













エージェント型AIの台頭により、自律的にタスクを実行し、推奨事項を行い、AIと従来のコンピューティングを融合させた複雑なワークフローを実行するエージェントに対する興奮が高まっています。しかし、実際の製品志向の環境でこのようなエージェントを作成することは、AIそのものを超えるさまざまな課題を提起します。
注意深いアーキテクチャがなければ、コンポーネント間の依存関係がボトルネックを作り出し、スケーラビリティを制限し、システムが進化するにつれてメンテナンスを複雑化させる可能性があります。解決策は、エージェント、インフラストラクチャ、および他のコンポーネントが硬直した依存関係なしに柔軟にやり取りするワークフローの切り離しにあります。
この種の柔軟でスケーラブルな統合には、データ交換のための共有の「言語」が必要です。つまり、イベント駆動型アーキテクチャ(EDA)によって推進されるイベントのストリームが重要です。アプリケーションをイベントを中心に整理することで、エージェントは、それぞれが独立して作業を行うレスポンシブで切り離されたシステムで動作できます。チームは技術的な選択を自由に行い、スケーリングのニーズを別々に管理し、コンポーネント間の明確な境界を維持することができ、真のアジリティを実現できます。
これらの原則を実証するために、私はPodPrep AIを開発しました。PodPrep AIは、Software Engineering DailyとSoftware Huddleのポッドキャストインタビューの準備を手助けするAIパワードの研究アシスタントです。この投稿では、PodPrep AIの設計とアーキテクチャについて詳しく説明し、EDAとリアルタイムデータストリームが効果的なエージェントシステムを支える方法を示します。
コードをご覧になりたい場合は、私のGitHubリポジトリにアクセスしてください。こちらに移動してください。
なぜAIのためのイベント駆動型アーキテクチャなのか?
現実世界のAIアプリケーションでは、緊密に結合された一枚岩の設計は持たない。概念実証やデモでは、単一の統合システムを使用することが多いが、本番環境ではこのアプローチはすぐに実用的ではなくなる。緊密に結合されたシステムはボトルネックを作り出し、スケーラビリティを制限し、繰り返しを遅らせるため、AIソリューションが成長する際に避ける必要がある重要な課題です。
典型的なAIエージェントを考えてみましょう。
複数のソースからデータを取得し、プロンプトエンジニアリングとRAGワークフローを処理し、確定的なワークフローを実行するためにさまざまなツールと直接やり取りする必要があるかもしれません。必要なオーケストレーションは複雑で、複数のシステムへの依存があります。そして、エージェントが他のエージェントと通信する必要がある場合、複雑さはさらに増します。柔軟なアーキテクチャがないと、これらの依存関係はスケーリングや変更をほぼ不可能にします。

本番環境では、通常、異なるチームがスタックの異なる部分を担当します:MLOpsとデータエンジニアリングがRAGパイプラインを管理し、データサイエンスがモデルを選択し、アプリケーション開発者がインターフェースとバックエンドを構築します。緊密に結合された設定では、これらのチームを依存関係に迫られ、デリバリーを遅らせ、スケーリングを困難にします。理想的には、アプリケーション層はAIの内部を理解する必要はなく、必要な時に単に結果を消費すべきです。
さらに、AIアプリケーションは孤立して動作することはできません。真の価値を実現するためには、AIの洞察力は顧客データプラットフォーム(CDP)、CRM、分析などをシームレスに流れる必要があります。顧客とのやり取りはリアルタイムで更新をトリガーし、他のツールに直接供給されて行動と分析に直結するべきです。統一されたアプローチがないと、プラットフォーム間での洞察の統合は管理が難しく、スケーラビリティが不可能になります。
EDA(Event-Driven Architecture)によるAIは、データのための「中枢神経系」を作成することでこれらの課題に対処します。EDAでは、アプリケーションが連鎖的なコマンドに依存するのではなく、イベントをブロードキャストします。これにより、コンポーネントが切り離され、データが必要な場所に非同期に流れることが可能となり、各チームが独立して作業できるようになります。EDAは、シームレスなデータ統合、スケーラブルな成長、そして弾力性を促進し、現代のAI駆動システムの強力な基盤となります。
スケーラブルなAI駆動のリサーチエージェントの設計
過去2年間、私はSoftware Engineering Daily、Software Huddle、Partially Redactedなどで何百ものポッドキャストをホストしてきました。
各ポッドキャストに備えるために、私はゲストやトピックに関する背景、潜在的な質問のシリーズを含むポッドキャストの概要を準備するために、徹底的なリサーチプロセスを実施しています。この概要を作成するために、通常はゲストやその会社に関する情報を調査し、彼らが出演したかもしれない他のポッドキャストを聴いたり、彼らが書いたブログ記事を読んだり、私たちが議論する主要なトピックについて調べたりします。
他のポッドキャストとのつながりや、トピックや類似のトピックに関連する自分の経験を織り込もうとしています。この全プロセスにはかなりの時間と労力がかかります。大規模なポッドキャスト運営では、ホストのためにこの作業を行う専任の研究者やアシスタントがいますが、私はそのような運営を行っていません。すべて自分で行わなければなりません。
これに対処するため、私のためにこの作業を行うエージェントを構築したいと考えました。高レベルで見ると、エージェントは以下の画像のようなものになるでしょう。

私はゲストの名前、会社、焦点を当てたいトピック、ブログ記事や既存のポッドキャストなどの参照URLなどの基本的なソース資料を提供し、そこからAIの魔法が働き、私のリサーチが完了します。
このシンプルなアイデアから、トークンだけで利用できるAI駆動のリサーチアシスタント「PodPrep AI」を作成することになりました。
この記事の残りの部分では、PodPrep AIのデザインについて議論し、ユーザーインターフェースから始めます。
エージェントユーザーインターフェースの構築
私は、研究プロセスのためのソース資料を簡単に入力できるウェブアプリケーションとしてエージェントのインターフェースを設計しました。これには、ゲストの名前、その会社、インタビューのトピック、追加のコンテキスト、関連するブログ、ウェブサイト、以前のポッドキャストインタビューへのリンクが含まれます。
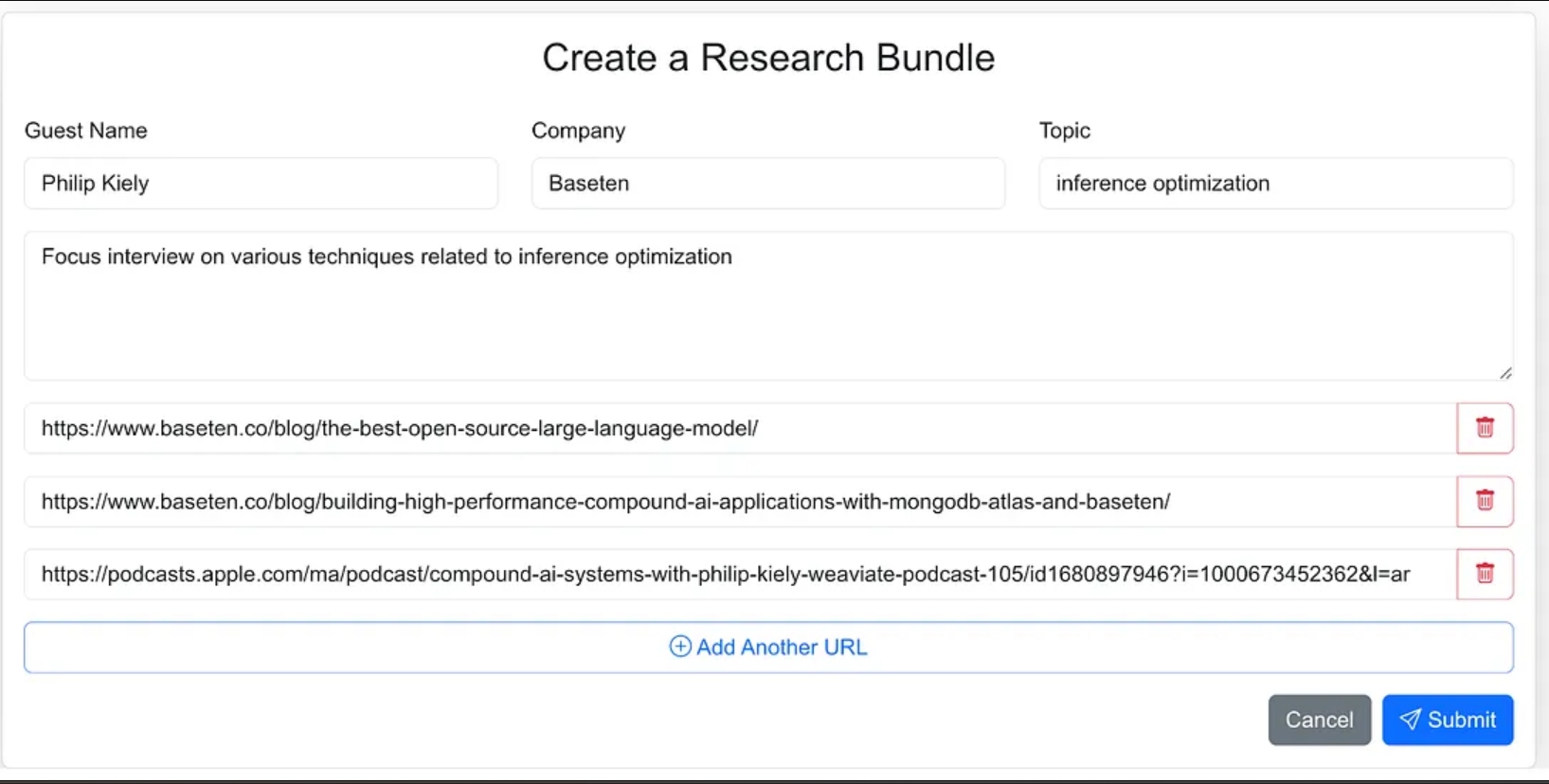
エージェントにあまり指示を与えず、エージェントのワークフローの一部としてソース資料を見つけさせることもできましたが、バージョン1.0ではソースURLを提供することに決めました。
Webアプリケーションは、Next.jsとMongoDBを使用して構築された標準の3層アプリケーションです。アプリケーションデータベースは
MongoDB

を使用しています。これはAIについては何も知りません。単純にユーザーが新しい研究バンドルを入力できるようにし、これらは処理中の状態になります。その後、エージェンティックプロセスがワークフローを完了し、アプリケーションデータベースに研究ブリーフを作成します。
AIマジックが完了すると、以下に示すエントリのブリーフィングドキュメントにアクセスできます。
- エージェンティックワークフローの作成
- バージョン1.0では、研究ブリーフを作成するために3つの主要なアクションを実行できるようにしたかった:
- 任意のWebサイトのURL、ブログ投稿、またはポッドキャストからテキストまたは要約を取得し、テキストを適切なサイズに切り分け、埋め込みを生成し、ベクトル表現を保存します。
研究ソースURLから抽出されたすべてのテキストから、最も興味深い質問を取り出して保存します。
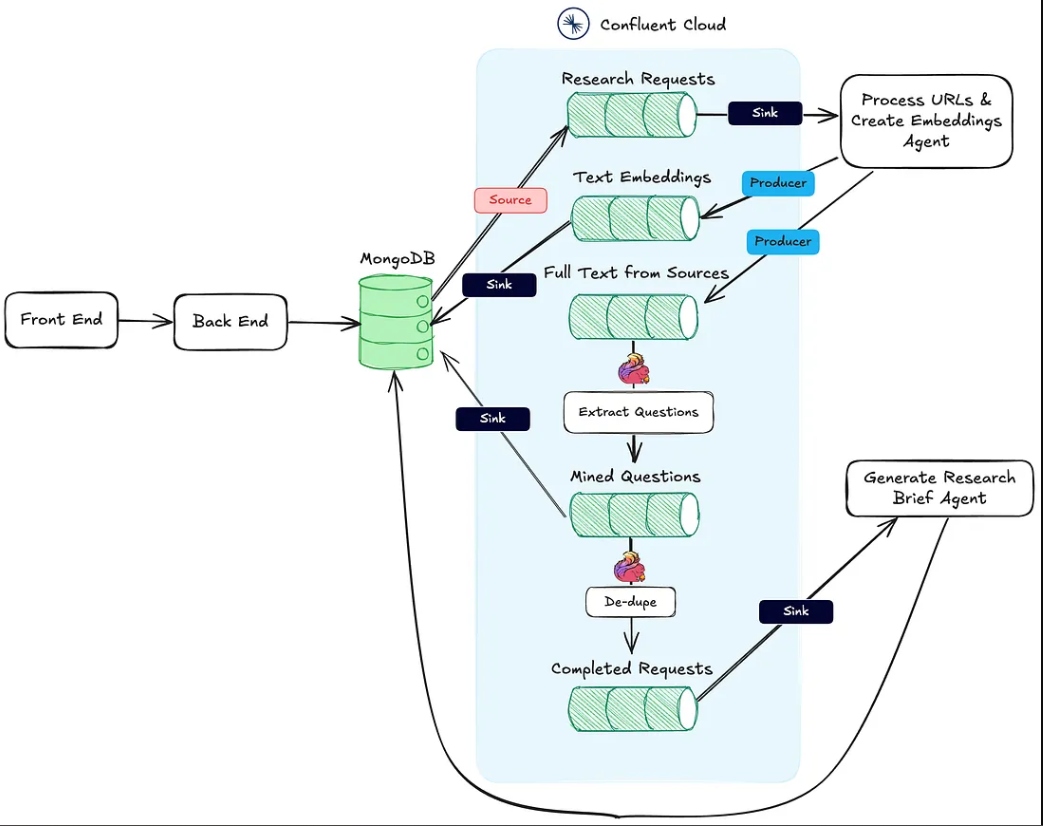
過去に行われた最良の質問に基づいた埋め込み、以前に行われた最良の質問に基づいた最も関連性の高いコンテキストを組み合わせたポッドキャスト研究ブリーフを生成します。以下の画像は、Webアプリケーションからエージェンティックワークフローまでのアーキテクチャを示しています。
上記のアクション#1は、
最後に、アクション #3 は リサーチブリーフエージェント によって実行されます。これはHTTPシンクエンドポイントでもあり、最初の2つのアクションが完了した後に呼び出されます。
次のセクションでは、これらのアクションそれぞれについて詳しく説明します。
プロセスURLと埋め込み作成エージェント
このエージェントは、リサーチソースURLからテキストを取得し、ベクトル埋め込みパイプラインを処理する責任があります。以下は、リサーチ資料を処理するための裏で行われている高レベルのフローです。

ユーザーがリサーチバンドルを作成し、MongoDBに保存すると、MongoDBソースコネクタがresearch-requestsというKafkaトピックにメッセージを生成します。これがエージェントのワークフローを開始します。
HTTPエンドポイントへの各POSTリクエストには、リサーチリクエストからのURLとMongoDBリサーチバンドルコレクション内のプライマリキーが含まれています。
エージェントは各URLをループ処理し、Appleポッドキャストでない場合は、フルページのHTMLを取得します。ページの構造がわからないため、関連するテキストを見つけるためにHTML解析ライブラリに依存することはできません。代わりに、必要な情報を得るために、以下のプロンプトを使用して温度ゼロでgpt-4o-miniモデルにページテキストを送信します。
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
ポッドキャストの場合、もう少し作業が必要です。
AppleポッドキャストURLのリバースエンジニアリング
ポッドキャストエピソードからデータを取得するには、まずWhisperモデルを使用して音声をテキストに変換する必要があります。しかし、その前に、各ポッドキャストエピソードの実際のMP3ファイルを特定し、ダウンロードして、25MB以下のチャンクに分割する必要があります(Whisperの最大サイズ)。
Appleはポッドキャストエピソードの直接のMP3リンクを提供していないという課題があります。ただし、MP3ファイルはポッドキャストの元のRSSフィードで利用可能であり、AppleのポッドキャストIDを使用してこのフィードをプログラムで見つけることができます。
たとえば、以下のURLでは、/idの後の数字部分がポッドキャストの固有のApple IDです:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
AppleのAPIを使用すると、ポッドキャストIDを検索し、RSSフィードのURLを含むJSONレスポンスを取得できます:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
一度RSSフィードXMLを取得すると、特定のエピソードを検索します。AppleからエピソードURLのみを持っているため、実際のタイトルではなくURLからのタイトルスラッグを使用して、フィード内のエピソードを特定し、そのMP3 URLを取得します。
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
ブログ投稿、ウェブサイト、およびMP3が利用可能な状態で、エージェントはLangChainの再帰文字テキスト分割機能を使用してテキストをチャンクに分割し、これらのチャンクから埋め込みを生成します。これらのチャンクはtext-embeddingsトピックに公開され、MongoDBにシンクされます。
- 注意: アプリケーションデータベースとベクトルデータベースの両方としてMongoDBを使用することにしました。ただし、私が取ったEDAアプローチのため、これらは簡単に別々のシステムにすることができ、Text Embeddingsトピックからのシンクコネクタを交換するだけの問題です。
埋め込みを作成・公開するだけでなく、エージェントはソースからのテキストもfull-text-from-sourcesというトピックに公開します。このトピックへの公開によってアクション#2が開始されます。
FlinkとOpenAIを使用して質問を抽出する
Apache Flinkは、リアルタイムで大量のデータを処理するために構築されたオープンソースのストリーム処理フレームワークであり、高スループットで低レイテンシのアプリケーションに最適です。FlinkをConfluentとペアにすることで、OpenAIのGPTなどのLLMをストリーミングワークフローに直接組み込むことができます。この統合により、リアルタイムのRAGワークフローが可能になり、質問抽出プロセスが最新のデータと連携して機能することが保証されます。
ストリーム内に元のソーステキストを持つことで、後で同じデータを使用する新しいワークフローを導入したり、研究ブリーフの生成プロセスを強化したり、データウェアハウスなどの下流サービスに送信したりできます。この柔軟な設定により、コアパイプライン全体を大幅に変更することなく、時間の経過とともに追加のAI機能や非AI機能を段階的に導入することができます。
PodPrep AIでは、ソースURLから取得したテキストから質問を抽出するためにFlinkを使用しています。
Flinkを使用してLLMを呼び出す設定には、ConfluentのCLIを介した接続の構成が必要です。以下に、OpenAI接続を設定するための例のコマンドが示されていますが、複数のオプションが利用可能です。
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
接続が確立されると、私はモデルを作成できます。Cloud ConsoleまたはFlink SQLシェルのいずれかで行います。質問抽出のために、モデルをそれに応じて設定します。
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
モデルが準備できたら、Flinkの組み込みml_predict関数を使用して、ソース資料から質問を生成し、出力をmined-questionsというストリームに書き込みます。これはMongoDBと同期され、後で使用されます。
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flinkはまた、すべての研究資料が処理された時点を追跡し、研究ブリーフ生成をトリガーします。これは、mined-questionsのURLがフルテキストソースストリームのURLと一致したときに、completed-requestsストリームに書き込むことで行われます。
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
メッセージがcompleted-requestsに書き込まれると、研究バンドルのユニークIDが生成 研究ブリーフエージェントに送信されます。
生成研究ブリーフエージェント
このエージェントは、利用可能な最も関連性の高い研究資料をすべて取り込み、LLMを使用して研究ブリーフを作成します。以下は、研究ブリーフを作成するために行われる高レベルのフローです。

生成研究ブリーフエージェントのフローダイアグラム
これらのステップのいくつかを分解してみましょう。LLMのプロンプトを構築するために、私は抽出された質問、トピック、ゲスト名、会社名、ガイダンス用のシステムプロンプト、およびポッドキャストのトピックに最も意味的に類似したベクトルデータベースに保存されたコンテキストを組み合わせます。
研究バンドルには限られたコンテキスト情報しかないため、ベクトルストアから直接最適なコンテキストを抽出することは困難です。この問題に対処するために、LLMに検索クエリを生成させ、図中の「検索クエリの作成」ノードに示されているように、最適なコンテンツを検索するようにします。
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
LLMによって生成されたクエリを使用して、埋め込みを作成し、bundleIdでフィルタリングしてMongoDBを検索し、特定のポッドキャストに関連する材料に絞り込みます。
特定された最適なコンテキスト情報を用いて、プロンプトを構築し、研究概要を生成し、その結果をMongoDBに保存してWebアプリケーションで表示します。
実装に関する注意点
PodPrep AIのフロントエンドアプリケーションとエージェントの両方をJavascriptで書きましたが、実際のシナリオでは、エージェントはおそらくPythonのような別の言語で書かれているでしょう。さらに、簡単のために、URLの処理と埋め込みの作成エージェントおよび研究概要の生成エージェントは、同じWebサーバーで実行される同じプロジェクト内にあります。実際の本番システムでは、これらは独立して実行されるサーバーレス関数になる可能性があります。
最後に
PodPrep AIの構築は、イベント駆動型アーキテクチャが実世界のAIアプリケーションのスケールと適応をどのように可能にするかを強調しています。FlinkとConfluentを用いて、厳密な依存関係なしにAI駆動のワークフローを実現するリアルタイムデータ処理システムを作成しました。このデカップリングアプローチにより、コンポーネントは独立して動作しつつ、イベントストリームを通じて接続され続けることができます。これは、異なるチームがスタックのさまざまな部分を管理する複雑で分散したアプリケーションにとって不可欠です。
今日のAI駆動の環境では、システム全体で新鮮なリアルタイムデータにアクセスすることが不可欠です。EDAはデータの「中枢神経系」として機能し、システムがスケールする際のシームレスな統合と柔軟性を実現します。
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink