













Introduzione
Ogni sistema informatico beneficia di una corretta amministrazione e monitoraggio. Tenere d’occhio il funzionamento del tuo sistema ti aiuterà a scoprire eventuali problemi e risolverli rapidamente.
Esistono molti strumenti a riga di comando creati a questo scopo. Questa guida ti presenterà alcune delle applicazioni più utili da avere nel tuo set di strumenti.
Prerequisiti
Per seguire questa guida, avrai bisogno di accesso a un computer con un sistema operativo basato su Linux. Questo può essere un server virtuale privato a cui ti sei connesso con SSH o il tuo computer locale. Tieni presente che questo tutorial è stato validato utilizzando un server Linux con Ubuntu 20.04, ma gli esempi forniti dovrebbero funzionare su un computer con qualsiasi versione di qualsiasi distribuzione Linux.
Se prevedi di utilizzare un server remoto per seguire questa guida, ti incoraggiamo a completare prima la nostra Guida all’Configurazione Iniziale del Server. Farlo ti fornirà un ambiente server sicuro, incluso un utente non root con privilegi sudo e un firewall configurato con UFW, che puoi utilizzare per sviluppare le tue competenze su Linux.
Passaggio 1 – Come visualizzare i processi in esecuzione in Linux
Puoi vedere tutti i processi in esecuzione sul tuo server utilizzando il comando top:
Outputtop - 15:14:40 up 46 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 56 total, 1 running, 55 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 1019600k total, 316576k used, 703024k free, 7652k buffers
Swap: 0k total, 0k used, 0k free, 258976k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.07 ksoftirqd/0
6 root RT 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
7 root RT 0 0 0 0 S 0.0 0.0 0:00.03 watchdog/0
8 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 cpuset
9 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 khelper
10 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
Le prime righe di output forniscono statistiche di sistema, come il carico della CPU/della memoria e il numero totale di attività in esecuzione.
Puoi vedere che c’è 1 processo in esecuzione e 55 processi che sono considerati in attesa perché non stanno utilizzando attivamente i cicli della CPU.
Il resto dell’output visualizzato mostra i processi in esecuzione e le loro statistiche di utilizzo. Per impostazione predefinita, top li ordina automaticamente in base all’utilizzo della CPU, quindi puoi vedere prima i processi più impegnativi. top continuerà a essere eseguito nel tuo shell finché non lo interrompi utilizzando la combinazione di tasti standard Ctrl+C per uscire da un processo in esecuzione. Questo invia un segnale kill, istruendo il processo a interrompersi delicatamente se è in grado di farlo.
Una versione migliorata di top, chiamata htop, è disponibile nella maggior parte dei repository dei pacchetti. Su Ubuntu 20.04, puoi installarlo con apt:
Dopo ciò, il comando htop sarà disponibile:
Output Mem[||||||||||| 49/995MB] Load average: 0.00 0.03 0.05
CPU[ 0.0%] Tasks: 21, 3 thr; 1 running
Swp[ 0/0MB] Uptime: 00:58:11
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1259 root 20 0 25660 1880 1368 R 0.0 0.2 0:00.06 htop
1 root 20 0 24188 2120 1300 S 0.0 0.2 0:00.56 /sbin/init
311 root 20 0 17224 636 440 S 0.0 0.1 0:00.07 upstart-udev-brid
314 root 20 0 21592 1280 760 S 0.0 0.1 0:00.06 /sbin/udevd --dae
389 messagebu 20 0 23808 688 444 S 0.0 0.1 0:00.01 dbus-daemon --sys
407 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.02 rsyslogd -c5
408 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
409 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.00 rsyslogd -c5
406 syslog 20 0 243M 1404 1080 S 0.0 0.1 0:00.04 rsyslogd -c5
553 root 20 0 15180 400 204 S 0.0 0.0 0:00.01 upstart-socket-br
htop offre una migliore visualizzazione dei thread CPU multipli, una migliore consapevolezza del supporto dei colori nei terminali moderni e più opzioni di ordinamento, tra le altre caratteristiche. A differenza di top, non è sempre installato per impostazione predefinita, ma può essere considerato un sostituto diretto. Puoi uscire da htop premendo Ctrl+C come con top.
Ecco alcuni tasti di scelta rapida che ti aiuteranno a utilizzare htop in modo più efficace:
- M: Sort processes by memory usage
- P: Sort processes by processor usage
- ?: Accedere all’aiuto
- k: Kill current/tagged process
- F2: Configurare htop. Qui puoi scegliere le opzioni di visualizzazione.
- /:: Cerca processi
Ci sono molte altre opzioni a cui puoi accedere tramite l’aiuto o la configurazione. Questi dovrebbero essere i tuoi primi passi nell’esplorare la funzionalità di htop. Nel prossimo passaggio, imparerai come monitorare la larghezza di banda di rete.
Passaggio 2 – Come Monitorare la Tua Larghezza di Banda di Rete
Se la tua connessione di rete sembra sovrautilizzata e non sei sicuro quale applicazione ne sia la causa, un programma chiamato nethogs è una buona scelta per scoprirlo.
Su Ubuntu, puoi installare nethogs con il seguente comando:
Dopo di ciò, il comando nethogs sarà disponibile:
OutputNetHogs version 0.8.0
PID USER PROGRAM DEV SENT RECEIVED
3379 root /usr/sbin/sshd eth0 0.485 0.182 KB/sec
820 root sshd: root@pts/0 eth0 0.427 0.052 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.912 0.233 KB/sec
nethogs associa ciascuna applicazione al suo traffico di rete.
Ci sono solo alcuni comandi che puoi utilizzare per controllare nethogs:
- M: Change displays between “kb/s”, “kb”, “b”, and “mb”.
- R: Sort by traffic received.
- S: Sort by traffic sent.
- Q: quit
iptraf-ng è un altro modo per monitorare il traffico di rete. Fornisce diverse interfacce di monitoraggio interattive.
Nota: IPTraf richiede una dimensione dello schermo di almeno 80 colonne per 24 righe.
Su Ubuntu, puoi installare iptraf-ng con il seguente comando:
iptraf-ng deve essere eseguito con privilegi di root, quindi dovresti precederlo con sudo:
Ti verrà presentato un menu che utilizza un framework di interfaccia a riga di comando chiamato ncurses.
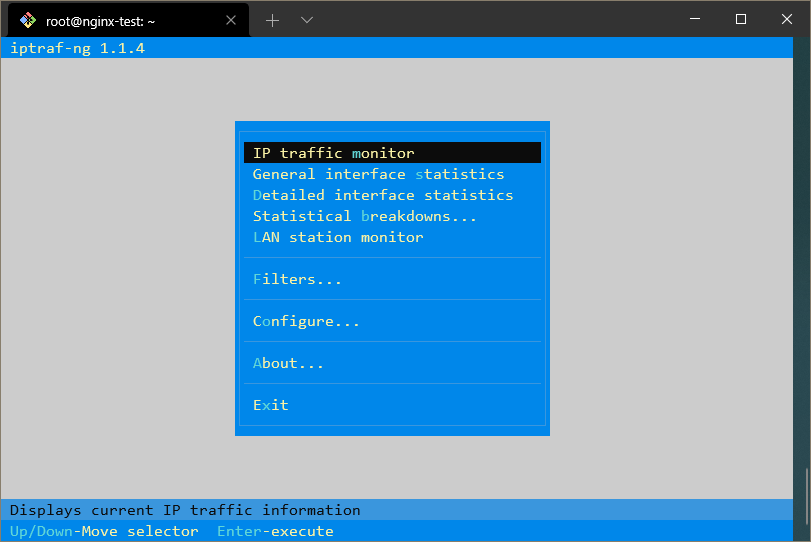
Con questo menu, puoi selezionare quale interfaccia desideri accedere.
Ad esempio, per ottenere una panoramica di tutto il traffico di rete, puoi selezionare il primo menu e poi “Tutte le interfacce”. Ti darà uno schermo che appare così:
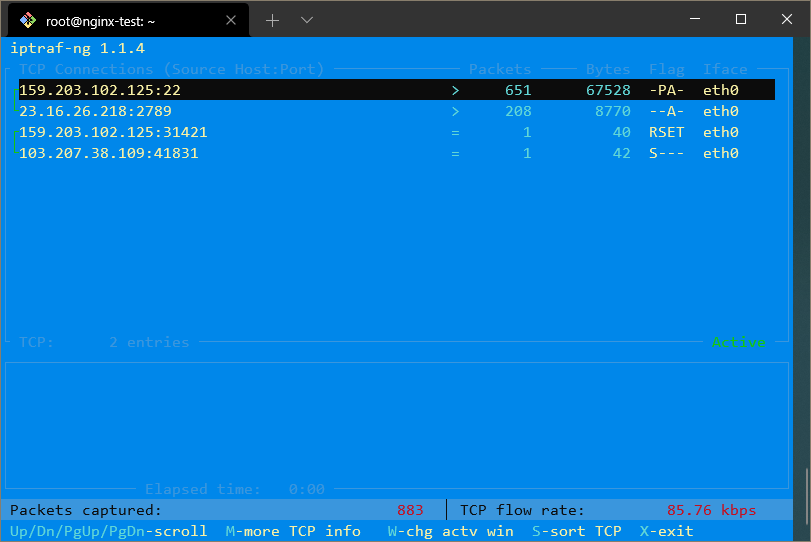
Qui puoi vedere quali indirizzi IP stai comunicando su tutte le tue interfacce di rete.
Se desideri che quegli indirizzi IP vengano risolti in domini, puoi abilitare la ricerca DNS inversa uscendo dalla schermata del traffico, selezionando Configura e poi attivando Ricerca DNS inversa.
Puoi anche abilitare i Nomi dei servizi TCP/UDP per vedere i nomi dei servizi in esecuzione invece dei numeri di porta.
Con entrambe queste opzioni abilitate, la visualizzazione potrebbe apparire così:
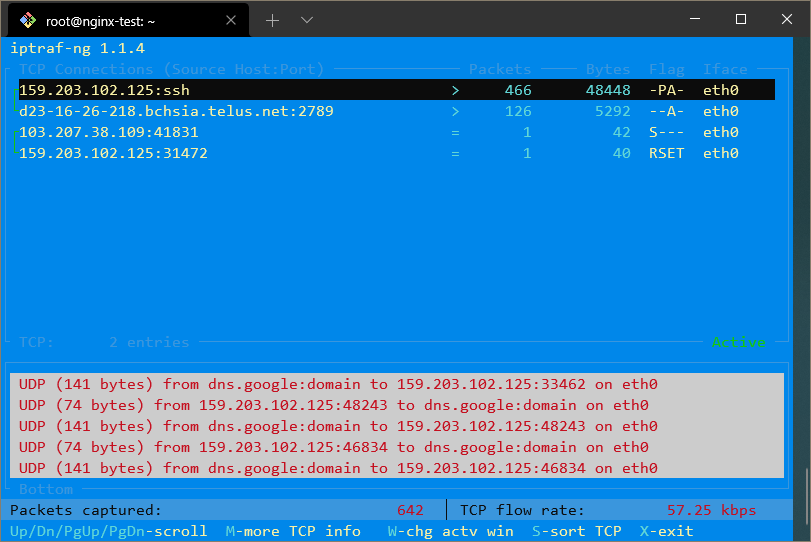
Il comando netstat è un altro strumento versatile per raccogliere informazioni di rete.
netstat è installato per impostazione predefinita su molti sistemi moderni, ma è possibile installarlo manualmente scaricandolo dai repository di pacchetti predefiniti del server. Su gran parte dei sistemi Linux, inclusa Ubuntu, il pacchetto contenente netstat è net-tools:
Per impostazione predefinita, il comando netstat da solo stampa un elenco di socket aperti:
OutputActive Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 192.241.187.204:ssh ip223.hichina.com:50324 ESTABLISHED
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
Active UNIX domain sockets (w/o servers)
Proto RefCnt Flags Type State I-Node Path
unix 5 [ ] DGRAM 6559 /dev/log
unix 3 [ ] STREAM CONNECTED 9386
unix 3 [ ] STREAM CONNECTED 9385
. . .
Se aggiungi l’opzione -a, elencherà tutte le porte, sia in ascolto che non in ascolto:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Active UNIX domain sockets (servers and established)
Proto RefCnt Flags Type State I-Node Path
unix 2 [ ACC ] STREAM LISTENING 6195 @/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 7762 /var/run/acpid.socket
unix 2 [ ACC ] STREAM LISTENING 6503 /var/run/dbus/system_bus_socket
. . .
Se desideri filtrare per vedere solo connessioni TCP o UDP, utilizza rispettivamente i flag -t o -u:
OutputActive Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 *:ssh *:* LISTEN
tcp 0 0 192.241.187.204:ssh rrcs-72-43-115-18:50615 ESTABLISHED
tcp6 0 0 [::]:ssh [::]:* LISTEN
Visualizza le statistiche passando il flag “-s”:
OutputIp:
13500 total packets received
0 forwarded
0 incoming packets discarded
13500 incoming packets delivered
3078 requests sent out
16 dropped because of missing route
Icmp:
41 ICMP messages received
0 input ICMP message failed.
ICMP input histogram:
echo requests: 1
echo replies: 40
. . .
Se desideri aggiornare continuamente l’output, puoi utilizzare il flag -c. Ci sono molte altre opzioni disponibili per netstat che puoi apprendere consultando la sua pagina del manuale.
Nel prossimo passaggio, imparerai alcuni modi utili per monitorare l’utilizzo del disco.
Passaggio 3 – Come monitorare l’utilizzo del disco
Per una rapida panoramica di quanto spazio su disco è rimasto sui tuoi dischi collegati, puoi utilizzare il programma df.
Senza alcuna opzione, il suo output appare così:
OutputFilesystem 1K-blocks Used Available Use% Mounted on
/dev/vda 31383196 1228936 28581396 5% /
udev 505152 4 505148 1% /dev
tmpfs 203920 204 203716 1% /run
none 5120 0 5120 0% /run/lock
none 509800 0 509800 0% /run/shm
Questo visualizza l’utilizzo del disco in byte, che potrebbe essere un po’ difficile da leggere.
Per risolvere questo problema, puoi specificare l’output in un formato leggibile dall’uomo:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
Se vuoi vedere lo spazio totale disponibile su tutti i filesystem, puoi passare l’opzione --total. Questo aggiungerà una riga in fondo con informazioni di riepilogo:
OutputFilesystem Size Used Avail Use% Mounted on
/dev/vda 30G 1.2G 28G 5% /
udev 494M 4.0K 494M 1% /dev
tmpfs 200M 204K 199M 1% /run
none 5.0M 0 5.0M 0% /run/lock
none 498M 0 498M 0% /run/shm
total 32G 1.2G 29G 4%
df può fornire una panoramica utile. Un’altra comando, du, fornisce una suddivisione per directory.
du analizzerà l’utilizzo per la directory corrente e eventuali sottodirectory. L’output predefinito di du in esecuzione in una directory home quasi vuota appare così:
Output4 ./.cache
8 ./.ssh
28 .
Ancora una volta, puoi specificare un output leggibile dall’utente passando -h:
Output4.0K ./.cache
8.0K ./.ssh
28K .
Per vedere le dimensioni dei file così come delle directory, digita quanto segue:
Output0 ./.cache/motd.legal-displayed
4 ./.cache
4 ./.ssh/authorized_keys
8 ./.ssh
4 ./.profile
4 ./.bashrc
4 ./.bash_history
28 .
Per un totale in fondo, puoi aggiungere l’opzione -c:
Output4 ./.cache
8 ./.ssh
28 .
28 total
Se sei interessato solo al totale e non ai dettagli, puoi eseguire:
Output28 .
C’è anche un’interfaccia ncurses per du, chiamata in modo appropriato ncdu, che puoi installare:
Questo rappresenterà graficamente l’utilizzo del disco:
Output--- /root ----------------------------------------------------------------------
8.0KiB [##########] /.ssh
4.0KiB [##### ] /.cache
4.0KiB [##### ] .bashrc
4.0KiB [##### ] .profile
4.0KiB [##### ] .bash_history
Puoi navigare nel filesystem utilizzando le frecce su e giù e premendo Invio su qualsiasi voce di directory.
Nella sezione seguente, imparerai come monitorare l’utilizzo della memoria.
Passo 4 – Come Monitorare l’Utilizzo della Memoria
Puoi controllare l’utilizzo attuale della memoria sul tuo sistema utilizzando il comando free.
Quando utilizzato senza opzioni, l’output appare così:
Output total used free shared buff/cache available
Mem: 1004896 390988 123484 3124 490424 313744
Swap: 0 0 0
Per visualizzare in un formato più leggibile, è possibile passare l’opzione -m per visualizzare l’output in megabyte:
Output total used free shared buff/cache available
Mem: 981 382 120 3 478 306
Swap: 0 0 0
La riga Mem include la memoria utilizzata per il buffering e la cache, che viene liberata non appena necessaria per altri scopi. Swap è la memoria che è stata scritta su un file di swap su disco per conservare la memoria attiva.
Infine, il comando vmstat può produrre varie informazioni sul sistema, inclusa la memoria, lo swap, l’I/O del disco e le informazioni sulla CPU.
Puoi utilizzare il comando per ottenere un’altra vista sull’utilizzo della memoria:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 99340 123712 248296 0 0 0 1 9 3 0 0 100 0
Puoi vedere questo in megabyte specificando le unità con il flag -S:
Outputprocs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
1 0 0 96 120 242 0 0 0 1 9 3 0 0 100 0
Per ottenere alcune statistiche generali sull’utilizzo della memoria, digita:
Output 495 M total memory
398 M used memory
252 M active memory
119 M inactive memory
96 M free memory
120 M buffer memory
242 M swap cache
0 M total swap
0 M used swap
0 M free swap
. . .
Per ottenere informazioni sull’utilizzo della cache dei singoli processi di sistema, digita:
OutputCache Num Total Size Pages
ext4_groupinfo_4k 195 195 104 39
UDPLITEv6 0 0 768 10
UDPv6 10 10 768 10
tw_sock_TCPv6 0 0 256 16
TCPv6 11 11 1408 11
kcopyd_job 0 0 2344 13
dm_uevent 0 0 2464 13
bsg_cmd 0 0 288 14
. . .
Questo ti darà dettagli su che tipo di informazioni sono memorizzate nella cache.
Conclusion
Utilizzando questi strumenti, dovresti iniziare a poter monitorare il tuo server dalla riga di comando. Ci sono molte altre utilità di monitoraggio utilizzate per scopi diversi, ma queste sono un buon punto di partenza.
Successivamente, potresti voler apprendere la gestione dei processi Linux utilizzando ps, kill e nice.