













I big data si sono evoluti significativamente dalla loro nascita alla fine degli anni 2000. Molte organizzazioni si sono adattate rapidamente alla tendenza e hanno costruito le loro piattaforme di big data utilizzando strumenti open source come Apache Hadoop. Successivamente, queste aziende hanno iniziato a incontrare difficoltà nella gestione delle esigenze di elaborazione dei dati in rapida evoluzione. Hanno affrontato sfide nel gestire le modifiche a livello di schema, l’evoluzione degli schemi di partizione e il dover tornare indietro nel tempo per esaminare i dati.
Ho affrontato sfide simili mentre progettavo sistemi distribuiti su larga scala negli anni 2010 per una grande azienda tecnologica e un cliente nel settore sanitario. Alcuni settori necessitano di queste capacità per aderire alle normative bancarie, finanziarie e sanitarie. Aziende fortemente orientate ai dati come Netflix hanno affrontato sfide simili. Hanno inventato un formato di tabella chiamato “Iceberg”, che si basa sui file di dati esistenti e offre funzionalità chiave sfruttando la sua architettura. Questo è rapidamente diventato il principale progetto ASF, poiché ha suscitato un rapido interesse nella comunità dei dati. Esplorerò le 5 principali caratteristiche chiave di Apache Iceberg in questo articolo con esempi e diagrammi.
1. Viaggio nel tempo

Figura 1: Viaggio nel tempo nel formato di tabella Apache Iceberg (immagine creata dall’autore)
Questa funzionalità ti consente di interrogare i tuoi dati così come esistono in qualsiasi punto. Ciò aprirà nuove possibilità per gli analisti di dati e di business per comprendere le tendenze e come i dati si sono evoluti nel tempo. Puoi tornare facilmente a uno stato precedente in caso di errori. Questa funzionalità facilita anche i controlli di audit consentendoti di analizzare i dati in un punto specifico nel tempo.
-- time travel to October 5th, 1978 at 07:00:00
SELECT * FROM prod.retail.cusotmers TIMESTAMP AS OF '1978-10-05 07:00:00';
-- time travel using a specific snapshot ID:
SELECT * FROM prod.retail.customers VERSON AS OF 949530903748831869;
2. Evoluzione dello Schema
L’evoluzione dello schema di Apache Iceberg consente modifiche allo schema senza sforzi e migrazioni costose. Man mano che le esigenze aziendali evolvono, puoi:
- Aggiungere e rimuovere colonne senza alcun tempo di inattività o riscritture delle tabelle.
- Aggiornare la colonna (allargamento).
- Cambiare l’ordine delle colonne.
- Rinominare una colonna esistente.
Queste modifiche sono gestite a livello di metadati senza la necessità di riscrivere i dati sottostanti.
-- add a new column to the table
ALTER TABLE prod.retail.customers ADD COLUMNS (email_address STRING);
-- remove an existing column from the table
ALTER TABLE prod.retail.customers DROP COLUMN num_of_years;
-- rename an existing column
ALTER TABLE prod.retail.customers RENAME COLUMN email_address TO email;
-- iceberg allows updating column types from int to bigint, float to double
ALTER TABLE prod.retail.customers ALTER COLUMN customer_id TYPE bigint;
3. Evoluzione della Partizione
Utilizzando il formato tabella di Apache Iceberg, puoi cambiare la strategia di partizionamento della tabella senza riscrivere la tabella sottostante o migrare i dati in una nuova tabella. Ciò è reso possibile poiché le query non fanno riferimento direttamente ai valori di partizione come in Apache Hadoop. Iceberg mantiene le informazioni sui metadati per ciascuna versione della partizione separatamente. Ciò rende facile ottenere le suddivisioni durante l’interrogazione dei dati. Ad esempio, interrogando una tabella in base all’intervallo di date, mentre la tabella utilizzava il mese come colonna di partizione (prima) come una suddivisione e il giorno come una nuova colonna di partizione (dopo) come un’altra suddivisione. Questo è chiamato pianificazione delle suddivisioni. Vedi l’esempio qui sotto.
-- create customers table partitioned by month of the create_date initially
CREATE TABLE local.retail.customer (
id BIGINT,
name STRING,
street STRING,
city STRING,
state STRING,
create_date DATE
USING iceberg
PARTITIONED BY (month(create_date));
-- insert some data into the table
INSERT INTO local.retail.customer VALUES
(1, 'Alice', '123 Maple St', 'Springfield', 'IL', DATE('2024-01-10')),
(2, 'Bob', '456 Oak St', 'Salem', 'OR', DATE('2024-02-15')),
(3, 'Charlie', '789 Pine St', 'Austin', 'TX', DATE('2024-02-20'));
-- change the partition scheme from month to date
ALTER TABLE local.retail.customer
REPLACE PARTITION FIELD month(create_date) WITH days(create_date);
-- insert couple more records
INSERT INTO local.retail.customer VALUES
(4, 'David', '987 Elm St', 'Portland', 'ME', DATE('2024-03-01')),
(5, 'Eve', '654 Birch St', 'Miami', 'FL', DATE('2024-03-02'));
-- select all columns from the table
SELECT * FROM local.retail.customer
WHERE create_date BETWEEN DATE('2024-01-01') AND DATE('2024-03-31');
-- output
1 Alice 123 Maple St Springfield IL 2024-01-10
5 Eve 654 Birch St Miami FL 2024-03-02
4 David 987 Elm St Portland ME 2024-03-01
2 Bob 456 Oak St Salem OR 2024-02-15
3 Charlie 789 Pine St Austin TX 2024-02-20
-- View parition details
SELECT partition, file_path, record_count
FROM local.retail.customer.files;
-- output
{"create_date_month":null,"create_date_day":2024-03-02} /Users/rellaturi/warehouse/retail/customer/data/create_date_day=2024-03-02/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00002.parquet 1
{"create_date_month":null,"create_date_day":2024-03-01} /Users/rvellaturi/warehouse/retail/customer/data/create_date_day=2024-03-01/00000-6-ae2fdf0d-5567-4c77-9bd1-a5d9f6c83dfe-0-00001.parquet 1
{"create_date_month":648,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-01/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00001.parquet 1
{"create_date_month":649,"create_date_day":null} /Users/rvellaturi/warehouse/retail/customer/data/create_date_month=2024-02/00000-3-64c8b711-f757-45b4-828f-553ae9779d14-0-00002.parquet 2
4. Transazioni ACID
Iceberg offre un supporto robusto per le transazioni in termini di Atomicità, Coerenza, Isolamento e Durabilità (ACID). Consente operazioni di scrittura concorrenti multiple, il che permette un alto throughput in lavori intensivi di dati senza compromettere la coerenza dei dati.
-- Start a transaction
START TRANSACTION;
-- Insert new records
INSERT INTO customers VALUES (1, 'John'), (2, 'Mike');
-- Update existing records
UPDATE customers SET column1 = 'Josh' WHERE id = 1;
-- Delete records
DELETE FROM customers WHERE id = 2;
-- Commit the transaction
COMMIT;
Tutte le operazioni in Iceberg sono transazionali, il che significa che i dati rimangono coerenti nonostante i guasti o le modifiche ai dati in modo concorrente.
-- Atomic update across multiple tables
START TRANSACTION;
UPDATE orders SET status = 'processed' WHERE order_id = 100;
INSERT INTO orders_processed SELECT * FROM orders WHERE order_id = 100;
COMMIT;
Supporta anche diversi livelli di isolamento, il che consente di bilanciare le prestazioni e la coerenza in base ai requisiti.
-- Set isolation level (syntax may vary depending on the query engine)
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
-- Perform operations
SELECT * FROM customers WHERE id = 1;
UPDATE customers SET rec_status= 'updated' WHERE id = 1;
COMMIT;
Ecco un riepilogo che mostra come Iceberg gestisce gli aggiornamenti e le cancellazioni a livello di riga.
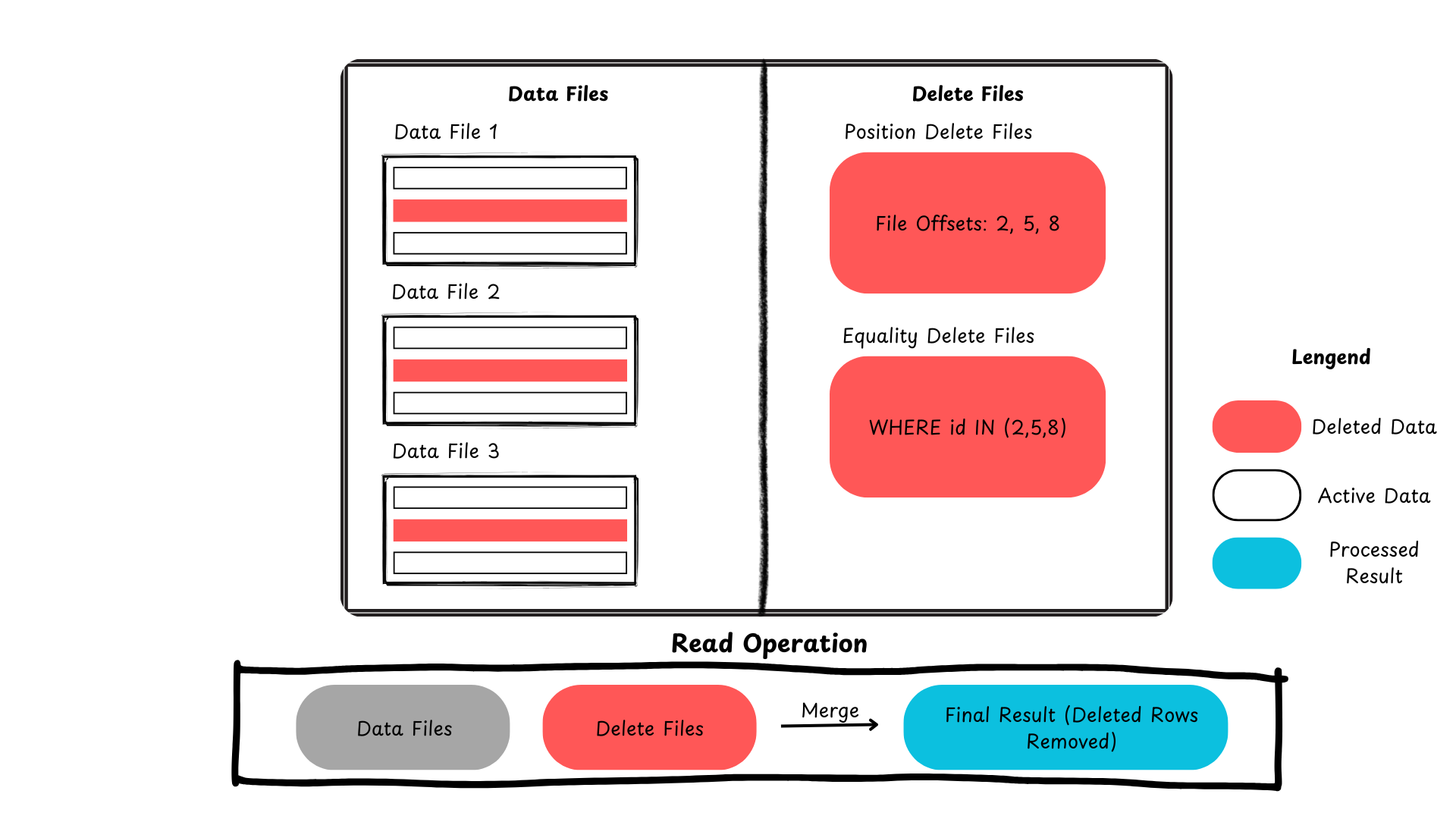
Figura 2: Processo di cancellazione dei record in Apache Iceberg (immagine creata dall’autore)
5. Operazioni avanzate sulle tabelle
Iceberg supporta operazioni avanzate sulle tabelle come:
- Creazione/gestione di snapshot delle tabelle: Questo consente di avere un robusto controllo delle versioni.
- Pianificazione e esecuzione rapida delle query con i suoi metadati altamente ottimizzati
- Strumenti integrati per la manutenzione delle tabelle, come la compattazione e la pulizia dei file orfani
Iceberg è progettato per funzionare con tutti i principali servizi di archiviazione cloud, come AWS S3, GCS e Azure Blob Storage. Inoltre, Iceberg si integra facilmente con motori di elaborazione dati come Spark, Presto, Trino e Hive.
Pensieri finali
Queste caratteristiche evidenziate consentono alle aziende di costruire laghi di dati moderni, flessibili, scalabili ed efficienti, che possono viaggiare nel tempo, gestire facilmente le modifiche allo schema, supportare transazioni ACID e l’evoluzione delle partizioni.
Source:
https://dzone.com/articles/key-features-of-apache-iceberg-for-data-lakes