













Il ritardo di replica in PostgreSQL si verifica quando le modifiche apportate sul server primario impiegano del tempo a riflettersi sul server replica. Che si utilizzi la replica in streaming o la replica logica, il ritardo può influenzare le prestazioni, la coerenza e la disponibilità del sistema. Questo post copre i tipi di replica, le loro differenze, le cause del ritardo, le formule matematiche per la stima del ritardo, le tecniche di monitoraggio e le strategie per ridurre al minimo il ritardo di replica.
Tipi di Replica in PostgreSQL
Replica in Streaming
La replica in streaming invia continuamente le modifiche del Write-Ahead Log (WAL) dal server primario a uno o più server replica in tempo quasi reale. Il replica applica le modifiche in modo sequenziale man mano che vengono ricevute. Questo metodo replica l’intero database e garantisce che i replica rimangano sincronizzati.
Vantaggi
- Bassa latenza con sincronizzazione quasi in tempo reale.
- Efficiente per la replica dell’intero database.
Svantaggi
- I replica sono in sola lettura, quindi tutte le transazioni di scrittura devono passare al nodo primario.
- Se la connessione di rete si interrompe, il ritardo può aumentare significativamente.
Replica Logica
La replica logica trasferisce modifiche a livello di dati anziché dati WAL a basso livello. Consente la replica selettiva, dove vengono replicate solo tabelle specifiche o parti di un database. La replica logica utilizza un processo di decodifica logica per convertire le modifiche WAL in modifiche simili a SQL.
Vantaggi
- Consente la replica selettiva di tabelle o schemi specifici.
- Supporta repliche scrivibili con opzioni di risoluzione dei conflitti.
Svantaggi
- Latenza più elevata a causa del sovraccarico della decodifica logica.
- È meno efficiente della replica in streaming per grandi set di dati.
Come si verifica il ritardo di replica
Il ritardo di replica si verifica quando il ritmo con cui vengono generate le modifiche sul server primario supera il ritmo con cui possono essere elaborate e applicate sul server di replica. Questo squilibrio può verificarsi a causa di vari fattori sottostanti, ognuno dei quali contribuisce ai ritardi nella sincronizzazione dei dati. Le cause più comuni del ritardo di replica sono:
Latenza di rete
La latenza di rete si riferisce al tempo impiegato dai dati per viaggiare dal server primario al server di replica. I segmenti WAL (Write-Ahead Log) vengono continuamente trasmessi sulla rete durante la replica in streaming. Anche lievi ritardi nella trasmissione di rete possono accumularsi, causando il ritardo della replica.
Cause
- Tempi di andata e ritorno di rete (RTT) elevati.
- Maggiore larghezza di banda per gestire grandi volumi di dati WAL.
- Congestione di rete o perdita di pacchetti.
Se il server principale genera cambiamenti significativi durante il traffico di picco, una rete lenta o sovraccarica può causare un collo di bottiglia, impedendo alla replica di ricevere i cambiamenti WAL.
Soluzione
Utilizzare connessioni di rete a bassa latenza e ad alta larghezza di banda e abilitare la compressione WAL (wal_compression = on) per ridurre le dimensioni dei dati durante la trasmissione.
Colli di bottiglia I/O
I colli di bottiglia I/O si verificano quando il disco del server replica è troppo lento nel scrivere i cambiamenti WAL in arrivo. La replica di streaming si basa sulla scrittura dei cambiamenti su disco prima che vengano applicati, quindi qualsiasi ritardo nel sottosistema I/O può causare un accumulo di ritardo.
Cause
- Dischi rigidi (HDD) lenti o sovraccarichi.
- Capacità di scrittura su disco insufficiente.
- Conflitto del disco con altri processi.
- Se il server replica utilizza dischi rigidi rotanti (HDD) anziché unità a stato solido (SSD), i cambiamenti WAL potrebbero non essere scritti abbastanza velocemente per tenere il passo con i cambiamenti dei dati, causando il ritardo della replica rispetto al server principale.
Soluzione
Per ottimizzare l’I/O disco di una replica, utilizzare SSD per velocità di scrittura più rapide e isolare i processi di replica da altre attività intensiva disco.
Limiti di CPU/Memoria
I processi di replica richiedono CPU e memoria per decodificare, scrivere e applicare modifiche. Se un server di replica non dispone di potenza di elaborazione o memoria sufficienti, potrebbe avere difficoltà a tenere il passo con le modifiche in arrivo, causando un ritardo nella replica.
Cause
- Nuclei CPU limitati o processori lenti.
- Memoria insufficiente per i buffer WAL.
- Altri processi consumano risorse CPU o memoria.
- Se il replica sta elaborando transazioni di grandi dimensioni o eseguendo query insieme alla replica, la CPU potrebbe essere saturata, rallentando il processo di replica.
Soluzione
Allocare più nuclei CPU e memoria al server di replica. Aumentare le dimensioni dei wal_buffers per migliorare l’efficienza di elaborazione dei WAL.
Carichi di lavoro pesanti sul server primario
Il ritardo nella replica può verificarsi anche quando il server primario genera troppe modifiche troppo rapidamente per il replica da gestire. Grandi transazioni, inserimenti di massa o aggiornamenti frequenti possono sovraccaricare la replica.
Cause
- Importazioni di dati di massa o grandi transazioni.
- Aggiornamenti ad alta frequenza a tabelle di grandi dimensioni.
- Carichi di lavoro ad alta concorrenza sul primario.
- Il carico delle transazioni potrebbe essere troppo pesante se il server primario elabora contemporaneamente molteplici transazioni di grandi dimensioni, ad esempio durante un’importazione di dati di massa. Il volume dei dati WAL potrebbe superare ciò che il replica può elaborare in tempo reale, aumentando il ritardo.
Soluzione
Ottimizzare le transazioni raggruppando più aggiornamenti minori ed evitando transazioni di lunga durata. Se la sincronizzazione rigorosa non è critica, utilizzare la replica asincrona per ridurre il carico di replica.
Conflitto di Risorse
Il conflitto di risorse si verifica quando più processi competono per le stesse risorse, come CPU, memoria o I/O su disco. Ciò può verificarsi sia sul server primario che sul server replica e portare a ritardi nel processo di replica.
Cause
- Altri processi consumano I/O su disco, CPU o memoria.
- Attività di background come backup o analisi in esecuzione contemporaneamente.
- Conflitto di rete tra il traffico di replica e altri trasferimenti di dati.
- Se il server replica esegue anche backup o query analitiche, la competizione per le risorse CPU e disco potrebbe rallentare il processo di replica.
Soluzione
Isolare i carichi di lavoro di replica da altri processi intensivi delle risorse. Pianificare i backup e le analisi durante le ore di minor utilizzo per evitare interferenze con la replica.
Formula Matematica per il Ritardo di Replica
Utilizzare la seguente formula per calcolare il ritardo di replica:

Nella replica logica, il tempo aggiuntivo è consumato dalla decodifica logica:

Monitoraggio del Ritardo di Replica
Monitoraggio della Replica in Streaming
La vista pg_stat_replication può essere utilizzata per monitorare il ritardo della replica in streaming. Fornisce informazioni sullo stato e sul ritardo tra i server primario e replica.
SELECT application_name, state,
pg_size_pretty(sent_lsn - write_lsn) AS lag_bytes,
sync_state
FROM pg_stat_replication;
sent_lsn: Ultima posizione WAL inviata alla replica.write_lsn: Ultima posizione WAL scritta sulla replica.lag_bytes: La differenza tra i due indica il ritardo.
Monitoraggio della Replica Logica
Il ritardo della replica logica può essere monitorato utilizzando la vista pg_stat_subscription.
SELECT subscription_name, active,
pg_size_pretty(pg_current_wal_lsn() - replay_lsn) AS lag_bytes
FROM pg_stat_subscription;
Esempio: Visualizzazione del Ritardo di Replica
Il seguente frammento di codice Python visualizza il ritardo della replica in streaming e logica nel tempo.
import matplotlib.pyplot as plt
time = ['12:00', '12:10', '12:20', '12:30', '12:40', '12:50', '13:00']
streaming_lag = [0.5, 0.6, 0.4, 0.7, 1.0, 0.9, 0.6]
logical_lag = [2.0, 2.5, 3.0, 2.8, 3.5, 4.0, 3.2]
plt.plot(time, streaming_lag, label='Streaming Replication Lag', marker='o')
plt.plot(time, logical_lag, label='Logical Replication Lag', marker='s')
plt.xlabel('Time')
plt.ylabel('Lag (seconds)')
plt.title('Replication Lag Over Time')
plt.legend()
plt.grid(True)
# Save the plot as an image file
plt.savefig('replication_lag_plot.png')
print("Plot saved as replication_lag_plot.png")
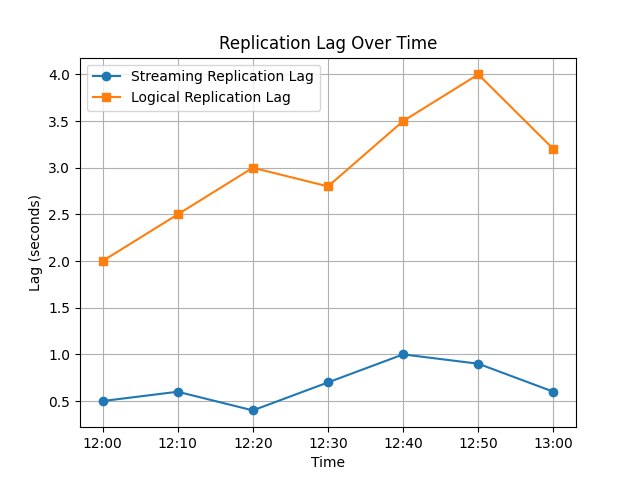
Il grafico risultante confronta le prestazioni della replica in streaming e logica. La replica logica tende ad avere un ritardo più variabile a causa dell’overhead di decodifica e di elaborazione.
Come Ridurre il Ritardo di Replica
1. Ottimizzare la Configurazione WAL
- Aumentare
wal_buffersper memorizzare più dati WAL in memoria. - Imposta
wal_writer_delaysu un valore più basso (ad esempio, 10 ms) per scrivere i dati WAL più velocemente.
wal_buffers = 64MB
wal_writer_delay = 10ms
2. Migliora le Prestazioni di Rete
- Utilizza connessioni di rete a bassa latenza e ad alta larghezza di banda tra il primario e le repliche.
- Comprimi i dati WAL durante la trasmissione per ridurre il tempo di trasferimento:
wal_compression = on.
3. Utilizza la Replicazione Asincrona (Quando Possibile)
-
La replicazione asincrona riduce il ritardo non aspettando che la replica confermi le modifiche ma introduce un rischio di perdita di dati.
ALTER SYSTEM SET synchronous_commit = 'off';
4. Abilita l’Applicazione Parallela nella Replicazione Logica
-
PostgreSQL 14+ consente l’applicazione parallela delle modifiche logiche, riducendo il ritardo per transazioni di grandi dimensioni.
ALTER SUBSCRIPTION my_subscription SET (parallel_apply = on);
5. Assegna più Risorse alle Repliche
- Assicurati che la replica abbia abbastanza CPU e memoria per elaborare rapidamente le modifiche WAL.
- Utilizza SSD per un I/O su disco più veloce sulla replica.
6. Transazioni in Batch
-
Raggruppa più aggiornamenti minori in meno transazioni per ridurre al minimo il sovraccarico.
Esempi Reali
Riduzione del Ritardo di Replica Streaming
Un’azienda che gestisce un cluster PostgreSQL ad alto traffico ha affrontato un ritardo di replica durante le ore di punta. Hanno dimezzato il ritardo di replica aumentando wal_buffers a 64MB e riducendo wal_writer_delay a 10ms. Passare a una connessione di rete ad alta velocità ha ridotto il ritardo a meno di un secondo.
Riduzione del Ritardo di Replica Logica
Un sistema con più sottoscrizioni logiche ha sperimentato un ritardo durante carichi di lavoro di scrittura elevati. Abilitare l’applicazione parallela in PostgreSQL 14 ha distribuito il carico di lavoro su numerosi lavoratori, riducendo il ritardo di replica da 4 secondi a meno di 1 secondo.
Conclusione
Il ritardo di replica è un problema critico che influisce sulle prestazioni e sulla coerenza dei sistemi PostgreSQL. La replica streaming offre bassa latenza ma richiede che l’intero database venga replicato, mentre la replica logica fornisce flessibilità ma con un sovraccarico maggiore. Un monitoraggio regolare utilizzando pg_stat_replication e pg_stat_subscription consente agli amministratori di rilevare e mitigare il ritardo.
L’ottimizzazione delle configurazioni WAL, il miglioramento delle prestazioni di rete, l’utilizzo di applicazioni parallele e l’allocazione di risorse adeguate possono ridurre significativamente il ritardo. Un’adeguata ottimizzazione garantisce che le repliche rimangano sincronizzate e che il sistema mantenga un’alta disponibilità e prestazioni.
Source:
https://dzone.com/articles/understanding-and-reducing-postgresql-replication-lag