













Chiunque lavori nel campo del DevOps oggi probabilmente concorderebbe sul fatto che codificare le risorse rende più facile osservare, gestire e automatizzare. Tuttavia, la maggior parte degli ingegneri riconoscerebbe anche che questa trasformazione comporta una nuova serie di sfide.
Forse il più grande problema delle operazioni di IaC sono le deviazioni – uno scenario in cui gli ambienti di runtime si discostano dai loro stati definiti da IaC, creando un problema che potrebbe avere gravi implicazioni a lungo termine. Queste discrepanze compromettono la coerenza degli ambienti cloud, portando a potenziali problemi di affidabilità e manutenibilità dell’infrastruttura e persino a rischi significativi per la sicurezza e la conformità.
Nel tentativo di ridurre al minimo questi rischi, coloro che sono responsabili della gestione di questi ambienti stanno classificando le deviazioni come un compito di alta priorità (e un grosso dispendio di tempo) per i team delle operazioni infrastrutturali.
Ciò ha portato all’adozione crescente di strumenti di rilevamento delle deviazioni che segnalano le discrepanze tra la configurazione desiderata e lo stato effettivo dell’infrastruttura. Sebbene efficaci nel rilevare le deviazioni, queste soluzioni sono limitate a emettere avvisi ed evidenziare differenze di codice, senza offrire approfondimenti più dettagliati sulla causa principale.
Perché il Rilevamento delle Deviazioni è Inadeguato
Lo stato attuale del rilevamento della deriva deriva dal fatto che le derive avvengono al di fuori del consolidato pipeline CI/CD e sono spesso riconducibili ad aggiustamenti manuali, aggiornamenti attivati tramite API o correzioni di emergenza. Di conseguenza, queste modifiche di solito non lasciano una traccia di audit nello strato IaC, creando un punto cieco che limita gli strumenti a segnalare solo le discrepanze di codice. Questo lascia alle squadre di ingegneria delle piattaforme il compito di speculare sull’origine della deriva e su come affrontarla nel modo migliore.
Questa mancanza di chiarezza rende risolvere la deriva un compito rischioso. Dopotutto, annullare automaticamente le modifiche senza comprendere il loro scopo — un approccio predefinito comune — potrebbe aprire una scatola di Pandora e innescare una cascata di problemi.
Un rischio è che questo potrebbe annullare aggiustamenti o ottimizzazioni legittimi, reintroducendo potenzialmente problemi che erano già stati risolti o interrompendo le operazioni di uno strumento di terze parti prezioso.
Prendiamo, ad esempio, un aggiustamento manuale applicato al di fuori del consueto processo IaC per affrontare un improvviso problema di produzione. Prima di annullare tali modifiche, è essenziale codificarle per preservarne l’intento e l’impatto o rischiare di prescrivere una cura che potrebbe rivelarsi peggiore della malattia.
Il Rilevamento Incontra il Contesto
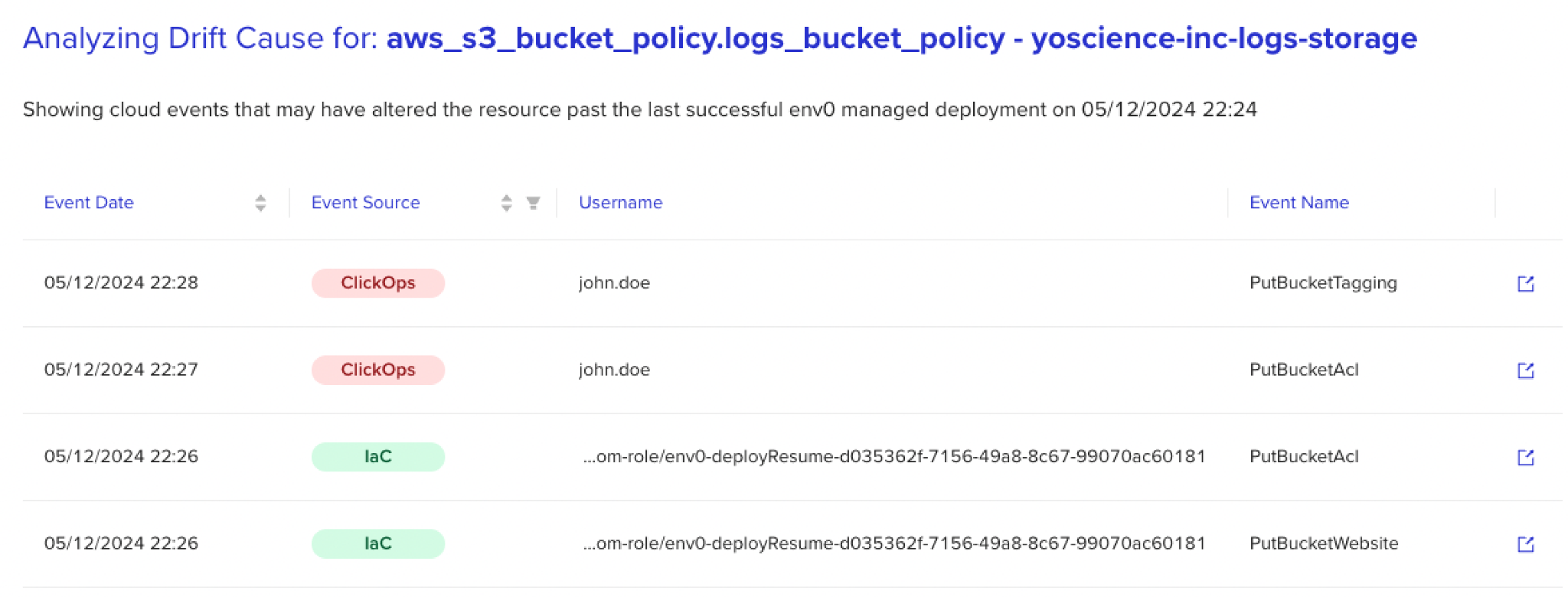
Vedere le organizzazioni alle prese con questi dilemmi ha ispirato il concetto di ‘Drift Cause‘. Questo concetto utilizza la logica assistita dall’IA per setacciare grandi registri eventi e fornire contesto aggiuntivo per ciascun cambiamento, risalendo alle origini dei cambiamenti – rivelando non solo il ‘cosa’ ma anche il ‘chi’, ‘quando’ e ‘perché’.
Questa capacità di elaborare registri non uniformi in blocco e raccogliere dati correlati ai cambiamenti ribalta il processo di riconciliazione. Per illustrare, lasciatemi riportare allo scenario che ho menzionato in precedenza e dipingere un quadro di ricevere un avviso di drift dalla soluzione di rilevamento – questa volta con contesto aggiuntivo.
Ora, con le informazioni fornite da Drift Cause, non solo puoi essere consapevole del drift ma anche fare zoom per scoprire che il cambiamento è stato effettuato da John alle 2 del mattino, proprio intorno al momento in cui l’applicazione stava gestendo un picco di traffico.
Senza queste informazioni, potresti assumere che il drift sia problematico e ripristinare il cambiamento, potenzialmente interrompendo operazioni critiche e causando guasti a valle.
Con il contesto aggiuntivo, invece, puoi collegare i puntini, contattare John, confermare che la correzione ha risolto un problema immediato e decidere che non dovrebbe essere riconciliato ciecamente. Inoltre, utilizzando questo contesto, puoi anche iniziare a pensare in anticipo e introdurre aggiustamenti alla configurazione per aggiungere scalabilità e prevenire il ripetersi del problema.
Questo è un esempio semplice, naturalmente, ma spero che possa dimostrare il beneficio di avere un contesto aggiuntivo sulle cause profonde — un elemento a lungo assente dalla rilevazione delle anomalie nonostante sia standard in altre aree di debug e risoluzione dei problemi. L’obiettivo, ovviamente, è aiutare i team a comprendere non solo cosa è cambiato, ma anche perché è cambiato, permettendo loro di intraprendere il miglior corso d’azione con fiducia.
Oltre alla gestione di IaC
Ma avere un contesto aggiuntivo per le anomalie, per quanto importante possa essere, è solo un pezzo di un puzzle molto più grande. Gestire grandi flotte cloud con risorse codificate introduce più di semplici sfide di drift, specialmente su larga scala. Gli strumenti di gestione IaC di attuale generazione sono efficaci nell’affrontare la gestione delle risorse, ma la domanda di maggiore visibilità e controllo negli ambienti a scala enterprise sta introducendo nuovi requisiti e guidando la loro inevitabile evoluzione.
Una direzione verso cui vedo muoversi questa evoluzione è la Gestione delle Risorse Cloud (CAM), che traccia e gestisce tutte le risorse in un ambiente cloud — siano esse fornite tramite IaC, API o operazioni manuali — fornendo una vista unificata degli asset e aiutando le organizzazioni a comprendere configurazioni, dipendenze e rischi, tutti elementi essenziali per la conformità, l’ottimizzazione dei costi e l’efficienza operativa.
Mentre la gestione dell’IaC si concentra sugli aspetti operativi, la gestione delle risorse cloud enfatizza la visibilità e la comprensione della postura del cloud. Agendo come un ulteriore strato di osservabilità, colma il divario tra flussi di lavoro codificati e modifiche ad-hoc, fornendo una visione complessiva dell’infrastruttura.
1+1 farà tre
La combinazione della gestione dell’IaC e della CAM consente ai team di gestire la complessità con chiarezza e controllo. Con l’avvicinarsi della fine dell’anno, è ‘stagione delle previsioni’ — quindi ecco la mia. Dopo aver trascorso la maggior parte dell’ultimo decennio a costruire e perfezionare una delle piattaforme di gestione dell’IaC più popolari (se posso dirlo io stesso), vedo questo come la naturale evoluzione della nostra industria: combinare la gestione dell’IaC, l’automazione e la governance con una visibilità migliorata sugli asset non codificati.
Credo che questa sinergia formerà la base per un migliore tipo di framework di governance del cloud — uno che sia più preciso, adattabile e a prova di futuro. Ormai, è quasi scontato che l’IaC sia la base della gestione dell’infrastruttura cloud. Tuttavia, dobbiamo anche riconoscere che non tutti gli asset saranno mai codificati. In tali casi, una soluzione di gestione dell’infrastruttura end-to-end non può limitarsi solo allo strato IaC.
La prossima frontiera, quindi, consiste nell’aiutare i team a espandere la visibilità sugli asset non codificati, assicurando che, man mano che l’infrastruttura evolve, continui a funzionare senza soluzione di continuità — un drifts riconciliato alla volta e oltre.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis