













Stato: Obsoleto
Questo articolo è obsoleto e non più mantenuto.
Motivo
I passaggi in questo tutorial funzionano ancora, ma produrranno una configurazione che ora è inutilmente difficile da mantenere.
Vedi Invece
Questo articolo potrebbe ancora essere utile come riferimento, ma potrebbe non seguire le migliori pratiche. Raccomandiamo vivamente di utilizzare un articolo più recente.
Introduzione
Insieme alla tracciatura e alla registrazione, il monitoraggio e l’allerta sono componenti essenziali di un stack di osservabilità Kubernetes. Configurare il monitoraggio per il cluster Kubernetes di DigitalOcean consente di tenere traccia dell’utilizzo delle risorse e analizzare e risolvere errori dell’applicazione.
A monitoring system usually consists of a time-series database that houses metric data and a visualization layer. In addition, an alerting layer creates and manages alerts, handing them off to integrations and external services as necessary. Finally, one or more components generate or expose the metric data that will be stored, visualized, and processed for alerts by the stack.
Una soluzione di monitoraggio popolare è lo stack open-source Prometheus, Grafana e Alertmanager, distribuito insieme a kube-state-metrics e node_exporter per esporre le metriche degli oggetti Kubernetes a livello di cluster e le metriche a livello di macchina come utilizzo CPU e memoria.
Implementare questo stack di monitoraggio su un cluster Kubernetes richiede la configurazione di singoli componenti, manifesti, metriche Prometheus e dashboard Grafana, il che può richiedere del tempo. Il Quickstart per il Monitoraggio del Cluster Kubernetes di DigitalOcean, rilasciato dal team di Educazione degli Sviluppatori della Community di DigitalOcean, contiene manifesti completamente definiti per uno stack di monitoraggio del cluster Prometheus-Grafana-Alertmanager, oltre a un insieme di allerte preconfigurate e dashboard Grafana. Può aiutarti a partire rapidamente e costituisce una solida base da cui costruire il tuo stack di osservabilità.
In questo tutorial, implementeremo questo stack preconfigurato su DigitalOcean Kubernetes, accederemo alle interfacce di Prometheus, Grafana e Alertmanager e descriveremo come personalizzarlo.
Prerequisiti
Prima di iniziare, avrai bisogno di un cluster Kubernetes DigitalOcean disponibile e dei seguenti strumenti installati nel tuo ambiente di sviluppo locale:
- Il comando di interfaccia a riga di comando
kubectlinstallato sulla tua macchina locale e configurato per connettersi al tuo cluster. Puoi leggere ulteriori informazioni sull’installazione e la configurazione dikubectlnella sua documentazione ufficiale. - Il sistema di controllo versione git installato sulla tua macchina locale. Per imparare come installare git su Ubuntu 18.04, consulta Come installare Git su Ubuntu 18.04.
- Lo strumento Coreutils base64 installato sulla tua macchina locale. Se stai utilizzando una macchina Linux, è probabile che sia già installato. Se stai utilizzando OS X, puoi utilizzare
openssl base64, che viene installato per impostazione predefinita.
<$>[nota]
Nota: La procedura di avvio rapido per il monitoraggio del cluster è stata testata solo su cluster Kubernetes DigitalOcean. Per utilizzare la procedura di avvio rapido con altri cluster Kubernetes, potrebbero essere necessarie alcune modifiche ai file di manifesto.
<$>
Passo 1 — Clonare il Repository GitHub e Configurare le Variabili d’Ambiente
Per iniziare, clonare il repository GitHub del Monitoraggio del Cluster Kubernetes di DigitalOcean sul proprio computer locale usando git:
Successivamente, navigare nel repository:
Dovresti vedere la seguente struttura delle directory:
OutputLICENSE
README.md
changes.txt
manifest
La directory manifest contiene manifest di Kubernetes per tutti i componenti dello stack di monitoraggio, inclusi Account dei Servizi, Deployments, StatefulSets, ConfigMaps, ecc. Per saperne di più su questi file di manifest e su come configurarli, vai avanti alla sezione Configurare lo Stack di Monitoraggio.
Se vuoi solo far funzionare le cose, inizia impostando le variabili d’ambiente APP_INSTANCE_NAME e NAMESPACE, che verranno utilizzate per configurare un nome unico per i componenti dello stack e configurare il Namespace in cui lo stack verrà distribuito:
In questo tutorial, impostiamo APP_INSTANCE_NAME su sammy-cluster-monitoring, che aggiungerà un prefisso a tutti i nomi degli oggetti Kubernetes dello stack di monitoraggio. Dovresti sostituire un prefisso descrittivo unico per il tuo stack di monitoraggio. Impostiamo anche il Namespace su default. Se desideri distribuire lo stack di monitoraggio in un Namespace diverso da default, assicurati prima di crearlo nel tuo cluster:
Dovresti vedere l’output seguente:
Outputnamespace/sammy created
In questo caso, la variabile d’ambiente NAMESPACE è stata impostata su sammy. Per il resto del tutorial, assumeremo che NAMESPACE sia stato impostato su default.
Adesso, usa il comando base64 per codificare in base64 una password sicura di Grafana. Assicurati di sostituire una password a tua scelta per your_grafana_password:
Se stai utilizzando macOS, puoi sostituire il comando openssl base64 che viene installato per default.
A questo punto, hai preso i manifesti Kubernetes dello stack e configurato le variabili d’ambiente richieste, quindi sei pronto per sostituire le variabili configurate nei file manifesto Kubernetes e creare lo stack nel tuo cluster Kubernetes.
Passaggio 2 — Creazione dello Stack di Monitoraggio
Il repository di DigitalOcean Kubernetes Monitoring Quickstart contiene manifesti per i seguenti componenti di monitoraggio, raccolta e visualizzazione:
- Prometheus è un database di serie temporali e strumento di monitoraggio che funziona interrogando endpoint di metriche e raccogliendo e elaborando i dati esposti da questi endpoint. Ti permette di interrogare questi dati utilizzando PromQL, un linguaggio di query per dati di serie temporali. Prometheus sarà distribuito nel cluster come un StatefulSet con 2 repliche che utilizzano Volumi Persistente con Block Storage di DigitalOcean. Inoltre, un set preconfigurato di Avvisi, Regole e Compiti di Prometheus sarà memorizzato come un ConfigMap. Per saperne di più su questi, passa alla sezione Prometheus della Configurazione dello Stack di Monitoraggio.
- Alertmanager, di solito implementato insieme a Prometheus, forma lo strato di avviso dello stack, gestendo gli avvisi generati da Prometheus e deduplicandoli, raggruppandoli e instradandoli verso integrazioni come email o PagerDuty. Alertmanager sarà installato come StatefulSet con 2 repliche. Per saperne di più su Alertmanager, consulta Alerting dalla documentazione di Prometheus.
- Grafana è uno strumento di visualizzazione e analisi dei dati che consente di creare dashboard e grafici per i tuoi dati metrici. Grafana sarà installato come StatefulSet con una replica. Inoltre, un set preconfigurato di Dashboard generato da kubernetes-mixin sarà memorizzato come ConfigMap.
- kube-state-metrics è un agente add-on che ascolta il server API di Kubernetes e genera metriche sullo stato degli oggetti Kubernetes come Deployment e Pods. Queste metriche vengono servite come testo semplice su endpoint HTTP e consumate da Prometheus. kube-state-metrics sarà installato come Deployment autoscalabile con una replica.
- node-exporter, un esportatore Prometheus che viene eseguito sui nodi del cluster e fornisce metriche del sistema operativo e dell’hardware come utilizzo della CPU e della memoria a Prometheus. Queste metriche vengono anche servite come testo semplice su endpoint HTTP e consumate da Prometheus. node-exporter sarà installato come DaemonSet.
Per impostazione predefinita, insieme allo scraping delle metriche generate da node-exporter, kube-state-metrics e gli altri componenti elencati sopra, Prometheus verrà configurato per raccogliere le metriche dai seguenti componenti:
- kube-apiserver, il server API di Kubernetes.
- kubelet, l’agente primario del nodo che interagisce con kube-apiserver per gestire Pod e contenitori su un nodo.
- cAdvisor, un agente di nodo che scopre i contenitori in esecuzione e raccoglie le loro metriche di utilizzo di CPU, memoria, filesystem e rete.
Per saperne di più sulla configurazione di questi componenti e sui lavori di scraping di Prometheus, passa avanti a Configurazione dello Stack di Monitoraggio. Ora sostituiremo le variabili d’ambiente definite nel passaggio precedente nei file di manifesto del repository e concatenare i singoli manifesti in un unico file principale.
Inizia utilizzando awk e envsubst per compilare le variabili APP_INSTANCE_NAME, NAMESPACE e GRAFANA_GENERATED_PASSWORD nei file di manifesto del repository. Dopo aver sostituito i valori delle variabili, i file verranno combinati e salvati in un file di manifesto principale chiamato sammy-cluster-monitoring_manifest.yaml.
Dovresti considerare di archiviare questo file nel controllo delle versioni in modo da poter tracciare le modifiche allo stack di monitoraggio e tornare a versioni precedenti. Se lo fai, assicurati di eliminare la variabile admin-password dal file in modo da non controllare la password di Grafana nel controllo delle versioni.
Ora che hai generato il file di manifesto principale, utilizza kubectl apply -f per applicare il manifesto e creare lo stack nel Namespace che hai configurato:
Dovresti vedere un output simile al seguente:
Outputserviceaccount/alertmanager created
configmap/sammy-cluster-monitoring-alertmanager-config created
service/sammy-cluster-monitoring-alertmanager-operated created
service/sammy-cluster-monitoring-alertmanager created
. . .
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/sammy-cluster-monitoring-prometheus-config created
service/sammy-cluster-monitoring-prometheus created
statefulset.apps/sammy-cluster-monitoring-prometheus created
Puoi seguire il progresso del deployment dello stack utilizzando kubectl get all. Una volta che tutti i componenti dello stack sono RUNNING, puoi accedere alle dashboard preconfigurate di Grafana tramite l’interfaccia web di Grafana.
Passaggio 3 — Accesso a Grafana ed Esplorazione dei Dati Metrici
Il manifesto del servizio Grafana espone Grafana come un Servizio ClusterIP, il che significa che è accessibile solo tramite un indirizzo IP interno al cluster. Per accedere a Grafana al di fuori del tuo cluster Kubernetes, puoi utilizzare kubectl patch per aggiornare il Servizio sul posto a un tipo visibile pubblicamente come NodePort o LoadBalancer, oppure utilizzare kubectl port-forward per inoltrare una porta locale a una porta del Pod Grafana. In questo tutorial inoltreremo le porte, quindi puoi saltare direttamente a Inoltro di una porta locale per accedere al servizio Grafana. La seguente sezione sulla esposizione di Grafana esternamente è inclusa solo a scopo di riferimento.
Esposizione del servizio Grafana utilizzando un bilanciamento del carico (opzionale)
Se desideri creare un Bilanciatore del Carico DigitalOcean per Grafana con un indirizzo IP pubblico esterno, utilizza kubectl patch per aggiornare il Servizio Grafana esistente sul posto al tipo di Servizio LoadBalancer:
Il comando patch di kubectl ti permette di aggiornare gli oggetti Kubernetes in loco per apportare modifiche senza dover ridistribuire gli oggetti. Puoi anche modificare direttamente il file di manifesto principale, aggiungendo un parametro type: LoadBalancer alla specifica del Servizio Grafana. Per saperne di più su kubectl patch e sui tipi di Servizio Kubernetes, puoi consultare le risorse Aggiornare gli oggetti API in loco utilizzando kubectl patch e Servizi nella documentazione ufficiale di Kubernetes.
Dopo aver eseguito il comando sopra, dovresti vedere quanto segue:
Outputservice/sammy-cluster-monitoring-grafana patched
Potrebbero volerci alcuni minuti per creare il Bilanciamento del Carico e assegnargli un IP pubblico. Puoi monitorare il suo progresso utilizzando il seguente comando con il flag -w per osservare le modifiche:
Una volta che il Bilanciamento del Carico di DigitalOcean è stato creato e gli è stato assegnato un indirizzo IP esterno, puoi recuperare il suo IP esterno utilizzando i seguenti comandi:
Adesso puoi accedere all’interfaccia utente di Grafana navigando su http://SERVICE_IP/.
Inoltrare una Porta Locale per Accedere al Servizio Grafana
Se non vuoi esporre il servizio Grafana esternamente, puoi inoltre inoltrare la porta locale 3000 direttamente al cluster verso un Pod Grafana usando kubectl port-forward.
Dovresti vedere il seguente output:
OutputForwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Questo inoltrerà la porta locale 3000 alla porta containerPort 3000 del Pod Grafana sammy-cluster-monitoring-grafana-0. Per saperne di più sull’inoltro delle porte in un cluster Kubernetes, consulta Usa l’inoltro delle porte per accedere alle applicazioni in un cluster.
Visita http://localhost:3000 nel tuo browser web. Dovresti vedere la seguente pagina di accesso di Grafana:

Per accedere, utilizza il nome utente predefinito admin (se non hai modificato il parametro admin-user) e la password configurata nella Fase 1.
Sarai portato al seguente Pannello di controllo principale:
Nella barra di navigazione sinistra, seleziona il pulsante Pannelli, quindi fai clic su Gestisci:
Sarai portato all’interfaccia di gestione dei pannelli seguente, che elenca i pannelli configurati nel manifesto dashboards-configmap.yaml:
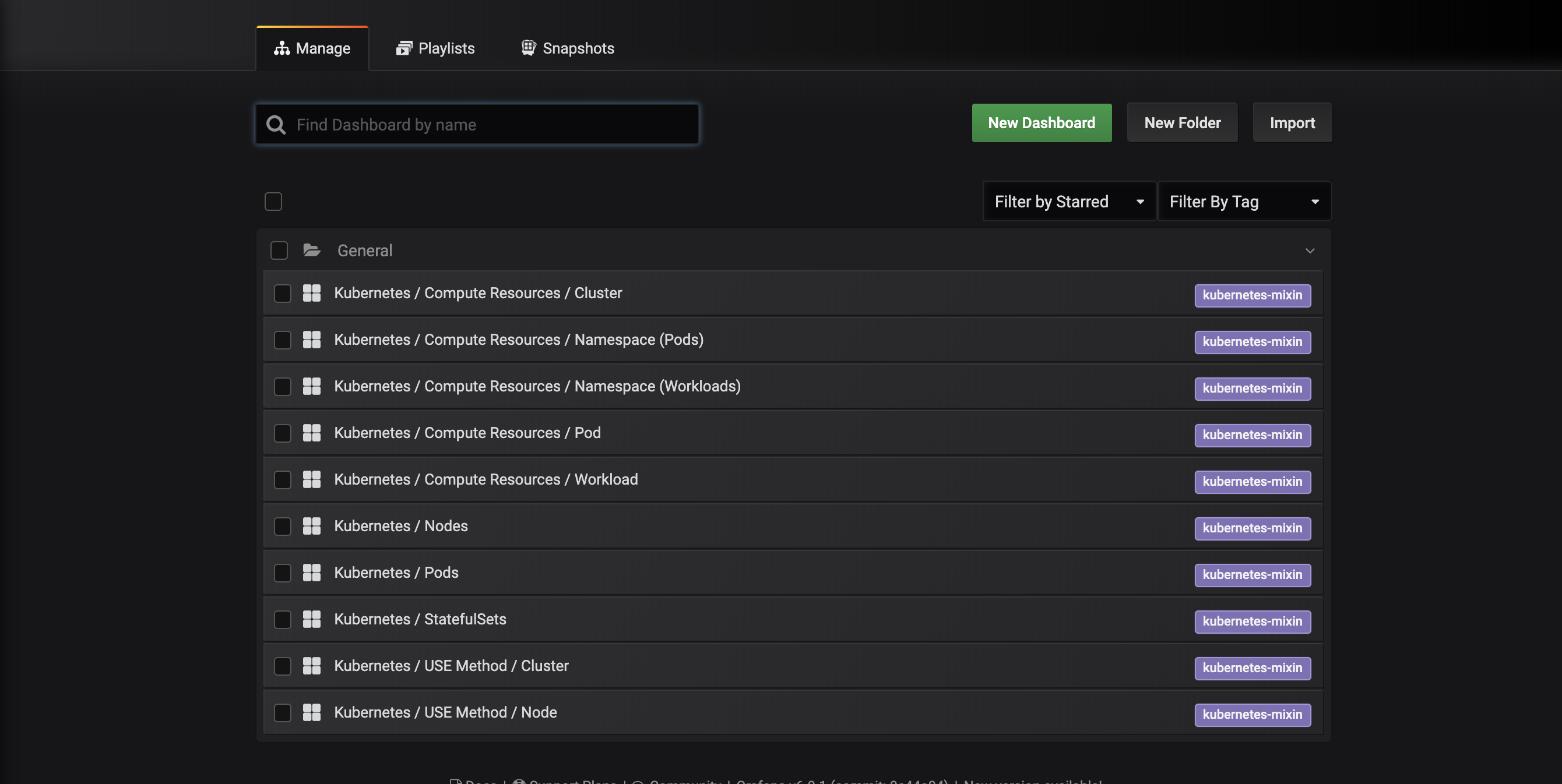
Questi dashboard sono generati da kubernetes-mixin, un progetto open source che ti consente di creare un set standardizzato di dashboard di monitoraggio del cluster Grafana e avvisi Prometheus. Per saperne di più, consulta il repository GitHub di kubernetes-mixin.
Fai clic sul dashboard Kubernetes / Nodi, che visualizza l’utilizzo della CPU, della memoria, del disco e della rete per un nodo specifico:
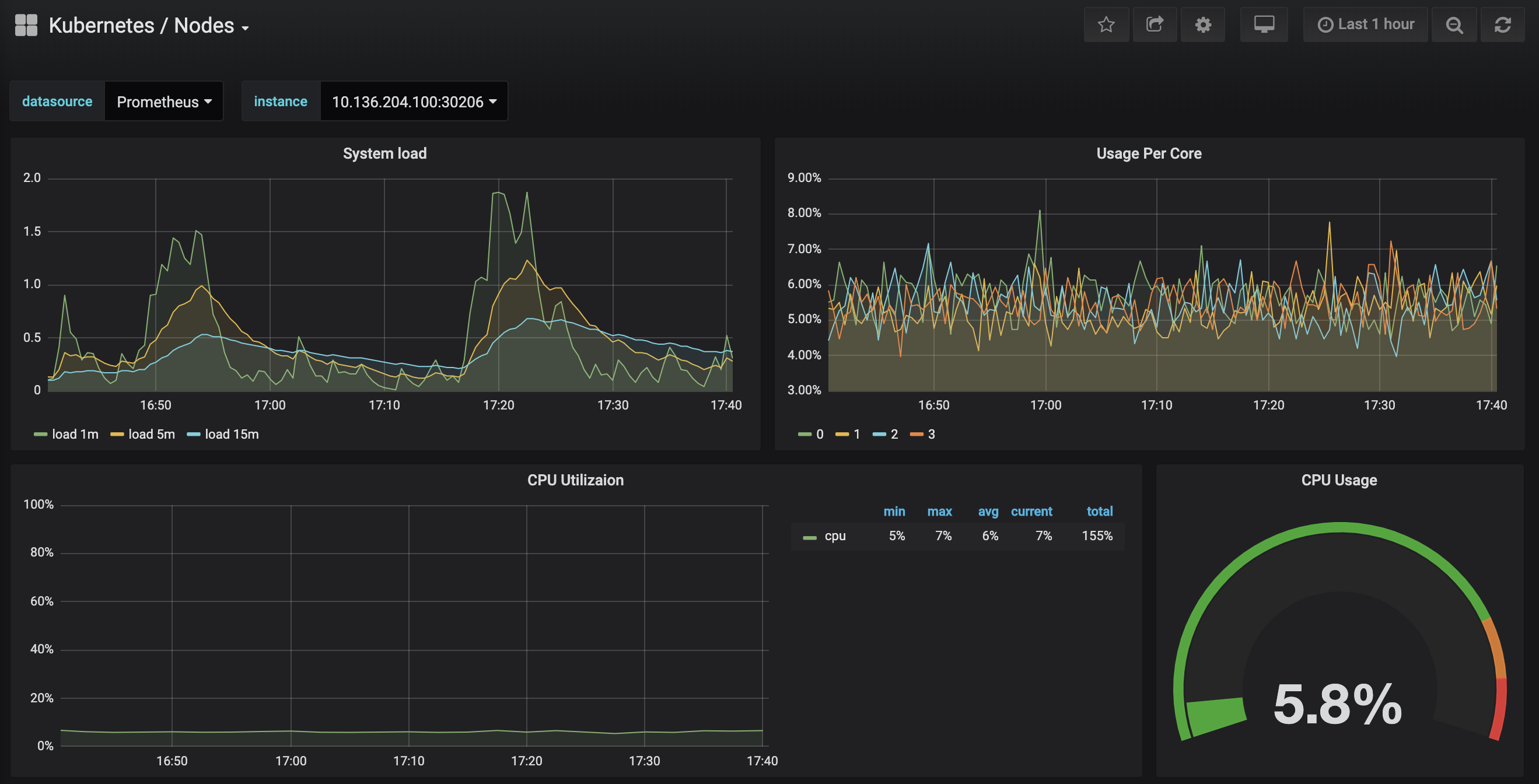
Descrivere come utilizzare questi dashboard è al di fuori dello scopo di questo tutorial, ma puoi consultare le seguenti risorse per saperne di più:
- Per saperne di più sul metodo USE per analizzare le prestazioni di un sistema, puoi consultare la pagina Il Metodo Utilizzazione, Saturazione e Errori (USE) di Brendan Gregg.
- Il Libro SRE di Google è un’altra risorsa utile, in particolare il Capitolo 6: Monitoraggio dei Sistemi Distribuiti.
- Per imparare come creare i tuoi dashboard Grafana, dai un’occhiata alla pagina Iniziare di Grafana.
Nel prossimo passaggio, seguiremo un processo simile per connetterci ed esplorare il sistema di monitoraggio Prometheus.
Passaggio 4 — Accesso a Prometheus e Alertmanager
Per connettersi ai Pods di Prometheus, è possibile utilizzare kubectl port-forward per inoltrare una porta locale. Se hai finito di esplorare Grafana, puoi chiudere il tunnel di inoltro della porta premendo CTRL-C. In alternativa, puoi aprire una nuova shell e creare una nuova connessione di inoltro della porta.
Inizia elencando i Pods in esecuzione nello spazio dei nomi default:
Dovresti vedere i seguenti Pods:
Outputsammy-cluster-monitoring-alertmanager-0 1/1 Running 0 17m
sammy-cluster-monitoring-alertmanager-1 1/1 Running 0 15m
sammy-cluster-monitoring-grafana-0 1/1 Running 0 16m
sammy-cluster-monitoring-kube-state-metrics-d68bb884-gmgxt 2/2 Running 0 16m
sammy-cluster-monitoring-node-exporter-7hvb7 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-c2rvj 1/1 Running 0 16m
sammy-cluster-monitoring-node-exporter-w8j74 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-0 1/1 Running 0 16m
sammy-cluster-monitoring-prometheus-1 1/1 Running 0 16m
Stiamo inoltrando la porta locale 9090 alla porta 9090 del Pod sammy-cluster-monitoring-prometheus-0:
Dovresti vedere il seguente output:
OutputForwarding from 127.0.0.1:9090 -> 9090
Forwarding from [::1]:9090 -> 9090
Ciò indica che la porta locale 9090 viene inoltrata correttamente al Pod di Prometheus.
Visita http://localhost:9090 nel tuo browser web. Dovresti vedere la seguente pagina di Grafico di Prometheus:

Da qui puoi utilizzare PromQL, il linguaggio di query di Prometheus, per selezionare e aggregare le metriche della serie temporale memorizzate nel suo database. Per saperne di più su PromQL, consulta Interrogare Prometheus dalla documentazione ufficiale di Prometheus.
Nel campo Espressione, digita kubelet_node_name e premi Esegui. Dovresti vedere un elenco di serie temporali con la metrica kubelet_node_name che riporta i Nodi nel tuo cluster Kubernetes. Puoi vedere quale nodo ha generato la metrica e quale job ha raschiato la metrica nei label della metrica:

Infine, nella barra di navigazione superiore, fai clic su Stato e poi su Obiettivi per vedere l’elenco degli obiettivi che Prometheus è stato configurato per raschiare. Dovresti vedere un elenco di obiettivi corrispondenti all’elenco dei punti di monitoraggio descritti all’inizio di Passaggio 2.
Per saperne di più su Prometheus e su come interrogare le metriche del tuo cluster, consulta la documentazione ufficiale di Prometheus.
Per connettersi ad Alertmanager, che gestisce gli avvisi generati da Prometheus, seguiremo un processo simile a quello utilizzato per connettersi a Prometheus. In generale, è possibile esplorare gli Avvisi di Alertmanager cliccando su Avvisi nella barra di navigazione superiore di Prometheus.
Per connettersi ai Pod di Alertmanager, utilizzeremo ancora una volta kubectl port-forward per inoltrare una porta locale. Se hai finito di esplorare Prometheus, puoi chiudere il tunnel di inoltro della porta premendo CTRL-C o aprire una nuova shell per creare una nuova connessione.
Stiamo per inoltrare la porta locale 9093 alla porta 9093 del Pod sammy-cluster-monitoring-alertmanager-0:
Dovresti vedere il seguente output:
OutputForwarding from 127.0.0.1:9093 -> 9093
Forwarding from [::1]:9093 -> 9093
Ciò indica che la porta locale 9093 viene inoltrata con successo a un Pod di Alertmanager.
Visita http://localhost:9093 nel tuo browser web. Dovresti vedere la seguente pagina Alerts di Alertmanager:
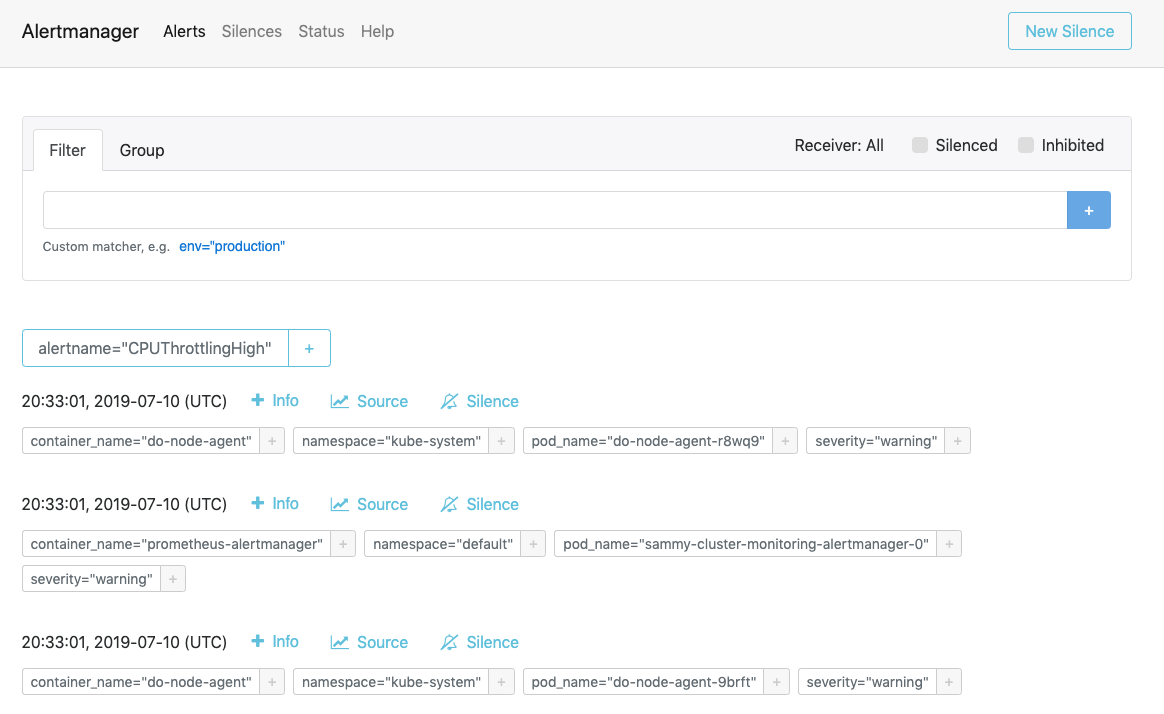
Da qui, puoi esplorare il lancio di avvisi e, eventualmente, metterli in silenzio. Per saperne di più su Alertmanager, consulta la documentazione ufficiale di Alertmanager.
Nel prossimo passaggio, imparerai come configurare e scalare facoltativamente alcuni dei componenti dello stack di monitoraggio.
Passaggio 6 — Configurazione dello Stack di Monitoraggio (opzionale)
I manifesti inclusi nel repository di Avvio rapido del monitoraggio del cluster Kubernetes di DigitalOcean possono essere modificati per utilizzare immagini container diverse, un numero diverso di repliche di Pod, porte diverse e file di configurazione personalizzati.
In questo passaggio, forniremo una panoramica ad alto livello dello scopo di ciascun manifesto e poi dimostreremo come scalare Prometheus fino a 3 repliche modificando il file manifesto principale.
Per iniziare, naviga nella sottodirectory manifests nel repository e elenca i contenuti della directory:
Outputalertmanager-0serviceaccount.yaml
alertmanager-configmap.yaml
alertmanager-operated-service.yaml
alertmanager-service.yaml
. . .
node-exporter-ds.yaml
prometheus-0serviceaccount.yaml
prometheus-configmap.yaml
prometheus-service.yaml
prometheus-statefulset.yaml
Qui troverai manifesti per i diversi componenti dello stack di monitoraggio. Per saperne di più sui parametri specifici nei manifesti, clicca sui link e consulta i commenti inclusi nei file YAML:
Alertmanager
-
alertmanager-0serviceaccount.yaml: Il Service Account di Alertmanager, utilizzato per dare agli Alertmanager Pods un’identità Kubernetes. Per saperne di più sui Service Accounts, consulta Configura Service Accounts per i Pods. -
alertmanager-configmap.yaml: Un ConfigMap contenente un file di configurazione minimo di Alertmanager, chiamatoalertmanager.yml. Configurare Alertmanager è al di là dello scopo di questo tutorial, ma puoi saperne di più consultando la sezione Configurazione della documentazione di Alertmanager. -
alertmanager-operated-service.yaml: Il servizio Alertmanagermesh, che viene utilizzato per instradare le richieste tra i Pod di Alertmanager nella configurazione attuale ad alta disponibilità a 2 repliche. -
alertmanager-service.yaml: Il servizio Alertmanagerweb, utilizzato per accedere all’interfaccia web di Alertmanager, che potresti aver fatto nel passaggio precedente. -
alertmanager-statefulset.yaml: Lo StatefulSet di Alertmanager, configurato con 2 repliche.
Grafana
-
dashboards-configmap.yaml: Un ConfigMap contenente le dashboard di monitoraggio Grafana preconfigurate in formato JSON. Generare un nuovo set di dashboard e allarmi da zero va oltre lo scopo di questo tutorial, ma per saperne di più puoi consultare il repository GitHub di kubernetes-mixin. -
grafana-0serviceaccount.yaml: Il Service Account di Grafana. -
grafana-configmap.yaml: Un ConfigMap che contiene un set predefinito di file di configurazione minimi di Grafana. -
grafana-secret.yaml: Un Segreto di Kubernetes contenente l’utente e la password di amministrazione di Grafana. Per saperne di più sui Secret di Kubernetes, consulta Secrets. -
grafana-service.yaml: Il manifesto che definisce il Servizio Grafana. -
grafana-statefulset.yaml: Lo StatefulSet di Grafana, configurato con 1 replica, che non è scalabile. L’escalation di Grafana è al di là dell’ambito di questo tutorial. Per imparare come creare una configurazione altamente disponibile di Grafana, puoi consultare Come configurare Grafana per l’alta disponibilità dalla documentazione ufficiale di Grafana.
kube-state-metrics
-
kube-state-metrics-0serviceaccount.yaml: L’Account del Servizio e il ClusterRole di kube-state-metrics. Per saperne di più sui ClusterRole, consulta Ruolo e ClusterRole dalla documentazione di Kubernetes. -
kube-state-metrics-deployment.yaml: Il manifesto principale di Deployment di kube-state-metrics, configurato con 1 replica scalabile dinamicamente utilizzandoaddon-resizer. -
kube-state-metrics-service.yaml: Il Servizio che espone il Deployment dikube-state-metrics.
node-exporter
-
node-exporter-0serviceaccount.yaml: L’account di servizio node-exporter. -
node-exporter-ds.yaml: Il manifesto del DaemonSet node-exporter. Poiché node-exporter è un DaemonSet, un Pod node-exporter viene eseguito su ogni nodo nel cluster.
###Prometheus
-
prometheus-0serviceaccount.yaml: L’account di servizio Prometheus, il ruolo del cluster e il binding del ruolo del cluster. -
prometheus-configmap.yaml: Un ConfigMap che contiene tre file di configurazione:alerts.yaml: Contiene un insieme preconfigurato di allarmi generati dakubernetes-mixin(che è stato utilizzato anche per generare i dashboard di Grafana). Per ulteriori informazioni sulla configurazione delle regole di allarme, consulta Regole di Allarme dalla documentazione di Prometheus.prometheus.yaml: Il file di configurazione principale di Prometheus. Prometheus è stato preconfigurato per raccogliere i dati da tutti i componenti elencati all’inizio di Passaggio 2. La configurazione di Prometheus va oltre lo scopo di questo articolo, ma per saperne di più, puoi consultare Configurazione nella documentazione ufficiale di Prometheus.rules.yaml: Un insieme di regole di registrazione di Prometheus che consentono a Prometheus di calcolare espressioni frequentemente necessarie o computazionalmente costose e salvare i risultati come un nuovo insieme di serie temporali. Anche queste sono generate dakubernetes-mixine la loro configurazione va oltre lo scopo di questo articolo. Per saperne di più, puoi consultare Regole di Registrazione nella documentazione ufficiale di Prometheus.
-
prometheus-service.yaml: Il servizio che espone l’StatefulSet di Prometheus. -
prometheus-statefulset.yaml: Lo StatefulSet di Prometheus, configurato con 2 repliche. Questo parametro può essere scalato a seconda delle tue esigenze.
Esempio: Scalinatura di Prometheus
Per mostrare come modificare lo stack di monitoraggio, scaliamo il numero di repliche di Prometheus da 2 a 3.
Apri il file manifesto principale sammy-cluster-monitoring_manifest.yaml con il tuo editor preferito:
Scorri fino alla sezione StatefulSet di Prometheus del manifesto:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 2
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Cambia il numero di repliche da 2 a 3:
Output. . .
apiVersion: apps/v1beta2
kind: StatefulSet
metadata:
name: sammy-cluster-monitoring-prometheus
labels: &Labels
k8s-app: prometheus
app.kubernetes.io/name: sammy-cluster-monitoring
app.kubernetes.io/component: prometheus
spec:
serviceName: "sammy-cluster-monitoring-prometheus"
replicas: 3
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels: *Labels
template:
metadata:
labels: *Labels
spec:
. . .
Quando hai finito, salva e chiudi il file.
Applica le modifiche usando kubectl apply -f:
Puoi monitorare il progresso usando kubectl get pods. Utilizzando questa stessa tecnica, puoi aggiornare molti dei parametri di Kubernetes e gran parte della configurazione per questo stack di osservabilità.
Conclusione
In questo tutorial, hai installato uno stack di monitoraggio Prometheus, Grafana e Alertmanager nel tuo cluster Kubernetes di DigitalOcean con un set standard di dashboard, regole di Prometheus e avvisi.
Puoi anche scegliere di distribuire questo stack di monitoraggio utilizzando il gestore dei pacchetti Kubernetes Helm. Per saperne di più, consulta Come configurare il monitoraggio del cluster Kubernetes di DigitalOcean con Helm e Prometheus. Un modo alternativo per avviare un stack simile è utilizzare la soluzione Stack di Monitoraggio Kubernetes di DigitalOcean Marketplace, attualmente in versione beta.
Il repository di avvio rapido per il monitoraggio del cluster Kubernetes di DigitalOcean si basa pesantemente su e è modificato dalla soluzione click-to-deploy di Prometheus di Google Cloud Platform. Un elenco completo delle modifiche e dei cambiamenti rispetto al repository originale può essere trovato nel file changes.md del repository di avvio rapido.