













このScyllaDB大学の実践ラボでは、ScyllaDB CDCソースコネクタを使用して、ScyllaDBクラスタのテーブル内の行レベルの変更イベントをKafkaサーバーにプッシュする方法を学びます。
ScyllaDB CDCとは何か?
要約すると、Change Data Capture(CDC)は、データベースのテーブルの現在の状態だけでなく、テーブルに加えられたすべての変更の履歴を照会できる機能です。CDCは、ScyllaDB Enterprise 2021.1.1およびScyllaDB Open Source 4.3からプロダクションリーディング(GA)で利用可能です。
ScyllaDBでは、CDCはオプションであり、テーブルごとに有効にされます。CDC対応テーブルに加えられた変更の履歴は、別の関連テーブルに保存されます。
CDCを有効にするには、テーブルの作成または変更時にCDCオプションを使用します。例:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};ScyllaDB CDCソースコネクタ
ScyllaDB CDC Source Connectorは、ScyllaDBクラスタ内のテーブルにおける行レベルの変更をキャプチャするソースコネクタです。これはDebeziumコネクタであり、Kafka Connect(Kafka 2.6.0+と互換性がある)と共に使用できます。コネクタは指定されたテーブルのCDCログを読み取り、各行レベルのINSERT、UPDATE、DELETE操作に対してKafkaメッセージを生成します。コネクタは障害耐性があり、失敗時にはScyllaからデータを再読み取りを試みます。また、Kafka Connectオフセット追跡を使用して、ScyllaDB CDCログ内の現在の位置を定期的に保存します。生成された各Kafkaメッセージには、タイムスタンプやテーブル名などのソース情報が含まれています。
注意: 執筆時点では、コレクション型(LIST、SET、MAP)やUDT(ユーザ定義型)はサポートされておらず、これらの型の列は生成されたメッセージから省略されます。この機能拡張要求やGitHubプロジェクトの他の開発について最新の情報を確認してください。
ConfluentおよびKafka Connect
Confluentは、データを連続的なリアルタイムストリームとして簡単にアクセス、保存、管理できる、包括的なデータストリーミングプラットフォームです。これにより、Apache Kafkaの利点が企業レベルの機能で拡張されます。Confluentを使用すると、モダンなイベント駆動型アプリケーションを構築しやすくなり、スケーラビリティ、パフォーマンス、信頼性をサポートする汎用データパイプラインを得ることができます。
Kafka Connectは、Apache Kafkaと他のデータシステム間でデータをスケーラブルかつ信頼性よくストリーミングするツールです。大量のデータセットをKafkaに入出力するコネクタを簡単に定義できます。データベース全体や、アプリケーションサーバーからのメトリクスをKafkaトピックに取り込み、低遅延でストリーム処理できるようにします。
Kafka Connectには2種類のコネクタが含まれています:
- ソースコネクタ: ソースコネクタは、データベース全体を取り込み、テーブル更新をKafkaトピックにストリーム配信します。また、アプリケーションサーバーからのメトリクスを収集し、Kafkaトピックに保存して、低遅延でストリーム処理できるようにします。
- シンクコネクタ: シンクコネクタは、Kafkaトピックからのデータをセカンダリインデックス(例: Elasticsearch)やバッチシステム(例: Hadoop)に配信し、オフライン分析を行います。
Dockerでのサービスセットアップ
このラボでは、Dockerを使用します。
環境が以下の前提条件を満たしていることを確認してください:
- Linux、Mac、またはWindows用のDocker。
- 注意: DockerでのScyllaDBの実行は、ScyllaDBの評価や試用にのみ推奨されます。
- ScyllaDBオープンソース。最高のパフォーマンスを得るためには、通常のインストールが推奨されます。
- KafkaおよびScyllaDBサービスのために8 GB以上のRAM。
- docker-compose
- Git
ScyllaDBインストールとテーブル初期化
まず、3ノードのScyllaDBクラスタを起動し、CDCが有効なテーブルを作成します。
まだ行っていない場合は、gitからサンプルをダウンロードしてください:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_Labこれは使用するdocker-composeファイルです。3ノードのScyllaDBクラスタを起動します:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0ScyllaDBクラスタを起動します:
docker-compose -f docker-compose-scylladb.yml up -d1分ほど待ってから、ScyllaDBクラスタが起動して通常の状態になっていることを確認してください:
docker exec scylla-node1 nodetool status次に、cqlshを使用してScyllaDBと対話します。キースペースを作成し、CDCが有効なテーブルを作成し、テーブルに行を挿入します:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- アドレス ロード トークン 所有 ホストID ラック
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Confluentセットアップとコネクタ構成
Kafkaサーバーを起動するために、トピックやメッセージを追跡するためのユーザーフレンドリーなWeb GUIを提供するConfluentプラットフォームを使用します。Confluentプラットフォームは、サービスを設定するためのdocker-compose.ymlファイルを提供します。
注意:これは、本番でApache Kafkaを使用する方法ではありません。例はトレーニングと開発の目的のみに役立ちます。ファイルを取得してください:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.yml次に、ScyllaDB CDCコネクタをダウンロードします:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarScyllaDBのCDCコネクタをDockerボリュームを使用してConfluent connectサービスプラグインディレクトリに追加するために、docker-compose-confluent.ymlを編集し、以下の2行を追加します。scylla-cdc-plugin.jarファイルのディレクトリを置き換えてください。
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryConfluentサービスを起動します:
docker-compose -f docker-compose-confluent.yml up -d1分ほど待ってから、ConfluentのWeb GUIにアクセスするためにhttp://localhost:9021にアクセスしてください。
Confluentダッシュボードを使用してScyllaConnectorを追加します:
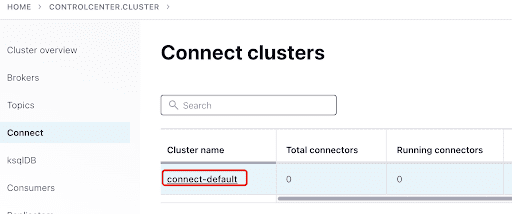
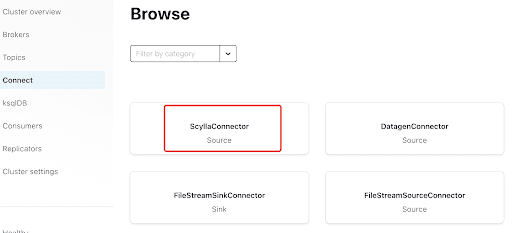
プラグインをクリックしてScyllaコネクタを追加します:
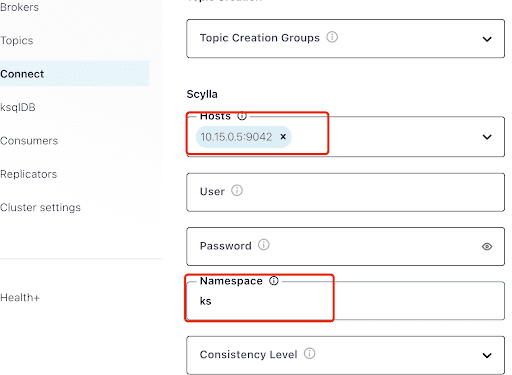
“Hosts”には、ScyllaノードのIPアドレス(nodetool statusコマンドの出力で確認可能)と、ScyllaDBサービスがリッスンしているポート9042を設定します。
“Namespace”は、以前ScyllaDBで作成したキースペースです。
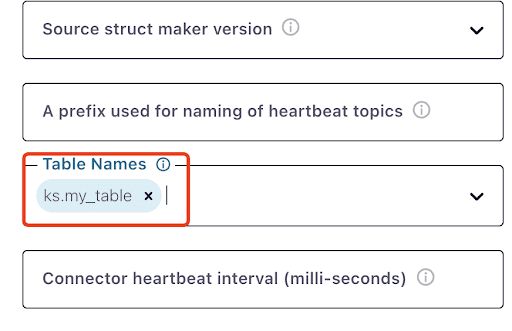
ks.my_tableが表示されるまで1分ほどかかることに注意してください:
Kafkaメッセージをテストします
MyScyllaCluster.ks.my_tableがScyllaDB CDCコネクタによって作成されたトピックであることがわかります。
次に、トピックセクションからKafkaメッセージを確認してください:
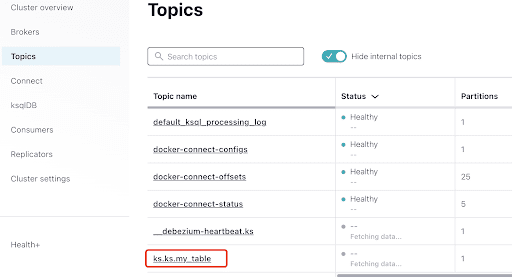
トピックを選択します。これは、ScyllaDBで作成したキースペースとテーブル名と同じです:
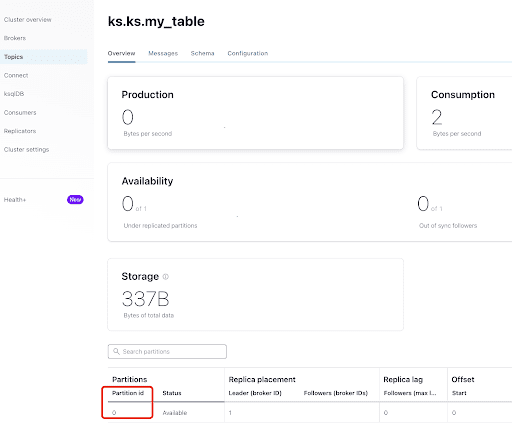
“Overview”タブから、トピックの情報を確認できます。下部には、このトピックがパーティション0にあることが表示されます。
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
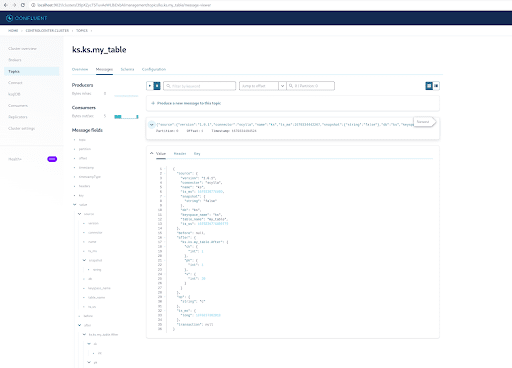
既にご存知かと思いますが、ScyllaDBのCDCメッセージはks.my_tableトピックに送信され、そのトピックのパーティションIDは0です。次に、「Messages」タブに移動し、パーティションID 0を「offset」フィールドに入力してください:
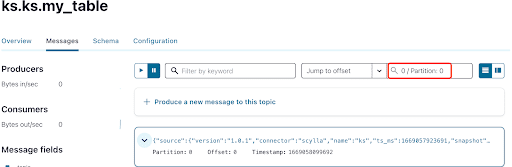
Kafkaトピックメッセージの出力から、ScyllaDBテーブルのINSERTイベントとデータがScylla CDCソースコネクタによってKafkaメッセージに転送されたことがわかります。メッセージをクリックして完全なメッセージ情報を表示してください:
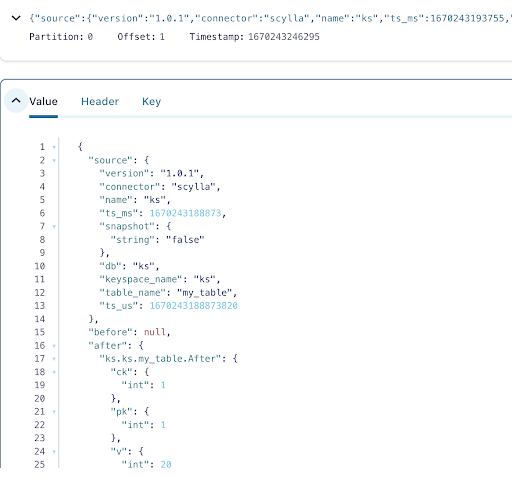
メッセージには、操作前後のデータステータスとともに、時間、ScyllaDBテーブル名、およびキースペース名が含まれています。これが挿入操作であるため、挿入前のデータはnullです。
次に、ScyllaDBテーブルに別の行を挿入します:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);そして、Kafkaで数秒待つと、新しいメッセージの詳細が表示されます:
クリーンアップ
このラボの作業が完了したら、Dockerコンテナとイメージを停止して削除できます。
すべてのコンテナIDのリストを表示するには:
docker container ls -aq次に、使用しなくなったコンテナを停止して削除できます:
docker stop <ID_or_Name>
docker rm <ID_or_Name>後でラボを再実行する場合は、手順に従って前回と同様にdocker-composeを使用できます。
まとめ
CDCソースコネクタを使用することで、Kafka Connectと互換性のあるKafkaプラグインを通じて、ScyllaDBテーブルの行レベルの変更(INSERT、UPDATE、またはDELETE)をすべてキャプチャし、それらのイベントをKafkaメッセージに変換できます。その後、他のアプリケーションからデータを消費したり、Kafkaで他の操作を実行したりできます。
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb