













In un’era caratterizzata da un aumento esponenziale nella generazione di dati, le organizzazioni devono sfruttare efficacemente questa ricchezza di informazioni per mantenere il loro vantaggio competitivo. La ricerca e l’analisi efficiente dei dati dei clienti — come l’identificazione delle preferenze degli utenti per le raccomandazioni di film o analisi del sentiment — svolgono un ruolo cruciale nel guidare un processo decisionale informato e nel migliorare le esperienze degli utenti. Ad esempio, un servizio di streaming può utilizzare ricerca vettoriale per raccomandare film personalizzati in base alla cronologia di visione e alle valutazioni individuali, mentre un marchio al dettaglio può analizzare i sentimenti dei clienti per affinare le strategie di marketing.
Come ingegneri dei dati, siamo incaricati di implementare queste soluzioni sofisticate, garantendo che le organizzazioni possano trarre approfondimenti azionabili da vasti set di dati. Questo articolo esplora le complessità della ricerca vettoriale utilizzando Elasticsearch, concentrandosi su tecniche efficaci e migliori pratiche per ottimizzare le prestazioni. Esaminando casi studio sul recupero di immagini per marketing personalizzato e analisi del testo per il clustering dei sentimenti dei clienti, dimostriamo come l’ottimizzazione della ricerca vettoriale possa portare a interazioni migliorate con i clienti e a una crescita aziendale significativa.
Cosa È la Ricerca Vettoriale?
La ricerca vettoriale è un metodo potente per identificare somiglianze tra punti dati rappresentandoli come vettori in uno spazio ad alta dimensione. Questo approccio è particolarmente utile per applicazioni che richiedono un recupero rapido di elementi simili basati sulle loro caratteristiche.
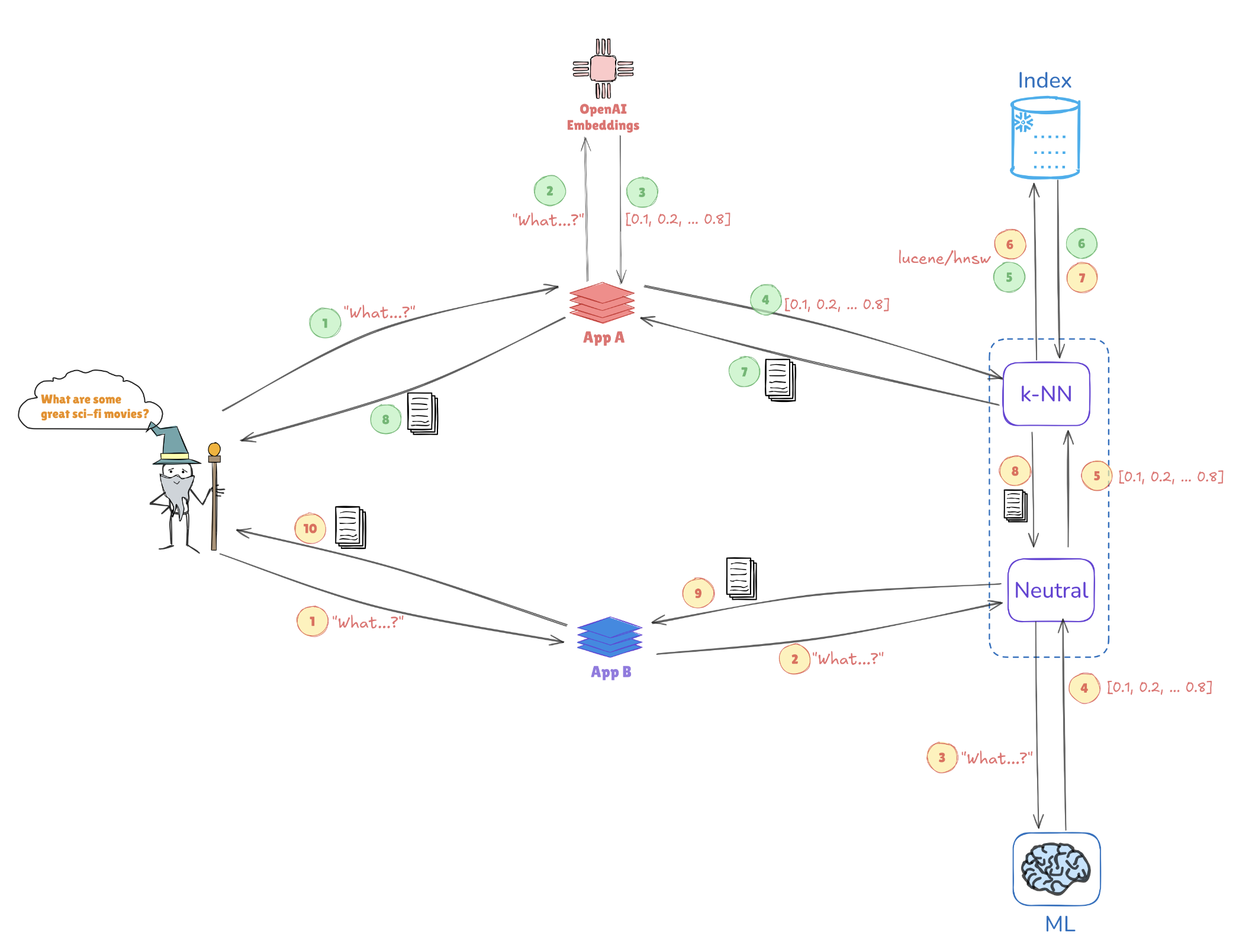
Illustrazione della Ricerca Vettoriale
Considera l’illustrazione qui sotto, che mostra come le rappresentazioni vettoriali consentono ricerche di similarità:
- Fusione delle query: La query “Quali sono alcuni grandi film di fantascienza?” viene convertita in una rappresentazione vettoriale, come [0.1, 0.2, …, 0.4].
- Indicizzazione: Questo vettore viene confrontato con vettori pre-indicizzati memorizzati in Elasticsearch (ad esempio, da applicazioni come AppA e AppB) per trovare query o punti dati simili.
- Ricerca k-NN: Utilizzando algoritmi come k-Nearest Neighbors (k-NN), Elasticsearch recupera in modo efficiente le migliori corrispondenze dai vettori indicizzati, aiutando a identificare rapidamente le informazioni più rilevanti.
Questo meccanismo consente a Elasticsearch di eccellere in casi d’uso come sistemi di raccomandazione, ricerche di immagini e elaborazione del linguaggio naturale, dove comprendere il contesto e la somiglianza è fondamentale.
Vantaggi Chiave della Ricerca Vettoriale con Elasticsearch
Supporto per Alta Dimensione
Elasticsearch eccelle nella gestione di strutture dati complesse, essenziali per applicazioni di AI e machine learning. Questa capacità è cruciale quando si tratta di gestire tipi di dati multifaccettati, come immagini o dati testuali.
Scalabilità
La sua architettura supporta la scalabilità orizzontale, consentendo alle organizzazioni di gestire set di dati in continua espansione senza compromettere le performance. Questo è fondamentale poiché i volumi di dati continuano a crescere.
Integrazione
Elasticsearch funziona senza problemi con l’Elastic stack, fornendo una soluzione completa per l’ingestione, l’analisi e la visualizzazione dei dati. Questa integrazione garantisce che gli ingegneri dei dati possano sfruttare una piattaforma unificata per vari compiti di elaborazione dei dati.
Best Practices per Ottimizzare le Prestazioni della Ricerca Vettoriale
1. Ridurre le Dimensioni dei Vettori
Ridurre la dimensionalità dei tuoi vettori può migliorare notevolmente le prestazioni di ricerca. Tecniche come PCA (Analisi delle Componenti Principali) o UMAP (Approssimazione e Proiezione di Varietà Uniformi) aiutano a mantenere le caratteristiche essenziali semplificando la struttura dei dati.
Esempio: Riduzione della Dimensione con PCA
Ecco come implementare PCA in Python utilizzando Scikit-learn:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Indicizzare in Modo Efficiente
Sfruttare gli algoritmi di Nearest Neighbor Approssimato (ANN) può accelerare significativamente i tempi di ricerca. Considera di utilizzare:
- HNSW (Hierarchical Navigable Small World): Conosciuto per il suo equilibrio tra prestazioni e accuratezza.
- FAISS (Facebook AI Similarity Search): Ottimizzato per grandi dataset e in grado di utilizzare l’accelerazione GPU.
Esempio: Implementazione di HNSW in Elasticsearch
Puoi definire le impostazioni del tuo indice in Elasticsearch per utilizzare HNSW come segue:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Query Batch
Per migliorare l’efficienza, l’elaborazione batch di più query in un’unica richiesta riduce l’overhead. Questo è particolarmente utile per applicazioni con un alto traffico utente.
Esempio: Elaborazione Batch in Elasticsearch
Puoi utilizzare l’endpoint _msearch per le query batch:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Utilizza la Cache
Implementa strategie di caching per query frequentemente accedute per diminuire il carico computazionale e migliorare i tempi di risposta.
5. Monitora le Prestazioni
Analizzare regolarmente le metriche di prestazione è fondamentale per identificare i colli di bottiglia. Strumenti come Kibana possono aiutare a visualizzare questi dati, consentendo aggiustamenti informati alla tua configurazione di Elasticsearch.
Regolazione dei Parametri in HNSW per Migliorare le Prestazioni
Ottimizzare HNSW implica regolare alcuni parametri per ottenere migliori prestazioni su grandi dataset:
M(numero massimo di connessioni): Aumentare questo valore migliora il richiamo ma potrebbe richiedere più memoria.EfConstruction(dimensione della lista dinamica durante la costruzione): Un valore più alto porta a un grafo più accurato ma può aumentare il tempo di indicizzazione.EfSearch(dimensione della lista dinamica durante la ricerca): Regolare questo parametro influisce sul compromesso velocità-accuratezza; un valore più grande fornisce una migliore capacità di richiamo ma richiede più tempo per il calcolo.
Esempio: Regolazione dei parametri HNSW
È possibile regolare i parametri HNSW durante la creazione dell’indice in questo modo:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Studio di caso: Impatto della riduzione della dimensionalità sulle prestazioni HNSW nelle applicazioni di dati dei clienti
Recupero immagini per il marketing personalizzato
Le tecniche di riduzione della dimensionalità svolgono un ruolo fondamentale nell’ottimizzazione dei sistemi di recupero immagini all’interno delle applicazioni di dati dei clienti. In uno studio, i ricercatori hanno applicato l’Analisi delle Componenti Principali (PCA) per ridurre la dimensionalità prima di indicizzare le immagini con le reti Hierarchical Navigable Small World (HNSW). La PCA ha fornito un notevole aumento della velocità di recupero — essenziale per le applicazioni che gestiscono elevate quantità di dati dei clienti — anche se ciò è stato a scapito di una minore precisione a causa della riduzione delle informazioni. Per affrontare questo problema, i ricercatori hanno esaminato anche l’Approssimazione e Proiezione Uniforme della Varianza (UMAP) come alternativa. UMAP ha conservato in modo più efficace le strutture dati locali, mantenendo i dettagli intricati necessari per le raccomandazioni di marketing personalizzate. Sebbene UMAP richiedesse una maggiore potenza computazionale rispetto alla PCA, ha bilanciato la velocità di ricerca con un’alta precisione, rendendolo una scelta valida per compiti critici di accuratezza.
Analisi del testo per il clustering del sentiment dei clienti
Nel campo dell’analisi del sentiment dei clienti, uno studio diverso ha scoperto che UMAP supera PCA nel clustering di dati testuali simili. UMAP ha consentito al modello HNSW di raggruppare i sentimenti dei clienti con maggiore precisione — un vantaggio nella comprensione del feedback dei clienti e nella fornitura di risposte più personalizzate. L’uso di UMAP ha facilitato valori EfSearch più piccoli in HNSW, migliorando la velocità e la precisione della ricerca. Questa efficienza di clustering migliorata ha consentito un’identificazione più rapida dei sentimenti dei clienti rilevanti, potenziando gli sforzi di marketing mirato e la segmentazione dei clienti basata sul sentiment.
Integrazione di Tecniche di Ottimizzazione Automatica
Ottimizzare la riduzione dimensionale e i parametri HNSW è essenziale per massimizzare le prestazioni dei sistemi di dati dei clienti. Le tecniche di ottimizzazione automatica semplificano questo processo di regolazione, garantendo che le configurazioni selezionate siano efficaci in diverse applicazioni:
- Ricerca a griglia e casuale: Questi metodi offrono un’esplorazione ampia e sistematica dei parametri, identificando configurazioni adatte in modo efficiente.
- Ottimizzazione bayesiana: Questa tecnica si concentra su parametri ottimali con meno valutazioni, conservando risorse computazionali.
- Cross-validation: La cross-validation aiuta a convalidare i parametri su vari dataset, assicurando la loro generalizzazione a contesti di dati dei clienti diversi.
Affrontare le Sfide nell’Automazione
Integrare l’automazione nei flussi di lavoro di riduzione della dimensionalità e HNSW può presentare sfide, in particolare nella gestione delle richieste computazionali e nell’evitare l’overfitting. Le strategie per superare queste sfide includono:
- Riduzione del sovraccarico computazionale: Utilizzare l’elaborazione parallela per distribuire il carico di lavoro riduce il tempo di ottimizzazione, migliorando l’efficienza del flusso di lavoro.
- Integrazione modulare: Un approccio modulare facilita l’integrazione senza soluzione di continuità dei sistemi automatizzati nei flussi di lavoro esistenti, riducendo la complessità.
- Prevenzione dell’overfitting: Una validazione robusta attraverso la cross-validation assicura che i parametri ottimizzati performino costantemente su diversi set di dati, minimizzando l’overfitting e migliorando la scalabilità nelle applicazioni di dati dei clienti.
Conclusione
Per sfruttare appieno le prestazioni della ricerca vettoriale in Elasticsearch, è essenziale adottare una strategia che combini la riduzione della dimensionalità, l’indicizzazione efficiente e la regolazione attenta dei parametri. Integrando queste tecniche, gli ingegneri dei dati possono creare un sistema di recupero dei dati altamente reattivo e preciso. I metodi di ottimizzazione automatizzati elevano ulteriormente questo processo, consentendo un continuo affinamento dei parametri di ricerca e delle strategie di indicizzazione. Man mano che le organizzazioni si affidano sempre più a intuizioni in tempo reale da vasti set di dati, queste ottimizzazioni possono migliorare significativamente le capacità decisionali, offrendo risultati di ricerca più rapidi e pertinenti. Abbracciare questo approccio prepara il terreno per una futura scalabilità e una maggiore reattività, allineando le capacità di ricerca con le crescenti esigenze aziendali e la crescita dei dati.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch