













ログは企業のデータ資産の大部分を占めることが多く、ビジネスログ(ユーザーアクティビティログなど)やサーバー、データベース、ネットワークやIoTデバイスのオペレーション・アンド・メンテナンスログなどがその例として挙げられます。
ログはビジネスの守護天使とも言えます。一方で、システムリスクの警告を提供し、トラブルシューティング時にエンジニアが根本原因を迅速に特定するのに役立ちます。他方で、時間範囲で拡大して見ると、有益なトレンドやパターンを見つけることができるかもしれません。また、ビジネスログはユーザー洞察の礎であることは言うまでもありません。
しかし、ログは以下の理由から手間がかかることがあります:
- 大量の流入。システムイベントやユーザーのクリックのたびにログが生成され、企業はよく一日に数千億の新しいログを生成します。
- 容量が大きい。ログは保持されるべきで、それが役立つ時までは無駄に見えるかもしれません。その結果、企業はPB単位のログデータを蓄積することがあり、その多くはほとんどアクセスされず、巨大なストレージスペースを消費します。
- 迅速に読み込みと検索が必要。トラブルシューティングのために対象のログを見つけることは、まさに干し草の山で針を探すようなものです。人々はリアルタイムのログ書き込みとリアルタイムのログクエリ応答を望んでいます。
これで理想的なログ処理システムがどのようなものか明確になりました。以下の機能をサポートするべきです:
- 高スループットのリアルタイムデータ取り込み。大量のログを書き込み、即座に表示可能であるべきです。
- 低コストストレージ。膨大な量のログを保存できるだけでなく、リソースを多く消費せずに済むようにする必要があります。
- リアルタイムテキスト検索: 迅速なテキスト検索が可能であるべきです。
一般的なソリューション: Elasticsearch と Grafana Loki
業界内で一般的なログ処理ソリューションとして、Elasticsearch と Grafana Loki がそれぞれ代表的です。
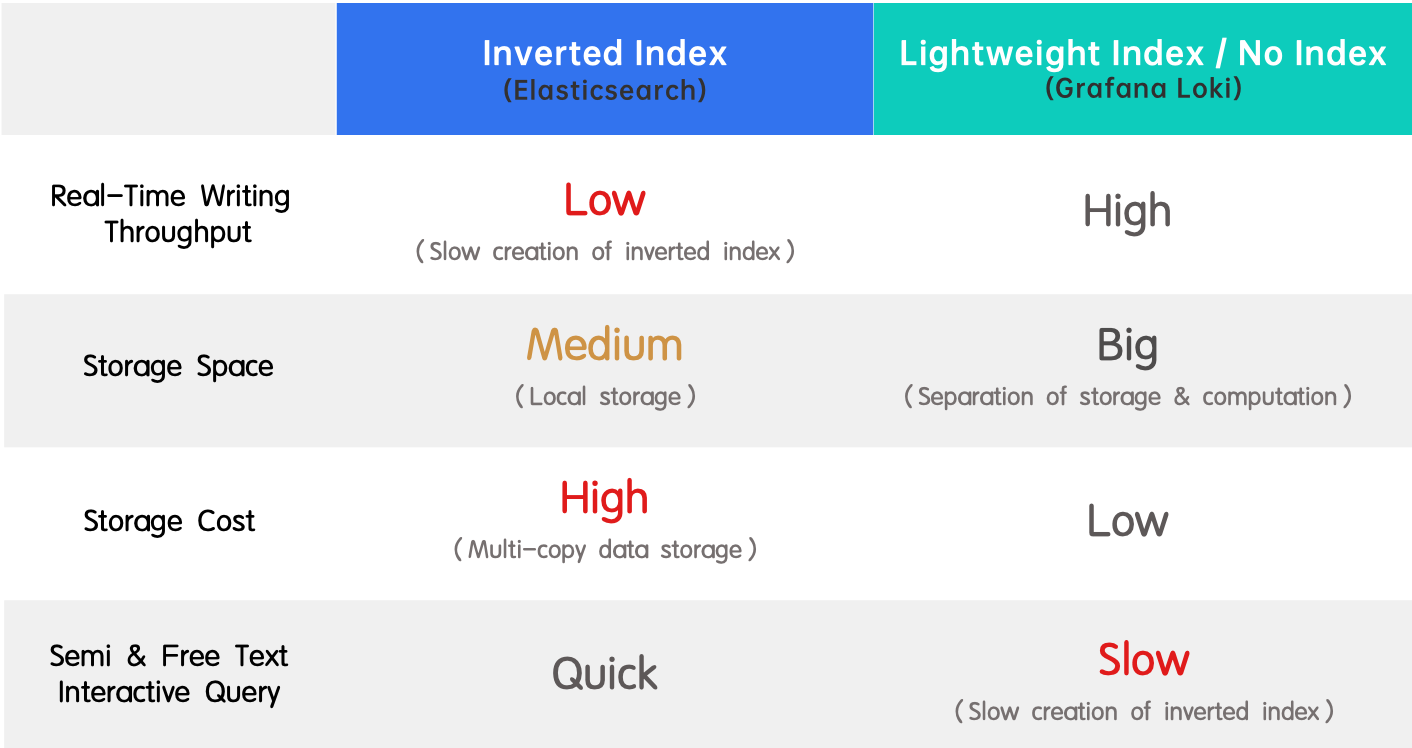
- 逆インデックス(Elasticsearch): 全文検索のサポートと高いパフォーマンスのため広く受け入れられています。一方で、リアルタイムの書き込みスループットが低く、インデックス作成には大きなリソース消費が伴います。
- 軽量インデックス/インデックスなし(Grafana Loki): 逆インデックスとは対照的に、リアルタイムの書き込みスループットが高く、ストレージコストが低いが、クエリが遅くなります。
逆インデックスの紹介
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
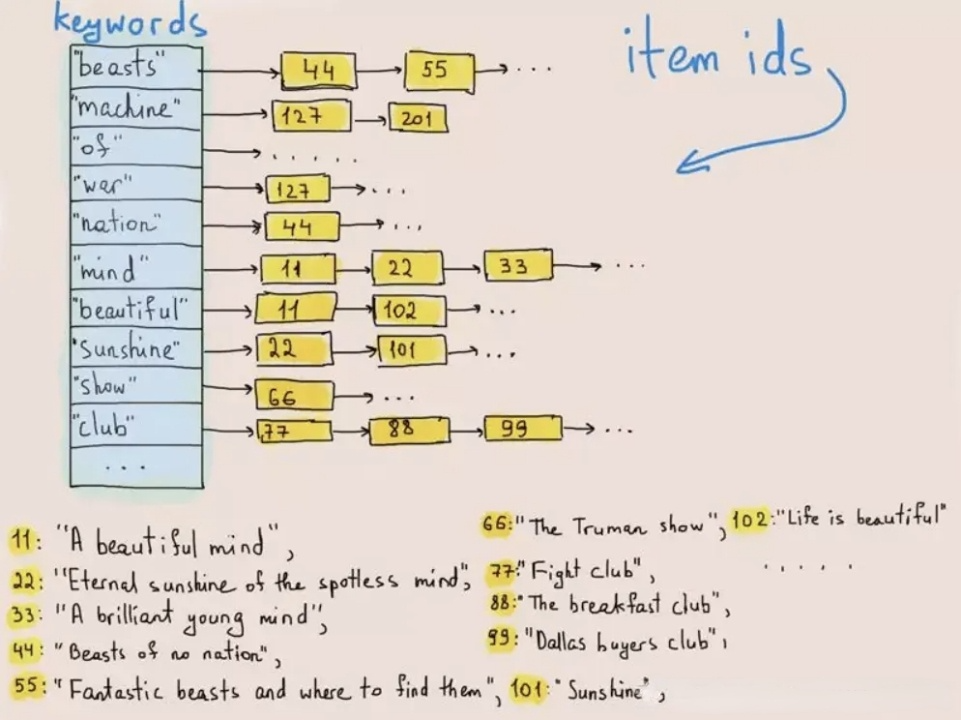
逆インデックスは、元々テキスト内の単語やフレーズを検索するために使用されていました。以下の図はその動作を示しています。
データ書き込み時に、システムはテキストを用語にトークン化し、これらの用語をポスティングリストに格納します。これは用語を存在する行のIDにマッピングします。テキスト検索時には、データベースがポスティングリスト内のキーワード(用語)に対応する行IDを見つけ、行IDに基づいて対象の行を取得します。この方法により、システムはデータセット全体を走査する必要がなくなり、クエリ速度を桁違いに向上させることができます。
Elasticsearchの逆インデックスでは、迅速な検索が書き込み速度、書き込みスループット、およびストレージスペースのコストを伴う。なぜなら、トークン化、辞書のソート、逆インデックスの作成はすべてCPUおよびメモリ集中的な操作であるためです。第二に、Elasticsearchは元のデータ、逆インデックス、そしてクエリの高速化のために列に保存されたデータの余分なコピーをすべて保存する必要があります。これは三重の冗長性です。
しかし、逆インデックスがない場合、例えばGrafana Lokiはクエリの遅さでユーザーエクスペリエンスを損なっており、これがログ分析におけるエンジニアの最大の痛みです。
要するに、ElasticsearchとGrafana Lokiは高い書き込みスループット、低いストレージコスト、そして迅速なクエリパフォーマンスの間のトレードオフを表しています。それらすべてを持つ方法があると言ったらどうでしょうか?私たちはApache Doris 2.0.0に逆インデックスを導入し、さらに最適化して、Elasticsearchよりもログクエリのパフォーマンスが2倍速く、使用するストレージスペースが5分の1であることを実現しました。これらの要因を組み合わせると、それは10倍優れたソリューションです。
Apache Dorisにおける逆インデックス
一般的に、インデックスを実装する方法は2つあります:外部インデックスシステムまたは組み込みインデックスです。
外部インデックスシステム: データベースに外部インデックスシステムを接続します。データ取り込み時に、データは両方のシステムに取り込まれます。インデックスシステムがインデックスを作成した後、その内部の元のデータを削除します。データユーザーがクエリを入力すると、インデックスシステムは関連するデータのIDを提供し、その後データベースはIDに基づいて対象データを検索します。
外部インデックスシステムを構築することは、データベースへの侵入性が低く、簡単ですが、いくつかの厄介な欠点があります:
- データを二つのシステムに書き込む必要があるため、データの不整合やストレージの冗長性が発生する可能性があります。
- データベースとインデックスシステムの間の相互作用はオーバーヘッドを引き起こすため、対象データが膨大な場合、二つのシステム間でのクエリは遅くなる可能性があります。
- 二つのシステムを維持することは消耗的です。
Apache Dorisでは、別の方法を選択しています。組み込みの逆インデックスは作成がより困難ですが、一度完成すると、より高速で、ユーザーフレンドリーで、維持が煩わしくないです。
Apache Dorisでは、データは以下の形式で配置されています。インデックスはインデックスゾーンに格納されています:
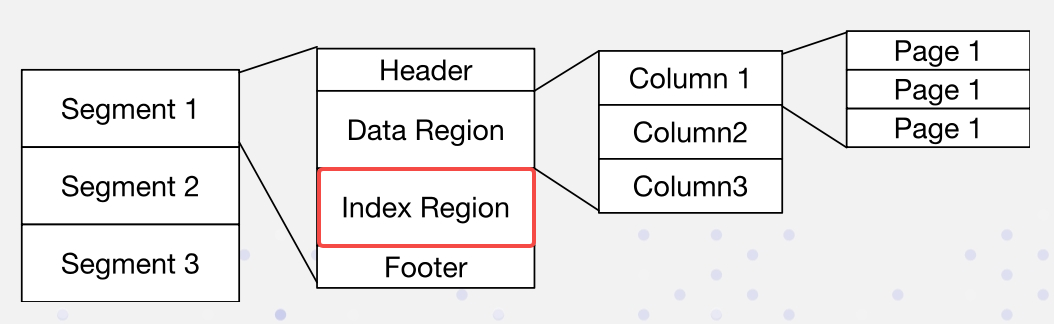
非侵入的な方法で逆インデックスを実装しています:
- データ取り込みと圧縮:セグメントファイルがDorisに書き込まれると、逆インデックスファイルも書き込まれます。インデックスファイルのパスはセグメントIDとインデックスIDによって決定されます。セグメント内の行はインデックス内のドキュメントに対応し、RowIDとDocIDも同様に対応しています。
- クエリ: もし
where句に逆インデックスを持つカラムが含まれている場合、システムはインデックスファイルを検索し、DocIDリストを返し、そのDocIDリストをRowIDビットマップに変換します。Apache DorisのRowIDフィルタリングメカニズムの下では、対象の行だけが読み取られます。これがクエリを高速化する方法です。
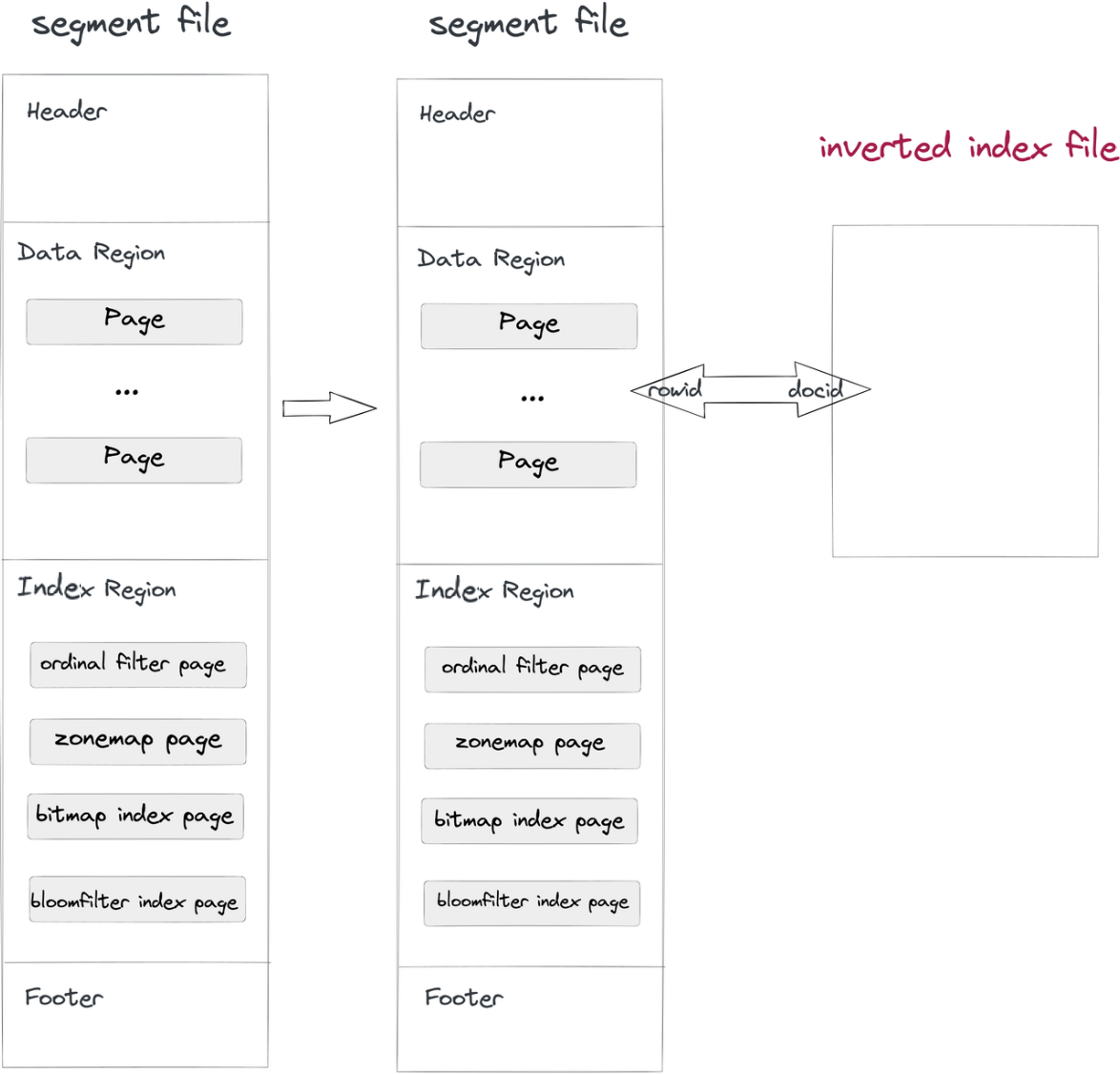
このような非侵襲的な方法で、インデックスファイルはデータファイルから分離されるため、逆インデックスに対する変更を行っても、データファイル自体や他のインデックスに影響を与えることはありません。
逆インデックスの最適化
一般的な最適化
C++ Implementation and Vectorization
ElasticsearchがJavaを使用するのとは異なり、Apache Dorisはそのストレージモジュール、クエリ実行エンジン、および逆インデックスでC++を実装しています。Javaと比較して、C++はより優れたパフォーマンスを提供し、より容易なベクタライゼーションが可能であり、JVM GCオーバーヘッドも発生しません。Apache Dorisでは、トークン化、インデックス作成、クエリなど、逆インデックスの各ステップをベクタライズしています。視点を提供するために、逆インデックスでは、Apache Dorisは各コアあたり20MB/sの速度でデータを書き込み、これはElasticsearchの4倍(5MB/s)です。
列指向ストレージと圧縮
Apache LuceneはElasticsearchにおける逆インデックスの基盤を築いています。Lucene自体はファイルストレージをサポートするために構築されており、データを行指向の形式で保存しています。
Apache Dorisでは、異なるカラムの逆インデックスは互いに隔離されており、逆インデックスファイルはベクタライゼーションとデータ圧縮を容易にするために列指向ストレージを採用しています。
Zstandard圧縮を利用することで、Apache Dorisは5:1から10:1の圧縮率を実現し、GZIP圧縮よりも高速な圧縮速度と50%のスペース使用量の削減を達成しています。
数値/日時列のBKDツリー
Apache Dorisは数値列と日時列に対してBKDツリーを実装しており、範囲クエリのパフォーマンスを向上させるだけでなく、それらの列を固定長文字列に変換する方法よりもスペース効率が良くなっています。その他の利点には以下があります:
- 効率的な範囲クエリ: 数値列と日時列内の対象データ範囲を迅速に特定できます。
- 少ないストレージスペース: 隣接するデータブロックを集約・圧縮し、ストレージコストを削減します。
- 多次元データのサポート: BKDツリーはGEOポイントや範囲などの多次元データ型に対して拡張性があり、適応的です。
BKDツリーに加えて、数値列と日時列上のクエリをさらに最適化しています。
- 低基礎数シナリオの最適化: 低基礎数シナリオのための圧縮アルゴリズムを微調整し、大量のインバースリストの展開と逆シリアル化によるCPUリソース消費を抑えています。
- プリフェッチング: 高ヒット率シナリオに対してプリフェッチングを採用。ヒット率が一定のしきい値を超える場合、Dorisはインデックス作成プロセスをスキップし、データフィルタリングを開始します。
OLAPに特化した最適化
通常、ログ分析は高度な機能(例えば、Apache Luceneにおける関連性スコアリング)を必要としない単純なクエリです。ログ処理ツールの基本となる機能は、迅速なクエリと低いストレージコストです。したがって、Apache Dorisでは、OLAPデータベースのニーズに応えるために、逆インデックス構造を最適化しました。
- データ取り込み時に、複数のスレッドが同じインデックスにデータを書き込むことを防止し、ロック競合によるオーバーヘッドを回避します。
- フォワードインデックスファイルとNormファイルを破棄してストレージスペースをクリアし、I/Oオーバーヘッドを削減します。
- 関連性スコアリングとランキングの計算ロジックを簡略化し、さらにオーバーヘッドを削減し、パフォーマンスを向上させます。
ログが時間範囲でパーティション化され、履歴ログのアクセス頻度が低いという事実に鑑みて、Apache Dorisの将来のバージョンでは、より粒度の細かく柔軟なインデックス管理を提供する予定です:
- 指定されたデータパーティションに対して逆インデックスを作成: 過去7日分のログなどにインデックスを作成します。
- 指定されたデータパーティションの逆インデックスを削除: 1ヶ月以上前のログなどのインデックスを削除します(インデックススペースをクリアするため)。
ベンチマーク
Apache DorisをオープンデータセットでElasticsearchとClickHouseと比較してテストしました。
公平な比較のために、ベンチマークツール、データセット、ハードウェアの統一を確保します。
Apache Doris vs. Elasticsearch
- ベンチマーキングツール: ES Rally、Elasticsearchの公式テストツール
- データセット: 1998年のワールドカップHTTPサーバーログ(ES Rally内に含まれる自己完結型データセット)
- 圧縮前のデータサイズ: 32G、2億4700万行、平均134バイト/行
- クエリ: 11種類のクエリ、キーワード検索、範囲クエリ、集計、ランキングを含む;各クエリは100回連続実行される。
- 環境: 3つの16C 64Gクラウド仮想マシン
Apache Dorisの結果:
- 書き込み速度: 550 MB/s、Elasticsearchの4.2倍
- 圧縮率: 10:1
- ストレージ使用量: Elasticsearchの20%
- 応答時間: Elasticsearchの43%

Apache Doris対ClickHouse
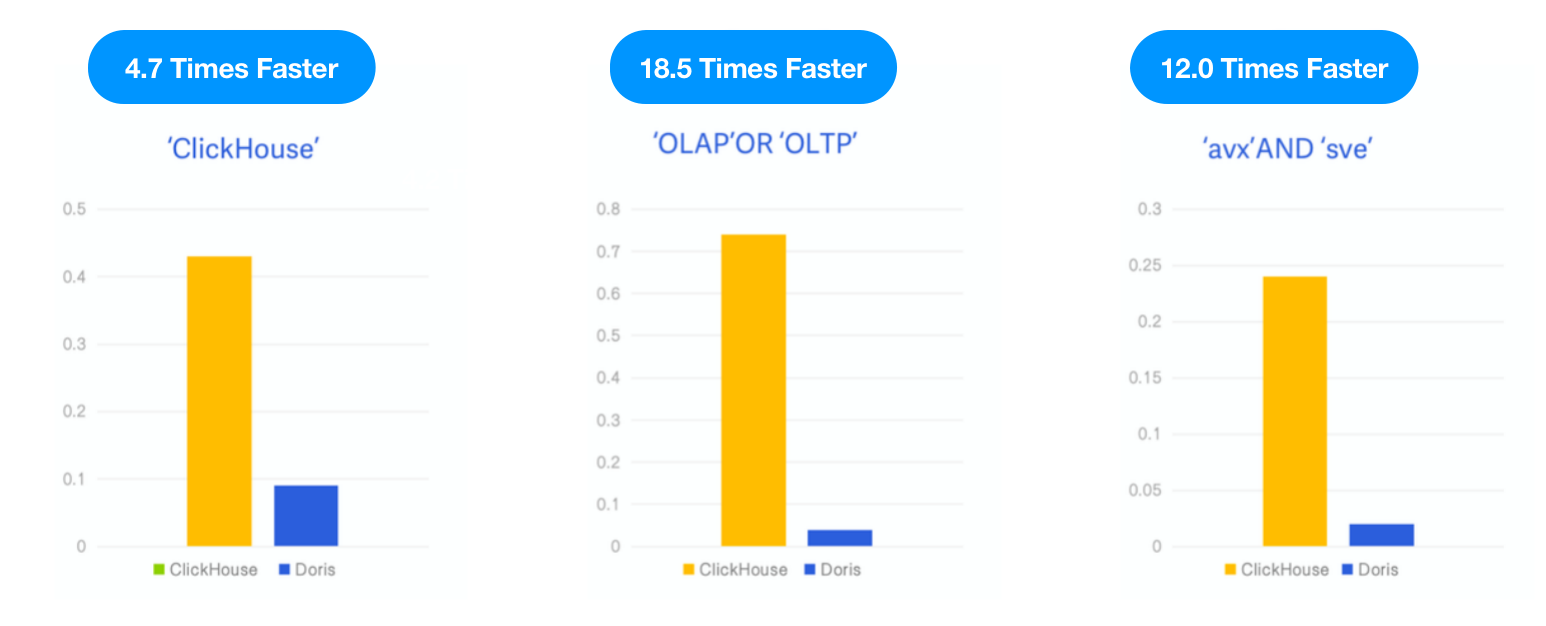
ClickHouseがv23.1で逆インデックスを実験的機能としてリリースしたため、同じデータセットとSQLを使用してApache DorisをClickHouseのブログで説明されているとおりにテストし、同じテストリソース、ケース、ツールの下で両者のパフォーマンスを比較しました。
- データ: 6.7G、2873万行、Hacker Newsデータセット、Parquet形式
- クエリ: 3種類のキーワード検索、キーワード”ClickHouse”、”OLAP”、”OLTP”、”avx”および”sve”の出現回数をカウント。
- 環境: 1つの16C 64Gクラウド仮想マシン
結果: Apache Dorisは、3つのクエリにおいてそれぞれClickHouseより4.7倍、18.5倍、12倍速かった。
使用法と例
- データセット: Hacker Newsからの100万件のコメントレコード
ステップ1: テーブル作成時に逆インデックスをデータテーブルに指定する。
パラメータ:
- INDEX idx_comment (
comment): “comment”列に”idx_comment”という名前のインデックスを作成 - USING INVERTED: テーブルに逆インデックスを指定
- PROPERTIES(“parser” = “english”): トークン化言語を英語に指定
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(注: 既存のテーブルにインデックスを追加するにはADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english")を使用できます。スマートインデックスやセカンダリインデックスとは異なり、逆インデックスの作成はコメント列の読み取りのみを含むため、はるかに高速です。)
ステップ2: MATCH_ALLを使用してコメント列から”OLAP”および”OLTP”という単語を検索。ここでの応答時間は、likeでのハードマッチングの1/10でした。(データ量が増加するとパフォーマンスの差が広がります。)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
詳細な機能紹介と使用ガイドについては、ドキュメントを参照してください: 逆インデックス
まとめ
一言で言えば、Apache DorisがElasticsearchよりも10倍のコストパフォーマンスを持つ理由は、逆インデックスに対するOLAP特化最適化によるものであり、これは列指向ストレージエンジン、大規模並列処理フレームワーク、ベクトル化クエリエンジン、そしてApache Dorisのコストベース最適化プログラムによってサポートされています。
私たちの逆インデックスソリューションに対する自慢はありますが、自社発表のベンチマークは議論の余地があることを理解しており、第三者のテスターからのフィードバックに対してオープンであり、Apache Dorisが実世界のケースでどのように機能するかを見ていきたいと考えています。
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co