













すべてのデータ駆動型組織には運用と分析のワークロードがあります。データストリーミング、データレイク、データウェアハウス、レイクハウスソリューション、そしてクラウドサービスを含むさまざまなデータプラットフォームにおいて、最良の品種選択アプローチが台頭しています。Apache Icebergのようなオープンなテーブルフォーマットフレームワークは、企業アーキテクチャにおいて信頼性の高いデータ管理と共有、スムーズなスキーマ進化、大規模データセットの効率的な処理、そしてコスト効率の高いストレージを確保するために不可欠です。また、ACIDトランザクションとタイムトラベルクエリに対する強力なサポートを提供します。
この記事では、市場のトレンドや、Iceberg、Hudi、Paimon、Delta Lake、XTableなどのテーブルフォーマットフレームワークの採用状況、そしてSnowflake、Databricks(Apache Spark)、Confluent(Apache Kafka/Flink)、Amazon Athena、Google BigQueryなどのデータプラットフォームの主要ベンダーの製品戦略について探ります。
データプラットフォームのためのオープンなテーブルフォーマットとは何か?
オープンなテーブルフォーマットは、データの整合性を維持し、クエリパフォーマンスを最適化し、プラットフォーム内に保存されているデータの明確な理解を確保するのに役立ちます。オープンなテーブルフォーマットは、データプラットフォームの典型的な構造には、データが整理され、アクセス可能で、簡単にクエリ可能なようにする特定のコンポーネントが含まれています。典型的なテーブルフォーマットには、テーブル名、カラム名、データタイプ、主キーと外部キー、インデックス、そして制約が含まれます。
これは新しい概念ではありません。あなたが好きな十年以上前のデータベース—オラクル、IBM DB2(メインフレームでも)やPostgreSQLなど—は同じ原理を使用しています。しかし、クラウドデータウェアハウス、データレイク、レイクハウスに関する要求と課題は、拡張性、パフォーマンス、クエリ能力において多少変わりました。
「レイクハウステーブルフォーマット」の利点:Apache Iceberg
組織のすべての部分がデータ駆動型になります。その結果、大規模なデータセット、ビジネスユニット間でのデータ製品の共有、そして近乎真の実時データ処理新しい要求が生じます。
Apache Icebergは、企業アーキテクチャに多くの利点を提供します:
- 単一ストレージ:データは一度だけ(さまざまなデータソースから)保存され、コストと複雑さを削減します
- 相互運用性:どの分析エンジンからも統合努力なしでアクセス可能
- すべてのデータ:運用と分析のワークロードを統一(トランザクションシステム、ビッグデータログ/IoT/クリックストリーム、モバイルAPI、第三方B2Bインターフェースなど)
- ベンダー独立:どの好きな分析エンジンでも使用可能(リアルタイムに近い、バッチ、APIベースに関係なく)
Apache HudiとDelta Lakeも同じ特性を提供します。ただし、Delta Lakeは主にDatabricksという単一のベンダーによって推進されています。
テーブルフォーマットとカタログインターフェース
Apache Icebergや类似的なテーブルフォーマットフレームワークに関する議論には二つの概念が含まれます:テーブルフォーマットとカタログインターフェース! 技術のエンドユーザーとして、あなたは両方必要です!
Apache Icebergプロジェクトはフォーマットを実装していますが、カタログについては chỉ 提供する規格(実装は提供しません):
- テーブルフォーマットは、テーブル内でのデータの組織化、保存、管理方法を定義します。
- カタログインターフェースは、テーブルのメタデータを管理し、データレイク内のテーブルへのアクセスのための抽象レイヤーを提供します。
Apache Icebergのドキュメントでは、この図に基づいて概念を詳細に説明しています:
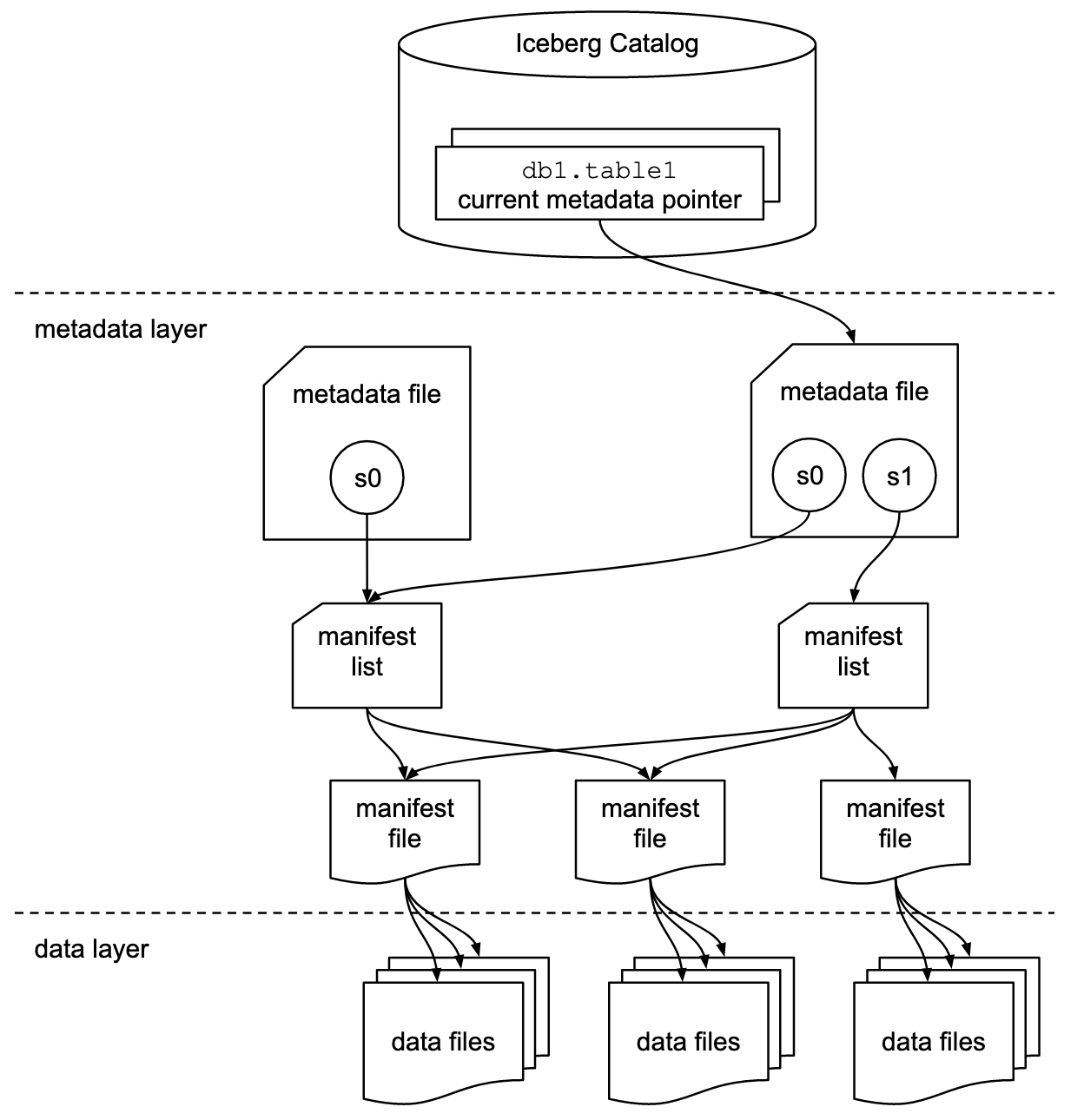
企業はIcebergのカタログインターフェースのさまざまな実装を使用しています。それぞれは異なるメタデータストアとサービスと統合しています。主要な実装には:
- ハドープカタログ:Hadoop Distributed File System(HDFS)またはそれに互換性のあるファイルシステムを使用してメタデータを保存します。すでにHadoopを使用している環境に適しています。
- ハイブカタログ:Apache Hive Metastoreと統合してテーブルメタデータを管理します。Hiveをメタデータ管理に使用しているユーザーに最適です。
- AWS Glueカタログ:AWS Glue Data Catalogを使用してメタデータを保存します。AWSエコシステム内で運用しているユーザー向けに設計されています。
- RESTカタログ:HTTPを通じてカタログ操作のためのRESTfulインターフェースを提供します。カスタムまたは第三者のメタデータサービスとの統合を可能にします。
- Nessieカタログ:プロジェクトNessieを使用し、Gitのような体験を提供してデータを管理します。
Apache Icebergの動向と拡大する採用動向は、多くのデータプラットフォームベンダーが独自のIcebergカタログを実装する動機付けとなっています。以下のセクションでデータプラットフォームとクラウドベンダーの戦略について議論し、SnowflakeのPolaris、DatabricksのUnity、ConfluentのTableflowなどいくつかの戦略を紹介します。
ファーストクラスのIcebergサポートとIcebergコネクタ
Apache Iceberg(またはHudi/Delta Lake)をサポートすることは、単にコネクタを提供し、テーブルフォーマットをAPIを通じて統合するだけ以上の意味を持っています。ベンダーやクラウドサービスは、データフォーマット間の自動マッピング、重要なSLA、タイムトラベル、直感的なユーザーインターフェースなど、高度な機能で差別化しています。
例を見てみましょう:Apache KafkaとIcebergの統合。さまざまなKafka Connectコネクタがすでに実装されています。しかし、Iceberg(例えば、ConfluentのTableflow)とのファーストクラスの統合を使用する利点を以下に示します:利点:
- コネクタ設定不要
- コネクタを通じた消費不要
- ビルトインメンテナンス(コンパaction、ガベージコレクション、スナップショット管理)
- 自動スキーマ進化
- 外部カタログサービスの同期
- シンプルな操作(完全管理型のSaaSソリューションでは、サーバーレスでエンドユーザーによるスケールや運用の必要がありません)
同様の利点は、シンプルなコネクタを提供するよりも他のデータプラットフォームや潜在的なファーストクラスの統合にも適用されます。
Apache Iceberg、Apache Hudi、そしてDelta Lakeを使用したデータレイク/レイクハウスのためのオープンなテーブルフォーマット
Apache Iceberg、Apache Hudi、そしてDelta Lakeなどのテーブルフォーマットフレームワークの一般的な目標は、大規模データの管理に関する一般的な課題を解決することでデータレイクの機能と信頼性を向上させることです。これらのフレームワークは以下のように役立ちます:
- データ管理の改善
- データレイクにおけるデータインゲージョン、ストレージ、リテrievalの簡単な取り扱いを促進します。
- 効率的なデータの組織化とストレージをサポートし、パフォーマンスとスケーラビリティを向上させます。
- データの一貫性を確保
- ACIDトランザクションのためのメカニズムを提供し、並行した読み取りと書き込み操作中でもデータが一貫性を保ち、信頼性があることを確保します。
- スナップショット隔離をサポートし、ユーザーが任意の時点でのデータの一貫した状態を閲覧できるようにします。
- スキーマ進化をサポート
- データスキーマの変更(列の追加、名前の変更、削除など)を、既存のデータを中断することなく、複雑な移行を必要とせずに行うことができます。
- クエリパフォーマンスの最適化
- 高度なインデックスとパーティショニング戦略を実装して、データクエリの速度と効率を向上させます。
- 効率的なメタデータ管理を可能にし、大規模なデータセットと複雑なクエリを効果的に処理します。
- データガバナンスの強化
- データの遡及性、バージョニング、監査をよりよく追跡および管理するためのツールを提供し、データ品質と遵守の維持に重要です。
これらの目標を達成することで、Apache Iceberg、Apache Hudi、そしてDelta Lakeなどのテーブルフォーマットフレームワークは組織がより強固でスケーラブルで信頼性の高いデータレイクおよびレイクハウスを構築するのを助けます。データエンジニア、データサイエンティスト、ビジネスアナリストは、テーブルフォーマットの上にアナリティクス、AI/ML、またはレポート/可視化ツールを利用して、大量のデータを管理および分析します。
Apache Iceberg、Hudi、Paimon、そしてDelta Lakeの比較
ここでApache Iceberg、Apache Hudi、Apache Paimon、そしてDelta Lakeのテーブルフォーマットフレームワークを比較することはしません。多くの専門家がこれについて既に書いています。各テーブルフォーマットフレームワークには独自の強みと利点がありますが、毎月の更新が必要ですという点があります。これは、これらのフレームワーク内での迅速な進化と革新、新しい改善と機能の追加によるものです。
以下は、私はブログ投稿で見た4つのオプションについての要約です:
- Apache Iceberg:スキーマとパーティションの進化、効率的なメタデータ管理、そして様々なデータ処理エンジンとの広範な互換性に優れています。
- Apache Hudi:リアルタイムデータインゲージメントとアップサートに最適で、強力な変更データキャプチャ機能とデータバージョニングを持ちます。
- Apache Paimon:FlinkとSparkを用いたストリーミングおよびバッチ処理のリアルタイムレイクハウスアーキテクチャを構築することを可能にするレイクフォーマットです。
- Delta Lake:強固なACIDトランザクション、スキーマの強制、タイムトラベル機能を提供し、データ品質と整合性の維持に最適です。
重要な決定ポイントは、Delta LakeはIcebergやHudiのように広範なコミュニティ által駆動されていないことです。Delta Lakeは主にDatabricksという単一のベンダーによってサポートされています。
Apache XTableは、Iceberg、Hudi、Delta Lakeをサポートする相互運用可能なクロステーブルフレームワークです。
ユーザーには多くの選択肢があります。 XTableは、以前はOneTableと呼ばれていたもので、Apache Hudi、Delta Lake、Apache Iceberg間の无缝のクロステーブル相互運用をサポートするアパッチのオープンソースライセンス下の孵化中のテーブルフレームワークです。
Apache XTable:
- 湖ハウステーブルフォーマット間のクロステーブル全方位相互運用性を提供します。
- 新しい または別のフォーマットではありません。Apache XTableは、湖ハウステーブルフォーマットのメタデータの変換のためのアブストラクションとツールを提供します。
もしかすると、Apache XTableは、特定のデータプラットフォームやクラウドベンダーに対する選択肢を提供しながらも、シンプルな統合と相互運用性を提供する答えかもしれません。
しかし注意してください:異なる技術之上的ラッパーは万能薬ではありません。数年前にApache Beamが登場したときにこれを見ました。Apache Beamは、オープンソースの統一モデルであり、データイングェージメントとデータプロセスワークフローの定義および実行のための言語ごとのSDKセットを提供しています。Flink、Spark、Samzaなどのさまざまなストリームプロセシングエンジンをサポートしています。Apache Beamの主要な推進力はGoogleで、Google Cloud Dataflowでのワークフローの移行を可能にしています。しかし、その制約は非常に大きく、そのようなラッパーはサポートする機能の最小公倍数を見つける必要があります。そして、ほとんどのフレームワークの主要な利点は、そのラッパーにはまらない20%です。そのため、例えばKafka Streamsは意図的にApache Beamをサポートしないようにしています。それは太多くの設計制約が必要になったからです。
テーブルフォーマットフレームワークの市場採用
まず第一に、私たちはまだ初期段階にいます。ガートナーのハイプサイクルの観点から見ると、まだ革新の引き金を引く段階で、誇大な期待のピークに向かっています。ほとんどの組織はまだ評価中で、組織全体でのプロダクションでのこれらのテーブルフォーマットの採用には至っていません。
振り返り:Kubernetes対Mesosphere対Cloud Foundryのコンテナ戦争
Apache Icebergの議論は、数年前のコンテナ戦争を思い出させます。「コンテナ戦争」という言葉は、ソフトウェア開発およびITインフラの分野における異なるコンテナ化技術やプラットフォーム間の競争と抗争を指しています。
対決していた3つの技術は、Kubernetes、Mesosphere、Cloud Foundryです。その推移を見てみましょう:

CloudfoundryとMesosphereは早かったが、Kubernetesが勝利した。なぜか?私は技術的な詳細や違いをすべて理解したことはありません。結局、3つのフレームワークがかなり似ているので、すべて次のことについてです:
- コミュニティの採用
- 機能リリースのタイミングが適切
- 良いマーケティング
- 運
- そして他のいくつかの要因
しかし、競合する3つのフレームワークがある代わりに、ソリューションやビジネスモデルを構築するための1つのリードするオープンソースフレームワークを持つことがソフトウェア産業にとって良いことです。
現在:Apache Iceberg対Hudi対Delta Lakeのテーブルフォーマット戦争
明らかに、Googleトレンドは統計的な証拠でも高度な研究でもありません。しかし、私は過去に市場のトレンドを分析するための直感的でシンプルで無料のツールとして多く使用してきました。したがって、このツールも使用して、Google検索が私の個人的な体験する市場の採用Apache Iceberg、Hudi、Delta Lake(Apache XTableはまだ小さすぎて追加されていません)と重なっているかどうかを見るために使用しました:
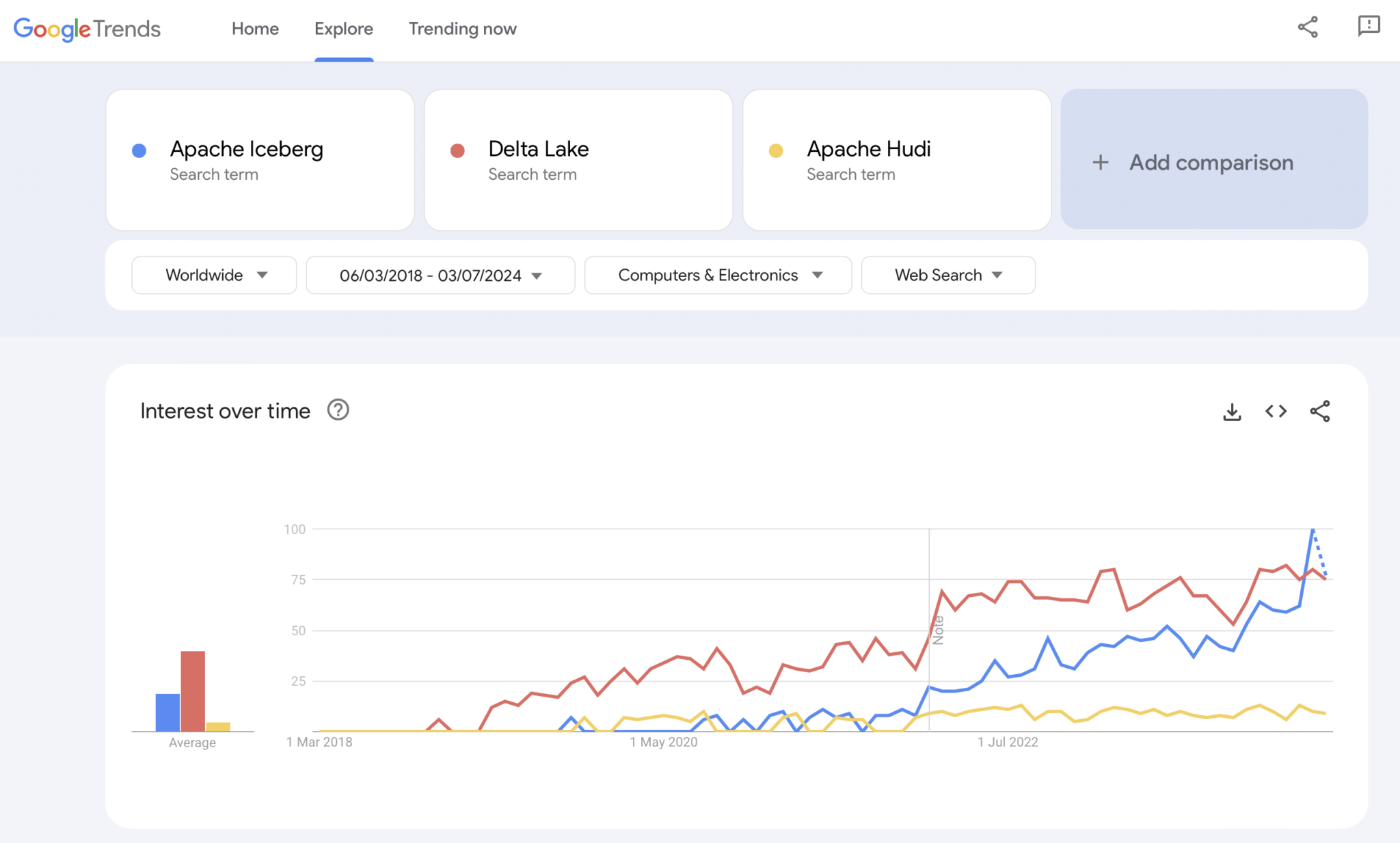
明らかに、数年前のコンテナ戦争が示したパターンと似たパターンが見えます。これがどこに向かっているか、そしてどの技術が勝つか、またはフレームワークが十分に異なる程度に分化して「万能薬はない」と証明するかは、将来が示してくれるでしょう。
私個人の意見としては、Apache Icebergが勝つと思います。なぜなら、技術的な理由は説明できません。ただ、多くの業界の顧客がますますそれについて話し始めているのを見ていますし、越来越多的ベンダーがサポートを開始しています。しかし、実際には気にしません誰が勝つか。コンテナ戦争のように、標準が一つで、ベンダーがその周囲の機能で差別化するのは良いと思います。Kubernetesがそうであるように
。それを踏まえて、現在のデータプラットフォームとクラウドプロバイダーのテーブルフォーマットサポートに関する戦略を見てみましょう
。Apache Icebergに対するデータプラットフォームとクラウドベンダーの戦略
この節では推測はしません。テーブルフォーマットフレームワークの進化は迅速で、ベンダーの戦略も急速に変わります。最新情報はベンダーのウェブサイトをご参照ください。ここでは、データプラットフォームとクラウドベンダーがApache Icebergのサポートと統合に関する現状についてです
- 。Snowflake:
- Apache Icebergをサポートしている間はかなり長い
- より良い統合と新しい機能を定期的に追加している
- SnowflakeのストレージやAmazon S3のような内部および外部のストレージオプション(トレードオフあり)
- Icebergのためのオープンソースのカタログ実装であるPolarisを発表し、コミュニティ主導、ベンダー非依存の双方向統合をサポートすることにコミット
- Databricks:
-
Delta Lakeをテーブルフォーマットとして重点的に、(現在オープンソース化された)Unityをカタログとして利用
Apache Icebergの背後を支える主要企業であるTabularを買収
オープンなIcebergインターフェース(両方向)をサポートする将来の戦略が不明確、またはLakehouseプラットフォームおよびDelta LakeやUnity Catalogのような技術にデータを供給することに限定 - Confluent:
-
Apache Icebergをデータストリーミングプラットフォーム(製品名はTableflow)に第一級市民として組み込む
Kafka Topicおよび関連するスキーマメタデータ(すなわちデータコンTRACT)をIcebergテーブルに変換
運用負荷と分析負荷の間の双方向統合
内蔵のサーバーレスFlinkとその統一されたバッチおよびストリーミングAPIによる分析、またはSnowflake、Databricks、Amazon Athenaなどの第三者分析エンジンとのデータ共有 - さらに多くのデータプラットフォームとオープンソース分析エンジン:
- Icebergをサポートする技術およびクラウドサービスのリストは毎月増えています
- いくつかの例:Apache Spark、Apache Flink、ClickHouse、Dremio、StarburstがTrino(以前はPrestoSQL)を使用、ClouderaがImpalaを使用、ImplyがApache Druidを使用、Fivetran
- クラウドサービスプロバイダー(AWS、Azure、Google Cloud、Alibaba):
- 異なる戦略および統合がありますが、すべてのクラウドプロバイダーは、これらのサービスにおけるIcebergサポートを増やしています。例えば:
- オブジェクトストレージ:Amazon S3、Azure Data Lake Storage (ALDS)、Google Cloud Storage
- カタログ:AWS Glue Catalogなどのクラウド特化型またはProject NessieやHive Catalogなどのベンダー非依存型
- 分析:Amazon Athena、Azure Synapse Analytics、Microsoft Fabric、Google BigQuery
- 異なる戦略および統合がありますが、すべてのクラウドプロバイダーは、これらのサービスにおけるIcebergサポートを増やしています。例えば:
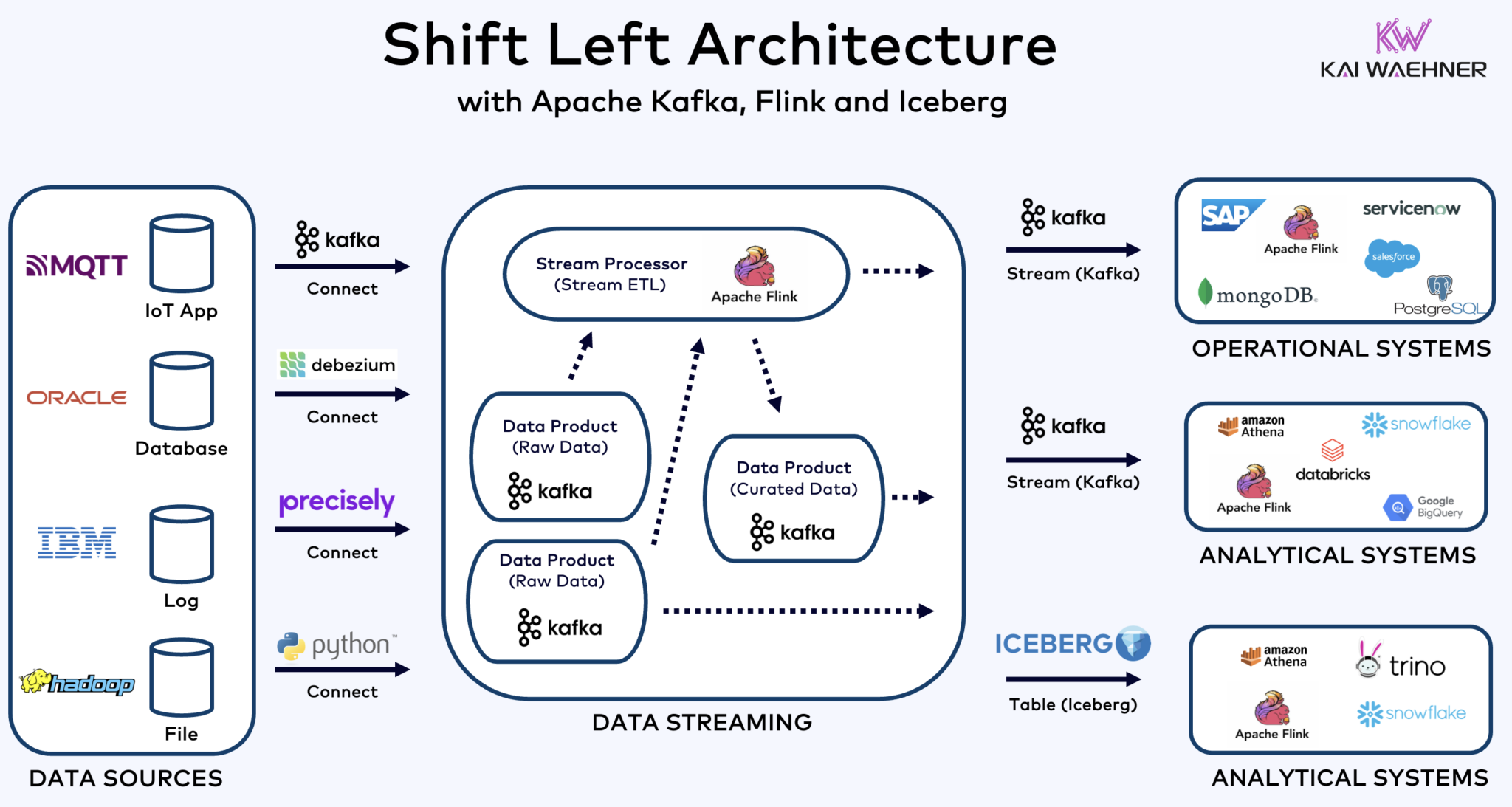
Kafka、Flink、Icebergを用いたシフトLEFTアーキテクチャで運用と分析のワークロードを統一
シフトLEFTアーキテクチャはデータ処理をデータソースに近づけ、Apache KafkaやFlinkなどのリアルタイムデータストリーミング技術を活用して、データがインジェストされた直後にデータの動きを直接処理します。このアプローチはレイテンシを削減し、データの一貫性と品質を向上させます。
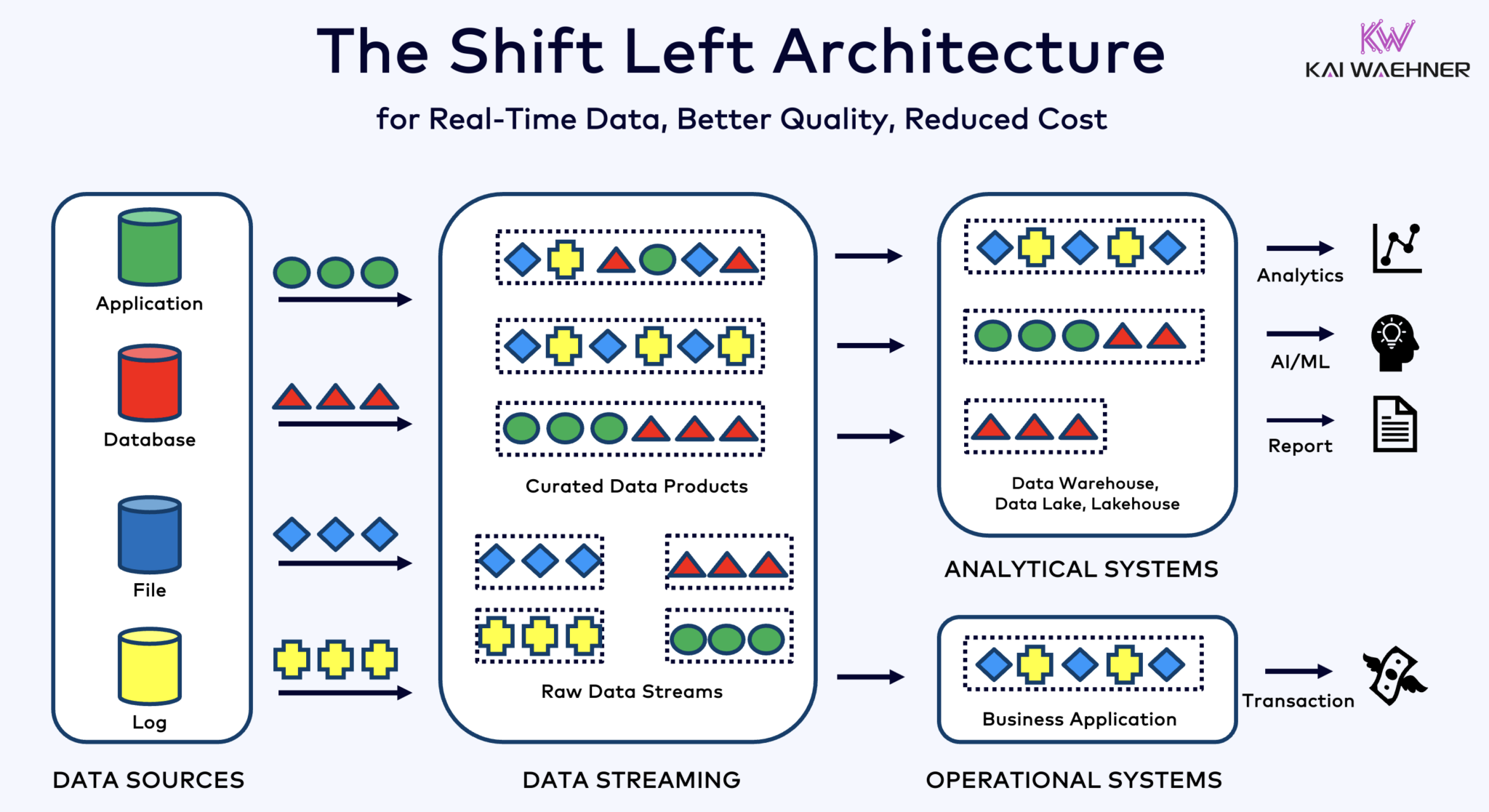
ETLおよびELTとは異なり、データが停止している状態でバッチ処理を行うのに対し、シフトLEFTアーキテクチャはリアルタイムのデータキャプチャと変換を可能にします。データを即座に使用可能にすることで、ゼロETLコンセプトに従いますが、企業アーキテクチャの左側にデータ処理をシフトすることで、多数のポイントツーポイント接続を持つ複雑でメンテナンスが困難なスパゲッティアーキテクチャを避けます。複雑でメンテナンスが困難なスパゲッティアーキテクチャを回避します。
シフトレフトアーキテクチャは、データがリアルタイムでアクション可能になる オペレーションシステムと分析システムの両方にとって、リバースETLの必要性を減少させます。全体として、このアーキテクチャはデータの新鮮さを向上させ、コストを削減し、データ駆動型アプリケーションの市場投入時間を短縮します。この概念について更多信息を私のブログ投稿「シフトレフトアーキテクチャ」で学びましょう。
Apache Icebergはオープンなテーブルフォーマットおよびカタログで、分析エンジン間のスムーズなデータ共有を可能にします
オープンなテーブルフォーマットおよびカタログは、企業アーキテクチャに非常に大きな利点をもたらします:
- 相互運用性
- 分析エンジンの選択の自由
- 市場投入時間の短縮
- コスト削減
Apache Icebergはベンダーおよびクラウドプロバイダー間で事実上の標準となりつつあります。しかし、まだ初期段階であり、Apache Hudi、Apache Paimon、Delta Lake、Apache XTableなどの競合およびラッパーテクノロジーも勢いを得ようとしています。
アイスバーグおよび他のオープンなテーブルフォーマットは、Snowflake、Databricks、Google BigQueryなど、複数の分析/データ/AI/MLプラットフォームとの統合において単一ストレージに大きな利点をもたらすだけでなく、Apache KafkaやFlinkなどの技術を用いたデータストリーミングによる運用と分析のワークロードの統合 にも役立ちます。シフトレフトアーキテクチャは、労力を削減し、データの品質と一貫性を向上させ、リアルタイムのアプリケーションとインサイトを可能にする重要な利点です。
最後に、データストリーミングとレイクハウス(そしてそれらがどのように相互に補完しているか)の違いにまだ疑問がある場合は、この10分のビデオをチェックしてください:
あなたのテーブルフォーマット戦略は何ですか?どの技術やクラウドサービスを接続していますか?私たちがLinkedInでつながりてそれについて議論しましょう!
Source:
https://dzone.com/articles/apache-iceberg-open-table-format-lakehouses-data-streaming