













Hibernate
Hibernate da solo non offre supporto per la ricerca full-text. Deve fare affidamento sul supporto del motore di database o su soluzioni di terze parti.
Un’estensione chiamata Hibernate Search si integra con Apache Lucene o Elasticsearch (c’è anche integrazione con OpenSearch).
Postgres
Postgres ha avuto funzionalità full-text search a partire dalla versione 7.3. Anche se non può competere con motori di ricerca come Elasticsearch o Lucene, offre comunque una soluzione flessibile e robusta che potrebbe essere sufficiente per soddisfare le aspettative degli utenti dell’applicazione—caratteristiche come stemming, ranking e indicizzazione.
Esamineremo brevemente come possiamo effettuare una ricerca full-text in Postgres. Per ulteriori informazioni, si prega di consultare la documentazione di Postgres. Per quanto riguarda il matching di testo essenziale, la parte più cruciale è l’operatore matematico @@.
Restituisce true se il documento (oggetto di tipo tsvector) corrisponde alla query (oggetto di tipo tsquery).
L’ordine non è cruciale per l’operatore. Quindi, non importa se mettiamo il documento sul lato sinistro dell’operatore e la query sul lato destro o in un ordine diverso.
Per una migliore dimostrazione, utilizziamo una tabella di database chiamata tweet.
create table tweet (
id bigint not null,
short_content varchar(255),
title varchar(255),
primary key (id)
)Con dati di questo tipo:
INSERT INTO tweet (id, title, short_content) VALUES (1, 'Cats', 'Cats rules the world');
INSERT INTO tweet (id, title, short_content) VALUES (2, 'Rats', 'Rats rules in the sewers');
INSERT INTO tweet (id, title, short_content) VALUES (3, 'Rats vs Cats', 'Rats and Cats hates each other');
INSERT INTO tweet (id, title, short_content) VALUES (4, 'Feature', 'This project is design to wrap already existed functions of Postgres');
INSERT INTO tweet (id, title, short_content) VALUES (5, 'Postgres database', 'Postgres is one of the widly used database on the market');
INSERT INTO tweet (id, title, short_content) VALUES (6, 'Database', 'On the market there is a lot of database that have similar features like Oracle');Ora vediamo come appare l’oggetto tsvector per la colonna short_content di ogni record.
SELECT id, to_tsvector('english', short_content) FROM tweet;Output:
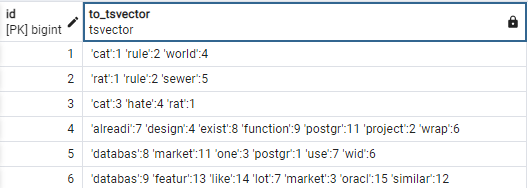
L’output mostra come to_tsvector converta la colonna di testo in un oggetto tsvector per la configurazione di ricerca testuale ‘english‘.
Configurazione di Ricerca Testuale
Il primo parametro per la funzione to_tsvector passato nell’esempio precedente era il nome della configurazione di ricerca testuale. In quel caso, era il “english“. Secondo la documentazione di Postgres, la configurazione di ricerca testuale è la seguente:
…la funzionalità di ricerca testuale completa include la possibilità di fare molte altre cose: evitare l’indicizzazione di certe parole (stop words), elaborare sinonimi e utilizzare un’analisi sofisticata, ad esempio, analizzare in base a più di solo spazio bianco. Questa funzionalità è controllata da configurazioni di ricerca testuale.
Quindi, la configurazione è un aspetto cruciale del processo e vitale per i risultati della ricerca full-text. Per diverse configurazioni, il motore Postgres può restituire risultati diversi. Ciò non deve necessariamente accadere tra dizionari per lingue diverse. Ad esempio, puoi avere due configurazioni per la stessa lingua, ma una ignora i nomi contenenti cifre (ad esempio, alcuni numeri seriali). Se passiamo nella nostra query il numero seriale specifico che stiamo cercando, che è obbligatorio, non troveremo alcun record per la configurazione che ignora le parole con numeri. Anche se abbiamo tali record nel database, si prega di consultare la documentazione sulla configurazione per maggiori informazioni.
Query Testuale
La query testuale supporta tali operatori come & (AND), | (OR), ! (NOT) e <-> (SEGUE). I primi tre operatori non richiedono una spiegazione più approfondita. L’operatore <-> verifica se le parole esistono e se sono disposte in un ordine specifico. Quindi, ad esempio, per la query “rat <-> cat“, ci aspettiamo che la parola “cat” esista, seguita dalla “rat”.
Esempi
- Contenuto che contiene il rat e il cat:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Rat & cat');
- Contenuto che contiene database e market, e il market è la terza parola dopo database:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database <3> market');
- Contenuto che contiene database ma non Postgres:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'database & !Postgres');
- Contenuto che contiene Postgres o Oracle:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ to_tsquery('english', 'Postgres | Oracle');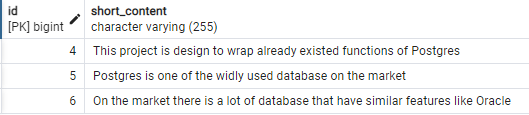
Funzioni Wrapper
Una delle funzioni wrapper che crea query di testo è già stata menzionata in questo articolo, che è la to_tsquery. Ci sono altre funzioni come:
plainto_tsqueryphraseto_tsquerywebsearch_to_tsquery
plainto_tsquery
La plainto_tsquery converte tutti i termini passati in una query in cui tutti i termini sono combinati con l’operatore & (AND). Ad esempio, l’equivalente di plainto_tsquery('english', 'Rat cat') è to_tsquery('english', 'Rat & cat').
Per l’utilizzo seguente:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ plainto_tsquery('english', 'Rat cat');Otteniamo il risultato seguente:

phraseto_tsquery
La phraseto_tsquery converte tutti i termini passati in una query in cui tutti i termini sono combinati con l’operatore <-> (SEGUE). Ad esempio, l’equivalente di phraseto_tsquery('english', 'cat rule') è to_tsquery('english', 'cat <-> rule').
Per l’utilizzo seguente:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ phraseto_tsquery('english', 'cat rule');Otteniamo il risultato seguente:

websearch_to_tsquery
La websearch_to_tsquery utilizza una sintassi alternativa per creare una query di testo valida.
- Unquoted text: Converte parte della sintassi allo stesso modo di
plainto_tsquery - Quoted text: Converte parte della sintassi allo stesso modo di
phraseto_tsquery - OR: Converte in “
|” (OR) operator - “
-“: Come “!” (NOT) operator
Ad esempio, l’equivalente di websearch_to_tsquery('english', '"cat rule" or database -Postgres') è to_tsquery('english', 'cat <-> rule | database & !Postgres').
Per il seguente utilizzo:
SELECT t.id, t.short_content FROM tweet t WHERE to_tsvector('english', t.short_content) @@ websearch_to_tsquery('english', '"cat rule" or database -Postgres');Otteniamo il risultato seguente:

Postgres and Hibernate Native Support
Come menzionato nell’articolo, Hibernate da solo non ha il supporto di ricerca full-text. Deve fare affidamento sul supporto del motore di database. Ciò significa che siamo autorizzati a eseguire query SQL native come mostrato negli esempi seguenti:
plainto_tsquery
public List<Tweet> findBySinglePlainQueryInDescriptionForConfigurationWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ plainto_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}websearch_to_tsquery
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescriptionWithNativeSQL(String textQuery, String configuration) {
return entityManager.createNativeQuery(String.format("select * from tweet t1_0 where to_tsvector('%1$s', t1_0.short_content) @@ websearch_to_tsquery('%1$s', :textQuery)", configuration), Tweet.class).setParameter("textQuery", textQuery).getResultList();
}Hibernate With posjsonhelper Library
La libreria posjsonhelper è un progetto open-source che aggiunge il supporto per query Hibernate per funzioni JSON di PostgreSQL e ricerca full-text.
Per il progetto Maven, è necessario aggiungere le dipendenze seguenti:
<dependency>
<groupId>com.github.starnowski.posjsonhelper.text</groupId>
<artifactId>hibernate6-text</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>6.4.0.Final</version>
</dependency>Per utilizzare i componenti presenti nella libreria posjsonhelper, è necessario registrarli nel contesto di Hibernate.
Ciò significa che deve esserci un’implementazione specificata dell’org.hibernate.boot.model.FunctionContributor. La libreria ha un’implementazione di questa interfaccia, ovvero com.github.starnowski.posjsonhelper.hibernate6.PosjsonhelperFunctionContributor.
A file with the name “org.hibernate.boot.model.FunctionContributor” under the “resources/META-INF/services” directory is required to use this implementation.
Esiste un altro modo per registrare il componente di posjsonhelper, che può essere fatto attraverso la programmazione. Per vedere come fare, consulta questo link.
Ora, possiamo utilizzare gli operatori di ricerca full-text nelle query di Hibernate.
PlainToTSQueryFunction
Questo è un componente che incapsula la funzione plainto_tsquery.
public List<Tweet> findBySinglePlainQueryInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PlainToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Per una configurazione con il valore 'english', il codice genererà la seguente dichiarazione:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ plainto_tsquery('english', ?);PhraseToTSQueryFunction
Questo componente incapsula la funzione phraseto_tsquery.
public List<Tweet> findBySinglePhraseInDescriptionForConfiguration(String textQuery, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new PhraseToTSQueryFunction((NodeBuilder) cb, configuration, textQuery), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Per la configurazione con il valore 'english', il codice genererà la seguente istruzione:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ phraseto_tsquery('english', ?)WebsearchToTSQueryFunction
Questo componente incapsula la funzione websearch_to_tsquery.
public List<Tweet> findCorrectTweetsByWebSearchToTSQueryInDescription(String phrase, String configuration) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Tweet> query = cb.createQuery(Tweet.class);
Root<Tweet> root = query.from(Tweet.class);
query.select(root);
query.where(new TextOperatorFunction((NodeBuilder) cb, new TSVectorFunction(root.get("shortContent"), configuration, (NodeBuilder) cb), new WebsearchToTSQueryFunction((NodeBuilder) cb, configuration, phrase), hibernateContext));
return entityManager.createQuery(query).getResultList();
}Per la configurazione con il valore 'english', il codice genererà la seguente istruzione:
select
t1_0.id,
t1_0.short_content,
t1_0.title
from
tweet t1_0
where
to_tsvector('english', t1_0.short_content) @@ websearch_to_tsquery('english', ?)Query HQL
Tutti i componenti menzionati possono essere utilizzati nelle query HQL. Per verificare come può essere fatto, si prega di fare clic su questo link.
Perché utilizzare la libreria posjsonhelper quando possiamo usare l’approccio nativo con Hibernate?
Sebbene concatenare dinamicamente una stringa che dovrebbe essere una query HQL o SQL possa essere facile, implementare predicati sarebbe una migliore pratica, specialmente quando si deve gestire criteri di ricerca basati su attributi dinamici dalla propria API.
Conclusione
Come menzionato nell’articolo precedente, il supporto alla ricerca full-text di Postgres può essere una buona alternativa per motori di ricerca significativi come Elasticsearch o Lucene, in alcuni casi. Ciò potrebbe evitare la decisione di aggiungere soluzioni di terze parti al nostro stack tecnologico, che potrebbero anche aggiungere più complessità e costi aggiuntivi.
Source:
https://dzone.com/articles/postgres-full-text-search-with-hibernate-6