













Shift-left è un approccio al software development e alle operazioni che enfatizza test, monitoraggio e automazione inizialmente nel ciclo di vita dello sviluppo del software. L’obiettivo dell’approccio shift-left è prevenire i problemi prima che si verifichino catturandoli presto e affrontandoli rapidamente.
Quando si identifica un problema di scalabilità o un bug inizialmente, è più rapido e conveniente risolverlo. Spostare codice inefficiente in container cloud può essere costoso, poiché potrebbe attivare l’auto-scalabilità e aumentare la bolletta mensile. Inoltre, si sarà in uno stato di emergenza fino a quando non si sarà in grado di identificare, isolare e risolvere il problema.
La Dichiarazione del Problema
I would like to demonstrate to you a case where we managed to avert a potential issue with an application that could have caused a major issue in a production environment.
I was reviewing the performance report of the UAT infrastructure following the recent application change. It was a Spring Boot microservice with MariaDB as the backend, running behind Apache reverse proxy and AWS application load balancer. The new feature was successfully integrated, and all UAT test cases are passed. However, I noticed the performance charts in the MariaDB performance dashboard deviated from pre-deployment patterns.
Questa è la timeline degli eventi.
Il 6 agosto alle 14:13, l’applicazione è stata riavviata con un nuovo file jar Spring Boot contenente un Tomcat incorporato.
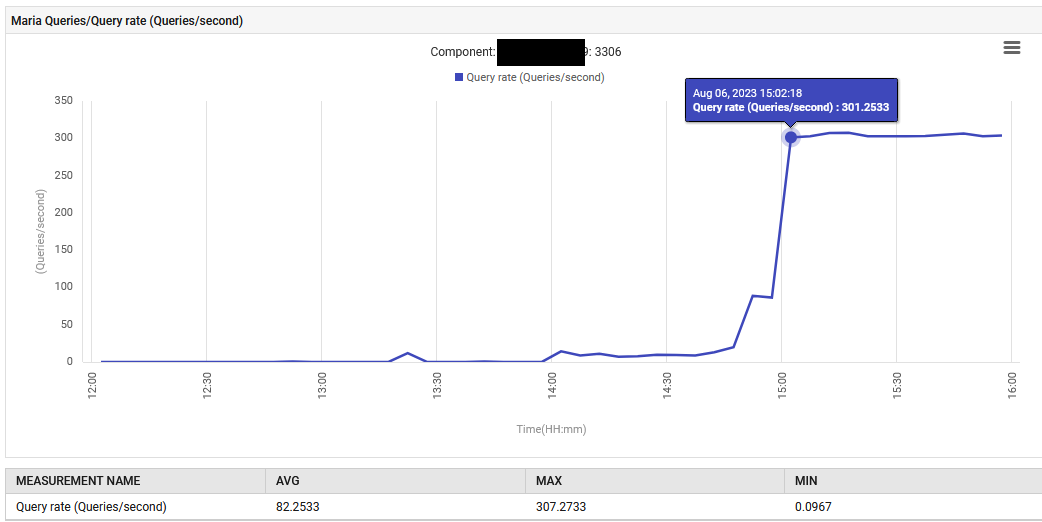
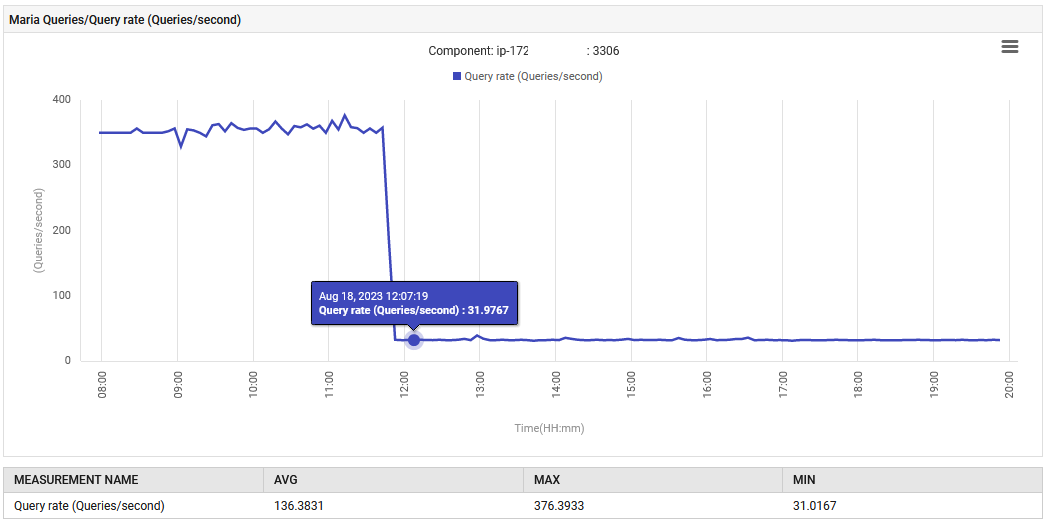
Alle 14:52, il tasso di elaborazione delle query per MariaDB è aumentato da 0.1 a 88 query al secondo e poi a 301 query al secondo.
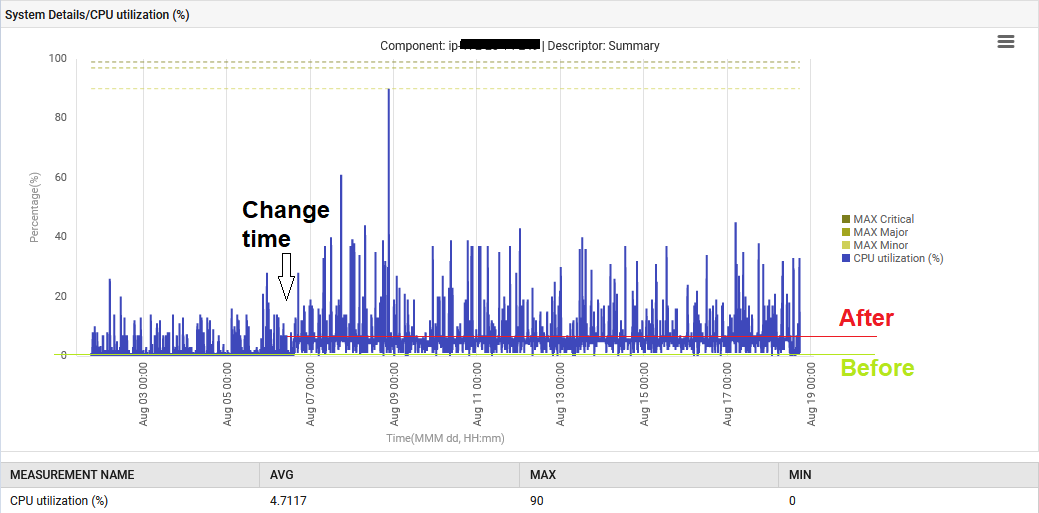
Inoltre, la CPU del sistema è stata elevata dal 1% al 6%.
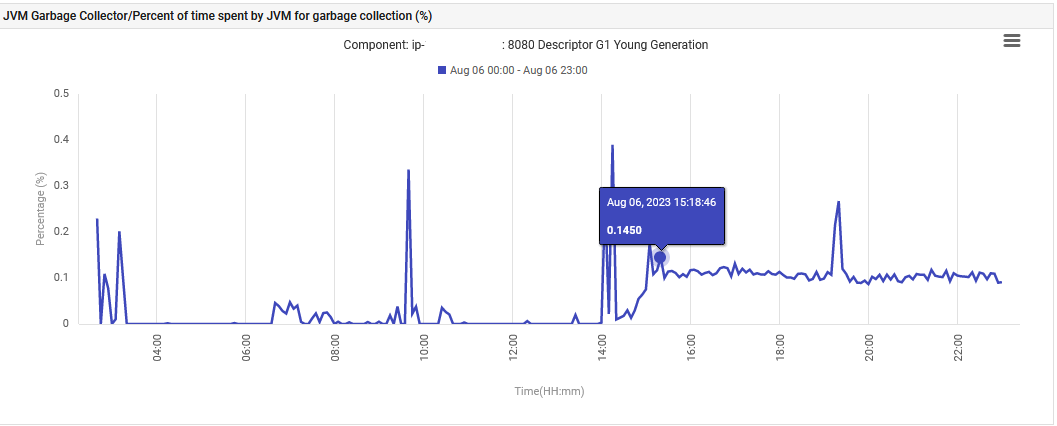
Infine, il tempo JVM speso sulla Garbage Collection G1 Young Generation è aumentato da 0% a 0.1% e si è mantenuto a quel livello.
L’applicazione, nella sua fase di UAT, sta emettendo in modo anomalo 300 query/sec, il che è ben oltre quanto progettato. La nuova funzionalità ha causato un aumento delle connessioni al database, motivo per cui l’aumento delle query è così drastico. Tuttavia, il dashboard di monitoraggio ha mostrato che le misure problematiche erano normali prima della distribuzione della nuova versione.
La Soluzione
Si tratta di un’applicazione Spring Boot che utilizza JPA per interrogare un MariaDB. L’applicazione è progettata per funzionare su due container per un carico minimo, ma è previsto che possa scalare fino a dieci.
Se un singolo container è in grado di generare 300 query al secondo, può gestire 3000 query al secondo se tutti e dieci i container sono operativi? Il database può avere abbastanza connessioni per soddisfare le esigenze delle altre parti dell’applicazione?
Non abbiamo avuto altra scelta che tornare al tavolo del developer per ispezionare i cambiamenti in Git.
La nuova modifica prenderà alcune record da un tavolo e le processerà. Questo è ciò che abbiamo osservato nella classe del servizio.
List<X> findAll = this.xRepository.findAll();
No, utilizzare il metodo findAll() senza pagination in Spring’s CrudRepository non è efficiente. La pagination aiuta a ridurre il tempo necessario per recuperare i dati dalla base di dati limitando la quantità di dati estratta. Questo è ciò che ci ha insegnato la nostra formazione primaria su RDBMS. Inoltre, la pagination aiuta a mantenere basso l’uso della memoria per evitare che l’applicazione crashi a causa di un sovraccarico di dati, nonché a ridurre l’impegno della Garbage Collection della Java Virtual Machine, come menzionato nella dichiarazione del problema sopra.
Questo test è stato condotto utilizzando solo 2.000 record in un singolo contenitore. Se questo codice fosse stato spostato in produzione, dove ci sono circa 200.000 record in fino a 10 contenitori, avrebbe potuto causare molta ansia e preoccupazione alla squadra quel giorno.
L’applicazione è stata ricostruita con l’aggiunta di una clausola WHERE al metodo.
List<X> findAll = this.xRepository.findAllByY(Y);
Il funzionamento normale è stato ripristinato. Il numero di query al secondo è diminuito da 300 a 30, e l’impegno nella garbage collection è tornato al livello originale. Inoltre, l’utilizzo della CPU del sistema è diminuito.
Apprendimento e Sommario
Chiunque lavori nell’Ingegneria della Resilienza dei Siti (SRE) apprezzerà l’importanza di questa scoperta. Siamo stati in grado di agire su di essa senza dover innalzare una bandiera di Severità 1. Se questo pacchetto difettoso fosse stato distribuito in produzione, avrebbe potuto innescare la soglia di auto-scalabilità del cliente, causando l’avvio di nuovi contenitori anche senza un carico utente aggiuntivo.
Ci sono tre principali lezioni da questa storia.
In primo luogo, è buona pratica attivare una soluzione di osservabilità fin dall’inizio, poiché può fornire una cronologia degli eventi che può essere utilizzata per identificare potenziali problemi. Senza questa cronologia, potrei non aver preso sul serio una percentuale di Garbage Collection dello 0,1% e un consumo di CPU del 6%, e il codice potrebbe essere stato rilasciato in produzione con conseguenze disastrose. Ampliare la portata della soluzione di monitoraggio ai server UAT ha aiutato il team a identificare potenziali cause prime e prevenire problemi prima che si verifichino.
In secondo luogo, dovrebbero esistere casi di test legati alle prestazioni nel processo di testing, e questi dovrebbero essere rivisti da qualcuno esperto in osservabilità. Ciò garantirà che la funzionalità del codice sia testata, così come le sue prestazioni.
Terzo, le tecniche di tracciamento delle prestazioni native cloud sono buone per ricevere avvisi su alta utilizzazione, disponibilità, ecc. Per raggiungere l’osservabilità, potresti aver bisogno degli strumenti e competenze giuste. Buon Codice!
Source:
https://dzone.com/articles/shift-left-monitoring-approach-for-cloud-apps-in-c