













免責事項:ブログで表明されたすべての意見や見解は、著者個人のものであり、必ずしも著者の雇用主や他のグループや個人の意見を反映するものではありません。この記事は、いかなるクラウド/データ管理プラットフォームのプロモーションでもありません。すべての画像やAPIはAzure/Databricksのウェブサイトで公開されています。。
Databricks Lakehouse Monitoringとは何ですか?
私の他の記事では、DatabricksやUnity Catalogとは何か、スクリプトを使用してカタログをゼロから作成する方法について説明しました。この記事では、Databricksプラットフォームの一部として利用可能なLakehouse Monitoring機能と、スクリプトを使用してその機能を有効にする方法について説明します。
Lakehouse Monitoringは、Lakehouse内のDelta Live Tablesに関するデータプロファイリングおよびデータ品質関連のメトリクスを提供します。Databricks Lakehouse Monitoringは、データボリュームの変化、数値分布の変化、列内のヌルおよびゼロの%、および時間経過に伴うカテゴリアルな異常の検出など、データについて包括的な洞察を提供します。
Lakehouse Monitoringを使用する理由は?
データおよびMLモデルのパフォーマンスを監視することで、データおよびモデルの品質と一貫性を時間の経過とともに追跡および確認するのに役立つ定量的な指標が得られます。
以下は、主な特徴の詳細です:
- データ品質とデータ整合性の追跡:データのパイプライン全体でのデータの流れを追跡し、データの整合性を確保し、データが時間の経過とともにどのように変化したかについて可視性を提供します。数値列の90パーセンタイル、ヌルおよびゼロ列の割合など。
- 時間の経過とともにデータのドリフト:現在のデータと既知のベースライン、またはデータの連続した時間ウィンドウ間のデータのドリフトを検出するためのメトリクスを提供します。
- データの統計的分布:時間の経過とともにデータの数値分布の変化を提供し、カテゴリカル列の値の分布が何であるか、過去とどのように異なるかに答えます。
- MLモデルのパフォーマンスと予測のドリフト:時間の経過とともにMLモデルの入力、予測、およびパフォーマンストレンドを提供します。
動作原理
Databricks Lakehouse Monitoringでは、次の種類の分析が提供されます:時系列、スナップショット、および推論。
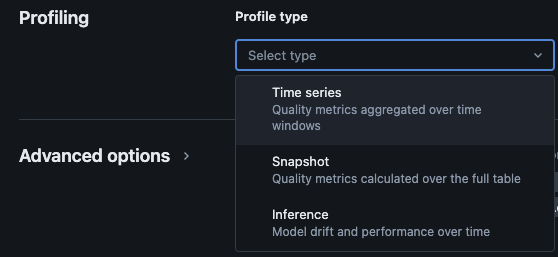
監視用のプロファイルタイプ
UnityカタログでテーブルのLakehouseモニタリングを有効にすると、指定されたモニタリングスキーマに2つのテーブルが作成されます。データの統計情報やプロファイル情報を時間経過と共に包括的に取得するために、これらのテーブルにクエリを実行し、ダッシュボードを作成できます(Databricksはデフォルトで設定可能なダッシュボードを提供します)。
- ドリフトメトリクステーブル:ドリフトメトリクステーブルには、データの時間経過に伴うドリフトに関連する統計情報が含まれます。カウントの違い、平均値の違い、% nullおよびゼロの違いなどの情報を収集します。
- プロファイルメトリクステーブル:プロファイルメトリクステーブルには、各列と時間ウィンドウ、スライス、およびグループ化列の組み合わせごとの要約統計が含まれます。InferenceLog分析の場合、分析テーブルにはモデルの精度メトリクスも含まれます。
スクリプトを使用してLakehouseモニタリングを有効にする方法
前提条件
- Unityカタログ、スキーマ、およびDelta Liveテーブルが存在すること。
- ユーザーがDelta Liveテーブルの所有者であること。
- プライベートAzure Databricksクラスターの場合、サーバーレスコンピュートからのプライベート接続が構成されていること。
ステップ1:ノートブックを作成し、Databricks SDKをインストールします。
Databricksワークスペースにノートブックを作成します。ワークスペースにノートブックを作成するには、サイドバーの”+”をクリックして、新規を選択し、その後ノートブックを選択します。
空白のノートブックがワークスペースに開きます。ノートブックの言語としてPythonが選択されていることを確認してください。
以下のコードスニペットをノートブックセルにコピーして貼り付け、セルを実行します。
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
ステップ2:変数を作成する
以下のコードスニペットをノートブックセルにコピーして貼り付け、セルを実行します。
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
ステップ3:モニタリングスキーマを作成する
以下のコードスニペットをノートブックセルにコピーして貼り付け、セルを実行します。このスニペットは、モニタリングスキーマがまだ存在しない場合に作成します。
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
ステップ4:モニタを作成する
以下のコードスニペットをノートブックセルにコピーして貼り付け、セルを実行します。このスニペットは、スキーマ内のすべてのテーブルに対してLakehouseモニタリングを作成します。
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
検証
スクリプトが正常に実行された後、カタログ -> スキーマ -> テーブルに移動し、テーブルの”品質“タブに移動してモニタリングの詳細を表示できます。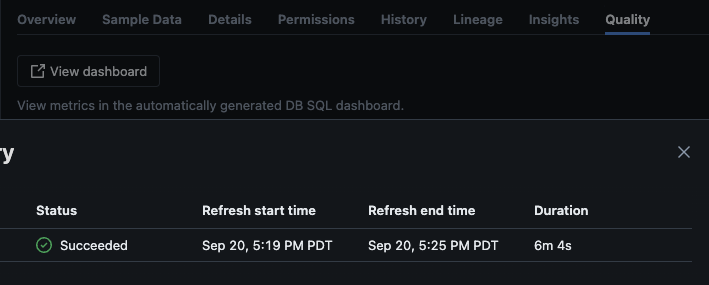
“ダッシュボードを表示“ボタンをクリックすると、モニタリングページの左上隅にデフォルトのモニタリングダッシュボードが開きます。最初はデータが空白になります。モニタリングがスケジュールで実行されると、時間の経過とともにすべての統計値、プロファイル、データ品質の値が表示されます。
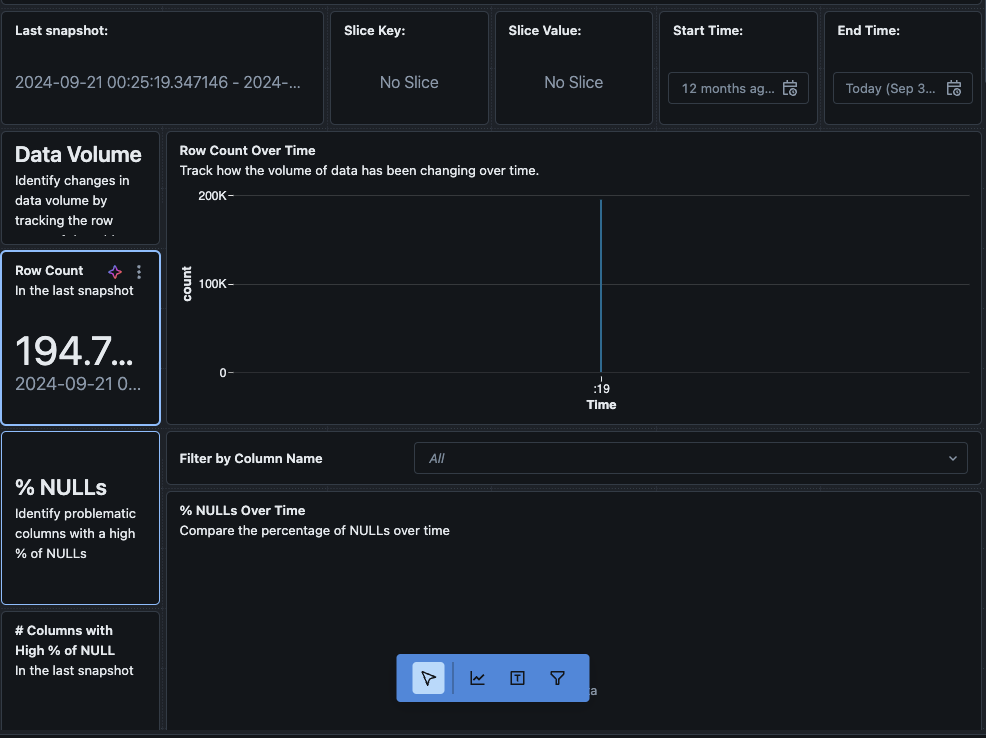
また、ダッシュボードの”データ“タブに移動することもできます。Databricksは、ドリフトやその他のプロファイル情報を取得するためのクエリのリストを提供しています。必要に応じて独自のクエリを作成して、データの時間経過にわたる包括的なビューを取得することもできます。
結論
Databricks Lakehouse モニタリングは、データ品質、プロファイルメトリクスの追跡、および時間の経過に伴うデータのドリフトの検出を行うための構造化された手段を提供します。この機能をスクリプトを介して有効にすることで、チームはデータの動作を把握し、データパイプラインの信頼性を確保することができます。本記事で説明したセットアッププロセスは、データの整合性を維持し、継続的なデータ分析の取り組みをサポートするための基盤を提供しています。
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring