













これは不動産大手のデジタル変革の一部です。機密性のため、ビジネスデータは明かしませんが、データ倉庫と最適化戦略について詳細にご紹介します。
では始めましょう。
アーキテクチャ
論理的には、私たちのデータアーキテクチャは四つの部分に分けられます。
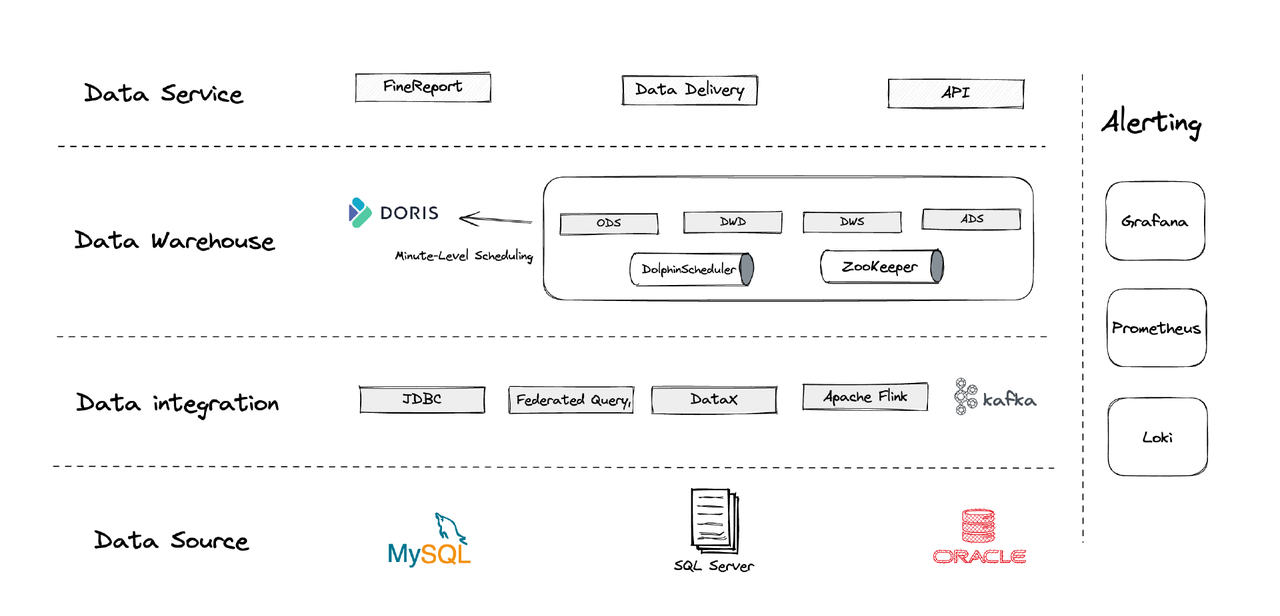
- データ統合: Flink CDC、DataX、Apache DorisのMulti-Catalog機能でサポートされています。
- データ管理: Apache Dolphinschedulerを使用してスクリプトのライフサイクル管理、マルチテナント管理の権限、データ品質の監視を行います。
- アラート: Grafana、Prometheus、Lokiを使用してコンポーネントリソースとログを監視します。
- データサービス: BIツールがユーザーとのインタラクションに登場し、データ照会や分析などを行います。
1. テーブル
私たちは、顧客や家屋などの各営業主体を中心にした次数テーブルとファクトテーブルを作成しています。同一の営業主体を含む一連の活動がある場合、それらは一つのフィールドで記録されるべきです。(これは以前の混乱したデータ管理システムから学んだ教訓です。)
2. レイヤー
私たちのデータ倉庫は五つの概念的なレイヤーに分けられており、Apache DorisとApache DolphinSchedulerを使用してこれらのレイヤー間でDAGスクリプトをスケジュールしています。

毎日、レイヤーは歴史的なステータスフィールドの変更やODSテーブルの不完全なデータ同期の場合に加えて、全体的な更新を行います。
3. インクリメンタル更新戦略
(1) セット where >= "activity time -1 day or -1 hour" 代わりにwhere >= "activity time
これを行う理由は、スケジューリングスクリプトの時間ギャップによるデータドリフトを防ぐためです。例えば、実行間隔を10分に設定し、スクリプトが23:58:00に実行され、新しいデータが23:59:00に到着したとします。where >= "activity timeを設定すると、その日のデータが見落とされます。
(2) スクリプトの実行前にテーブルの最大プライマリーキーのIDを取得し、そのIDを補助テーブルに格納し、セットwhere >= "ID in auxiliary table"
これはデータの重複を避けるためです。Apache Dorisのユニークキーモデルを使用し、プライマリーキーのセットを指定すると、ソーステーブルのプライマリーキーに変更がある場合、その変更が記録され、関連するデータがロードされる可能性があります。この方法は、ソーステーブルが自動インクリメントプライマリーキーを持つ場合にのみ適用可能です。
(3) テーブルをパーティション分割
タイムベースの自動インクリメントデータ(ログテーブルなど)に関しては、履歴データやステータスの変更が少ない場合もありますが、データ量が膨大であるため、全体的な更新やスナップショットの作成に大きな計算圧力がかかる可能性があります。そのため、このようなテーブルをパーティション化する方が良く、各インクリメント更新では1つのパーティションのみを置き換えればよいのです。(データのズレにも注意が必要です。)
4. 全体的な更新戦略
(1) テーブルのトランケート
テーブルをクリアしてから、ソーステーブルから全データを取り込みます。これは小さなテーブルや、早朝にユーザーの活動がないシナリオに適用可能です。
(2) ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
これはアトミック操作であり、大きなテーブルにおすすめです。スクリプトを実行するたびに、同じスキーマの一時テーブルを作成し、全データをロードしてから、元のテーブルをそれで置き換えます。
アプリケーション
- ETLジョブ: 毎分
- 初回展開の設定: 8ノード、2フロントエンド、8バックエンド、ハイブリッド展開
- ノードの設定: 32C * 60GB * 2TB SSD
これは、テラバイト規模のレガシーデータとギガバイト規模のインクリメントデータに対する私たちの設定です。参考としてご利用いただけますし、この基盤でクラスターをスケールアウトすることも可能です。Apache Dorisの展開は簡単で、他のコンポーネントは必要ありません。
1. オフラインデータとログデータを統合するために、DataXを使用しています。DataXはCSV形式や多くのリレーショナルデータベースのリーダーをサポートし、Apache DorisはDataX-Doris-Writerを提供しています。

2. Flink CDCを使用して、ソーステーブルからデータを同期します。そして、Apache Dorisのマテリアライズドビューや集約モデルを利用してリアルタイムのメトリクスを集約します。リアルタイムで処理するメトリクスの一部だけであり、データベース接続を多く生成したくないため、1つのFlinkジョブで複数のCDCソーステーブルを維持しています。これはDinkyのマルチソースマージングとフルデータベース同期機能で実現されており、またFlink DataStreamのマルチソースマージングタスクを自分で実装することも可能です。Flink CDCとApache Dorisはスキーマ変更をサポートしていることに注意してください。
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. SQLスクリプトや”Shell + SQL”スクリプトを使用し、スクリプトのライフサイクル管理を行います。ODS層では、一般的なDataXジョブファイルを書き、各ソーステーブルのインジェストのパラメータを渡すことで、各ソーステーブルごとにDataXジョブを書くのではなく、保守が非常に簡単になるようにしています。Apache DorisのETLスクリプトをDolphinSchedulerで管理し、バージョン管理も行っています。本番環境でエラーが発生した場合、いつでもロールバックすることができます。
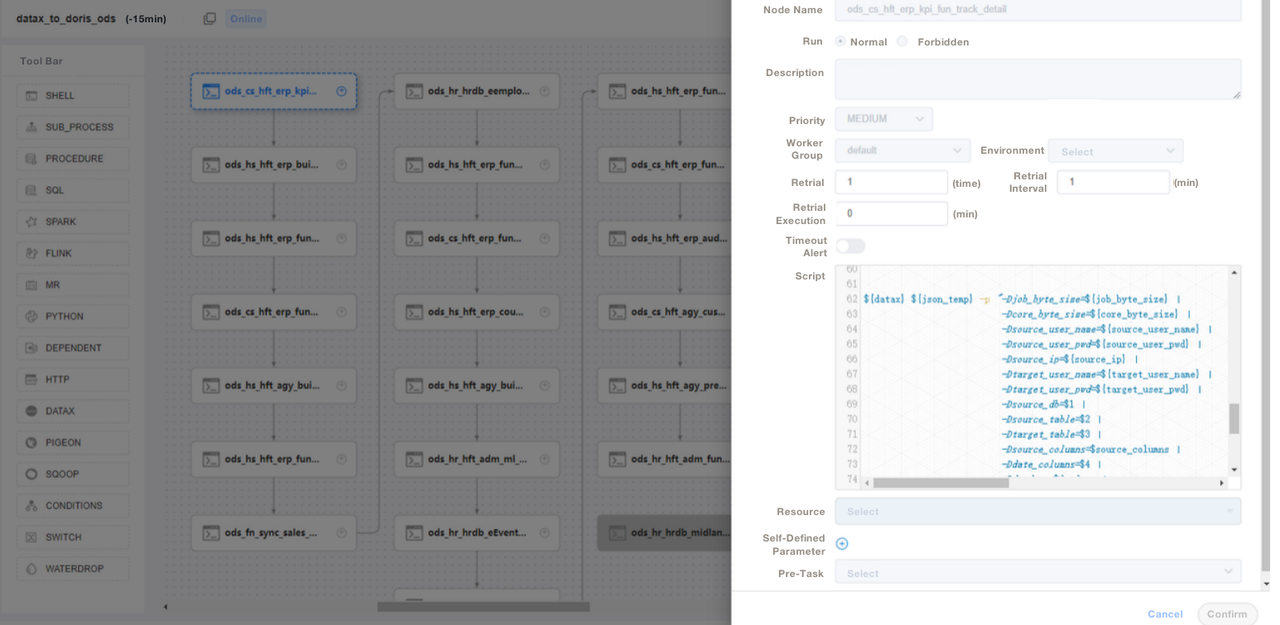
4. ETLスクリプトでデータをインジェストした後、レポートツールにページを作成します。SQLを使用して異なるアカウントに異なる権限を割り当てます。これには行、フィールド、グローバルディクショナリの変更権限も含まれます。Apache Dorisはアカウントに対する権限制御をサポートしており、MySQLと同様に機能します。
また、Apache Dorisのデータバックアップを災害復旧に使用し、Apache Dorisの監査ログをSQL実行効率の監視に活用しています。クラスタのメトリックアラートにはGrafana+Lokiを、ノードコンポーネントのデーモンプロセスの監視にはSupervisorを利用しています。
最適化
データ取り込み
DataXを使用してオフラインデータをストリームロードしています。これにより、各バッチのサイズを調整できます。ストリームロード方法は結果を同期して返すため、アーキテクチャのニーズに合わせています。もしDolphinSchedulerを使用して非同期データインポートを実行すると、システムがスクリプトが実行されたと判断し、混乱を引き起こす可能性があります。別の方法を使用する場合は、show loadをシェルスクリプトで実行し、正規表現フィルタリングの状態を確認して取り込みが成功したかどうかを確認することをお勧めします。
データモデル
Apache Dorisのユニークキーモデルをほとんどのテーブルに採用しています。ユニークキーモデルはデータスクリプトの冪等性を保証し、上流データの重複を効果的に回避します。
外部データの読み取り
Apache Dorisのマルチカタログ機能を使用して外部データソースに接続しています。これにより、カタログレベルで外部データのマッピングを作成できます。
クエリ最適化
文字でない最も頻繁に使用されるフィールド(例えばintやwhere句)を最初の36バイトに配置することをお勧めします。これにより、ポイントクエリでこれらのフィールドをミリ秒単位でフィルタリングできます。
データ辞書
私たちにとって、データ辞書を作成することが重要です。なぜなら、これにより人的コミュニケーションコストが大幅に削減され、大きなチームであればあるほど頭を悩ませることがあります。私たちはApache Dorisのinformation_schemaを使用してデータ辞書を生成しています。これを利用することで、テーブルやフィールドの全体像を迅速に把握し、開発効率を向上させることができます。
パフォーマンス
オフラインデータ取り込み時間: 数分以内
クエリレイテンシー: 1億行以上のデータを含むテーブルに対して、Apache Dorisはカスタムクエリに1秒以内、複雑なクエリに5秒以内で応答します。
リソース消費: このデータ倉庫を構築するためには、少数のサーバーのみを必要とします。Apache Dorisの70%の圧縮率は、大量のストレージリソースを節約します。
経験と結論
実際、現在のデータアーキテクチャに進化する前に、Hive、Spark、Hadoopを試してオフラインデータ倉庫を構築しました。その結果、私たちのような伝統的な企業にとっては、Hadoopは過剰であり、扱うデータ量がそれほど多くなかったためです。最も適したコンポーネントを見つけることが重要です。
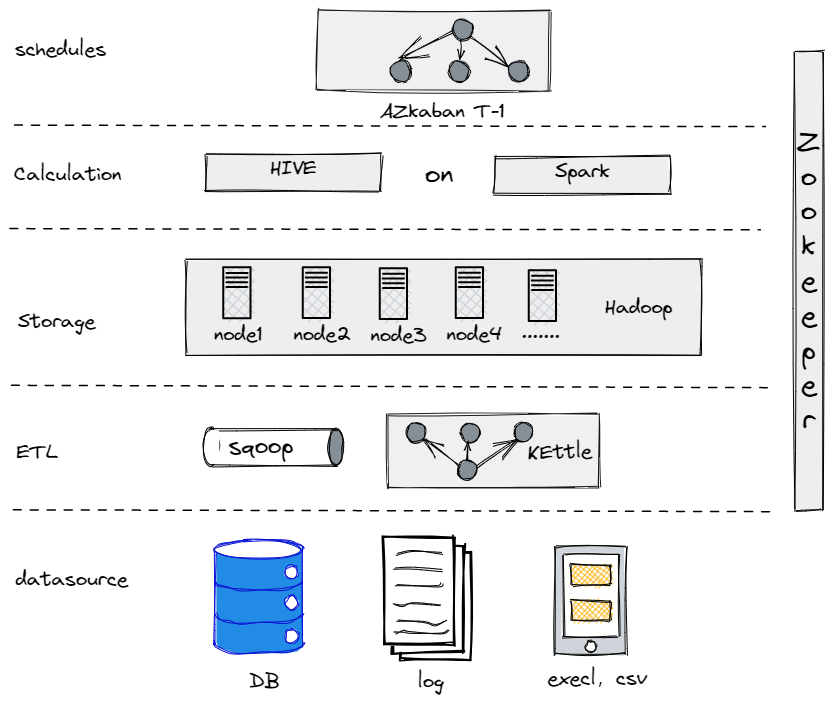
私たちの古いオフラインデータ倉庫
一方で、ビッグデータ移行をスムーズに進めるためには、データプラットフォームをできるだけ使いやすく、メンテナンスが簡単なものにしなければなりません。そこでApache Dorisに着地した理由です。MySQLプロトコルと互換性があり、豊富な機能群を提供しており、独自のUDFを開発する必要がないからです。また、フロントエンドとバックエンドの2種類のプロセスから構成されており、拡張性が高く、トラッキングも容易です。
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry