













Che cos’è Elasticsearch?
Elasticsearch è un motore di ricerca e analisi altamente scalabile e distribuito, costruito sulla libreria di ricerca Apache Lucene. È progettato per gestire grandi volumi di dati strutturati, semi-strutturati e non strutturati, rendendolo adatto a una vasta gamma di casi d’uso, tra cui motori di ricerca, analisi dei log, e-commerce e analisi della sicurezza.
Elasticsearch utilizza un’architettura distribuita che consente di memorizzare e elaborare grandi volumi di dati attraverso più nodi in un cluster. I dati vengono indicizzati e memorizzati in shard, che sono distribuiti tra i nodi per migliorare la scalabilità e la tolleranza ai guasti. Elasticsearch supporta anche la ricerca e l’analisi in tempo reale, consentendo agli utenti di interrogare e analizzare i dati in tempo quasi reale.
Una delle caratteristiche chiave di Elasticsearch è la sua potente capacità di ricerca. Supporta una vasta gamma di query di ricerca, tra cui ricerca full-text, ricerca geospaziale, ecc. Offre inoltre supporto per funzionalità avanzate di analisi come aggregazioni, metriche e visualizzazione dei dati.
Elasticsearch viene spesso utilizzato insieme ad altri strumenti nello stack Elastic, tra cui Logstash per la raccolta e l’elaborazione dei dati e Kibana per la visualizzazione e l’analisi dei dati. Insieme, questi strumenti forniscono una soluzione completa per la ricerca e l’analisi che può essere utilizzata per una vasta gamma di applicazioni e casi d’uso.
Che cos’è Apache Lucene?
Apache Lucene è una libreria di ricerca open-source che fornisce potenti capacità di ricerca testuale e indicizzazione. È ampiamente utilizzata dai sviluppatori e dalle organizzazioni per costruire applicazioni di ricerca, che vanno da motori di ricerca a piattaforme di e-commerce.
Lucene funziona indicizzando il contenuto testuale dei documenti e memorizzando l’indice in un formato strutturato che può essere ricercato in modo efficiente. L’indice è composto da una serie di liste invertite, che forniscono mapping tra termini e documenti che li contengono. Quando viene inviata una query di ricerca, Lucene utilizza l’indice per recuperare rapidamente i documenti che corrispondono alla query.
Oltre alle sue capacità di base di ricerca e indicizzazione, Lucene offre una gamma di funzionalità avanzate, tra cui supporto per la ricerca fuzzy e la ricerca spaziale. Fornisce inoltre strumenti per evidenziare i risultati della ricerca e ordinare i risultati in base alla pertinenza.
Lucene è utilizzato da una vasta gamma di organizzazioni e progetti, inclusa Elasticsearch. La sua ricca gamma di funzionalità, flessibilità ed estensibilità la rendono una scelta popolare per la costruzione di applicazioni di ricerca di ogni tipo.
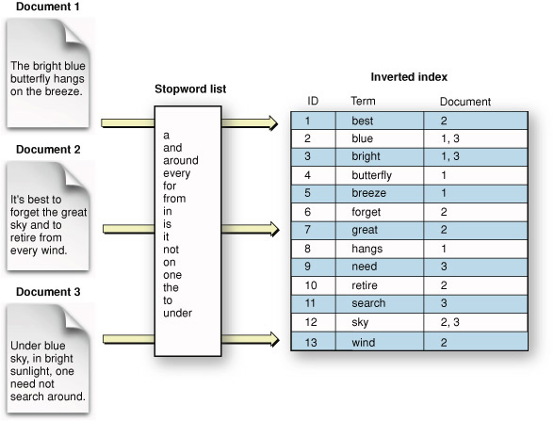
Che cos’è l’Indice Invertito?
L’Indice Invertito di Lucene è una struttura dati utilizzata per ricercare e recuperare dati testuali da una raccolta di documenti in modo efficiente. L’Indice Invertito è una caratteristica centrale di Lucene e viene utilizzato per memorizzare i termini e i loro documenti associati che compongono l’indice.
L’Inverted Index offre diversi vantaggi rispetto ad altre strategie di ricerca. Innanzitutto, permette il recupero rapido ed efficiente di documenti in base ai termini di ricerca. In secondo luogo, è in grado di gestire grandi quantità di dati testuali, rendendolo adatto per casi d’uso che implicano grandi collezioni di documenti. Infine, supporta una vasta gamma di funzionalità di ricerca avanzate, come il matching fuzzy e il stemming, che possono migliorare l’accuratezza e la pertinenza dei risultati della ricerca.
Perché Elasticsearch?
Ci sono diverse ragioni per cui Elasticsearch è una scelta popolare per la costruzione di applicazioni di ricerca e analisi:
Facile da scalare (Distribuito): Elasticsearch è progettato per scalare orizzontalmente sin dall’inizio. Ogni volta che è necessario aumentare la capacità, è sufficiente aggiungere altri nodi, e il cluster si riorganizzerà autonomamente per sfruttare l’hardware aggiuntivo.
Un server può ospitare una o più parti di uno o più indici, e ogni volta che nuovi nodi vengono introdotti nel cluster, vengono semplicemente aggiunti alla festa. Ogni tale indice, o parte di esso, è chiamato shard, e i shard di Elasticsearch possono essere spostati facilmente attraverso il cluster.
Tutto è a un solo JSON call di distanza (API RESTful): Elasticsearch è guidato dalle API. Quasi ogni azione può essere eseguita utilizzando una semplice API RESTful tramite JSON su HTTP. Le risposte sono sempre in formato JSON.
Potenza scatenata di Lucene sotto il cofano: Elasticsearch utilizza internamente Lucene per sviluppare le sue capaci di ricerca distribuita e analisi all’avanguardia. Poiché Lucene è una tecnologia stabile e provata, e viene continuamente arricchita con nuove funzionalità e migliori pratiche, avere Lucene come motore sottostante che alimenta Elasticsearch.
Eccellente DSL di Query: L’API REST espone un DSL di query molto complesso e capace, ma facile da usare. Ogni query è solo un oggetto JSON che può praticamente contenere qualsiasi tipo di query o addirittura diversi di loro combinati. L’uso di query filtrate, con alcune query espresse come filtri Lucene, aiuta a sfruttare la memorizzazione in cache e quindi a velocizzare le query comuni o complesse con parti che possono essere riutilizzate.
Multi-Tenancy: È possibile memorizzare più indici su un’installazione di Elasticsearch – nodo o cluster. La cosa bella è che è possibile eseguire query su più indici con una singola query semplice.
Supporto per funzionalità di ricerca avanzate (Full Text): Elasticsearch utilizza Lucene per fornire le più potenti capacità di ricerca full-text disponibili in qualsiasi prodotto open-source. La ricerca è dotata di supporto multilingue, un potente linguaggio di query, supporto per geolocalizzazione, suggerimenti did-you-mean a livello di contesto, autocomplete e snippet di ricerca. Supporto per script nei filtri e nei punteggi.
Configurabile e Estensibile: Molte configurazioni di Elasticsearch possono essere modificate mentre Elasticsearch è in esecuzione, ma alcune richiederanno un riavvio (e, in alcuni casi, una riindicizzazione). La maggior parte delle configurazioni può essere modificata anche utilizzando l’API REST.
Orientamento ai documenti: Archivia entità del mondo reale complesse in Elasticsearch come documenti JSON strutturati. Tutti i campi sono indicizzati per impostazione predefinita e tutti gli indici possono essere utilizzati in una singola query per restituire risultati ad una velocità mozzafiato.
Schema libero: Elasticsearch ti consente di iniziare facilmente. Invia un documento JSON e cercherà di rilevare la struttura dei dati, indicizzare i dati e renderli ricercabili.
Gestione dei conflitti: La versione controllo ottimistico può essere utilizzata dove necessario per garantire che i dati non vengano mai persi a causa di modifiche conflittuali da più processi.
Comunità attiva: La comunità, oltre a creare strumenti e plugin gradevoli, è molto disponibile e solidale. L’atmosfera generale è fantastica e questa è una metrica importante di qualsiasi progetto OSS. Ci sono anche alcuni libri attualmente in fase di scrittura da parte di membri della comunità e molti post di blog in rete che condividono esperienze e conoscenze.
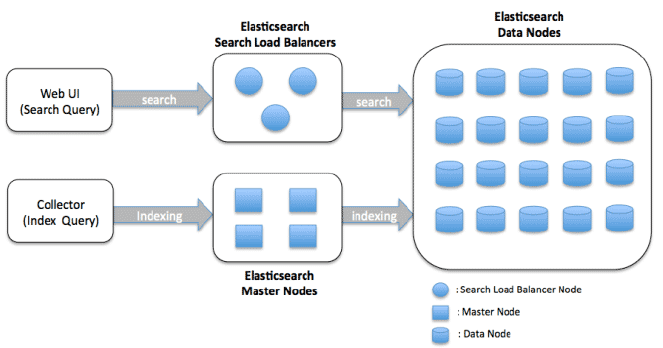
Architettura di Elasticsearch
I componenti principali dell’architettura di Elasticsearch sono:
Nodo: Un nodo è un’istanza di Elasticsearch che memorizza dati e fornisce capacità di ricerca e indicizzazione. I nodi possono essere configurati per essere o meno un nodo master o un nodo dati, o entrambi. I nodi master sono responsabili della gestione a livello di cluster, mentre i nodi dati memorizzano i dati e eseguono operazioni di ricerca.
Cluster: Un cluster è un gruppo di uno o più nodi che collaborano per memorizzare e elaborare dati. Un cluster può contenere più indici (raccolte di documenti) e shard (un modo per distribuire i dati attraverso più nodi).
Indice: Un indice è una raccolta di documenti che condividono una struttura simile. Ogni documento è rappresentato come un oggetto JSON e contiene uno o più campi. Elasticsearch indice tutti i campi per impostazione predefinita, rendendo facile la ricerca e l’analisi dei dati.
Shard: Un indice può essere suddiviso in più shard, che sono essenzialmente sottoinsiemi più piccoli dell’indice. Lo sharding consente il processamento parallelo dei dati e la memorizzazione distribuita attraverso più nodi.
Replica: Elasticsearch può creare repliche di ciascun shard per fornire tolleranza ai guasti e alta disponibilità. Le repliche sono copie dello shard originale e possono essere posizionate su nodi diversi.
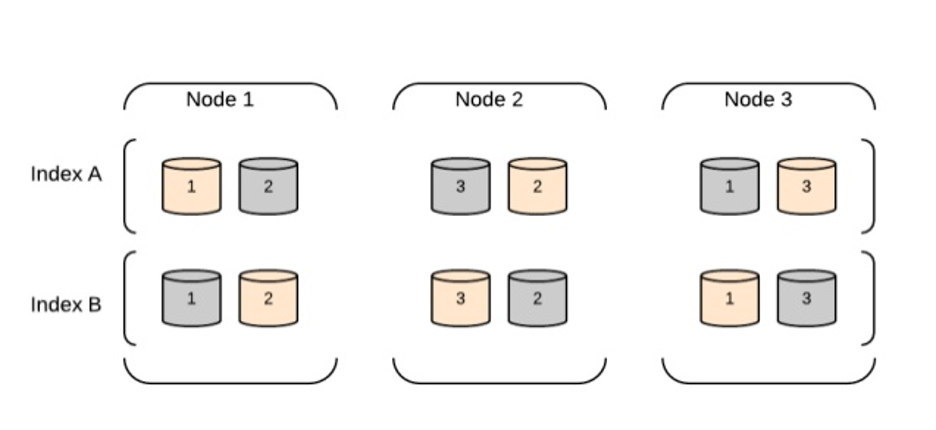
Architettura del cluster dei nodi dati
I nodi dati sono responsabili della memorizzazione e dell’indicizzazione dei dati, nonché delle operazioni di ricerca e aggregazione. L’architettura è progettata per essere scalabile e distribuita, consentendo la scalabilità orizzontale aggiungendo più nodi al cluster.
Ecco i principali componenti di un’architettura del cluster dei nodi dati di Elasticsearch:
Nodo dati: Un nodo è un’istanza di Elasticsearch che memorizza dati e fornisce capacità di ricerca e indicizzazione. In un cluster di nodi dati, ogni nodo è responsabile della memorizzazione di una porzione dei dati dell’indice e del servizio delle query di ricerca relative a tali dati.
Stato del cluster: Lo stato del cluster è una struttura dati che contiene informazioni sul cluster, inclusa la lista dei nodi, degli indici, dei shard e delle loro posizioni. Il nodo master è responsabile del mantenimento dello stato del cluster e della distribuzione a tutti gli altri nodi nel cluster.
Scoperta e trasporto: I nodi in un cluster Elasticsearch comunicano tra loro utilizzando due protocolli: scoperta e trasporto. Il protocollo di scoperta è responsabile della scoperta di nuovi nodi che si uniscono al cluster o di nodi che hanno lasciato il cluster. Il protocollo di trasporto è responsabile della trasmissione e ricezione di dati tra i nodi.
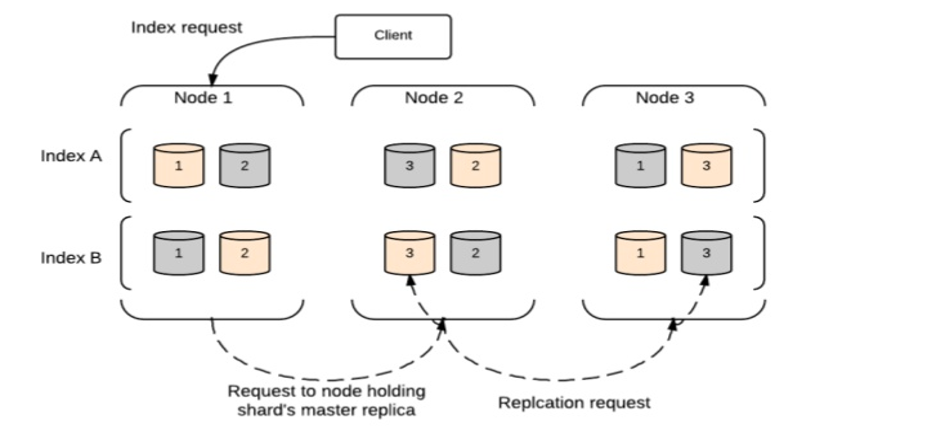
Richiesta di Indice
La richiesta di indice viene eseguita come diagramma a blocchi in Elasticsearch.
Chi usa Elasticsearch?
Alcune aziende e organizzazioni che utilizzano Elasticsearch:
Netflix: Netflix utilizza Elasticsearch per alimentare il suo motore di ricerca e raccomandazioni, consentendo agli utenti di trovare rapidamente contenuti da guardare.
GitHub: GitHub utilizza Elasticsearch per fornire capacità di ricerca veloce ed efficiente attraverso i loro repository di codice, problemi e richieste di pull.
Uber: Uber utilizza Elasticsearch per alimentare la loro piattaforma di analisi in tempo reale, permettendo loro di tracciare e analizzare i dati del loro servizio di trasporto condiviso in tempo reale.
Wikipedia: Wikipedia utilizza Elasticsearch per alimentare il suo motore di ricerca e fornire risultati di ricerca rapidi e accurati agli utenti.
Source:
https://dzone.com/articles/introduction-to-elasticsearch-1