













Introduzione
Il modello di dati relazionale, che organizza i dati in tabelle di righe e colonne, predomina negli strumenti di gestione dei database. Oggi ci sono altri modelli di dati, tra cui NoSQL e NewSQL, ma i sistemi di gestione di database relazionali (RDBMS) restano dominanti per la memorizzazione e la gestione dei dati in tutto il mondo.
Questo articolo confronta e mette a confronto tre dei RDBMS open source più ampiamente implementati: SQLite, MySQL e PostgreSQL. In particolare, esplorerà i tipi di dati che ciascun RDBMS utilizza, i loro vantaggi e svantaggi e le situazioni in cui sono ottimizzati al meglio.
A Bit About Database Management Systems
I database sono cluster logicamente modellati di informazioni, o dati. Un sistema di gestione di database (DBMS), d’altra parte, è un programma informatico che interagisce con un database. Un DBMS ti consente di controllare l’accesso a un database, scrivere dati, eseguire query e svolgere qualsiasi altra attività relativa alla gestione del database.
Anche se i sistemi di gestione di database sono spesso indicati come “database”, i due termini non sono intercambiabili. Un database può essere qualsiasi raccolta di dati, non solo uno memorizzato su un computer. Al contrario, un DBMS si riferisce specificamente al software che ti consente di interagire con un database.
Tutti i sistemi di gestione di database hanno un modello sottostante che struttura come i dati sono memorizzati e accessibili. Un sistema di gestione di database relazionale è un DBMS che impiega il modello di dati relazionale. In questo modello relazionale, i dati sono organizzati in tabelle. Le tabelle, nel contesto dei RDBMS, sono più formalmente indicate come relazioni. Una relazione è un insieme di tuple, che sono le righe in una tabella, e ogni tupla condivide un insieme di attributi, che sono le colonne in una tabella:
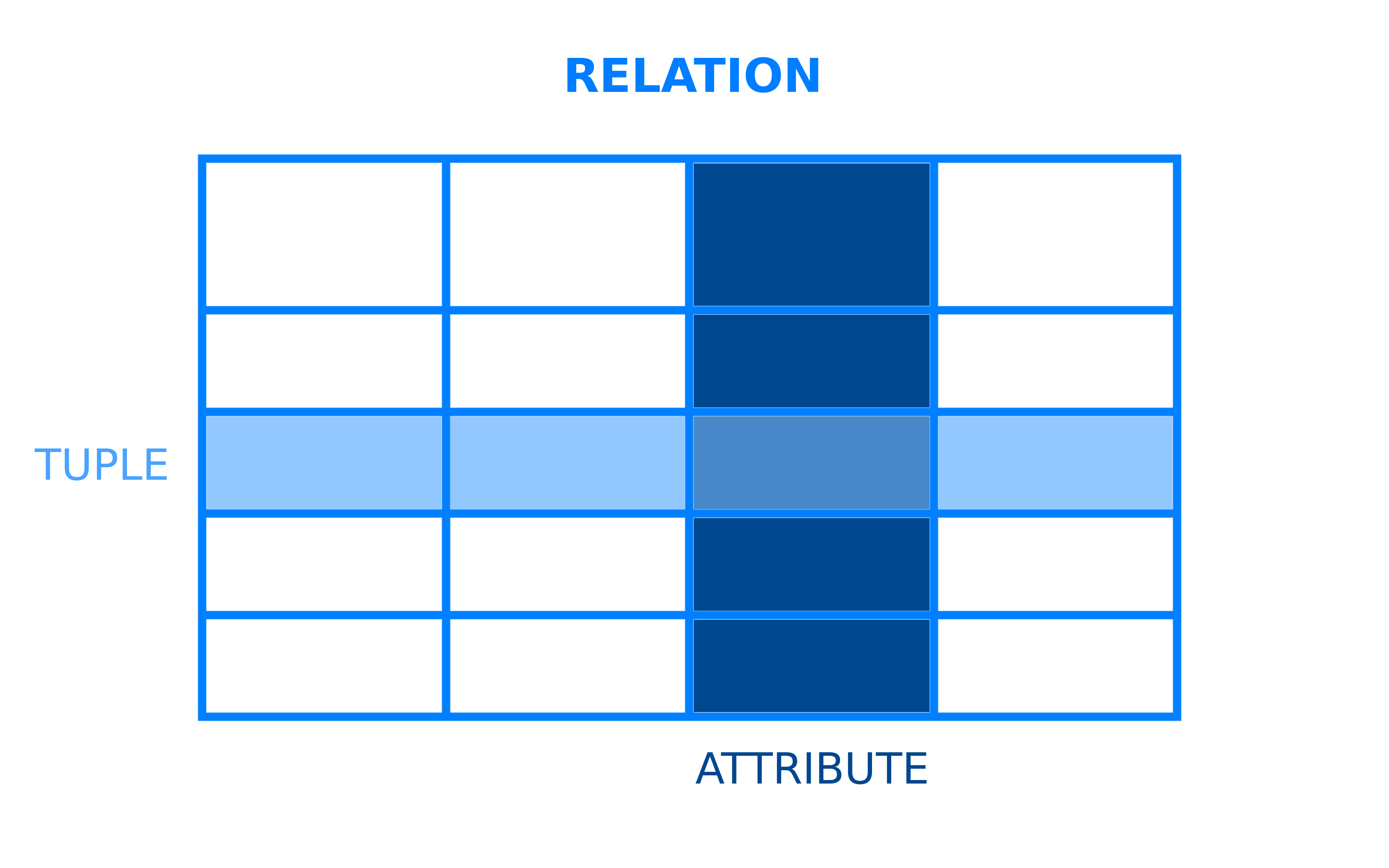
La maggior parte dei database relazionali utilizza il linguaggio di query strutturato (SQL) per gestire e interrogare i dati. Tuttavia, molti RDBMS utilizzano il proprio dialetto particolare di SQL, che può avere determinate limitazioni o estensioni. Queste estensioni includono tipicamente funzionalità aggiuntive che consentono agli utenti di eseguire operazioni più complesse rispetto a quanto potrebbero fare con SQL standard.
Nota: Il termine “SQL standard” compare diverse volte in questa guida. Gli standard SQL sono mantenuti congiuntamente dall’American National Standards Institute (ANSI), dall’Organizzazione internazionale per la standardizzazione (ISO) e dalla Commissione elettrotecnica internazionale (IEC). Ogni volta che questo articolo menziona “SQL standard” o “lo standard SQL”, si riferisce alla versione attuale dello standard SQL pubblicato da questi enti.
È importante notare che lo standard SQL completo è grande e complesso: la conformità completa al core SQL:2011 richiede 179 funzionalità. A causa di ciò, la maggior parte dei RDBMS non supporta l’intero standard, anche se alcuni si avvicinano di più alla piena conformità rispetto ad altri.
Tipi di dati e vincoli
Ad ogni colonna viene assegnato un tipo di dato che determina quale tipo di voci sono ammesse in quella colonna. I diversi RDBMS implementano tipi di dati diversi, che non sono sempre direttamente interscambiabili. Alcuni tipi di dati comuni includono date, stringhe, interi e booleani.
Memorizzare interi in un database è più sfumato che inserire numeri in una tabella. I tipi di dati numerici possono essere firmati, il che significa che possono rappresentare sia numeri positivi che negativi, o non firmati, il che significa che possono rappresentare solo numeri positivi. Ad esempio, il tipo di dato tinyint di MySQL può contenere 8 bit di dati, che corrispondono a 256 valori possibili. Il range firmato di questo tipo di dati va da -128 a 127, mentre il range non firmato va da 0 a 255.
È importante poter controllare quali dati sono ammessi in un database. A volte, un amministratore di database imporrà un vincolo su una tabella per limitare i valori che possono essere inseriti in essa. Un vincolo si applica tipicamente a una particolare colonna, ma alcuni vincoli possono anche essere applicati a un’intera tabella. Ecco alcuni vincoli comunemente utilizzati in SQL:
UNIQUE: Applicando questo vincolo a una colonna si assicura che nessuna due voci in quella colonna siano identiche.NOT NULL: Questo vincolo garantisce che una colonna non abbia vociNULL.PRIMARY KEY: Una combinazione diUNIQUEeNOT NULL, il vincoloPRIMARY KEYassicura che nessuna voce nella colonna siaNULLe che ogni voce sia distinta.FOREIGN KEY: UnaFOREIGN KEYè una colonna in una tabella che si riferisce allaPRIMARY KEYdi un’altra tabella. Questo vincolo viene utilizzato per collegare due tabelle. Le voci nella colonnaFOREIGN KEYdevono già esistere nella colonnaPRIMARY KEYgenitore affinché il processo di scrittura abbia successo.CHECK: Questo vincolo limita l’intervallo di valori che possono essere inseriti in una colonna. Ad esempio, se la tua applicazione è destinata solo ai residenti dell’Alaska, potresti aggiungere un vincoloCHECKsu una colonna del codice postale per consentire solo voci tra 99501 e 99950.
Se desideri saperne di più sui sistemi di gestione di database, consulta il nostro articolo su Un Confronto tra Sistemi e Modelli di Gestione di Database NoSQL.
Ora che abbiamo affrontato generalmente i sistemi di gestione di database relazionali, passiamo al primo dei tre database relazionali open source che questo articolo tratterà: SQLite.
SQLite
SQLite è un DBMS autocontenuto, basato su file e completamente open source noto per la sua portabilità, affidabilità e forte performance anche in ambienti a bassa memoria. Le sue transazioni sono conformi a ACID, anche nei casi in cui il sistema si blocca o subisce un’interruzione di corrente.
Il sito web del progetto SQLite lo descrive come un database “senza server”. La maggior parte dei motori di database relazionali è implementata come un processo server in cui i programmi comunicano con il server host attraverso una comunicazione tra processi che inoltra le richieste. Al contrario, SQLite consente a qualsiasi processo che accede al database di leggere e scrivere direttamente sul file disco del database. Questo semplifica il processo di configurazione di SQLite, poiché elimina la necessità di configurare un processo server. Allo stesso modo, non è necessaria alcuna configurazione per i programmi che utilizzeranno il database SQLite: tutto ciò di cui hanno bisogno è l’accesso al disco.
SQLite è un software libero e open source e non è richiesta alcuna licenza speciale per utilizzarlo. Tuttavia, il progetto offre diverse estensioni, ciascuna a pagamento una tantum, che aiutano con la compressione e la crittografia. Inoltre, il progetto offre vari pacchetti di supporto commerciale, ciascuno a pagamento annuale.
Tipi di dati supportati da SQLite
SQLite permette una varietà di tipi di dati, organizzati nelle seguenti classi di archiviazione:
| Data Type | Explanation |
|---|---|
null |
Includes any NULL values. |
integer |
Signed integers, stored in 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value. |
real |
Real numbers, or floating point values, stored as 8-byte floating point numbers. |
text |
Text strings stored using the database encoding, which can either be UTF-8, UTF-16BE or UTF-16LE. |
blob |
Any blob of data, with every blob stored exactly as it was input. |
Nel contesto di SQLite, i termini “classe di archiviazione” e “tipo di dati” sono considerati interscambiabili. Se desideri saperne di più sui tipi di dati di SQLite e sull’affinità dei tipi di SQLite, consulta la documentazione ufficiale di SQLite sull’argomento.
Vantaggi di SQLite
- Piccola dimensione: Come suggerisce il suo nome, la libreria SQLite è molto leggera. Anche se lo spazio che utilizza varia a seconda del sistema in cui è installata, può occupare meno di 600KiB di spazio. Inoltre, è completamente autosufficiente, il che significa che non ci sono dipendenze esterne che devi installare sul tuo sistema affinché SQLite funzioni.
- Facile da usare: SQLite è talvolta descritto come un database “senza configurazione” pronto all’uso appena estratto dalla confezione. SQLite non viene eseguito come processo server, il che significa che non ha mai bisogno di essere avviato, fermato o riavviato e non viene fornito con file di configurazione da gestire. Queste caratteristiche contribuiscono a semplificare il percorso dall’installazione di SQLite all’integrazione con un’applicazione.
- Portatile: A differenza di altri sistemi di gestione di database, che tipicamente memorizzano i dati come un ampio insieme di file separati, un intero database SQLite è memorizzato in un singolo file. Questo file può trovarsi ovunque in una gerarchia di directory e può essere condiviso tramite supporti rimovibili o protocollo di trasferimento file.
Svantaggi di SQLite
- Concorrenza limitata: Anche se più processi possono accedere e interrogare un database SQLite contemporaneamente, solo un processo può apportare modifiche al database in un determinato momento. Ciò significa che, sebbene SQLite supporti una maggiore concorrenza rispetto alla maggior parte degli altri sistemi di gestione di database incorporati, non può supportare quanto i RDBMS client/server come MySQL o PostgreSQL.
- Nessuna gestione utenti: I sistemi di database spesso forniscono supporto per gli utenti, o connessioni gestite con privilegi di accesso predefiniti al database e alle tabelle. Poiché SQLite legge e scrive direttamente su un file di disco ordinario, le uniche autorizzazioni di accesso applicabili sono le tipiche autorizzazioni di accesso del sistema operativo sottostante. Ciò rende SQLite una scelta poco adatta per le applicazioni che richiedono più utenti con privilegi di accesso speciali.
- Sicurezza: Un motore di database che utilizza un server può, in alcuni casi, fornire una migliore protezione da bug nell’applicazione client rispetto a un database senza server come SQLite. Ad esempio, i puntatori erranti in un client non possono corrompere la memoria sul server. Inoltre, poiché un server è un singolo processo persistente, un database client-server può controllare l’accesso ai dati con maggiore precisione rispetto a un database senza server. Ciò consente un bloccaggio più dettagliato e una migliore concorrenza.
Quando usare SQLite
- Applicazioni incorporate: SQLite è una grande scelta di database per le applicazioni che necessitano di portabilità e non richiedono espansione futura. Esempi includono applicazioni locali per singolo utente, applicazioni mobili o giochi.
- Sostituzione dell’accesso al disco: Nei casi in cui un’applicazione deve leggere e scrivere file su disco direttamente, può essere vantaggioso utilizzare SQLite per la funzionalità aggiuntiva e la semplicità che deriva dall’uso di SQL.
- Test: Per molte applicazioni può essere eccessivo testare la loro funzionalità con un DBMS che utilizza un processo server aggiuntivo. SQLite ha una modalità in memoria che può essere utilizzata per eseguire test rapidamente senza il sovraccarico delle operazioni effettive sul database, rendendolo una scelta ideale per i test.
Quando non usare SQLite
- Lavorare con molte dati: SQLite può tecnicamente supportare un database fino a 140TB di dimensione, purché anche il disco rigido e il sistema di file supportino i requisiti di dimensione del database. Tuttavia, il sito web di SQLite raccomanda che qualsiasi database che si avvicini a 1TB sia ospitato su un database client-server centralizzato, poiché un database SQLite di quella dimensione o più grande sarebbe difficile da gestire.
- Volumi di scrittura elevati: SQLite consente solo un’operazione di scrittura per essere eseguita in un dato momento, il che limita significativamente il suo throughput. Se la tua applicazione richiede molte operazioni di scrittura o scritture concorrenti multiple, SQLite potrebbe non essere adeguato alle tue esigenze.
- È richiesto l’accesso alla rete: Poiché SQLite è un database senza server, non fornisce un accesso diretto alla rete ai suoi dati. Questo accesso è incorporato nell’applicazione. Se i dati in SQLite si trovano su una macchina separata dall’applicazione, sarà necessario un collegamento motore-disco ad alta larghezza di banda attraverso la rete. Si tratta di una soluzione costosa e inefficiente e, in tali casi, un DBMS client-server potrebbe essere una scelta migliore.
MySQL
Secondo il DB-Engines Ranking, MySQL è stato il RDBMS open-source più popolare dal momento in cui il sito ha iniziato a tracciare la popolarità dei database nel 2012. È un prodotto ricco di funzionalità che alimenta molti dei più grandi siti web e delle applicazioni al mondo, tra cui Twitter, Facebook, Netflix e Spotify. Iniziare con MySQL è relativamente semplice, grazie in gran parte alla sua documentazione esaustiva e alla grande comunità di sviluppatori, così come all’abbondanza di risorse online relative a MySQL.
MySQL è stato progettato per la velocità e l’affidabilità, a discapito della piena adesione allo standard SQL. Gli sviluppatori di MySQL lavorano continuamente per avvicinarsi maggiormente allo standard SQL, ma è ancora indietro rispetto ad altre implementazioni SQL. Tuttavia, viene fornito con vari modi e estensioni SQL che lo avvicinano alla conformità.
A differenza delle applicazioni che utilizzano SQLite, le applicazioni che utilizzano un database MySQL vi accedono attraverso un processo demone separato. Poiché il processo server si interpone tra il database e altre applicazioni, consente un maggiore controllo su chi ha accesso al database.
MySQL ha ispirato una ricchezza di applicazioni di terze parti, strumenti e librerie integrate che estendono la sua funzionalità e aiutano a renderlo più facile da utilizzare. Alcuni dei più ampiamente utilizzati di questi strumenti di terze parti sono phpMyAdmin, DBeaver e HeidiSQL.
Tipi di dati supportati da MySQL
I tipi di dati di MySQL possono essere organizzati in tre categorie principali: tipi numerici, tipi di data e ora e tipi di stringa.
Tipi numerici:
| Data Type | Explanation |
|---|---|
tinyint |
A very small integer. The signed range for this numeric data type is -128 to 127, while the unsigned range is 0 to 255. |
smallint |
A small integer. The signed range for this numeric type is -32768 to 32767, while the unsigned range is 0 to 65535. |
mediumint |
A medium-sized integer. The signed range for this numeric data type is -8388608 to 8388607, while the unsigned range is 0 to 16777215. |
int or integer |
A normal-sized integer. The signed range for this numeric data type is -2147483648 to 2147483647, while the unsigned range is 0 to 4294967295. |
bigint |
A large integer. The signed range for this numeric data type is -9223372036854775808 to 9223372036854775807, while the unsigned range is 0 to 18446744073709551615. |
float |
A small (single-precision) floating-point number. |
double, double precision, or real |
A normal sized (double-precision) floating-point number. |
dec, decimal, fixed, or numeric |
A packed fixed-point number. The display length of entries for this data type is defined when the column is created, and every entry adheres to that length. |
bool or boolean |
A Boolean is a data type that only has two possible values, usually either true or false. |
bit |
A bit value type for which you can specify the number of bits per value, from 1 to 64. |
Tipi di data e ora:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
Tipi di stringa:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; entries of this type are padded on the right with spaces to meet the specified length when stored. |
varchar |
A string of variable length. |
binary |
Similar to the char type, but a binary byte string of a specified length rather than a nonbinary character string. |
varbinary |
Similar to the varchar type, but a binary byte string of a variable length rather than a nonbinary character string. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
An enumeration, which is a string object that takes a single value from a list of values that are declared when the table is created. |
set |
Similar to an enumeration, a string object that can have zero or more values, each of which must be chosen from a list of allowed values that are specified when the table is created. |
Vantaggi di MySQL
- Popolarità e facilità d’uso: Come uno dei sistemi di database più popolari al mondo, non mancano gli amministratori di database che hanno esperienza nel lavorare con MySQL. Allo stesso modo, esiste un’abbondanza di documentazione stampata e online su come installare e gestire un database MySQL. Questo include diversi strumenti di terze parti – come phpMyAdmin – che mirano a semplificare il processo di avvio con il database.
- Sicurezza: MySQL viene installato con uno script che ti aiuta a migliorare la sicurezza del tuo database impostando il livello di sicurezza della password dell’installazione, definendo una password per l’utente root, rimuovendo account anonimi e rimuovendo database di test che sono, per impostazione predefinita, accessibili a tutti gli utenti. Inoltre, a differenza di SQLite, MySQL supporta la gestione degli utenti e ti consente di concedere privilegi di accesso caso per caso.
- Velocità: Scegliendo di non implementare determinate funzionalità di SQL, gli sviluppatori di MySQL sono stati in grado di dare priorità alla velocità. Anche se i test di benchmark più recenti mostrano che altri RDBMS come PostgreSQL possono eguagliare o almeno avvicinarsi a MySQL in termini di velocità, MySQL conserva comunque la reputazione di essere una soluzione di database estremamente veloce.
- Replicazione: MySQL supporta diversi tipi di replicazione, che è la pratica di condividere informazioni tra due o più host per migliorare la affidabilità, la disponibilità e la tolleranza ai guasti. Questo è utile per configurare una soluzione di backup del database o per scalare in modo orizzontale il proprio database.
Svantaggi di MySQL
- Limitazioni conosciute: Poiché MySQL è stato progettato per la velocità e la facilità d’uso piuttosto che per la piena conformità SQL, presenta alcune limitazioni funzionali. Ad esempio, manca il supporto per le clausole
FULL JOIN. - Licenze e funzionalità proprietarie: MySQL è un software con doppia licenza, con una edizione comunitaria gratuita e open-source con licenza GPLv2 e diverse edizioni commerciali a pagamento rilasciate sotto licenze proprietarie. A causa di ciò, alcune funzionalità e plugin sono disponibili solo per le edizioni proprietarie.
- Sviluppo rallentato: Dall’acquisizione del progetto MySQL da parte di Sun Microsystems nel 2008, e successivamente da parte di Oracle Corporation nel 2009, ci sono state lamentele da parte degli utenti secondo cui il processo di sviluppo per il DBMS si è significativamente rallentato, poiché la comunità non ha più la possibilità di reagire rapidamente ai problemi e implementare cambiamenti.
Quando utilizzare MySQL
- Operazioni distribuite: Il supporto alla replicazione di MySQL lo rende una scelta eccellente per configurazioni di database distribuiti come architetture primario-secondario o primario-primario.
- Siti web e applicazioni web: MySQL alimenta molti siti web e applicazioni in tutto Internet. Questo è in gran parte dovuto alla facilità con cui è possibile installare e configurare un database MySQL, così come alla sua velocità complessiva e scalabilità nel lungo periodo.
- Crescita futura prevista: Il supporto alla replicazione di MySQL può facilitare lo scaling orizzontale. Inoltre, è un processo relativamente semplice passare a un prodotto commerciale MySQL, come MySQL Cluster, che supporta la frammentazione automatica, un altro processo di scaling orizzontale.
Quando non utilizzare MySQL
- Conformità SQL è necessaria: Dato che MySQL non cerca di implementare completamente lo standard SQL, questo strumento non è completamente conforme a SQL. Se la conformità completa o anche quasi completa a SQL è fondamentale per il tuo caso d’uso, potresti voler utilizzare un DBMS più pienamente conforme.
- Concorrenza e grandi volumi di dati: Anche se MySQL generalmente si comporta bene con operazioni di lettura pesanti, le letture-scritture concorrenti possono essere problematiche. Se la tua applicazione avrà molti utenti che scrivono dati contemporaneamente, un altro RDBMS come PostgreSQL potrebbe essere una scelta migliore per il database.
PostgreSQL
PostgreSQL, anche conosciuto come Postgres, si presenta come “il database relazionale open-source più avanzato al mondo”. È stato creato con l’obiettivo di essere altamente estensibile e conforme agli standard. PostgreSQL è un database relazionale ad oggetti, il che significa che, sebbene sia principalmente un database relazionale, include anche funzionalità – come l’ereditarietà delle tabelle e il sovraccarico delle funzioni – che sono più spesso associate ai database ad oggetti.
Postgres è in grado di gestire efficientemente più compiti contemporaneamente, una caratteristica nota come concorrenza. Ciò avviene senza blocchi di lettura grazie alla sua implementazione del Controllo di Concorrenza Multiversione (MVCC), che garantisce l’atomicità, la coerenza, l’isolamento e la durabilità delle sue transazioni, conosciute anche come conformità ACID.
PostgreSQL non è utilizzato tanto quanto MySQL, ma esistono comunque numerosi strumenti e librerie di terze parti progettati per semplificare il lavoro con PostgreSQL, inclusi pgAdmin e Postbird.
Tipi di Dati Supportati da PostgreSQL
PostgreSQL supporta tipi di dati numerici, stringhe, e data e ora come MySQL. In aggiunta, supporta tipi di dati per forme geometriche, indirizzi di rete, stringhe di bit, ricerche di testo e voci JSON, così come diversi tipi di dati idiosincratici.
Tipi Numerici:
| Data Type | Explanation |
|---|---|
bigint |
A signed 8 byte integer. |
bigserial |
An auto-incrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
A number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An auto-incrementing 2 byte integer. |
serial |
An auto-incrementing 4 byte integer. |
Tipi di Caratteri:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Tipi di Data e Ora:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Tipi Geometrici:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Tipi di Indirizzo di Rete:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Tipi di Stringhe di Bit:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Tipi di Ricerca Testuale:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
Tipi JSON:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Altri tipi di dati:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Vantaggi di PostgreSQL
- Conformità SQL: Più di SQLite o MySQL, PostgreSQL mira a conformarsi strettamente agli standard SQL. Secondo la documentazione ufficiale di PostgreSQL, PostgreSQL supporta 160 delle 179 funzionalità richieste per una piena conformità SQL:2011, oltre a una lunga lista di funzionalità opzionali.
- Open source e basato sulla community: Un progetto completamente open source, il codice sorgente di PostgreSQL è sviluppato da una grande e devota comunità. Allo stesso modo, la comunità di Postgres mantiene e contribuisce a numerosi risorse online che descrivono come lavorare con il DBMS, tra cui la documentazione ufficiale, il wiki di PostgreSQL, e vari forum online.
- Estendibile: Gli utenti possono estendere PostgreSQL in modo programmabile e al volo attraverso la sua operazione basata su cataloghi e il suo utilizzo del caricamento dinamico. È possibile designare un file di codice oggetto, come una libreria condivisa, e PostgreSQL lo caricherà secondo necessità.
Svantaggi di PostgreSQL
- Performance della memoria: Per ogni nuova connessione client, PostgreSQL fa fork di un nuovo processo. Ogni nuovo processo viene allocato circa 10MB di memoria, che può accumularsi rapidamente per database con molte connessioni. Di conseguenza, per operazioni semplici ad alta lettura, PostgreSQL è tipicamente meno performante rispetto ad altri RDBMS, come MySQL.
- Popolarità: Anche se più ampiamente usato negli ultimi anni, PostgreSQL ha storicamente risentito del ritardo rispetto a MySQL in termini di popolarità. Una conseguenza di ciò è che ci sono ancora meno strumenti di terze parti che possono aiutare a gestire un database PostgreSQL. Allo stesso modo, non ci sono tanti amministratori di database con esperienza nella gestione di un database Postgres rispetto a quelli con esperienza MySQL.
Quando usare PostgreSQL
- L’integrità dei dati è importante: PostgreSQL è completamente conforme a ACID dal 2001 e implementa il controllo della concorrenza multiversione per garantire che i dati rimangano consistenti, rendendolo una scelta solida di RDBMS quando l’integrità dei dati è critica.
- Integrazione con altri strumenti: PostgreSQL è compatibile con una vasta gamma di linguaggi di programmazione e piattaforme. Ciò significa che se mai avessi bisogno di migrare il tuo database su un altro sistema operativo o integrarlo con uno strumento specifico, sarà probabilmente più semplice con un database PostgreSQL rispetto a un altro DBMS.
- Operazioni complesse: Postgres supporta piani di query che possono sfruttare più CPU per rispondere alle query con maggiore velocità. Ciò, unito al suo forte supporto per più scrittori concorrenti, lo rende una scelta eccellente per operazioni complesse come il data warehousing e l’elaborazione di transazioni online.
Quando non usare PostgreSQL
- La velocità è imperativa: A discapito della velocità, PostgreSQL è stato progettato con l’espandibilità e la compatibilità in mente. Se il tuo progetto richiede le operazioni di lettura più veloci possibili, PostgreSQL potrebbe non essere la scelta migliore tra i DBMS.
- Impostazioni semplici: A causa della sua vasta gamma di funzionalità e del suo forte rispetto degli standard SQL, Postgres può essere eccessivo per configurazioni di database semplici. Per operazioni con un carico elevato di lettura in cui è richiesta la velocità, MySQL è tipicamente una scelta più pratica.
- Replicazione complessa: Anche se PostgreSQL offre un forte supporto alla replicazione, è comunque una funzionalità relativamente nuova. Alcune configurazioni — come un’architettura primaria-primaria — sono possibili solo con estensioni. La replicazione è una funzionalità più matura su MySQL e molti utenti ritengono la replicazione di MySQL più facile da implementare, specialmente per coloro che non hanno esperienza sufficiente in amministrazione di database e sistemi.
Conclusione
Oggi, SQLite, MySQL e PostgreSQL sono i tre sistemi di gestione di database relazionali open-source più popolari al mondo. Ognuno ha le proprie caratteristiche e limitazioni uniche e eccelle in scenari particolari. Ci sono molte variabili da considerare nella scelta di un RDBMS, e la scelta raramente è semplice come scegliere il più veloce o quello con più funzionalità. La prossima volta che hai bisogno di una soluzione di database relazionale, assicurati di fare una ricerca approfondita su questi e altri strumenti per trovare quello che meglio si adatta alle tue esigenze.
Se desideri saperne di più su SQL e su come utilizzarlo per gestire un database relazionale, ti invitiamo a consultare il nostro How To Manage an SQL Database foglio di riferimento. D’altra parte, se desideri apprendere sui database non relazionali (o NoSQL), dai un’occhiata al nostro Comparison Of NoSQL Database Management Systems.