













組織は、最初のユースケースを展開するために単一のApache Kafkaクラスターを使用してデータストリーミングの導入を開始します。グループ全体のデータガバナンスとセキュリティの必要性がありますが、異なるSLA、レイテンシ、インフラ要件により、新しいKafkaクラスターが導入されます。複数のKafkaクラスターが規範であり、例外ではありません。ユースケースには、ハイブリッド統合、集約、移行、災害復旧が含まれます。このブログ投稿では、さまざまな業界での異なるKafka展開に向けた実際の成功事例やクラスター戦略を探っています。

Apache Kafka:イベント駆動アーキテクチャとデータストリーミングの事実上の標準
Apache Kafkaは、高スループットで低レイテンシのデータ処理を目的としたオープンソースの分散イベントストリーミングプラットフォームです。リアルタイムでレコードのストリームを公開、購読、保存、処理できます。
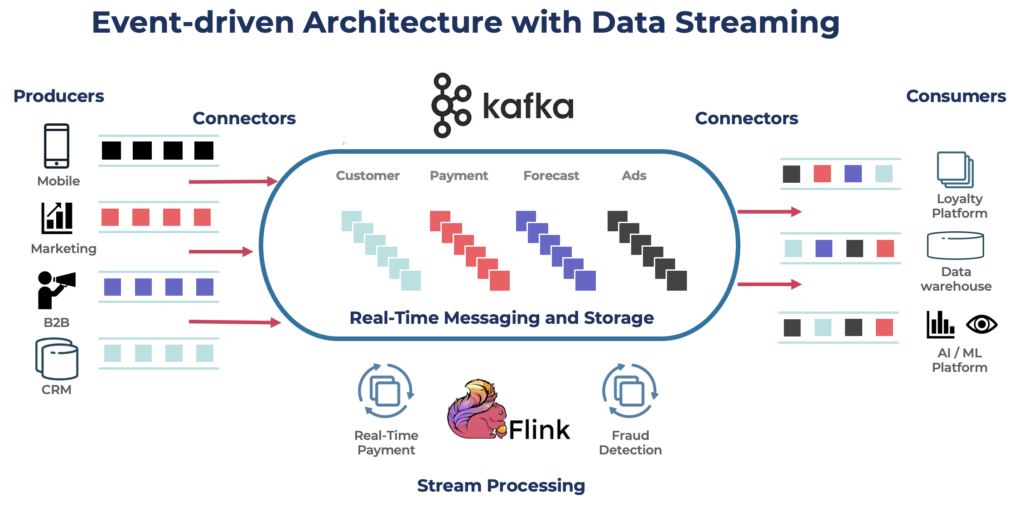
Kafkaはリアルタイムデータパイプラインおよびストリーミングアプリケーションの 構築に人気の選択肢です。Kafkaプロトコルは、さまざまなフレームワーク、ソリューション、クラウドサービスにおけるイベントストリーミングの事実上の標準となりました。持続的ストレージ、スケーラビリティ、フォールトトレランスなどの機能を備え、運用および分析ワークロードをサポートします。Kafkaには、統合のためのKafka Connectやストリーム処理のためのKafka Streamsなどのコンポーネントが含まれており、さまざまなデータ駆動型ユースケースに対応する多用途なツールです。
Kafkaはリアルタイムユースケースで有名ですが、多くのプロジェクトは、データベース、データレイク、レガシーシステム、オープンAPI、クラウドネイティブアプリケーションを含む企業全体のアーキテクチャにおけるデータの一貫性を確保するために、このデータストリーミングプラットフォームを活用しています。
異なるApache Kafkaクラスタの種類
Kafkaは分散システムです。生産環境のセットアップには通常、少なくとも4つのブローカーが必要です。そのため、多くの人は、スループットやユースケースを追加する際にスケールアップする単一の分散クラスタが必要であると自動的に考えます。これは最初は間違っていません。しかし…
1つのKafkaクラスタはすべてのユースケースに対する正しい答えではありません。さまざまな特性がKafkaクラスタのアーキテクチャに影響を与えます:
- 可用性:ゼロダウンタイム? 99.99%稼働時間SLA? 非クリティカルな分析?
- レイテンシ: エンドツーエンドの処理は100ミリ秒未満ですか(処理を含む)?10分間のエンドツーエンドのデータウェアハウスパイプライン?歴史的なイベントを再処理するためのタイムトラベル?
- コスト: 価値とコストのバランス?総所有コスト(TCO)が重要です。たとえば、パブリッククラウドでは、ネットワーキングが総Kafkaコストの80%に達することがあります!
- セキュリティとデータプライバシ: データプライバシ(PCIデータ、GDPRなど)?データガバナンスとコンプライアンス?属性レベルでのエンドツーエンドの暗号化?独自のキーの持参?パブリックアクセスとデータ共有?エアギャップ環境?
- スループットとデータサイズ: クリティカルなトランザクション(通常は低ボリューム)?ビッグデータフィード(クリックストリーム、IoTセンサー、セキュリティログなど)?
オンプレミス対パブリッククラウド、地域対グローバルなど、関連するトピックもKafkaアーキテクチャに影響を与えます。
Apache Kafkaクラスターの戦略とアーキテクチャ
単一のKafkaクラスターは、データストリーミングの旅においてしばしば正しい出発点です。適切に運用およびスケーリングされれば、異なるビジネスドメインから複数のユースケースを取り込み、秒間ギガバイトの処理が可能です。
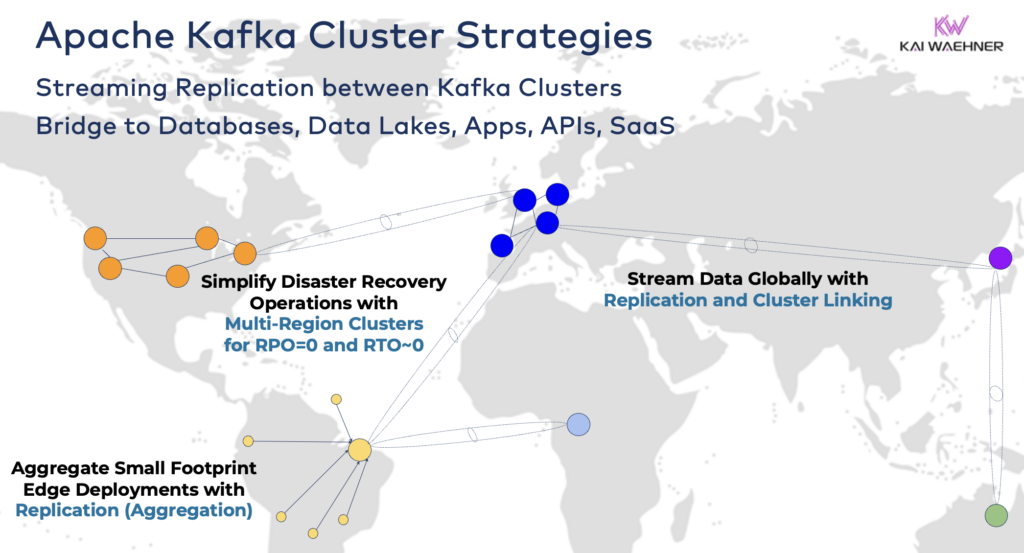
ただし、プロジェクト要件に応じて、複数のKafkaクラスターを備えたエンタープライズアーキテクチャが必要です。以下はいくつか一般的な例です。
- ハイブリッドアーキテクチャ:複数のデータセンター間でのデータ統合および一方向または双方向のデータ同期。通常、オンプレミスデータセンターとパブリッククラウドサービスプロバイダーとの接続。クラウドアナリティクスへのレガシーからの移行が最も一般的なシナリオの1つです。ただし、コマンド&コントロール通信も可能であり、たとえば、リージョナル環境(たとえば、モバイルアプリからの支払いや注文をメインフレームに保存する)に決定/推奨事項/トランザクションを送信することができます。
- マルチリージョン/マルチクラウド:コンプライアンス、コスト、またはデータプライバシーの理由によるデータレプリケーション。データ共有には通常、すべてのKafkaトピックではなく、一部のイベントのみが含まれます。医療分野もこの方向に進んでいます。
- 災害復旧:異なるデータセンターやクラウドリージョン間でのアクティブアクティブまたはアクティブパッシブモードでの重要なデータのレプリケーション。災害が発生した場合のフェイルオーバーおよびフォールバックメカニズムの戦略とツールを含み、ビジネスの継続性とコンプライアンスを保証します。
- 集約:地域クラスターによるローカル処理(例:前処理、ストリーミングETL、ストリーム処理ビジネスアプリケーション)およびキュレーションされたデータのビッグデータセンターやクラウドへのレプリケーション。小売店が優れた例です。
- 移行:オンプレミスからクラウドへの移行やセルフマネージドオープンソースからフルマネージドSaaSへのIT近代化。これらの移行は、ビジネスが引き続き運営される中で、ゼロダウンタイムやデータ損失なく行われることがあります。
- エッジ(非接続/エアギャップ):セキュリティ、コスト、または遅延が要求される場合、工場や小売店などでエッジ展開が必要とされます。一部の産業は単方向ハードウェアゲートウェイとデータダイオードを使用して安全重視の環境に展開しています。
- シングルブローカー:弾力性に乏しいですが、機械や産業用PC(IPC)にKafkaブローカーを埋め込んで集約されたデータを大規模なクラウド分析Kafkaクラスターにレプリケートするなどのシナリオには十分です。兵士の戦場でのコンピュータへのデータストリーミング(統合と処理を含む)のインストールが1つの良い例です。
ハイブリッドKafkaクラスターのブリッジング
これらのオプションは組み合わせることができます。たとえば、エッジに単一のブローカーを配置する場合、特定のデータが通常リモートデータセンターにレプリケートされます。ハイブリッドクラスターは、どのようにブリッジされるかによって異なるアーキテクチャを持っています:公共インターネットを介した接続、プライベートリンク、VPCピアリング、トランジットゲートウェイなど。
これまでConfluent Cloudの発展を見てきましたが、セキュリティと接続に費やすエンジニアリング時間の量を過小評価していました。ただし、セキュリティブリッジの欠如は<Kafkaクラウドサービスの採用の主な障害です。したがって、Kafkaクラスター間で単なる公共インターネットを超えたさまざまなセキュリティブリッジを提供する方法はありません。
組織がデータセンターからクラウドにデータを複製する必要があるユースケースさえありますが、クラウドサービスが接続を開始することは許可されていません。Confluentは、そのようなセキュリティ要件のために「ソース起点リンク」という特定の機能を構築しました。ここで、ソース(つまり、オンプレミスのKafkaクラスター)が常に接続を開始するため、クラウドのKafkaクラスターがデータを消費しているにもかかわらず:
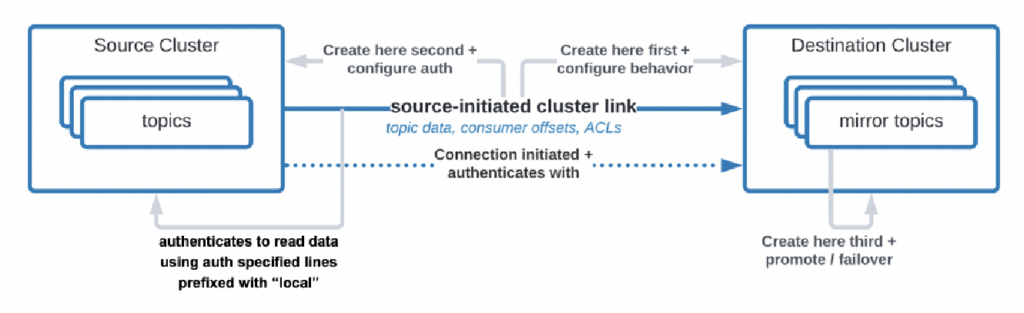 ソース:Confluent
ソース:Confluent
ご覧の通り、すぐに複雑になります。最初からあなたを助ける正しい専門家を見つけてください、最初のクラスターやアプリケーションを展開した後ではなく。
かなり前に、分散、ハイブリッド、エッジ、およびグローバルApache Kafka展開のアーキテクチャパターンについて詳細なプレゼンテーションで説明しました。デプロイメントオプションとトレードオフについての詳細は、そのスライドデッキとビデオレコーディングをご覧ください。
RPO対RTO = データ損失対ダウンタイム
RPOとRTOは、Kafkaクラスター戦略を決定する前に議論する必要のある2つの重要なKPIです:
- RPO(回復ポイント目標)は、データ損失を最小限に抑えるためにバックアップを頻繁に行うべきである最大許容データ損失量を時間で測定したものです。
- RTO(リカバリタイムオブジェクティブ)は、障害発生後にビジネスオペレーションを復旧するのに許容される最大時間です。これらは、データバックアップと災害復旧戦略を計画し、コストと運用上の影響をバランスさせるために組織が役立てます。
人々はしばしば、RPO = 0およびRTO = 0という目標から始めますが、これを達成するのがどれほど困難(しかし不可能ではない)かすぐに気づきます。災害時にどれだけのデータを失うことができるかを決定する必要があります。災害が発生した場合は、災害復旧計画が必要です。法務およびコンプライアンスチームは、災害が発生した場合にいくつかのデータセットを失ってもよいかどうかを判断する必要があります。これらを含む多くの課題は、Kafkaクラスタの戦略を評価する際に議論する必要があります。
MIrrorMakerやCluster Linkingなどのツールを使用してKafkaクラスタ間のレプリケーションを行うと、非同期でありRPO > 0となります。RPO = 0を提供するのはストレッチKafkaクラスタのみです。
ストレッチKafkaクラスタ:データセンター間での同期レプリケーションによるゼロデータ損失
複数のKafkaクラスタを使用するほとんどの展開では、MIrrorMakerやConfluent Cluster Linkingなどのツールを介してデータセンターまたはクラウド間で非同期レプリケーションが行われます。これはほとんどのユースケースには十分ですが、災害が発生した場合にはいくつかのメッセージが失われます。RPOは0よりも大きくなります。
ストレッチKafkaクラスタは、Kafkaブローカーを1つの単一クラスタとして3つのデータセンターに展開します。このレプリケーションは同期的です(これはKafkaが1つのクラスタ内でデータを複製する方法です)、そして災害が発生してもデータ損失はゼロ(RPO = 0)を保証します。
なぜ常にストレッチクラスタを使うべきではないのでしょうか?
- データセンター間で低遅延(<~50ms)かつ安定した接続が必要です。
- 3つのデータセンターが必要です。2つだけでは、書き込みや読み取りを過半数(クオーラム)が承認する必要があるため、システムの信頼性を確保できません。
- 1つのデータセンターでクラスターを実行するよりも、設定、運用、監視が難しいです。
- 多くのユースケースでは、コストと価値のバランスが取れないです。実際の災害時には、多くの組織やユースケースが、いくつかのメッセージを失うことよりも大きな問題を抱えています(たとえそれが支払いや注文などの重要なデータであっても)。
はっきり言って、パブリッククラウドでは、リージョンには通常3つのデータセンター(可用性ゾーン)があります。したがって、クラウドでは、1つのクラウドリージョンがストレッチされたクラスターとしてカウントされるかどうかは、あなたのSLAに依存します。ほとんどのSaaS Kafkaオファリングはここでストレッチされたクラスターに展開されています。
しかし、多くのコンプライアンスシナリオでは、1つのクラウドリージョンのKafkaクラスターだけでは、災害が発生した場合にSLAと事業継続を保証するには十分ではないとは見なされません。
Confluentは、これらの課題の一部を解決する専用製品を開発しました:Multi-Region Clusters(MRC)。これは、ストレッチされたKafkaクラスター内で同期および非同期レプリケーションを行う機能を提供します。
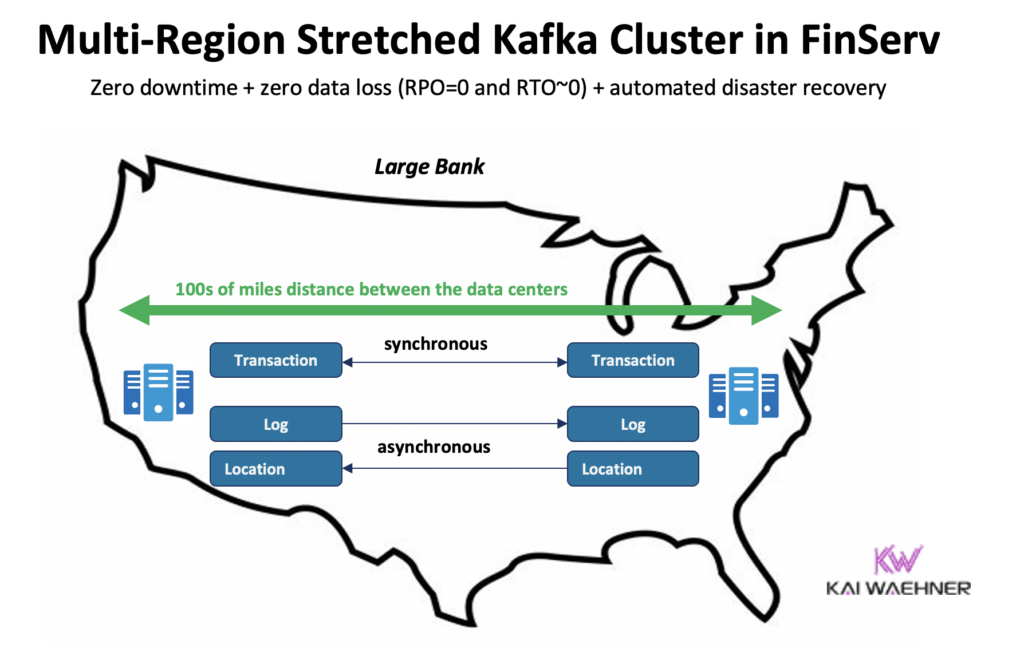
たとえば、金融サービスのシナリオでは、MRCは低ボリュームの重要なトランザクションを同期的に複製しますが、高ボリュームのログを非同期的に複製します。
- 米国東部および米国西部から入力される「支払い」トランザクションを完全同期レプリケーションで処理
- 同じクラスター内の「ログ」と「位置」情報は非同期で使用 – レイテンシーに最適化
- 自動化された災害復旧(ゼロダウンタイム、ゼロデータ損失)
グローバルKafkaプレゼンテーションでのストレッチドKafkaクラスターとアクティブアクティブ/アクティブパッシブ間のレプリケーションに関する詳細詳細。
Kafkaクラウド提供の価格設定(セルフマネージドと比較)
上記のセクションでは、プロジェクト要件に応じて異なるKafkaアーキテクチャを検討する必要がある理由が説明されています。セルフマネージドのKafkaクラスターは必要なように構成できます。パブリッククラウドでは、完全管理型の提供は異なります(他の完全管理型SaaSと同様)。価格が異なるのは、SaaSベンダーが合理的な制限を構成する必要があるためです。ベンダーは特定のSLAを提供する必要があります。
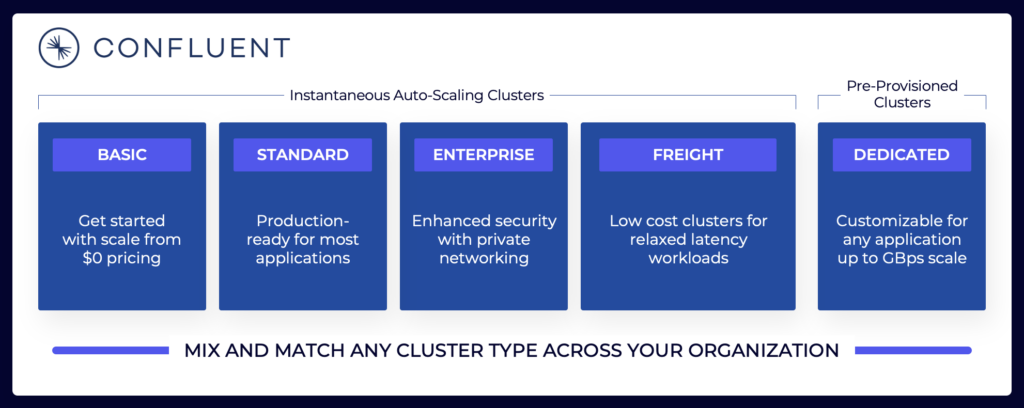
データストリーミングの景色には、さまざまなKafkaクラウド提供が含まれます。Confluentの現在のクラウド提供の例があり、異なるSLA、セキュリティ機能、およびコストモデルを持つマルチテナントおよび専用環境が含まれています。
 ソース:Confluent
ソース:Confluent
さまざまなパブリッククラウドで利用可能な異なるベンダーのクラスタータイプを評価し理解することを確認してください。これには、総所有コスト(TCO)、提供される稼働時間のSLA、地域間またはクラウドプロバイダー間のレプリケーションコストなどが含まれます。ギャップや制限事項は、詳細に意図的に隠されていることがよくあります。
たとえば、Amazon Managed Streaming for Apache Kafka(MSK)を使用している場合、利用規約には「アンダーラインのApache KafkaまたはApache Zookeeperエンジンソフトウェアに起因して要求が失敗する可能性のある利用不可、停止、または終了には、サービスのコミットメントは適用されない」と記載されていることを認識しておくべきです。
ただし、価格とサポートのSLAは比較の重要な要素の1つに過ぎません。データストリーミングプラットフォームを評価する際には、考慮すべき多くの “ビルド対バイ” の意思決定があります。
Kafkaストレージ:ティアドストレージおよびIcebergテーブル形式を使用してデータを一度だけ保存
Apache Kafkaはティアド・ストレージを追加して、コンピュートとストレージを分離しました。この機能により、スケーラブルで信頼性が高く、コスト効率の良いエンタープライズアーキテクチャが実現されます。KafkaのTiered Storageにより、コスト効率の良い方法でKafkaコミットログにペタバイト単位のデータを保存する新しいKafkaクラスタータイプが可能になります(データレイク内のように)。これにより、過去のデータを再処理するために時間を遡ることができ、タイムスタンプと確実な順序付けが可能です。KOR Financialは、長期的な永続性のためにApache Kafkaをデータベースとして使用する素敵な例です。
Kafkaは、オペレーションと分析用のデータを一度だけ保存するShift Left Architectureを可能にします:

この観点から、複数のKafkaクラスターに関する私の説明したユースケースについて再考してみてください。データをまだバッチでデータベース、データレイク、または別のデータセンターやクラウドリージョンにレプリケートする必要がありますか? いいえ。リアルタイムでデータを同期し、データを一度だけ保存し(通常はAmazon S3のようなオブジェクトストアに)、その後、Snowflake、Databricks、Amazon Athena、Google Cloud BigQueryなどのすべての分析エンジンをこの標準のテーブル形式に接続する必要があります。
複数のKafkaクラスターに関する実際の成功事例
ほとんどの組織は複数のKafkaクラスターを持っています。このセクションでは、異なる業界での4つの成功事例を探ります:
- Paypal(金融サービス)– 米国:即時支払い、不正防止。
- JioCinema(Telco/Media) – APAC:データ統合、クリックストリーム分析、広告、パーソナライゼーション。
- Audi(Automotive/Manufacturing) – EMEA:要求されるクリティカルおよび分析要件を持つコネクテッドカー。
- New Relic(Software/Cloud) – US:世界中でのオブザーバビリティおよびアプリケーションパフォーマンス管理(APM)。
Paypal:セキュリティゾーンによる分離。
PayPalは、ユーザーが世界中で安全かつ便利にリアルタイムでオンラインで送金および受け取りができるデジタル支払いプラットフォームです。これには、スケーラブルでセキュアかつコンプライアンスを満たすKafkaインフラストラクチャが必要です。
2022年のブラックフライデーでは、Kafkaトラフィックのボリュームが1日に約1.3兆メッセージに達しました。現在、PayPalには85以上のKafkaクラスタがあり、毎年のホリデーシーズンにはトラフィックの急増に対応するためにKafkaインフラストラクチャを拡張しています。Kafkaプラットフォームは、ビジネスに影響を与えることなく、このトラフィック増加をサポートするためにシームレスにスケーリングされ続けています。
今日、PayPalのKafkaフリートには1,500以上のブローカーがおり、20,000以上のトピックをホストしています。イベントはクラスタ間でレプリケートされ、99.99%の可用性が提供されています。
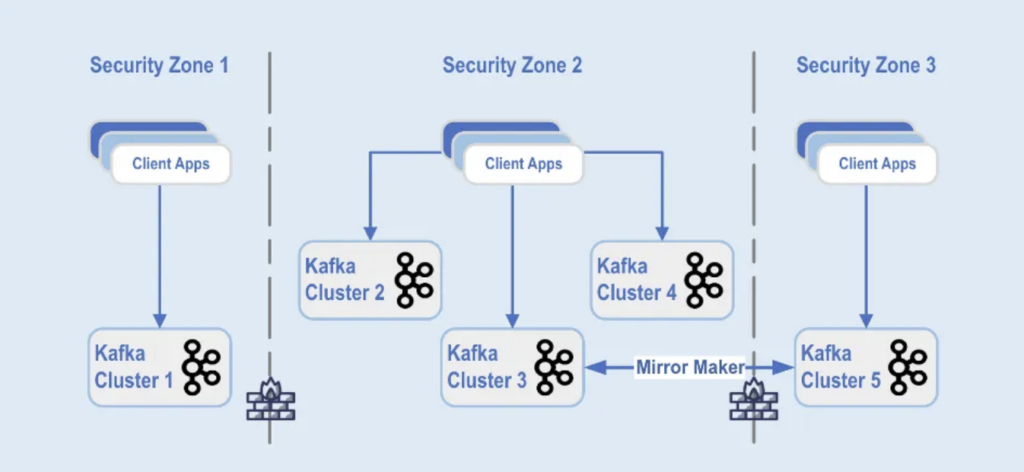
Kafkaクラスタの展開は、データセンター内の異なるセキュリティゾーンに分割されています:
 ソース:Paypal
ソース:Paypal
これらのセキュリティゾーン全体にKafkaクラスターが展開されており、データ分類とビジネス要件に基づいています。ミラーメーカーなどのツールを使用したリアルタイムレプリケーション(この例では、Kafka Connectインフラストラクチャで実行されている)やConfluent Cluster Linking(簡単でエラーが少ないアプローチを使用し、レプリケーションのためにKafkaプロトコルを直接使用)を使用して、データをデータセンター全体にミラーリングし、災害復旧を支援し、セキュリティゾーン間の通信を実現しています。
JioCinema:ユースケースとSLAによる分離
JioCinemaは、インドで急成長しているビデオストリーミングプラットフォームです。この電気通信事業者のOTTサービスは、クリケットのインドプレミアリーグ(IPL)などのライブスポーツ、新たに立ち上げられたアニメハブ、およびパリ2024オリンピックなどの主要イベントの包括的な計画で知られています。
データアーキテクチャは、データ処理のためにApache Kafka、Flink、およびSparkを活用しており、これについては、Kafka Summit India 2024で発表されました:
 ソース:JioCinema
ソース:JioCinema
データストリーミングは、ユーザーエクスペリエンスとコンテンツ配信を変革するさまざまなユースケースで重要な役割を果たしています。秒間1000万件以上のメッセージが、分析、ユーザーインサイト、およびコンテンツ配信メカニズムを強化しています。
JioCinemaのユースケースには、
- インターサービスコミュニケーション
- クリックストリーム/分析
- 広告トラッカー
- 機械学習とパーソナライゼーション
JioCinemaのデータプラットフォーム、分析、および消費の責任者であるKushal Khandelwal氏は、すべてのデータが等しくないこと、および優先順位とSLAがユースケースによって異なることを説明しました。
 出典: JioCinema
出典: JioCinema
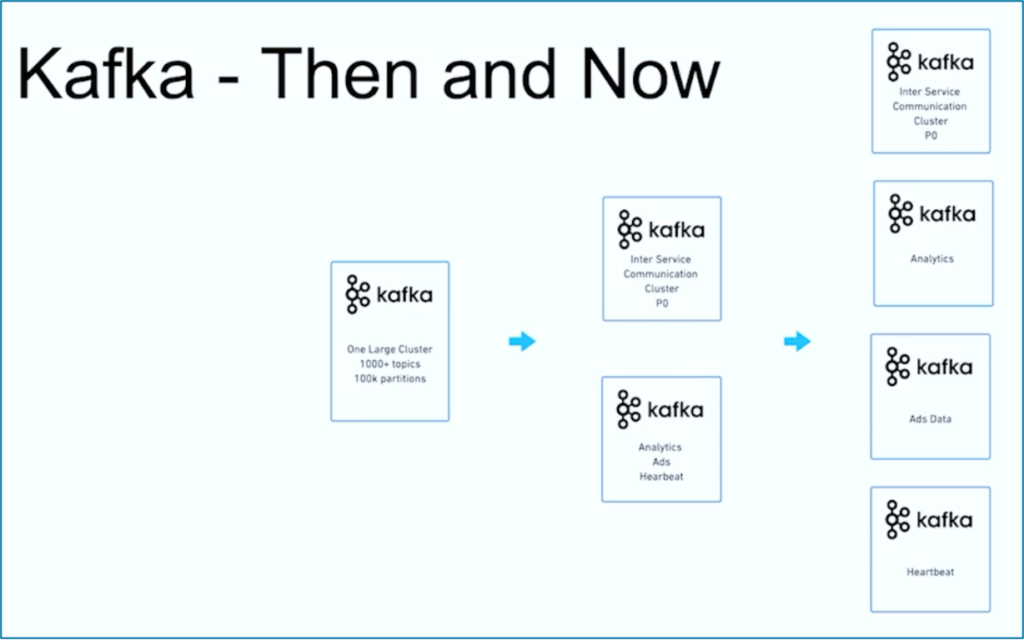
データストリーミングは旅です。世界中の多くの他の組織と同様に、JioCinemaは、さまざまなユースケース向けに1000以上のKafkaトピックと10万以上のKafkaパーティションを使用する1つの大規模なKafkaクラスターから始まりました。時間の経過とともに、ユースケースとSLAに関する懸念の分離が、複数のKafkaクラスターに発展しました:
 出典: JioCinema
出典: JioCinema
JioCinemaの成功例は、データストリーミング組織の一般的な進化を示しています。では、異なる2つのKafkaクラスターが1つのユースケースで最初から展開された別の例を見てみましょう。
Audi: Operations vs. Analytics for Connected Cars
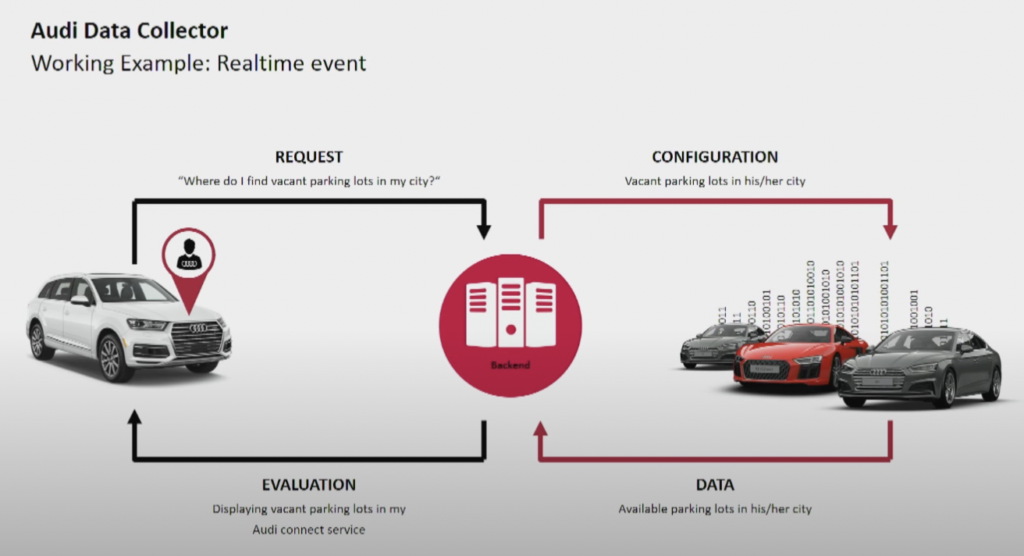
自動車メーカーのAudiは、インターネット接続やインテリジェントシステムを統合した先進技術を搭載したコネクテッドカーを提供しています。Audiの車両はリアルタイムナビゲーション、遠隔診断、高度な車載エンターテイメントを可能にします。これらの車両にはAudi Connectサービスが搭載されており、緊急通報、オンライン交通情報、スマートホームデバイスとの統合などの機能が備わっており、運転者の利便性と安全性を向上させています。
 出典: Audi
出典: Audi
Audiは2018年のKafkaサミットの基調講演で、自動車メーカーのアーキテクチャを紹介しました。Audiのエンタープライズアーキテクチャは、非常に異なるSLAとユースケースを持つ2つのKafkaクラスターに依存しています。
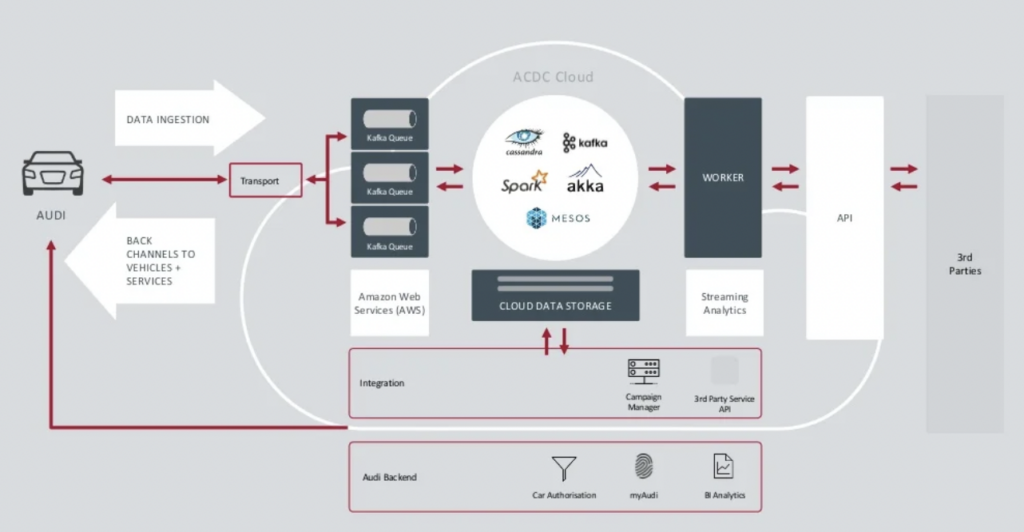 出典: Audi
出典: Audi
データインジェスションKafkaクラスターは非常に重要です。24時間365日規模で実行する必要があります。KafkaとMQTTを使用して数百万台の車に最後の接続性を提供します。Kafka and MQTT IT側から車両への逆チャネルは、サービス通信とOTA(オーバーザエア)アップデートに役立ちます。
ACDC Cloudは、Audiのコネクテッドカーアーキテクチャの分析Kafkaクラスターです。このクラスターは、Apache Sparkなどのバッチ処理フレームワークを使用して、規模化されたIoTおよびログデータの膨大なボリュームを処理する多数の分析ワークロードの基盤です。
このアーキテクチャはすでに2018年に発表されました。Audiのスローガンである「技術を通じた進歩」は、企業が同様のシナリオを展開する前に新しい技術を革新に応用した方法を示しています。コネクテッドカーからのすべてのセンサーデータがリアルタイムで処理され、歴史的分析とレポートのために保存されます。
New Relic:世界的なマルチクラウドオブザーバビリティ
New Relicは、世界中の顧客向けにアプリケーションとインフラストラクチャのリアルタイムパフォーマンスモニタリングと分析を提供するクラウドベースのオブザーバビリティプラットフォームです。
New Relicのソフトウェアエンジニアリング部門のVPであるAndrew Hartnett氏は、データストリーミングがNew Relicのビジネスモデル全体にとって重要であることを説明しています。
“カフカは私たちの中枢神経系です。私たちが行うすべての活動の一部です。当社では、110の異なるエンジニアリングチーム全体のほとんどのサービスが何らかの形でKafkaに関わっており、それは本当にミッションクリティカルです。求めていたのは成長する能力であり、Confluent Cloudがそれを提供してくれました。
New Relicは最大7兆のデータポイントを分単位で取り込み、2023年には2.5エクサバイトのデータを取り込む予定です。New Relicがマルチクラウド戦略を拡大するにつれて、チームはすべての環境を一元管理するためにConfluent Cloudを使用します。
「New Relicはマルチクラウドです。私たちは顧客がいる場所にいたいのです。同じ環境、同じ地域にいたいと考えており、Kafkaも一緒にそこに置いておきたかった」とArtnettはConfluentのケーススタディで述べています。
複数のKafkaクラスタが規範であり、例外ではありません。
イベント駆動型アーキテクチャやストリーム処理は数十年前から存在しています。Apache KafkaやFlinkなどのオープンソースフレームワークと完全に管理されたクラウドサービスの組み合わせにより、採用が拡大しています。ますます多くの組織がKafkaの規模に苦しんでいます。企業全体のデータガバナンス、エクセレンスセンター、展開や運用の自動化、エンタープライズアーキテクチャのベストプラクティスが、独立または連携するビジネスドメイン向けに複数のKafkaクラスタでデータストリーミングを成功裏に提供するのに役立ちます。”
複数のKafkaクラスタは例外ではなく、通常です。ハイブリッド統合、災害復旧、移行、または集約などのユースケースにより、必要なSLAを備えたリアルタイムデータストリーミングがどこでも可能となります。
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies