













Il servizio Amazon Simple Storage Service (S3) è un servizio di archiviazione di oggetti altamente scalabile, duraturo e sicuro offerto da Amazon Web Services (AWS). S3 consente alle aziende di memorizzare e recuperare qualsiasi quantità di dati da qualsiasi punto su Internet utilizzando i suoi servizi di livello aziendale. S3 è progettato per essere altamente interoperabile e si integra perfettamente con altri servizi Amazon Web Services (AWS) e strumenti e tecnologie di terze parti per elaborare i dati archiviati in Amazon S3. Uno di questi è Amazon EMR (Elastic MapReduce), che ti consente di elaborare grandi quantità di dati utilizzando strumenti open-source come Spark.
Apache Spark è un sistema di calcolo distribuito open-source utilizzato per elaborare grandi quantità di dati. Spark è progettato per consentire velocità e supporta vari tipi di origini dati, inclusa Amazon S3. Spark offre un modo efficiente per elaborare grandi quantità di dati e eseguire calcoli complessi in poco tempo.
Memphis.dev è un’alternativa di prossima generazione ai tradizionali message broker. Un message broker cloud-native semplice, robusto e duraturo, racchiuso in un intero ecosistema che consente lo sviluppo economico, rapido e affidabile di casi d’uso basati su code moderne.
Il modello comune dei message broker è quello di eliminare i messaggi dopo aver superato la politica di mantenimento definita, come tempo/dimensione/numero di messaggi. Memphis offre una seconda fascia di archiviazione per un mantenimento più lungo, possibilmente infinito, per i messaggi memorizzati. Ogni messaggio che esce dalla stazione migrerà automaticamente alla seconda fascia di archiviazione, che in quel caso è AWS S3.
In questo tutorial, sarai guidato attraverso il processo di configurazione di una stazione Memphis con una seconda classe di storage collegata a AWS S3. Un ambiente su AWS. Seguito dalla creazione di un bucket S3, dalla configurazione di un cluster EMR, dall’installazione e configurazione di Apache Spark sul cluster, dalla preparazione dei dati in S3 per il processamento, dal processamento dei dati con Apache Spark, dalle best practices e dalla ottimizzazione delle prestazioni.
Configurazione dell’Ambiente
Memphis
- Per iniziare, prima installa Memphis.
- Abilita l’integrazione con AWS S3 attraverso il centro di integrazione di Memphis.
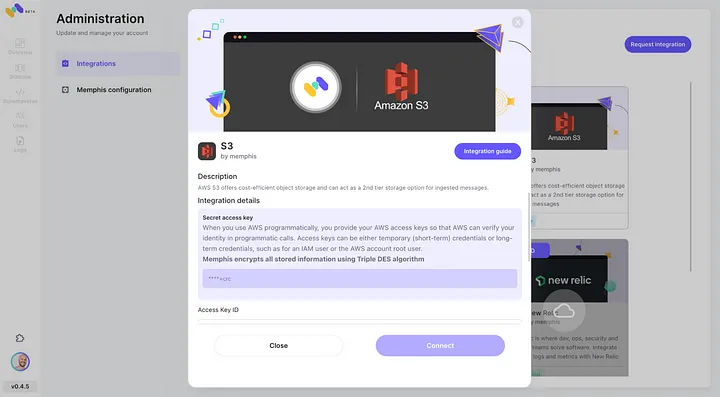
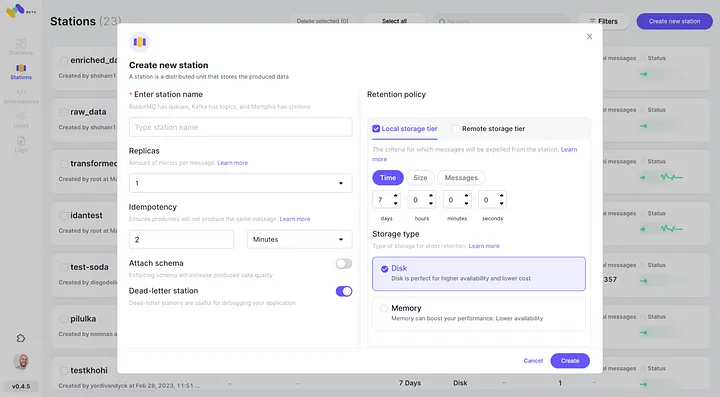
3. Crea una stazione (topic) e scegli una politica di conservazione.
4. Ogni messaggio che supera la politica di conservazione configurata verrà scaricato in un bucket S3.
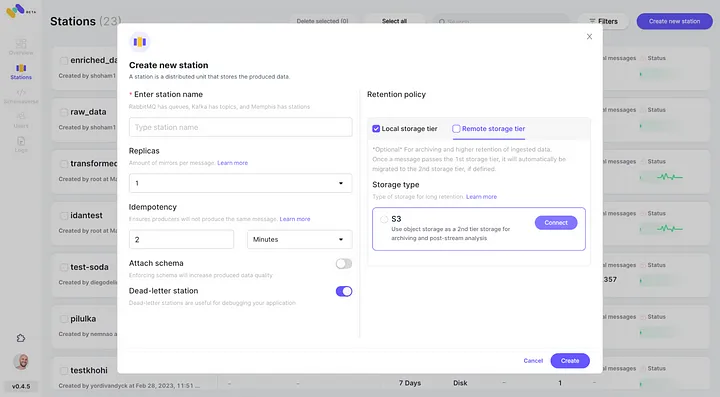
5. Verifica l’integrazione appena configurata con AWS S3 come seconda classe di storage cliccando su “Connetti”.
6. Inizia a produrre eventi per la tua nuova stazione Memphis.
Crea un Bucket AWS S3
Se non l’hai già fatto, prima devi creare un account AWS. Successivamente, crea un bucket S3 dove potrai memorizzare i tuoi dati. Puoi utilizzare il Pannello di controllo AWS, l’AWS CLI o un SDK per creare un bucket. Per questa guida, utilizzerai il console di gestione AWS.
Fai clic su “Crea bucket”.
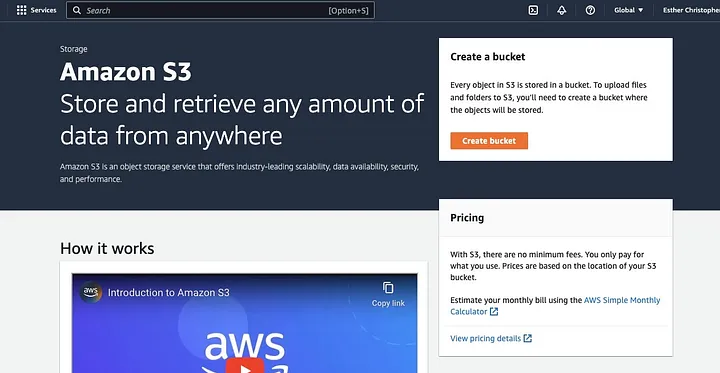
Quindi procedi a creare un nome per il bucket che rispetti la convenzione di denominazione e scegli la regione in cui desideri che il bucket sia situato. Configura “Proprietà degli oggetti” e “Blocca tutto l’accesso pubblico” secondo il tuo caso d’uso.
Assicurati di configurare altre autorizzazioni del bucket per consentire al tuo Spark application di accedere ai dati. Infine, fai clic sul pulsante “Crea bucket” per creare il bucket.
Configurazione di un Cluster EMR con Spark Installato
Amazon Elastic MapReduce (EMR) è un servizio web basato su Apache Hadoop che consente agli utenti di elaborare in modo conveniente grandi quantità di dati utilizzando tecnologie big data, inclusa Apache Spark. Per creare un cluster EMR con Spark installato, apri il console EMR e seleziona “Clusters” sotto “EMR on EC2” sul lato sinistro della pagina.
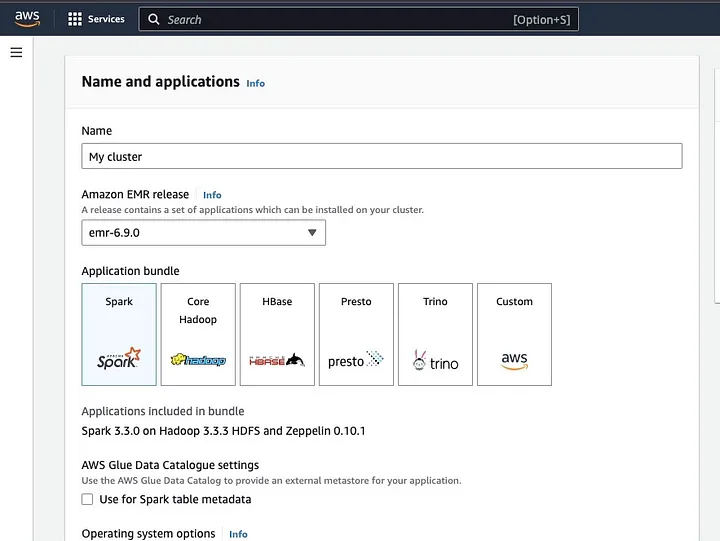
Fai clic su “Crea cluster” e assegna al cluster un nome descrittivo. Sotto “Pacchetto applicazione”, seleziona Spark per installarlo sul tuo cluster.
Scorri verso il basso fino alla sezione “Cluster logs” e seleziona la casella di controllo per Pubblica log specifici del cluster su Amazon S3.
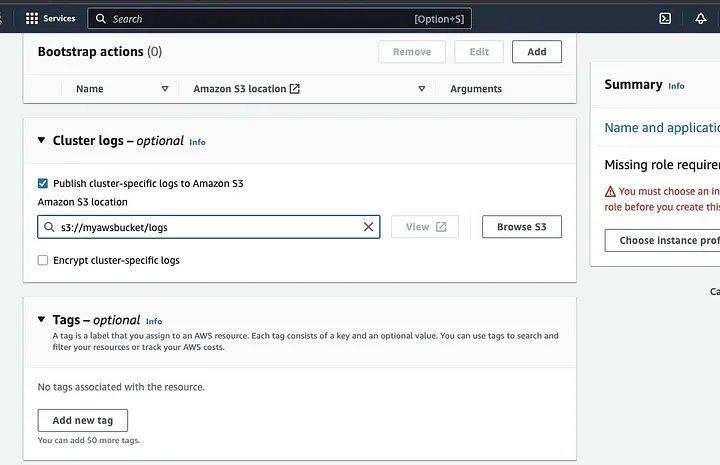
Ciò creerà un prompt per inserire l’ubicazione di Amazon S3 utilizzando il nome del bucket S3 che hai creato nel passaggio precedente, seguito da /logs, ad esempio, s3://myawsbucket/logs. /logs sono richiesti da Amazon per creare una nuova cartella nel tuo bucket dove Amazon EMR può copiare i file di log del tuo cluster.
Vai alla sezione “Configurazione della sicurezza e dei permessi” e inserisci la tua chiave EC2 o opta per la creazione di una.
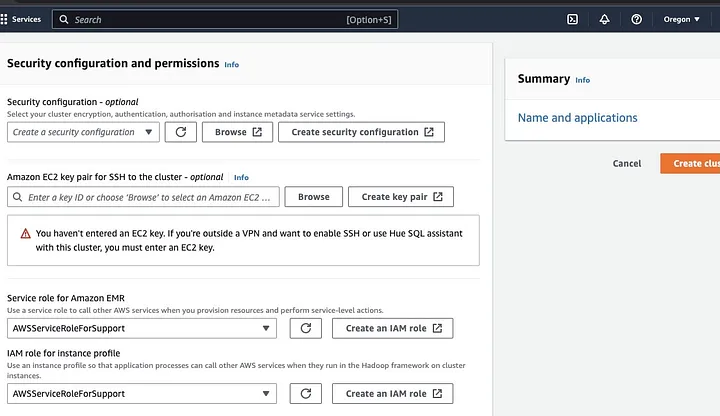
Quindi clicca sulle opzioni a discesa per “Ruolo del servizio per Amazon EMR” e scegli AWSServiceRoleForSupport. Scegli la stessa opzione a discesa per “Ruolo IAM per profilo dell’istanza”. Aggiorna l’icona se necessario per ottenere queste opzioni a discesa.
Infine, clicca sul pulsante “Crea cluster” per avviare il cluster e monitora lo stato del cluster per verificare che sia stato creato.
Installazione e configurazione di Apache Spark sul cluster EMR
Dopo aver creato con successo un cluster EMR, il passaggio successivo sarà configurare Apache Spark sul cluster EMR. I cluster EMR forniscono un ambiente gestito per eseguire applicazioni Spark sull’infrastruttura AWS, rendendo facile lanciare e gestire cluster Spark in cloud. Configura Spark per lavorare con i tuoi dati e le tue esigenze di elaborazione e poi invia job Spark al cluster per elaborare i tuoi dati.
È possibile configurare Apache Spark al cluster tramite il protocollo Secure Shell (SSH). Ma prima, è necessario autorizzare le connessioni di sicurezza SSH al cluster, che sono state impostate per impostazione predefinita al momento della creazione del cluster EMR. Una guida su come autorizzare le connessioni SSH può essere trovata qui.
Per creare una connessione SSH, è necessario specificare la coppia di chiavi EC2 selezionata al momento della creazione del cluster. Quindi connettersi al cluster EMR utilizzando lo shell Spark collegando prima il nodo primario. Per prima cosa, è necessario recuperare il DNS pubblico del master del nodo primario navigando a sinistra del console AWS, sotto EMR on EC2, scegliere Cluster e quindi selezionare il cluster del nome DNS pubblico che si desidera ottenere.
Nel terminale del tuo sistema operativo, inserisci il seguente comando.
ssh hadoop@ec2-###-##-##-###.compute-1.amazonaws.com -i ~/mykeypair.pemSostituisci ec2-###-##-##-###.compute-1.amazonaws.com con il nome del tuo DNS pubblico master e ~/mykeypair.pem con il nome e il percorso del file .pem (Segui questa guida per ottenere il file .pem file). Si verrà visualizzato un messaggio di richiesta a cui la risposta dovrebbe essere sì – digitare exit per chiudere il comando SSH.
Preparazione dei dati per il processamento con Spark e caricamento nel bucket S3
Il processamento dei dati richiede una preparazione prima di caricare i dati in un formato che Spark può elaborare facilmente. Il formato utilizzato è influenzato dal tipo di dati che si ha e dall’analisi che si intende eseguire. Alcuni formati utilizzati includono CSV, JSON e Parquet.
Crea una nuova sessione Spark e carica i tuoi dati in Spark utilizzando l’API pertinente. Ad esempio, utilizza il metodo spark.read.csv() per leggere i file CSV in un DataFrame Spark.
Amazon EMR, un servizio gestito per cluster dell’ecosistema Hadoop, può essere utilizzato per elaborare i dati. Riduce la necessità di configurare, ottimizzare e mantenere i cluster. Presenta anche altre integrazioni con Amazon SageMaker, ad esempio, per avviare un processo di allenamento del modello SageMaker da una pipeline Spark in Amazon EMR.
Una volta che i dati sono pronti, utilizzando il metodo DataFrame.write.format("s3"), puoi leggere un file CSV dal bucket Amazon S3 in un DataFrame Spark. Dovresti aver configurato le tue credenziali AWS e avere i permessi di scrittura per accedere al bucket S3.
Indica il bucket S3 e il percorso dove vuoi salvare i dati. Ad esempio, puoi utilizzare il metodo df.write.format("s3").save("s3://my-bucket/path/to/data") per salvare i dati nel bucket S3 specificato.
Una volta che i dati sono stati salvati nel bucket S3, puoi accedervi da altre applicazioni Spark o strumenti, o puoi scaricarlo per ulteriori analisi o elaborazioni. Per caricare il bucket, crea una cartella e scegli il bucket che hai creato inizialmente. Scegli il pulsante Azioni e fai clic su “Crea Cartella” nelle voci a discesa. Ora puoi nominare la nuova cartella.
Per caricare i file dei dati nel bucket, seleziona il nome della cartella dei dati.
Nella sezione Carica – Scegli “Wizard file” e scegli Aggiungi File.
Segui le indicazioni del console Amazon S3 per caricare i file e seleziona “Avvia Caricamento”.
È importante considerare e garantire le migliori pratiche per proteggere i tuoi dati prima di caricare i dati nel bucket S3.
Comprendere i Formati e gli Schemi dei Dati
I formati dei dati e gli schemi sono due concetti correlati ma completamente diversi e importanti nella gestione dei dati. Il formato dei dati si riferisce all’organizzazione e alla struttura dei dati all’interno del database. Ci sono vari formati per memorizzare dati, ovvero CSV, JSON, XML, YAML, ecc. Questi formati definiscono come i dati dovrebbero essere strutturati insieme ai diversi tipi di dati e alle applicazioni applicabili. Allo stesso tempo, gli schemi dei dati sono la struttura del database stesso. Definisce il layout del database e garantisce che i dati siano memorizzati in modo appropriato. Uno schema di database specifica le viste, le tabelle, gli indici, i tipi e altri elementi. Questi concetti sono importanti nell’analisi e nella visualizzazione del database.
Pulizia e Pre-elaborazione dei Dati in S3
È essenziale verificare attentamente eventuali errori nei tuoi dati prima di elaborarlo. Per iniziare, accedi alla cartella dei dati in cui hai salvato il file dei dati nel tuo bucket S3 e scaricalo nel tuo computer locale. Successivamente, caricherai i dati nello strumento di elaborazione dati, che verrà utilizzato per pulire e pre-elaborare i dati. Per questa guida, lo strumento di pre-elaborazione utilizzato è Amazon Athena che aiuta ad analizzare dati strutturati e non strutturati memorizzati in Amazon S3
Vai su Amazon Athena nella Console AWS.
Fai clic su “Create” per creare una nuova tabella e poi su “CREATE TABLE”.
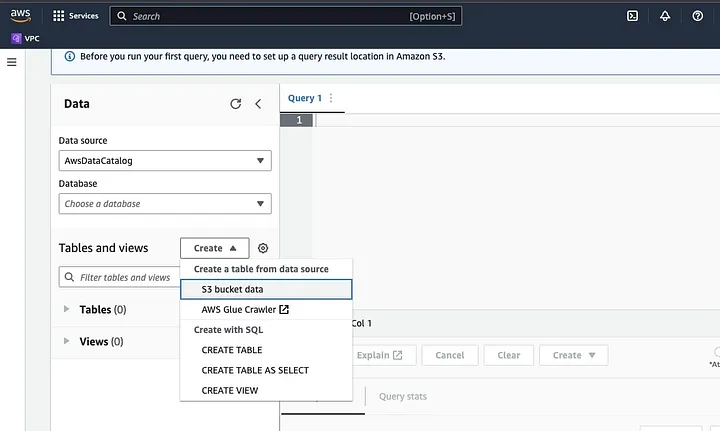
Digita il percorso del tuo file di dati nella parte evidenziata come LOCATION.
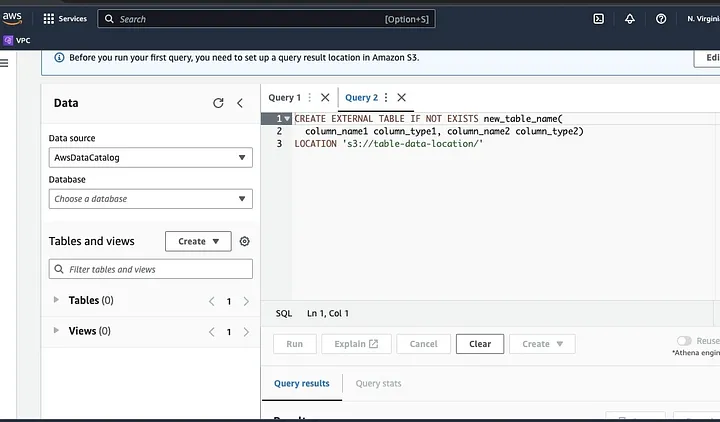
Segui le promesse per definire lo schema per i dati e salva la tabella. Ora, puoi eseguire una query per verificare che i dati siano caricati correttamente e poi pulire e pre-elaborare i dati
Un esempio:
Questa query identifica i duplicati presenti nei dati.
SELECT row1, row2, COUNT(*)
FROM table
GROUP row, row2
HAVING COUNT(*) > 1;Questo esempio crea una nuova tabella senza i duplicati:
CREATE TABLE new_table AS
SELECT DISTINCT *
FROM table;Infine, esporta i dati puliti di nuovo su S3 navigando nel bucket S3 e nella cartella per caricare il file.
Comprendere il Framework Spark
Il framework Spark è un sistema di calcolo cluster open source, semplice ed espressivo che è stato costruito per lo sviluppo rapido. Si basa sulla lingua di programmazione Java e funge da alternativa ad altri framework Java. La caratteristica principale di Spark è la sua capacità di calcolo dei dati in memoria che velocizza il processamento di grandi set di dati.
Configurare Spark per funzionare con S3
Per configurare Spark per funzionare con S3, inizia aggiungendo la dipendenza AWS Hadoop al tuo applicativo Spark. Fallo aggiungendo la seguente riga al tuo file di costruzione (ad esempio, build.sbt per Scala o pom.xml per Java):
libraryDependencies += "org.apache.hadoop" % "hadoop-aws" % "3.3.1"Inserisci la chiave di accesso AWS e la chiave di accesso segreta nel tuo applicativo Spark impostando le seguenti proprietà di configurazione:
spark.hadoop.fs.s3a.access.key <ACCESS_KEY_ID>
spark.hadoop.fs.s3a.secret.key <SECRET_ACCESS_KEY>Imposta le seguenti proprietà utilizzando l’oggetto SparkConf nel tuo codice:
val conf = new SparkConf()
.set("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.set("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")Imposta l’URL dell’endpoint S3 nel tuo applicativo Spark impostando la seguente proprietà di configurazione:
spark.hadoop.fs.s3a.endpoint s3.<REGION>.amazonaws.comSostituisci <REGION> con la regione AWS in cui si trova il tuo bucket S3 (ad esempio, us-east-1).
È necessario un nome di bucket compatibile con DNS per concedere al client S3 in Hadoop l’accesso alle richieste S3. Se il nome del tuo bucket contiene punti o underscore, potrebbe essere necessario abilitare l’accesso in stile path per il client S3 in Hadoop, che utilizza uno stile host virtuale. Imposta la seguente proprietà di configurazione per abilitare l’accesso in stile path:
spark.hadoop.fs.s3a.path.style.access trueInfine, crea una sessione Spark con la configurazione S3 impostando il prefisso spark.hadoop nella configurazione Spark:
val spark = SparkSession.builder()
.appName("MyApp")
.config("spark.hadoop.fs.s3a.access.key", "<ACCESS_KEY_ID>")
.config("spark.hadoop.fs.s3a.secret.key", "<SECRET_ACCESS_KEY>")
.config("spark.hadoop.fs.s3a.endpoint", "s3.<REGION>.amazonaws.com")
.getOrCreate()Sostituisci i campi di <ACCESS_KEY_ID>, <SECRET_ACCESS_KEY> e <REGION> con le tue credenziali AWS e la regione S3.
Per leggere i dati da S3 in Spark, verrà utilizzato il metodo spark.read e quindi specificare il percorso S3 dei tuoi dati come fonte di input.
Un esempio di codice che dimostra come leggere un file CSV da S3 in un DataFrame in Spark:
val spark = SparkSession.builder()
.appName("ReadDataFromS3")
.getOrCreate()
val df = spark.read
.option("header", "true") // Specify whether the first line is the header or not
.option("inferSchema", "true") // Infer the schema automatically
.csv("s3a://<BUCKET_NAME>/<FILE_PATH>")In questo esempio, sostituisci <BUCKET_NAME> con il nome del tuo bucket S3 e <FILE_PATH> con il percorso del tuo file CSV all’interno del bucket.
Trasformazione dei dati con Spark
La trasformazione dei dati con Spark si riferisce generalmente a operazioni sui dati per pulire, filtrare, aggregare e unire i dati. Spark mette a disposizione un ricco set di API per la trasformazione dei dati. Queste includono le API DataFrame, Dataset e RDD. Alcune delle operazioni comuni di trasformazione dei dati in Spark includono il filtraggio, la selezione di colonne, l’aggregazione dei dati, l’unione dei dati e la classificazione dei dati.
Ecco un esempio di operazioni di trasformazione dei dati:
Classificazione dei dati: Questa operazione consiste nella classificazione dei dati in base a una o più colonne. Il metodo orderBy o sort su un DataFrame o Dataset viene utilizzato per ordinare i dati in base a una o più colonne. Ad esempio:
val sortedData = df.orderBy(col("age").desc)Infine, potrebbe essere necessario scrivere il risultato su S3 per memorizzare i risultati.
Spark fornisce varie API per scrivere dati su S3, come DataFrameWriter, DatasetWriter e RDD.saveAsTextFile.
Il seguente è un esempio di codice che dimostra come scrivere un DataFrame su S3 in formato Parquet:
val outputS3Path = "s3a://<BUCKET_NAME>/<OUTPUT_DIRECTORY>"
df.write
.mode(SaveMode.Overwrite)
.option("compression", "snappy")
.parquet(outputS3Path)Sostituire il campo input del <BUCKET_NAME> con il nome del tuo bucket S3 e <OUTPUT_DIRECTORY> con il percorso della directory di output nel bucket.
Il metodo mode specifica il modo di scrittura, che può essere Overwrite, Append, Ignore o ErrorIfExists. Il metodo option può essere utilizzato per specificare varie opzioni per il formato di output, come il codec di compressione.
È inoltre possibile scrivere dati su S3 in altri formati, come CSV, JSON e Avro, modificando il formato di output e specificando le opzioni appropriate.
Comprendere la Partizionamento dei Dati in Spark
In termini semplici, il partizionamento dei dati in Spark si riferisce alla divisione del dataset in porzioni più piccole e gestibili attraverso il cluster. Lo scopo di questo è ottimizzare le prestazioni, ridurre la scalabilità e migliorare in definitiva la gestione del database. In Spark, i dati vengono elaborati in parallelo su diversi cluster. Questo è reso possibile dai Resilient Distributed Datasets (RDD), che sono una raccolta di grandi quantità di dati complessi. Per impostazione predefinita, l’RDD è partizionato tra vari nodi a causa delle loro dimensioni.
Per funzionare in modo ottimale, ci sono modi per configurare Spark per assicurarsi che i lavori vengano eseguiti rapidamente e che le risorse siano gestite in modo efficace. Alcuni di questi includono la memorizzazione nella cache, la gestione della memoria, la serializzazione dei dati e l’uso di mapPartitions() rispetto a map().
Spark UI è un’interfaccia utente grafica basata sul web che fornisce informazioni dettagliate sulle prestazioni e sull’uso delle risorse di un’applicazione Spark. Include diverse pagine, come Panoramica, Esecutori, Fasi e Task, che forniscono informazioni su vari aspetti di un lavoro Spark. Spark UI è uno strumento essenziale per il monitoraggio e il debug delle applicazioni Spark, poiché aiuta a identificare i colli di bottiglia delle prestazioni e le limitazioni delle risorse e a risolvere gli errori. Esaminando metriche come il numero di task completati, la durata del lavoro, l’uso della CPU e della memoria e i dati di shuffle scritti e letti, gli utenti possono ottimizzare i loro lavori Spark e assicurarsi che vengano eseguiti in modo efficiente.
Conclusione
In sintesi, elaborare i dati su AWS S3 utilizzando Apache Spark è un modo efficace e scalabile per analizzare enormi dataset. Utilizzando le risorse di storage e calcolo basate sul cloud di AWS S3 e Apache Spark, gli utenti possono elaborare i loro dati in modo rapido ed efficace senza doversi preoccupare della gestione dell’architettura.
In questo tutorial, abbiamo esaminato l’impostazione di un bucket S3 e di un cluster Apache Spark su AWS EMR, la configurazione di Spark per lavorare con AWS S3 e la scrittura e l’esecuzione di applicazioni Spark per elaborare i dati. Abbiamo anche trattato la partizionamento dei dati in Spark, l’interfaccia utente di Spark e l’ottimizzazione delle prestazioni in Spark.
Riferimento
Per ulteriori approfondimenti sulla configurazione di Spark per prestazioni ottimali, guarda qui.
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-connect-master-node-ssh.html
Source:
https://dzone.com/articles/stateful-stream-processing-with-memphis-and-apache-spark