













Whisper AI è un modello avanzato di riconoscimento automatico del parlato (ASR) sviluppato da OpenAI che può trascrivere audio in testo con un’accuratezza impressionante e supporta più lingue. Sebbene Whisper AI sia principalmente progettato per l’elaborazione in batch, può essere configurato per la trascrizione in tempo reale del parlato su Linux.
In questa guida, esamineremo il processo passo passo per installare, configurare e far funzionare Whisper AI per la trascrizione dal vivo su un sistema Linux.
Cosa è Whisper AI?
Whisper AI è un modello di riconoscimento vocale open-source addestrato su un vasto dataset di registrazioni audio ed è basato su un’architettura di deep learning che gli consente di:
- Trascrivere il parlato in più lingue.
- Gestire accenti e rumori di fondo in modo efficiente.
- Eseguire la traduzione del linguaggio parlato in inglese.
Poiché è progettato per una trascrizione ad alta precisione, è ampiamente utilizzato in:
- Servizi di trascrizione dal vivo (ad esempio, per l’accessibilità).
- Assistenti vocali e automazione.
- Trascrivere file audio registrati.
Per impostazione predefinita, Whisper AI non è ottimizzato per l’elaborazione in tempo reale. Tuttavia, con alcuni strumenti aggiuntivi, può elaborare flussi audio dal vivo per una trascrizione immediata.
Requisiti di sistema per Whisper AI
Prima di eseguire Whisper AI su Linux, assicurati che il tuo sistema soddisfi i seguenti requisiti:
Requisiti Hardware:
- CPU: Un processore multi-core (Intel/AMD).
- RAM: Almeno 8GB (si consigliano 16GB o più).
- GPU: GPU NVIDIA con CUDA (opzionale ma accelera significativamente l’elaborazione).
- Archiviazione: Minimo 10GB di spazio libero su disco per modelli e dipendenze.
Requisiti Software:
- Una distribuzione Linux come Ubuntu, Debian, Arch, Fedora, ecc.
- Python versione 3.8 o successiva.
- Gestore di pacchetti Pip per l’installazione dei pacchetti Python.
- FFmpeg per la gestione dei file audio e dei flussi.
Passaggio 1: Installazione delle Dipendenze Richieste
Prima di installare Whisper AI, aggiorna l’elenco dei pacchetti e aggiorna i pacchetti esistenti.
sudo apt update [On Ubuntu] sudo dnf update -y [On Fedora] sudo pacman -Syu [On Arch]
Successivamente, devi installare Python 3.8 o versioni successive e il gestore di pacchetti Pip come mostrato.
sudo apt install python3 python3-pip python3-venv -y [On Ubuntu] sudo dnf install python3 python3-pip python3-virtualenv -y [On Fedora] sudo pacman -S python python-pip python-virtualenv [On Arch]
Infine, devi installare FFmpeg, che è un framework multimediale utilizzato per elaborare file audio e video.
sudo apt install ffmpeg [On Ubuntu] sudo dnf install ffmpeg [On Fedora] sudo pacman -S ffmpeg [On Arch]
Passaggio 2: Installa Whisper AI in Linux
Una volta installate le dipendenze richieste, puoi procedere all’installazione di Whisper AI in un ambiente virtuale che ti consente di installare pacchetti Python senza influire sui pacchetti di sistema.
python3 -m venv whisper_env source whisper_env/bin/activate pip install openai-whisper
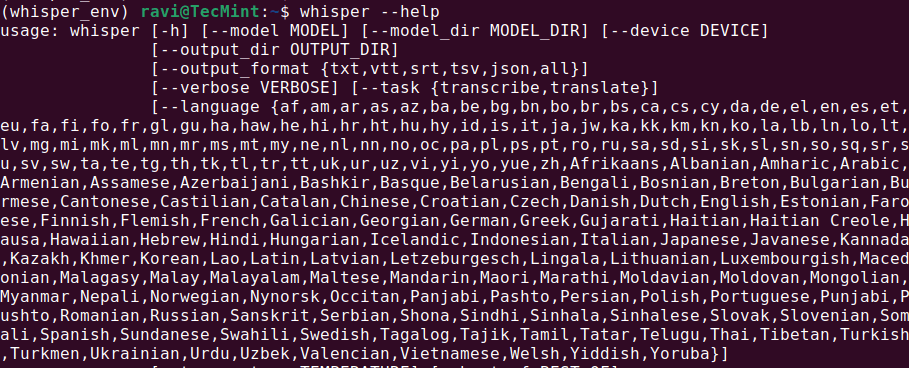
Una volta completata l’installazione, verifica se Whisper AI è stato installato correttamente eseguendo.
whisper --help
Questo dovrebbe visualizzare un menu di aiuto con comandi e opzioni disponibili, il che significa che Whisper AI è installato e pronto per essere utilizzato.
Passo 3: Eseguire Whisper AI su Linux
Una volta installato Whisper AI, puoi iniziare a trascrivere file audio utilizzando diversi comandi.
Trascrivere un file audio
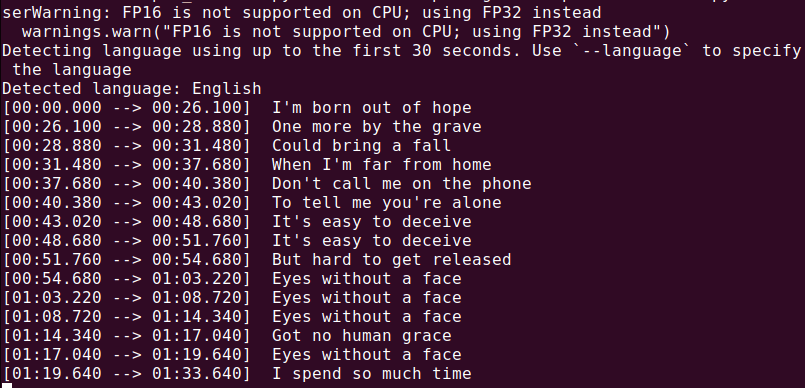
Per trascrivere un file audio (audio.mp3), esegui:
whisper audio.mp3
Whisper elaborerà il file e genererà una trascrizione in formato testo.
Ora che tutto è installato, creiamo uno script Python per catturare audio dal tuo microfono e trascriverlo in tempo reale.
nano real_time_transcription.py
Copia e incolla il seguente codice nel file.
import sounddevice as sd
import numpy as np
import whisper
import queue
import threading
# Load the Whisper model
model = whisper.load_model("base")
# Audio parameters
SAMPLE_RATE = 16000
BUFFER_SIZE = 1024
audio_queue = queue.Queue()
def audio_callback(indata, frames, time, status):
"""Callback function to capture audio data."""
if status:
print(status)
audio_queue.put(indata.copy())
def transcribe_audio():
"""Thread to transcribe audio in real time."""
while True:
audio_data = audio_queue.get()
audio_data = np.concatenate(list(audio_queue.queue)) # Combine buffered audio
audio_queue.queue.clear()
# Transcribe the audio
result = model.transcribe(audio_data.flatten(), language="en")
print(f"Transcription: {result['text']}")
# Start the transcription thread
transcription_thread = threading.Thread(target=transcribe_audio, daemon=True)
transcription_thread.start()
# Start capturing audio from the microphone
with sd.InputStream(callback=audio_callback, channels=1, samplerate=SAMPLE_RATE, blocksize=BUFFER_SIZE):
print("Listening... Press Ctrl+C to stop.")
try:
while True:
pass
except KeyboardInterrupt:
print("\nStopping...")
Esegui lo script utilizzando Python, che inizierà ad ascoltare l’input del tuo microfono e visualizzerà il testo trascritto in tempo reale. Parla chiaramente nel tuo microfono e dovresti vedere i risultati stampati nel terminale.
python3 real_time_transcription.py
Conclusione
Whisper AI è uno strumento potente di riconoscimento vocale che può essere adattato per la trascrizione in tempo reale su Linux. Per ottenere i migliori risultati, utilizza una GPU e ottimizza il tuo sistema per l’elaborazione in tempo reale.
Source:
https://www.tecmint.com/whisper-ai-audio-transcription-on-linux/