













Questa è una parte della trasformazione digitale di un colosso immobiliare. Per motivi di riservatezza, non suggerirò alcun dato aziendale, ma otterrete una visione dettagliata del nostro data warehouse e delle nostre strategie di ottimizzazione.
Iniziamo.
Architettura
Logicamente, la nostra architettura dei dati può essere divisa in quattro parti.
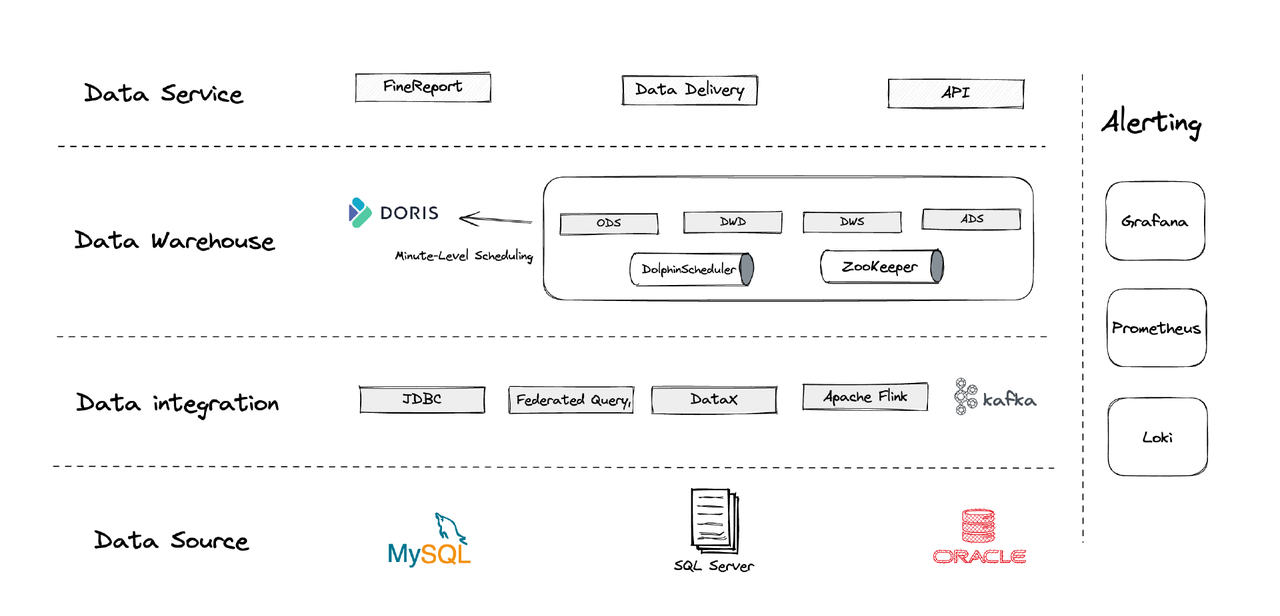
- Integrazione dati: Questa è supportata da Flink CDC, DataX e dalla funzione Multi-Catalog di Apache Doris.
- Gestione dati: Utilizziamo Apache Dolphinscheduler per la gestione del ciclo di vita dei script, i privilegi nella gestione multi-tenant e il monitoraggio della qualità dei dati.
- Allarmi: Utilizziamo Grafana, Prometheus e Loki per monitorare le risorse dei componenti e i log.
- Servizi dati: Qui entrano in gioco gli strumenti BI per l’interazione con l’utente, come query e analisi dei dati.
1. Tabelle
Creiamo le nostre tabelle dimensionali e di fatto centrate su ogni entità operativa nel business, inclusa la clientela, le case, ecc. Se ci sono una serie di attività che coinvolgono la stessa entità operativa, dovrebbero essere registrate da un unico campo. (Questa è una lezione appresa dal nostro precedente sistema di gestione dei dati caotico.)
2. Livelli
Il nostro data warehouse è diviso in cinque livelli concettuali. Utilizziamo Apache Doris e Apache DolphinScheduler per pianificare gli script DAG tra questi livelli.

Ogni giorno, i livelli subiscono un aggiornamento generale oltre a aggiornamenti incrementali in caso di modifiche nei campi di stato storici o di sincronizzazione dati incompleta delle tabelle ODS.
3. Strategie di Aggiornamento Incrementale
(1) Imposta where >= "activity time -1 giorno o -1 ora" invece di where >= "activity time
La ragione di questa scelta è prevenire lo spostamento dei dati causato dalla differenza temporale nei script di pianificazione. Supponiamo, con l’intervallo di esecuzione impostato a 10 minuti, che lo script venga eseguito alle 23:58:00 e che un nuovo dato arrivi alle 23:59:00. Se impostiamo where >= "activity time, quel dato del giorno verrebbe perso.
(2) Recupera l’ID della chiave primaria più grande della tabella prima di ogni esecuzione dello script, memorizza l’ID nella tabella ausiliaria e imposta where >= "ID nella tabella ausiliaria"
Questo serve a evitare la duplicazione dei dati. La duplicazione potrebbe verificarsi se si utilizza il modello di Chiave Unica di Apache Doris e si designano un set di chiavi primarie, perché se ci sono modifiche nelle chiavi primarie nella tabella sorgente, queste modifiche saranno registrate e i dati pertinenti saranno caricati. Questo metodo può risolvere il problema, ma è applicabile solo quando le tabelle sorgente hanno chiavi primarie a incremento automatico.
(3) Partiziona le tabelle
Per i dati con incremento automatico basato sul tempo, come tabelle di log, potrebbero esserci meno modifiche nei dati storici e nello stato, ma il volume di dati è elevato, quindi potrebbe esserci una grande pressione computazionale sulle operazioni di aggiornamento complessive e sulla creazione di snapshot. Pertanto, è meglio partizionare tali tabelle in modo che per ogni aggiornamento incrementale, ci sia bisogno solo di sostituire una partizione. (Potresti dover prestare attenzione anche alla deriva dei dati.)
4. Strategie di Aggiornamento Complessive
(1) Cancella Tabella
Rimuovi tutti i dati dalla tabella e quindi inserisci tutti i dati dalla tabella sorgente. Questo è applicabile per tabelle piccole e scenari senza attività degli utenti nelle ore piccole.
(2)ALTER TABLE tbl1 REPLACE WITH TABLE tbl2
Questa è un’operazione atomica, ed è consigliata per tabelle grandi. Ogni volta prima di eseguire uno script, creiamo una tabella temporanea con lo stesso schema, carichiamo tutti i dati in essa e sostituiamo la tabella originale con essa.
Applicazione
- Job ETL: ogni minuto
- Configurazione per il primo deploy: 8 nodi, 2 front-end, 8 back-end, deployment ibrido
- Configurazione del nodo: 32C * 60GB * 2TB SSD
Questa è la nostra configurazione per TBs di dati legacy e GBs di dati incrementali. Puoi usarla come riferimento e dimensionare il tuo cluster a partire da questo. Il deployment di Apache Doris è semplice. Non hai bisogno di altri componenti.
1. Per integrare i dati offline e i log, utilizziamo DataX, che supporta il formato CSV e lettori di molti database relazionali, e Apache Doris fornisce un DataX-Doris-Writer.

2. Utilizziamo Flink CDC per sincronizzare i dati dalle tabelle di origine. Successivamente, aggregiamo le metriche in tempo reale utilizzando la Vista Materializzata o il Modello Aggregato di Apache Doris. Poiché dobbiamo elaborare solo una parte delle metriche in modo reale e non vogliamo generare troppi collegamenti al database, utilizziamo un unico job Flink per gestire più tabelle di origine CDC. Questo è realizzato dalle funzionalità di merging multi-sorgente e sincronizzazione completa del database di Dinky, oppure puoi implementare un task di merging multi-sorgente Flink DataStream da solo. È importante notare che Flink CDC e Apache Doris supportano il Cambio di Schema.
EXECUTE CDCSOURCE demo_doris WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '10000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'ods.ods_*,ods.ods_*',
'sink.connector' = 'doris',
'sink.fenodes' = '127.0.0.1:8030',
'sink.username' = 'root',
'sink.password' = '123456',
'sink.doris.batch.size' = '1000',
'sink.sink.max-retries' = '1',
'sink.sink.batch.interval' = '60000',
'sink.sink.db' = 'test',
'sink.sink.properties.format' ='json',
'sink.sink.properties.read_json_by_line' ='true',
'sink.table.identifier' = '${schemaName}.${tableName}',
'sink.sink.label-prefix' = '${schemaName}_${tableName}_1'
);3. Utilizziamo script SQL o “Shell + SQL” e gestiamo il ciclo di vita degli script. Alla livello ODS, scriviamo un file di job DataX generale e passiamo parametri per ogni inserimento della tabella di origine invece di scrivere un job DataX per ogni tabella di origine. In questo modo, rendiamo molto più semplice la manutenzione. Gestiamo gli script ETL di Apache Doris su DolphinScheduler, dove effettuiamo anche il controllo delle versioni. In caso di errori nell’ambiente di produzione, possiamo sempre eseguire il rollback.
4. Dopo l’ingestione dei dati con gli script ETL, creiamo una pagina nel nostro strumento di reporting. Assegniamo privilegi diversi a diversi account utilizzando SQL, inclusa la possibilità di modificare righe, campi e dizionari globali. Apache Doris supporta il controllo dei privilegi sugli account, che funziona allo stesso modo di quello in MySQL.
Utilizziamo anche il backup dei dati Apache Doris per il disaster recovery, i log di audit di Apache Doris per monitorare l’efficienza dell’esecuzione delle query SQL, Grafana+Loki per gli avvisi sulle metriche del cluster e Supervisor per monitorare i processi demoni dei componenti dei nodi.
Ottimizzazione
Ingestione Dati
Utilizziamo DataX per caricare in streaming i dati offline. Ciò ci consente di regolare la dimensione di ogni batch. Il metodo Stream Load restituisce risultati in modo sincrono, il che soddisfa le esigenze della nostra architettura. Se eseguiamo l’importazione di dati asincrona utilizzando DolphinScheduler, il sistema potrebbe presumere che lo script sia stato eseguito, il che può causare confusione. Se utilizzi un metodo diverso, ti consigliamo di eseguire show load nello script shell e di controllare lo stato di filtraggio dei regex per vedere se l’ingestione ha successo.
Modello Dati
Adottiamo il modello Unique Key di Apache Doris per la maggior parte delle nostre tabelle. Il modello Unique Key garantisce l’idempotenza dei script dei dati e evita efficacemente la duplicazione dei dati dall’upstream.
Lettura Dati Esterni
Utilizziamo la funzionalità Multi-Catalog di Apache Doris per connetterci a fonti di dati esterne. Ciò ci consente di creare mapping di dati esterni a livello di Catalog.
Ottimizzazione delle Query
Ti suggeriamo di inserire i campi più utilizzati di tipo non carattere (come int e clausole where) nei primi 36 byte, in modo da poter filtrare questi campi in pochi millisecondi nelle query puntuali.
Dizionario Dati
Per noi, è fondamentale creare un dizionario dei dati poiché riduce in modo significativo i costi di comunicazione del personale, che possono essere un problema quando si ha una grande squadra. Utilizziamo il information_schema in Apache Doris per generare un dizionario dei dati. Con esso, possiamo rapidamente comprendere l’intera struttura delle tabelle e dei campi e quindi aumentare l’efficienza dello sviluppo.
Prestazioni
Tempo di ingestione dei dati offline: Entro pochi minuti
Latenza delle query: Per le tabelle contenenti oltre 100 milioni di righe, Apache Doris risponde alle query ad-hoc in un secondo e alle query complesse in cinque secondi.
Consumo di risorse: Richiede solo un piccolo numero di server per costruire questo data warehouse. Il rapporto di compressione del 70% di Apache Doris ci consente di risparmiare molte risorse di archiviazione.
Esperienza e Conclusioni
In realtà, prima di evolverci nell’attuale architettura dei dati, abbiamo provato Hive, Spark e Hadoop per costruire un data warehouse offline. Si è rivelato che Hadoop era eccessivo per una società tradizionale come la nostra, poiché non avevamo troppi dati da elaborare. È importante trovare il componente che meglio si adatta alle proprie esigenze.
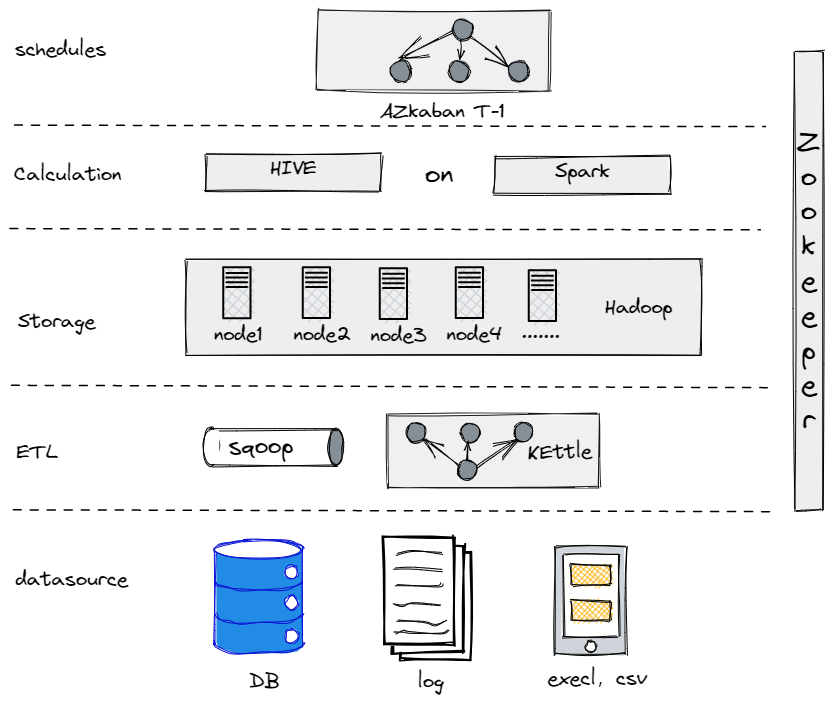
Il Nostro Vecchio Data Warehouse Offline
D’altra parte, per agevolare la nostra transizione verso big data, è necessario rendere la nostra piattaforma dati il più semplice possibile sia in termini di utilizzo che di manutenzione. Ecco perché abbiamo optato per Apache Doris. Essa è compatibile con il protocollo MySQL e offre una vasta gamma di funzioni, evitando quindi la necessità di sviluppare i propri UDF. Inoltre, è costituita da solo due tipi di processi: front-end e back-end, il che la rende facile da scalare e monitorare.
Source:
https://dzone.com/articles/building-a-data-warehouse-for-traditional-industry