













Caso Classico 1
Molti professionisti del software mancano di una conoscenza approfondita del ragionamento logico TCP/IP, il che spesso porta a identificare erroneamente i problemi come problemi misteriosi. Alcuni sono scoraggiati dalla complessità della letteratura sul networking TCP/IP, mentre altri sono fuorviati da dettagli confusi in Wireshark. Ad esempio, un DBA che affronta problemi di prestazioni potrebbe interpretare erroneamente i dati di cattura dei pacchetti in Wireshark, concludendo erroneamente che le ritrasmissioni TCP siano la causa.

Poiché si sospetta una ritrasmissione, è essenziale comprenderne la natura. La ritrasmissione coinvolge fondamentalmente la ritrasmissione per timeout. Per confermare se la ritrasmissione sia effettivamente la causa, sono necessarie informazioni temporali, che non sono fornite nello screenshot sopra. Dopo aver richiesto un nuovo screenshot al DBA, le informazioni sul timestamp sono state incluse.

Quando si analizzano i pacchetti di rete, le informazioni sul timestamp sono cruciali per un ragionamento logico accurato. Una differenza di tempo nell’intervallo dei microsecondi tra due pacchetti duplicati suggerisce o una ritrasmissione per timeout o una cattura di pacchetti duplicati. In un tipico ambiente LAN con un tempo di andata e ritorno (RTT) di circa 100 microsecondi, dove TCP le ritrasmissioni richiedono almeno un RTT, una ritrasmissione che si verifica a solo 1/100 del RTT indica probabilmente una cattura di pacchetti duplicati piuttosto che una reale ritrasmissione per timeout.
Caso Classico 2
Un altro caso classico illustra l’importanza del ragionamento logico nell’analisi dei problemi di rete.
Un giorno, un sviluppatore aziendale è venuto di corsa, dicendo che uno script programmato utilizzando il middleware del database MySQL era fallito nelle prime ore del mattino senza alcuna risposta. Dopo aver sentito del problema, ho controllato i log degli errori del middleware del database MySQL ma non ho trovato indizi utili. Così, ho chiesto agli sviluppatori se potessero riprodurre il problema, sapendo che una volta riproducibile, un problema diventa più facile da risolvere.
Gli sviluppatori hanno provato più volte a riprodurre il problema ma senza successo. Tuttavia, hanno fatto una nuova scoperta: hanno scoperto che eseguire le stesse query SQL durante il giorno risultava in tempi di risposta diversi rispetto alle prime ore del mattino. Sospettavano che quando la risposta SQL fosse lenta, il middleware del database MySQL bloccasse la sessione e non restituisse i risultati al client.
Basandosi su questa intuizione, è stato chiesto al team delle operazioni sul database di modificare lo SQL dello script per simulare una risposta SQL lenta. Di conseguenza, il middleware del database MySQL ha restituito i risultati senza incontrare il problema di blocco riscontrato nelle prime ore del mattino.
Per un po’, la causa radice non poteva essere identificata, e gli sviluppatori hanno scoperto un problema funzionale con il middleware del database MySQL. Pertanto, gli sviluppatori e le operazioni del DBA sono diventati sempre più convinti che il middleware del database MySQL stesse ritardando le risposte. In realtà, questi problemi non erano correlati ai tempi di risposta del middleware del database MySQL.
Dagli eventi del primo giorno, il problema si è effettivamente verificato. Tutti coinvolti hanno cercato di individuare la causa, facendo varie ipotesi, ma la vera ragione è rimasta sfuggente.
Il giorno successivo, gli sviluppatori hanno segnalato che il problema dello script si è ripresentato la mattina presto, tuttavia non sono riusciti a riprodurlo durante il giorno. Gli sviluppatori, sentendosi sotto pressione in quanto lo script stava per essere utilizzato online, si sono lamentati della situazione. Il mio unico suggerimento è stato di utilizzare lo script durante il giorno per evitare problemi la mattina presto. Con tutti i sospetti concentrati sul middleware del database MySQL, è stato difficile analizzare il problema da altre prospettive.
Come sviluppatore responsabile del middleware del database MySQL, problemi misteriosi come questi non possono essere facilmente trascurati. Ignorarli potrebbe influenzare l’uso successivo del middleware del database MySQL e c’è anche pressione da parte della dirigenza per risolvere il problema prontamente. Alla fine, è stato deciso di implementare una soluzione di analisi di cattura pacchetti a basso costo: durante l’esecuzione dello script la mattina presto, sarebbero state eseguite catture di pacchetti sul server per analizzare cosa stesse accadendo in quel momento. L’obiettivo era determinare se il middleware del database MySQL non inviava affatto una risposta o se inviava una risposta che lo script client non riceveva. Una volta confermato che il middleware del database MySQL aveva effettivamente inviato una risposta, il problema non sarebbe stato attribuito agli sviluppatori del middleware del database MySQL.
Il terzo giorno, gli sviluppatori hanno riferito che il problema verificatosi nelle prime ore del mattino non si era ripresentato, e l’analisi dei pacchetti catturati ha confermato che il problema non si era verificato. Dopo un’attenta considerazione, sembrava improbabile che il problema fosse esclusivamente legato al middleware del database MySQL: le frequenti occorrenze nelle prime ore del mattino e le rare occorrenze durante il giorno erano sconcertanti. L’unica linea d’azione era aspettare che il problema si ripresentasse e analizzarlo in base ai pacchetti catturati.
Il quarto giorno, il problema non si è ripresentato.
Tuttavia, il quinto giorno, il problema è finalmente riapparso, portando speranza per una risoluzione.
I file di cattura dei pacchetti sono numerosi. Prima, chiedere agli sviluppatori di fornire il timestamp in cui si è verificato il problema, poi cercare tra i dati di cattura dei pacchetti per identificare la query SQL che ha causato il problema. Il risultato finale è il seguente:
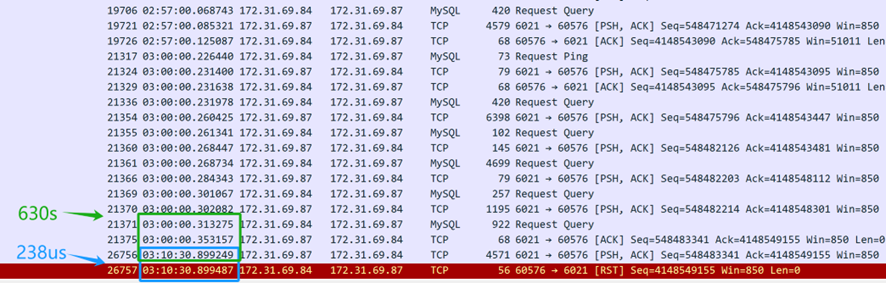
Dal contenuto della cattura dei pacchetti sopra (catturato dal server), sembra che la query SQL sia stata inviata alle 3 del mattino. Il middleware del database MySQL ha impiegato 630 secondi (03:10:30.899249-03:00:00.353157) per restituire la risposta SQL al client, indicando che il middleware del database MySQL ha effettivamente risposto alla query SQL. Tuttavia, solo 238 microsecondi dopo (03:10:30.899487-03:10:30.899249), il livello TCP del server ha ricevuto un pacchetto di reset, che era sospettosamente rapido. È importante notare che questo pacchetto di reset non può essere immediatamente considerato proveniente dal client.
In primo luogo, è necessario confermare chi ha inviato il pacchetto di reset — se è stato inviato dal client o da un dispositivo intermedio lungo il percorso. Poiché la cattura dei pacchetti è stata eseguita solo sul lato server, le informazioni sulla situazione dei pacchetti del client non sono disponibili. Analizzando i file di cattura dei pacchetti dal lato server e applicando il ragionamento logico, l’obiettivo è identificare la causa principale del problema.
Se si ipotizza che il client abbia inviato un reset, ciò implicherebbe che lo strato TCP del client non riconosce più lo stato TCP di questa connessione — passando da uno stato stabilito a uno inesistente. Questo cambiamento di stato TCP notificherebbe all’applicazione client un problema di connessione, causando l’errore immediato dello script client. Tuttavia, in realtà, lo script client sta ancora aspettando che la risposta torni. Pertanto, l’ipotesi che il client abbia inviato un reset non è vera — il client non ha inviato un reset. La connessione del client è ancora attiva, ma sul lato server, la relativa connessione è stata terminata dal reset.
Chi ha inviato il reset, allora? Il principale sospettato è l’ambiente cloud di Amazon. Sulla base di questa analisi della cattura dei pacchetti, le operazioni DBA hanno interrogato il servizio clienti di Amazon e ricevuto le seguenti informazioni:
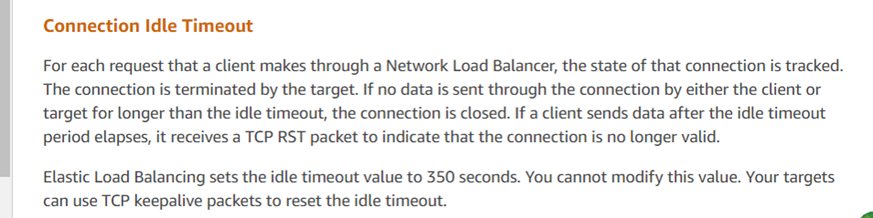
La risposta del servizio clienti è in linea con i risultati dell’analisi, indicando che l’ELB (Elastic Load Balancer, simile a LVS) di Amazon ha terminato forzatamente la sessione TCP. Secondo il loro feedback, se una risposta supera la soglia di 350 secondi (come osservato nella cattura dei pacchetti a 630 secondi), il dispositivo ELB di Amazon invia un reset alla parte rispondente (in questo caso, il server). Gli script client distribuiti dagli sviluppatori non hanno ricevuto il reset e hanno erroneamente supposto che la connessione con il server fosse ancora attiva. Le raccomandazioni ufficiali per tali problemi includono l’uso di meccanismi TCP keepalive per mitigare queste problematiche.
Con la risposta ufficiale ottenuta, il problema è stato considerato completamente risolto.
Questo caso specifico illustra come i problemi online possano essere altamente complessi, richiedendo la cattura di informazioni critiche — in questo caso, i dati di cattura dei pacchetti — per comprendere la situazione così come si è verificata. Attraverso il ragionamento logico e l’applicazione del reductio ad absurdum, è stata identificata la causa principale.
Source:
https://dzone.com/articles/logical-reasoning-in-network-problems