













Apache Hadoop Distributed File System (HDFS)の登場は、企業のデータの保存、処理、分析に革命をもたらし、ビッグデータの成長を加速させ、業界に変革的な変化をもたらしました。
当初、Hadoopはストレージとコンピューティングを統合していましたが、クラウドコンピューティングの台頭によりこれらのコンポーネントが分離されるようになりました。オブジェクトストレージはHDFSの代替として登場しましたが、限界がありました。これらの制限を補完するために、JuiceFS、オープンソースの高性能な分散ファイルシステムが、計算、分析、トレーニングなどのデータ集約的なシナリオに対して経済的なソリューションを提供しています。ストレージとコンピューティングの分離を採用するかどうかは、スケーラビリティ、パフォーマンス、コスト、互換性などの要因によって決まります。
この記事では、Hadoopのアーキテクチャをレビューし、ストレージとコンピューティングの分離の重要性と実現可能性について議論し、市場で利用可能なソリューションを探り、それぞれの利点と欠点を強調します。その目的は、ストレージとコンピューティングの分離アーキテクチャの変革を経験している企業に洞察とインスピレーションを提供することです。
Hadoopアーキテクチャの設計特徴
Hadoop: オールインワンフレームワーク
2006年、Hadoopは3つのコンポーネントで構成されるオールインワンフレームワークとしてリリースされました。
- 計算のためのMapReduce
- リソーススケジューリングのためのYARN
- 分散ファイルストレージのためのHDFS
 Core components of Hadoop
Core components of Hadoop多様な計算コンポーネント
これら三つのコンポーネントの中で、計算層は急速な発展を遂げています。最初はMapReduceだけでしたが、すぐにTezやSparkのような様々な計算フレームワーク、Hiveのようなデータ倉庫、PrestoやImpalaのようなクエリエンジンが登場しました。これらのコンポーネントと共に、Sqoopのような多くのデータ転送ツールも存在します。

HDFSがストレージシステムを支配
約十年にわたり、分散ファイルシステムであるHDFSは、支配的なストレージシステムでした。ほぼすべての計算コンポーネントのデフォルトの選択肢でした。ビッグデータエコシステム内の上記のすべてのコンポーネントは、HDFS APIのために設計されていました。一部のコンポーネントは、HDFSの特定の機能を深く活用しています。例えば:
これらのビッグデータコンポーネントの設計選択は、HDFS APIに基づいており、クラウドにデータプラットフォームを展開する際の潜在的な課題をもたらしました。
ストレージ-計算結合アーキテクチャ
以下の図は、計算とストレージを組み合わせた簡略化されたHDFSアーキテクチャの一部を示しています。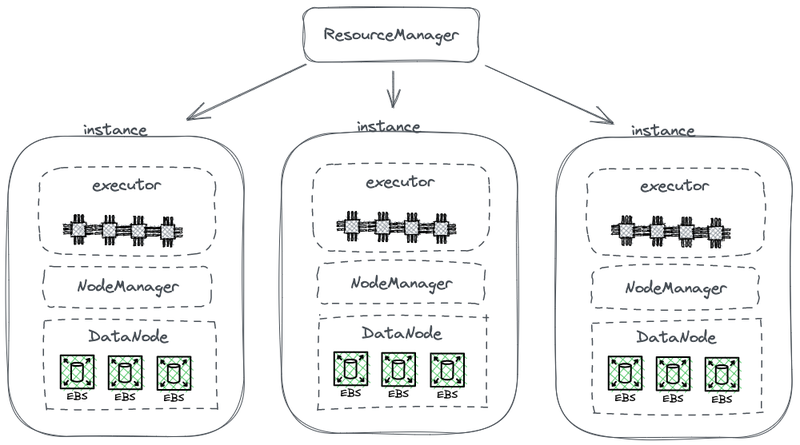
Hadoopストレージ・コンピュート組み合わせアーキテクチャ
この図では、各ノードはデータを保存するHDFS DataNodeとして機能します。さらに、YARNは各ノードにNode Managerプロセスを展開します。これにより、YARNはノードを計算タスクの管理リソースの一部として認識できます。このアーキテクチャにより、ストレージとコンピュートが同じマシン上で共存し、計算中にディスクからデータを読み取ることができます。
なぜHadoopはストレージとコンピュートを組み合わせるのか
Hadoopは、デザイン段階でのネットワーク通信とハードウェアの制限のため、ストレージとコンピュートを組み合わせています。
2006年当時、クラウドコンピューティングはまだ初期段階であり、Amazonは最初のサービスをリリースしたばかりでした。データセンターでは、主流のネットワークカードは主に100 Mbpsで動作していました。ビッグデータワークロード用のデータディスクは、約50 MB/sのスループットを達成し、ネットワーク帯域幅に換算すると約400 Mbpsでした。
8枚のディスクを搭載したノードが最大容量で稼働している状況を考えると、効率的なデータ伝送のためには数ギガビット/秒のネットワーク帯域が必要でした。残念ながら、ネットワークカードの最大容量は1 Gbpsに制限されており、結果としてノードあたりのネットワーク帯域は、ノード内のすべてのディスクの能力を十分に活用するには不十分でした。そのため、計算タスクがネットワークの一方の端にあり、データが他方の端にあるデータノードに存在する場合、ネットワーク帯域は大きなボトルネックとなりました。
ストレージ-コンピューティングの分離が必要である理由
2006年から約2016年まで、企業は以下の問題に直面していました:
- アプリケーションにおけるコンピューティングパワーとストレージの需要はバランスが取れず、それらの成長率が異なっていました。企業データは急速に成長していましたが、コンピューティングパワーの需要はそれほど速く成長していませんでした。人間によって開発されたこれらのタスクは、短時間で指数関数的に増加することはありませんでした。しかし、これらのタスクから生成されたデータは急速に蓄積され、指数関数的に増加する可能性がありました。また、一部のデータは企業にとって直ちに有用ではないかもしれませんが、将来価値があると考えられます。そのため、企業はデータを包括的に保存し、その潜在的価値を探求することにしました。
- スケーリング時には、企業は計算とストレージの両方を同時に拡張する必要があり、しばしば計算リソースの浪費につながりました。ストレージと計算が組み合わされたアーキテクチャのハードウェアトポロジは、容量拡張に影響を与えました。ストレージ容量が不足した場合、組み合わされたアーキテクチャのデータノードが計算を担当するため、マシンの追加だけでなく、CPUやメモリのアップグレードも必要でした。したがって、マシンは通常、計算能力とストレージのバランスの良いコンフィギュレーションを備えており、十分なストレージ容量と比較可能な計算能力を提供していました。しかし、実際の計算能力の需要は予想どおりに増加しませんでした。その結果、拡大された計算能力は企業にとって大きな無駄でした。
- 計算とストレージのバランスを取り、適切なマシンを選択することが難しくなりました。クラスタ全体のストレージとI/Oのリソース利用率は非常に不均衡になる可能性があり、クラスタが大きくなるほどこの不均衡は悪化します。さらに、計算とストレージの要件のバランスを取るために適切なマシンを購入することが難しかったです。
- データが不均等に分散される可能性があるため、データが存在するインスタンス上で計算タスクを効果的にスケジュールすることが難しかった。データロケリティスケジューリング戦略は、データ分布の不均衡の可能性から、実世界のシナリオに効果的に対処できない場合があります。例えば、特定のノードがローカルのホットスポットになり、より多くの計算能力を必要とすることがあります。その結果、ビッグデータプラットフォーム上のタスクがこれらのホットスポットノードにスケジュールされたとしても、I/Oパフォーマンスは依然として制限要因になる可能性があります。
ストレージとコンピューティングを切り離すことが実現可能になった理由
2006年から2016年までのハードウェアおよびソフトウェアの進歩,特に以下のものにより、ストレージとコンピューティングを分離することが実現可能になりました:
ネットワークカード
10 Gbのネットワークカードの採用が広まり、データセンターやクラウド環境では20 Gb、40 Gb、さらには50 Gbの容量も増えています。AIのシナリオでは、100 GBの容量を持つネットワークカードも使用されています。これは、ネットワーク帯域幅が100倍以上増加したことを意味します。
ディスク
多くの企業は、大規模データクラスターのストレージにディスクベースのソリューションに依存しています。ディスクのスループットは倍増し、50 MB/sから100 MB/sに増加しました。10 GBのネットワークカードを搭載したインスタンスは、約12枚のディスクのピークスループットをサポートできます。これはほとんどの企業にとって十分であり、したがって、ネットワーク伝送はもはやボトルネックではありません。
ソフトウェア
Snappy、LZ4、Zstandardなどの効率的な圧縮アルゴリズムや、Avro、Parquet、Orcなどの列指向ストレージ形式の使用により、I/O圧力がさらに緩和されました。大規模データ処理のボトルネックはI/OからCPU性能に移行しました。
ストレージとコンピューティングの分離を実装する方法
最初の試み:クラウドへのHDFSの独立展開
HDFSの独立展開
2013年から、業界内でストレージとコンピューティングを分離する試みが行われています。最初のアプローチは非常にシンプルで、コンピューティングワーカーと統合せずにHDFSを独立して展開するものでした。このソリューションは、Hadoopエコシステムに新しいコンポーネントを導入しませんでした。
下の図に示すように、NodeManagerはDataNodesに展開されなくなりました。これは、コンピューティングタスクがもはやDataNodesに送られないことを意味します。ストレージは独立したクラスターとなり、計算に必要なデータは、エンドツーエンドの10 Gbネットワークカードでサポートされるネットワーク経由で転送されました。(ネットワーク転送ラインは図には示されていません。)

このソリューションは、HDFSの最も巧妙な設計であるデータの局所性を放棄しましたが、ネットワーク通信の高速化はクラスター構成を大幅に容易にしました。これは、デービス、Juicedataの共同創業者、そして2013年にFacebookで彼のチームメイトと共に行われた実験によって示されました。結果は、コンピューティングノードの独立した展開と管理の実現可能性を確認しました。
しかし、この試みはさらに発展しませんでした。主な理由は、HDFSをクラウドに展開する際の課題です。
クラウドへのHDFS展開の課題
クラウドへのHDFS展開は以下の問題に直面します:
- HDFSのマルチレプリカ機構は、クラウド上での企業のコストを増加させる可能性があります:かつて、企業はデータセンター内でベアディスクを使用してHDFSシステムを構築していました。ディスク損傷のリスクを軽減するため、HDFSはデータの安全性と可用性を確保するためのマルチレプリカ機構を実装しました。しかし、データをクラウドに移行する際、クラウドプロバイダーは既にマルチレプリカ機構で保護されたクラウドディスクを提供しています。その結果、企業はクラウド内でデータを3回コピーする必要があり、コストが大幅に増加します。
- ベアディスクでの展開オプションが限定されている:クラウドプロバイダーはいくつかのマシンタイプでベアディスクを提供していますが、利用可能なオプションは限定されています。例えば、クラウドで利用可能な100の仮想マシンタイプのうち、ベアディスクをサポートするのは5〜10タイプに過ぎません。この限定された選択肢は、企業のクラスターの特定の要件を満たすことができない可能性があります。
- クラウドの独自の利点を活用できない:クラウドにHDFSを展開するには、手動でのマシン作成、展開、保守、監視、および操作が必要であり、スケーラブルなスケーリングやサブスクリプションモデルの利便性がありません。これらはクラウドコンピューティングの主要な利点です。したがって、ストレージとコンピューティングの分離を実現しながらクラウドにHDFSを展開するのは容易ではありません。
HDFSの制限
HDFS自体には以下の制限があります:
- NameNodesのスケーラビリティに制限がある:HDFS内のNameNodesは垂直方向にのみスケール可能で、分散的にスケールすることはできません。この制限により、単一のHDFSクラスタ内で管理可能なファイル数に制約が課せられます。
- 5億以上のファイルを保存すると運用コストが高くなる:私たちの経験から、3億以下のファイルであればHDFSの運用と保守は比較的容易です。しかし、ファイル数が5億を超えると、HDFSフェデレーションのメカニズムの実装が必要になります。これにより、運用および管理コストが高くなります。
- NameNodeの高いリソース使用率と負荷がHDFSクラスタの可用性に影響する:NameNodeが多くのリソースを消費し、負荷が高い場合、完全なガベージコレクション(GC)がトリガされる可能性があります。これは、HDFS全体の可用性に影響を与えます。システムストレージはダウンタイムを経験し、データの読み取りができなくなり、GCプロセスへの介入ができません。システムのフリーズ期間は決定できません。これは、高負荷のHDFSクラスタで継続的な問題です。
パブリッククラウド+オブジェクトストレージ
クラウドコンピューティングの進化により、企業はHDFSの代わりにオブジェクトストレージを利用するオプションを持つようになりました。オブジェクトストレージは、大規模で非構造化なデータを保存するために特別に設計されており、データのアップロードとダウンロードを容易にするアーキテクチャを提供しています。高度にスケーラブルなストレージ容量を提供し、コスト効果を確保しています。
HDFSの代替としてのオブジェクトストレージの利点
オブジェクトストレージは、AWSから始まり、他のクラウドプロバイダーによってHDFSの代替として採用されるようになり、注目を集めています。以下の利点が注目されています。
- サービス指向ですぐに使える:オブジェクトストレージは、展開、監視、メンテナンスの作業が不要で、便利でユーザーフレンドリーな経験を提供しています。
- エラスティックスケーリングとプリペイド課金: 企業はオブジェクトストレージの使用量に基づいて支払いを行い、容量計画の必要性を排除します。彼らはオブジェクトストレージバケットを作成し、必要なだけ多くのデータを保存でき、ストレージ容量の制限について心配する必要はありません。
オブジェクトストレージの欠点
しかし、オブジェクトストレージをHadoopのような複雑なデータシステムをサポートするために使用する場合、以下の課題が生じます。
欠点1: ファイルリストのパフォーマンスが悪い
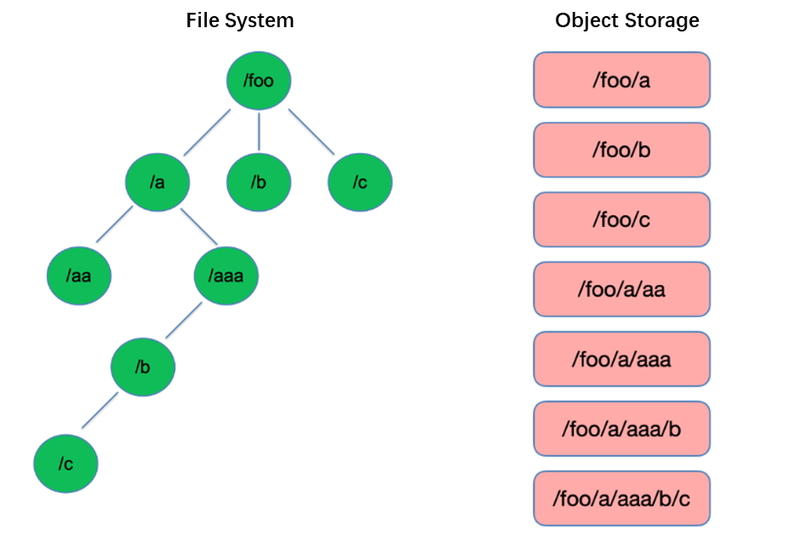
リスティングはファイルシステムで最も基本的な操作の1つです。HDFSのようなツリー構造では軽量で高速です。
対照的に、オブジェクトストレージはフラットな構造を採用し、数千から数十億のオブジェクトを保存および取得するためにキー(一意の識別子)でインデックスを作成する必要があります。その結果、List操作を実行する場合、オブジェクトストレージはこのインデックス内で検索することしかできず、ツリー構造に比べて大幅に性能が劣ります。
欠点2: アトミックリネーム機能の欠如、タスクのパフォーマンスと安定性に影響
抽出、変換、ロード(ETL)計算モデルでは、各サブタスクがその結果を一時ディレクトリに書き込みます。全体のタスクが完了すると、一時ディレクトリを最終ディレクトリ名にリネームできます。
これらのリネーム操作は、HDFSのようなファイルシステムではアトミックで高速であり、トランザクションを保証します。しかし、オブジェクトストレージはネイティブなディレクトリ構造を持たないため、リネーム操作の処理は内部データの大量のコピーを伴うシミュレートされたプロセスです。このプロセスは時間がかかり、トランザクション保証を提供しません。
ユーザーがオブジェクトストレージを使用する際、彼らは通常、従来のファイルシステムからのパス形式をオブジェクトのキーとして使用します。例えば、”/order/2-22/8/10/detail”のように。リネーム操作の際、ディレクトリ名を含むすべてのオブジェクトを検索し、新しいディレクトリ名をキーとしてすべてのオブジェクトをコピーする必要があります。このプロセスはデータコピーを伴い、ファイルシステムに比べて性能が大幅に低くなり、1つまたは2つの桁が遅くなる可能性があります。
さらに、トランザクション保証の欠如により、プロセス中に失敗のリスクがあり、誤ったデータが発生する可能性があります。これらの小さく見える違いは、タスクパイプライン全体のパフォーマンスと安定性に影響を与えます。
短所ナンバー3: 最終的な一貫性メカニズムがデータの正確性とタスクの安定性に影響を与える
例えば、複数のクライアントが同時にパスの下にファイルを作成すると、List APIを介して取得されるファイルリストにはすぐにすべての作成されたファイルが含まれない場合があります。オブジェクトストレージの内部システムがデータの一貫性を達成するのに時間がかかります。このアクセスパターンはETLデータ処理で一般的に使用され、最終的な一貫性はデータの正確性とタスクの安定性に影響を与える可能性があります。
オブジェクトストレージのデータ一貫性を維持できない問題に対処するため、AWSはEMRFSという製品をリリースしました。そのアプローチは、追加のDynamoDBデータベースを利用するものです。例えば、Sparkがファイルを書き込む際、同時にファイルリストのコピーもDynamoDBに書き込みます。そして、オブジェクトストレージのList APIを継続的に呼び出し、取得した結果をデータベースに保存された結果と比較し、一致するまで待機するメカニズムが確立されます。しかし、このメカニズムの安定性は十分ではなく、オブジェクトストレージが存在するリージョンの負荷に影響され、パフォーマンスが変動することがあります。したがって、理想的な解決策ではありません。
短所#4: Hadoopコンポーネントとの互換性が限られている
HDFSは、Hadoopエコシステムの初期段階で主なストレージ選択肢であり、さまざまなコンポーネントがHDFS APIに基づいて開発されました。オブジェクトストレージの導入により、データストレージ構造とAPIが変更されました。
クラウドプロバイダーは、コンポーネント間およびクラウドオブジェクトストレージとの接続を修正し、上位層のコンポーネントにパッチを当てる必要があります。この作業は、パブリッククラウドプロバイダーに大きな負荷をかけます。
その結果、パブリッククラウドプロバイダーが提供するビッグデータプラットフォームでサポートされる計算コンポーネントの数は限られており、通常はSpark、Hive、Prestoのいくつかのバージョンのみが含まれます。この制限は、ビッグデータプラットフォームをクラウドに移行する際や、独自のディストリビューションとコンポーネントに特定の要件があるユーザーにとって、課題となっています。
オブジェクトストレージの強力なパフォーマンスを活用しつつ、ファイルシステムの信頼性を維持するために、企業はオブジェクトストレージ + JuiceFSを利用できます。
オブジェクトストレージ + JuiceFS
ユーザーがオブジェクトストレージ上で複雑なデータ計算、分析、およびトレーニングを行いたい場合、オブジェクトストレージだけでは企業の要件を十分に満たすことができない可能性があります。これが、JuicedataがJuiceFSを開発する背後にある主な動機であり、オブジェクトストレージの制限を補完することを目的としています。
JuiceFSは、クラウド向けに設計されたオープンソース、高性能な分散ファイルシステムです。オブジェクトストレージと組み合わせることで、計算、分析、トレーニングなどのデータ集約的なシナリオに対してコスト効果の高いソリューションを提供します。
JuiceFS + オブジェクトストレージの動作方法
以下の図は、JuiceFSがHadoopクラスタ内での展開を示しています。
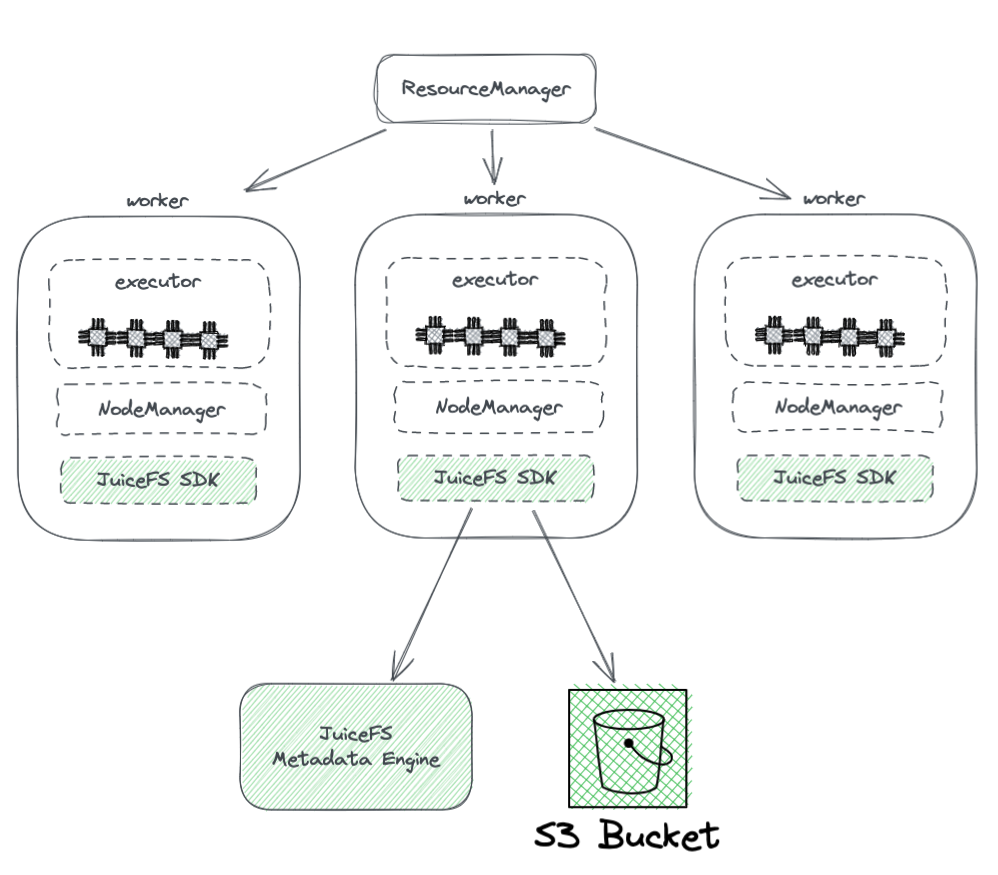
図から以下の点がわかります。
- YARNによって管理されるすべてのワーカーノードは、JuiceFS Hadoop SDKを搭載しており、HDFSとの完全な互換性を保証できます。
- SDKは2つのコンポーネントにアクセスします。
-
JuiceFSメタデータエンジン:メタデータエンジンはHDFSのNameNodeに対応するもので、ファイルシステム全体のメタデータ情報を格納します。これには、ディレクトリ数、ファイル名、権限、タイムスタンプが含まれ、HDFSのNameNodeが直面するスケーラビリティとGCの課題を解決します。
-
S3バケット:データはS3バケット内に格納され、HDFSのDataNodeに類似していると見なすことができます。大量のディスクとして使用でき、データストレージとレプリケーションタスクを管理します。
-
-
JuiceFSは以下の3つのコンポーネントで構成されています:
- JuiceFS Hadoop SDK
- メタデータエンジン
- S3バケット
オブジェクトストレージの直接使用に比べたJuicefsの利点
JuiceFSはオブジェクトストレージの直接使用に比べていくつかの利点を提供します:
- HDFSとの完全互換性:これは、JuiceFSの初期設計がPOSIXを完全にサポートすることによって達成されます。POSIX APIはHDFSよりも広範囲で複雑です。
- 既存のHDFSおよびオブジェクトストレージとの併用が可能:Hadoopシステムの設計のおかげで、JuiceFSは既存のHDFSおよびオブジェクトストレージシステムと併用でき、完全な置き換えを必要としません。Hadoopクラスタ内では、複数のファイルシステムを設定でき、JuiceFSとHDFSが共存し協力することができます。このアーキテクチャにより、既存のHDFSクラスタの完全置換が不要になり、多大な労力とリスクが伴います。ユーザーはアプリケーションのニーズやクラスタの状況に基づいてJuiceFSを徐々に統合できます。
- 強力なメタデータパフォーマンス:JuiceFSはS3からメタデータエンジンを分離し、S3のメタデータパフォーマンスに依存しなくなりました。これにより、最適なメタデータパフォーマンスが保証されます。JuiceFSを使用する際、基盤となるオブジェクトストレージとのインタラクションは、Get、Put、Deleteなどの基本的な操作に簡略化されます。このアーキテクチャは、オブジェクトストレージのメタデータのパフォーマンス上の制限を克服し、最終的な一貫性に関する問題を解消します。
- 原子リネームのサポート: JuiceFSは独立したメタデータエンジンを持つため、原子リネーム操作をサポートしています。キャッシュはホットデータのアクセス性能を向上させ、データローカリティ機能を提供します。キャッシュを使用することで、ホットデータは毎回ネットワーク経由でオブジェクトストレージから取得する必要がなくなります。さらに、JuiceFSはHDFS固有のデータローカリティAPIを実装しており、データローカリティをサポートするすべての上位コンポーネントがデータの親和性を再認識できるようになります。これにより、YARNはキャッシングが確立されたノード上でタスクを優先的にスケジュールすることができ、ストレージとコンピューティングが結合されたHDFSと同等の全体的な性能を実現します。
- JuiceFSはPOSIXと互換性があるため、機械学習やAI関連のアプリケーションと簡単に統合できます.
結論
企業の要件の進化と技術の進歩,ストレージとコンピューティングのアーキテクチャは結合から分離へと変化しました。
ストレージとコンピューティングの分離を実現する方法は多岐にわたり、それぞれに利点と欠点があります。HDFSをクラウドに展開する方法から、Hadoopと互換性のあるパブリッククラウドソリューションを利用する方法、さらにはオブジェクトストレージ+JuiceFSのようなソリューションを採用する方法もあり、これらはクラウド上で複雑なビッグデータの計算とストレージに適し�ています。
企業にとって、万能な解決策は存在せず、重要なのは特定のニーズに基づいてアーキテクチャを選択することです。しかし、選択が何であれ、シンプルさは常に安全な選択です。
著者について
瑞蘇は、ジューシーデータのパートナーであり、2017年からジュースFS製品、市場、オープンソースコミュニティの完全な開発に携わる創設メンバーです。16年の業界経験を持ち、ソフトウェア、インターネット、非政府組織でR&D、プロダクトマネージャー、ファウンダーなどの役割を務めてきました。
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora