













In questo articolo review come installare, aggiornare e rimuovere pacchetti in Red Hat Enterprise Linux 7. Vedremo anche come automatizzare le attività usando cron e concluseremo questo guide spiegando come trovare e interpretare i file di log del sistema con l’obiettivo di insegnarvi perché queste sono capacità essenziali per ogni amministratore di sistema.

Gestione Pacchetti tramite Yum
Per installare un pacchetto insieme a tutte le sue dipendenze che non sono già state installate, userai:
# yum -y install package_name(s)
Dove package_name(s) rappresentano almeno un nome di pacchetto reale.
Ad esempio, per installare httpd e mlocate (nell’ordine indicato), digita.
# yum -y install httpd mlocate
Nota: Il lettera y nell’esempio precedente ignora le richieste di conferma che yum presenta prima di eseguire la download e l’installazione effettiva dei programmi richiesti. Puoi lasciare fuori se ti piace.
Per default, yum installerà il pacchetto con l’architettura che corrisponde all’architettura del SO, a meno di essere override aggiungendo l’architettura del pacchetto prima del suo nome.
Ad esempio, su un sistema 64 bit, yum install package installerà la versione x86_64 del pacchetto, mentre yum install package.x86 (se disponibile) installerà la versione 32-bit.
Ci saranno momenti in cui vuoi installare un pacchetto ma non sai esattamente come si chiama. Le opzioni search all o search possono cercare nei repository attualmente abilitati un determinato keyword nel nome del pacchetto e/o nella sua descrizione, rispettivamente.
Ad esempio,
# yum search log
cercherà nei repository installati i pacchetti che contengono la parola log nei loro nomi e nelle loro schede, mentre
# yum search all log
proverrà lo stesso keyword nella descrizione del pacchetto e nei campi url anche.
Una volta che la ricerca restituisce una lista di pacchetti, potresti volere mostrare informazioni ulteriori su di alcuni di essi prima dell’installazione. E ‘quando la opzione info si rivelerà utile:
# yum info logwatch
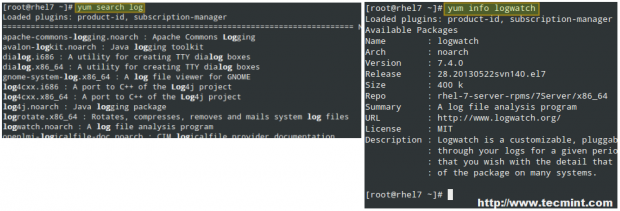
Puoi controllare regolarmente per aggiornamenti con il seguente comando:
# yum check-update
Il comando sopra restituirà tutti i pacchetti installati per i quali è disponibile un aggiornamento. Nell’esempio mostrato sotto l’immagine, solo rhel-7-server-rpms ha un aggiornamento disponibile:

Poi puoi aggiornare solo quel pacchetto con,
# yum update rhel-7-server-rpms
Se ci sono molti pacchetti da aggiornare, yum update aggiornarà tutti in una sola volta.
Ma cosa succede quando conosci il nome di un’esecuzibile, come ps2pdf, ma non sai quale pacchetto lo fornisce? Puoi scoprire con yum whatprovides “*/[executable]”:
# yum whatprovides “*/ps2pdf”

Ora, quando si tratta di rimuovere un pacchetto, puoi farlo con yum remove package. Facile, no? questo dimostra che yum è un gestore di pacchetti completo e potente.
# yum remove httpd
Leggi anche: 20 Comandi Yum per la gestione del package management in RHEL 7
RPM, il Vecchio e semplice
RPM (anche noto come RPM Package Manager, o in origine come RedHat Package Manager) può anche essere utilizzato per installare o aggiornare i pacchetti quando sono presenti come pacchetti autonomi .rpm.
Di solito viene utilizzato con gli stili -Uvh per indicare che deve installare il pacchetto se non è già presente o tentare di aggiornarlo se è installato (-U), fornendo un output dettagliato (-v) e una progress bar con hash marks (-h) mentre l’operazione è in corso. Ad esempio,
# rpm -Uvh package.rpm
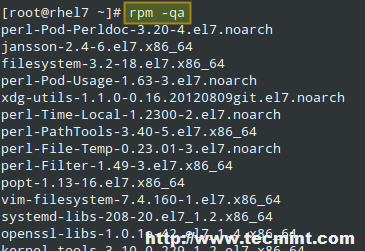
Un’altra tipica utilizzazione di rpm è produrre una lista di tutti i pacchetti attualmente installati con code>rpm -qa (abbreviazione per query all):
# rpm -qa
Leggi anche: 20 Comandi RPM per installare i pacchetti in RHEL 7
pianificazione delle attività tramite Cron
I sistemi operativi Linux e altri di tipo Unix includono uno strumento chiamato cron che consente di pianificare attività (cioè comandi o script di shell) per essere eseguite in base a una pianificazione periodica. Cron controlla ogni minuto la directory /var/spool/cron per file che sono nominati dopo le account in /etc/passwd.
Quando si eseguono comandi, tutti gli output vengono inviati al proprietario del crontab (o all’utente specificato nella variabile di ambiente MAILTO nel file /etc/crontab, se esiste).
I file crontab (che vengono creati digitando crontab -e e premendo Invio) hanno il seguente formato:

Quindi, se vogliamo aggiornare il database locale dei file (usato da locate per trovare file per nome o pattern) ogni secondo giorno del mese alle 2:15 del mattino, dobbiamo aggiungere il seguente ingresso crontab:
15 02 2 * * /bin/updatedb
L’ingresso crontab sopra riportato dice: “Esegui /bin/updatedb il secondo giorno del mese, ogni mese dell’anno, indipendentemente dal giorno della settimana, alle 2:15 del mattino”. Come avrai già indovinato, il simbolo asterisco viene utilizzato come carattere jolly.
Dopo aver aggiunto un compito cron, è possibile vedere che è stato aggiunto un file chiamato root all’interno di /var/spool/cron, come abbiamo menzionato in precedenza. Quel file elenca tutti i compiti che il demone crond dovrebbe eseguire:
# ls -l /var/spool/cron
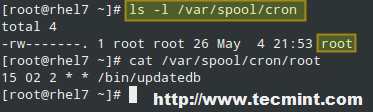
Nell’immagine sopra, il crontab dell’utente attuale può essere visualizzato utilizzando cat /var/spool/cron/root o,
# crontab -l
Se è necessario eseguire un compito su base più dettagliata (ad esempio, due volte al giorno o tre volte ogni mese), cron può aiutarti anche in questo.
Ad esempio, per eseguire /my/script il primo e il quindici di ogni mese e inviare qualsiasi output a /dev/null, è possibile aggiungere due ingressi crontab come segue:
01 00 1 * * /myscript > /dev/null 2>&1 01 00 15 * * /my/script > /dev/null 2>&1
Ma per renderlo più facile da mantenere, puoi combinare entrambi gli elementi in un solo record:
01 00 1,15 * * /my/script > /dev/null 2>&1
Seguendo l’esempio precedente, puoi eseguire /my/other/script alle 1:30 am del primo giorno di ogni tre mesi:
30 01 1 1,4,7,10 * /my/other/script > /dev/null 2>&1
Ma quando devi ripetere una determinata attività ogni “x” minuti, ore, giorni o mesi, puoi dividere la posizione destra dalla frequenza desiderata. La seguente voce crontab ha esattamente lo stesso significato dell’ precedente:
30 01 1 */3 * /my/other/script > /dev/null 2>&1
O forse hai bisogno di eseguire un determinato compito con una frequenza fissa o dopo il boot del sistema, ad esempio. Puoi usare una delle seguenti stringhe invece dei cinque campi per indicare l’ora esatta in cui vuoi che il tuo compito venga eseguito:
@reboot Run when the system boots. @yearly Run once a year, same as 00 00 1 1 *. @monthly Run once a month, same as 00 00 1 * *. @weekly Run once a week, same as 00 00 * * 0. @daily Run once a day, same as 00 00 * * *. @hourly Run once an hour, same as 00 * * * *.
Leggi anche: 11 Comandi per pianificare i Posti di Lavoro in Cron in RHEL 7
Ricerca e Verifica dei Log
I log del sistema si trovano (e vengono rotati) all’interno della directory /var/log. secondo lo standard di gerarchia del filesystem Linux, questa directory contiene log generici, che vengono scritti in essa o in una sottodirectory appropriata (come audit, httpd o samba nell’immagine seguente) dademon in fase di operazione del sistema:
# ls /var/log

Altri log interessanti sono dmesg (contiene tutti i messaggi dal buffer ad anello del kernel), secure (registra i tentativi di connessione che richiedono autenticazione dell’utente), messages (messaggi a livello di sistema) e wtmp (registra tutti i login e logout degli utenti).
I log sono molto importanti perché ti consentono di dare un’occhiata a ciò che sta succedendo in ogni momento nel tuo sistema e a ciò che è successo in passato. Rappresentano uno strumento prezioso per risolvere i problemi e monitorare un server Linux, e per questo spesso vengono utilizzati con il comando tail -f per visualizzare gli eventi in tempo reale, man mano che avvengono e vengono registrati in un log.
Ad esempio, se si desidera visualizzare eventi correlati al kernel, digitare il seguente comando:
# tail -f /var/log/dmesg
Lo stesso vale se si desidera visualizzare l’accesso al proprio server web:
# tail -f /var/log/httpd/access.log
Riepilogo
Se sai gestire efficientemente i pacchetti, pianificare compiti e sapere dove cercare informazioni sull’operatività attuale e passata del tuo sistema, puoi essere certo di non avere sorprese molto spesso. Spero che questo articolo ti abbia aiutato a imparare o a rinfrescare le tue conoscenze su queste competenze di base.
Non esitare a scriverci utilizzando il modulo di contatto qui sotto se hai domande o commenti.
Source:
https://www.tecmint.com/yum-package-management-cron-job-scheduling-monitoring-linux-logs/