













Quando si lavora con Amazon S3 (Simple Storage Service), probabilmente si utilizza il console web di S3 per scaricare, copiare o caricare file nei bucket di S3. Utilizzare la console è assolutamente valido, è stato progettato per questo, in primo luogo.
Soprattutto per gli amministratori abituati a fare più clic con il mouse che a usare i comandi da tastiera, la console web è probabilmente la più semplice. Tuttavia, gli amministratori alla fine incontreranno la necessità di eseguire operazioni su file bulk con Amazon S3, come un caricamento di file non assistito. L’interfaccia grafica non è il miglior strumento per questo.
Per tali requisiti di automazione con Amazon Web Services, inclusi Amazon S3, lo strumento AWS CLI fornisce agli amministratori opzioni da riga di comando per gestire i bucket e gli oggetti di Amazon S3.
In questo articolo, imparerai come utilizzare lo strumento AWS CLI da riga di comando per caricare, copiare, scaricare e sincronizzare file con Amazon S3. Imparerai anche le basi per fornire l’accesso al tuo bucket S3 e configurare quel profilo di accesso per funzionare con lo strumento AWS CLI.
Prerequisiti
Poiché questo è un articolo su come fare, ci saranno esempi e dimostrazioni nelle sezioni successive. Per seguirci con successo, dovrai soddisfare diversi requisiti.
- Un account AWS. Se non hai già una sottoscrizione AWS esistente, puoi registrarti per un AWS Free Tier.
- Un bucket AWS S3. Puoi utilizzare un bucket esistente se preferisci. Tuttavia, è consigliabile creare invece un bucket vuoto. Si prega di fare riferimento a Creazione di un bucket.
- A Windows 10 computer with at least Windows PowerShell 5.1. In this article, PowerShell 7.0.2 will be used.
- Lo strumento AWS CLI versione 2 deve essere installato sul tuo computer.
- Cartelle e file locali che caricherai o sincronizzerai con Amazon S3
Preparazione dell’accesso a AWS S3
Supponendo che tu abbia già soddisfatto i requisiti. Penseresti di poter già utilizzare AWS CLI con il tuo bucket S3. Voglio dire, non sarebbe bello se fosse così semplice?
Per coloro che stanno iniziando a lavorare con Amazon S3 o AWS in generale, questa sezione mira ad aiutarti a configurare l’accesso a S3 e a configurare un profilo AWS CLI.
La documentazione completa per la creazione di un utente IAM in AWS può essere trovata nel seguente link. Creazione di un utente IAM nel tuo account AWS
Creazione di un utente IAM con autorizzazione di accesso a S3
Quando si accede ad AWS usando la CLI, sarà necessario creare uno o più utenti IAM con abbastanza accesso alle risorse con cui intendi lavorare. In questa sezione, creerai un utente IAM con accesso ad Amazon S3.
Per creare un utente IAM con accesso a Amazon S3, è prima necessario accedere alla tua console AWS IAM. Nel gruppo Access management, clicca su Users. Successivamente, fai clic su Add user.
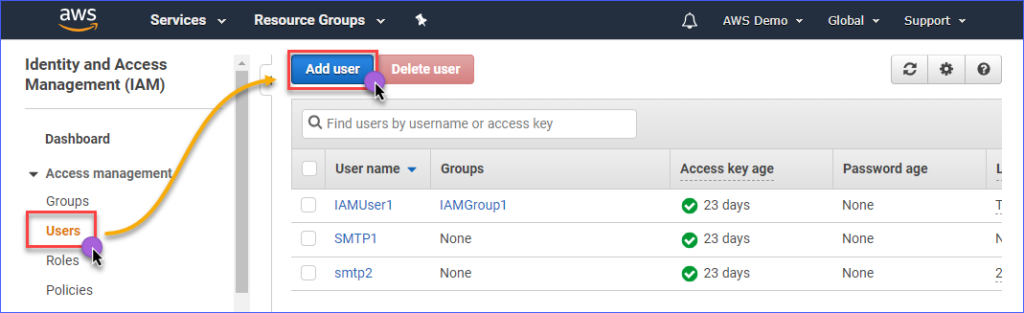
Inserisci il nome dell’utente IAM che stai creando nel campo User name come ad esempio s3Admin. Nella selezione Access type*, spunta Programmatic access. Quindi, clicca su Next: Permissions.

Successivamente, fai clic su Attach existing policies directly. Cerca il nome della policy AmazonS3FullAccess e spunta la casella corrispondente. Una volta fatto, clicca su Next: Tags.

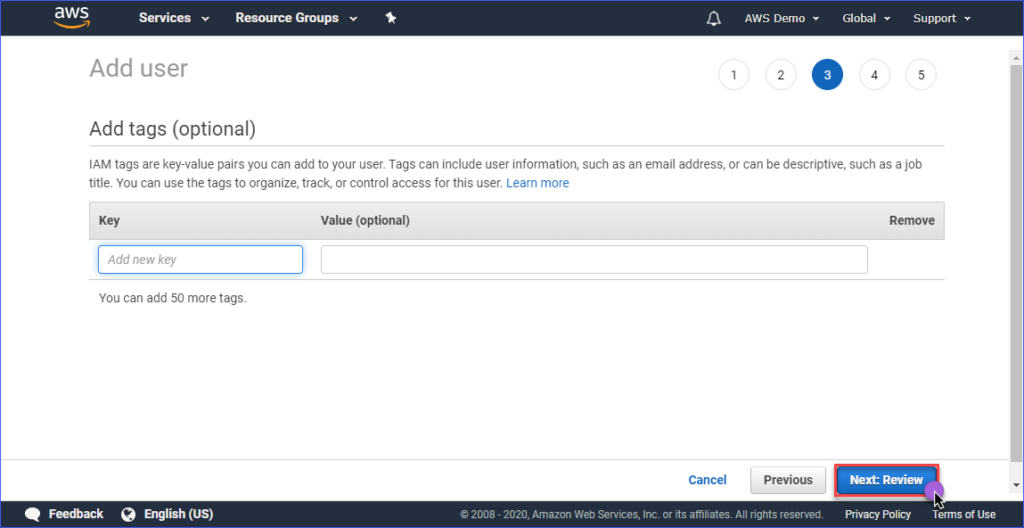
La creazione di tag è facoltativa nella pagina Add tags, puoi semplicemente saltarla e fare clic su Next: Review button.
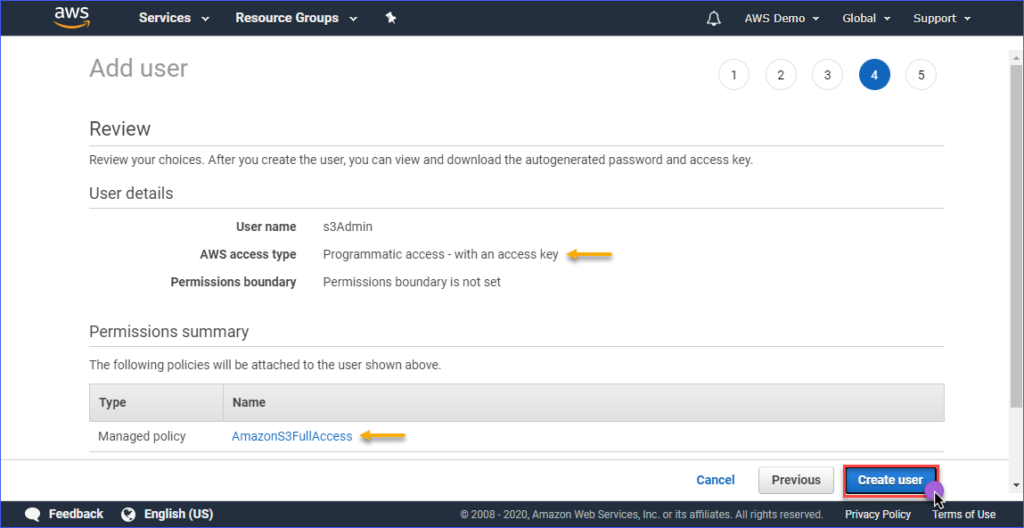
Nella pagina Review, ti verrà presentato un riepilogo del nuovo account in fase di creazione. Clicca su Create user.
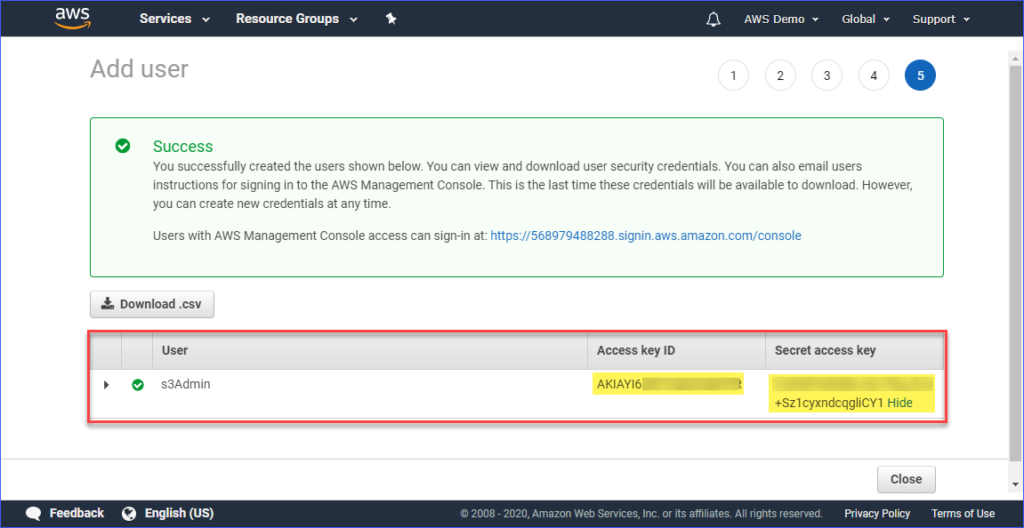
Infine, una volta creato l’utente, è necessario copiare i valori di Access key ID e Secret access key e salvarli per un uso futuro. Nota che questa è l’unica occasione in cui puoi visualizzare questi valori.
Configurazione di un profilo AWS sul tuo computer
Ora che hai creato l’utente IAM con l’accesso appropriato a Amazon S3, il passo successivo è configurare il profilo AWS CLI sul tuo computer.
Questa sezione presuppone che tu abbia già installato lo strumento AWS CLI versione 2 come richiesto. Per la creazione del profilo, avrai bisogno delle seguenti informazioni:
- L’ID chiave di accesso dell’utente IAM.
- La chiave di accesso segreta associata all’utente IAM.
- Il nome della regione predefinita corrisponde alla posizione del tuo bucket AWS S3. Puoi consultare l’elenco degli endpoint utilizzando questo link. In questo articolo, il bucket AWS S3 si trova nella regione Asia Pacifico (Sydney), e l’endpoint corrispondente è ap-southeast-2.
- Il formato di output predefinito. Utilizza JSON per questo.
Per creare il profilo, apri PowerShell e digita il comando seguente e segui le istruzioni.
Inserisci l’ID chiave di accesso, la chiave di accesso segreta, il nome della regione predefinita, e il nome di output predefinito. Fai riferimento alla dimostrazione qui sotto.

Test di accesso AWS CLI
Dopo aver configurato il profilo AWS CLI, puoi verificare che il profilo funzioni eseguendo il seguente comando in PowerShell.
Il comando sopra dovrebbe elencare i bucket Amazon S3 che hai nel tuo account. La dimostrazione qui sotto mostra il comando in azione. Il risultato mostra che l’elenco dei bucket S3 disponibili indica che la configurazione del profilo è stata eseguita con successo.

Per apprendere sui comandi AWS CLI specifici per Amazon S3, puoi visitare la pagina Riferimento ai Comandi AWS CLI S3.
Gestione dei File in S3
Con AWS CLI, le operazioni tipiche di gestione dei file possono essere eseguite come caricare file su S3, scaricare file da S3, eliminare oggetti in S3 e copiare oggetti S3 in un’altra posizione S3. È solo una questione di conoscere il comando giusto, la sintassi, i parametri e le opzioni.
Nelle sezioni seguenti, l’ambiente utilizzato consiste nei seguenti elementi.
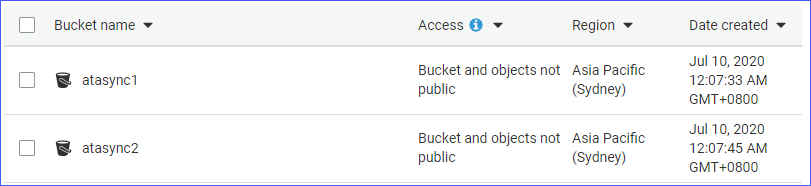
- Due bucket S3, chiamati atasync1e atasync2. La schermata qui sotto mostra i bucket S3 esistenti nella console Amazon S3.
- Directory locale e file situati sotto c:\sync.

Caricamento File Singoli su S3
Quando carichi file su S3, puoi caricare un file alla volta o caricare più file e cartelle in modo ricorsivo. A seconda delle tue esigenze, puoi scegliere quello che ritieni più appropriato.
Per caricare un file su S3, dovrai fornire due argomenti (origine e destinazione) al comando aws s3 cp.
Ad esempio, per caricare il file c:\sync\logs\log1.xml nella radice del bucket atasync1, puoi utilizzare il comando seguente.
Nota: i nomi dei bucket S3 sono sempre prefissati con S3:// quando utilizzati con AWS CLI
Esegui il comando sopra in PowerShell, ma cambia prima la sorgente e la destinazione in modo che si adattino al tuo ambiente. L’output dovrebbe assomigliare alla dimostrazione seguente.

La demo sopra mostra che il file denominato c:\sync\logs\log1.xml è stato caricato senza errori nella destinazione S3 s3://atasync1/.
Utilizza il comando qui sotto per elencare gli oggetti alla radice del bucket S3.
Eseguire il comando sopra in PowerShell produrrà un output simile, come mostrato nella demo sotto. Come puoi vedere nell’output sottostante, il file log1.xml è presente nella radice della posizione S3.

Caricamento di file e cartelle multipli su S3 in modo ricorsivo
La sezione precedente ti ha mostrato come copiare un singolo file in una posizione S3. Cosa succede se devi caricare più file da una cartella e da sottocartelle? Sicuramente non vorresti eseguire lo stesso comando più volte per nomi file diversi, giusto?
Il comando aws s3 cp ha un’opzione per elaborare file e cartelle in modo ricorsivo, ed è l’opzione --recursive.
Come esempio, la directory c:\sync contiene 166 oggetti (file e sottocartelle).
Utilizzando l’opzione --recursive, tutti i contenuti della cartella c:\sync verranno caricati su S3 mantenendo anche la struttura delle cartelle. Per testare, utilizza il codice di esempio qui sotto, ma assicurati di cambiare la sorgente e la destinazione in modo appropriato per il tuo ambiente.
Noterai dal codice qui sotto che la sorgente è c:\sync e la destinazione è s3://atasync1/sync. La chiave /sync che segue il nome del bucket S3 indica all’AWS CLI di caricare i file nella cartella /sync in S3. Se la cartella /sync non esiste in S3, verrà creata automaticamente.
Il codice sopra produrrà l’output, come mostrato nella dimostrazione qui sotto.

Caricamento di file e cartelle multipli su S3 in modo selettivo
In alcuni casi, caricare TUTTI i tipi di file non è la migliore opzione. Ad esempio, quando è necessario caricare solo file con estensioni specifiche (ad esempio, *.ps1). Altre due opzioni disponibili per il comando cp sono --include e --exclude.
Mentre l’utilizzo del comando nella sezione precedente include tutti i file nel caricamento ricorsivo, il comando qui sotto includerà solo i file che corrispondono all’estensione del file *.ps1 ed escluderà ogni altro file dal caricamento.
La dimostrazione qui sotto mostra come funziona il codice sopra quando viene eseguito.

Un altro esempio è se si desidera includere più estensioni di file diverse, sarà necessario specificare l’opzione --include più volte.
Il comando di esempio qui sotto includerà solo i file *.csv e *.png nel comando di copia.
Eseguendo il codice sopra in PowerShell ti presenterà un risultato simile, come mostrato di seguito.

Scaricamento di oggetti da S3
Basandoti sugli esempi appresi in questa sezione, puoi anche eseguire le operazioni di copia in senso inverso. Ciò significa che puoi scaricare gli oggetti dalla posizione del bucket S3 al computer locale.
La copia da S3 a locale richiede di invertire le posizioni della sorgente e della destinazione. La sorgente è la posizione S3 e la destinazione è il percorso locale, come mostrato di seguito.
Nota che le stesse opzioni utilizzate durante il caricamento dei file su S3 sono applicabili anche durante il download degli oggetti da S3 al locale. Ad esempio, scaricare tutti gli oggetti utilizzando il comando seguente con l’opzione --recursive.
Copia di oggetti tra le posizioni S3
Oltre al caricamento e al download di file e cartelle, utilizzando AWS CLI, puoi anche copiare o spostare file tra due posizioni del bucket S3.
Noterai il comando di seguito che utilizza una posizione S3 come sorgente e un’altra posizione S3 come destinazione.
La dimostrazione seguente mostra il file di origine copiato in un’altra posizione S3 utilizzando il comando sopra.

Sincronizzazione di file e cartelle con S3
Hai imparato finora come caricare, scaricare e copiare file in S3 utilizzando i comandi AWS CLI. In questa sezione, imparerai un altro comando di operazione sui file disponibile in AWS CLI per S3, che è il comando sync. Il comando sync elabora solo i file aggiornati, nuovi ed eliminati.
Ci sono alcuni casi in cui è necessario mantenere aggiornati e sincronizzati i contenuti di un bucket S3 con una directory locale su un server. Ad esempio, potrebbe essere necessario mantenere sincronizzati su S3 i log delle transazioni presenti su un server a intervalli regolari.
Utilizzando il comando di seguito riportato, i file di log *.XML situati nella cartella c:\sync del server locale saranno sincronizzati con la posizione S3 su s3://atasync1.
La dimostrazione qui sotto mostra che dopo l’esecuzione del comando sopra riportato in PowerShell, tutti i file *.XML sono stati caricati nella destinazione S3 s3://atasync1/.

Sincronizzazione di nuovi file e file modificati con S3
Nell’esempio seguente si suppone che il contenuto del file di log Log1.xml sia stato modificato. Il comando sync dovrebbe rilevare tale modifica e caricare sul S3 le modifiche apportate al file locale, come mostrato nella dimostrazione qui sotto.
Il comando da utilizzare è ancora lo stesso dell’esempio precedente.

Come si può vedere dall’output sopra riportato, poiché solo il file Log1.xml è stato modificato localmente, è stato l’unico file sincronizzato su S3.
Sincronizzazione delle eliminazioni con S3
Per impostazione predefinita, il comando sync non elabora le eliminazioni. Qualsiasi file eliminato dalla posizione di origine non viene rimosso dalla destinazione. A meno che non si utilizzi l’opzione --delete.
Nell’esempio seguente, il file di nome Log5.xml è stato eliminato dalla posizione di origine. Il comando per sincronizzare i file sarà completato con l’opzione --delete, come mostrato nel codice qui sotto.
Quando si esegue il comando sopra in PowerShell, il file eliminato denominato Log5.xml dovrebbe essere eliminato anche nella posizione di destinazione S3. Di seguito viene mostrato un esempio di risultato.

Riepilogo
Amazon S3 è una risorsa eccellente per archiviare file nel cloud. Con l’uso dello strumento AWS CLI, il modo in cui si utilizza Amazon S3 viene ulteriormente ampliato e si apre l’opportunità di automatizzare i processi.
In questo articolo, hai imparato come utilizzare lo strumento AWS CLI per caricare, scaricare e sincronizzare file e cartelle tra posizioni locali e bucket S3. Hai anche appreso che i contenuti dei bucket S3 possono essere copiati o spostati anche in altre posizioni S3.
Può esserci molti altri scenari di utilizzo dello strumento AWS CLI per automatizzare la gestione dei file con Amazon S3. Puoi persino provare a combinarlo con lo scripting di PowerShell e creare i tuoi strumenti o moduli riutilizzabili. Sta a te trovare queste opportunità e mostrare le tue competenze.