













著者は、フリー・アンド・オープンソース基金を、寄付のための執筆プログラムの一環として寄付先に選びました。
はじめに
データベースの監視は、データベースのパフォーマンスを示すさまざまなメトリクスを系統的に追跡する連続的なプロセスです。パフォーマンスデータを観察することで、貴重な洞察を得ることができ、ボトルネックの可能性を特定し、データベースのパフォーマンスを改善する追加の方法を見つけることができます。このようなシステムでは、通常、何かがうまくいかない場合に管理者に通知するアラート機能が実装されています。収集された統計情報は、データベースの構成やワークフローを改善するだけでなく、クライアントアプリケーションのそれらも改善するために使用できます。
Elastic Stack (ELK スタック)を使用する利点は、優れた検索サポートと新しいデータの迅速な取り込み能力です。データの更新には優れていませんが、これは過去のデータがほとんど変更されない監視とログ記録の目的には受け入れられるトレードオフです。 Elasticsearch は、データの強力なクエリ手段を提供し、これを使用してデータベースのさまざまな時間帯での動作をよりよく理解するために Kibana を介して利用できます。これにより、データベースの負荷と実際のイベントを相関させ、データベースの使用状況を把握できます。
このチュートリアルでは、Redis INFO コマンドによって生成されたデータベースメトリクスを Logstash を介して Elasticsearch にインポートします。これには、Logstash を定期的にコマンドを実行し、その出力を解析し、すぐに Elasticsearch にインデックス登録するように構成する必要があります。後でインポートされたデータは、Kibana で分析および視覚化できます。チュートリアルの最後には、Redis 統計を自動的に取得するシステムが完成します。
前提条件
- Ubuntu 18.04サーバーが少なくとも8 GBのRAM、ルート権限、およびセカンダリーの非ルートアカウントで構成されています。これは、この初期サーバー設定ガイドに従って設定できます。このチュートリアルでは、非ルートユーザーは
sammyです。 - サーバーにJava 8がインストールされています。インストール手順については、Ubuntu 18.04にJavaを
aptでインストールする方法を参照し、最初のステップに概説されたコマンドに従います。Java開発キット(JDK)をインストールする必要はありません。 - サーバーにNginxがインストールされています。その手順については、Ubuntu 18.04にNginxをインストールする方法のチュートリアルを参照してください。
- サーバーにElasticsearchとKibanaがインストールされています。最初の2つのステップを完了します。Ubuntu 18.04にElasticsearch、Logstash、およびKibana(Elastic Stack)をインストールする方法のチュートリアル。
- A Redis managed database provisioned from DigitalOcean with connection information available. Make sure that your server’s IP address is on the whitelist. For a guide on creating a Redis database using the DigitalOcean Control Panel, visit the Redis Quickstart guide.
- サーバーにRedliがインストールされています。これは、Ubuntu 18.04で管理されたデータベースに接続する方法のチュートリアルに従っています。
ステップ1 — Logstashのインストールと設定
このセクションでは、Logstashをインストールし、Redisデータベースクラスターから統計を取得し、それをElasticsearchに送信してインデックス化するように設定します。
まず、次のコマンドでLogstashをインストールします:
Logstashをインストールしたら、次のコマンドでサービスを自動起動に設定します:
統計を取得するためにLogstashを構成する前に、データ自体がどのように見えるかを確認しましょう。 Redisデータベースに接続するには、管理されたデータベースコントロールパネルに移動し、接続の詳細パネルから、ドロップダウンメニューからフラグを選択します:
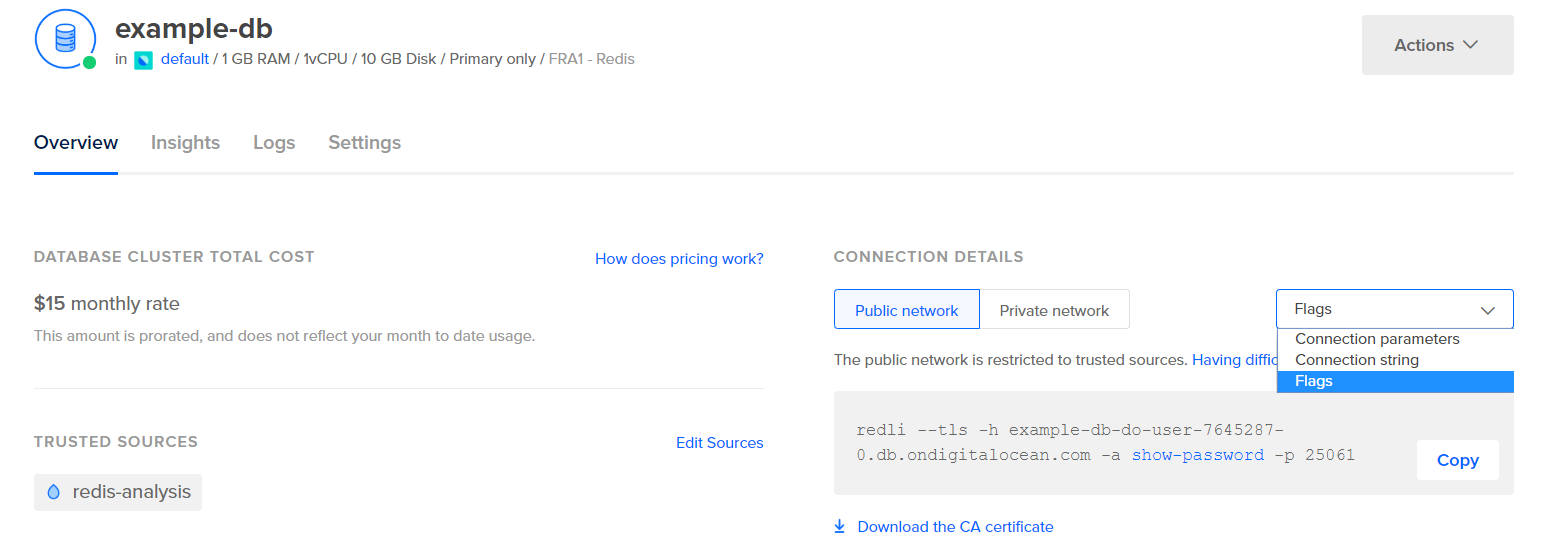
データベースに接続するための事前に構成されたRedliクライアントのコマンドが表示されます。 コピーをクリックして、次のコマンドをサーバーで実行します。コピーしたコマンドでredli_flags_commandを置き換えます:
このコマンドの出力が長いため、それを異なるセクションに分割して説明します。
Redis infoコマンドの出力では、セクションは#でマークされ、これはコメントを示します。値はkey:valueの形式で埋められるため、比較的解析しやすくなります。
Serverセクションには、Redisビルドのバージョンやそれが基づいているGitコミットなどの技術情報が含まれています。一方、Clientsセクションでは、現在開かれている接続の数が提供されます。
Output# Server
redis_version:6.2.6
redis_git_sha1:4f4e829a
redis_git_dirty:1
redis_build_id:5861572cb79aebf3
redis_mode:standalone
os:Linux 5.11.12-300.fc34.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
atomicvar_api:atomic-builtin
gcc_version:11.2.1
process_id:79
process_supervised:systemd
run_id:b8a0aa25d8f49a879112a04a817ac2acd92e0c75
tcp_port:25060
server_time_usec:1640878632737564
uptime_in_seconds:1679
uptime_in_days:0
hz:10
configured_hz:10
lru_clock:13488680
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
io_threads_active:0
# Clients
connected_clients:4
cluster_connections:0
maxclients:10032
client_recent_max_input_buffer:24
client_recent_max_output_buffer:0
...
Memoryセクションでは、Redisが自身に割り当てたRAMの量や、可能な限り使用できる最大のメモリ量が確認されます。メモリが不足してきた場合、制御パネルで指定した戦略を使用してキーを解放します(この出力のmaxmemory_policyフィールドに表示されます)。
Output...
# Memory
used_memory:977696
used_memory_human:954.78K
used_memory_rss:9977856
used_memory_rss_human:9.52M
used_memory_peak:977696
used_memory_peak_human:954.78K
used_memory_peak_perc:100.00%
used_memory_overhead:871632
used_memory_startup:810128
used_memory_dataset:106064
used_memory_dataset_perc:63.30%
allocator_allocated:947216
allocator_active:1273856
allocator_resident:3510272
total_system_memory:1017667584
total_system_memory_human:970.52M
used_memory_lua:37888
used_memory_lua_human:37.00K
used_memory_scripts:0
used_memory_scripts_human:0B
number_of_cached_scripts:0
maxmemory:455081984
maxmemory_human:434.00M
maxmemory_policy:noeviction
allocator_frag_ratio:1.34
allocator_frag_bytes:326640
allocator_rss_ratio:2.76
allocator_rss_bytes:2236416
rss_overhead_ratio:2.84
rss_overhead_bytes:6467584
mem_fragmentation_ratio:11.43
mem_fragmentation_bytes:9104832
mem_not_counted_for_evict:0
mem_replication_backlog:0
mem_clients_slaves:0
mem_clients_normal:61504
mem_aof_buffer:0
mem_allocator:jemalloc-5.1.0
active_defrag_running:0
lazyfree_pending_objects:0
...
Persistenceセクションでは、Redisが保存したキーをディスクに保存した最終時刻と、保存が成功したかどうかが表示されます。 Statsセクションでは、クライアントとクラスター内の接続に関連する数値、リクエストされたキーが見つかった(または見つからなかった)回数などが提供されます。
Output...
# Persistence
loading:0
current_cow_size:0
current_cow_size_age:0
current_fork_perc:0.00
current_save_keys_processed:0
current_save_keys_total:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1640876954
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:1
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:217088
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
module_fork_in_progress:0
module_fork_last_cow_size:0
# Stats
total_connections_received:202
total_commands_processed:2290
instantaneous_ops_per_sec:0
total_net_input_bytes:38034
total_net_output_bytes:1103968
instantaneous_input_kbps:0.01
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
expire_cycle_cpu_milliseconds:29
evicted_keys:0
keyspace_hits:0
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:452
total_forks:1
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
tracking_total_keys:0
tracking_total_items:0
tracking_total_prefixes:0
unexpected_error_replies:0
total_error_replies:0
dump_payload_sanitizations:0
total_reads_processed:2489
total_writes_processed:2290
io_threaded_reads_processed:0
io_threaded_writes_processed:0
...
Replicationの下のroleを見ることで、プライマリまたはレプリカノードに接続されているかどうかがわかります。セクションの残りの部分では、現在接続されているレプリカの数と、プライマリに対してレプリカが欠けているデータの量が提供されます。接続しているインスタンスがレプリカである場合、追加のフィールドがあるかもしれません。
注意: Redisプロジェクトでは、ドキュメントやさまざまなコマンドで「マスター」と「スレーブ」という用語を使用しています。DigitalOceanでは一般的に「プライマリ」と「レプリカ」という代替用語を好みます。このガイドでは可能な限り「プライマリ」と「レプリカ」という用語をデフォルトで使用しますが、「マスター」と「スレーブ」という用語が不可避に現れる場合もあることに注意してください。
Output...
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:f727fad3691f2a8d8e593b087c468bbb83703af3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:45088768
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
...
CPUの下には、Redisが現在消費しているシステム(used_cpu_sys)とユーザー(used_cpu_user)のCPUパワーの量が表示されます。 Clusterセクションには、cluster_enabledという唯一のフィールドが含まれており、これはRedisクラスタが実行されていることを示します。
Output...
# CPU
used_cpu_sys:1.617986
used_cpu_user:1.248422
used_cpu_sys_children:0.000000
used_cpu_user_children:0.001459
used_cpu_sys_main_thread:1.567638
used_cpu_user_main_thread:1.218768
# Modules
# エラー統計
# クラスタ
cluster_enabled:0
# Keyspace
Logstashは、Redisデータベースで定期的にinfoコマンドを実行し(あなたがちょうど行ったのと同様)、結果を解析してElasticsearchに送信するように指示されます。 その後、後でKibanaからそれらにアクセスできるようになります。
Redis統計情報のインデックス設定をElasticsearchに格納するための構成ファイルは、/etc/logstash/conf.dディレクトリの下にredis.confという名前で保存されます。 Logstashはサービスとして起動されると、それらを自動的にバックグラウンドで実行します。
お気に入りのエディター(たとえばnano)を使用してredis.confを作成してください:
以下の行を追加してください:
input {
exec {
command => "redis_flags_command info"
interval => 10
type => "redis_info"
}
}
filter {
kv {
value_split => ":"
field_split => "\r\n"
remove_field => [ "command", "message" ]
}
ruby {
code =>
"
event.to_hash.keys.each { |k|
if event.get(k).to_i.to_s == event.get(k) # is integer?
event.set(k, event.get(k).to_i) # convert to integer
end
if event.get(k).to_f.to_s == event.get(k) # is float?
event.set(k, event.get(k).to_f) # convert to float
end
}
puts 'Ruby filter finished'
"
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "%{type}"
}
}
コントロールパネルで前のステップで使用したコマンドであるredis_flags_commandを置換することを忘れないでください。
inputを定義します。これは、収集されたデータで実行されるフィルターのセットであり、フィルターされたデータをElasticsearchに送信します。入力は、サーバーで定期的にcommandを実行するexecコマンド、および一定の時間間隔(秒単位)で指定するintervalが含まれます。また、Elasticsearchにインデックス化されるドキュメントタイプを定義するtypeパラメーターも指定します。 execブロックは、commandとmessageの2つのフィールドを含むオブジェクトを渡します。commandフィールドには実行されたコマンドが含まれ、messageにはその出力が含まれます。
入力から収集されたデータに順次適用される2つのフィルターがあります。kvフィルターは、キー値フィルターを表し、Logstashに組み込まれています。これは、一般的な形式のデータ(keyvalue_separatorvalue)を解析するために使用され、値およびフィールドセパレーターを指定するためのパラメーターが提供されます。フィールドセパレーターは、一般形式でフォーマットされたデータを区切る文字列に関連しています。Redis INFOコマンドの出力の場合、フィールドセパレーター(field_split)は改行であり、値セパレーター(value_split)は:です。定義された形式に従わない行は、コメントを含めて破棄されます。
kvフィルターを設定するには、value_splitパラメーターに:を渡し、field_splitパラメーターに新しい行を示す\r\nを渡します。また、remove_fieldに現在のデータオブジェクトからcommandとmessageフィールドを配列の要素として渡すことで、それらが今は無用なデータを含んでいるため、それらを削除するように指示します。
kvフィルターは、解析された値を文字列(テキスト)タイプとして表します。これは問題を引き起こします、なぜならば Kibana が実際には数値であっても文字列型を簡単に処理できないからです。これを解決するために、数値のみの文字列を数値に変換するためのカスタム Ruby コードを使用します。2つ目のフィルターは、codeパラメーターを受け入れる文字列を含むrubyブロックです。
eventはLogstashがコードに提供する変数であり、フィルターパイプライン内の現在のデータを含みます。前述のように、フィルターは一つずつ実行されるため、Ruby フィルターはkvフィルターから解析されたデータを受け取ります。Ruby コード自体はeventをハッシュに変換し、キーをトラバースし、そのキーに関連付けられた値が整数または浮動小数点数(小数点を含む数値)として表現できるかどうかを確認します。できる場合、文字列値は解析された数値に置き換えられます。ループが終了すると、進行状況を報告するメッセージ(Ruby filter finished)が出力されます。
処理されたデータは、Elasticsearchにインデックス化するために送信されます。生成されたドキュメントは、入力で定義され、パラメータとして出力ブロックに渡されるredis_infoインデックスに保存されます。
ファイルを保存して閉じます。
ステップ2 — Logstashの構成をテストする
今度は、構成をテストしてデータが適切に取得されるかを確認します。
Logstashは、-fパラメータにそのファイルパスを渡すことで特定の構成を実行することをサポートしています。以下のコマンドを実行して、前のステップで作成した新しい構成をテストします:
出力が表示されるまでに時間がかかる場合がありますが、すぐに次のようなものが表示されます:
OutputUsing bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2021-12-30 15:42:08.887 [main] runner - Starting Logstash {"logstash.version"=>"7.16.2", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2021-12-30 15:42:08.932 [main] settings - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
[INFO ] 2021-12-30 15:42:08.939 [main] settings - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
[WARN ] 2021-12-30 15:42:09.406 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2021-12-30 15:42:09.449 [LogStash::Runner] agent - No persistent UUID file found. Generating new UUID {:uuid=>"acc4c891-936b-4271-95de-7d41f4a41166", :path=>"/usr/share/logstash/data/uuid"}
[INFO ] 2021-12-30 15:42:10.985 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2021-12-30 15:42:11.601 [Converge PipelineAction::Create<main>] Reflections - Reflections took 77 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2021-12-30 15:42:12.215 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.366 [Converge PipelineAction::Create<main>] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2021-12-30 15:42:12.431 [Converge PipelineAction::Create<main>] elasticsearch - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:12.494 [[main]-pipeline-manager] elasticsearch - New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["http://localhost:9200"]}
[INFO ] 2021-12-30 15:42:12.755 [[main]-pipeline-manager] elasticsearch - Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[WARN ] 2021-12-30 15:42:12.955 [[main]-pipeline-manager] elasticsearch - Restored connection to ES instance {:url=>"http://localhost:9200/"}
[INFO ] 2021-12-30 15:42:12.967 [[main]-pipeline-manager] elasticsearch - Elasticsearch version determined (7.16.2) {:es_version=>7}
[WARN ] 2021-12-30 15:42:12.968 [[main]-pipeline-manager] elasticsearch - Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>7}
[WARN ] 2021-12-30 15:42:13.065 [[main]-pipeline-manager] kv - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2021-12-30 15:42:13.090 [Ruby-0-Thread-10: :1] elasticsearch - Using a default mapping template {:es_version=>7, :ecs_compatibility=>:disabled}
[INFO ] 2021-12-30 15:42:13.147 [Ruby-0-Thread-10: :1] elasticsearch - Installing Elasticsearch template {:name=>"logstash"}
[INFO ] 2021-12-30 15:42:13.192 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/etc/logstash/conf.d/redis.conf"], :thread=>"#<Thread:0x5104e975 run>"}
[INFO ] 2021-12-30 15:42:13.973 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.78}
[INFO ] 2021-12-30 15:42:13.983 [[main]-pipeline-manager] exec - Registering Exec Input {:type=>"redis_info", :command=>"redli --tls -h db-redis-fra1-68603-do-user-1446234-0.b.db.ondigitalocean.com -a hnpJxAgoH3Om3UwM -p 25061 info", :interval=>10, :schedule=>nil}
[INFO ] 2021-12-30 15:42:13.994 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2021-12-30 15:42:14.034 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
Ruby filter finished
Ruby filter finished
Ruby filter finished
...
Ruby filter finishedというメッセージが定期的に出力されます(前のステップで10秒に設定されています)。これは、統計情報がElasticsearchに送信されていることを意味します。
キーボードでCTRL + CをクリックしてLogstashを終了できます。前述のように、Logstashはサービスとして起動されたときに/etc/logstash/conf.dで見つかったすべての構成ファイルを自動的にバックグラウンドで実行します。それを開始するには、次のコマンドを実行します:
Logstashを実行して、Redisクラスタに接続してデータを収集できるかどうかを確認しました。次に、Kibanaでいくつかの統計データを探索します。
ステップ3 — Kibanaでのインポートされたデータの探索
このセクションでは、Kibanaでデータベースのパフォーマンスを説明する統計データを探索して可視化します。
ウェブブラウザで、前提条件の一部としてKibanaを公開したドメインに移動します。デフォルトのウェルカムページが表示されます:
LogstashがElasticsearchに送信しているデータを探索する前に、まずKibanaにredis_infoインデックスを追加する必要があります。これを行うには、まずウェルカムページから自分で探索するを選択し、次に左上隅のハンバーガーメニューを開きます。Analyticsの下に、Discoverをクリックします。
Kibanaは新しいインデックスパターンを作成するように求められます:
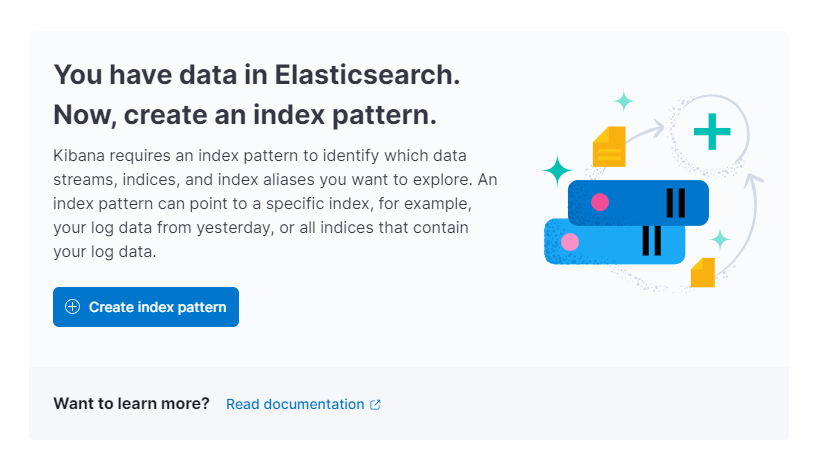
インデックスパターンを作成をクリックします。新しいインデックスパターンを作成するフォームが表示されます。Kibanaのインデックスパターンは、複数のElasticsearchインデックスからデータを一度に取り込む方法を提供し、1つのインデックスのみを探索するために使用できます。

右側には、Kibanaが使用可能なすべてのインデックスがリストされており、redis_infoなどの、Logstashで構成したものも含まれています。 名前テキストフィールドに入力し、タイムスタンプフィールドとしてドロップダウンから@timestampを選択します。完了したら、下のインデックスパターンを作成ボタンを押します。
視覚化を作成して表示するには、ハンバーガーメニューを開きます。 アナリティクスの下で、ダッシュボードを選択します。読み込みが完了したら、視覚化を作成を押して新しい視覚化を開始します:
左側のパネルには、Kibanaが視覚化に使用できる値のリストが表示され、それらは画面の中央部分に表示されます。画面の右上には、日付範囲ピッカーがあります。視覚化に@timestampフィールドが使用されている場合、Kibanaは範囲ピッカーで指定された時間間隔に属するデータのみを表示します。
ページのメイン部分のドロップダウンから、ラインをラインとエリアセクションの下で選択します。次に、左側のリストからused_memoryフィールドを見つけて、中央部分にドラッグします。すぐに時間経過に伴う使用メモリの中央値のライン視覚化が表示されます:
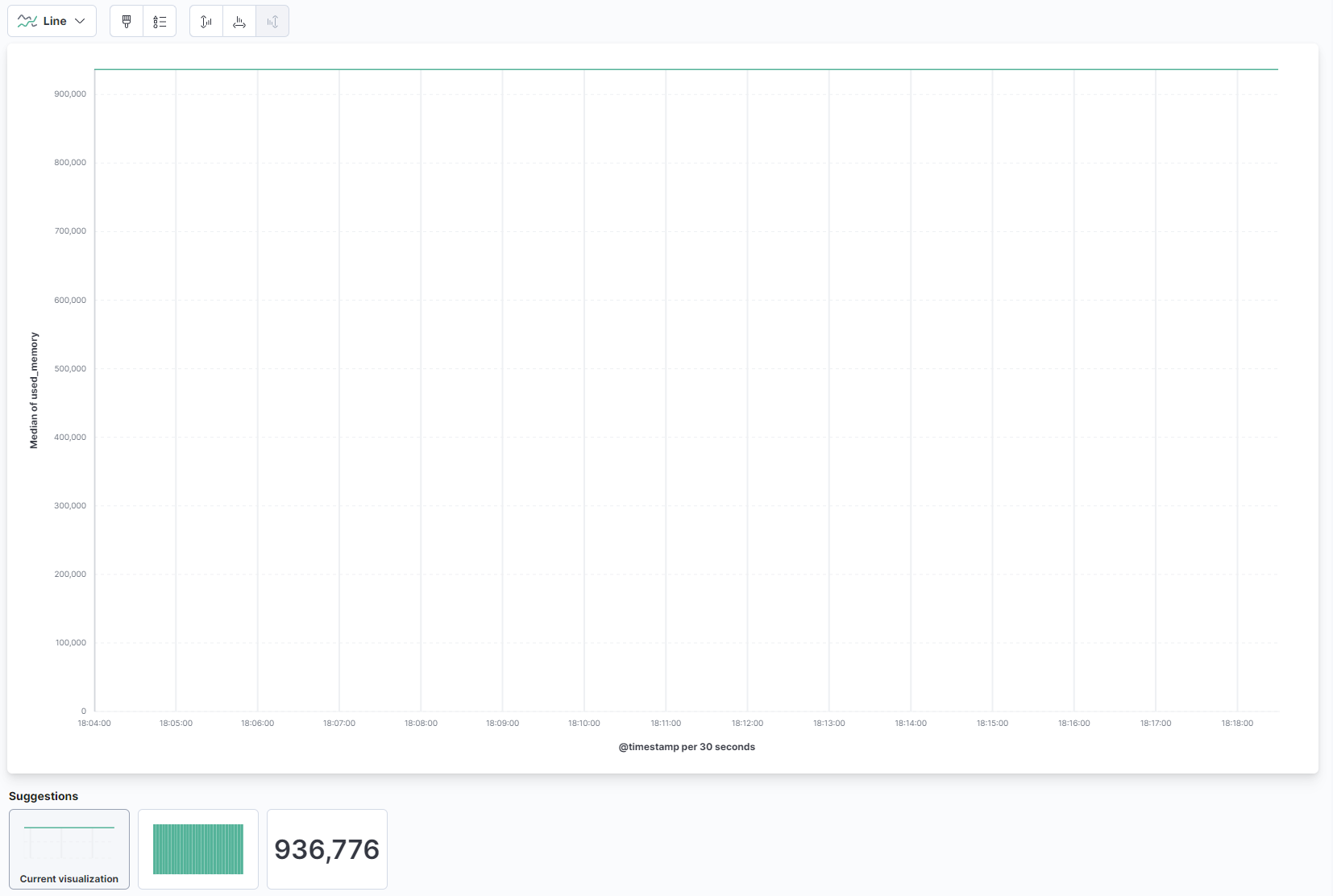
右側では、水平および垂直軸の処理方法を設定できます。そこで、表示されている軸を押して、垂直軸を中央値の代わりに平均値を表示するように設定できます:
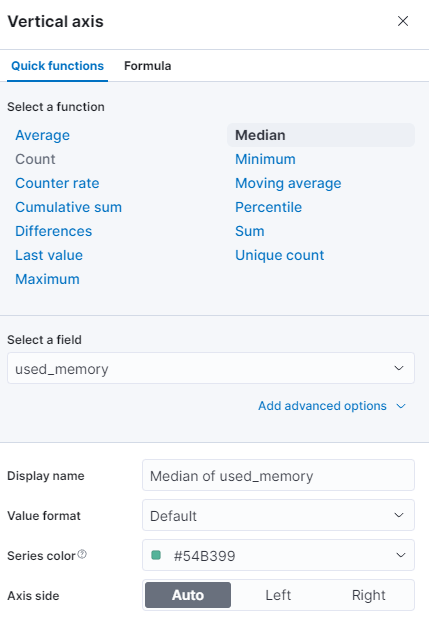
異なる関数を選択するか、独自の関数を提供できます:
グラフは、更新された値で即座にリフレッシュされます。
このステップでは、Kibanaを使用して管理されたRedisデータベースのメモリ使用状況を可視化しました。これにより、データベースの使用状況をより良く把握し、クライアントアプリケーションやデータベース自体を最適化するのに役立ちます。
結論
サーバーにElastic Stackがインストールされ、定期的に管理されたRedisデータベースから統計データを取得するように構成されました。Kibanaや他の適切なソフトウェアを使用してデータを分析および可視化できます。これにより、データベースのパフォーマンスに関する貴重な洞察と現実世界の相関関係を得るのに役立ちます。
Redis Managed Databaseで何ができるかの詳細については、製品ドキュメントを参照してください。別の可視化タイプでデータベースの統計を表示したい場合は、詳細な手順についてはKibanaドキュメントをチェックしてください。