













データベースのシャーディングは、データを「シャード」と呼ばれる小さな部分に分割するプロセスです。シャーディングは、書き込みをスケールアップする必要がある場合に一般的に導入されます。成功したアプリケーションの寿命中に、データベースサーバーは処理または容量レベルで実行できる書き込みの最大数に達するでしょう。データを複数のシャードにスライスし、それぞれが独自のデータベースサーバー上にあることで、各ノードのストレスを軽減し、全体のデータベースの書き込み容量を効果的に増加させます。これがデータベースのシャーディングです。
分散SQLは、完全に自動化され、アプリケーションに対して透明なシャーディングに似た戦略でリレーショナルデータベースをスケールアップする新しい方法です。分散SQLデータベースは、ほぼ線形にスケールアップできるように設計されています。この記事では、分散SQLの基本と、始める方法を学びます。
データベースシャーディングの欠点
シャーディングはいくつかの課題を引き起こします。
- データのパーティション分割: 複数のシャードにデータをどのようにパーティション分割するかを決定することは、データの近接性とホットスポットを避けるための均等なデータ分布のバランスを見つけることを要求するため、課題となる場合があります。
- 障害対応: 主要ノードが障害により停止し、シャードが負荷を担うのに十分でない場合、ダウンタイムなしで新しいノードにデータを取得する方法は何でしょうか?
- クエリの複雑さ: アプリケーションコードはデータシャーディングロジックに結合され、複数のノードからデータを必要とするクエリは再結合する必要があります。
- データ整合性: 複数のシャード間でデータ整合性を保証することは、シャード全体でデータの更新を調整する必要があるため、課題となる場合があります。特に、同時に更新が行われる場合、異なる書き込み間の競合を解決する必要がある場合があります。
- エラスティックスケーラビリティ: データ量やクエリ数が増加すると、データベースに追加のシャードを追加する必要があります。これは、ダウンタイムが避けられない複雑なプロセスであり、データをすべてのシャードに均等に再配置するための手動プロセスが必要です。
これらの欠点のいくつかは、ポリグロット永続性(異なるワークロードに異なるデータベースを使用)、データベースネイティブシャーディング機能を持つストレージエンジン、またはデータベースプロキシを採用することで緩和できます。ただし、データベースのシャーディングで直面するいくつかの課題に対処する一方で、これらのツールは制限があり、常に管理が必要な複雑さを引き起こします。
分散SQLとは何ですか?
分散SQLとは、新世代のリレーショナルデータベースを指します。簡単に言えば、分散SQLデータベースは、アプリケーションにとって単一の論理データベースのように見える透過的なシャーディングを持つリレーショナルデータベースです。分散SQLデータベースは共有されていないアーキテクチャと、読み取りと書き込みの両方をスケールしながら、真のACID準拠と高可用性を維持するストレージエンジンとして実装されています。分散SQLデータベースは、2000年代に人気を集めたNoSQLデータベースのスケーラビリティの機能を持ちながら、一貫性を犠牲にすることはありません。彼らはリレーショナルデータベースの利点を維持し、マルチリージョンの回復力を持つクラウド互換性を追加します。
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
分散SQLはどのように機能しますか?
分散型SQLの仕組みを理解するために、MariaDB Xpandのケースを考えてみましょう。これはオープンソースのMariaDBデータベースと互換性のある分散型SQLデータベースです。Xpandはデータとインデックスをノード間でスライスし、データのリバランスや分散クエリの実行などのタスクを自動的に実行します。クエリは遅延を最小限に抑えるために並列に実行されます。データは自動的に複製され、障害の単一のポイントがないことを保証します。ノードが失敗すると、Xpandは残りのノードでデータをリバランスします。新しいノードが追加されるときも同じことが起こります。リバランサーと呼ばれるコンポーネントは、ホットスポットが発生しないように確認します。これは、手動のデータベースシャーディングで問題となることがあります。これは、1つのノードが他のノードと比べて多くのトランザクションを処理しなければならず、時には他のノードがアイドル状態になる場合があります。
例を見てみましょう。some_tableというテーブルと複数の行を持つデータベースインスタンスがあるとします。
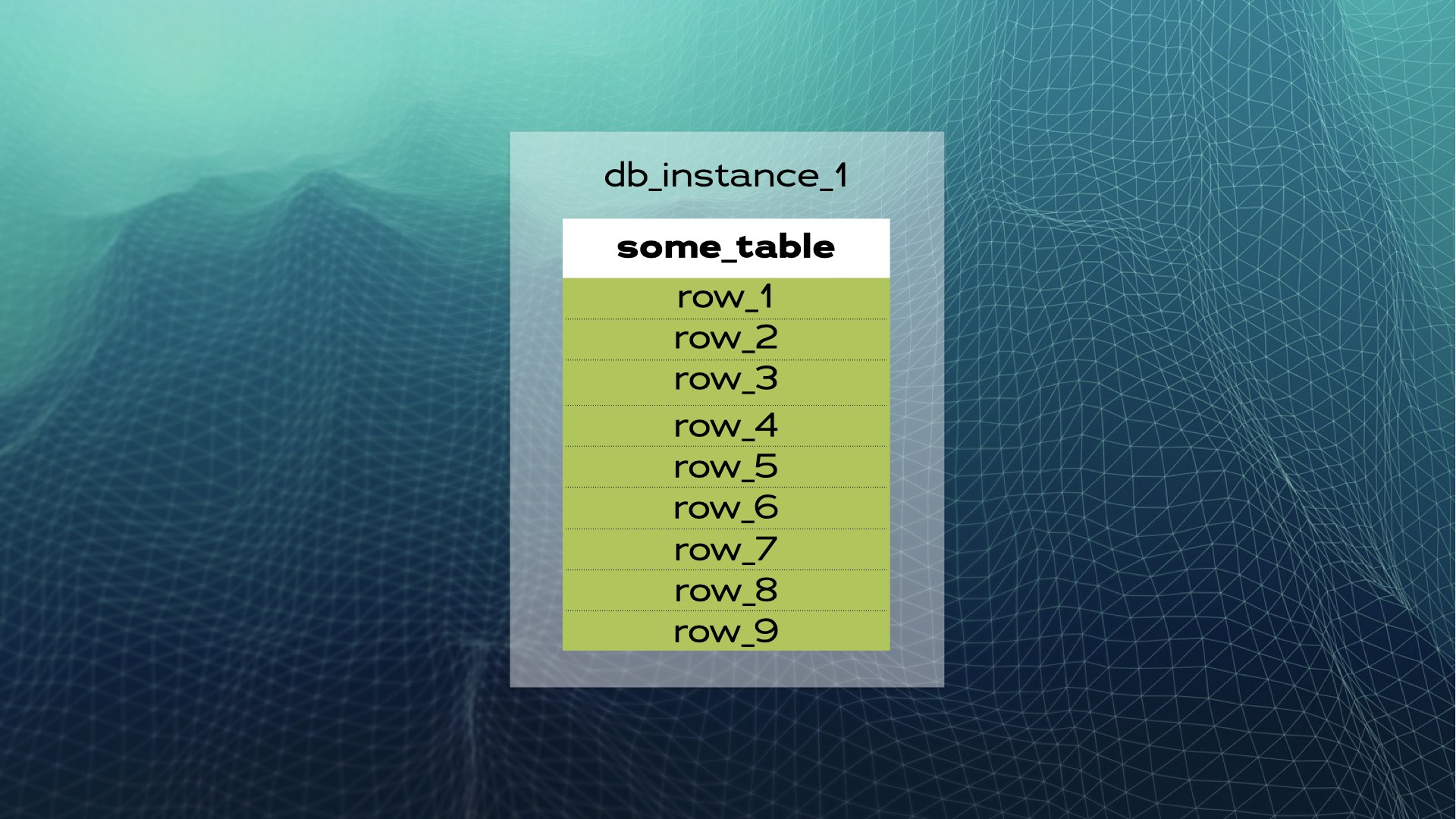
データを3つのチャンク(シャード)に分割できます。

そして、各データチャンクを別々のデータベースインスタンスに移動します。
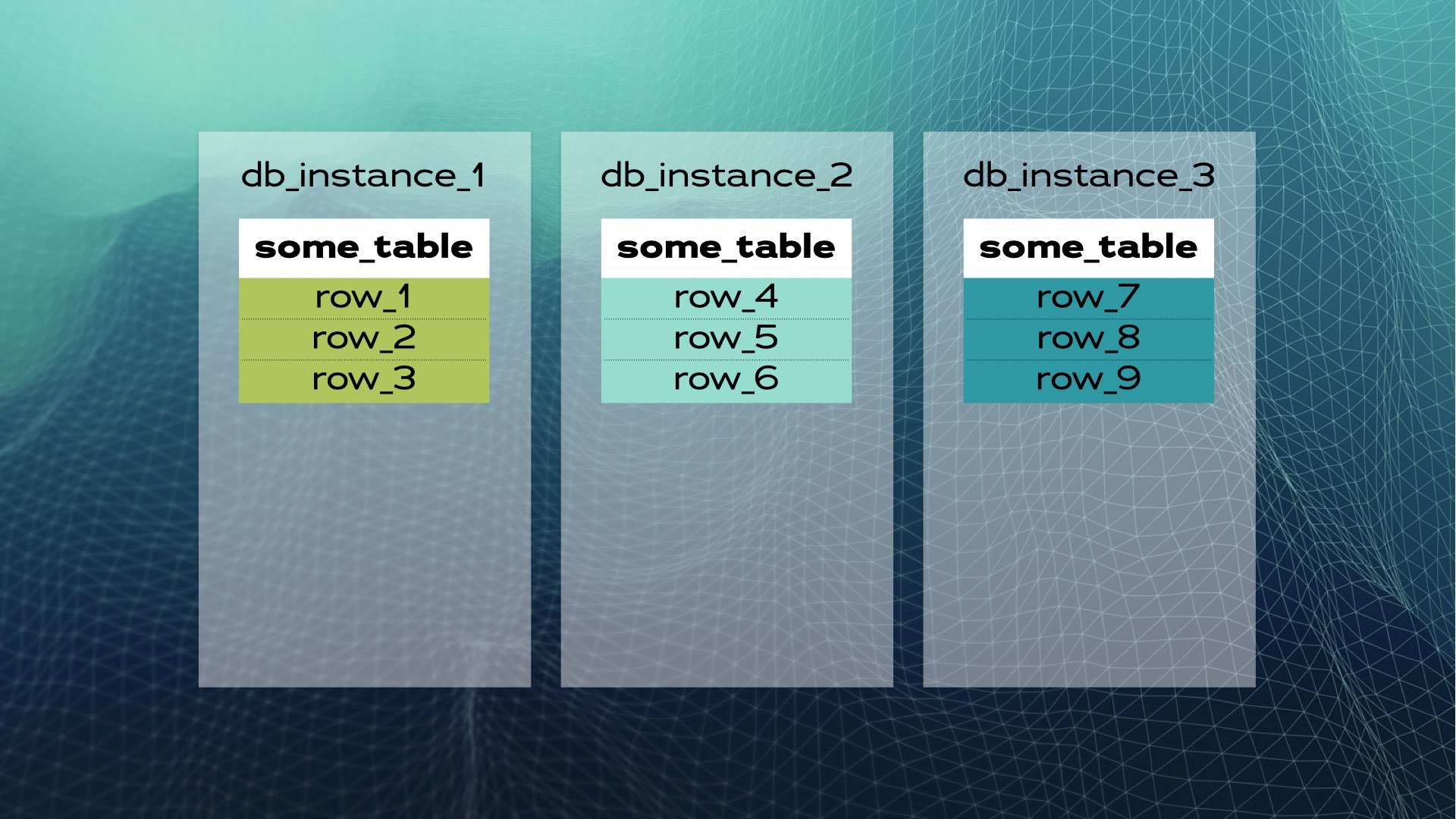
これが手動でのデータベース共有の様子です。分散SQLはこれを自動的に行います。Xpandの場合、各シャードはスライスと呼ばれます。行は、テーブルの列のサブセットのハッシュを使用してスライスされます。スライスされるのはデータだけでなく、インデックスもスライスされてノード(データベースインスタンス)間に分散されます。さらに、高可用性を維持するために、スライスは他のノードに複製されます(ノードあたりのレプリカ数は設定可能です)。これも自動的に行われます:
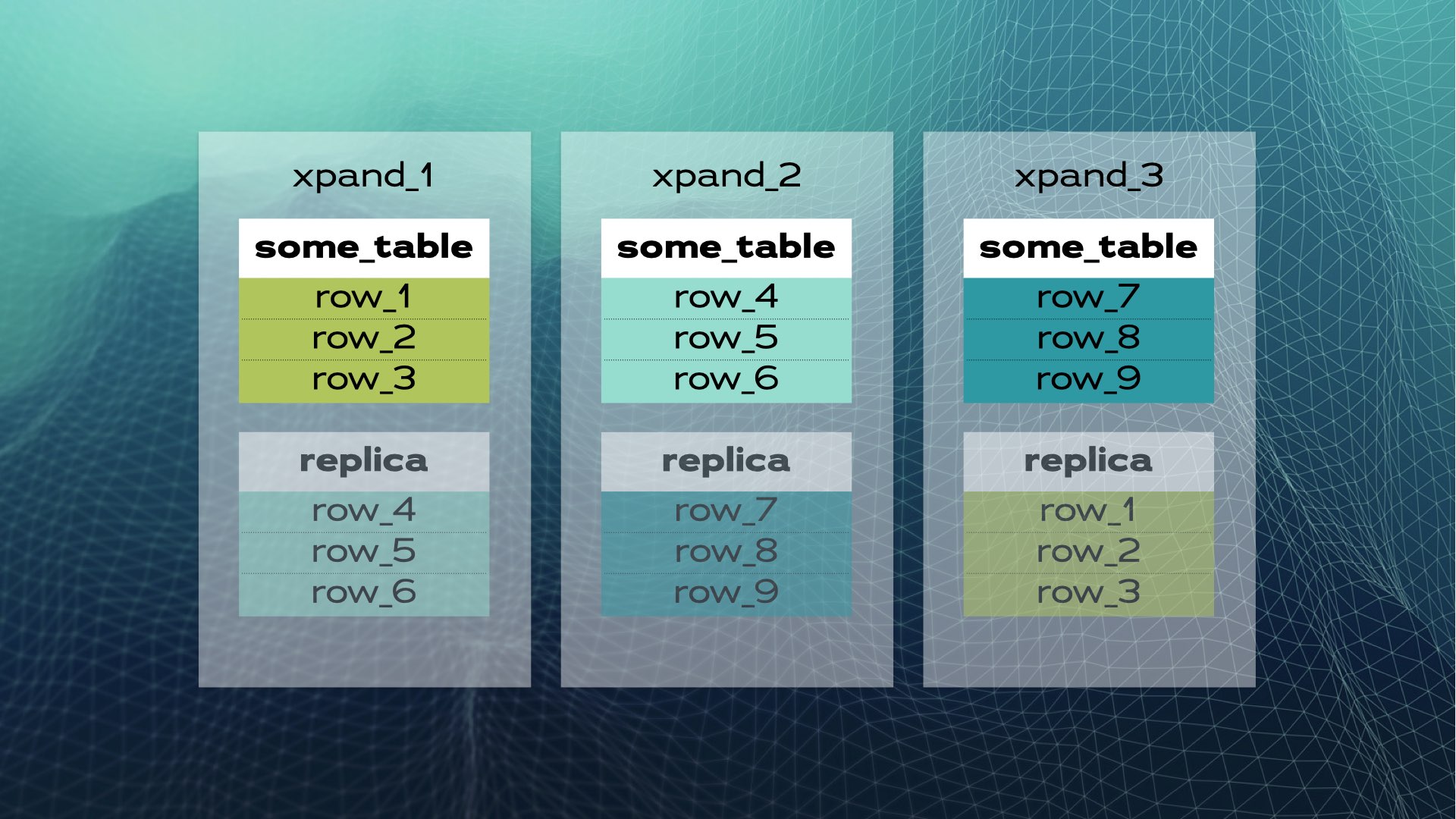
クラスタに新しいノードが追加されたり、ノードが失敗した場合、Xpandは手動介入なしでデータを自動的に再バランスします。前のクラスタにノードが追加されたときに何が起こるか:

いくつかの行が新しいノードに移動されて、システム全体の容量が増加します。図には示されていませんが、インデックスやレプリカも移動されて更新されることに注意してください。前のクラスタのより完全なビュー(データのリロケーションが若干異なる)がこの図に示されています:
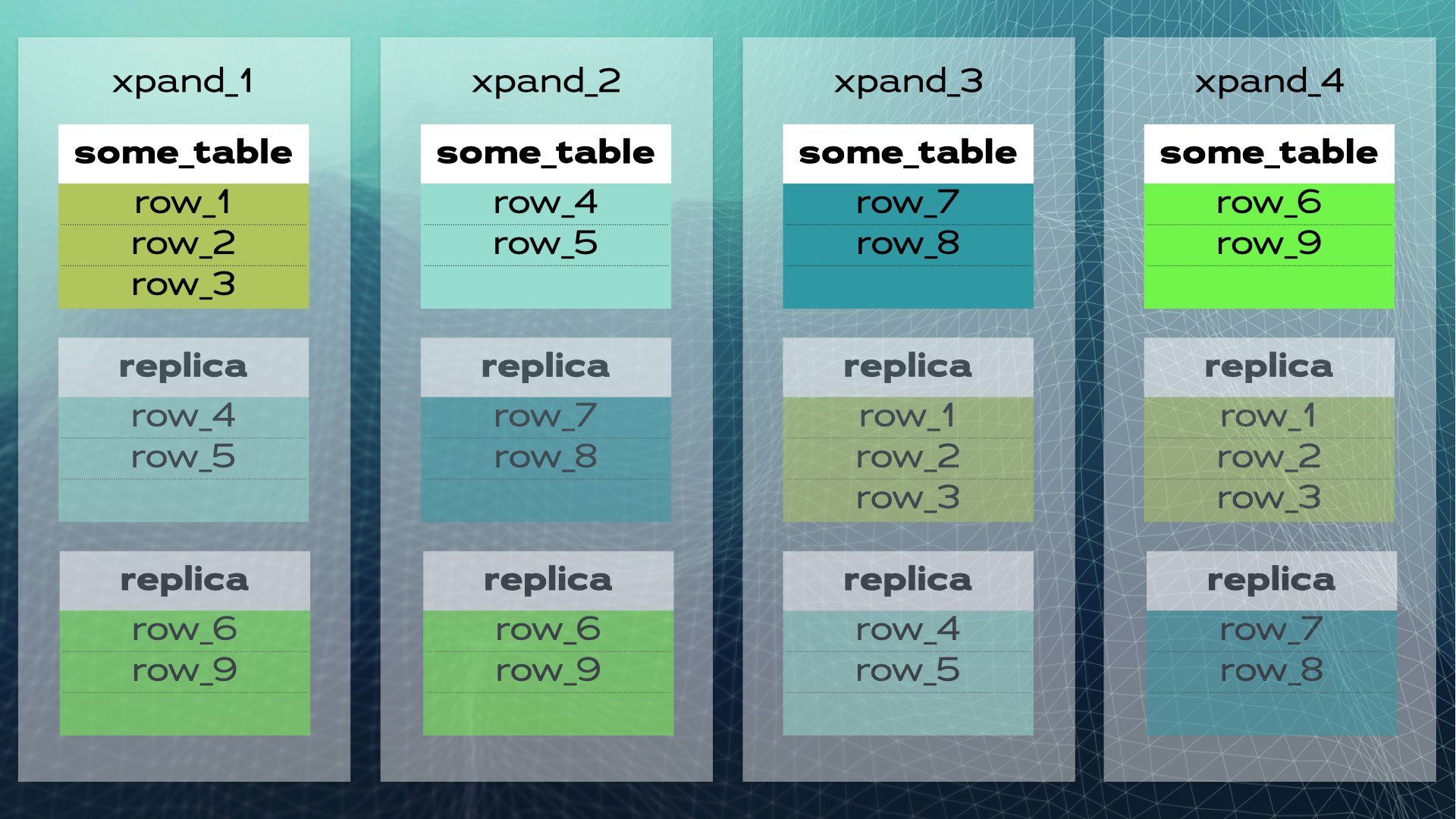
このアーキテクチャにより、ほぼ線形なスケーラビリティが可能です。アプリケーションレベルでの手動介入は必要ありません。アプリケーションにとって、クラスタは単一の論理データベースのように見えます。アプリケーションはロードバランサー(MariaDB MaxScale)を介してデータベースに接続します:
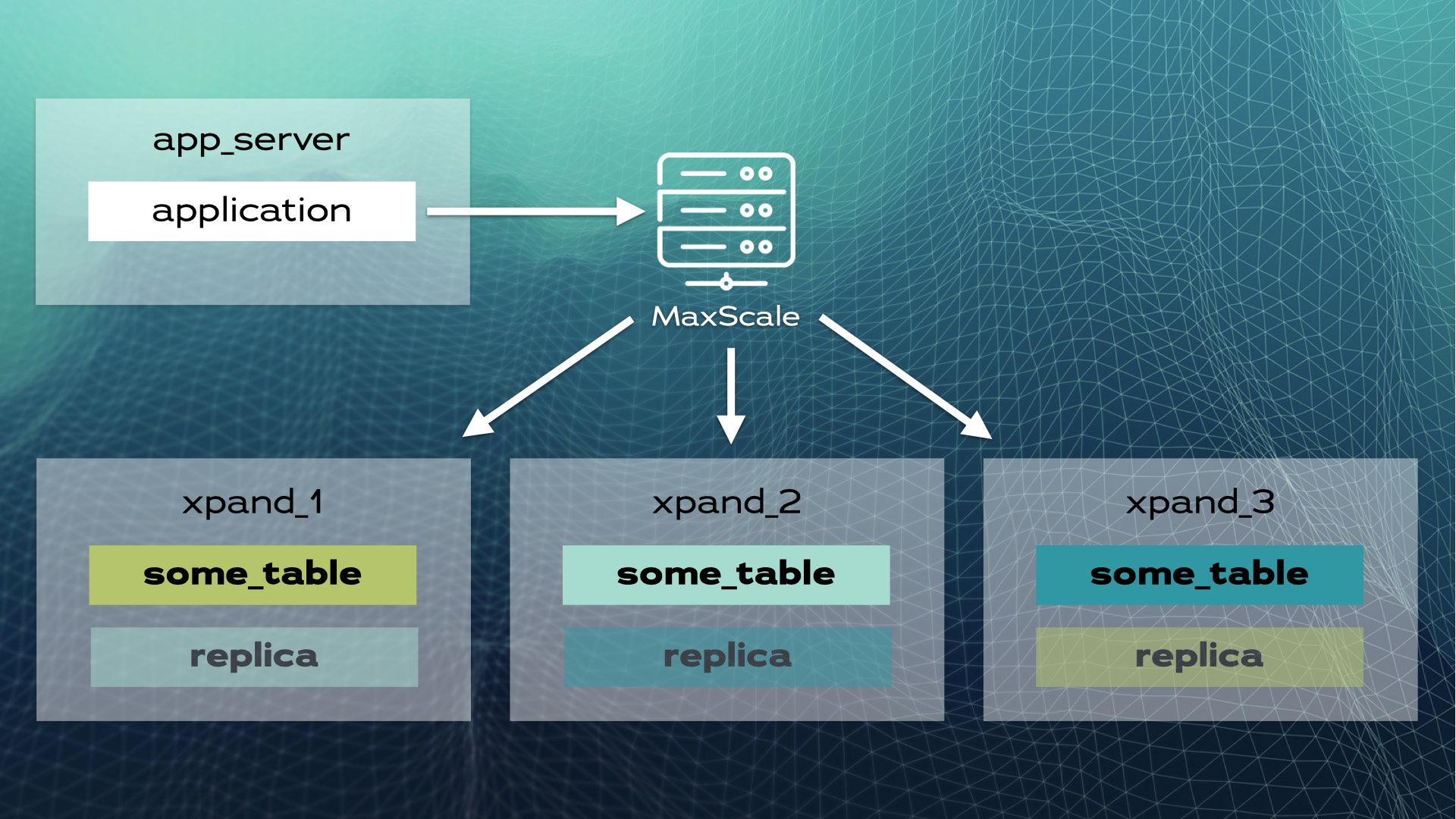
アプリケーションが書き込み操作(例えば、INSERTやUPDATE)を送信すると、ハッシュが計算されて正しいスライスに送信されます。複数の書き込みは複数のノードに並行して送信されます。
分散型SQLの使用を避けるべき状況
データベースをシャーディングすることはパフォーマンスを向上させるが、ノード間の通信レベルでの追加オーバーヘッドも引き起こす。データベースが正しく設定されていないか、クエリルーターが最適化されていない場合、パフォーマンスが遅くなる可能性がある。分散型SQLは、毎秒10Kクエリ未満または毎秒5Kトランザクション未満のアプリケーションで最良の選択肢ではないかもしれない。また、データベースが主に多数の小さなテーブルで構成されている場合、モノリシックデータベースの方が優れたパフォーマンスを発揮する可能性がある。
分散型SQLの始め方
分散型SQLデータベースは、アプリケーションにとって1つの論理データベースのように見えるため、始め方は簡単です。以下が必要です。
- DBeaver、DbGate、DataGripなどのSQLクライアント、またはIDEのSQLクライアント拡張機能
- A distributed SQL database
Dockerは2つ目の部分を簡単にします。例えば、MariaDBは評価、テスト、開発用に単一ノードのXpandデータベースを作成できるmariadb/xpand-single Dockerイメージを公開しています。
Xpandコンテナーを開始するには、以下のコマンドを実行します。
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Dockerイメージのドキュメントを参照して詳細を確認してください。
注意: この記事を執筆している時点で、mariadb/xpand-single DockerイメージはARMアーキテクチャでは利用できません。これらのアーキテクチャ(例えばM1プロセッサー搭載のAppleマシン)では、UTMを使用して仮想マシン(VM)を作成し、例えばDebianをインストールしてください。ホスト名を割り当て、SSHを使用してVMに接続し、DockerをインストールしてMariaDB Xpandコンテナを作成してください。
データベースへの接続
Xpandデータベースへの接続は、MariaDB コミュニティやエンタープライズサーバーへの接続と同じです。mariadb CLIツールがインストールされている場合、以下を実行してください:
mariadb -h 127.0.0.1 -u user -pデータベースに接続するには、DBeaverやDataGripのようなSQLデータベース用のGUIを使用するか、IDE(例えばこれのようなVS Code用のSQL拡張機能)を利用できます。今回は、DbGateという無料かつオープンソースのSQLクライアントを使用します。DbGateをダウンロードし、デスクトップアプリケーションとして実行するか、Dockerを使用している場合は、Webアプリケーションとして展開し、Webブラウザからどこからでもアクセスできるようにすることができます(人気のphpMyAdminに似ています)。以下のコマンドを実行してください:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateコンテナが起動すると、ブラウザをhttp://localhost:3000/に向けます。接続詳細を入力してください:
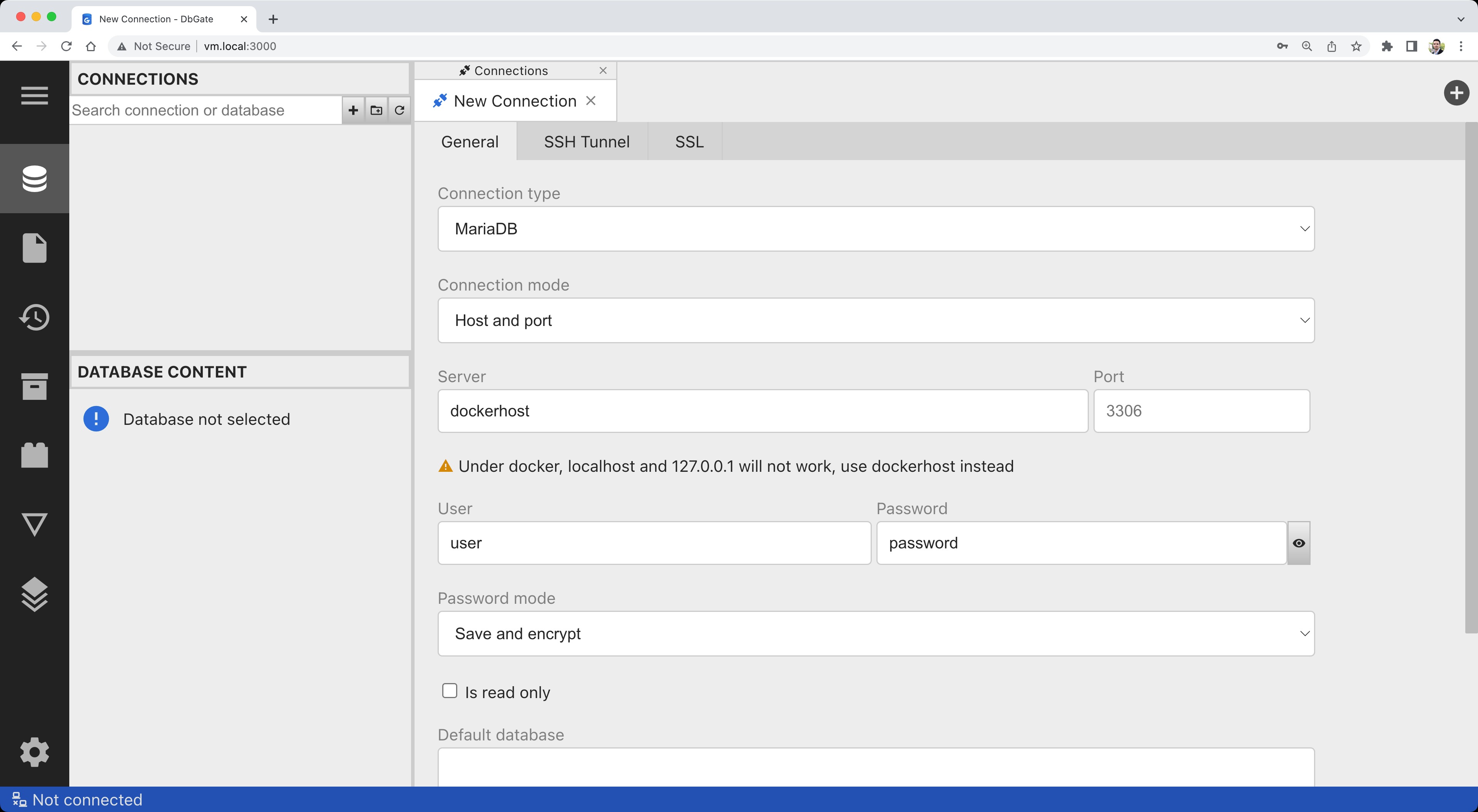
をクリックし、接続が成功したことを確認してください:

をクリックし、左パネルの接続を右クリックしてデータベースを作成を選択し、新しいデータベースを作成します。テーブルを作成したり、SQLスクリプトをインポートしたりしてみてください。試してみたいだけの場合、NationやSakilaは良い例示データベースです。
Java、JavaScript、Python、C++から接続
アプリケーションからXpandに接続するためには、MariaDB Connectorsを使用できます。多くのプログラミング言語と永続性フレームワークの組み合わせが可能です。これについては、この記事の範囲外ですが、すぐに始めて実際の動作を見たい場合は、Java、JavaScript、Python、C++のコード例があるこのクイックスタートページをチェックしてください。
分散SQLの真の力
この記事では、開発やテスト目的でのシングルノードXpandを立ち上げる方法を学びましたが、本番のワークロードとは対照的です。しかし、分散SQLデータベースの真の力は、データを最適に再配置するリバランサーを使って、ノードを追加するだけで、読み取り(古典的なデータベースシャーディングのように)だけでなく、書き込みもスケールできる能力にあります。Xpandをマルチノードトポロジで展開することは可能ですが、本番で最も簡単に使用する方法はSkySQLを通じてです。
分散SQLやMariaDB Xpandについてさらに学びたい場合は、以下のリソースリストをご覧ください。
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding