













Utilizzare il monitoraggio IT nell’infrastruttura di un’organizzazione può migliorarne l’affidabilità e aiutare a prevenire problemi gravi, guasti e tempi di inattività. Esistono diversi approcci per implementare il monitoraggio IT, utilizzando strumenti dedicati o funzionalità native. Con entrambi gli approcci, è possibile visualizzare i dati di monitoraggio quando necessario o configurare avvisi automatici e report per essere notificati di eventi importanti. Questo post del blog spiega come migliorare la strategia di monitoraggio IT utilizzando allarmi e report.
L’importanza del monitoraggio IT e dei report per le imprese
Il monitoraggio IT è cruciale per le organizzazioni perché aiuta a garantire che l’infrastruttura IT funzioni correttamente e in modo affidabile.
- Massimizzare il tempo di attività e l’affidabilità. I sistemi aziendali critici di solito richiedono un’operatività 24 ore su 24, 7 giorni su 7. Tali sistemi sono utilizzati in settori come la sanità, la finanza e altri fornitori di servizi dove i tempi di inattività possono portare a conseguenze gravi. Fortunatamente, è possibile prevenire tali problemi se si implementa e si configura correttamente un sistema di monitoraggio IT.
La rilevazione proattiva dei problemi aiuta gli amministratori a scoprire potenziali problemi come sovraccarichi del server, errori delle applicazioni, problemi hardware e degrado delle prestazioni in tempo prima che portino a guasti gravi. Questo approccio proattivo consente agli amministratori di interagire e eseguire azioni correttive prima che abbiano un impatto negativo sui server, macchine virtuali (VM), operazioni aziendali e utenti finali. Ricevere report che indicano problemi potenziali rende il monitoraggio e l’amministrazione IT più efficienti.
- Migliorare la sicurezza. Il monitoraggio IT viene utilizzato per rilevare tentativi di accesso non autorizzati, traffico di rete insolito e altre attività sospette che possono essere un indicatore di un attacco informatico. Questo approccio consente agli amministratori di rilevare minacce alla sicurezza in tempo. Alcuni settori devono conformarsi a requisiti normativi che richiedono il monitoraggio continuo dei sistemi IT per evitare sanzioni.
- Migliorare le prestazioni e l’efficienza. Gli amministratori possono ottimizzare l’uso delle risorse su server, macchine virtuali e attrezzature di rete configurando il monitoraggio IT e gli avvisi. Configurare gli strumenti di monitoraggio IT per tracciare l’uso della CPU, della memoria e della larghezza di banda per ulteriori analisi di questi dati consente di comprendere meglio cosa migliorare. Di conseguenza, le organizzazioni possono ottimizzare le loro risorse e ridurre gli sprechi per raggiungere un’alta efficienza nei loro sistemi IT. Questo aiuta anche gli amministratori a identificare i colli di bottiglia e migliorare le prestazioni.
- Migliorare la continuità aziendale e il ripristino dopo i disastri. Il rilevamento precoce dei guasti è una delle principali ragioni per cui gli amministratori delle organizzazioni dovrebbero configurare sistemi di monitoraggio IT con notifiche. Questo approccio può individuare segnali di corruzione dei dati, arresti anomali delle applicazioni e guasti hardware in anticipo per prevenire la perdita di dati. La prevenzione della perdita di dati è necessaria per mantenere la continuità aziendale. Utilizzando strumenti di monitoraggio con notifiche configurate, gli amministratori possono garantire che i sistemi di backup e i piani di ripristino dopo i disastri siano testati e funzionanti correttamente. Può essere un’assicurazione che un’azienda possa recuperare rapidamente dati e carichi di lavoro in caso di disastro.
- Migliorare l’esperienza del cliente. I clienti si aspettano che i servizi siano disponibili in qualsiasi momento. La configurazione dei sistemi di monitoraggio IT per controllare server, VM, attrezzature di rete e applicazioni relative al funzionamento del sito web aiuta a garantire che i siti web e i servizi siano sempre disponibili per i clienti. Non solo la disponibilità delle risorse, ma anche le prestazioni sono monitorate per ottenere il miglior servizio.
Ricevere report che includono informazioni sugli inconvenienti può portare a una rapida risoluzione. I report includono le informazioni necessarie agli amministratori per risolvere i problemi il prima possibile. Queste azioni riducono al minimo l’impatto negativo sui clienti e, di conseguenza, i clienti hanno un’esperienza positiva.
- Gestione dei costi. Configurare un monitoraggio proattivo può prevenire tempi di inattività. I tempi di inattività non programmati possono essere costosi perché un’organizzazione perde entrate e deve spendere risorse per recuperare i dati e l’infrastruttura. Il monitoraggio con notifiche di avviso consente agli amministratori di risolvere il problema il più rapidamente possibile e ridurre il rischio di inattività.
Comprendere gli allarmi nel monitoraggio IT
Configurare allarmi per i sistemi di monitoraggio IT migliora il tempo di reazione degli amministratori per essere a conoscenza del problema e risolverlo più velocemente. Se solo risorse come pagine web con grafici e statistiche sono configurate, allora l’amministratore di sistema può notare i problemi solo quando controlla la pagina web con le informazioni di monitoraggio. Gli amministratori hanno un ampio insieme di compiti diversi e di solito non possono monitorare continuamente una pagina web con lo stato dell’infrastruttura IT.
Quando gli allarmi sono configurati, gli amministratori ricevono un messaggio di notifica riguardo al problema, a un potenziale problema, a un guasto o ad altri eventi critici o sospetti il prima possibile. Di solito è possibile configurare un intervallo di tempo, ad esempio, un messaggio può essere inviato dopo 1 minuto o 5 minuti dalla rilevazione di un problema da parte del sistema di monitoraggio.
Di conseguenza, l’amministratore di sistema può notare il problema più rapidamente e reagire per risolverlo ed evitare conseguenze negative. Possono essere utilizzati diversi metodi di notifica, come notifiche via email, SMS, Skype, ecc., a seconda del software di monitoraggio IT.
Cosa sono gli allarmi e perché sono importanti?
Gli allarmi sono notifiche che vengono attivate quando si verifica un evento specifico e vengono soddisfatte le condizioni o le soglie appropriate nel sistema IT. Queste condizioni possono basarsi su eventi diversi, tra cui:
- Problemi di prestazioni: Elevato utilizzo della CPU, esaurimento della memoria, tempi di risposta lenti
- Soglie delle risorse: Spazio su disco in esaurimento, saturazione della larghezza di banda della rete
- Guasti di sistema: Arresti anomali del server, errori delle applicazioni, interruzioni del servizio
- Incidenti di sicurezza: Tentativi di accesso non autorizzati, rilevamento di malware, traffico di rete insolito
- Eventi operativi: Fallimenti di backup, riavvii del servizio, modifiche alla configurazione
Quando un allarme viene attivato, il sistema di monitoraggio genera un avviso, e questo avviso viene inviato all’utente pertinente, principalmente all’amministratore IT, attraverso vari canali. Questi avvisi contengono informazioni sul problema, inclusa la sua gravità, il sistema o componente interessato e le azioni raccomandate.
Metriche chiave da monitorare
Utilizzo della CPU. Monitorare l’utilizzo della CPU è necessario per garantire che ci siano abbastanza risorse per server e sistemi in termini di potenza di elaborazione. Questo è importante per gestire carichi di lavoro senza essere sovraccaricati. Un utilizzo elevato della CPU può essere un segnale che il sistema è sovraccarico. Un basso utilizzo della CPU indica che ci sono abbastanza risorse o che le risorse della CPU sono sottoutilizzate.
Utilizzo della memoria (RAM). Applicazioni e servizi hanno bisogno di abbastanza memoria per un’operazione fluida, e il parametro della memoria è critico in questo contesto. Gli amministratori dovrebbero monitorare l’utilizzo della RAM per evitare congestioni di memoria, che possono causare degrado delle prestazioni e persino crash di sistema. Prestare attenzione a un utilizzo eccessivo della memoria, a un’allocazione insufficiente della memoria e a memory leak.
Utilizzo del disco e prestazioni di I/O. Lo spazio su disco e le prestazioni di input/output (I/O) sono metriche critiche per lo storage dei dati. Si consiglia di monitorare questi parametri per prevenire problemi legati allo storage, inclusi problemi di prestazioni. Prestare attenzione a un utilizzo elevato del disco, a una rapida crescita dello spazio su disco utilizzato, a un’elevata latenza durante la lettura/scrittura dei dati e a tempi di attesa I/O frequenti. Comportamenti anomali riguardanti questi parametri possono indicare potenziali problemi di storage.
Bandwidth di rete e latenza. Le prestazioni di rete influenzano tutte le operazioni in un ufficio o un data center poiché computer, server e macchine virtuali sono collegati tra loro tramite la rete. Le prestazioni di rete sono cruciali per i servizi forniti ai clienti. Monitorare la larghezza di banda di rete e la latenza ti consente di individuare i colli di bottiglia e altri problemi e risolverli in tempo per utilizzare efficientemente le risorse di rete. Presta attenzione all’utilizzo elevato della rete, alla perdita di pacchetti e alla latenza elevata perché questi indicatori sono segnali di prestazioni lente e problemi di connettività di rete.
Disponibilità dei servizi e dei processi. Processi importanti vengono eseguiti nei sistemi operativi su server o macchine virtuali e devono essere disponibili per soddisfare le esigenze aziendali. Monitorare i servizi e la loro disponibilità garantisce che i servizi critici siano in funzione. Per garantire la disponibilità del servizio, gli amministratori dovrebbero monitorare il tempo di attività, le frequenze di riavvio del servizio e i fallimenti dei processi.
Prestazioni del database. I database sono spesso parte di soluzioni più complesse, tra cui applicazioni web. Inoltre, la maggior parte delle soluzioni software per uso interno nelle organizzazioni richiede database. Per queste ragioni, è importante monitorare le prestazioni e la disponibilità del database. Monitorare i database garantisce che i dati siano accessibili e che le operazioni correlate si svolgano senza intoppi. Quando si monitora un database, concentrati sui tempi di risposta delle query, sulle query lente, sulle chiusure del database e sull’utilizzo del pool di connessioni, poiché queste metriche sono vitali per la salute del database.
Reporting per il monitoraggio IT
La reportistica viene utilizzata per fornire approfondimenti strutturati e praticabili dall’enorme quantità di dati raccolti dagli strumenti di monitoraggio. La reportistica trasforma i dati grezzi in informazioni che possono essere leggibili e comprensibili per le persone che lavorano in un’organizzazione e principalmente per gli amministratori IT. Dopo aver esaminato i rapporti, gli amministratori e la direzione possono prendere decisioni informate. Questo consente ai team IT di ottimizzare le prestazioni, prevenire problemi e migliorare la continuità aziendale.
I rapporti possono evidenziare anomalie che non sono evidenti durante la ricerca degli allarmi. I dati nei rapporti sono aggregati per maggiore comodità, per evitare la necessità di cercare manualmente metriche chiave e organizzare i dati raccolti. Di conseguenza, gli amministratori hanno una panoramica ad alto livello dell’intera infrastruttura e dei componenti più importanti. Essere informati sulle condizioni che portano a un incidente può essere utilizzato dagli amministratori per una rapida risposta agli incidenti e per attuare misure preventive.
Monitoraggio con NAKIVO Backup & Replication
NAKIVO Backup & Replication può aiutarti a monitorare gli elementi della tua infrastruttura IT. Vai alla sezione Monitoraggio nell’interfaccia web, aggiungi gli elementi monitorati e controlla i grafici che mostrano le metriche supportate dell’infrastruttura VMware vSphere.
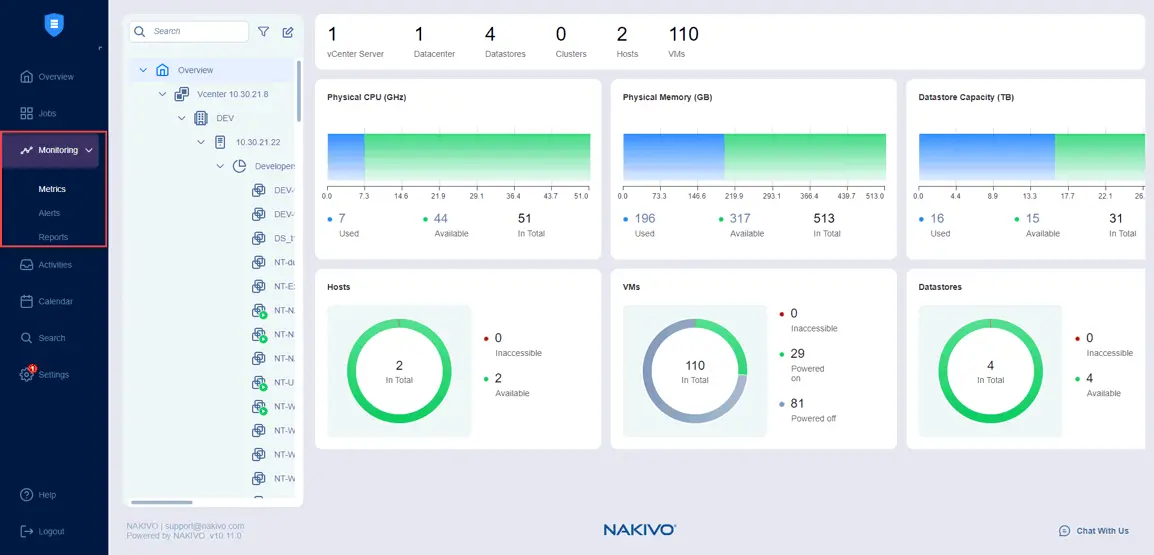
Puoi selezionare gli elementi da monitorare, come gli host ESXi o cluster, VM VMware e datastore in Monitoraggio>Metriche.
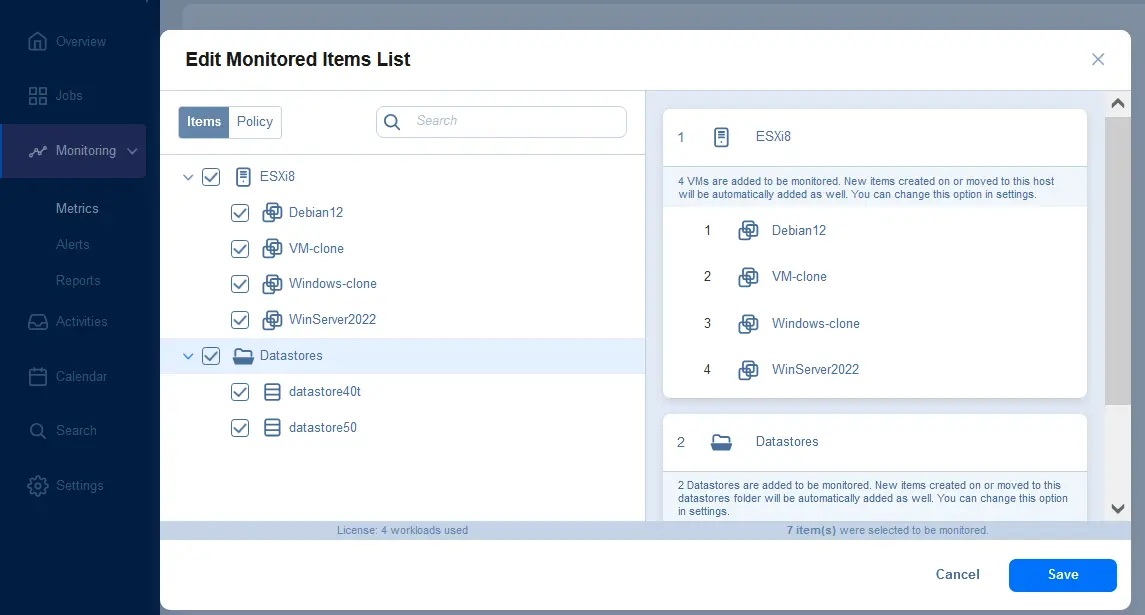
Configurare allarmi nella soluzione NAKIVO
Puoi configurare avvisi nella soluzione NAKIVO per essere notificato su potenziali problemi il prima possibile, permettendoti di affrontarli rapidamente prima che portino a conseguenze gravi.
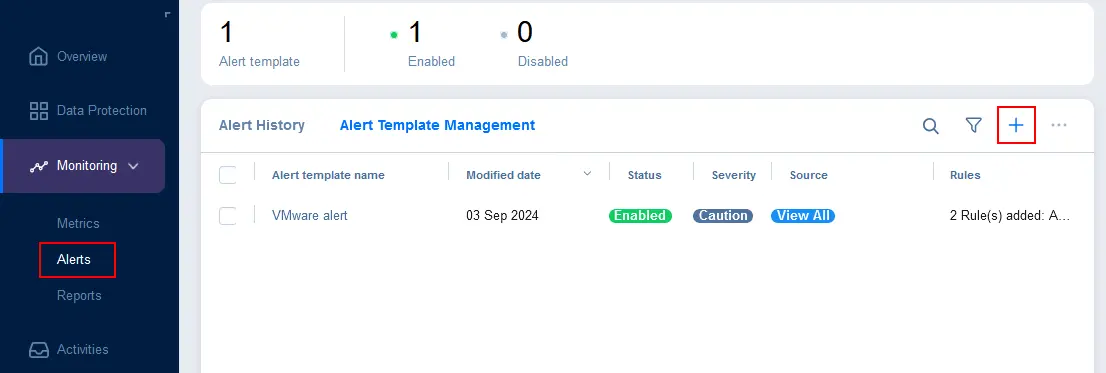
- Vai su Monitoraggio > Avvisi, seleziona la scheda Gestione Modelli di Avviso e fai clic su + per aggiungere avvisi per elementi specifici.
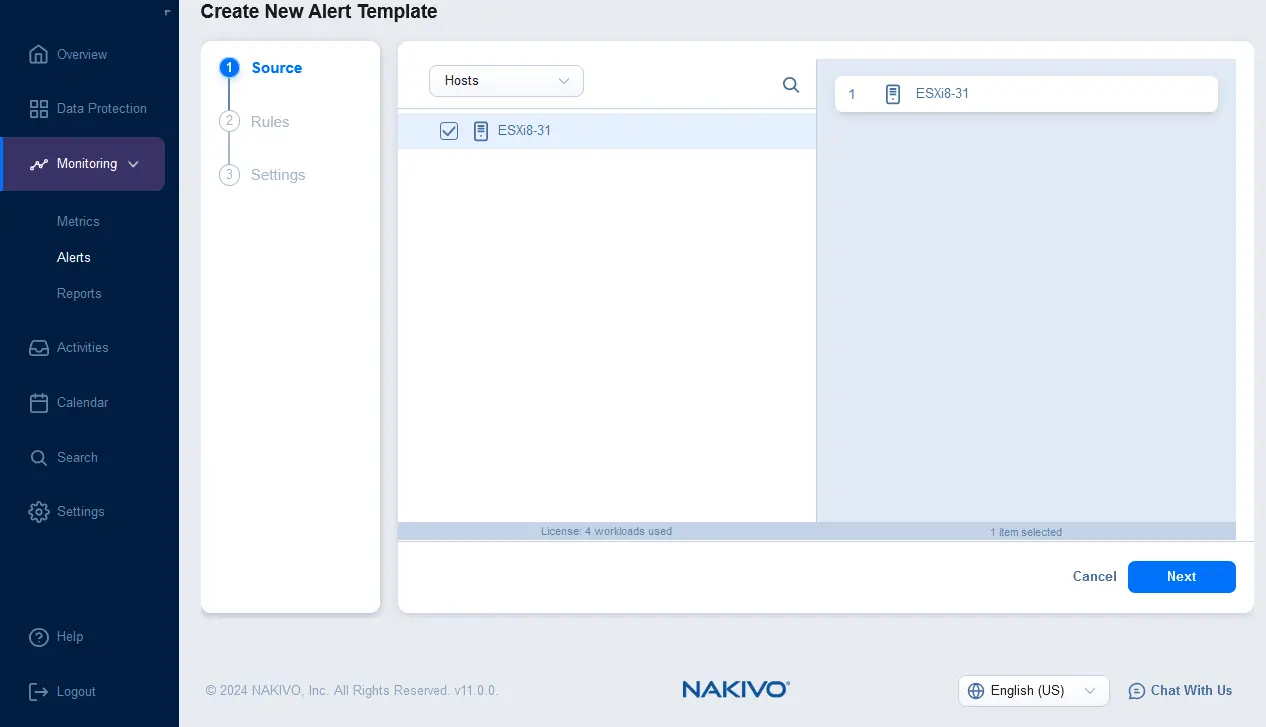
- Seleziona gli elementi monitorati per i quali deve essere attivato l’avviso. Puoi selezionare host ESXi, macchine virtuali (VM) o datastore. Fai clic su Avanti per continuare.
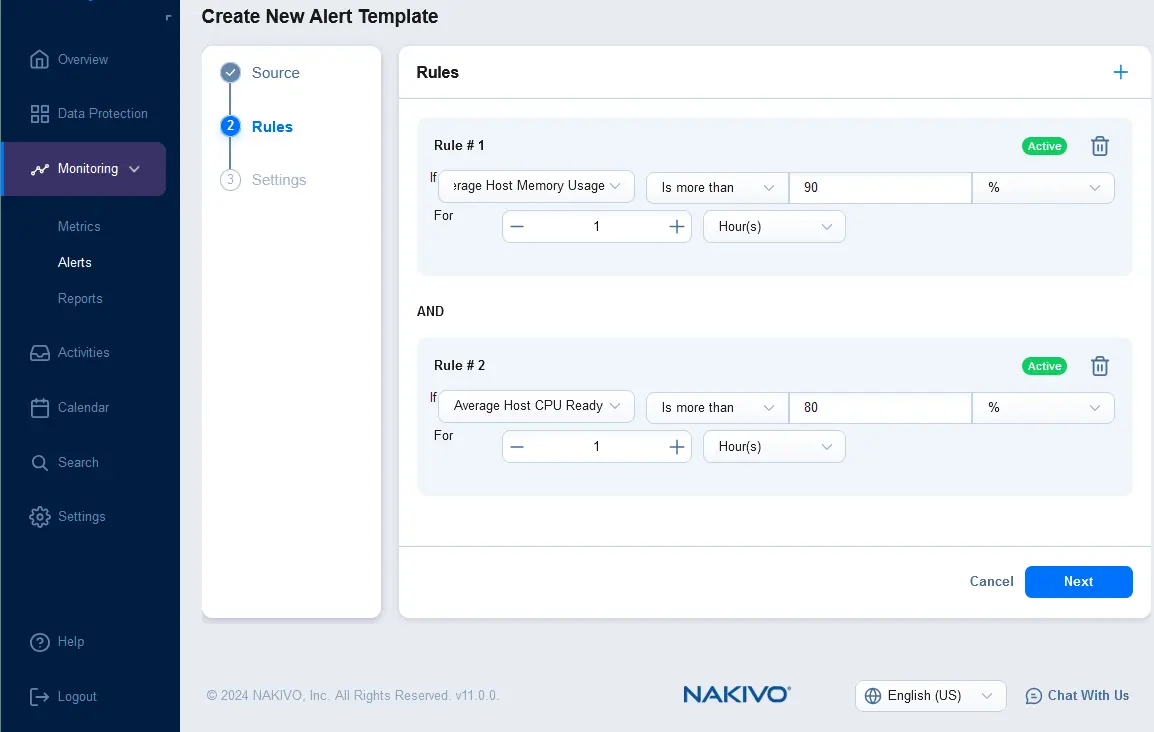
- Configura regole per un nuovo modello di avviso. Fai clic su + e seleziona la condizione della regola. Ad esempio, puoi impostare un modello di regola di avviso che deve essere attivato se l’uso medio della memoria dell’host supera il 90% per 1 ora. Puoi aggiungere più regole per un modello di avviso.
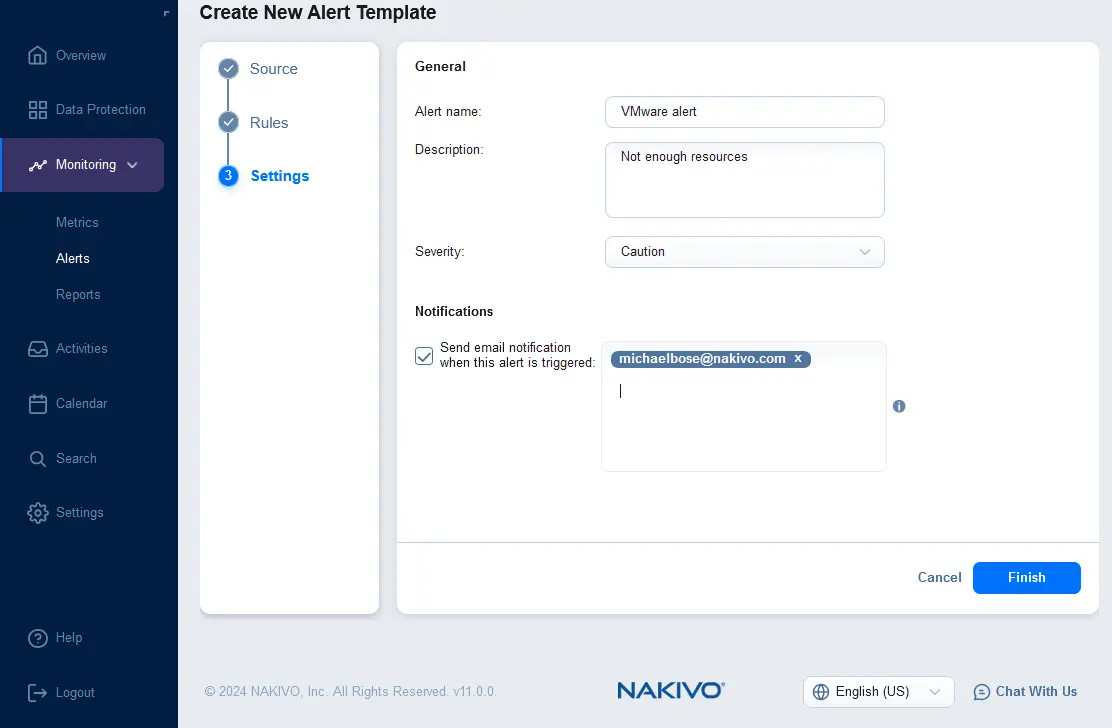
- Configura le impostazioni per il modello di avviso. Inserisci il nome e la descrizione dell’avviso, e seleziona la gravità. Puoi selezionare la casella per inviare una notifica via email quando questo avviso viene attivato e inserire più indirizzi email dei destinatari che dovrebbero ricevere le notifiche di avviso. Clicca Fine.
Configurazione dei rapporti nella soluzione NAKIVO
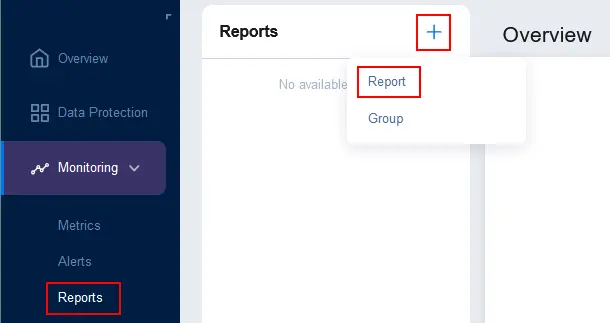
- Per configurare i rapporti, vai su Monitoraggio > Rapporti, clicca + e premi Rapporto.
- Puoi selezionare uno dei tipi di sorgente supportati:
- Panoramica dell’infrastruttura – informazioni sui server vCenter, sugli host ESXi gestiti da vCenter e sugli host ESXi autonomi
- Prestazioni delle VM
- Capacità del datastore
- Prestazioni dell’host
- Rapporto di protezione
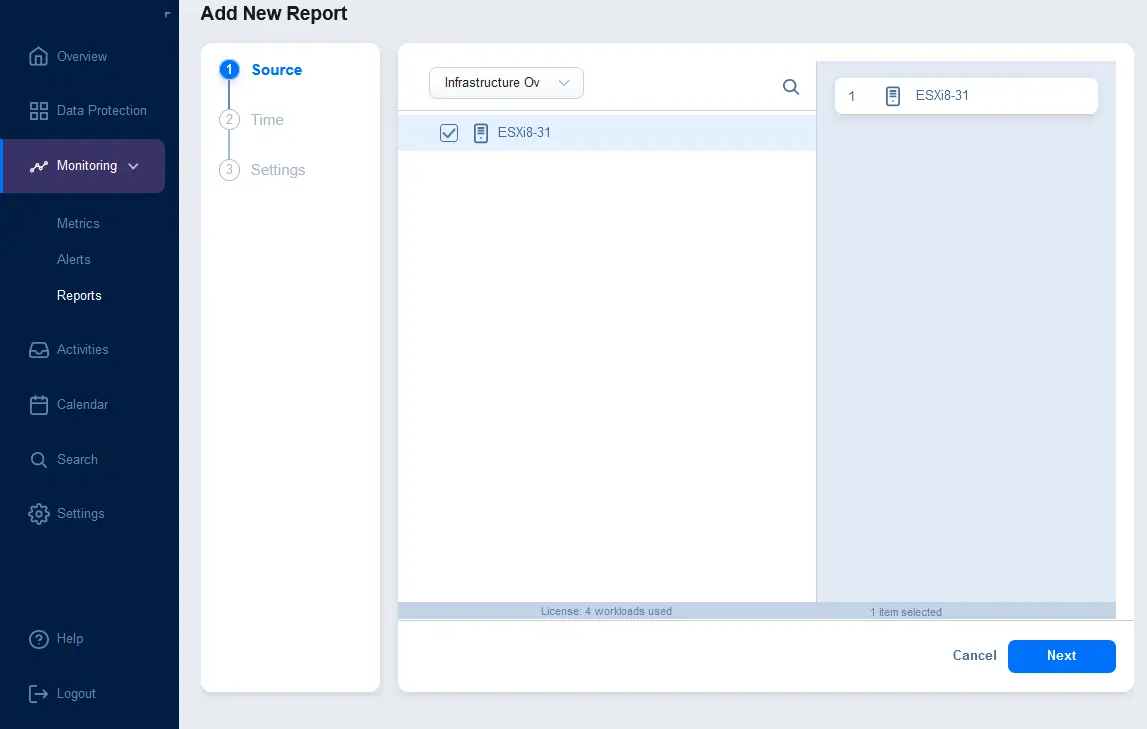
Una volta selezionato il tipo di sorgente, seleziona gli elementi da includere nel rapporto. Nello screenshot qui sotto, puoi vedere che Panoramica dell’infrastruttura è selezionato nell’elenco a discesa e un host ESXi è selezionato per essere incluso nel rapporto. Fai clic su Avanti per continuare.
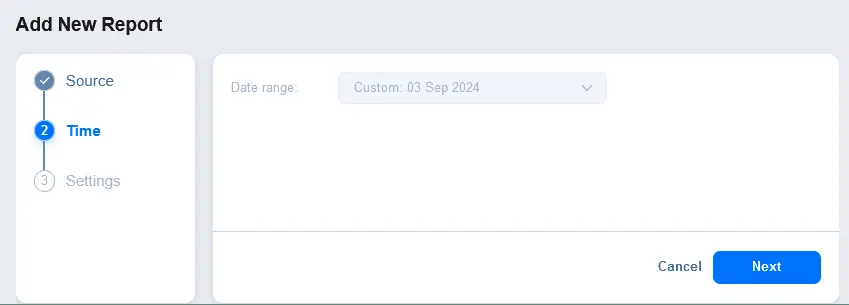
- Configura gli intervalli di data e ora per il rapporto. Ad esempio, puoi creare un rapporto per gli ultimi 30 giorni.
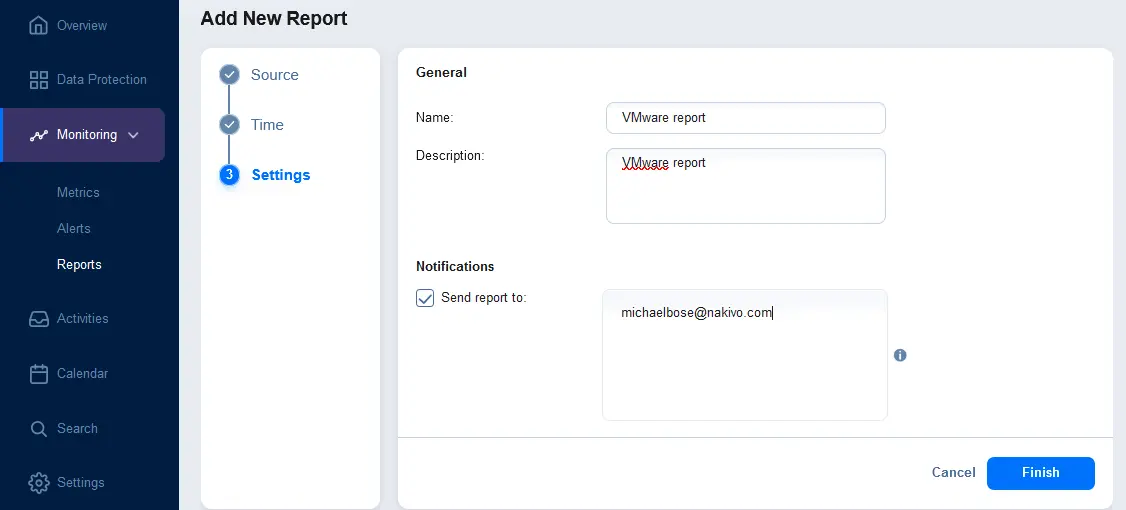
- Configura le impostazioni del report. Inserisci un nome e una descrizione del report visualizzato. Facoltativamente, nella sezione Notifiche, seleziona la casella per inviare un report agli indirizzi email specificati. Inserisci un indirizzo email e premi Invio per applicare questo indirizzo email. Puoi inserire più indirizzi email. Premi Fine per salvare le impostazioni per la creazione del report.
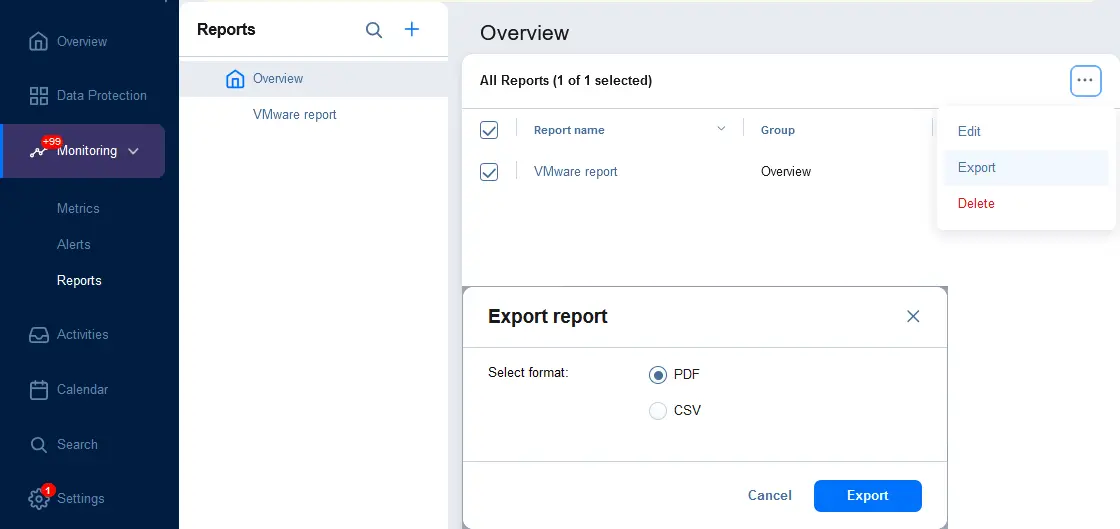
- Puoi esportare i report in un file. Vai a Monitoraggio > Report e seleziona i report che desideri esportare (seleziona le caselle di controllo). Fai clic sul pulsante … (ulteriori opzioni), fai clic su Esporta, e nella finestra di dialogo, seleziona il formato del file (PDF o CSV). Premi Esporta.
Conclusione
Il monitoraggio delle infrastrutture IT può migliorare l’efficienza dell’amministrazione, garantire la continuità aziendale e ridurre i costi. Si raccomanda di configurare gli strumenti di monitoraggio IT per inviare avvisi e report per una rapida risposta agli incidenti per prevenire potenziali problemi e risolvere i problemi esistenti il prima possibile. Usa NAKIVO Backup & Replication per proteggere i tuoi dati, comprese le macchine virtuali VMware, oltre a monitorare la tua infrastruttura vSphere e i lavori di protezione dei dati.
Source:
https://www.nakivo.com/blog/how-to-use-alarms-and-reporting-for-it-monitoring/