













Imparare Linux è una delle competenze più preziose nell’industria tecnologica. Può aiutare a fare le cose più velocemente e in modo più efficiente. Molti dei server potenti e supercomputer del mondo girano su Linux.
Imparare Linux, oltre a rinforzare il tuo ruolo attuale, può anche aiutare a passare ad altre carriere tecnologiche come DevOps, Cybersecurity e Cloud Computing.
In questo manuale, imparerai i concetti di base della linea di comando Linux, per poi passare a argomenti più avanzati come lo scripting della shell e l’amministrazione del sistema. Che tu sia nuovo a Linux o lo usi da anni, questo libro ha qualcosa da offrirti.
Nota importante: Tutti gli esempi in questo libro sono dimostrati in Ubuntu 22.04.2 LTS (Jammy Jellyfish). La maggior parte degli strumenti da linea di comando sono più o meno gli stessi in altre distribuzioni. Tuttavia, alcune applicazioni GUI e comandi potrebbero differire se stai lavorando su un’altra distribuzione Linux.
Indice
-
Capitolo 2: Introduzione alla Shell Bash e ai Comandi di Sistema
-
Parte 5: Gli elementi essenziali dell’editing di testo in Linux
Parte 1: Introduzione a Linux
1.1. Inizia con Linux
Cosa è Linux?
Linux è un sistema operativo open source basato sul sistema operativo Unix. È stato creato da Linus Torvalds nel 1991.
Open source significa che il codice sorgente del sistema operativo è accessibile al pubblico. Questo consente a chiunque di modificare il codice originale, personalizzarlo e distribuire il nuovo sistema operativo a potenziali utenti.
Perché dovresti imparare riguardo a Linux?
Nella landscape attuale dei data center, Linux e Microsoft Windows emergono come i principali contendenti, con Linux che detiene una fetta significativa del mercato.
Ecco alcuni motivi convincenti per imparare Linux:
-
Date le ampie aree di hosting Linux, è probabile che il tuo applicativo sia ospitato su Linux. Perciò imparare Linux come sviluppatore diventa sempre più prezioso.
-
Con il cloud computing che diventa la norma, sono altissime le probabilità che le tue istanze cloud dipendano da Linux.
-
Linux costituisce la base per molti sistemi operativi destinati all’Internet of Things (IoT) e alle applicazioni mobili.
-
Nell’IT, ci sono molte opportunità per chi ha competenze in Linux.
Cosa significa che Linux è un sistema operativo open source?
Innanzitutto, cos’è il software open source? Il software open source è un software il cui codice sorgente è liberamente accessibile, consentendo a chiunque di utilizzarlo, modificarlo e distribuirlo.
Ogni volta che viene creato un codice sorgente, viene automaticamente considerato coperto da copyright, e la sua distribuzione è regolata dal detentore del copyright attraverso licenze software.
In contrasto con l’open source, il software proprietario o closed-source limita l’accesso al suo codice sorgente. Solo i creatori possono visualizzarlo, modificarlo o distribuirlo.
Linux è principalmente open source, il che significa che il suo codice sorgente è liberamente disponibile. Chiunque può visualizzarlo, modificarlo e distribuirlo. Sviluppatori provenienti da qualsiasi parte del mondo possono contribuire al suo miglioramento. Questo pone le basi della collaborazione, che è un aspetto importante del software open source.
Questo approccio collaborativo ha portato all’ampia adozione di Linux su server, desktop, sistemi embedded e dispositivi mobili.
L’aspetto più interessante di Linux essere open source è che chiunque può personalizzare il sistema operativo secondo le proprie esigenze specifiche senza essere vincolato da limitazioni proprietarie.
Chrome OS utilizzato dai Chromebook si basa su Linux. Android, che alimenta molti smartphone a livello globale, si basa anche su Linux.
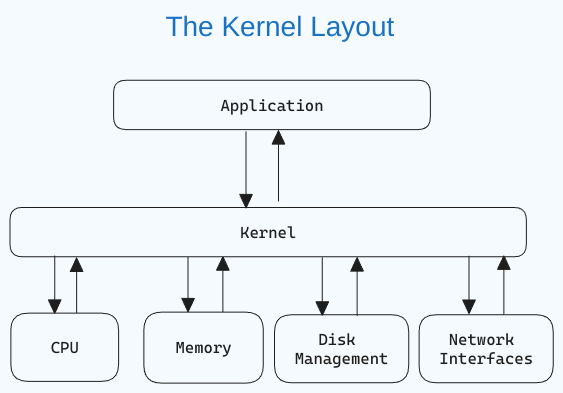
Cos’è un Kernel Linux?
Il kernel è il componente centrale di un sistema operativo che gestisce il computer e le sue operazioni hardware. Si occupa delle operazioni di memoria e del tempo della CPU.
Il kernel funge da ponte tra le applicazioni e l’elaborazione dei dati a livello hardware utilizzando comunicazioni tra processi e chiamate di sistema.
Il kernel viene caricato nella memoria prima dell’avvio del sistema operativo e rimane fino alla disattivazione dello stesso. E’ responsabile per compiti come la gestione del disco, la gestione delle task e la gestione della memoria.
Se sei curioso di come si presenta il kernel di Linux, qui si trova il link di GitHub.
Cosa è una distribuzione Linux?
A questo punto, sai che puoi riutilizzare il codice del kernel Linux, modificarlo e creare un nuovo kernel. Puoi anche combinare differenti utility e software per creare un sistema operativo completamente nuovo.
Una distribuzione Linux o distro è una versione del sistema operativo Linux che include il kernel Linux, le utility di sistema e altro software. essendo open source, una distribuzione Linux è un insieme collaborativo che coinvolge molte comunità indipendenti di sviluppo open source.
Cosa significa che una distribuzione è derivata? Quando dici che una distribuzione è “derivata” da un’altra, la nuova distro è costruita sulla base o sul fondamento della distribuzione originale. Questa derivazione può includere l’uso dello stesso sistema di gestione pacchetti (ne parleremo più tardi), della stessa versione del kernel e a volte degli stessi strumenti di configurazione.
Oggi, ci sono migliaia di distribuzioni Linux da cui scegliere, che offrono obiettivi e criteri differenti per la selezione e il supporto del software fornito dalla loro distribuzione.
Le distribuzioni variano l’una dall’altra, ma hanno in generale alcune caratteristiche comuni:
-
Una distribuzione consiste in un kernel Linux.
-
Supporta programmi dello spazio utente.
-
Una distribuzione può essere piccola e adatta a un solo scopo o includere migliaia di programmi open-source.
-
Deve essere fornito qualche mezzo per installare e aggiornare la distribuzione e i suoi componenti.
Se guardate la Linea Temporale delle Distribuzioni Linux, vedrete due maggiori distribuzioni: Slackware e Debian. Da esse sono derivate diverse distribuzioni. Per esempio, Ubuntu e Kali sono derivati da Debian.
Cose sono le risorse dell’approvazione? Ci sono varie risorse dell’approvazione. Le distribuzioni derivate possono sfruttare la stabilità, la sicurezza e i grandi repository software della distribuzione genitore.
Quando si costruisce su un fondamento esistente, i sviluppatori possono concentrarsi esclusivamente sulle caratteristiche specializzate della nuova distribuzione. Gli utenti delle distribuzioni derivate possono beneficiare dalla documentazione, dalla community support e dalle risorse già disponibili per la distribuzione genitore.
Alcune popolari distribuzioni Linux sono:
-
Ubuntu: Una delle distribuzioni Linux più utilizzate e popolari. È user-friendly e consigliata per i principianti. Scopri di più su Ubuntu qui.
-
Linux Mint: Basata su Ubuntu, Linux Mint offre un’esperienza user-friendly con un focus sul supporto multimediale. Scopri di più su Linux Mint qui.
-
Arch Linux: Popolare tra gli utenti esperti, Arch è una distribuzione leggera e flessibile rivolta agli utenti che preferiscono un approccio fai-da-te. Scopri di più su Arch Linux qui.
-
Manjaro: Basato su Arch Linux, Manjaro offre un’esperienza user-friendly con software preinstallati e strumenti di gestione del sistema facili da usare. Scopri di più su Manjaro qui.
-
Kali Linux: Kali Linux offre un insieme completo di strumenti per la sicurezza e si concentra principalmente su cybersecurity e hacker. Scopri di più su Kali Linux qui.
Come installare e accedere a Linux
Il modo migliore per imparare è applicare i concetti in corso. In questa sezione, impareremo come installare Linux sul tuo computer così da poter seguire. Imparerai anche come accedere a Linux su un computer Windows.
Ti consiglio di seguire una delle metodologie indicate in questa sezione per ottenere accesso a Linux in modo da poter seguire.
Installa Linux come SO primario
Installare Linux come SO primario è il modo più efficiente per usare Linux, in quanto puoi utilizzare tutta la potenza della tua macchina.
In questa sezione imparerete come installare Ubuntu, una delle distribuzioni Linux più popolari. Per ora ho omesso altre distribuzioni, visto che voglio mantenere le cose semplici. Potete sempre esplorare altre distribuzioni una volta comodi con Ubuntu.
-
Step 1 – Scarica l’ISO di Ubuntu: Vai sul sito ufficiale web e scarica il file ISO. Assicuratevi di scegliere una versione stabile che sia etichettata come “LTS”. LTS sta per Long Term Support, cioè puoi ottenere aggiornamenti di sicurezza e manutenzione gratuiti per un lungo periodo (di solito 5 anni).
-
Step 2 – Crea una chiavetta USB bootabile: Esistono molti software in grado di creare una chiavetta USB bootabile. Io vi consiglio Rufus, poiché è abbastanza facile da usare. Puoi scaricarlo da qui.
-
Passaggio 3 – Avvia dalla chiavetta USB: Una volta che la tua chiavetta USB avviabile è pronta, inseriscila e avvia dal dispositivo USB. Il menu di avvio dipende dal tuo laptop. Puoi cercare su Google il menu di avvio per il modello del tuo laptop.
-
Passaggio 4 – Segui le istruzioni. Una volta avviato il processo di avvio, seleziona
prova o installa ubuntu.
Il processo richiederà del tempo. Una volta che appare l’interfaccia grafica, puoi selezionare la lingua, la disposizione della tastiera e continuare. Inserisci il tuo nome utente e nome. Ricorda le credenziali perché le avrai bisogno per accedere al sistema e ottenere i privilegi completi. Attendi il completamento dell’installazione.
-
Passaggio 5 – Riavvia: Clicca su riavvia ora e rimuovi la chiavetta USB.
-
Passaggio 6 – Accesso: Accedi con le credenziali che hai inserito in precedenza.
Ecco fatto! Ora puoi installare app e personalizzare il tuo desktop.

Per un’installazione avanzata, puoi esplorare i seguenti argomenti:
-
Partizionamento del disco.
-
Impostare la memoria di swap per abilitare l’ibernazione.
Accesso al terminale
Una parte importante di questo manuale è imparare a utilizzare il terminale, dove eseguirai tutti i comandi e vedrai accadere la magia. Puoi cercare il terminale premendo il tasto “windows” e digitando “terminale”. Puoi aggiungere il Terminale nel dock dove si trovano le altre app per un accesso facile.
💡 La scorciatoia per aprire il terminale è
ctrl+alt+t
Puoi anche aprire il terminale da dentro una cartella. Fai clic con il tasto destro dove ti trovi e clicca su “Apri nel terminale”. Questo aprirà il terminale nella stessa posizione.
Come utilizzare Linux su un computer Windows
A volte potresti aver bisogno di eseguire contemporaneamente Linux e Windows. Fortunatamente, ci sono modi per ottenere il meglio di entrambi i mondi senza dover avere computer diversi per ciascun sistema operativo.
In questa sezione, esplorerai alcuni modi per utilizzare Linux su un computer Windows. Alcuni di essi sono basati su browser o cloud e non richiedono alcuna installazione del sistema operativo prima di poterli utilizzare.
Opzione 1: “Dual-boot” Linux + Windows Con il dual-boot, è possibile installare Linux accanto a Windows sul computer, permettendovi di scegliere quale sistema operativo utilizzare all’avvio.
Questo richiede la partizionatura del disco fisso e l’installazione di Linux su una partizione separata. Con questo approcio, è possibile utilizzare solo uno dei due sistemi operativi alla volta.
Opzione 2: Utilizzare Windows Subsystem for Linux (WSL) Il Windows Subsystem for Linux fornisce una piattaforma di compatibilità che consente di eseguire nativamente i binari Linux su Windows.
L’utilizzo di WSL offre alcuni vantaggi. L’installazione di WSL è semplice e non richiede molto tempo. È leggero rispetto alle VM in cui devi allocare risorse dalla macchina host. Non è necessario installare nessuna ISO o immagine del disco virtuale per i computer Linux, che tendono a essere file pesanti. È possibile utilizzare Windows e Linux side by side.
Come installare WSL2
Prim首, abilita l’opzione Windows Subsystem for Linux nelle impostazioni.
-
Vai a Iniziare. Cerca “Attiva o disattiva le caratteristiche di Windows.”
-
Seleziona l’opzione “Windows Subsystem for Linux” se non è già selezionata.
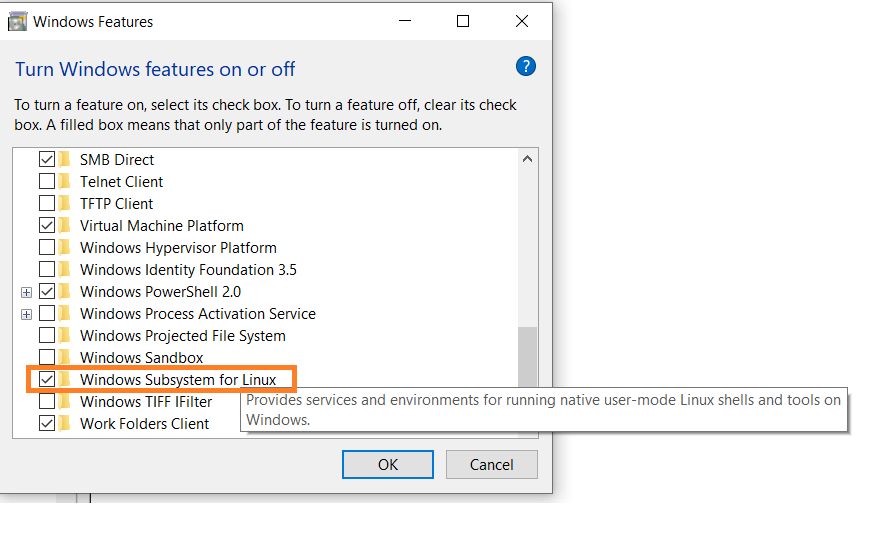
-
Poi, apri il tuo prompt dei comandi e fornisci i comandi di installazione.
-
Apri Prompt dei comandi come amministratore:

-
Esegui il comando seguente:
wsl --install
Questo è l’output:
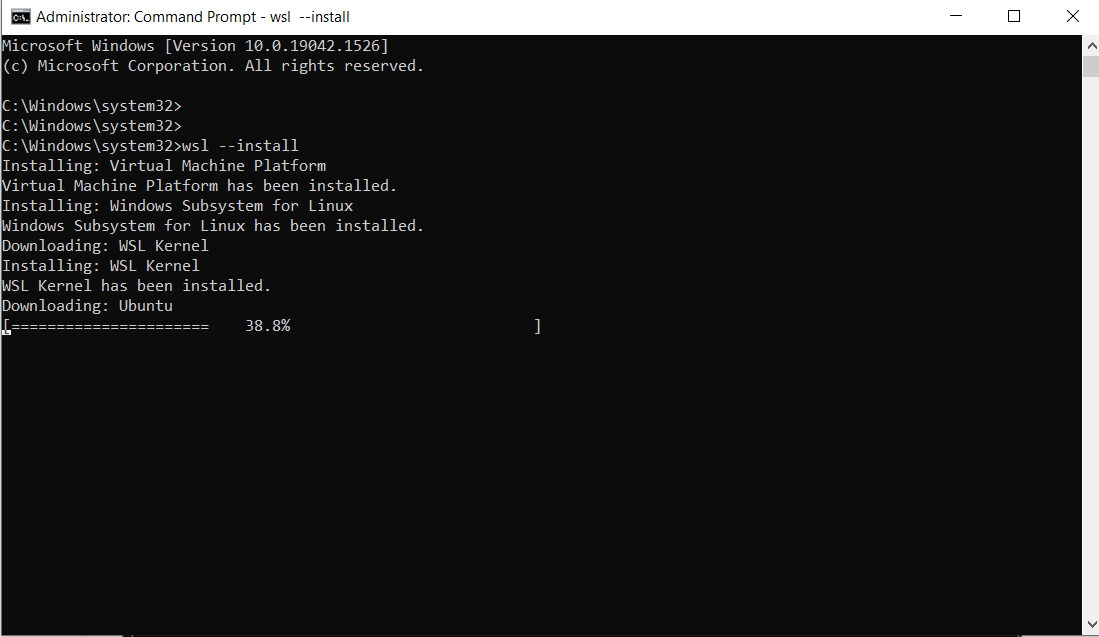
Nota: Per default, Ubuntu verrà installato.
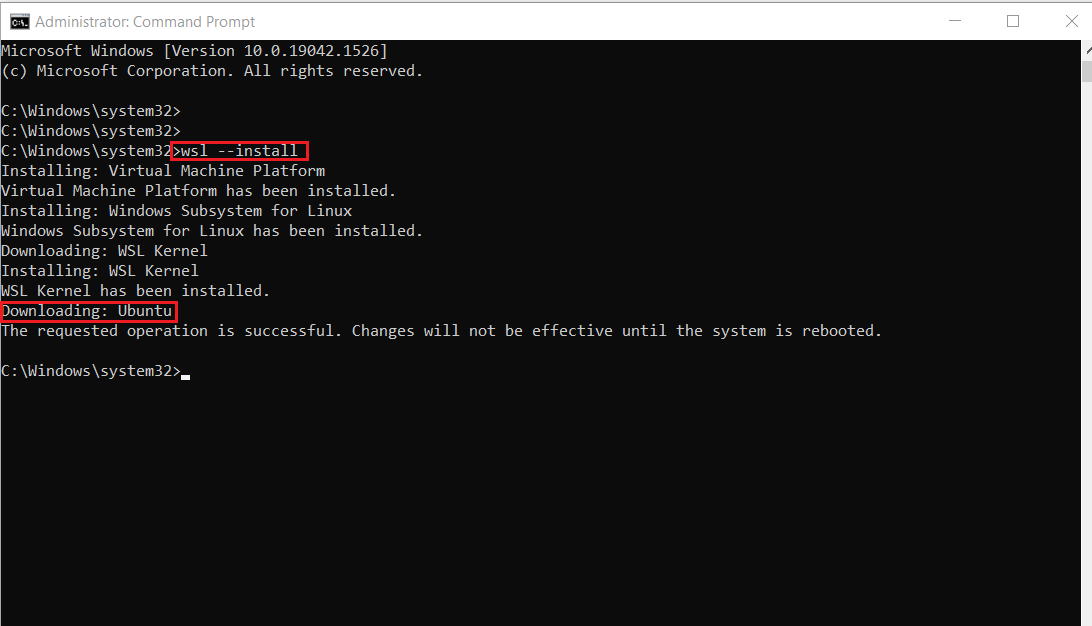
- Una volta completata l’installazione, dovrai riavviare il tuo computer Windows. Quindi, riavvia il tuo computer Windows.
Dopo il riavvio, potresti vedere una finestra come questa:
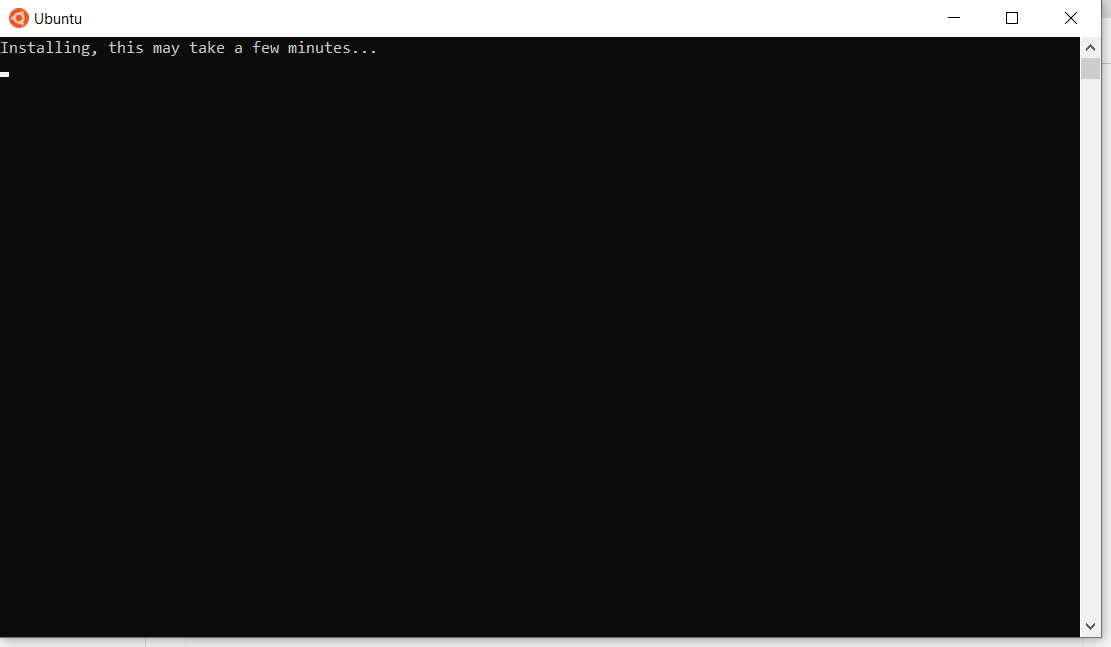
Una volta completata l’installazione di Ubuntu, verrai chiesto di inserire il tuo nome utente e la password.

Ecco questo! Sei pronto ad usare Ubuntu.
Lancia Ubuntu cercando dalla listade Start.
Ecco qui l’istanza di Ubuntu avviata.

Opzione 3: Usare una Macchina Virtuale (VM)
Una macchina virtuale (VM) è una emulazione software di un sistema informatico fisico. Permette di eseguire molti sistemi operativi e applicazioni su un singolo sistema fisico allo stesso tempo.
Puoi utilizzare software di virtualizzazione come Oracle VirtualBox o VMware per creare una macchina virtuale che esegue Linux all’interno dell’ambiente Windows. Ciò consente di eseguire Linux come sistema operativo ospite insieme a Windows.
I software per VM offrono opzioni per allocare e gestire risorse hardware per ogni VM, inclusi core CPU, memoria, spazio su disco e banda di rete. È possibile regolare queste allocazioni in base alle richieste dei sistemi operativi ospiti e delle applicazioni.
Ecco alcune delle opzioni comuni disponibili per la virtualizzazione:
Opzione 4: Utilizzare una Soluzione basata sul Browser
Le soluzioni basate sul browser sono particolarmente utili per le rapide prove, l’apprendimento o l’accesso agli ambienti Linux da dispositivi che non hanno installato Linux.
È possibile utilizzare editor di codice online o terminali web-based per accedere a Linux. Notare che in questi casi di solito non hai privilegi di amministrazione completi.
Editori di codice online
Gli editori di codice online offrono editori con terminali Linux integrati. Mentre la loro scopo primario è la programmazione, è anche possibile utilizzare il terminale Linux per eseguire comandi e svolgere attività.
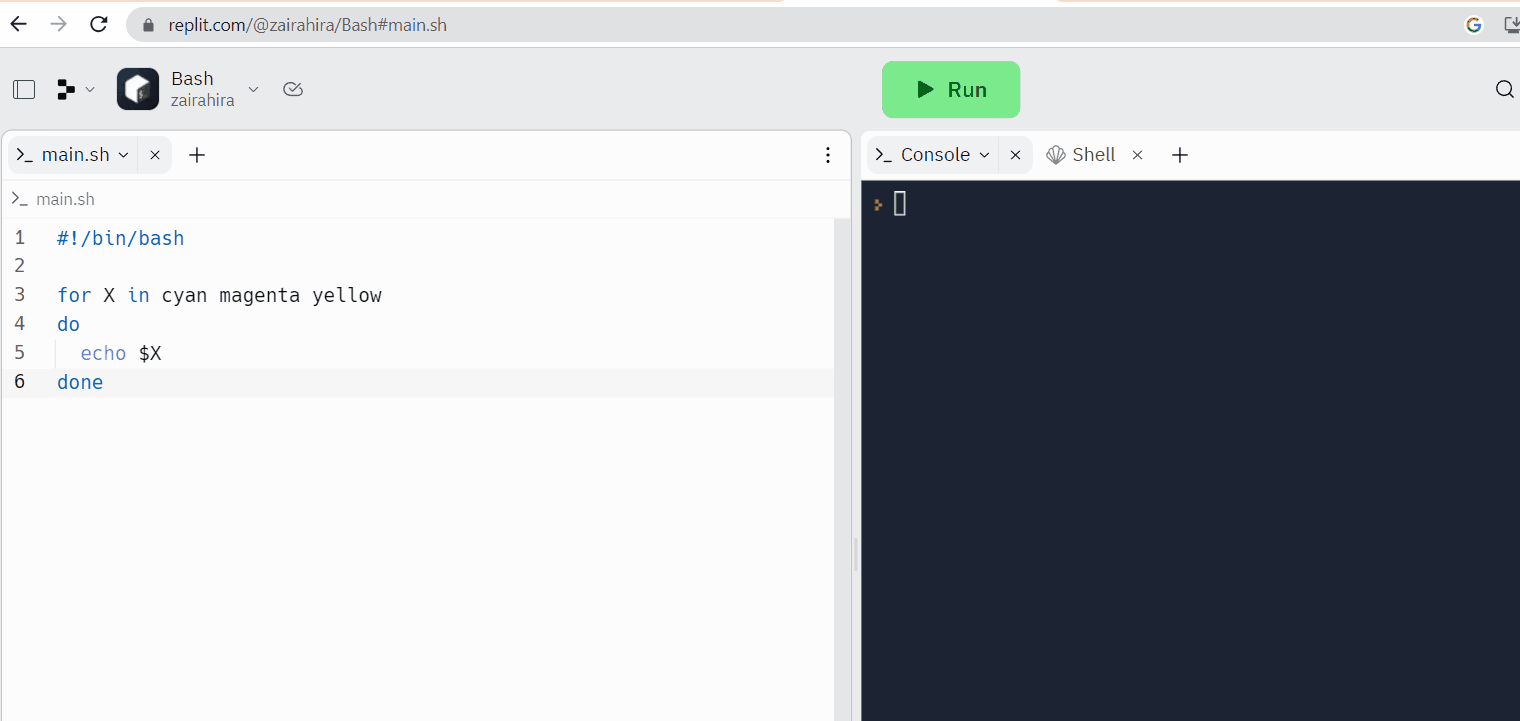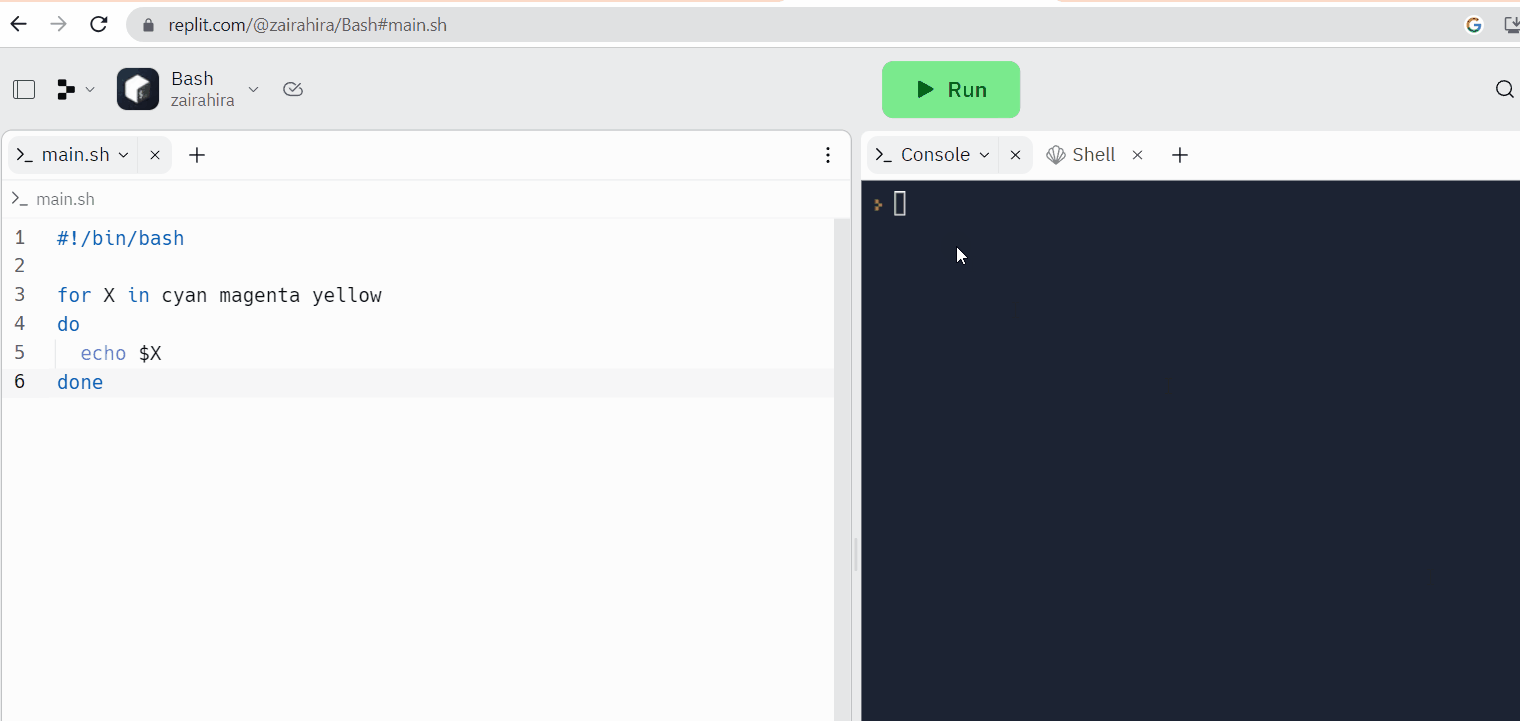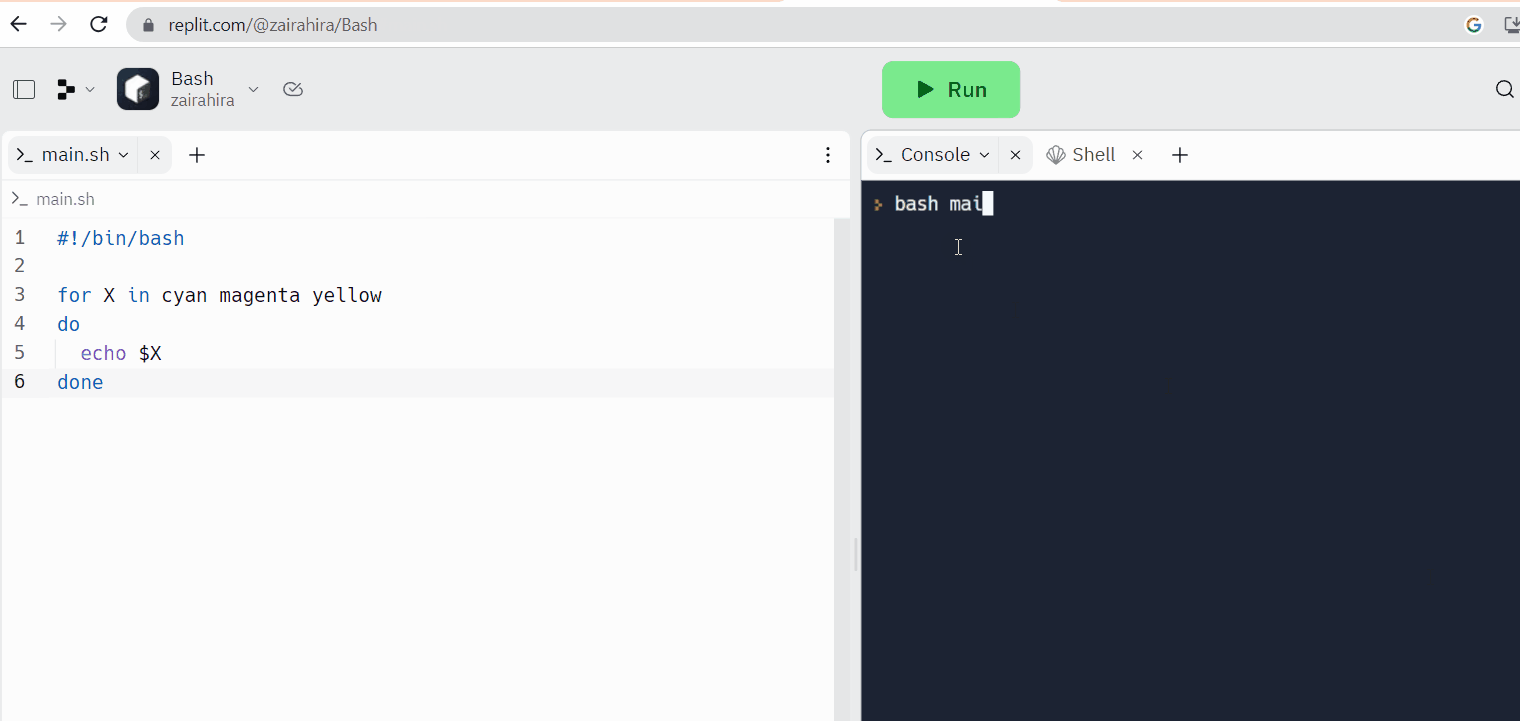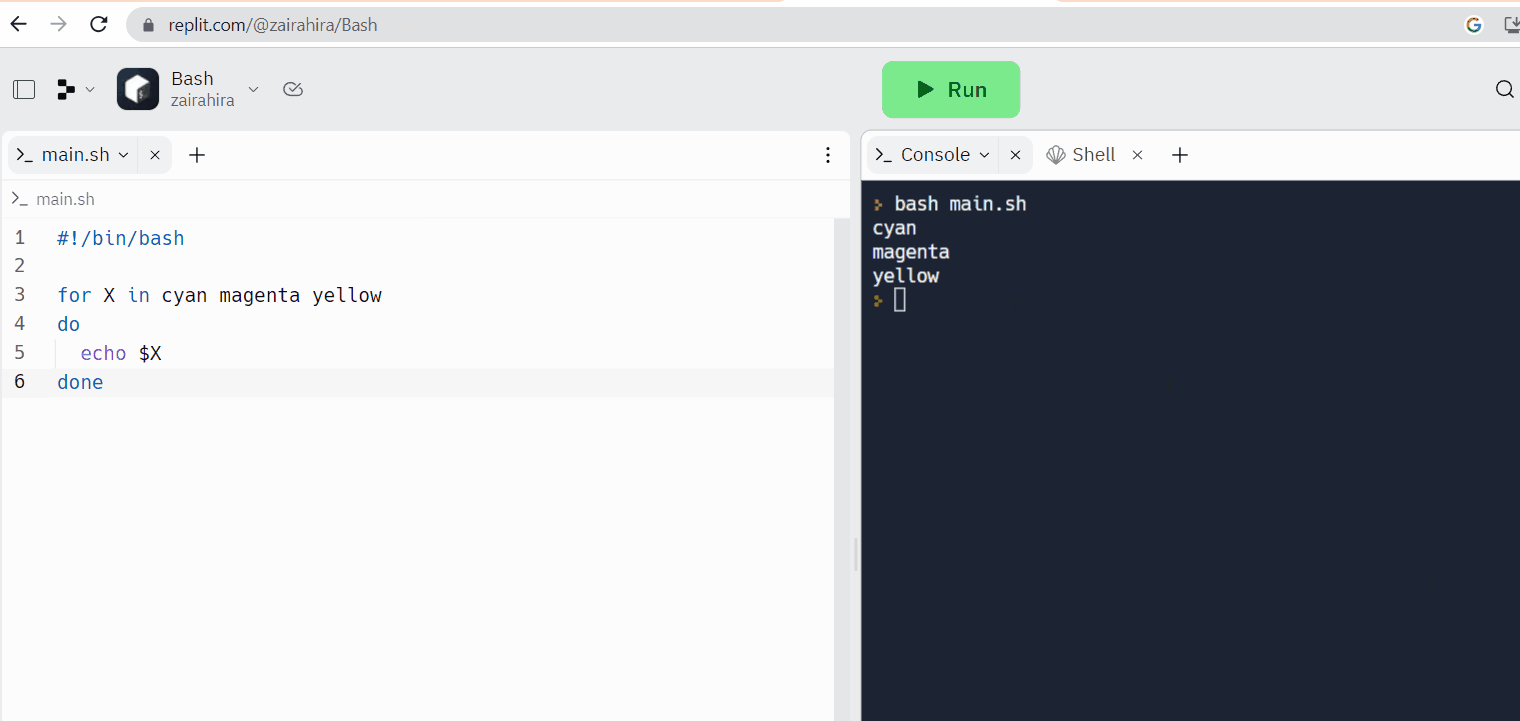
Replit è un esempio di editor di codice online in cui è possibile scrivere il proprio codice e accedere alla shell Linux nello stesso tempo.
Terminali Linux web-based:
I terminali Linux online consentono di accedere direttamente alla interfaccia a riga di comando Linux dalla vostra browser. Questi terminali forniscono una interfaccia web-based alla shell Linux, permettendo di eseguire comandi e lavorare con le utility Linux.
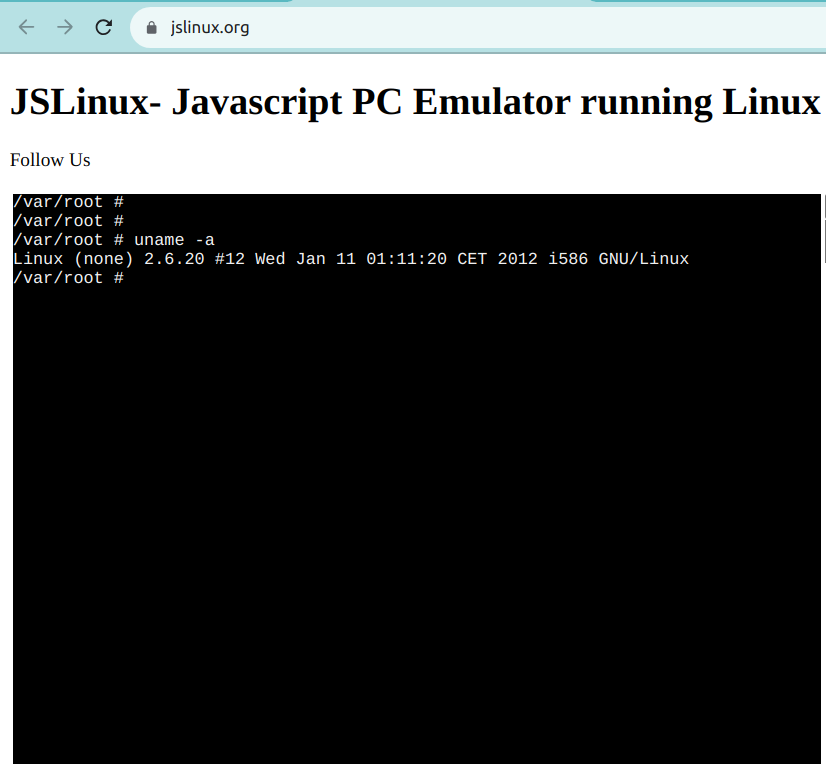
Un esempio di questo è JSLinux. La screenshot sottostante mostra un ambiente Linux pronto all’uso:
Opzione 5: Utilizza una Soluzione in Cloud
Invece di eseguire Linux direttamente sul tuo computer Windows, puoi considerare l’uso di ambienti Linux in cloud o server virtuali privati (VPS) per accedere e lavorare con Linux remoto.
Servizi come Amazon EC2, Microsoft Azure o DigitalOcean forniscono istanze Linux che puoi collegare dal tuo computer Windows. Notare che alcuni di questi servizi offrono piattaforme gratuite, ma non sono generalmente gratis a lungo termine.
Parte 2: Introduzione alla Shell Bash e ai Comandi di Sistema
2.1. Introduzione alla shell Bash
Introduzione alla shell Bash
Il comando della linea di comando di Linux è fornito da un programma chiamato shell. Negli anni, il programma della shell si è evoluto per offrire varie opzioni.
Utenti differenti possono essere configurati per utilizzare shell diverse. Tuttavia, la maggior parte degli utenti preferisce rimanere con la shell predefinita attuale. La shell predefinita per molte distribuzioni Linux è la GNU Bourne-Again Shell (bash). Bash è succeduto dalla shell Bourne (sh).
Per scoprire quale shell stai utilizzando attualmente, apri il tuo terminale e inserisci il seguente comando:
echo $SHELL
Breakdown del comando:
-
Il comando
echoviene usato per stampare sul terminale. -
La variabile speciale
$SHELLcontiene il nome della shell attuale.
Nella mia configurazione, l’output è /bin/bash. Questo significa che sto usando la shell bash.
# output
echo $SHELL
/bin/bash
Bash è molto potente in quanto può semplificare alcune operazioni che sono difficili da eseguire in modo efficiente con una GUI (o Interfaccia Grafica Utente). Ricorda che la maggior parte dei server non ha una GUI, e è meglio imparare ad usare le potenzialità di un’interfaccia a linea di comando (CLI).
Terminale vs Shell
I termini “terminale” e “shell” vengono spesso usati come sinonimi, ma si riferiscono a parti diverse dell’interfaccia a linea di comando.
Il terminale è l’interfaccia che usi per interagire con la shell. La shell è l’interprete di comandi che processa e esegue i tuoi comandi. Scoprirai di più riguardo alle shell nel Capitolo 6 del manuale.
Cos’è un prompt?
Quando una shell viene usata in maniera interattiva, mostra un $ quando aspetta un comando dall’utente. Questo si chiama il prompt della shell.
[username@host ~]$
Se la shell è in esecuzione come root (scoprirai di più riguardo all’utente root più avanti), il prompt viene cambiato in #.
[root@host ~]#
2.2 Struttura del Comando
Un comando è un programma che esegue una operazione specifica. Una volta che hai accesso alla shell, puoi inserire qualsiasi comando dopo il simbolo $ e vedere l’output sul terminale.
Di solito, i comandi Linux seguono questa sintassi:
command [options] [arguments]
Ecco il dettaglio della sintassi precedente:
-
comando: Questo è il nome del comando che vuoi eseguire.ls(lista),cp(copia) erm(rimuovi) sono comandi comuni di Linux. -
[opzioni]: Le opzioni, o flag, spesso precedute da un trattino (-) o un doppio trattino (–), modificano il comportamento del comando. Possono cambiare il modo in cui il comando opera. Ad esempio,ls -autilizza l’opzione-aper visualizzare i file nascosti nella directory corrente. -
[argomenti]: Gli argomenti sono gli input per i comandi che ne richiedono uno. Possono essere nomi di file, nomi utente o altri dati su cui il comando agirà. Ad esempio, nel comandocat access.log,catè il comando eaccess.logè l’input. Di conseguenza, il comandocatvisualizza il contenuto del fileaccess.log.
Opzioni e argomenti non sono richiesti per tutti i comandi. Alcuni comandi possono essere eseguiti senza opzioni o argomenti, mentre altri potrebbero richiederne uno o entrambi per funzionare correttamente. Puoi sempre fare riferimento al manuale del comando per verificare le opzioni e gli argomenti supportati.
Consiglio: Puoi visualizzare il manuale di un comando usando il comando man.
Puoi accedere alla pagina manuale per ls con man ls, e apparirà così:

Le pagine man sono un grande e veloce modo per accedere alla documentazione. Consiglio caldamente di consultare le pagine man per i comandi che usi più spesso.
2.3. Comandi Bash e Scorciatoie da Tastiera
Quando sei nel terminale, puoi accelerare i tuoi task usando le scorciatoie.
Ecco alcune delle scorciatoie più comuni nel terminale:
| Operazione | Scorciatoia |
| Cerca il comando precedente | Freccia su |
| Salta all’inizio della parola precedente | Ctrl+Freccia sinistra |
| Cancella i caratteri dal cursore alla fine della riga di comando | Ctrl+K |
| Completa comandi, nomi di file e opzioni | Premendo Tab |
| Salta all’inizio della riga di comando | Ctrl+A |
| Visualizza l’elenco dei comandi precedenti | history |
2.4. Identificarti: Il Comando whoami
Puoi ottenere il nome utente con cui sei loggato usando il comando whoami. Questo comando è utile quando stai passando tra diversi utenti e vuoi confermare l’utente corrente.
Subito dopo il segno $, digita whoami e premi enter.
whoami
Questo è l’output che ho ottenuto.
zaira@zaira-ThinkPad:~$ whoami
zaira
Parte 3: Comprendere il tuo sistema Linux
3.1. Scoprire il tuo OS e le specifiche
Stampa le informazioni di sistema usando il comando uname
Puoi ottenere informazioni dettagliate del sistema tramite il comando uname.
Quando fornisci l’opzione -a, stampa tutte le informazioni di sistema.
uname -a
# output
Linux zaira 6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
Nell’output sopra,
-
Linux: Indica il sistema operativo. -
zaira: Rappresenta il nome host della macchina. -
6.5.0-21-generic #21~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Fri Feb 9 13:32:52 UTC 2: Fornisce informazioni sulla versione del kernel, data di build e altri dettagli aggiuntivi. -
x86_64 x86_64 x86_64: Indica l’architettura del sistema. -
GNU/Linux: Rappresenta il tipo di sistema operativo.
Trova i dettagli sull’architettura della CPU usando il comando lscpu
Il comando lscpu in Linux viene utilizzato per visualizzare informazioni sull’architettura della CPU. Quando esegui lscpu nel terminale, fornisce dettagli come:
-
L’architettura della CPU (per esempio, x86_64)
-
Modalità di operazione CPU (per esempio, 32-bit, 64-bit)
-
Ordine dei byte (per esempio, Little Endian)
-
CPU(s) (numero di CPU), e così via
Proviamolo:
lscpu
# output
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 5 5500U with Radeon Graphics
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 1
CPU max MHz: 4056.0000
CPU min MHz: 400.0000
Questo è stato un bel po’ di informazioni, ma anche utili! Ricorda che puoi sempre sfogliare le informazioni rilevanti usando specifici flag. Guarda il manuale del comando con man lscpu.
Parte 4: Gestire i file dalla riga di comando
4.1. La gerarchia del file system in Linux
Tutti i file in Linux sono memorizzati in un file system.Segue una struttura ad albero rovesciato perché la radice si trova nella parte più alta.
Il / è la directory radice e il punto di partenza del file system. La directory radice contiene tutte le altre directory e file sul sistema. Il carattere / funge anche da separatore di directory tra i nomi dei percorsi. Per esempio, /home/alice forma un percorso completo.
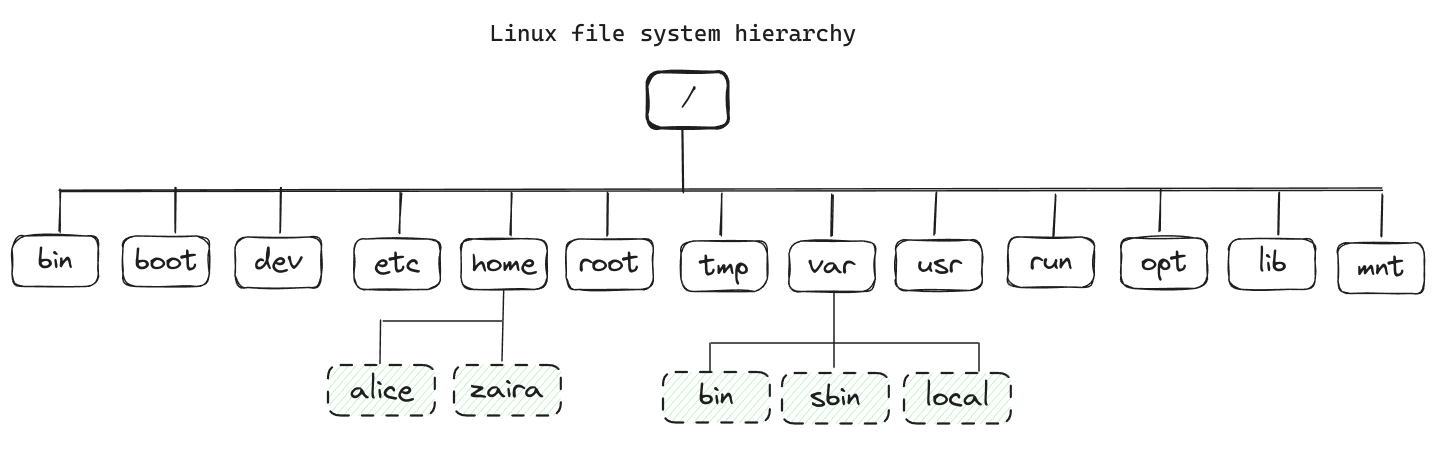
L’immagine sottostante mostra la gerarchia completa del filesystem. Ogni directory serve un scopo specifico.
Nota che questa non è una lista esaustiva e diverse distribuzioni potrebbero avere configurazioni differenti.
Ecco una tabella che mostra lo scopo di ogni directory:
| Posizione | Scopo |
| /bin | Binari di comandi essenziali |
| /boot | File statici del caricatore di boot, necessari per avviare il processo di avvio. |
| /etc | Configurazione del sistema specifica dell’host |
| /home | Cartelle home degli utenti |
| /root | Cartella home dell’utente amministrativo root |
| /lib | Librerie condivise essenziali e moduli del kernel |
| /mnt | Punto di mount per montare un filesystem temporaneamente |
| /opt | Pacchetti di software applicativi aggiuntivi |
| /usr | Software installato e librerie condivise |
| /var | Dati variabili persistenti tra avvii |
| /tmp | File temporanei accessibili a tutti gli utenti |
💡 Nota: Puoi imparare di più sul filesystem usando il comando man hier.
Puoi controllare il tuo filesystem usando il comando tree -d -L 1. Puoi modificare il flag -L per cambiare la profondità dell’albero.
tree -d -L 1
# output
.
├── bin -> usr/bin
├── boot
├── cdrom
├── data
├── dev
├── etc
├── home
├── lib -> usr/lib
├── lib32 -> usr/lib32
├── lib64 -> usr/lib64
├── libx32 -> usr/libx32
├── lost+found
├── media
├── mnt
├── opt
├── proc
├── root
├── run
├── sbin -> usr/sbin
├── snap
├── srv
├── sys
├── tmp
├── usr
└── var
25 directories
Questa lista non è esaustiva e differenti distribuzioni e sistemi potrebbero essere configurati in modo diverso.
4.2. Navigare nel file system Linux
Percorso assoluto contro percorso relativo
Il percorso assoluto è l’intero percorso dalla directory radice al file o alla directory. Comincia sempre con un /. Ad esempio, /home/john/documents.
Il percorso relativo, d’altro canto, è il percorso dalla directory corrente al file o alla directory di destinazione. Non comincia con un /. Ad esempio, documents/work/project.
Localizzare la directory corrente usando il comando pwd
È facile perdere la direzione nel file system Linux, specialmente se sei nuovo alla riga di comando. È possibile localizzare la directory corrente usando il comando pwd.
Ecco un esempio:
pwd
# output
/home/zaira/scripts/python/free-mem.py
Cambiare directory usando il comando cd
Il comando per cambiare directory è cd e sta per “change directory” (cambia directory). È possibile usare il comando cd per navigare in una directory diversa.
È possibile usare un percorso relativo o un percorso assoluto.
Ad esempio, se vuoi navigare nella seguente struttura file (seguendo le linee rosse):
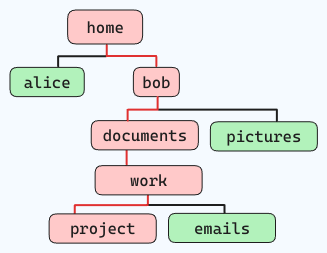
e sei situato in “home”, il comando sarà simile a questo:
cd home/bob/documents/work/project
Alcuni altri scorciatoie di comando cd di uso comune sono:
| Comando | Descrizione |
cd .. |
Torna in un directory precedente |
cd ../.. |
Torna in due directory precedenti |
cd o cd ~ |
Vai nella directory home |
cd - |
Vai nella precedente directory |
4.3. Gestione file e directory
Quando si lavora con file e directory, potrebbe essere necessario copiarli, spostarli, eliminarli e creare nuovi file e directory. Ecco alcuni comandi che potrebbero aiutarti in questo.
💡Nota: È possibile distinguere un file da una cartella guardando la prima lettera nell’output di ls -l. Un '-' rappresenta un file e un 'd' una cartella.
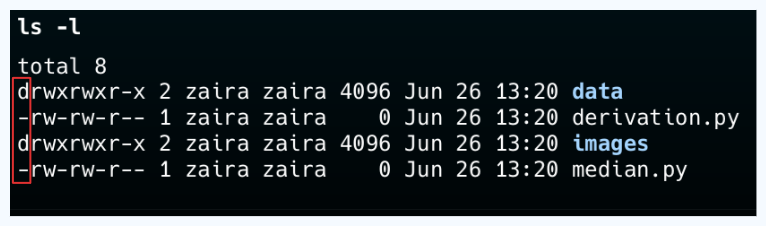
Creazione di nuove directory utilizzando il comando mkdir
È possibile creare una directory vuota utilizzando il comando mkdir.
# crea una directory vuota chiamata "foo" nella directory corrente
mkdir foo
È anche possibile creare directory ricorsivamente utilizzando l’opzione -p.
mkdir -p tools/index/helper-scripts
# output di tree
.
└── tools
└── index
└── helper-scripts
3 directories, 0 files
Creazione di nuovi file utilizzando il comando touch
Il comando touch crea un file vuoto. Puoi usarlo così:
# crea un file vuoto "file.txt" nella directory corrente
touch file.txt
I nomi di file possono essere concatenati se si vuole creare molti file in un singolo comando.
# Crea file vuoti "file1.txt", "file2.txt" e "file3.txt" nella cartella corrente
touch file1.txt file2.txt file3.txt
Rimuovere file e directory usando i comandi rm e rmdir
Puoi usare il comando rm per rimuovere sia file che directory non vuote.
| Comando | Descrizione |
rm file.txt |
Rimuove il file file.txt |
rm -r directory |
Rimuove la directory directory e i suoi contenuti |
rm -f file.txt |
Rimuove il file file.txt senza chiedere conferma |
rmdir directory |
Rimuove una directory vuota |
🛑 Notare che dovresti usare la flags -f con cautela in quanto non verrà richiesta una conferma prima di eliminare un file. Anche, bada con cura quando state eseguendo i comandi rm nella cartella root, in quanto potrebbe portare alla rimozione di file importanti del sistema.
Copiare file usando il comando cp
Per copiare file in Linux, usa il comando cp.
- Sintassi per copiare file:
cp source_file destination_of_file
Questo comando copia un file chiamato file1.txt in una nuova posizione file /home/adam/logs.
cp file1.txt /home/adam/logs
Il comando cp anche crea una copia di un file con il nome fornito.
Questo comando copia un file chiamato file1.txt in un altro file chiamato file2.txt nella stessa cartella.
cp file1.txt file2.txt
Spostare e rinominare file e cartelle usando il comando mv
Il comando mv viene utilizzato per spostare file e cartelle da una directory all’altra.
Sintassi per spostare file:mv file_sorgente directory_destinazione
Esempio: Sposta un file chiamato file1.txt in una cartella chiamata backup:
mv file1.txt backup/
Per spostare una directory e il suo contenuto:
mv dir1/ backup/
Rinominare file e cartelle in Linux viene fatto anche con il comando mv.
Sintassi per rinominare file:mv vecchio_nome nuovo_nome
Esempio: Rinomina un file da file1.txt a file2.txt:
mv file1.txt file2.txt
Rinomina una cartella da dir1 a dir2:
mv dir1 dir2
4.4. Localizzare File e Cartelle Usando il Comando find
Il comando find permette di cercare efficientemente file, cartelle, dispositivi a caratteri e a blocchi.
Di seguito la sintassi di base del comando find:
find /path/ -type f -name file-to-search
Dove,
-
/percorsoè il percorso in cui si presume che il file sia stato trovato. Questo è il punto di partenza per la ricerca dei file. Il percorso può anche essere/o.che rappresenta rispettivamente la radice e la directory corrente. -typerappresenta i descrittori di file. possono essere qualsiasi delle seguenti:
f– File normale come file di testo, immagini e file nascosti.
d– Directory. Queste sono le cartelle sotto considerazione.
l– Link simbolico. I link simbolici indicano file ed è simili ai collegamenti.
c– Dispositivo a caratteri. I file utilizzati per accedere ai dispositivi a caratteri sono chiamati file dispositivo a caratteri. I driver comunicano con i dispositivi a caratteri inviando e ricevendo singoli caratteri (byte, octetti). Esempi includono le tastiere, le schede audio e il mouse.
b– Dispositivo blocco. I file utilizzati per accedere ai dispositivi blocco sono chiamati file dispositivo blocco. I driver comunicano con i dispositivi blocco inviando e ricevendo blocchi di dati completi. Esempi includono USB e CD-ROM.-
-nameè il nome del tipo di file che si vuole cercare.
Come cercare file per nome o estensione
Supponiamo che ci serve trovare file che contengono “style” nel loro nome. Ushermo questo comando:
find . -type f -name "style*"
#output
./style.css
./styles.css
Adesso diciamo che vogliamo trovare file con una estensione particolare come .html. Modifichiamo il comando così:
find . -type f -name "*.html"
# output
./services.html
./blob.html
./index.html
Come cercare file nascosti
Un punto all’inizio del nome del file rappresenta i file nascosti. Normalmente sono nascosti, ma possono essere visualizzati con ls -a nella directory corrente.
Possiamo modificare il comando find come mostrato qui sotto per cercare file nascosti:
find . -type f -name ".*"
Elenco e ricerca di file nascosti
ls -la
# contenuti della cartella
total 5
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:17 .
drwxr-x--- 61 zaira zaira 4096 Mar 26 14:12 ..
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_history
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bash_logout
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:17 .bashrc
find . -type f -name ".*"
# output del find
./.bash_logout
./.bashrc
./.bash_history
Sopra potete vedere un elenco di file nascosti nella mia directory home.
Come cercare log e file di configurazione
I file di log hanno solitamente l’estensione .log e li possiamo trovare così:
find . -type f -name "*.log"
Allo stesso modo, possiamo cercare i file di configurazione così:
find . -type f -name "*.conf"
Come cercare altri file per tipo
Possiamo cercare i file a blocchi di caratteri fornendo c a -type:
find / -type c
Allo stesso modo, possiamo trovare i file a blocchi di dispositivo usando b:
find / -type b
Come cercare directory
Nell’esempio sotto, stiamo cercando le cartelle usando la bandiera -type d.
ls -l
# elenco contenuti cartella
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 hosts
-rw-rw-r-- 1 zaira zaira 0 Mar 26 14:23 hosts.txt
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 images
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:23 style
drwxrwxr-x 2 zaira zaira 4096 Mar 26 14:22 webp
find . -type d
# output directory find
.
./webp
./images
./style
./hosts
Come cercare file per dimensione
Un uso incredibilmente utile del comando find è quello di elencare file in base a una dimensione specifica.
find / -size +250M
Qui, stiamo elencando file la cui dimensione supera i 250MB.
Altre unità includono:
-
G: GigaBytes. -
M: MegaByte. -
K: KiloByte -
c: byte.
Basta sostituire con l’unità pertinente.
find <directory> -type f -size +N<Unit Type>
Come cercare i file in base al tempo di modifica
Utilizzando il flag -mtime, è possibile filtrare file e cartelle in base al tempo di modifica.
find /path -name "*.txt" -mtime -10
Ad esempio,
-
-mtime +10 significa che si sta cercando un file modificato 10 giorni fa.
-
-mtime -10 significa meno di 10 giorni.
-
-mtime 10 Se si salta il + o il – significa esattamente 10 giorni.
4.5. Comandi di base per la visualizzazione dei file
Concatenare e visualizzare i file usando il comando cat
Il comando cat in Linux è usato per visualizzare il contenuto di un file. Può anche essere usato per concatenare file e crearne di nuovi.
Ecco la sintassi di base del comando cat:
cat [options] [file]
Il modo più semplice di usare cat è senza opzioni o argomenti. In questo modo viene visualizzato il contenuto del file sul terminale.
Ad esempio, se vuoi visualizzare il contenuto di un file chiamato file.txt, puoi usare il seguente comando:
cat file.txt
Questo mostrerà tutti i contenuti del file all’interno del terminale contemporaneamente.
Per visualizzare i file di testo in modo interattivo usando less e more
Mentre cat mostra l’intero file in una sola volta, less e more ti consentono di visualizzare il contenuto di un file in modo interattivo. È utile quando vuoi scorrere attraverso un file grande o cercare contenuti specifici.
La sintassi del comando less è la seguente:
less [options] [file]
Il comando more è simile a less ma ha meno funzionalità. Viene utilizzato per visualizzare il contenuto di un file a schermo intero.
La sintassi del comando more è la seguente:
more [options] [file]
Per entrambi i comandi, puoi utilizzare la barra spaziatrice per scorrere di una pagina in basso, la tastiera per scorrere di una riga in basso e la tastatura per uscire dall’visualizzatore.
Per muoverti indietro puoi usare la tastiera, e per muoverti avanti puoi usare la tastiera.
Visualizzazione dell’ultima parte dei file usando tail
A volte potrebbe servire solo per visualizzare le ultime righe di un file invece di tutto il file. Il comando tail in Linux viene utilizzato per visualizzare l’ultima parte di un file.
Ad esempio, tail file.txt mostrerà di default le ultime 10 righe del file file.txt.
Se vuoi visualizzare un numero diverso di righe, puoi usare l’opzione -n seguita dal numero di righe che vuoi visualizzare.
# Visualizza le ultime 50 righe del file file.txt
tail -n 50 file.txt
💡Nota: Un’altra utilità del comando tail è l’opzione in streaming (-f). Questa opzione ti consente di visualizzare il contenuto di un file mentre viene scritto. È una utilità utile per la visualizzazione e il monitoraggio di file di log in tempo reale.
Visualizzazione dell’inizio dei file usando head
Come tail visualizza la parte finale di un file, puoi usare il comando head in Linux per visualizzare l’inizio di un file.
Ad esempio, head file.txt visualizzerà le prime 10 righe del file file.txt per impostazione predefinita.
Per cambiare il numero di righe visualizzate, puoi usare l’opzione -n seguita dal numero di righe che vuoi visualizzare.
Conteggio di parole, righe e caratteri usando wc
Puoi contare parole, righe e caratteri in un file usando il comando wc.
Ad esempio, l’esecuzione di wc syslog.log mi ha dato l’output seguente:
1669 9623 64367 syslog.log
Nell’output sopra,
-
1669rappresenta il numero di righe nel filesyslog.log. -
9623rappresenta il numero di parole nel filesyslog.log. -
64367rappresenta il numero di caratteri nel filesyslog.log.
Quindi, il comando wc syslog.log ha contato 1669 righe, 9623 parole, e 64367 caratteri nel file syslog.log.
Confrontare i file riga per riga usando diff
Confrontare e trovare le differenze tra due file è un’attività comune in Linux. Puoi confrontare due file direttamente dalla riga di comando usando il comando diff.
La sintassi di base del comando diff è:
diff [options] file1 file2
Ecco due file, hello.py e also-hello.py, che confronteremo usando il comando diff:
# contenuto di hello.py
def greet(name):
return f"Hello, {name}!"
user = input("Enter your name: ")
print(greet(user))
# contenuto di also-hello.py
more also-hello.py
def greet(name):
return fHello, {name}!
user = input(Enter your name: )
print(greet(user))
print("Nice to meet you")
- Controlla se i file sono gli stessi o meno
diff -q hello.py also-hello.py
# Output
Files hello.py and also-hello.py differ
- Vedere come i file differiscono. Per questo, puoi usare l’opzione
-uper vedere un output unificato:
diff -u hello.py also-hello.py
--- hello.py 2024-05-24 18:31:29.891690478 +0500
+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500
@@ -3,4 +3,5 @@
user = input(Enter your name: )
print(greet(user))
+print("Nice to meet you")
— hello.py 2024-05-24 18:31:29.891690478 +0500
- Nell’output sopra:
--- hello.py 2024-05-24 18:31:29.891690478 +0500indica il file in confronto e la sua data e ora.+++ also-hello.py 2024-05-24 18:32:17.207921795 +0500indica l’altro file in confronto e la sua data e ora.@@ -3,4 +3,5 @@mostra le linee in cui si verificano le modifiche. In questo caso, indica che le righe 3 e 4 del file originale sono state modificate in righe 3 e 5 del file modificato.user = input(Enter your name: )è una riga dal file originale.print(greet(user))è un’altra riga dal file originale.
+print("Nice to meet you")è una riga aggiunta nel file modificato.
diff -y hello.py also-hello.py
Per visualizzare il diff in un formato side-by-side, puoi usare il flag -y:
def greet(name): def greet(name):
return fHello, {name}! return fHello, {name}!
user = input(Enter your name: ) user = input(Enter your name: )
print(greet(user)) print(greet(user))
> print("Nice to meet you")
# Output
- Nell’output:
- Le righe uguali in entrambi i file sono visualizzate fianco a fianco.
Le righe diverse sono mostrate con un simbolo > che indica che la riga è presente solo in uno dei file.
Capitolo 5: Gli elementi essenziali della modifica di testo in Linux
La capacità di modificare testi usando la riga di comando è una delle competenze più importanti in Linux. In questa sezione, imparerai a usare due popolari editor di testo in Linux: Vim e Nano.
Consiglio di padroneggiare un qualsiasi editor di testo a tua scelta e di adottarlo. Ti farà risparmiare tempo e renderà più produttivo. Vim e nano sono scelte sicure poiché sono presenti sulla maggior parte delle distribuzioni Linux.
5.1. Padronanza di Vim: La guida completa
Introduzione a Vim
- Vim è uno strumento popolare per la modifica di testo nella riga di comando. Vim ha le sue peculiarità: è potente, personalizzabile e veloce. Ecco alcuni motivi per cui dovresti considerare di imparare Vim:
- La maggior parte dei server viene accessibile tramite CLI, quindi nell’amministrazione di sistema, non avrai necessariamente il lusso di una GUI. Ma Vim ha il tuo supporto – sarà sempre lì.
- Alcune utility di Linux, ad esempio l’editing delle attività cron, lavorano nello stesso formato di editing di Vim.
Vim è adatto a tutti – principianti e utenti avanzati. Vim supporta ricerche di stringhe complesse, evidenziazione delle ricerche e molto di più. Grazie ai plugin, Vim offre funzionalità estese agli sviluppatori e agli amministratori di sistema, incluse la completamento del codice, l’evidenziazione della sintassi, la gestione dei file, il controllo della versione, e altro.
Vim ha due varianti: Vim (vim) e Vim tiny (vi). Vim tiny è una versione più piccola di Vim che manca di alcune caratteristiche di Vim.
Come iniziare a usare vim
vim your-file.txt
Inizia a usare Vim con questo comando:
your-file.txt può essere un nuovo file o un file esistente che vuoi modificare.
Navigando in Vim: padroneggiare i movimenti e i modalità di comando
Nell’era iniziale della CLI, i tastieri non avevano tasti freccia. Quindi, la navigazione veniva fatta usando l’insieme di tasti disponibili, hjkl tra questi.
Essendo incentrato sul tastiera, l’uso dei tasti hjkl può notevolmente accelerare le attività di modifica del testo.
Nota: Anche se i tasti freccia funzionerebbero abbastanza bene, puoi ancora sperimentare con i tasti hjkl per navigare. Alcune persone trovano questa modalità di navigazione efficiente.

💡Consiglio: Per ricordare la sequenza hjkl, usa questo: hang back, jump down, kick up, leap forward.
I tre modalità di Vim
- Devi conoscere le tre modalità operative di Vim e come passare da una all’altra. I tasti funzionano diversamente in ciascuna modalità di comando. Le tre modalità sono le seguenti:
- Modalità comando.
- Modalità modifica.
Modalità visuale.
Modalità Comando. Quando avvii Vim, sei in modalità comando di default. Questa modalità ti permette di accedere ad altre modalità.
⚠ Per passare ad altre modalità, devi prima essere nella modalità comando
Modalità Modifica
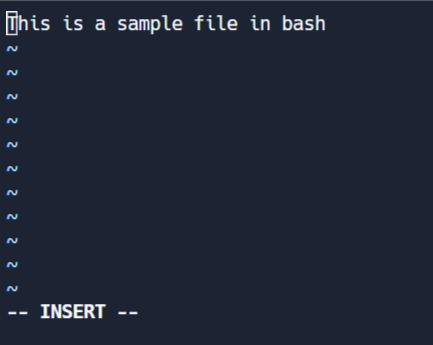
Questa modalità ti permette di fare modifiche al file. Per entrare in modalità modifica, premi I mentre sei in modalità comando. Nota il cambiamento a ‘-- INSERT' in fondo allo schermo.
Modalità visuale
- Questa modalità ti consente di lavorare su un singolo carattere, un blocco di testo o righe di testo. Scolleghiamo questo concetto in semplici passaggi. ricorda, usa le combinazioni riportate di seguito quando sei in modalità comando.
Shift + V→ Seleziona più righe.Ctrl + V→ Modalità blocco
V → Modalità carattere
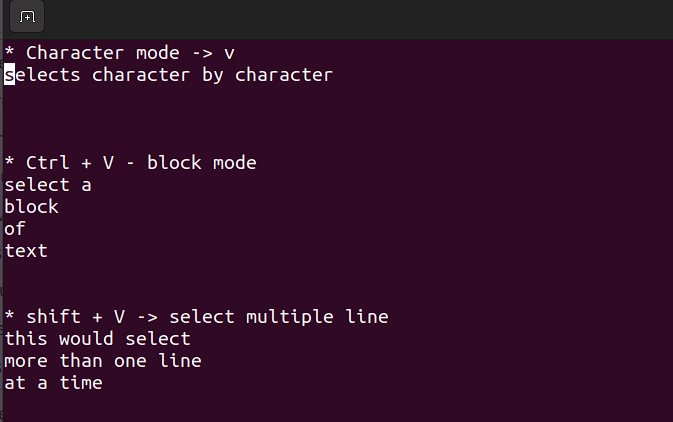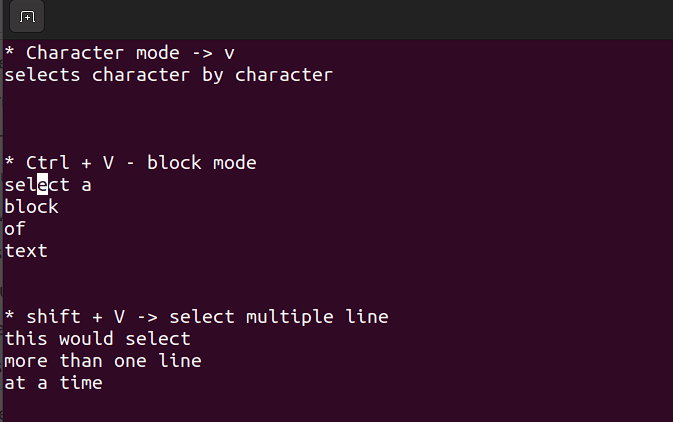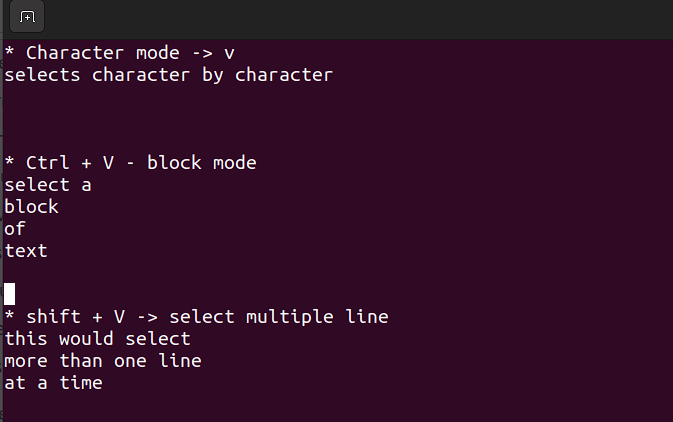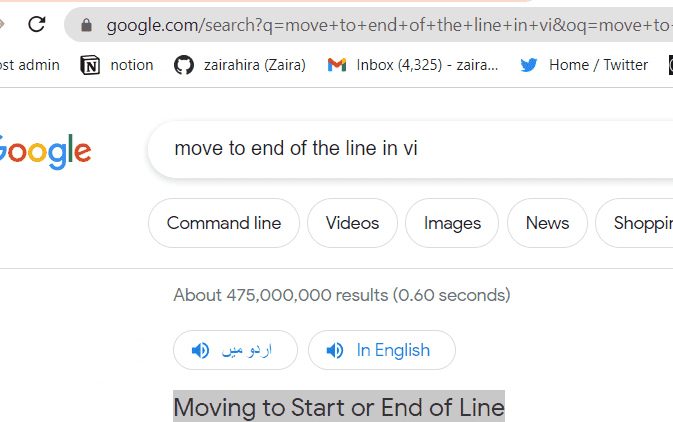
La modalità visuale è utile quando hai bisogno di copiare, incollare o modificare righe in blocco.
Modalità comando estesa.
La modalità comando estesa ti consente di eseguire operazioni avanzate come la ricerca, impostare i numeri di riga e evidenziare il testo. Vedremo l’uso della modalità estesa nella sezione successiva.
Come rimanere sulla strada? Se dimentichi la tua modalità corrente, premi solo ESC due volte e tornerai nella Modalità Comando.
Modifica efficiente in Vim: Copia/incolla e ricerca
1. Come copiare e incollare in Vim
- Copia-incolla viene chiamato ‘yank’ e ‘put’ nei termini Linux. Per copiare e incollare, segui questi passaggi:
- Seleziona il testo in modalità visuale.
- Premi
'y'per copiare/yank.
Muovi il cursore alla posizione desiderata e premi 'p'.
2. Come cercare testo in Vim
In Vim è possibile cercare qualsiasi serie di stringhe usando il carattere / nella modalità comando. Per cercare, digita /stringa-da-cercare.
Nella modalità comando, digita :set hls e premi enter. Cerca usando /stringa-da-cercare. Questo evidenzierebbe le ricerche.
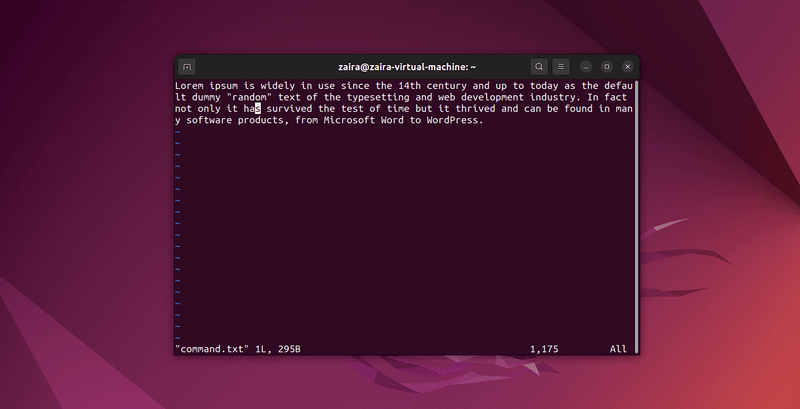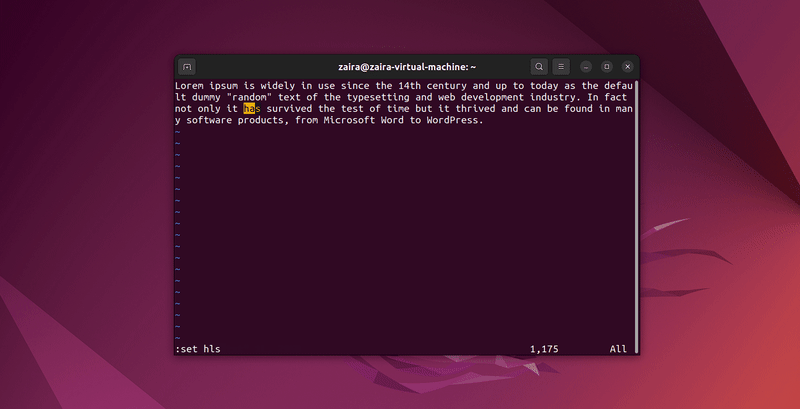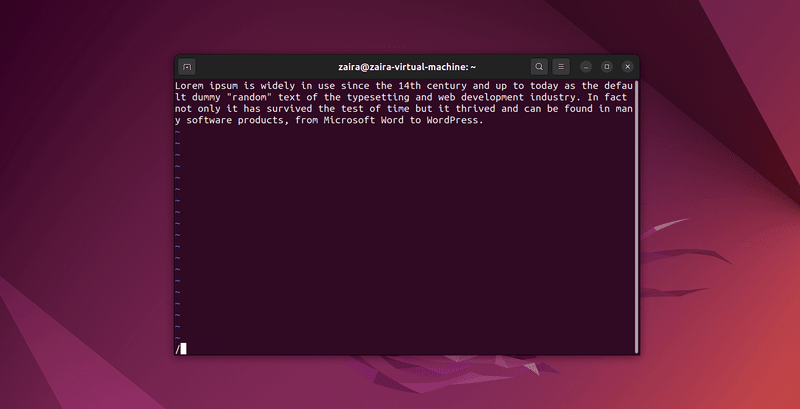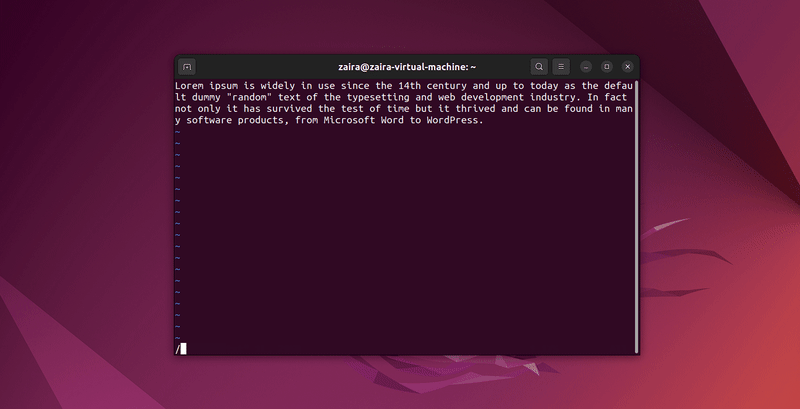
Proviamo a cercare alcune stringhe:
3. Come uscire da Vim
- Prima, passa alla modalità comando (premendo due volte la barra di scorrimento) e quindi usa questi comandi:
- Esci senza salvare →
:q!
Esci e salva → :wq!
Scorciatoie in Vim: Modificare più velocemente
- Nota: Tutte queste scorciatoie funzionano solo nella modalità comando.
Ctrl+u: Vai su di mezza paginaP: Incollare sopra il cursore:%s/old/new/g: Sostituisci tutte le occorrenze dioldconnewnel file:q!: Esci senza salvare
Ctrl+w seguito da h/j/k/l: Naviga tra le finestre divise
5.2. padroneggiare Nano
Cominciare con Nano: L’editor di testo user-friendly
Nano è un editor di testo user-friendly facile da usare e perfetto per i principianti. È preinstallato nella maggior parte delle distribuzioni Linux.
nano
Per creare un nuovo file usando Nano, usa il seguente comando:
nano filename
Per iniziare a modificare un file esistente con Nano, usa il seguente comando:
Elenco delle scorciatoie da tastiera in Nano
Studiamo le scorciatoie da tastiera più importanti in Nano. Userai queste scorciatoie per eseguire varie operazioni come salvare, uscire, copiare, incollare, e altro.
Scrivi in un file e salvalo
Una volta aperto Nano usando il comando nano, puoi iniziare a scrivere il testo. Per salvare il file, premi Ctrl+O. Ti verrà chiesto di inserire il nome del file. Premi Invio per salvare il file.
Uscire da nano
Puoi uscire da Nano premendo Ctrl+X. Se hai cambiamenti non salvati, Nano ti chiederà se salvare le modifiche prima di uscire.
Copiare e incollare
Per selezionare una regione, usa ALT+A. Un marcatore apparirà. Usa le frecce per selezionare il testo. Una volta selezionato, esci dal marcatore con ALT+^.
Per copiare il testo selezionato, premi Ctrl+K. Per incollare il testo copiato, premi Ctrl+U.
Tagliare e incollare
Seleziona la regione con ALT+A. Una volta selezionato, taglia il testo con Ctrl+K. Per incollare il testo tagliato, premi Ctrl+U.
Navigazione
Usa Alt \ per spostarti all’inizio del file.
Usa Alt / per spostarti alla fine del file.
Visualizzare i numeri di riga
Quando apri un file con nano -l filename, puoi visualizzare i numeri di riga sul lato sinistro del file.
Ricerca
Puoi cercare una specifica riga numero con ALt + G. Inserisci il numero di riga nella richiesta e premi Invio.
Puoi anche avviare la ricerca di una stringa con CTRL + W e premere Enter. Se vuoi cercare all’indietro, puoi premere Alt+W dopo aver avviato la ricerca con Ctrl+W.
- RIassunto delle scorciatoie da tastiera in Nano
Ctrl+G: Mostra il testo di aiutoCtrl+J: Justifica il paragrafo correnteCtrl+V: Scorri in basso di una paginaCtrl+\: Cerca e sostituisce
Alt+E: Ripeti l’ultima operazione annullata
Parte 6: Bash Scripting
6.1. Definizione dello scripting Bash
Uno script bash è un file che contiene una sequenza di comandi eseguiti linea per linea dal programma bash. Consente di eseguire una serie di azioni, come spostarsi in una directory specifica, creare una cartella e lanciare un processo usando la riga di comando.
Salvando i comandi in un script, è possibile ripetere la stessa sequenza di step multipli volte e eseguirli facendo partire il script.
6.2 Vantaggi dell’Scripting Bash
L’scripting Bash è una potente e versatile工具 per automatizzare le attività di amministrazione del sistema, gestire le risorse del sistema e svolgere altre attività routine negli sistemi Unix/Linux.
- Alcuni vantaggi dell’scripting della shell sono:
- Automazione: Gli script di shell consentono di automatizzare attività e processi ripetuti, risparmiando tempo e riducendo il rischio di errori che può verificarsi con l’esecuzione manuale.
- Portabilità: Gli script di shell possono essere eseguiti su varie piattaforme e sistemi operativi, inclusi Unix, Linux, macOS, e persino Windows attraverso l’uso di emulatori o macchine virtuali.
- Flexibilità: I script di shell sono altamente personalizzabili e possono essere facilmente modificati per soddisfare specifiche esigenze. Possono anche essere combinati con altri linguaggi di programmazione o utilità per creare script più potenti.
- Accessibilità: I script di shell sono facili da scrivere e non richiedono strumenti o software speciali. Possono essere modificati usando qualsiasi editor di testo, e la maggior parte dei sistemi operativi ha un interprete di shell integrato.
- Integrazione: I script di shell possono essere integrati con altri strumenti e applicazioni, come database, server web e servizi cloud, consentendo compiti di automazione e gestione di sistemi più complessi.
Debugging: I script di shell sono facili da debuggare, e la maggior parte delle shell ha strumenti di debug e di segnalazione degli errori integrati che aiutano a identificare e risolvere rapidamente i problemi.
6.3. Panoramica di Bash Shell e dell’Interfaccia a Linea di Comando
Il termine “shell” e “bash” sono spesso usati in modo intercambiabile. Ma c’è una sottile differenza tra i due.
Il termine “shell” si riferisce a un programma che fornisce un’interfaccia a riga di comando per interagire con un sistema operativo. Bash (Bourne-Again SHell) è uno degli shell Unix/Linux più comunemente usati ed è lo shell predefinito in molte distribuzioni Linux.
Fino ad ora, i comandi che hai inserito sono stati essenzialmente inseriti in un “shell”.
Sebbene Bash sia un tipo di shell, ci sono altri shell disponibili anche, come Korn shell (ksh), C shell (csh), e Z shell (zsh). Ogni shell ha la sua propria sintassi e insieme di funzionalità, ma condividono l’obiettivo comune di fornire un’interfaccia a riga di comando per interagire con il sistema operativo.
ps
# output:
PID TTY TIME CMD
20506 pts/0 00:00:00 bash <--- the shell type
20931 pts/0 00:00:00 ps
Puoi determinare il tuo tipo di shell usando il comando ps:
In sintesi, mentre “shell” è un termine generale che si riferisce a qualsiasi programma che fornisce un’interfaccia a riga di comando, “Bash” è un tipo specifico di shell ampiamente utilizzato nei sistemi Unix/Linux.
Nota: In questa sezione, useremo lo shell “bash”.
6.4. Come creare ed eseguire script Bash
Convenzioni di denominazione degli script
Secondo le convenzioni di denominazione, gli script bash terminano con .sh. Tuttavia, gli script bash possono funzionare perfettamente anche senza l’estensione sh.
Aggiungere lo Shebang
Gli script Bash iniziano con un shebang. Shebang è una combinazione di bash # e bang ! seguito dal percorso della shell di bash. Questa è la prima riga dello script. Shebang indica alla shell di eseguirlo tramite la shell di bash. Shebang è semplicemente un percorso assoluto per l’interprete di bash.
#!/bin/bash
Di seguito è riportato un esempio dell’istruzione shebang.
which bash
Puoi trovare il percorso della tua shell di bash (che potrebbe variare da quello sopra) utilizzando il comando:
Creazione del tuo primo script bash
Il nostro primo script richiede all’utente di inserire un percorso. In cambio, verranno elencati i suoi contenuti.
vim run_all.sh
Crea un file chiamato run_all.sh utilizzando un editor a tua scelta.
#!/bin/bash
echo "Today is " `date`
echo -e "\nenter the path to directory"
read the_path
echo -e "\n you path has the following files and folders: "
ls $the_path
Aggiungi i seguenti comandi nel tuo file e salvalo:
1 Diamo uno sguardo più approfondito allo script riga per riga. Sto visualizzando lo stesso script di nuovo, ma questa volta con i numeri di riga.
2 echo "Today is " `date`
3
4 echo -e "\nenter the path to directory"
5 read the_path
6
7 echo -e "\n you path has the following files and folders: "
8 ls $the_path
- #!/bin/bash
- Riga n. 1: Il shebang (
#!/bin/bash) punta al percorso della shell di bash. - Riga n. 2: Il comando
echovisualizza la data e l’ora correnti sul terminale. Nota che ladateè tra apici inversi. - Riga n. 4: Vogliamo che l’utente inserisca un percorso valido.
- Riga n. 5: Il comando
readlegge l’input e lo memorizza nella variabilethe_path.
Riga n. 8: Il comando ls prende la variabile con il percorso memorizzato e mostra i file e le cartelle correnti.
Esecuzione dello script bash
chmod u+x run_all.sh
Per rendere lo script eseguibile, assegna i diritti di esecuzione al tuo utente usando questo comando:
- Qui,
chmodmodifica la proprietà di un file per l’utente corrente:u.+xaggiunge i diritti di esecuzione all’utente corrente. Ciò significa che l’utente che è il proprietario può ora eseguire lo script.
run_all.sh è il file che desideriamo eseguire.
- Puoi eseguire lo script utilizzando uno dei metodi menzionati:
sh run_all.shbash run_all.sh
./run_all.sh
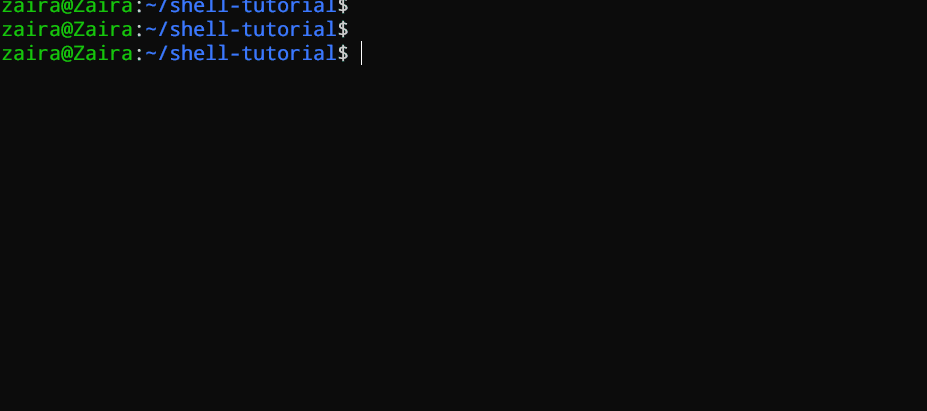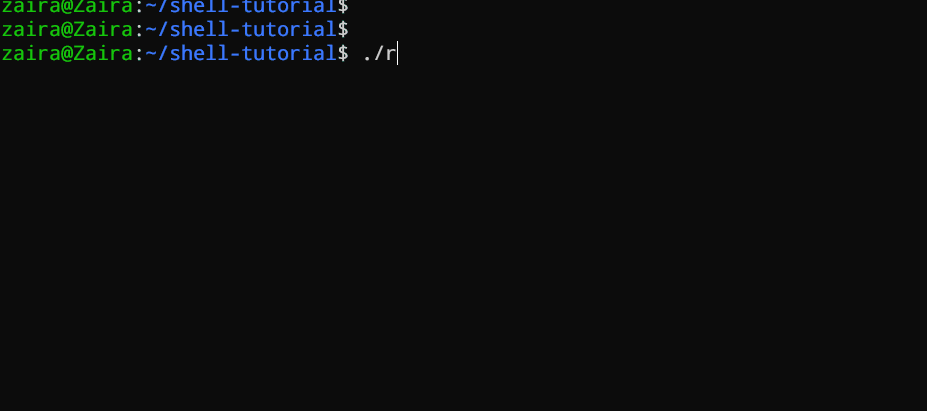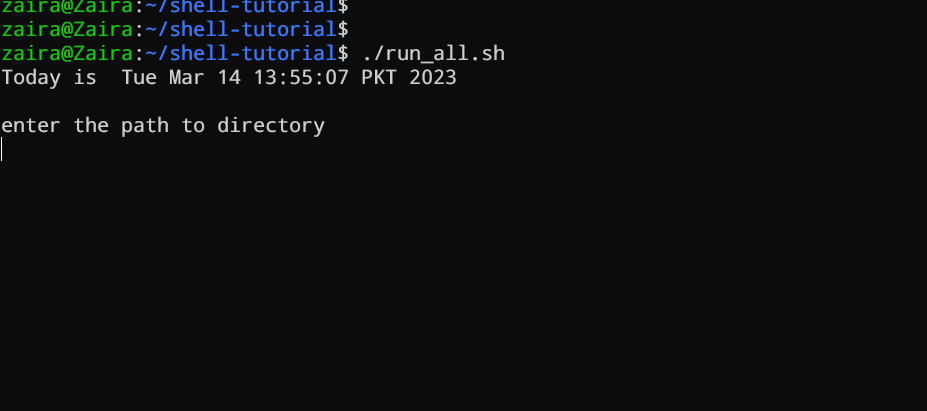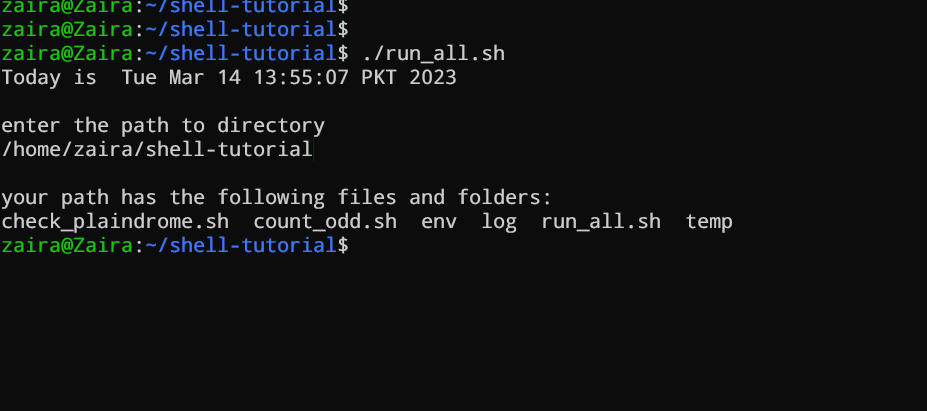
Vediamo come funziona in azione 🚀
6.5. Fondamenti dello scripting di Bash
Commenti nello scripting di Bash
I commenti iniziano con un # nello scripting di Bash. Ciò significa che qualsiasi riga che inizia con un # è un commento e sarà ignorata dall’interprete.
I commenti sono molto utili per documentare il codice ed è una buona pratica aggiungerli per aiutare gli altri a capire il codice.
Ecco alcuni esempi di commenti:
# Questo è un esempio di commento
# Entrambe queste righe saranno ignorate dall’interprete
Variabili e tipi di dati in Bash
Le variabili ti permettono di memorizzare dati. Puoi usare le variabili per leggere, accedere e manipolare dati nel tuo script.
In Bash non ci sono tipi di dati. In Bash, una variabile è in grado di memorizzare valori numerici, singoli caratteri o stringhe di caratteri.
- In Bash, puoi utilizzare e impostare i valori delle variabili nei seguenti modi:
country=Netherlands
Assegnare il valore direttamente:
same_country=$country
2. Assegnare il valore in base all’output ottenuto da un programma o comando, utilizzando la sostituzione dei comandi. Nota che è necessario utilizzare il simbolo $ per accedere al valore di una variabile esistente.
Questo assegna il valore di country alla nuova variabile same_country.
country=Netherlands
echo $country
Per accedere al valore di una variabile, aggiungi $ al nome della variabile.
Netherlands
new_country=$country
echo $new_country
# output
Netherlands
# output
Qui sopra, puoi vedere un esempio di assegnazione e stampa dei valori di variabili.
Convenzioni per la denominazione delle variabili
- Nello scripting Bash, si seguono le seguenti convenzioni per la denominazione delle variabili:
- I nomi delle variabili devono iniziare con una lettera o un underscore (
_). - I nomi delle variabili possono contenere lettere, numeri, e underscore (
_). - I nomi delle variabili sono sensibili alle maiuscole e alle minuscole.
- I nomi delle variabili non dovrebbero contenere spazi o caratteri speciali.
- Usa nomi descrittivi che riflettono lo scopo della variabile.
Evita di usare parole riservate, come if, then, else, fi, e così via come nomi di variabili.
name
count
_var
myVar
MY_VAR
Di seguito alcuni esempi di nomi di variabili validi in Bash:
E qui alcuni esempi di nomi di variabili non validi:
2ndvar (variable name starts with a number)
my var (variable name contains a space)
my-var (variable name contains a hyphen)
# nomi di variabili non validi
Seguire queste convenzioni di denominazione aiuta a rendere gli script Bash più leggibili e più facili da mantenere.
Input e output negli script Bash
Raccolta dati in input
- In questa sezione, discuteremo alcuni metodi per fornire input ai nostri script.
Leggere l’input dell’utente e memorizzarlo in una variabile
#!/bin/bash
echo "What's your name?"
read entered_name
echo -e "\nWelcome to bash tutorial" $entered_name
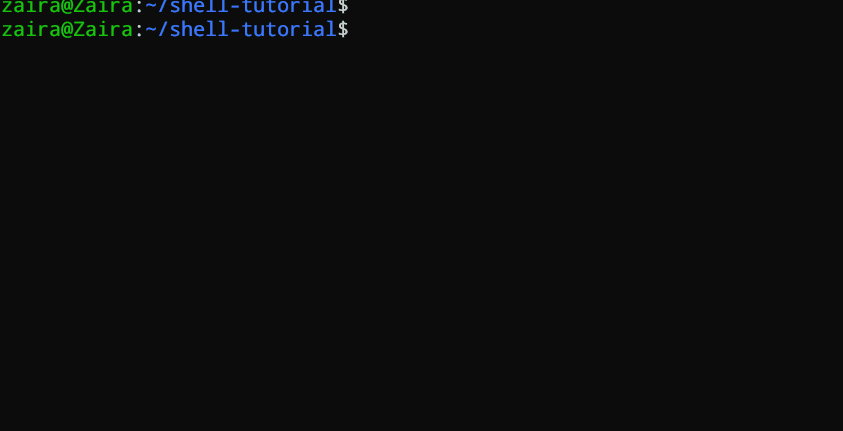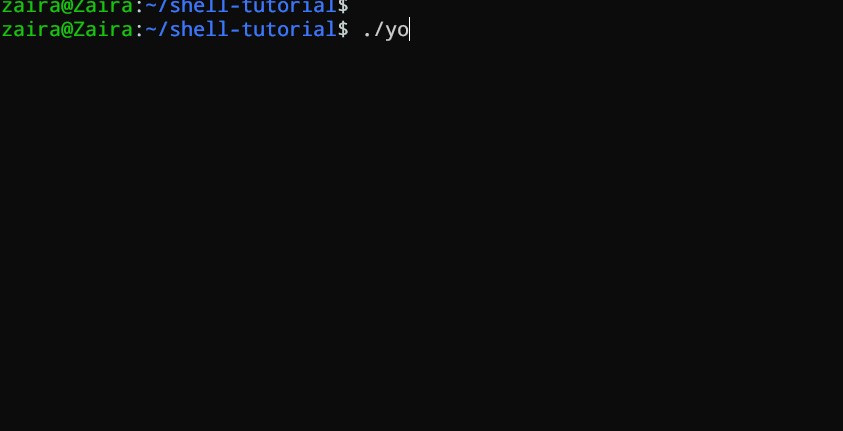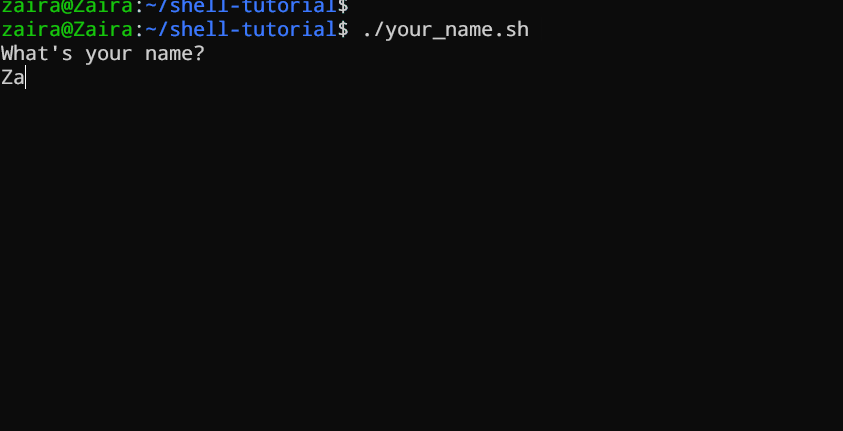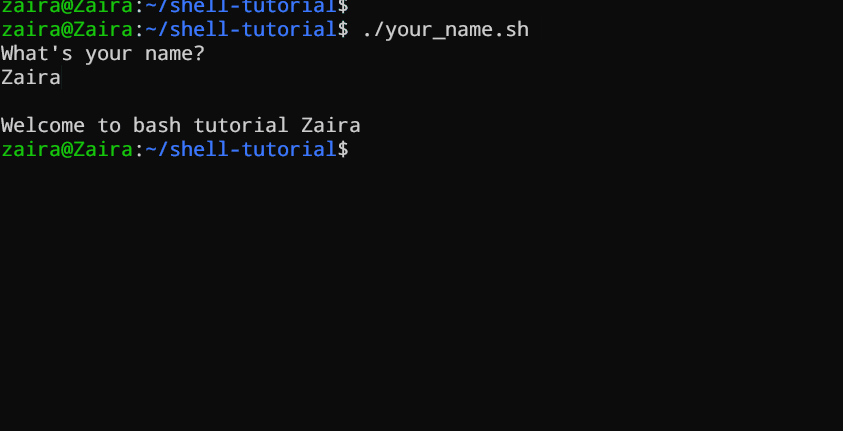
Possiamo leggere l’input dell’utente usando il comando read.
2. Leggere da un file
while read line
do
echo $line
done < input.txt
Questo codice legge ogni riga dal file chiamato input.txt e la stampa nel terminale. Studieremo i cicli while più avanti in questa sezione.
3. Argomenti della riga di comando
In uno script Bash o una funzione, $1 indica l’argomento iniziale passato, $2 indica il secondo argomento passato, e così via.
#!/bin/bash
echo "Hello, $1!"
Questo script prende un nome come argomento della riga di comando e stampa un saluto personalizzato.
Abbiamo fornito Zaira come nostro argomento per lo script.
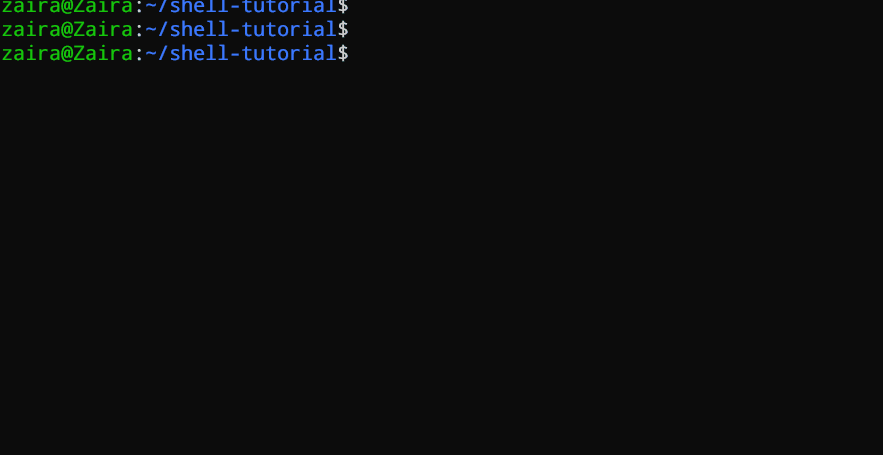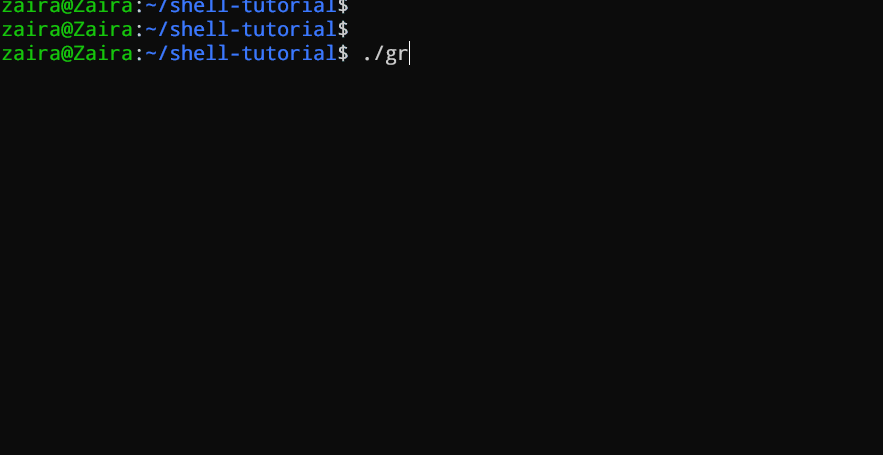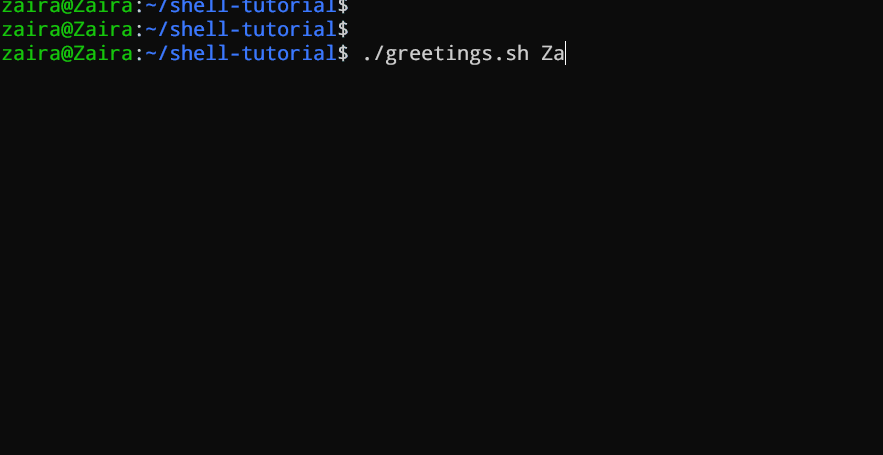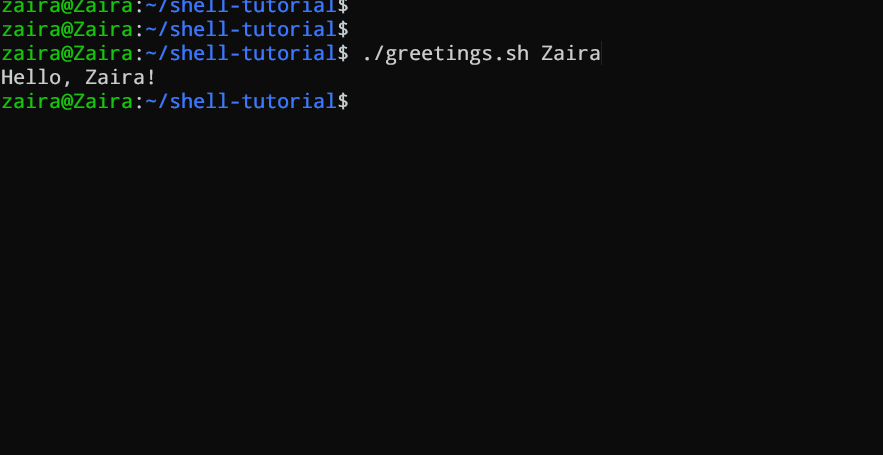
Output:
Visualizzazione output
- Qui discuteremo alcuni metodi per ricevere output dagli script.
echo "Hello, World!"
Stampare sul terminale:
Questo stampa il testo “Hello, World!” sul terminale.
echo "This is some text." > output.txt
2. Scrivere su un file:
Questo scrive il testo “This is some text.” in un file chiamato output.txt. Notare che l’operatore > sovrascrive un file se contiene già del contenuto.
echo "More text." >> output.txt
3. Aggiungere a un file:
È un’applicazione che appende il testo “More text.” alla fine del file output.txt.
ls > files.txt
4. Reindirizzamento dell’output:
Questo elenca i file nella directory corrente e scrive l’output in un file chiamato files.txt. puoi reindirizzare l’output di qualsiasi comando verso un file in questo modo.
Imparerai i dettagli del reindirizzamento dell’output nella sezione 8.5.
Istruzioni condizionali (if/else)
Espressioni che producono un risultato booleano, vero o falso, sono chiamate condizioni. Ci sono diversi modi per valutare le condizioni, incluso if, if-else, if-elif-else, e condizioni nidificate.
if [[ condition ]];
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fi
Sintassi:
Sintassi delle istruzioni condizionali di bash
if [ $a -gt 60 -a $b -lt 100 ]
Potremmo usare operatori logici come AND -a e OR -o per fare confronti con maggiore significato.
Questa istruzione verifica se entrambe le condizioni sono true: a è maggiore di 60 AND b è minore di 100.
#!/bin/bash
Vediamo un esempio di uno script Bash che utilizza if, if-else, e if-elif-else per determinare se un numero inserito dall'utente sia positivo, negativo o zero:
echo "Please enter a number: "
read num
if [ $num -gt 0 ]; then
echo "$num is positive"
elif [ $num -lt 0 ]; then
echo "$num is negative"
else
echo "$num is zero"
fi
# Script per determinare se un numero è positivo, negativo o zero
Il script prima invita l’utente a inserire un numero. Poi, utilizza una istruzione if per controllare se il numero è maggiore di 0. Se lo è, il script segnala che il numero è positivo. Se il numero non è maggiore di 0, il script passa alla prossima istruzione, che è una istruzione if-elif.
Qui, il script controlla se il numero è minore di 0. Se lo è, il script segnala che il numero è negativo.
Infine, se il numero non è né maggiore né minore di 0, il script utilizza una istruzione else per segnalare che il numero è zero.
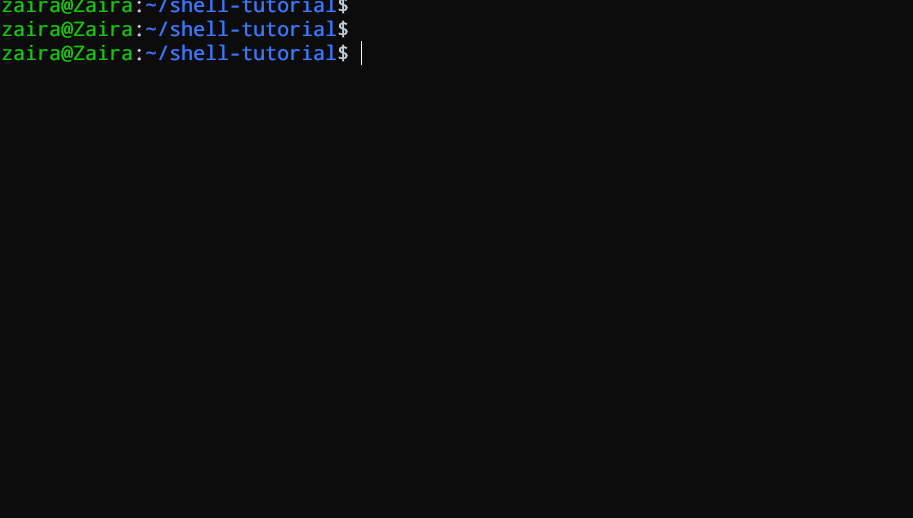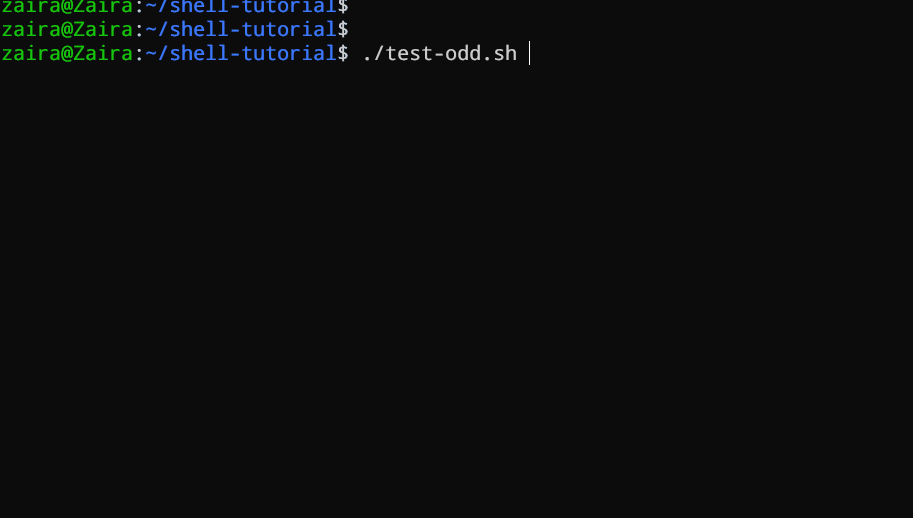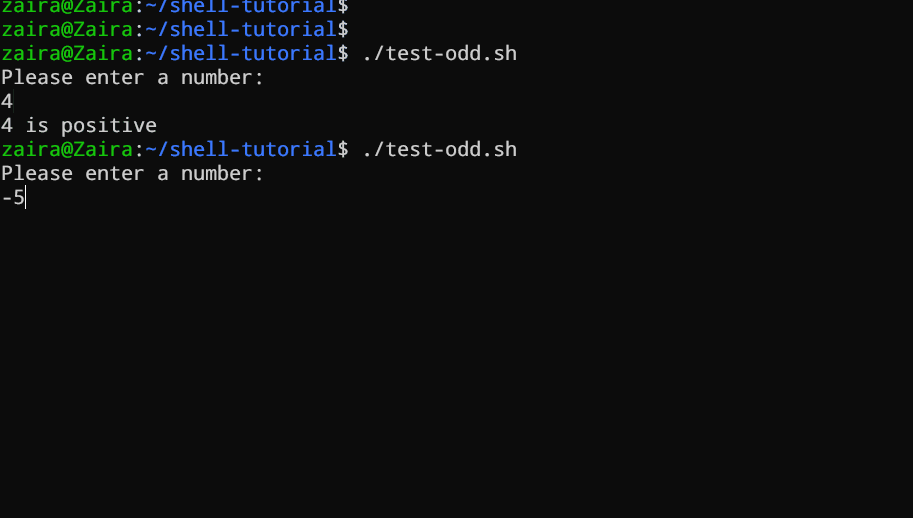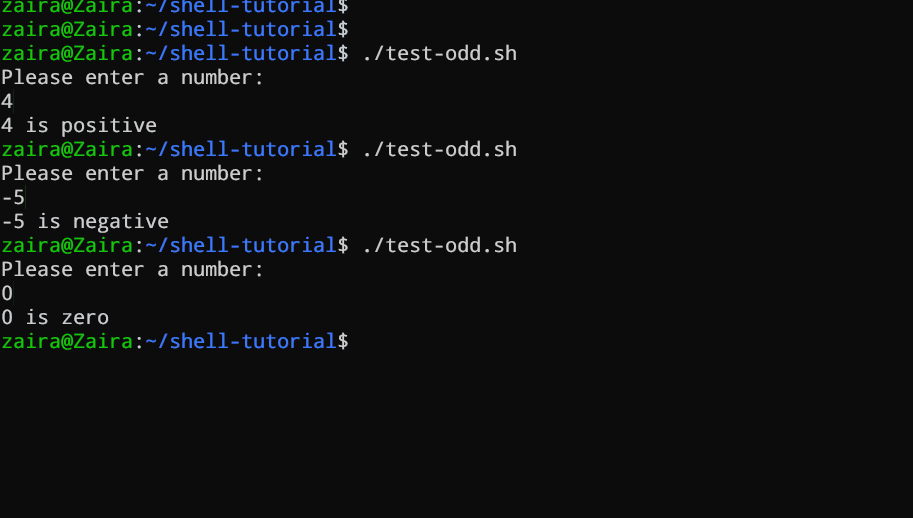
Vedere in azione 🚀
Iterazione e diramazione in Bash
Ciclo while
I cicli while controllano una condizione e si iterano finché la condizione rimane true. Dobbiamo fornire una dichiarazione del contatore che incrementa il contatore per controllare l’esecuzione del ciclo.
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
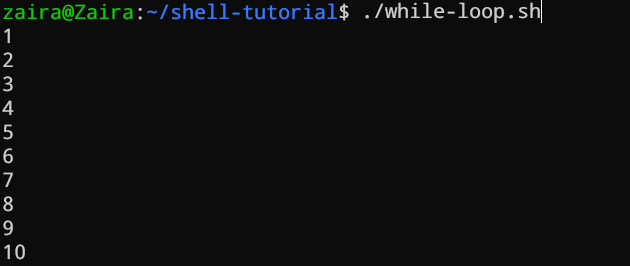
Nell’esempio sottostante, (( i += 1 )) è la dichiarazione del contatore che incrementa il valore di i. Il ciclo verrà eseguito esattamente 10 volte.
Ciclo for
Il ciclo for, come il ciclo while, permette di eseguire istruzioni un numero specifico di volte. Ogni ciclo si differenzia nella sua sintassi e nell’uso.
#!/bin/bash
for i in {1..5}
do
echo $i
done

Nell’esempio sottostante, il ciclo itererà 5 volte.
Istruzioni case
case expression in
pattern1)
Nel Bash, gli statement "case" sono usati per confrontare un valore dato con un elenco di pattern e eseguire un blocco di codice in base al primo pattern che corrisponde. La sintassi per uno statement "case" in Bash è la seguente:
;;
pattern2)
# codice da eseguire se l'espressione corrisponde a pattern1
;;
pattern3)
# codice da eseguire se l'espressione corrisponde a pattern2
;;
*)
# codice da eseguire se l'espressione corrisponde a pattern3
;;
esac
# codice da eseguire se nessuno dei pattern precedenti corrisponde all’espressione
Qui, “espressione” è il valore che vogliamo confrontare, e “pattern1”, “pattern2”, “pattern3”, e così via sono i pattern contro cui vogliamo confrontarlo.
Il doppio punto “;;” separa ogni blocco di codice da eseguire per ogni pattern. L’asterisco “*” rappresenta il caso predefinito, che viene eseguito se nessuno dei pattern specificati corrisponde all’espressione.
fruit="apple"
case $fruit in
"apple")
echo "This is a red fruit."
;;
"banana")
echo "This is a yellow fruit."
;;
"orange")
echo "This is an orange fruit."
;;
*)
echo "Unknown fruit."
;;
esac
Vediamo un esempio:
In questo esempio, dato che il valore di fruit è apple, il primo pattern corrisponde e viene eseguito il blocco di codice che stampa This is a red fruit.. Se il valore di fruit fosse invece banana, il secondo pattern corrisponderebbe e verrà eseguito il blocco di codice che stampa This is a yellow fruit., e così via.
Se il valore di fruit non corrisponde a nessuno dei pattern specificati, viene eseguito il caso predefinito, che stampa Unknown fruit.
Parte 7: Gestire i Pacchetti Software in Linux
Linux viene fornito con diversi programmi integrati. Tuttavia, potresti aver bisogno di installare nuovi programmi in base alle tue esigenze. Potresti anche dover aggiornare le applicazioni esistenti.
7.1. Pacchetti e Gestione dei Pacchetti
Cos’è un pacchetto?
Un pacchetto è una raccolta di file raggruppati insieme. Questi file sono essenziali per l’esecuzione di un particolare programma. Questi file contengono i file eseguibili del programma, le librerie e altre risorse.
Oltre ai file necessari per l’esecuzione del programma, i pacchetti contengono anche script di installazione, che copiano i file dove sono necessari. Un programma può contenere molti file e dipendenze. Con i pacchetti, è più facile gestire tutti i file e le dipendenze contemporaneamente.
Qual è la differenza tra sorgente e binario?
I programmatori scrivono il codice sorgente in un linguaggio di programmazione. Questo codice sorgente viene poi compilato in codice macchina che il computer può comprendere. Il codice compilato è chiamato codice binario.
Quando scarichi un pacchetto, puoi ottenere il codice sorgente o il codice binario. Il codice sorgente è il codice leggibile dall’uomo che può essere compilato in codice binario. Il codice binario è il codice compilato che il computer può comprendere.
I pacchetti sorgente possono essere utilizzati con qualsiasi tipo di macchina se il codice sorgente è compilato correttamente. Il binario, d’altra parte, è codice compilato specifico per un particolare tipo di macchina o architettura.
uname -m
Puoi trovare l'architettura della tua macchina usando il comando uname -m.
x86_64
# output
Dipendenze del pacchetto
Spesso i programmi condividono file. Invece di includere questi file in ogni pacchetto, un pacchetto separato può fornirli per tutti i programmi.
Per installare un programma che ha bisogno di questi file, è necessario anche installare il pacchetto che li contiene. Questo è chiamato dipendenza del pacchetto. Specificare le dipendenze rende i pacchetti più piccoli e più semplici, riducendo i duplicati.
Quando si installa un programma, è necessario installare anche le sue dipendenze. La maggior parte delle dipendenze richieste è generalmente già installata, ma potrebbero essere necessarie alcune ulteriori. Quindi, non sorprenderti se vengono installati anche altri pacchetti insieme al pacchetto scelto. Queste sono le dipendenze necessarie.
Gestori di pacchetti
Linux offre un sistema di gestione dei pacchetti completo per l’installazione, l’aggiornamento, la configurazione e la rimozione del software.
Con la gestione dei pacchetti, è possibile accedere a una base organizzata di migliaia di pacchetti software e avere la possibilità di risolvere le dipendenze e controllare gli aggiornamenti del software.
I pacchetti possono essere gestiti utilizzando sia utilità da riga di comando che possono essere facilmente automatizzate dagli amministratori di sistema, sia attraverso un’interfaccia grafica.
Canali/repository software
⚠️ La gestione dei pacchetti è diversa per le diverse distribuzioni. Qui stiamo usando Ubuntu.
L’installazione del software è un po’ diversa in Linux rispetto a Windows e Mac.
Linux utilizza i repository per archiviare i pacchetti software. Un repository è una raccolta di pacchetti software disponibili per l’installazione tramite un gestore di pacchetti.
Un gestore di pacchetti memorizza anche un indice di tutti i pacchetti disponibili da un repository. A volte l’indice viene ricostruito per assicurarsi che sia aggiornato e per conoscere quali pacchetti sono stati aggiornati o aggiunti al canale dall’ultima volta che ha controllato.
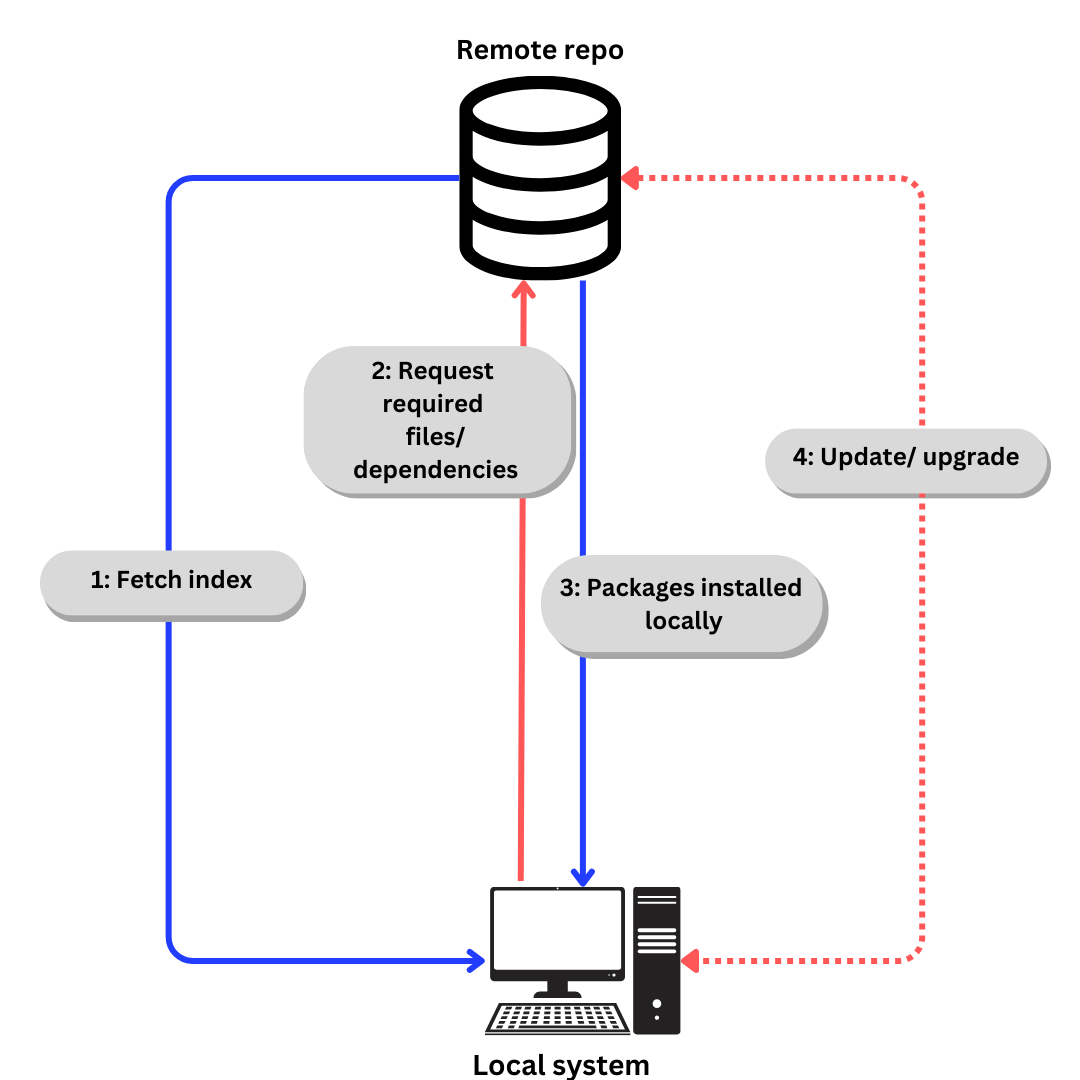
Il processo generico di scaricamento del software da un repository è più o meno come questo:
- Se parliamo specificamente di Ubuntu,
- L’indice viene recuperato usando
apt update.(aptè spiegato nella prossima sezione). - I file richiesti/dipendenze vengono richiesti secondo l’indice usando
apt install - I pacchetti e le dipendenze vengono installati localmente.
Aggiorna le dipendenze e i pacchetti quando necessario usando apt update e apt upgrade
Nei distro basati su Debian, puoi trovare l’elenco dei repository (repositories) in /etc/apt/sources.list.
7.2. Installare un pacchetto tramite riga di comando
Il comando apt è un potente strumento a riga di comando, che funziona con lo “Strumento di Pacchettizzazione Avanzato (APT)” di Ubuntu.
`apt`, insieme ai comandi inclusi, fornisce le funzioni per installare nuovi pacchetti software, aggiornare pacchetti software esistenti, aggiornare l’indice della lista dei pacchetti e persino aggiornare l’intero sistema Ubuntu.
Per visualizzare i log dell’installazione tramite `apt`, è possibile visualizzare il file `/var/log/dpkg.log`.
Di seguito sono illustrati i comandi `apt`:
Installazione di pacchetti
sudo apt install htop
Ad esempio, per installare il pacchetto `htop`, è possibile utilizzare il seguente comando:
Aggiornamento dell’indice della lista dei pacchetti
sudo apt update
L’indice della lista dei pacchetti è una lista di tutti i pacchetti disponibili nei repository. Per aggiornare l’indice locale dei pacchetti, è possibile utilizzare il seguente comando:
Aggiornamento dei pacchetti
I pacchetti installati sul sistema possono ricevere aggiornamenti che contengono correzioni di bug, patch di sicurezza e nuove funzionalità.
sudo apt upgrade
Per aggiornare i pacchetti, è possibile utilizzare il seguente comando:
Rimozione di pacchetti
sudo apt remove htop
Per rimuovere un pacchetto, come `htop`, è possibile utilizzare il seguente comando:
7.3. Installazione di un pacchetto tramite un metodo grafico avanzato – Synaptic
Se non si è a proprio agio con la riga di comando, è possibile utilizzare una applicazione GUI per installare pacchetti. È possibile ottenere gli stessi risultati della riga di comando, ma con una interfaccia grafica.
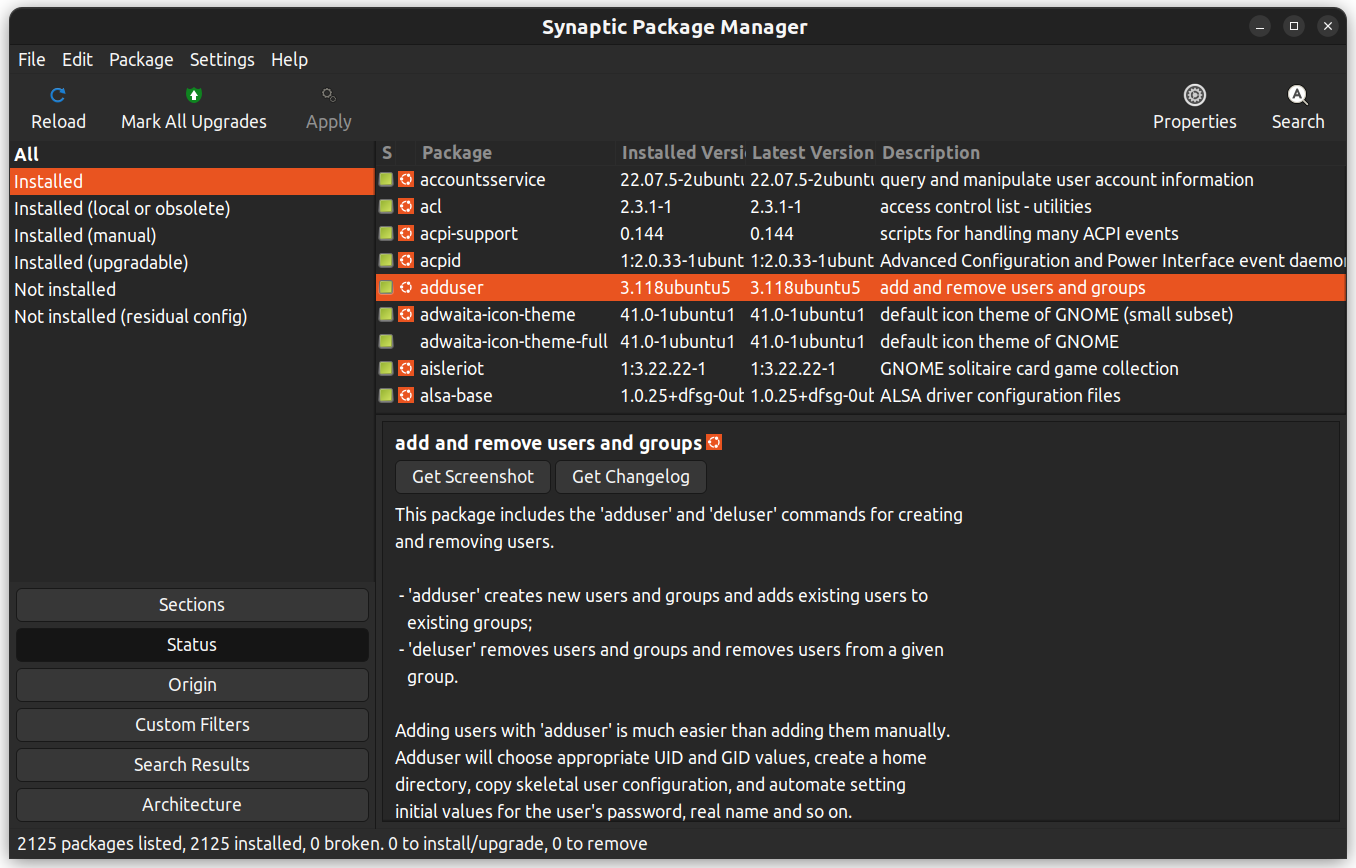
Synaptic è un’applicazione grafica per la gestione dei pacchetti che aiuta a elencare i pacchetti installati, il loro stato, gli aggiornamenti in sospeso e così via. Offre filtri personalizzati per aiutare a restringere i risultati della ricerca.
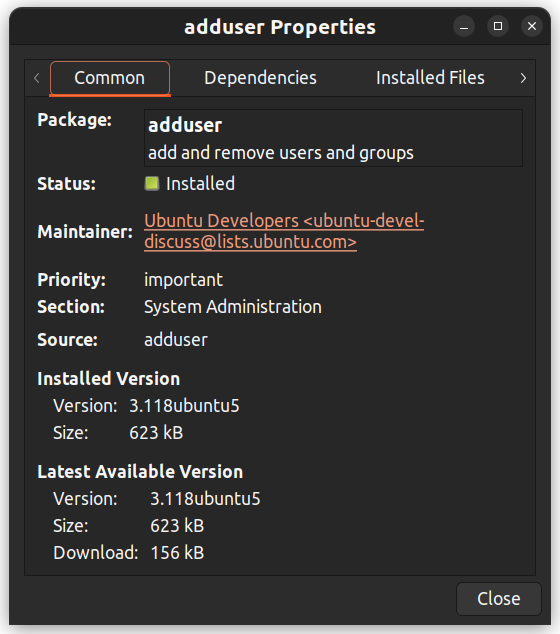
Puoi anche fare clic destro su un pacchetto e visualizzare dettagli addizionali come le dipendenze, il maintainer, la dimensione e i file installati.
7.4. Installare pacchetti scaricati da un sito web
Potresti voler installare un pacchetto che hai scaricato da un sito web invece di uno repository software. questi pacchetti si chiamano file .deb.
cd directory
sudo dpkg -i package_name.deb
Usodpkgper installare i pacchetti:dpkg è una utility a riga di comando utilizzata per installare i pacchetti. Per installare un pacchetto con dpkg, apri il Terminale e digita il seguente:
Nota: Sostituisci “directory” con la directory in cui il pacchetto è memorizzato e “package_name” con il nome del file del pacchetto.
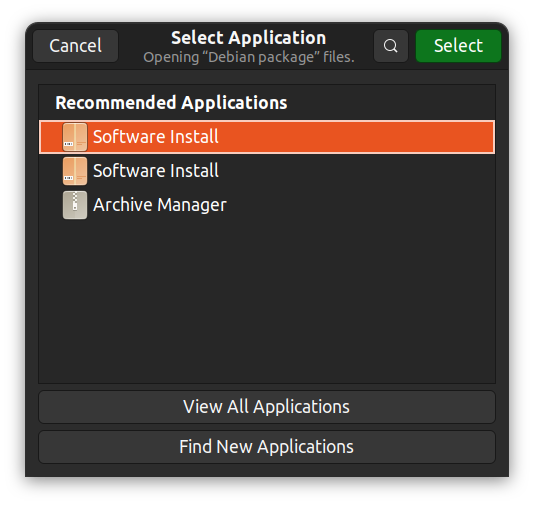
In alternativa, puoi fare clic destro, selezionare “Apri con un’applicazione differente” e scegliere una app grafica a tuo piacimento.
💡 Tip: In Ubuntu, puoi vedere una lista dei pacchetti installati con dpkg --list.
Parte 8: argomenti avanzati di Linux
8.1. Gestione Utenti
Può esserci più utenti con diversi livelli di accesso nel sistema. In Linux, l’utente root ha il massimo livello di accesso e può eseguire qualsiasi operazione sul sistema. Gli utenti regolari hanno accesso limitato e possono eseguire solo operazioni per le quali hanno il permesso.
Cos’è un utente?
Un account utente fornisce una separazione tra differenti persone e programmi che possono eseguire comandi.
Gli esseri umani identificano gli utenti con un nome, poiché i nomi sono facili da lavorare con. Ma il sistema identifica gli utenti con un numero univoco chiamato l’ID utente (UID).
Quando gli utenti umani effettuano l’accesso utilizzando il nome utente fornito, devono utilizzare una password per autorizzarsi.
I conti utente formano le fondamenta della sicurezza del sistema. La proprietà dei file è anche associata ai conti utente e impone contropposizioni di accesso ai file. Ogni processo ha un account utente associato che fornisce un livello di controllo per gli amministratori.
- Esistono tre tipi principali di account utente:
- Superutente: Il superutente ha accesso completo al sistema. Il nome del superutente è
root. Ha unUIDpari a 0. - Utente di sistema: L’utente di sistema ha account utente utilizzati per eseguire i servizi di sistema. Questi account sono utilizzati per eseguire i servizi di sistema e non sono destinati all’interazione umana.
Utente normale: Gli utenti normali sono utenti umani che hanno accesso al sistema.
id
uid=1000(john) gid=1000(john) groups=1000(john),4(adm),24(cdrom),27(sudo),30(dip)... output truncated
Il comando id mostra l’ID utente e l’ID gruppo dell’utente corrente.
id username
Per visualizzare le informazioni di base di un altro utente, passare il nome utente come argomento al comando id.
ps -u
Per visualizzare le informazioni relative agli utenti per i processi, usare il comando ps con l'opzione -u.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 16968 3920 ? Ss 18:45 0:00 /sbin/init splash
root 2 0.0 0.0 0 0 ? S 18:45 0:00 [kthreadd]
# Output
Per impostazione predefinita, i sistemi usano il file /etc/passwd per memorizzare le informazioni utente.
root:x:0:0:root:/root:/bin/bash
Ecco una riga dal file /etc/passwd:
- Il file
/etc/passwdcontiene le seguenti informazioni riguardo ciascun utente: - Nome utente:
root– Il nome utente dell’account utente. - Password:
x– La password in formato cifrato per l’account utente che è memorizzata nel file/etc/shadowper motivi di sicurezza. - ID utente (UID):
0– L’identificativo numerico univoco per l’account utente. - ID gruppo (GID):
0– L’identificativo del gruppo primario per l’account utente. - Informazioni utente:
root– Il nome reale per l’account utente. - Directory principale:
/root– La directory principale per l’account utente.
Shell: /bin/bash – Il shell predefinito per l’account utente. Un utente di sistema potrebbe utilizzare /sbin/nologin se non sono consentiti accessi interattivi per quell’utente.
Cosa è un gruppo?
Un gruppo è una collezione di account utente che condividono accesso e risorse. I gruppi hanno nomi di gruppo per identificarli. Il sistema identifica i gruppi tramite un numero univoco chiamato ID gruppo (GID).
Per impostazione predefinita, le informazioni sui gruppi sono memorizzate nel file /etc/group.
adm:x:4:syslog,john
Ecco un’entrata dal file /etc/group:
- Ecco la scomposizione dei campi nell’entrata fornita:
- Nome del gruppo:
adm– Il nome del gruppo. - Password:
x– La password per il gruppo è memorizzata nel file/etc/gshadowper motivi di sicurezza. La password è facoltativa e appare vuota se non impostata. - ID del gruppo (GID):
4– L’identificatore numerico univoco del gruppo.
Membri del gruppo: syslog,john – L’elenco degli username che fanno parte del gruppo. In questo caso, il gruppo adm ha due membri: syslog e john.
Nella voce specifica, il nome del gruppo è adm, l’ID del gruppo è 4, e il gruppo ha due membri: syslog e john. Il campo password è generalmente impostato a x per indicare che la password del gruppo è memorizzata nel file /etc/gshadow.
- I gruppi sono ulteriormente divisi in ‘principali‘ e ‘supplementari‘.
- Gruppo principale: Ogni utente è assegnato automaticamente un gruppo principale. Questo gruppo di solito ha lo stesso nome dell’utente e viene creato quando viene creato l’account utente. Normalmente, i file e le directory creati dall’utente appartengono a questo gruppo principale.
Gruppi supplementari: Sono gruppi aggiuntivi a cui un utente può appartenere oltre al proprio gruppo primario. Gli utenti possono essere membri di più gruppi supplementari. Questi gruppi consentono all’utente di avere i permessi per le risorse condivise tra i gruppi stessi. Consentono di accedere alle risorse condivise senza influire sui permessi dei file del sistema e mantenendo intatta la sicurezza. Mentre un utente deve appartenere a un gruppo primario, l’appartenenza a gruppi supplementari è facoltativa.
Controllo dell’accesso: trovare e capire i permessi dei file
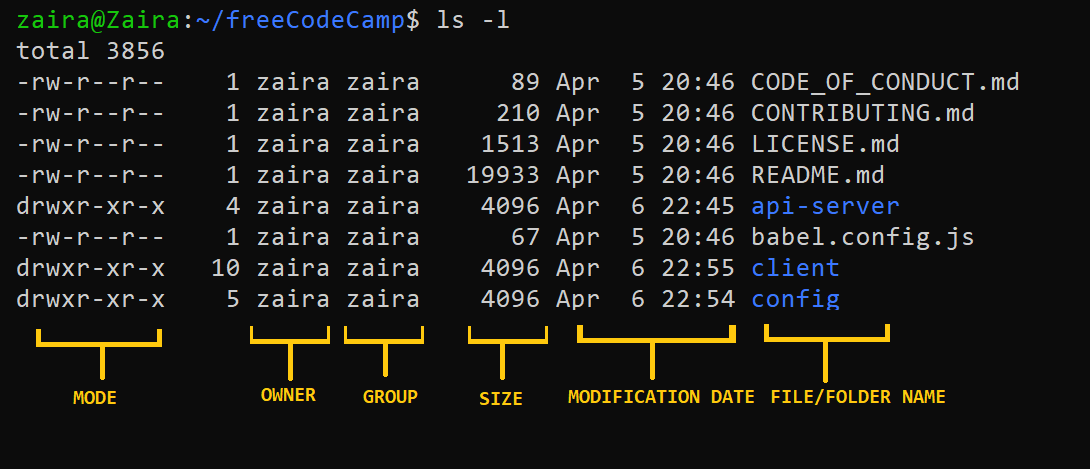
La proprietà dei file può essere visualizzata con il comando ls -l. La prima colonna dell’output del comando ls -l mostra i permessi del file. Le altre colonne mostrano il proprietario del file e il gruppo di appartenenza.

Diamo un’occhiata più da vicino alla colonna mode:
- Mode definisce due cose:
- Tipo di file: Il tipo di file definisce il tipo del file. Per i file normali che contengono semplici dati è vuoto
-. Per altri tipi speciali di file il simbolo è diverso. Per una directory che è un file speciale, èd. I file speciali sono trattati in modo diverso dall’OS.
Classi di permessi: Il prossimo insieme di caratteri definisce i permessi per utente, gruppo e altri rispettivamente.
– Utente: Questo è il proprietario di un file e il proprietario del file appartiene a questa classe.
– Gruppo: I membri del gruppo del file appartengono a questa classe
– Altro: Tutti gli utenti che non fanno parte delle classi utente o gruppo appartengono a questa classe.
💡Nota: La proprietà della directory può essere visualizzata utilizzando il comando ls -ld.
Come leggere i permessi simbolici o i permessi rwx
- La rappresentazione
rwxè conosciuta come la rappresentazione simbolica dei permessi. Nell’insieme di permessi, rsta per leggi. È indicato nel primo carattere della triade.wsta per scrivi. È indicato nel secondo carattere della triade.
x sta per esecuzione. È indicato nel terzo carattere della triade.
Leggere:
Per i file normali, i permessi di lettura consentono di aprire e leggere il file solo. Gli utenti non possono modificare il file.
Anche per le directory, i permessi di lettura consentono di elencare il contenuto della directory senza alcuna modifica nella directory.
Scrivere:
Quando i file hanno permessi di scrittura, l’utente può modificare (modificare, eliminare) il file e salvarlo.
Per le cartelle, i permessi di scrittura consentono all’utente di modificare il suo contenuto (creare, eliminare e rinominare i file all’interno di essa), e modificare il contenuto dei file ai quali l’utente ha permessi di scrittura.
Esempi di permessi in Linux
- Ora che sappiamo come interpretare i permessi di lettura, diamo un’occhiata ad alcuni esempi.
-
-rw-rw-r--: Un file modificabile dal proprietario e dal gruppo, ma non da altri.
drwxrwx---: Una directory modificabile dal proprietario e dal gruppo.
Esegui:
Per i file, le autorizzazioni di esecuzione consentono all’utente di eseguire uno script esecutabile. Per le directory, l’utente può accedere a esse e visualizzare i dettagli delle file nella directory.
Come cambiare i permessi e il possesso dei file in Linux usando chmod e chown
Adesso che sappiamo i fondamenti di possesso e permessi, vediamo come possiamo modificare i permessi usando il comando chmod.
chmod permissions filename
Sintassi dichmod:
- Dove,
permissionspossono essere lettura, scrittura, esecuzione o una combinazione di queste.
filename è il nome del file per il quale i permessi devono essere cambiati. Questo parametro può anche essere una lista di file per cambiare i permessi in blocco.
- Possiamo cambiare i permessi usando due modalità:
- Modalità simbolica: questo metodo utilizza simboli come
u,g,oper rappresentare gli utenti, i gruppi e gli altri. Le autorizzazioni sono rappresentate comer, w, xper le autorizzazioni di lettura, scrittura e esecuzione, rispettivamente. È possibile modificare le autorizzazioni utilizzando +, – e =.
Modalità assoluta: questo metodo rappresenta le autorizzazioni come numeri ottali a tre cifre che vanno da 0 a 7.
Adesso, vediamo le modalità in dettaglio.
Come cambiare le autorizzazioni usando la modalità simbolica
| La tabella sottostante riassume la rappresentazione utente: | Rappresentazione utente |
| u | Descrizione |
| g | utente/proprietario |
| o | gruppo |
altro
| Possiamo usare operatori matematici per aggiungere, rimuovere e assegnare autorizzazioni. La tabella sottostante mostra il riepilogo: | Operatore |
| Descrizione | + |
| Aggiunge una autorizzazione a un file o directory | – |
| Rimuove l’autorizzazione | \= |
Imposta i permessi se non presenti prima. Anche sovrascrive i permessi se impostati precedentemente.
Esempio:
Supponiamo di avere uno script e di voler renderlo esecutabile per il proprietario del file zaira.

I permessi attuali del file sono così:
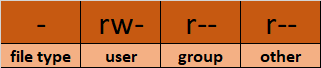
Dividiamo i permessi così:
chmod u+x mymotd.sh
Per aggiungere i diritti di esecuzione (x) al proprietario (u) usando il metodo simbolico, possiamo usare il comando sottostante:
Output:
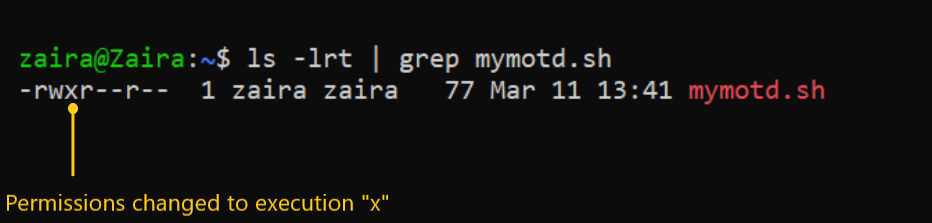
Ora, vediamo che sono stati aggiunti i permessi di esecuzione per il proprietario zaira.
- Esempi aggiuntivi per cambiare permessi tramite il metodo simbolico:
- Rimuovere i permessi di
letturaescritturapergruppoealtro:chmod go-rw. - Rimuovere i permessi di
letturaperaltro:chmod o-r.
Assegnare i permessi di scrittura al gruppo e sovrascrivere i permessi esistenti: chmod g=w.
Come cambiare i permessi usando il modo assoluto
Modalità assoluta utilizza numeri per rappresentare i permessi e operatori matematici per modificarli.
| La tabella seguente mostra come possiamo assegnare i permessi corrispondenti: | PERMESSO |
| PROVVEDERE PERMESSO | leggi |
| aggiungi 4 | scrivere |
| aggiungi 2 | eseguire |
aggiungi 1
| I permessi possono essere revocati utilizzando la sottrazione. La tabella seguente mostra come possono rimuovere i permessi corrispondenti. | PERMESSO |
| RIMUOVERE PERMESSO | leggi |
| sottrai 4 | scrivere |
| sottrai 2 | eseguire |
sottrai 1
- ESEMPIO:
Impostare leggi (aggiungi 4) per utente, leggi (aggiungi 4) e eseguire (aggiungi 1) per gruppo, e solo eseguire (aggiungi 1) per altri.
chmod 451 file-name
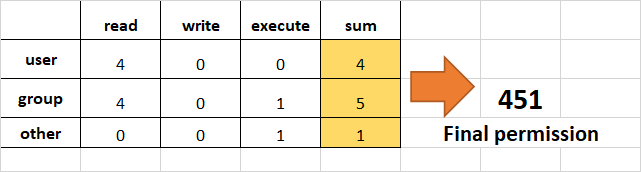
Ecco come abbiamo fatto il calcolo:
- Nota che questo è identico a
r--r-x--x.
Rimuovere i diritti di esecuzione da altro e gruppo.
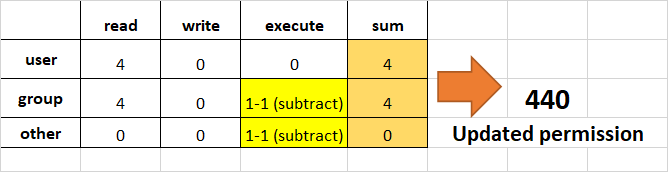
- Per rimuovere l’esecuzione da
altroegruppo, sottrai 1 dalla parte di esecuzione degli ultimi due byte.
Assegnare lettura, scrittura e esecuzione al utente, lettura e esecuzione al gruppo e solo lettura agli altri.

Questo sarebbe lo stesso di rwxr-xr--.
Come cambiare la proprietà utilizzando il comando chown
Prossimamente, impareremo come cambiare la proprietà di un file. È possibile cambiare la proprietà di un file o cartella utilizzando il comando chown. In alcuni casi, cambiare la proprietà richiede permessi di sudo.
chown user filename
Sintassi di chown
Come cambiare la proprietà utente con chown
Trasferiamo la proprietà dall’utente zaira all’utente news.

chown news mymotd.sh
Comando per cambiare la proprietà: sudo chown news mymotd.sh.

Output:
Come cambiare simultaneamente proprietà utente e gruppo
chown user:group filename
Possiamo anche utilizzare chown per cambiare proprietà utente e gruppo simultaneamente.
Come cambiare la proprietà della directory
chown -R admin /opt/script
È possibile cambiare la proprietà ricorsivamente per i contenuti in una directory. L’esempio seguente cambia la proprietà della directory /opt/script per consentire all’utente admin.
Come cambiare la proprietà del gruppo
chown :admins /opt/script
In caso di necessità solo per cambiare il proprietario del gruppo, è possibile usare chown anteponendo il nome del gruppo a una :.
Come passare tra utenti
[user01@host ~]$ su user02
Password:
[user02@host ~]$
Puoi passare da un utente all’altro usando il comando su.
Come ottenere accesso superutente
L’utente superamministratore, o root, ha il massimo livello di accesso su un sistema Linux. L’utente root può eseguire qualsiasi operazione sul sistema. L’utente root può accedere a tutti i file e directory, installare o rimuovere software, e modificare o sovrascrivere le configurazioni del sistema.
Con grandi poteri arriva la responsabilità. Se l’utente root viene compromesso, qualcuno può ottenere il controllo completo sul sistema. Si consiglia di usare l’account utente root solo quando necessario.
[user01@host ~]$ su
Password:
[root@host ~]Se ometti il nome utente, il comando su passa automaticamente all'account utente root.
#
Un’altra variante del comando su è su -. Il comando su passa all’account utente root ma non cambia le variabili d’ambiente. Il comando su - passa all’account utente root e cambia le variabili d’ambiente alle dell’utente di destinazione.
Eseguire comandi con sudo
Per eseguire comandi come l’utente root senza passare all’account root, puoi usare il comando sudo. Il comando sudo ti permette di eseguire comandi con privilegi elevati.
Eseguire comandi con sudo è una opzione più sicura rispetto a eseguire i comandi come utente root. Questo perché solo un set specifico di utenti può essere autorizzato a eseguire comandi con sudo. Questo è definito nel file /etc/sudoers.
Anche sudo registra tutti i comandi eseguiti con esso, fornendo una traccia di audit di chi ha eseguito quali comandi e quando.
cat /var/log/auth.log | grep sudo
In Ubuntu, è possibile trovare i log di audit qui:
user01 is not in the sudoers file. This incident will be reported.
Per un utente che non ha accesso a sudo, viene segnalato nei log e genera un messaggio come questo:
Gestione account utenti locali
Creazione di utenti dalla riga di comando
sudo useradd username
Il comando utilizzato per aggiungere un nuovo utente è:
Questo comando imposta una directory home dell’utente e crea un gruppo privato designato dalla username dell’utente. Attualmente, l’account manca di una password valida, impedendo all’utente di accedere fino a quando una password non è creata.
Modifica di utenti esistenti
Il comando usermod viene utilizzato per modificare gli utenti esistenti. Ecco alcune delle opzioni comuni utilizzate con il comando usermod:
- Ecco alcuni esempi del comando
usermodin Linux: - Cambia il nome utente di accesso di un utente:
- Cambiare la directory home di un utente:
- Aggiungere un utente a un gruppo supplementare:
- Cambiare la shell di un utente:
- Bloccare l’account di un utente:
- Sbloccare l’account di un utente:
- Imposta una data di scadenza per un account utente:
- Cambia l’ID utente (UID) di un utente:
- Cambiare il gruppo primario di un utente:
Rimuovi un utente da un gruppo supplementare:
Eliminazione utenti
- Il comando
userdelviene utilizzato per eliminare un account utente e i relativi file dal sistema. sudo userdel nomeutente: rimuove i dettagli dell’utente da/etc/passwdma conserva la directory home dell’utente.
Il comando sudo userdel -r nomeutente rimuove i dettagli dell’utente da /etc/passwd e cancella anche la directory home dell’utente.
Cambiare le password degli utenti
- Il comando
passwdviene utilizzato per cambiare la password di un utente.
sudo passwd nomeutente: imposta la password iniziale o modifica la password esistente di nomeutente. Viene anche usato per cambiare la password dell’utente attualmente connesso.
8.2 Connessione a server remoti tramite SSH
Accesso ai server remoti è una delle attività essenziali per gli amministratori di sistema. È possibile connettersi a diversi server o accedere a database attraverso la macchina locale ed eseguire comandi, tutto usando SSH.
Che cos’è il protocollo SSH?
SSH sta per Secure Shell. È un protocollo di rete crittografico che consente la comunicazione sicura tra due sistemi.
La porta predefinita per SSH è la 22.
- I due partecipanti nella comunicazione via SSH sono:
- Il server: la macchina a cui si vuole accedere.
Il client: Il sistema da cui si accede al server.
- Il processo di connessione a un server segue questi passaggi:
- Avvio connessione: Il client invia una richiesta di connessione al server.
- Scambio di chiavi: Il server invia la sua chiave pubblica al client. Entrambi concordano i metodi di crittografia da utilizzare.
- Generazione chiave di sessione: Il client e il server usano lo scambio di chiavi Diffie-Hellman per creare una chiave di sessione condivisa.
- Autenticazione del cliente: Il cliente effettua l’accesso al server utilizzando una password, una chiave privata o un altro metodo.
Comunicazione sicura: Dopo l’autenticazione, il cliente e il server comunicano in modo sicuro tramite crittografia.
Come connettersi a un server remoto utilizzando SSH?
Il comando ssh è una utility integrata in Linux ed è anche quella predefinita. Rende l’accesso ai server molto facile e sicuro.
Qui, stiamo parlando di come il client avrebbe una connessione al server.
- Prima di connettersi a un server, devi avere le seguenti informazioni:
- L’indirizzo IP o il nome di dominio del server.
- Il nome utente e la password del server.
Il numero di porta a cui ha accesso nel server.
ssh username@server_ip
La sintassi di base del comando ssh è:
ssh [email protected]
Ad esempio, se il tuo nome utente è john e l’IP del server è 192.168.1.10, il comando sarebbe:
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-70-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Fri Jun 5 10:17:32 UTC 2024
System load: 0.08 Processes: 122
Usage of /: 12.3% of 19.56GB Users logged in: 1
Memory usage: 53% IP address for eth0: 192.168.1.10
Swap usage: 0%
Last login: Fri Jun 5 09:34:56 2024 from 192.168.1.2
john@hostname:~$ Dopo quello, verrai richiesto di inserire la password segreta. La tua schermata sarà simile a questa:
# Inizio a inserire i comandi
Ora puoi eseguire i comandi relevanti sul server 192.168.1.10.
ssh -p port_number username@server_ip
⚠️ La porta predefinita per ssh è 22, ma è anche vulnerabile, poiché gli hacker la cercheranno probabilmente prima. Il tuo server può esporre un’altra porta e condividere l’accesso con te. Per connetterti a una porta diversa, usa l’opzione -p.
8.3. Analisi e parsing avanzati dei log
I file di log, una volta configurati, vengono generati dal tuo sistema per una varietà di ragioni utili. Possono essere usati per tracciare eventi di sistema, monitorare le prestazioni di sistema e risolvere problemi. Sono particolarmente utili per gli amministratori di sistema in cui possono tracciare errori delle applicazioni, eventi di rete e attività dell’utente.
Di seguito un esempio di file di log:
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 DEBUG Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 WARN Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 DEBUG API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
# file di log di esempio
- Un file di log solitamente contiene le seguenti colonne:
- Timestamp: La data e l’ora in cui si è verificato l’evento.
- Livello Log: La gravità dell’evento (INFO, DEBUG, WARN, ERROR).
- Componente: Il componente del sistema che ha generato l’evento (Startup, Config, Database, User, Security, Network, Email, API, Session, Shutdown).
- Messaggio: Una descrizione dell’evento che si è verificato.
Informazioni aggiuntive: Informazioni aggiuntive relative all’evento.
Nei sistemi in tempo reale, i file di registro tendono ad essere lunghi migliaia di righe e vengono generati ogni secondo. possono essere molto dettagliati a seconda della configurazione. Ogni colonna in un file di registro è un pezzo di informazione che può essere usato per rintracciare i problemi. Questo rende i file di registro difficili da leggere e capire manualmente.
Qui entra in gioco l’analisi dei log. L’analisi dei log è il processo di estrarre informazioni utili dai file di registro. Coinvolge suddividere i file di registro in parti più piccole e gestibili ed estrarre le informazioni rilevanti.
Le informazioni filtrate possono anche essere utili per creare avvisi, rapporti e dashboard.
In questa sezione, esplorerai alcune tecniche per l’analisi dei file di registro in Linux.
Estrazione del testo usando grep
Grep è una utility integrata di bash. Sta per “global regular expression print”. Grep viene usato per cercare stringhe nei file.
- Eccone alcuni utilizzi comuni di
grep: - Questo comando cerca “search_string” nel file chiamato
filename. - Questo comando cerca “
search_string” in tutti i file all’interno della directory specificata e nelle sue sottodirectory. - Questo comando esegue una ricerca non sensibile alla lettera maiuscola/minuscola di “search_string” nel file chiamato
filename. - Questo comando mostra i numeri di riga insieme alle righe corrispondenti nel file chiamato
filename. - Questo comando conteggia il numero di righe che contengono “search_string” nel file chiamato
filename. - Questo comando mostra tutte le righe che non contengono “search_string” nel file chiamato
filename. - Questo comando cerca la parola intera “word” nel file chiamato
filename.
Questo comando consente l’uso di espressioni regolari estese per un’impostazione di corrispondenza più complessa nel file chiamato filename.
💡 Consiglio: Se ci sono molti file in una cartella, puoi usare il comando sottostante per trovare l'elenco dei file che contengono le stringhe desiderate.
grep -l "String to Match" /path/to/directory
# trova l’elenco dei file che contengono le stringhe desiderate
Estrazione del testo usando sed
sed viene utilizzato per “editor di flussi”. Processa i dati in maniera flusso-orientata, ovvero legge i dati riga per riga. sed ti consente di cercare pattern e eseguire azioni sulle righe che corrispondono a quei pattern.
Sintassi di base dised:
sed [options] 'command' file_name
La sintassi di base di sed è la seguente:
Qui, comando viene utilizzato per eseguire operazioni come sostituzione, eliminazione, inserimento e così via sul dati testuali. Il nome del file è il nome del file che si desidera processare.
seduso:
1. Sostituzione:
sed 's/old-text/new-text/' filename
La flag s viene utilizzata per sostituire del testo. Il vecchio-testo viene sostituito con nuovo-testo:
sed 's/error/warning/' system.log
Per esempio, per cambiare tutte le occorrenze di “error” in “warning” nel file di registro system.log:
2. Stampa righe contenenti un certo pattern:
sed -n '/pattern/p' filename
Usando sed per filtrare e mostrare righe che corrispondono a un certo pattern:
sed -n '/ERROR/p' system.log
Ad esempio, per trovare tutte le righe contenenti “ERROR”:
3. Eliminazione righe contenenti un certo pattern:
sed '/pattern/d' filename
Puoi eliminare righe dall’output che corrispondono a un certo pattern:
sed '/DEBUG/d' system.log
Ad esempio, per rimuovere tutte le righe contenenti “DEBUG”:
4. Estrazione di campi specifici da una riga di registro:
sed -n 's/^\([0-9]\{4\}-[0-9]\{2\}-[0-9]\{2\}\).*/\1/p' system.log
Puoi usare le espressioni regolari per estrarre parti delle righe. Supponi che ogni riga di log inizi con una data nel formato “YYYY-MM-DD”. Potresti estrarre solo la data da ogni riga:
Il parsing del testo con awk
awk ha la capacità di suddividere facilmente ogni riga in campi. È adatto per elaborare testi strutturati come file di log.
Sintassi di base diawk
awk 'pattern { action }' file_name
La sintassi di base di awk è:
Qui, pattern è una condizione che deve essere soddisfatta affinché venga eseguita l’azione. Se il pattern è omesso, l’azione viene eseguita su ogni riga.
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
- Nelle prossime esempi, userai questo file di log come esempio:
Accesso alle colonne usandoawk
zaira@zaira-ThinkPad:~$ awk '{ print $1 }' sample.log
I campi in awk (separati da spazi bianchi per impostazione predefinita) possono essere acceduti usando $1, $2, $3, e così via.
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
2024-04-25
zaira@zaira-ThinkPad:~$ awk '{ print $2 }' sample.log
# output
09:00:00
09:01:00
09:02:00
09:03:00
09:04:00
09:05:00
09:06:00
09:07:00
09:08:00
09:09:00
- # output
awk '/ERROR/ { print $0 }' logfile.log
Stampa righe contenenti un pattern specifico (per esempio, ERROR)
2024-04-25 09:05:00 ERROR Network: Network timeout on request (ReqID: 456)
# output
- Questo stampa tutte le righe che contengono “ERROR”.
awk '{ print $1, $2 }' logfile.log
Estrazione del primo campo (Data e Ora)
2024-04-25 09:00:00
2024-04-25 09:01:00
2024-04-25 09:02:00
2024-04-25 09:03:00
2024-04-25 09:04:00
2024-04-25 09:05:00
2024-04-25 09:06:00
2024-04-25 09:07:00
2024-04-25 09:08:007
2024-04-25 09:09:00
# output
- Questo estrarrà i primi due campi da ogni riga, che in questo caso sarebbero la data e l’ora.
awk '{ count[$3]++ } END { for (level in count) print level, count[level] }' logfile.log
Riepiloga le occorrenze di ogni livello di log
1
WARN 1
ERROR 1
DEBUG 2
INFO 6
# output
- Il risultato sarà un riassunto del numero di occorrenze di ciascun livello di log.
awk '{ $3="INFO"; print }' sample.log
Filtra campi specifici (ad esempio, dove il terzo campo è INFO)
2024-04-25 09:00:00 INFO Startup: Application starting
2024-04-25 09:01:00 INFO Config: Configuration loaded successfully
2024-04-25 09:02:00 INFO Database: Database connection established
2024-04-25 09:03:00 INFO User: New user registered (UserID: 1001)
2024-04-25 09:04:00 INFO Security: Attempted login with incorrect credentials (UserID: 1001)
2024-04-25 09:05:00 INFO Network: Network timeout on request (ReqID: 456)
2024-04-25 09:06:00 INFO Email: Notification email sent (UserID: 1001)
2024-04-25 09:07:00 INFO API: API call with response time over threshold (Duration: 350ms)
2024-04-25 09:08:00 INFO Session: User session ended (UserID: 1001)
2024-04-25 09:09:00 INFO Shutdown: Application shutdown initiated
INFO
# output
Questo comando estrarrà tutte le righe in cui il terzo campo è “INFO”.
💡 Suggerimento: Il separatore predefinito in awk è uno spazio. Se il tuo file di log utilizza un separatore diverso, puoi specificarlo utilizzando l’opzione -F. Ad esempio, se il tuo file di log utilizza i due punti come separatore, puoi utilizzare awk -F: '{ print $1 }' logfile.log per estrarre il primo campo.
Analisi dei file di log con cut
Il comando cut è un comando semplice ma potente utilizzato per estrarre sezioni di testo da ciascuna riga di input. Poiché i file di log sono strutturati e ogni campo è delimitato da un carattere specifico, come uno spazio, una tabulazione o un delimitatore personalizzato, cut è molto bravo nell’estrazione di quei campi specifici.
cut [options] [file]
La sintassi di base del comando cut è:
- Alcune opzioni comunemente utilizzate per il comando cut:
-d: Specifica un delimitatore utilizzato come separatore di campo.-f: Seleziona i campi da visualizzare.
-c : Specifica le posizioni dei caratteri.
cut -d ' ' -f 1 logfile.log
Ad esempio, il comando qui sotto estrae il primo campo (separato da uno spazio) da ogni riga del file di log:
Esempi d’usocutper l’analisi dei log
2024-04-25 08:23:01 INFO 192.168.1.10 User logged in successfully.
2024-04-25 08:24:15 WARNING 192.168.1.10 Disk usage exceeds 90%.
2024-04-25 08:25:02 ERROR 10.0.0.5 Connection timed out.
...
Supponiamo di avere un file di log strutturato come segue, dove i campi sono separati da spazi:
cutpuò essere usato nei seguenti modi:
cut -d ' ' -f 2 system.log
Estrazione dell'ora da ogni voce di log:
08:23:01
08:24:15
08:25:02
...
# Output
- Questo comando usa uno spazio come delimitatore e seleziona il secondo campo, che è la componente temporale di ogni voce di log.
cut -d ' ' -f 4 system.log
Estrazione degli indirizzi IP dai log:
192.168.1.10
192.168.1.10
10.0.0.5
# Output
- Questo comando estrae il quarto campo, che è l’indirizzo IP da ogni voce di log.
cut -d ' ' -f 3 system.log
Estrazione dei livelli di log (INFO, WARNING, ERROR):
INFO
WARNING
ERROR
# Output
- Questo estrae il terzo campo che contiene il livello di log.
Combinazionecutcon altri comandi:
grep "ERROR" system.log | cut -d ' ' -f 1,2
L'output di altri comandi può essere inviato al comando cut attraverso una pipe. Supponiamo di voler filtrare i log prima di tagliare. È possibile usare grep per estrarre le righe contenenti "ERROR" e quindi usare cut per ottenere informazioni specifiche da quelle righe:
2024-04-25 08:25:02
# Output
- Questo comando filtra prima le righe che contengono “ERROR”, poi estrae la data e l’ora da queste righe.
Estrazione di multipli campi:
cut -d ' ' -f 1,2,3 system.log`
È possibile estrarre più campi allo stesso tempo specificando un range o una lista separata da virgole di campi:
2024-04-25 08:23:01 INFO
2024-04-25 08:24:15 WARNING
2024-04-25 08:25:02 ERROR
...
# Output
Il comando precedente estrae i primi tre campi da ciascuna voce di registro, ovvero data, ora e livello di registro.
Analisi di file di log con sort e uniq
Ordinare e rimuovere i duplicati sono operazioni comuni quando si lavora con file di log. I comandi sort e uniq sono comandi potenti utilizzati per ordinare e rimuovere i duplicati dall’input, rispettivamente.
Sintassi di base di sort
sort [options] [file]
Il comando sort organizza le righe di testo in ordine alfabetico o numerico.
- Alcune opzioni chiave per il comando sort:
-n: Ordina il file presupponendo che il contenuto sia numerico.-r: Inverte l’ordine di ordinamento.-k: Specifica una chiave o numero di colonna per ordinare.
-u: Ordina e rimuove le righe duplicate.
La comanda uniq viene usata per filtrare o contare e rapportare righe ripetute in un file.
uniq [options] [input_file] [output_file]
La sintassi di uniq è:
- Alcune opzioni chiave per la comanda
uniqsono: -c: Prefissa alle righe il numero di occorrenze.-d: Stampa solo righe duplicate.
-u: Stampa solo righe uniche.
Esempi di utilizzo di sort e uniq insieme per la parsificazione dei log
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-26 ERROR Connection timed out.
- Prendiamo per esempio i seguenti record di log per queste dimostrazioni:
sort system.log
Ordinamento degli entry di log per data:
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Output
- Questo ordina gli entry di log in base alla data, se la data è il primo campo.
sort system.log | uniq
Ordinamento e rimozione di righe duplicate:
2024-04-25 INFO User logged in successfully.
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 ERROR Connection timed out.
2024-04-26 INFO Scheduled maintenance.
# Output
- Questa comanda ordina il file di log e lo incolonna verso
uniq, rimuovendo le righe duplicate.
sort system.log | uniq -c
Conteggio delle occorrenze di ciascuna riga:
2 2024-04-25 INFO User logged in successfully.
1 2024-04-25 WARNING Disk usage exceeds 90%.
2 2024-04-26 ERROR Connection timed out.
1 2024-04-26 INFO Scheduled maintenance.
# Output
- Ordina gli entry di log e poi conta ciascuna riga unica. Secondo l’output, la riga
'2024-04-25 INFO User logged in successfully.'è comparsa 2 volte nel file.
sort system.log | uniq -u
Identificare le voci di registro uniche:
2024-04-25 WARNING Disk usage exceeds 90%.
2024-04-26 INFO Scheduled maintenance.
# Output
- Questo comando mostra le righe uniche.
sort -k2 system.log
Ordinare per livello di log:
2024-04-26 ERROR Connection timed out.
2024-04-26 ERROR Connection timed out.
2024-04-25 INFO User logged in successfully.
2024-04-25 INFO User logged in successfully.
2024-04-26 INFO Scheduled maintenance.
2024-04-25 WARNING Disk usage exceeds 90%.
# Output
Ordina le voci in base al secondo campo, che è il livello di log.
8.4. Gestione dei processi Linux via linea di comando
- Un processo è un’istanza in esecuzione di un programma. Un processo consiste di:
- Uno spazio di indirizzi della memoria allocata.
- Stati del processo.
Proprietà quali la proprietà, gli attributi di sicurezza e l’uso delle risorse.
- Un processo ha anche un ambiente che consiste di:
- Variabili locali e globali
- Il contesto di pianificazione attuale
Risorse di sistema allocate, come porte di rete o descrittori di file.
Quando esegui il comando ls -l, il sistema operativo crea un nuovo processo per eseguire il comando. Il processo ha un ID, uno stato, e viene eseguito fino a quando il comando è completato.
Capire la creazione e il ciclo di vita del processo
In Ubuntu, tutti i processi hanno origine dal processo di sistema iniziale chiamato systemd, che è il primo processo avviato dalla kernel durante l’avvio.
Il processo systemd ha un ID di processo (PID) di 1 e si occupa di inizializzare il sistema, avviare e gestire altri processi e gestire i servizi di sistema. Tutti i processi rimanenti sul sistema sono discendenti da systemd.
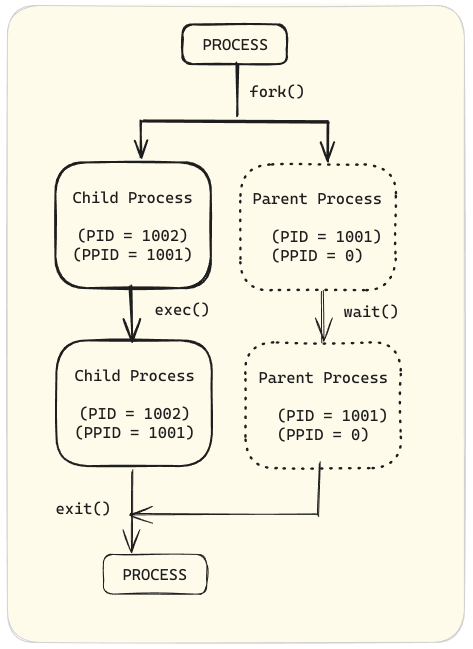
Un processo genitore duplica lo spazio di indirizzi del suo stesso processo (fork) per creare una nuova struttura di processo (figlio). Ogni nuovo processo è assegnato un unico ID di processo (PID) per la tracciatura e per scopi di sicurezza. Il PID e l’ID di processo del genitore (PPID) fanno parte dell’ambiente del nuovo processo. Qualsiasi processo può creare un processo figlio.
Attraverso la routine del fork, un processo figlio eredita le identità di sicurezza, i file descriptor precedenti e attuali, i privilegi di porta e risorse, le variabili di ambiente e il codice del programma. Un processo figlio può quindi eseguire il suo proprio codice del programma.
Di solito, un processo genitore dorme mentre il processo figlio si avvia, impostando una richiesta (wait) per essere notificato quando il figlio è completato.
Al termine, il processo figlio ha già chiuso o scartato le sue risorse e l’ambiente. L’unico risorsa rimasta, detta zombie, è una voce nella tabella dei processi. Il genitore, segnalato sveglio quando il figlio esce, pulisce la tabella dei processi dalla voce del figlio, liberando così l’ultima risorsa del processo figlio. Il processo genitore quindi continua l’esecuzione del suo codice del programma.
Comprendere gli stati dei processi

I processi in Linux attraversano differenti stati durante il loro ciclo di vita. L’ stato di un processo indica ciò che il processo sta facendo in quel momento e come interagisce con il sistema. I processi passano da uno stato all’altro in base al loro stato di esecuzione e all’algoritmo di scheduling del sistema.
| I processi in un sistema Linux possono essere in uno dei seguenti stati: | Stato |
| Descrizione | (new) |
| Stato iniziale quando un processo è creato tramite una chiamata di sistema fork. | Esecuzione pronta (R) |
| Il processo è pronto per l’esecuzione e attende di essere pianificato su un CPU. | In esecuzione (utente) (R) |
| Il processo sta esecutando in modalità utente, eseguendo applicazioni utente. | In esecuzione (kernel) (R) |
| Il processo sta esecutando in modalità kernel, gestendo chiamate di sistema o interruzioni hardware. | In attesa (S) |
| Il processo attende l’completamento di un evento (ad esempio, un’operazione I/O) ed è facilmente risvegliabile. | In attesa (non interrompibile) (D) |
| Il processo è in uno stato di sleep non interrompibile, attendendo una condizione specifica (di solito un’operazione I/O) per completare l’esecuzione e non può essere interrotto da segnali. | In attesa (sleep disco) (K) |
| Il processo attende l’completamento di operazioni di I/O del disco. | Inattivo (I) |
| Il processo è inattivo, non sta facendo nulla e attende un evento. | Arrestato (T) |
| L’esecuzione del processo è stata interrotta, solitamente da un segnale, e può essere ripresa in seguito. | Zombi (Z) |
Il processo ha completato l’esecuzione ma ha ancora una voce nella tabella dei processi, in attesa che suo genitore legga il suo stato di uscita.
| I processi si spostano tra questi stati nei seguenti modi: | Transizione |
| Descrizione | Fork |
| Crea un nuovo processo da un processo genitore, passando da (nuovo) a Attivo (pronto) (R). | Schedulazione |
| Il scheduler seleziona un processo attivo, lo fa passare allo stato In Esecuzione (utente) o In Esecuzione (kernel). | Esecuzione |
| Il processo passa da Attivo (pronto) (R) allo stato In Esecuzione (kernel) (R) quando è inizializzato per l’esecuzione. | Prelevazione o Re-schedulazione |
| Il processo può essere prelevato o re-schedulato, tornando allo stato Attivo (pronto) (R). | Chiamata di Sistema |
| Il processo effettua una chiamata di sistema, passando da In Esecuzione (utente) (R) allo stato In Esecuzione (kernel) (R). | Ritorno |
| Il processo completa una chiamata di sistema e torna ad In Esecuzione (utente) (R). | Attesa |
| Il processo attende un evento, passando da In Esecuzione (kernel) (R) ad uno degli stati Inattivo (S, D, K o I). | Evento o Segnale |
| Il processo viene svegliato da un evento o segnale, spostandolo da uno stato di Sleep back a Runnable (pronto) (R). | Sospendi |
| Il processo viene sospeso, passando da Esecuzione (kernel) o Runnable (pronto) allo Stato arrestato (T). | Riprendi |
| Il processo viene ripreso, spostandosi dallo Stato arrestato (T) di nuovo a Runnable (pronto) (R). | Esci |
| Il processo termina, passando da Esecuzione (utente) o Esecuzione (kernel) allo Stato fantasma (Z). | Mangiare |
Il processo genitore legge lo stato di uscita del processo fantasma, rimuovendolo dalla tabella dei processi.
Come visualizzare i processi
zaira@zaira:~$ ps aux
Puoi usare il comando ps insieme ad una combinazione di opzioni per visualizzare i processi su un sistema Linux. Il comando ps viene utilizzato per mostrare informazioni su una selezione di processi attivi. Per esempio, ps aux mostra tutti i processi in esecuzione sul sistema.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 168140 11352 ? Ss May21 0:18 /sbin/init splash
root 2 0.0 0.0 0 0 ? S May21 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? I< May21 0:00 [rcu_gp]
root 4 0.0 0.0 0 0 ? I< May21 0:00 [rcu_par_gp]
root 5 0.0 0.0 0 0 ? I< May21 0:00 [slub_flushwq]
root 6 0.0 0.0 0 0 ? I< May21 0:00 [netns]
root 11 0.0 0.0 0 0 ? I< May21 0:00 [mm_percpu_wq]
root 12 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_kthread]
root 13 0.0 0.0 0 0 ? I May21 0:00 [rcu_tasks_rude_kthread]
*... output truncated ....*
# Output
- L’output sopra mostra una fotografia del sistema in esecuzione attuale. Ogni riga rappresenta un processo con le seguenti colonne:
UTENTE: L’utente che possiede il processo.PID: L’ID del processo.%CPU: L’utilizzo della CPU del processo.%MEM: L’utilizzo della memoria del processo.VSZ: La dimensione della memoria virtuale del processo.RSS: La dimensione del set residente, ossia la memoria fisica non scambiata che un task ha utilizzato.TTY: Il terminale di controllo del processo. Un?indica che non c’è un terminale di controllo.Ss: Leader di sessione. Questo è un processo che ha avviato una sessione ed è il leader di un gruppo di processi ed è in grado di controllare i segnali del terminale. La primaSindica lo stato di sonno, e la secondasindica che è un leader di sessione.START: L’ora o la data di avvio del processo.TIME: Il tempo cumulativo della CPU.
COMMAND: Il comando che ha avviato il processo.
Processi in background e in foreground
In questa sezione, imparerai come puoi controllare i job eseguendoli in background o in foreground.
Un job è un processo avviato dalla shell. Quando esegui un comando nel terminale, viene considerato un job. Un job può essere eseguito in foreground o in background.
- Per dimostrare il controllo, creerai prima tre processi e li eseguirai in background. Successivamente, elencherai i processi e li alternerai tra foreground e background. Vedrai come metterli in pausa o farli uscire completamente.
Crea Tre Processi
Apre un terminale e avvia tre processi a lungo termine. Usa il comando sleep che tiene il processo in esecuzione per un numero specificato di secondi.
sleep 300 &
sleep 400 &
sleep 500 &
# esegui il comando sleep per 300, 400, e 500 secondi
- Il carattere
&alla fine di ogni comando sposta il processo in background.
Visualizza I Job In Background
jobs
Usa il comando jobs per visualizzare l’elenco dei job in background.
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
- L’output dovrebbe essere più o meno come questo:
Porta Un Job In Background In Foreground
fg %1
Per portare un job in background in foreground, usa il comando fg seguito dal numero del job. Per esempio, per portare il primo job (sleep 300) in foreground:
- Questo porterà il job
1in foreground.
Sposta Il Job In Foreground Di Nuovo In Background
Mentre il lavoro è in esecuzione in primo piano, puoi sospendere e spostarlo in background premendo Ctrl+Z per sospendere il lavoro.
zaira@zaira:~$ fg %1
sleep 300
^Z
[1]+ Stopped sleep 300
zaira@zaira:~$ jobs
Un lavoro sospeso apparirà così:
[1]+ Stopped sleep 300
[2] Running sleep 400 &
[3]- Running sleep 500 &
# lavoro sospeso
Ora usa il comando bg per riprendere il lavoro con ID 1 in background.
# Premi Ctrl+Z per sospendere il lavoro in primo piano
bg %1
- # Poi, riprendilo in background
jobs
[1] Running sleep 300 &
[2]- Running sleep 400 &
[3]+ Running sleep 500 &
Mostra di nuovo i lavori
- In questo esercizio, hai:
- Avviato tre processi in background usando i comandi sleep.
- Usato jobs per visualizzare l’elenco dei lavori in background.
- Portato un lavoro in primo piano con
fg %numero_lavoro. - Sospeso il lavoro con
Ctrl+Ze spostato nuovamente in background conbg %numero_lavoro.
Usato nuovamente jobs per verificare lo stato dei lavori in background.
Adesso sai come controllare i lavori.
Uccidere processi
È possibile terminare un processo non rispondente o indesiderato utilizzando il comando kill. Il comando kill invia un segnale a un ID di processo, chiedendogli di terminare.
Sono disponibili diverse opzioni con il comando kill.
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24)
...terminated
# Opzioni disponibili con kill
- Ecco alcuni esempi del comando
killin Linux: - Questo comando invia il segnale predefinito
SIGTERMal processo con PID 1234, richiedendone la terminazione. - Questo comando invia il segnale predefinito
SIGTERMa tutti i processi con il nome specificato. - Questo comando invia il segnale
SIGKILLal processo con PID 1234, terminandolo forzatamente. - Questo comando invia il segnale
SIGSTOPal processo con PID 1234, fermandolo.
Questo comando invia il segnale predefinito SIGTERM a tutti i processi appartenenti all’utente specificato.
Questi esempi mostrano vari modi di utilizzare il comando kill per gestire i processi in un ambiente Linux.
Qui ci sono le informazioni sulle opzioni del comando kill e i segnali in forma tabellare: questa tabella riepiloga le opzioni e i segnali più comuni del comando kill utilizzati in Linux per la gestione dei processi. |
Comando / Opzione | Segnale |
| Descrizione | kill <pid> |
SIGTERM |
| Richiede al processo di terminare in modo grazioso (segnale predefinito). | kill -9 <pid> |
SIGKILL |
| Forza il processo a terminare immediatamente senza pulizia. | kill -SIGKILL <pid> |
SIGKILL |
| Forza il processo a terminare immediatamente senza pulizia. | kill -15 <pid> |
SIGTERM |
Invia esplicitamente il segnale SIGTERM per richiedere la terminazione in modo grazioso. |
kill -SIGTERM <pid> |
SIGTERM |
Invia esplicitamente il segnale SIGTERM per richiedere la terminazione in modo grazioso. |
kill -1 <pid> |
SIGHUP |
| Tradizionalmente significa “sospendere”; può essere usato per ricaricare i file di configurazione. | kill -SIGHUP <pid> |
SIGHUP |
| Tradizionalmente significa “metti da parte”; può essere utilizzato per reimpostare i file di configurazione. | kill -2 <pid> |
SIGINT |
Richiede al processo di terminare (uguale a premere Ctrl+C nel terminale). |
kill -SIGINT <pid> |
SIGINT |
Richiede al processo di terminare (uguale a premere Ctrl+C nel terminale). |
kill -3 <pid> |
SIGQUIT |
| Causa il termine del processo e genera un core dump per il debug. | kill -SIGQUIT <pid> |
SIGQUIT |
| Causa il termine del processo e genera un core dump per il debug. | kill -19 <pid> |
SIGSTOP |
| Mette in pausa il processo. | kill -SIGSTOP <pid> |
SIGSTOP |
| Mette in pausa il processo. | kill -18 <pid> |
SIGCONT |
| Riprende un processo in pausa. | kill -SIGCONT <pid> |
SIGCONT |
| Riprende un processo in pausa. | killall <name> |
Variabile |
| Invia un segnale a tutti i processi con il nome specificato. | killall -9 <name> |
SIGKILL |
| Forza la terminazione di tutti i processi con il nome dato. | pkill |
Variabile |
| Invia un segnale ai processi in base a una corrispondenza del modello. | pkill -9 |
SIGKILL |
| Forza la terminazione di tutti i processi corrispondenti al modello. | xkill |
SIGKILL |
Utilità grafica che consente di cliccare su una finestra per terminare il processo corrispondente.
8.5. Stream standard di input e output in Linux
- La lettura dell’input e la scrittura dell’output sono una parte essenziale per capire la linea di comando e la scrittura di script in shell. In Linux, ogni processo ha tre stream predefiniti:
- Il file descriptor per
stdinè0. - Standard Output (
stdout): Questo è lo stream di output predefinito in cui un processo scrive il suo output. Per impostazione predefinita, l’output standard è il terminale. L’output può anche essere ridirezionato su un file o un altro programma. Il descrittore di file perstdoutè1.
Standard Error (stderr): Questo è lo stream di errori predefinito in cui un processo scrive i suoi messaggi di errore. Per impostazione predefinita, l’errore standard è il terminale, consentendo di visualizzare i messaggi di errore anche se stdout è ridirezionato. Il descrittore di file per stderr è 2.
Redirezione e Pipeline
Redirezione: È possibile ridirigere gli stream di errore e output su file o altri comandi. Ad esempio:
ls > output.txt
# Ridirezionare stdout su un file
ls non_existent_directory 2> error.txt
# Ridirezionare stderr su un file
ls non_existent_directory > all_output.txt 2>&1
# Ridirezionare sia stdout che stderr su un file
- Nell’ultimo comando,
ls non_existent_directory: elenca i contenuti di una directory chiamata non_existent_directory. Poiché questa directory non esiste,lsgenererà un messaggio di errore.> all_output.txt: L’operatore>reindirizza l’output standard (stdout) del comandolsnel fileall_output.txt. Se il file non esiste, verrà creato. Se esiste, i suoi contenuti verranno sovrascritti.
2>&1:: Qui, 2 rappresenta il descrittore di file per l’errore standard (stderr). &1 rappresenta il descrittore di file per l’output standard (stdout). Il carattere & è utilizzato per specificare che 1 non è il nome del file ma un descrittore di file.
Quindi, 2>&1 significa “inoltra stderr (2) ovunque stdout (1) sia attualmente diretto”, il che in questo caso è il file all_output.txt. Perciò, sia l’output (se ce ne fosse stato) che il messaggio di errore da ls verranno scritti in all_output.txt.
Pipeline:
ls | grep image
Puoi usare i tubi (|) per passare l'output di un comando come input per un altro:
image-10.png
image-11.png
image-12.png
image-13.png
... Output truncated ...
# Output
8.6 Automazione in Linux – Automatizza attività con i job cron
Cron è una potente utilità per la pianificazione di job disponibile nei sistemi operativi Unix-like. Configurando cron, puoi impostare job automatizzati che vengono eseguiti su base giornaliera, settimanale, mensile o ad altri orari specifici. Le capacità di automazione fornite da cron rivestono un ruolo cruciale nella amministrazione dei sistemi Linux.
Il demone crond (un tipo di programma che viene eseguito in background) consente la funzionalità di cron. Cron legge le crontab (tabelle cron) per l’esecuzione di script predefiniti.
Usando una sintassi specifica, puoi configurare un job cron per pianificare script o altri comandi per l’esecuzione automatica.
Cos’è un job cron in Linux?
Qualsiasi compito che pianifichi tramite crons si chiama un job cron.
Adesso, vediamo come funzionano i job cron.
Come controllare l’accesso ai crons
Per usare i job cron, un amministratore deve consentire l’aggiunta di job cron per gli utenti nel file /etc/cron.allow.
Se riceve una richiesta del genere, significa che non hai i permessi necessari per utilizzare cron.
![]()
Per consentire a John di utilizzare cron, include il suo nome nel file /etc/cron.allow. Crea il file se non esiste. Questo consentirà a John di creare e modificare job cron.
Gli utenti possono anche essere rifiutati accesso alle cron job aggiungendo i loro nomi utente nel file /etc/cron.d/cron.deny.
Come aggiungere job cron in Linux
Prima di utilizzare le job cron, dovrai controllare lo stato del servizio cron. Se cron non è installato, puoi facilmente scaricarlo tramite il package manager. Usa questo comando per controllare:
sudo systemctl status cron.service
# Controlla il servizio cron su un sistema Linux
Sintassi job cron
- I crontab usano i seguenti flag per aggiungere e elencare job cron:
crontab -e: modifica le entry crontab per aggiungere, eliminare o modificare job cron.crontab -l: elenca tutti i job cron per l’utente corrente.crontab -u username -l: elenca i cron di un altro utente.
crontab -u username -e: modifica i cron di un altro utente.
Quando elenci le cron job e esistono, vedrai qualcosa di simile a questo:
* * * * * sh /path/to/script.sh
# Esempio di lavoro di cron
- Nell’esempio sopra,
* rappresenta minuti ore giorni mesi giorni settimana, rispettivamente. Vedere i dettagli di questi valori qui sotto: |
VALORE | |
| DESCRIZIONE | Minuti | 0-59 |
| Il comando verrà eseguito al minuto specifico. | Ore | 0-23 |
| Il comando verrà eseguito all’ora specifica. | Giorni | 1-31 |
| I comandi verranno eseguiti in questi giorni del mese. | Mesi | 1-12 |
| Il mese in cui devono essere eseguiti i compiti. | Giorni della settimana | 0-6 |
- Giorni della settimana in cui verranno eseguiti i comandi. Qui, 0 è Domenica.
shrappresenta che lo script è uno script bash e dovrebbe essere eseguito da/bin/bash.
/percorso/allo/script.sh specifica il percorso dello script.
* * * * * sh /path/to/script/script.sh
| | | | | |
| | | | | Command or Script to Execute
| | | | |
| | | | |
| | | | |
| | | | Day of the Week(0-6)
| | | |
| | | Month of the Year(1-12)
| | |
| | Day of the Month(1-31)
| |
| Hour(0-23)
|
Min(0-59)
Ecco un riassunto della sintassi del lavoro di cron:
Esempi di lavoro di cron
| Di seguito alcuni esempi di pianificazione dei lavori di cron. | PIANIFICA |
| VALORE PIANIFICATO | 5 0 * 8 * |
| Alle 00:05 in agosto. | 5 4 * * 6 |
| Alle 04:05 del sabato. | 0 22 * * 1-5 |
Alle 22:00 ogni giorno della settimana dal lunedì al venerdì.
Va bene se non riesci a comprendere tutto in una volta. Puoi esercitarti e generare pianificazioni cron sul sito web crontab guru.
Come impostare un lavoro cron
- In questa sezione, vedremo un esempio di come pianificare uno script semplice con un lavoro cron.
#!/bin/bash
echo `date` >> date-out.txt
Crea uno script chiamato date-script.sh che stampa la data e l’ora di sistema e le aggiunge a un file. Lo script è mostrato di seguito:
chmod 775 date-script.sh
2. Rendi lo script eseguibile dando i relativi permessi di esecuzione.
3. Aggiungi lo script nel crontab utilizzando il comando crontab -e.
*/1 * * * * /bin/sh /root/date-script.sh
Qui, l’abbiamo pianificato per essere eseguito ogni minuto.
cat date-out.txt
4. Controlla l'output del file date-out.txt. Secondo lo script, la data di sistema dovrebbe essere stampata in questo file ogni minuto.
Wed 26 Jun 16:59:33 PKT 2024
Wed 26 Jun 17:00:01 PKT 2024
Wed 26 Jun 17:01:01 PKT 2024
Wed 26 Jun 17:02:01 PKT 2024
Wed 26 Jun 17:03:01 PKT 2024
Wed 26 Jun 17:04:01 PKT 2024
Wed 26 Jun 17:05:01 PKT 2024
Wed 26 Jun 17:06:01 PKT 2024
Wed 26 Jun 17:07:01 PKT 2024
# output
Come risolvere i problemi nei cron
I cron sono molto utili, ma potrebbero non funzionare sempre come previsto. Fortunatamente, ci sono alcuni metodi efficaci che puoi utilizzare per risolverli.
1. Controlla la pianificazione.
Innanzitutto, puoi provare a verificare la pianificazione impostata per il cron. Puoi farlo con la sintassi che hai visto nelle sezioni precedenti.
2. Controlla i log di cron.
Prima di tutto, devi controllare se il cron è stato eseguito al tempo previsto o meno. In Ubuntu, puoi verificarlo dai log di cron situati in /var/log/syslog.
Se c’è una voce in questi log al momento corretto, significa che il cron è stato eseguito secondo il programma che hai impostato.
1 Jun 26 17:02:01 zaira-ThinkPad CRON[27834]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
2 Jun 26 17:02:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
3 Jun 26 17:03:01 zaira-ThinkPad CRON[28255]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
4 Jun 26 17:03:02 zaira-ThinkPad systemd[2094]: Started Tracker metadata extractor.
5 Jun 26 17:04:01 zaira-ThinkPad CRON[28538]: (zaira) CMD (/bin/sh /home/zaira/date-script.sh)
Di seguito sono riportati i log del nostro esempio di job di cron. Nota la prima colonna che mostra il timestamp. Il percorso dello script è anche menzionato alla fine della riga. Le righe #1, 3 e 5 mostrano che lo script è stato eseguito come previsto.
3. Redireziona l’output di cron in un file.
Puoi redirezionare l'output di cron in un file e controllare il file per eventuali errori.
* * * * * sh /path/to/script.sh &> log_file.log
# Redireziona l’output di cron in un file
8.7. Basi di rete di Linux
Linux offre numerosi comandi per visualizzare informazioni relative alla rete. In questa sezione discuteremo brevemente alcuni comandi.
Visualizza le interfacce di rete con ifconfig
ifconfig
Il comando ifconfig fornisce informazioni sulle interfacce di rete. Ecco un esempio di output:
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::a00:27ff:fe4e:66a1 prefixlen 64 scopeid 0x20<link>
ether 08:00:27:4e:66:a1 txqueuelen 1000 (Ethernet)
RX packets 1024 bytes 654321 (654.3 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 512 bytes 123456 (123.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 256 bytes 20480 (20.4 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 256 bytes 20480 (20.4 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# Output
L’output del comando ifconfig mostra le interfacce di rete configurate sul sistema, insieme a dettagli quali indirizzi IP, indirizzi MAC, statistiche sui pacchetti, e altro.
Queste interfacce possono essere dispositivi fisici o virtuali.
Per estrarre gli indirizzi IPv4 e IPv6, puoi usare ip -4 addr e ip -6 addr rispettivamente.
Visualizza l’attività di rete connetstat
Il comando netstat mostra l’attività di rete e le statistiche fornendo le seguenti informazioni:
- Ecco alcuni esempi di utilizzo del comando
netstatnella riga di comando: - Mostra tutti i socket in ascolto e non in ascolto:
- Mostra solo le porte in ascolto:
- Mostra le statistiche di rete:
- Mostra la tabella di routing:
- Visualizza le connessioni TCP:
- Mostra le connessioni UDP:
- Mostra le interfacce di rete:
- Visualizza il PID e i nomi dei programmi per le connessioni:
- Mostra le statistiche per un protocollo specifico (per esempio, TCP):
Visualizza informazioni estese:
Controlla la connettività di rete tra due dispositivi usando ping
ping google.com
ping viene usato per testare la connettività di rete tra due dispositivi. Invia pacchetti ICMP al dispositivo di destinazione e attende una risposta.
ping google.com
PING google.com (142.250.181.46) 56(84) bytes of data.
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=1 ttl=60 time=78.3 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=2 ttl=60 time=141 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=3 ttl=60 time=205 ms
64 bytes from fjr04s06-in-f14.1e100.net (142.250.181.46): icmp_seq=4 ttl=60 time=100 ms
^C
--- google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 78.308/131.053/204.783/48.152 ms
ping verifica se si ottiene una risposta indietro senza ottenere un timeout.
— google.com ping statistiche —
Puoi fermare la risposta con Ctrl + C.
Testa gli endpoint con il comando curl
- Il comando
curlsta per “client URL”. Viene usato per trasferire dati verso o da un server. Può anche essere usato per testare gli endpoint API che aiutano a risolvere errori di sistema e applicazione.
curl http://www.official-joke-api.appspot.com/random_joke
{"type":"general",
"setup":"What did the fish say when it hit the wall?","punchline":"Dam.","id":1}
- Ad esempio, puoi usare
http://www.official-joke-api.appspot.com/per sperimentare con il comandocurl.
curl -o random_joke.json http://www.official-joke-api.appspot.com/random_joke
Il comando curl senza opzioni utilizza il metodo GET per default.
curl -osalva l’output nel file menzionato.
curl -I http://www.official-joke-api.appspot.com/random_joke
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Vary: Accept-Encoding
X-Powered-By: Express
Access-Control-Allow-Origin: *
ETag: W/"71-NaOSpKuq8ChoxdHD24M0lrA+JXA"
X-Cloud-Trace-Context: 2653a86b36b8b131df37716f8b2dd44f
Content-Length: 113
Date: Thu, 06 Jun 2024 10:11:50 GMT
Server: Google Frontend
# salva l’output in random_joke.json
curl -I recupera solo gli header.
8.8. Rilevamento problemi Linux: strumenti e tecniche
Rapporto di attività del sistema con sar
Il comando sar in Linux è un potente strumento per la raccolta, il reporting e il salvataggio di informazioni sull’attività del sistema. Fa parte del pacchetto sysstat ed è largamente utilizzato per il monitoraggio della performance del sistema nel tempo.
Per utilizzare sar è necessario prima installare sysstat utilizzando sudo apt install sysstat.
Installato, avviare il servizio con sudo systemctl start sysstat.
Verificare lo stato con sudo systemctl status sysstat.
sar [options] [interval] [count]
Una volta che lo stato è attivo, il sistema comincerà a raccogliere varie statistiche che puoi utilizzare per accedere e analizzare i dati storici. Vedremo questo dettagliatamente a breve.
sar -u 1 3
La sintassi del comando sar è la seguente:
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:09:26 CPU %user %nice %system %iowait %steal %idle
19:09:27 all 3.78 0.00 2.18 0.08 0.00 93.96
19:09:28 all 4.02 0.00 2.01 0.08 0.00 93.89
19:09:29 all 6.89 0.00 2.10 0.00 0.00 91.01
Average: all 4.89 0.00 2.10 0.06 0.00 92.95
Ad esempio, sar -u 1 3 mostrerà le statistiche sull’utilizzo della CPU ogni secondo per tre volte.
# Output
Ecco alcuni casi d’uso comuni e esempi di come utilizzare il comando sar.
sar può essere utilizzato per varie finalità:
sar -r 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:10:46 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
19:10:47 4600104 8934352 5502124 36.32 375844 4158352 15532012 65.99 6830564 2481260 264
19:10:48 4644668 8978940 5450252 35.98 375852 4165648 15549184 66.06 6776388 2481284 36
19:10:49 4646548 8980860 5448328 35.97 375860 4165648 15549224 66.06 6774368 2481292 116
Average: 4630440 8964717 5466901 36.09 375852 4163216 15543473 66.04 6793773 2481279 139
1. Utilizzo della memoria
Per controllare l’utilizzo della memoria (libera e utilizzata), usare:
Questo comando mostra le statistiche sulla memoria ogni secondo tre volte.
sar -S 1 3
sar -S 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:11:20 kbswpfree kbswpused %swpused kbswpcad %swpcad
19:11:21 8388604 0 0.00 0 0.00
19:11:22 8388604 0 0.00 0 0.00
19:11:23 8388604 0 0.00 0 0.00
Average: 8388604 0 0.00 0 0.00
2. Utilizzo dello spazio swap
Per visualizzare le statistiche sull’utilizzo dello spazio swap, usare:
Questo comando aiuta a monitorare l’utilizzo dello swap, che è cruciale per i sistemi che stanno esaurendo la memoria fisica.
sar -d 1 3
3. Carico dei dispositivi I/O
Per segnalare l’attività dei dispositivi a blocchi e delle partizioni dei dispositivi a blocchi:
Questo comando fornisce statistiche dettagliate sui trasferimenti di dati da e verso i dispositivi a blocchi ed è utile per diagnosticare i colli di bottiglia dell’I/O.
sar -n DEV 1 3
5. Statistiche di rete
sar -n DEV 1 3
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:12:47 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19:12:48 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19:12:48 wlp3s0 10.00 3.00 1.83 0.37 0.00 0.00 0.00 0.00
19:12:48 br-5129d04f972f 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
.
.
.
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: enp2s0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...output truncated...
Per visualizzare le statistiche di rete, come il numero di pacchetti ricevuti (trasmessi) dall’interfaccia di rete:
# -n DEV dice a sar di segnalare le interfacce dei dispositivi di rete
Questo visualizza le statistiche di rete ogni secondo per tre secondi, aiutando nel monitoraggio del traffico di rete.
- 6. Dati storici
- # sono “true” e “false”. Non inserire altri valori, saranno
- Configurare l’intervallo di raccolta dati: Modificare la configurazione del lavoro cron per impostare l’intervallo di raccolta dati.
sar -u -f /var/log/sysstat/sa04
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
15:20:49 LINUX RESTART (12 CPU)
16:13:30 LINUX RESTART (12 CPU)
18:16:00 CPU %user %nice %system %iowait %steal %idle
18:16:01 all 0.25 0.00 0.67 0.08 0.00 99.00
Average: all 0.25 0.00 0.67 0.08 0.00 99.00
Sostituisci <GG> con il giorno del mese per il quale vuoi visualizzare i dati.
Nel comando seguente, /var/log/sysstat/sa04 fornisce statistiche per il quarto giorno del mese corrente.
sar -I SUM 1 3
7. Interruzioni CPU in tempo reale
Linux 6.5.0-28-generic (zaira-ThinkPad) 04/06/24 _x86_64_ (12 CPU)
19:14:22 INTR intr/s
19:14:23 sum 5784.00
19:14:24 sum 5694.00
19:14:25 sum 5795.00
Average: sum 5757.67
Per osservare le interruzioni per secondo servite dalla CPU in tempo reale, usa questo comando:
# Output
Questo comando aiuta a monitorare la frequenza con cui la CPU gestisce le interruzioni, cosa cruciale per il tuning del performance in tempo reale.
Questi esempi illustrano come puoi usare sar per monitorare vari aspetti del rendimento del sistema. L’uso regolare di sar può aiutare a identificare i colli di bottiglia del sistema e a garantire che le applicazioni contino a funzionare efficientemente.
8.9. Strategia generale di troubleshooting per i server
Perché abbiamo bisogno di capire il monitoraggio?
Il monitoraggio del sistema è un aspetto importante dell’amministrazione del sistema. Le applicazioni critiche richiedono un alto livello di proattività per prevenire i guasti e ridurre l’impatto dell’interruzione.
Linux offre strumenti molto potenti per valutare lo stato di salute del sistema. In questa sezione, imparerai i vari metodi disponibili per controllare lo stato di salute del tuo sistema e identificare i colli di bottiglia.
[user@host ~]$ uptime 19:15:00 up 1:04, 0 users, load average: 2.92, 4.48, 5.20
Trova il carico medio e l’uptime del sistema
I riavvii del sistema possono occasionalmente disturbare alcune configurazioni. Per controllare quanto tempo la macchina è stata attiva, usa il comando: uptime. Oltre all’uptime, il comando mostra anche il carico medio.
Il carico medio è il carico del sistema negli ultimi 1, 5 e 15 minuti. Un’occhiata rapida indica se il carico del sistema sembra aumentare o diminuire nel tempo.
Nota: La coda ideale della CPU è 0. Questo è possibile solo quando non ci sono code di attesa per la CPU.
lscpu
Il carico per-CPU può essere calcolato dividendo il carico medio per il numero totale di CPU disponibili.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
.
.
.
output omitted
Per trovare il numero di CPU, usa il comando lscpu.
# output
Se la media di carico sembra aumentare e non diminuire, i CPU sono sovraccaricati. C’è un processo bloccato o una perdita di memoria.
free -mh
Calcolo della memoria libera
total used free shared buff/cache available
Mem: 14Gi 3.5Gi 7.7Gi 109Mi 3.2Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
A volte, un alto utilizzo della memoria potrebbe causare problemi. Per controllare la memoria disponibile e quella in uso, usare il comando free.
# output
Calcolo dello spazio disco
df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 1.5G 2.4M 1.5G 1% /run
/dev/nvme0n1p2 103G 34G 65G 35% /
tmpfs 7.3G 42M 7.2G 1% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
efivarfs 246K 93K 149K 39% /sys/firmware/efi/efivars
/dev/nvme0n1p3 130G 47G 77G 39% /home
/dev/nvme0n1p1 511M 6.1M 505M 2% /boot/efi
tmpfs 1.5G 140K 1.5G 1% /run/user/1000
Per assicurarsi che il sistema sia in salute, non dimenticare lo spazio disco. Per elencare tutti i punti di mount disponibili e i loro rispettivi percentuali utilizzati, usare il comando riportato di seguito. Idealmente, lo spazio disco utilizzato non dovrebbe superare il 80%.
Il comando df fornisce dettagliati spazi disco.
Determinazione degli stati dei processi
[user@host ~]$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
runner 1 0.1 0.0 1535464 15576 ? S 19:18 0:00 /inject/init
runner 14 0.0 0.0 21484 3836 pts/0 S 19:21 0:00 bash --norc
runner 22 0.0 0.0 37380 3176 pts/0 R+ 19:23 0:00 ps aux
Gli stati dei processi possono essere monitorati per vedere se ci sono processi bloccati con un alto utilizzo della memoria o del CPU.
Ciò che abbiamo visto prima è che il comando ps fornisce informazioni utili riguardo un processo. Guardare alle colonne CPU e MEM.
Monitoraggio del sistema in tempo reale
Il monitoraggio in tempo reale fornisce una finestra sullo stato reale del sistema.
Una utility che puoi usare per fare questo è il comando top.
Il comando top mostra una visualizzazione dinamica dei processi del sistema, mostrando un intestazione riepilogativa seguita da una lista dei processi o thread. Contrariamente al suo omologo statico ps, top aggiorna in continuazione le statistiche del sistema.
Con top, puoi visualizzare dettagli ben organizzati in una finestra compatta. Esistono numerose bandiere, scorciatoie e metodi di evidenziazione che accompagnano top.
Puoi anche eliminare processi usando top. Per far questo, premi k e poi inserisci l’ID del processo.
Interpretazione dei log
I log del sistema e delle applicazioni contengono tonnellate di informazioni sulla situazione del sistema. Contengono informazioni utili e codici di errore che indicano gli errori. Se cerci codici di errore nei log, la identificazione e il tempo per la correzione delle issue possono essere notevolmente ridotti.
Analisi delle porte di rete
L’aspetto della rete non deve essere ignorato poiché i problemi di rete sono comuni e potrebbero influire sul sistema e sul traffico. Alcuni problemi di rete comuni includono l’esaurimento delle porte, la soffocatura delle porte, risorse non rilasciate e così via.
| Per identificare questi problemi, dobbiamo comprendere lo stato delle porte. | Alcuni stati delle porte sono spiegati brevemente qui: |
| Stato | Descrizione |
| LISTEN | Rappresenta le porte in attesa di una richiesta di connessione da qualsiasi remote TCP e porta. |
| ESTABLISHED | Rappresenta connessioni aperte in cui i dati ricevuti possono essere consegnati al destinatario. |
| TIME WAIT | Rappresenta il tempo di attesa per garantire l’acknowledgment della richiesta di termina connessione. |
FIN WAIT2
Rappresenta l’attesa di una richiesta di termina connessione da parte del TCP remoto.
[user@host ~]$ /sbin/sysctl net.ipv4.ip_local_port_range
net.ipv4.ip_local_port_range = 15000 65000
Esploriamo come possiamo analizzare le informazioni relative alle porte in Linux.
Intervalli di porte: Gli intervalli di porte sono definiti nel sistema, e l’intervallo può essere incrementato/decrementato di conseguenza. Nell’estratto di codice seguente, l’intervallo va da 15000 a 65000, per un totale di 50000 porte disponibili (65000 – 15000). Se le porte utilizzate stanno raggiungendo o superando questo limite, allora c’è un problema.
L’errore riportato nei log in questi casi può essere Failed to bind to port o Too many connections.
Identificazione della perdita di pacchetti
Nella monitoraggio del sistema, abbiamo bisogno di assicurarci che la comunicazione in arrivo e in partenza sia intatta.
[user@host ~]$ ping 10.13.6.113
PING 10.13.6.141 (10.13.6.141) 56(84) bytes of data.
64 bytes from 10.13.6.113: icmp_seq=1 ttl=128 time=0.652 ms
64 bytes from 10.13.6.113: icmp_seq=2 ttl=128 time=0.593 ms
64 bytes from 10.13.6.113: icmp_seq=3 ttl=128 time=0.478 ms
64 bytes from 10.13.6.113: icmp_seq=4 ttl=128 time=0.384 ms
64 bytes from 10.13.6.113: icmp_seq=5 ttl=128 time=0.432 ms
64 bytes from 10.13.6.113: icmp_seq=6 ttl=128 time=0.747 ms
64 bytes from 10.13.6.113: icmp_seq=7 ttl=128 time=0.379 ms
^C
--- 10.13.6.113 ping statistics ---
7 packets transmitted, 7 received,0% packet loss, time 6001ms
rtt min/avg/max/mdev = 0.379/0.523/0.747/0.134 ms
Un comando utile è ping. ping colpisce il sistema di destinazione e porta indietro la risposta. Notate le ultime linee di statistica che mostrano la percentuale di perdita di pacchetti e il tempo.
# ping indirizzo IP destinazione
I pacchetti possono anche essere catturati in tempo reale usando tcpdump. Ne parleremo più tardi.
Raccolta di statistiche per l’autopsia dell’incidente
- È sempre una buona pratica raccogliere alcune statistiche che saranno utili per identificare la causa radicale in seguito. Di solito, dopo il riavvio del sistema o il riavvio dei servizi, perdiamo lo snapshot del sistema precedente e i log.
Di seguito alcuni metodi per catturare lo snapshot del sistema.
- Backup Log
Prima di apportare eventuali modifiche, copiare i file di log in un’altra posizione. Questo è fondamentale per capire in quale stato era il sistema al momento del problema. A volte i file di log sono l’unico punto di accesso per osservare gli stati del sistema passati, poiché altri dati in tempo reale vengono persi.
sudo tcpdump -i any -w
TCP Dump
Tcpdump è un'utilità a riga di comando che consente di catturare e analizzare il traffico di rete in entrata e in uscita. È principalmente utilizzato per aiutare a risolvere problemi di rete. Se si ritiene che il traffico del sistema sia influenzato, eseguire tcpdump come segue:
# Dove,
# -i any cattura il traffico da tutte le interfacce
# -w specifica il nome del file di output
# Interrompere il comando dopo qualche minuto, in quanto la dimensione del file potrebbe aumentare
# utilizzare l’estensione del file come .pcap
Una volta catturato tcpdump, è possibile utilizzare strumenti come Wireshark per l’analisi visiva del traffico.
Conclusione
Grazie per aver letto il libro fino in fondo. Se lo ha trovato utile, considerare la condivisione con altri.
Il libro non finisce qui, però. Continuerò a migliorarlo e ad aggiungere nuovi materiali in futuro. Se hai trovato qualche problema o se vuoi suggerire delle migliorie, sentiti libero a aprire un PULL REQUEST/ISSUES.
- Mantieni le connessioni e prosegui il tuo percorso di apprendimento!
-
LinkedIn: Condivido articoli e post sulla tecnologia li. Lascia una raccomandazione su LinkedIn ed endorziami sulle competenze rilevanti.
Accedi a contenuti esclusivi: Per assistenza personalizzata e contenuti esclusivi vai qui.
Accedi a contenuti esclusivi: Per assistenza personalizzata e contenuti esclusivi vai qui.
Source:
https://www.freecodecamp.org/news/learn-linux-for-beginners-book-basic-to-advanced/