













導入
コンテナを管理するためにKubernetesを採用する組織は、分散システムの健康状態を監視するソリューションが必要です。そのために、Prometheusが登場します。これは、K8sスペース内のコンテナ化されたアプリケーションを監視する強力なオープンソースツールです。
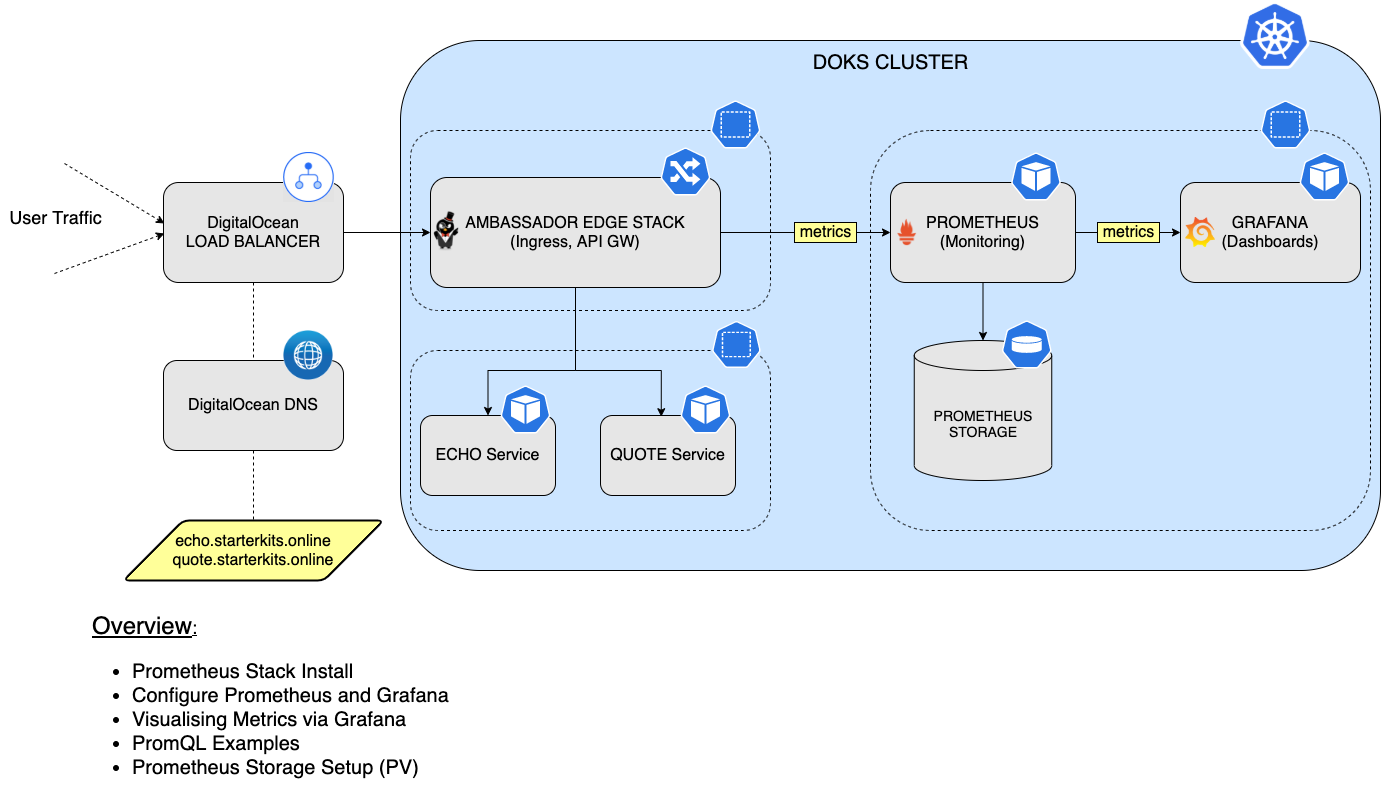
このチュートリアルでは、Prometheusスタックをインストールして構成し、DOKSクラスターからすべてのポッド、およびKubernetesクラスターの状態メトリクスを監視する方法を学びます。その後、PrometheusをGrafanaと接続してすべてのメトリクスを視覚化し、PromQL言語を使用してクエリを実行します。最後に、Prometheusインスタンスの永続ストレージを構成して、DOKSクラスターとアプリケーションのすべてのメトリクスデータを永続化します。
目次
- 前提条件
- ステップ1 – Prometheusスタックのインストール
- ステップ2 – PrometheusとGrafanaの構成
- ステップ3 – PromQL(Prometheusクエリ言語)
- ステップ4 – Grafanaを使用したメトリクスの視覚化
- ステップ5 – Prometheusの永続ストレージの設定
- ステップ6 – Grafanaの永続ストレージの設定
- 結論
前提条件
このチュートリアルを完了するには、次が必要です:
- A Git client to clone the Starter Kit repository.
- Helm:Prometheusスタックのリリースとアップグレードを管理します。
- Kubectl:Kubernetesとのやり取りに使用します。
- Curl:例(バックエンドアプリケーション)のテストに使用します。
- Emojivotoサンプルアプリ:クラスターに展開されています。そのリポジトリのREADMEに従ってください。
kubectlのコンテキストがKubernetesクラスターを指すように構成されていることを確認してください。DOKSセットアップチュートリアルのステップ3 – DOKSクラスターの作成を参照してください。
ステップ1 – Prometheusスタックのインストール
このステップでは、Kubernetes用の意見の分かれる完全な監視スタックであるkube-prometheusスタックをインストールします。これには、Prometheus Operator、kube-state-metrics、事前に構築されたマニフェスト、Node Exporters、Metrics API、Alerts Manager、およびGrafanaが含まれています。
このタスクを完了するためにHelmパッケージマネージャを使用します。 Helmチャートはこちらで入手できます。
まず、Starter Kitリポジトリをクローンし、ディレクトリをローカルコピーに変更します。
次に、Helmリポジトリを追加し、利用可能なチャートをリストします:
出力は次のようになります:
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 0.18.1 v0.23.0 The Alertmanager handles alerts sent by client ...
prometheus-community/kube-prometheus-stack 35.5.1 0.56.3 kube-prometheus-stack collects Kubernetes manif...
...
興味のあるチャートは、クラスタにPrometheus、Promtail、Alertmanager、およびGrafanaをインストールするprometheus-community/kube-prometheus-stackです。このチャートの詳細については、kube-prometheus-stackページをご覧ください。
次に、お好みのエディターを使用して、Starter Kit リポジトリ内の 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml ファイルを開いて検査します(可能であれば、YAML リントのサポートがあるエディターが望ましいです)。デフォルトでは、kubeSched および etcd のメトリクスは無効になっています。これらのコンポーネントは DOKS によって管理されており、Prometheus からアクセスできません。ストレージは emptyDir に設定されています。これは、Prometheus ポッドが再起動すると ストレージが消えることを意味します(後で Prometheus の永続ストレージを設定するセクションでこれを修正します)。
[オプション] もし、DigitalOcean Managed Kubernetes Cluster ガイドの ステップ 4 – 監視用に専用ノードを追加するに従った場合、Starter Kit リポジトリ内の 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml ファイルを編集し、Grafana と Prometheus の両方の affinity セクションのコメントを解除する必要があります。
上記構成の説明:
preferredDuringSchedulingIgnoredDuringExecution– スケジューラーはルールに一致するノードを見つけようと試みます。一致するノードが利用できない場合でも、スケジューラーは Pod をスケジュールします。preference.matchExpressions– 基準に基づいて特定のノードを一致させるために使用されるセレクター。上記の例では、スケジューラにワークロード(例:Pod)をpreferredキーとobservability値を使用してラベル付けされたノードに配置するよう指示しています。
最後に、Helmを使用してkube-prometheus-stackをインストールしてください:
A specific version of the Helm chart is used. In this case 35.5.1 was picked, which maps to the 0.56.3 version of the application (see output from Step 2.). It’s a good practice to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
次に、PrometheusスタックのHelmリリースのステータスを確認してください:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prom-stack monitoring 1 2022-06-07 09:52:53.795003 +0300 EEST deployed kube-prometheus-stack-35.5.1 0.56.3
出力は次のようになります。 STATUS列の値に注意してください – deployedと表示されるはずです。
Prometheusの利用可能なKubernetesリソースを確認してください:
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prom-stack-kube-prome-alertmanager-0 2/2 Running 0 3m3s
pod/kube-prom-stack-grafana-8457cd64c4-ct5wn 2/2 Running 0 3m5s
pod/kube-prom-stack-kube-prome-operator-6f8b64b6f-7hkn7 1/1 Running 0 3m5s
pod/kube-prom-stack-kube-state-metrics-5f46fffbc8-mdgfs 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-gcb8s 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-kc5wz 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-qn92d 1/1 Running 0 3m5s
pod/prometheus-kube-prom-stack-kube-prome-prometheus-0 2/2 Running 0 3m3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m3s
service/kube-prom-stack-grafana ClusterIP 10.245.147.83 <none> 80/TCP 3m5s
service/kube-prom-stack-kube-prome-alertmanager ClusterIP 10.245.187.117 <none> 9093/TCP 3m5s
service/kube-prom-stack-kube-prome-operator ClusterIP 10.245.79.95 <none> 443/TCP 3m5s
service/kube-prom-stack-kube-prome-prometheus ClusterIP 10.245.86.189 <none> 9090/TCP 3m5s
service/kube-prom-stack-kube-state-metrics ClusterIP 10.245.119.83 <none> 8080/TCP 3m5s
service/kube-prom-stack-prometheus-node-exporter ClusterIP 10.245.47.175 <none> 9100/TCP 3m5s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m3s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prom-stack-prometheus-node-exporter 3 3 3 3 3 <none> 3m5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prom-stack-grafana 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-prome-operator 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-state-metrics 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prom-stack-grafana-8457cd64c4 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-prome-operator-6f8b64b6f 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-state-metrics-5f46fffbc8 1 1 1 3m5s
NAME READY AGE
statefulset.apps/alertmanager-kube-prom-stack-kube-prome-alertmanager 1/1 3m3s
statefulset.apps/prometheus-kube-prom-stack-kube-prome-prometheus 1/1 3m3s
以下のリソースがデプロイされているはずです:prometheus-node-exporter、kube-prome-operator、kube-prome-alertmanager、kube-prom-stack-grafana、およびkube-state-metrics。出力は次のようになります:
その後、Grafanaに接続できます(デフォルトの資格情報:admin/prom-operator – prom-stack-values-v35.5.1ファイルを参照してください)。ローカルマシンにポートフォワーディングすることで:
default login/passwordでGrafanaを公開ネットワークに公開しないでください(例:イングレスマッピングまたはLBサービスの作成)。
Grafanaのインストールにはいくつかのダッシュボードが付属しています。 localhost:3000でウェブブラウザを開きます。そこから、ダッシュボード -> ブラウズに移動し、異なるダッシュボードを選択できます。
次の部分では、Prometheusのセットアップ方法を見ていきます。モニタリングのターゲットを検出するために、Emojivotoサンプルアプリケーションを使用します。また、ServiceMonitorについても学びます。
すでにPrometheusとGrafanaをクラスターにデプロイしました。このステップでは、ServiceMonitorの使用方法を学びます。 ServiceMonitorは、Prometheusに新しい監視対象をどのように検出するかを伝える方法の1つです。
Emojivoto Deploymentは、前提条件セクションのステップ5で作成され、デフォルトでポート8801で/metricsエンドポイントをKubernetesサービス経由で提供します。
次に、Prometheusが消費するメトリクスデータを公開するEmojivotoサービスを見つけます。対象となるサービスはemoji-svcとvoting-svcです(emojivotoネームスペースを使用していることに注意してください):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emoji-svc ClusterIP 10.245.135.93 <none> 8080/TCP,8801/TCP 22h
voting-svc ClusterIP 10.245.164.222 <none> 8080/TCP,8801/TCP 22h
web-svc ClusterIP 10.245.61.229 <none> 80/TCP 22h
出力は次のようになります:
次に、メトリクスを検査するためにport-forwardを実行します。
公開されたメトリクスは、Webブラウザでlocalhostに移動するか、curlを使用して次のように表示できます:
出力は次のように見えます:
go_gc_duration_seconds{quantile="0"} 5.317e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105305
go_gc_duration_seconds{quantile="0.5"} 0.000138168
go_gc_duration_seconds{quantile="0.75"} 0.000225651
go_gc_duration_seconds{quantile="1"} 0.016986437
go_gc_duration_seconds_sum 0.607979843
go_gc_duration_seconds_count 2097
# TYPE go_gc_duration_seconds summary
voting-svcサービスのメトリクスを検査するには、emoji-svcのポート転送を停止し、2番目のサービスに対して同じ手順を実行します。
- 次に、PrometheusをEmojivotoメトリクスサービスに接続します。これにはいくつかの方法があります:
- <static_config> – ターゲットのリストとそれらの共通のラベルセットを指定することができます。
- <kubernetes_sd_config> – KubernetesのREST APIからスクレイプターゲットを取得し、常にクラスターの状態と同期を取ることができます。
Prometheus Operator – CRDを介してKubernetesクラスター内でのPrometheusモニタリングを簡素化します。
次に、Prometheus Operatorによって公開されたServiceMonitorCRDを使用して、新しいモニタリングターゲットを定義します。
まず、Starter Kit Gitリポジトリがクローンされているディレクトリに移動します(すでに移動していない場合)。
次に、選択したテキストエディタ(可能であればYAMLリントサポート付き)を使用して、スターターキットリポジトリ内の04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yamlファイルを開きます。提供されたコメントを、additionalServiceMonitorsセクションの周囲から削除してください。出力は以下のようになります:
- 上記構成の説明:
selector -> matchExpressions–ServiceMonitorに監視対象のサービスを教えます。この設定では、ラベルキーがappで値がemoji-svcおよびvoting-svcであるすべてのサービスが対象となります。ラベルは次のコマンドを実行して取得できます:kubectl get svc --show-labels -n emojivotonamespaceSelector– ここでは、Emojivotoが展開された名前空間と一致させたいです。
endpoints -> port – 監視対象のサービスのポートを参照します。
最後に、Helmを使用して変更を適用します:
次に、Prometheusのスクレイピング対象にEmojivotoターゲットが追加されているかどうかを確認してください。ポート9090でPrometheusのポートフォワードを作成します:
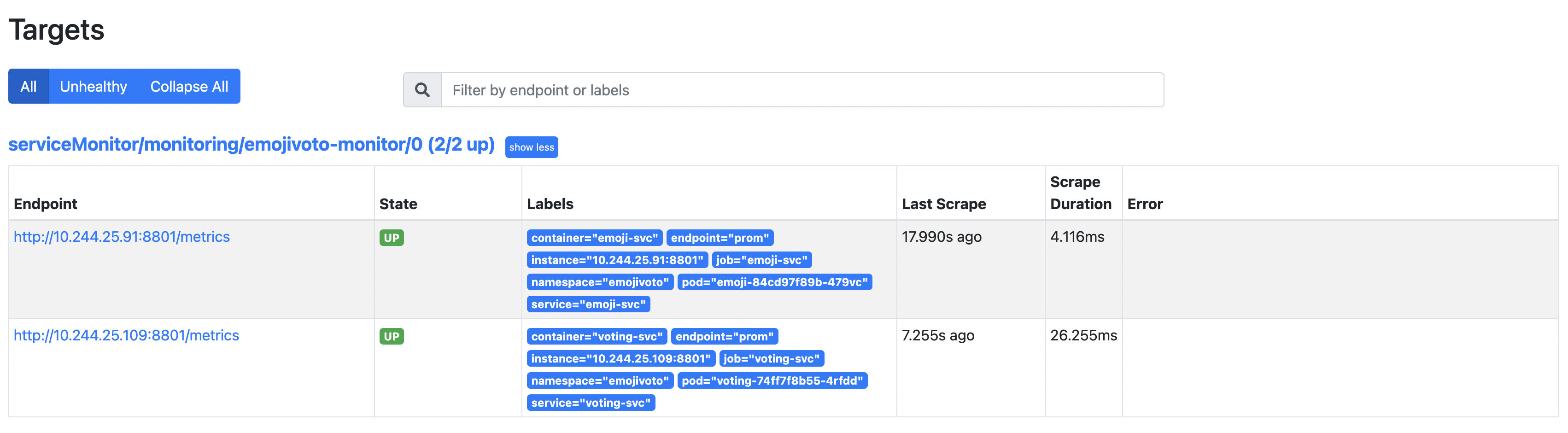
localhost:9090でウェブブラウザを開きます。次に、Status -> Targetsページに移動し、結果を確認します(serviceMonitor/monitoring/emojivoto-monitor/0パスに注意してください):
Emojivoto展開はメトリクスエンドポイントを公開する2つのサービスで構成されているため、発見されたターゲットの数は2件です。
次のステップでは、いくつかの簡単な例とともに、PromQL(Prometheusクエリ言語)を発見し、その言語を学びます。
ステップ3 – PromQL(Prometheusクエリ言語)
このステップでは、Prometheusクエリ言語(PromQL)の基礎を学びます。 PromQLを使用すると、DOKSクラスターからのすべてのPodやアプリケーションからのさまざまなメトリクスに対するクエリを実行できます。
PromQLは、Prometheus用に特別に構築されたDSL(Domain Specific Language)であり、メトリクスをクエリすることができます。 全体の式は最終値を定義し、ネストされた式は引数とオペランドの値を表します。 より詳細な説明については、公式のPromQLページをご覧ください。
次に、Emojivotoメトリクスの1つ、つまりemojivoto_votes_totalを調査します。 これは、総投票数を表すカウンター値であり、Emojivoto投票エンドポイントへの各リクエストごとに増加します。
まず、Prometheusのポート9090にポートフォワードを作成します。
次に、式ブラウザを開きます。
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 20
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
クエリ入力フィールドにemojivoto_votes_totalを貼り付け、Enterキーを押します。 出力は次のようになります:
Emojivotoアプリケーションに移動し、ホームページから100の絵文字をクリックして投票します。
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
ステップ3のクエリ結果ページに移動し、実行ボタンをクリックします。100の絵文字のカウンターが1つ増えるのを確認できます。出力は次のようになります:
PromQLは、ベクトルと呼ばれる類似したデータをグループ化します。上記のように、各ベクトルにはお互いに異なる属性のセットがあります。興味のある属性に基づいて結果をグループ化できます。たとえば、voting-svcサービスからのリクエストのみに関心がある場合は、クエリフィールドに次のように入力してください:
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 492
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 532
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 521
出力は次のようになります(自分の基準に一致する結果のみが選択されることに注意してください):
上記の結果は、メトリクスを送信するEmojivoto展開から各Podの合計リクエストを示しています(これには2つのメトリクスが含まれます)。
これは、PromQLが何であり、何ができるかの非常に単純な紹介です。しかし、これだけではなく、メトリクスのカウント、事前定義された間隔でのレートの計算などができます。言語のさらなる機能については公式のPromQLページをご覧ください。
次のステップでは、Grafanaを使用してEmojivotoサンプルアプリケーションのメトリクスを可視化する方法を学びます。
Prometheusにはデータを可視化するためのいくつかの組み込みサポートがありますが、それよりも優れた方法は、監視および可観測性のためのオープンソースプラットフォームであるGrafanaを使用することです。これにより、クラスターの状態を視覚化および探索できます。
公式ページには、次のように記載されています:
データをクエリ、視覚化、アラート、理解することができます。データがどこに保存されているかにかかわらず。
Grafanaをインストールするための追加の手順は不要です。なぜなら、ステップ1 – PrometheusスタックのインストールがGrafanaをインストールしてくれたからです。以下のようにポートフォワードを行うだけで、ダッシュボードに直接アクセスできます(デフォルトの資格情報:admin/prom-monitor):
Emojivotoメトリクス全体を表示するには、Grafanaからデフォルトでインストールされているダッシュボードの1つを使用します。
Grafanaダッシュボードセクションに移動します。
次に、General/Kubernetes/Compute Resources/Namespace(Pods)ダッシュボードを検索してアクセスします。
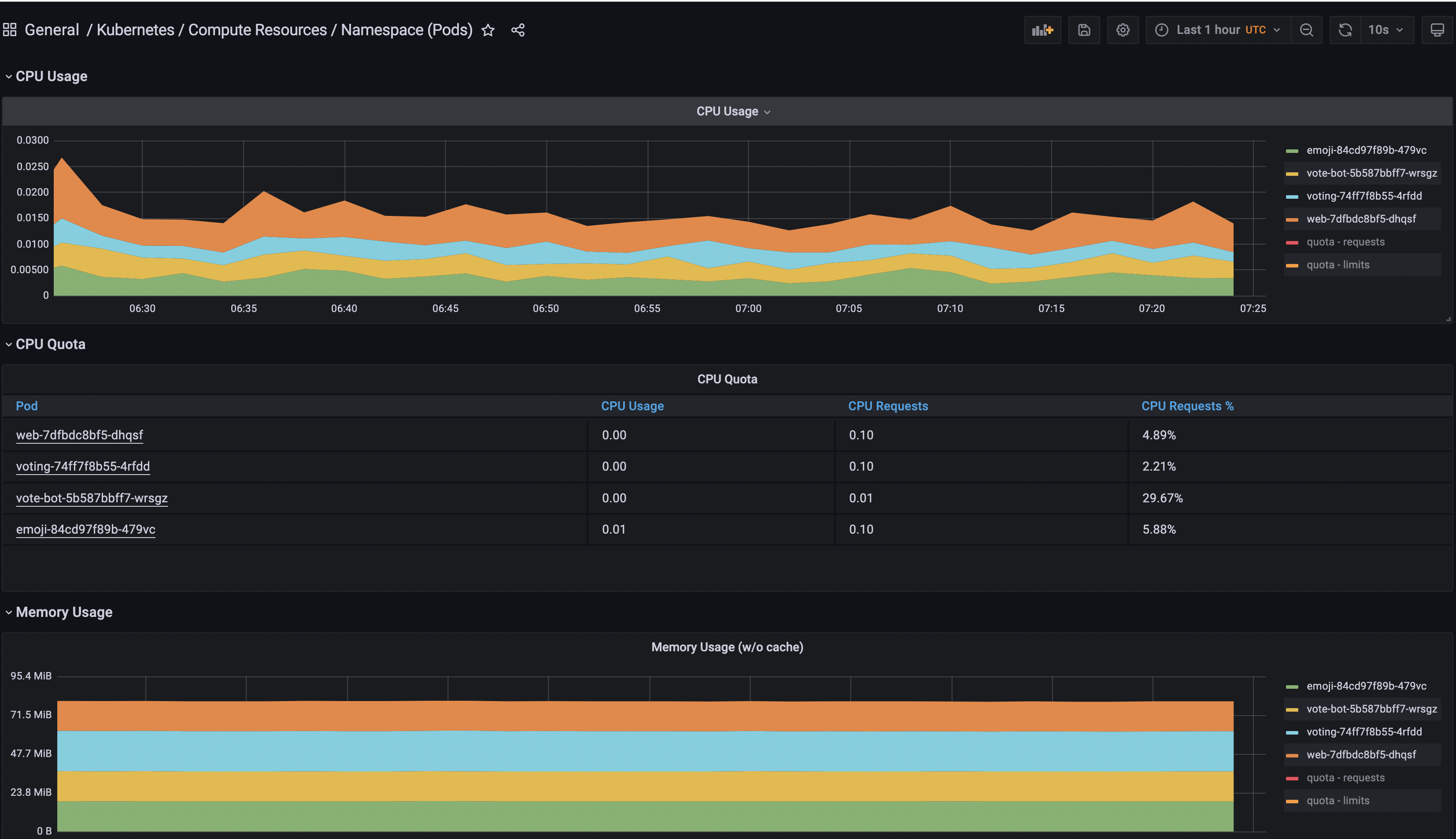
最後に、Prometheusデータソースを選択し、emojivotoネームスペースを追加します。
Grafanaの別のデータソースを可視化するために、パネルを追加したり、スコープに基づいてグループ化したりすることができます。また、Grafanaのkube-mixinプロジェクトからKubernetes用の利用可能なダッシュボードを探索することもできます。
次に、DOKSおよびアプリケーションのメトリクスをサーバーの再起動やクラスターの障害に関係なく永続化するために、Prometheusの永続ストレージを設定します。
このステップでは、Prometheusの永続ストレージを有効にして、メトリクスデータがサーバーの再起動時やクラスターの障害発生時に永続化される方法を学びます。
まず、進行するためにストレージクラスが必要です。次のコマンドを実行して利用可能なものを確認します。
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 4d2h
出力は次のようになります。DigitalOcean Block Storageが使用可能であることに注意してください。
次に、Starter Kit Gitリポジトリがクローンされたディレクトリに移動します(すでに移動していない場合)。
次に、適切なテキストエディター(できればYAML lintサポート付き)を使用して、スターターキットリポジトリ内の 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml ファイルを開きます。 storageSpec 行を検索し、Prometheus に必要なセクションのコメントを解除します。 storageSpec の定義は次のようになります:
- 上記構成の説明:
volumeClaimTemplate– 新しい PVC を定義します。storageClassName– ストレージクラスを定義します(kubectl get storageclassコマンドの出力と同じ値を使用する必要があります)。
resources – ストレージのリクエスト値を設定します。この場合、新しいボリュームには合計5 Gi の容量が要求されます。
最後に、Helm を使用して設定を適用します:
上記の手順を完了したら、PVC のステータスを確認します:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prome-prometheus-0 Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

出力は次のようになります。 STATUS 列には Bound が表示されるはずです。
このステップでは、Grafanaの永続ストレージを有効にして、グラフがサーバーの再起動時やクラスターの障害発生時でも維持されるようにします。DigitalOcean Block Storageを使用して、5 Giの永続ボリュームクレーム(PVC)を定義します。次のステップは、ステップ5 – Prometheusの永続ストレージの構成と同じです。
まず、提供されたStarter Kitリポジトリ内の04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yamlファイルをテキストエディターで開きます(可能であればYAMLリントサポート付きのものを選択してください)。Grafanaの永続ストレージセクションは次のようになります:
次に、Helmを使用して設定を適用します:
上記の手順を完了したら、PVCの状態を確認します:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prom-stack-grafana Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

出力は次のようになります。STATUS列にはBoundが表示されます。
- 必要なボリュームのサイズを計算するために、公式ドキュメントのアドバイスと以下の式に従ってください:
- Prometheusは、サンプルあたり平均1〜2バイトしか保存しません。したがって、Prometheusサーバーの容量を計画するためには、次のおおまかな式を使用できます。
必要なディスク容量 = 保持時間(秒)× 1秒あたりの取り込まれるサンプル数 × サンプルあたりのバイト数
取り込まれるサンプルのレートを下げるには、スクレイプする時間系列の数を減らす(ターゲットの数を減らすか、ターゲットあたりの系列数を減らす)か、スクレイプ間隔を増やすことができます。ただし、系列数を減らす方が、系列内のサンプルの圧縮により効果的です。