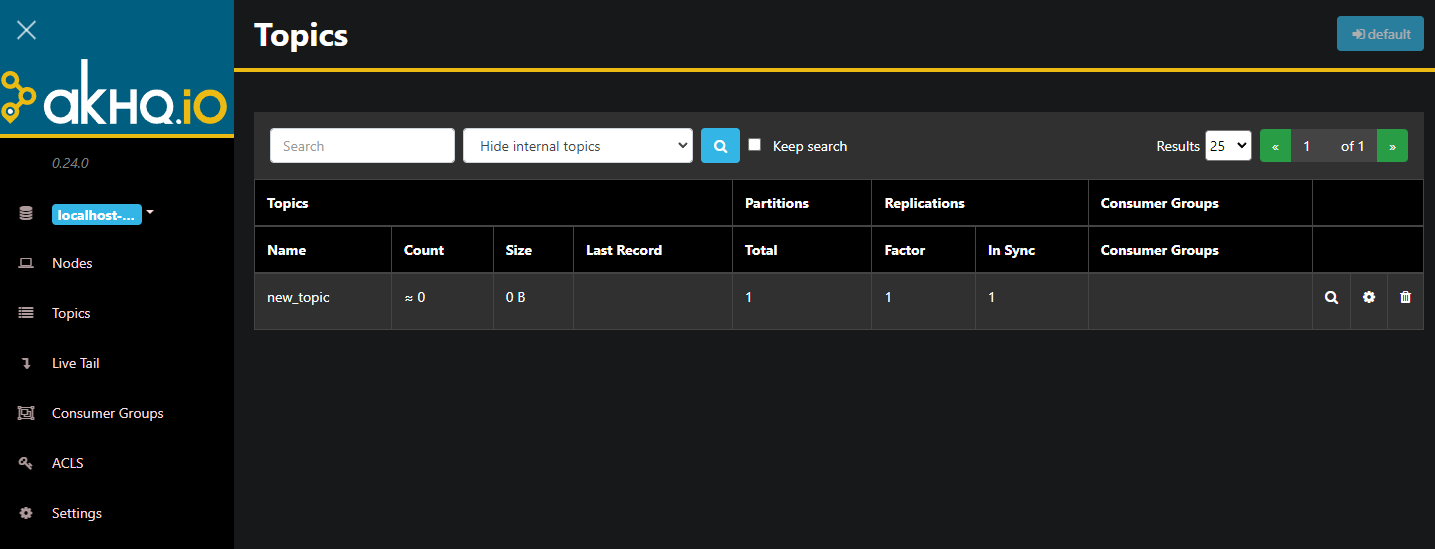
AKHQは現在、背景で運行しています。デフォルトでは、8080のポートで公開されています。ブラウザで、そのポートを含むドメインに移動してアクセスします。デフォルトのビューが表示され、トピックのリストが表示されます:
トピックの行をダブルクリックすることで、詳細なビューにアクセスすることができます:
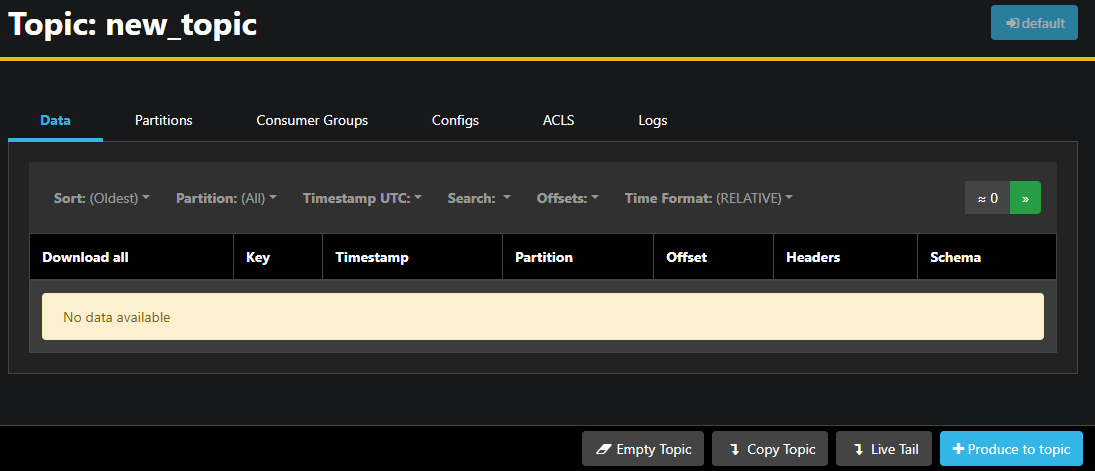
AKHQを使用すると、トピック内のメッセージや、分割、コンsumer グループやその設定を表示できます。下部の右にあるボタンを使用して、トピックを空にするかコピーすることもできます。
`new_topic`トピックは空ですので、Topicにメッセージを送信するボタンを押して、新しいメッセージのパラメーターを選択するインターフェースを開きます:
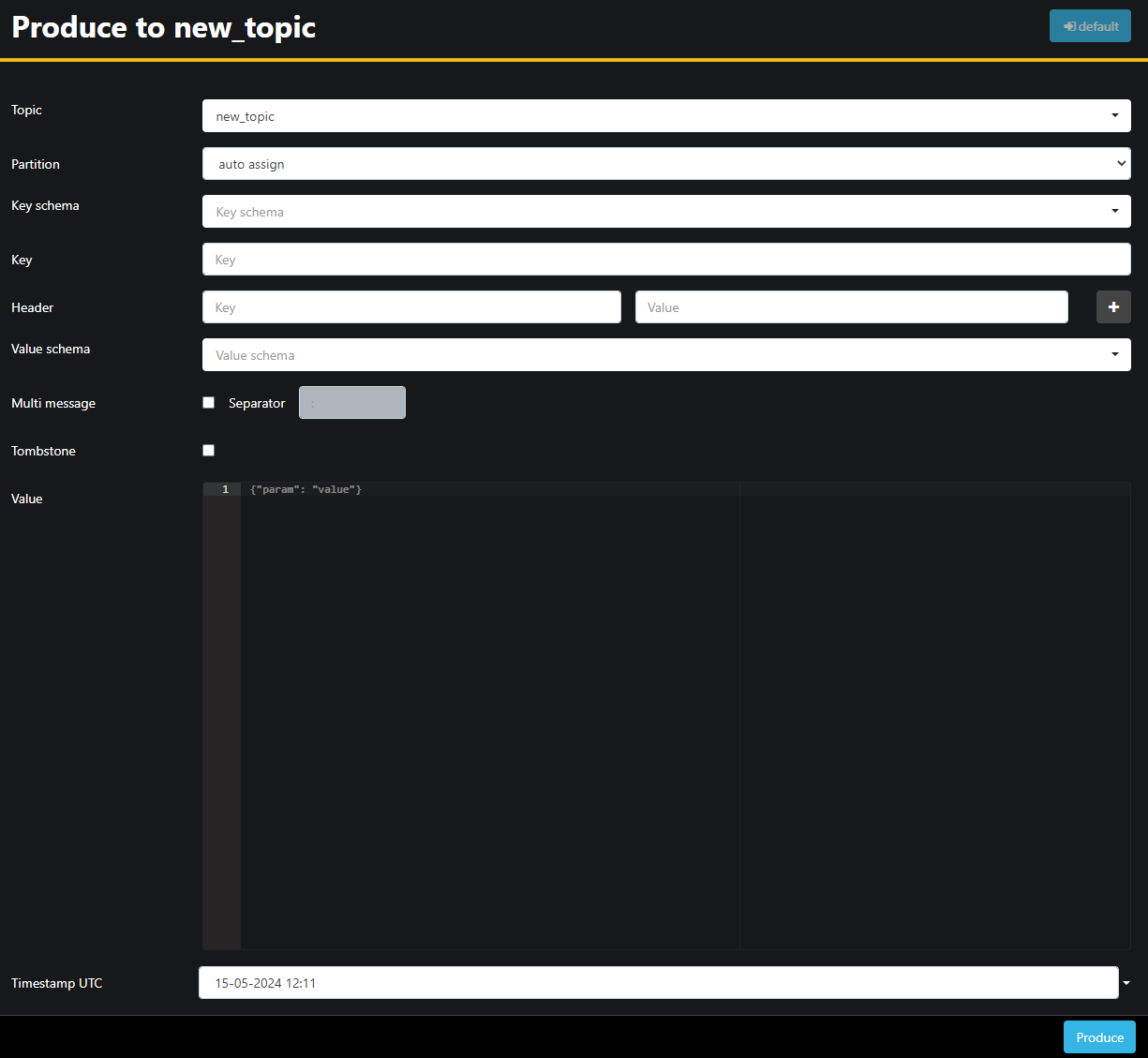
AKHQは自動的にトピック名を入力します。Value字段にHello World!を入力し、そしてProduceを押します。メッセージはKafkaに送信され、Dataタブで見ることができます:
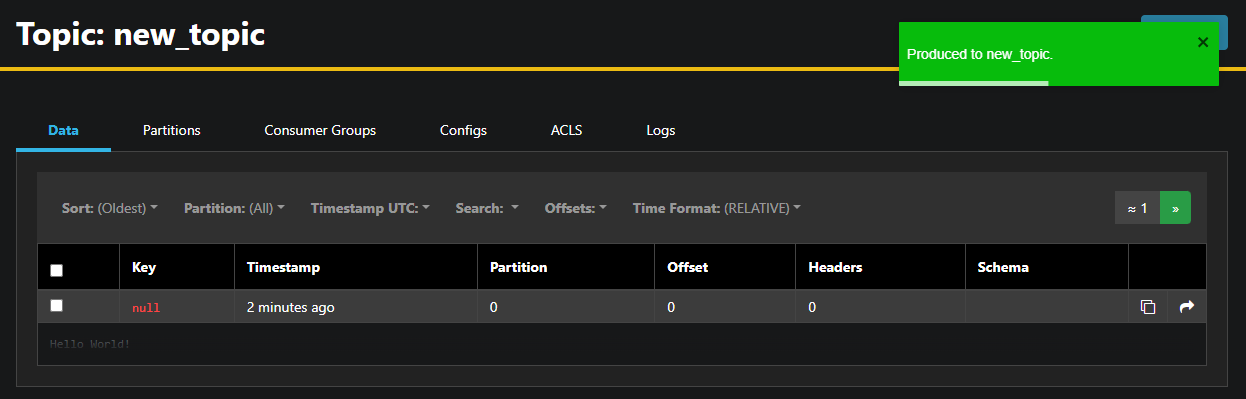
メッセージの内容が大きい場合、AKHQは最初の行しか表示しません。完全なメッセージを表示するには、行の暗闇部分を押して表示させます。
左のサイドバーから、Nodesを押してクラスタ内のブローカーを一覧表示することもできます。現在、クラスタには1つのノードしか含まれていません:

ノードをダブルクリックすることで、その設定を远处から変更することができる構成を開きます。
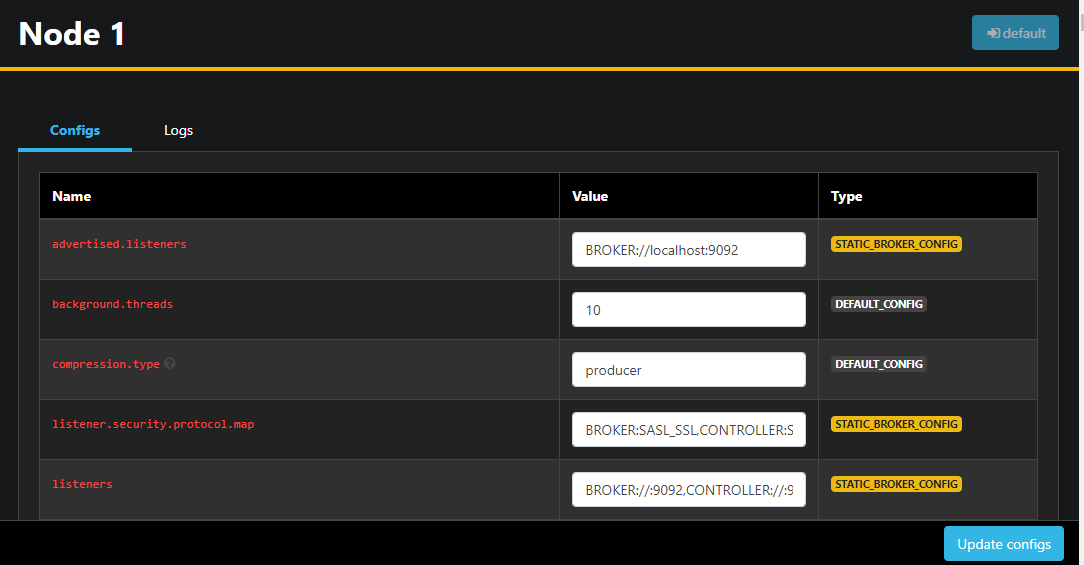
変更を行った後、右下の更新設定ボタンを押すことでそれらを適用することができます。同様に、任意のトピックの設定を表示したり修正したりするには、それにアクセスして設定タブに切り替えることができます。
この節では、Kafkaノードとトピックをリモートから管理し、監視するための簡単易用のUIを提供しているWebアプリAKHQを設定しました。これにより、トピックやノードの設定パラメータを即座にプロデュースしたり、コンシューマしたり、更新することができます。
結び
このチュートリアルでは、KafkaのインストールをTLSで暗号化、SASLでユーザー認証を設定することで保護しました。そして、Prometheusを使用した指標のエクスポートを設定し、Grafanaに基づいて視覚化しました。その後、Kafkaクラスターを管理するためのWebアプリAKHQの使用方法を学びました。
著者はApache Software FoundationにWrite for DOnationsプログラムの一部として寄付を受け取ることを選びました。
Source:
https://www.digitalocean.com/community/developer-center/how-to-secure-and-monitor-kafka