













Introduzione
Le organizzazioni che stanno sempre più adottando Kubernetes per gestire i loro contenitori hanno bisogno di una soluzione per monitorare la salute del loro sistema distribuito. Per questo motivo, entra in gioco Prometheus – un potente strumento open-source per monitorare le applicazioni containerizzate nel tuo spazio K8s.
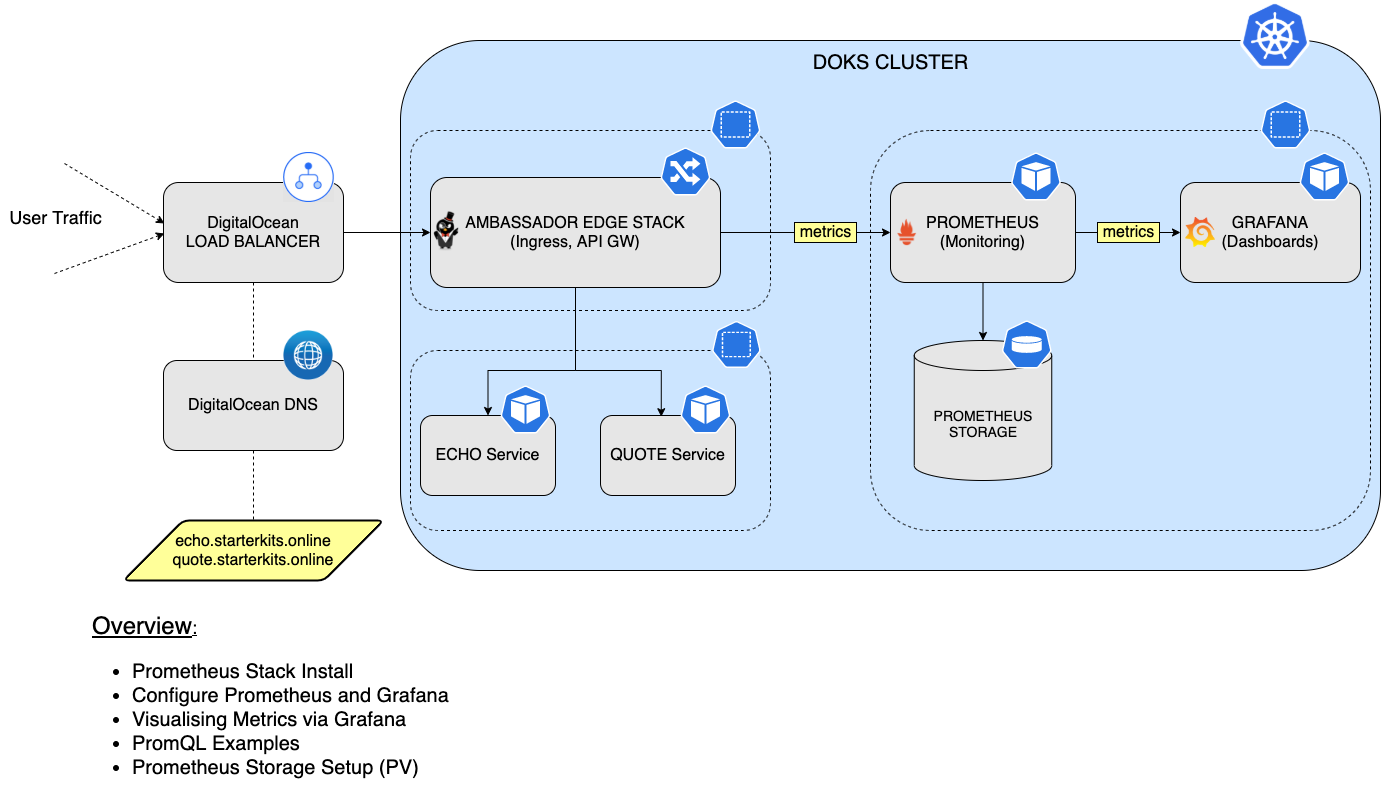
In questo tutorial, imparerai come installare e configurare lo stack Prometheus, per monitorare tutti i pod dal tuo cluster DOKS, nonché le metriche dello stato del cluster Kubernetes. Successivamente, connetterai Prometheus a Grafana per visualizzare tutte le metriche e eseguire query utilizzando il linguaggio PromQL. Infine, configurerai lo storage persistente per la tua istanza di Prometheus, per conservare tutti i dati delle metriche del cluster DOKS e delle applicazioni.
Tabella dei contenuti
- Prerequisiti
- Passaggio 1 – Installazione dello stack Prometheus
- Passaggio 2 – Configurare Prometheus e Grafana
- Passaggio 3 – PromQL (Linguaggio di interrogazione Prometheus)
- Passaggio 4 – Visualizzare le metriche utilizzando Grafana
- Passaggio 5 – Configurazione dello Storage Persistente per Prometheus
- Passaggio 6 – Configurazione dello Storage Persistente per Grafana
- Conclusioni
Prerequisiti
Per completare questo tutorial, avrai bisogno di:
- A Git client to clone the Starter Kit repository.
- Helm per gestire le distribuzioni e gli aggiornamenti dello stack di Prometheus.
- Kubectl per l’interazione con Kubernetes.
- Curl per testare gli esempi (applicazioni backend).
- Applicazione di Esempio Emojivoto distribuita nel cluster. Segui i passaggi nel README del repository.
Assicurati che il contesto di kubectl sia configurato per puntare al tuo cluster Kubernetes. Consulta Passaggio 3 – Creazione del Cluster DOKS dal tutorial di configurazione di DOKS.
Passaggio 1 – Installazione dello Stack Prometheus
In questo passaggio, installerai lo stack kube-prometheus, che è uno stack di monitoraggio completo per Kubernetes. Include l’Operatore Prometheus, kube-state-metrics, manifesti pre-costruiti, Node Exporters, Metrics API, Alerts Manager e Grafana.
Utilizzerai il gestore dei pacchetti Helm per completare questa attività. La chart Helm è disponibile qui per lo studio.
Per prima cosa, clona il repository Starter Kit e cambia la directory con la tua copia locale.
Successivamente, aggiungi il repository Helm e elenca le chart disponibili:
L’output assomiglia a quanto segue:
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 0.18.1 v0.23.0 The Alertmanager handles alerts sent by client ...
prometheus-community/kube-prometheus-stack 35.5.1 0.56.3 kube-prometheus-stack collects Kubernetes manif...
...
La chart di interesse è prometheus-community/kube-prometheus-stack che installerà Prometheus, Promtail, Alertmanager e Grafana sul cluster. Visita la pagina kube-prometheus-stack per ulteriori dettagli su questa chart.
Quindi, apri e ispeziona il file 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornito nel repository Starter Kit utilizzando un editor a tua scelta (preferibilmente con supporto per il lint YAML). Per impostazione predefinita, le metriche di kubeSched e etcd sono disabilitate: questi componenti sono gestiti da DOKS e non sono accessibili a Prometheus. Nota che lo storage è impostato su emptyDir. Significa che lo storage verrà eliminato se i pod di Prometheus vengono riavviati (risolverai questo problema in seguito nella sezione Configurazione dello Storage Persistente per Prometheus).
[OPZIONALE] Se hai seguito il Passaggio 4 – Aggiunta di un nodo dedicato per l’osservabilità della guida Configurazione di un Cluster Kubernetes Gestito da DigitalOcean, dovrai modificare il file 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornito nel repository Starter Kit e decommentare le sezioni affinity sia per Grafana che per Prometheus.
Spiegazioni per la configurazione sopra riportata:
preferredDuringSchedulingIgnoredDuringExecution– lo scheduler cerca di trovare un nodo che soddisfi la regola. Se un nodo corrispondente non è disponibile, lo scheduler comunque pianifica il Pod.preference.matchExpressions– selettore utilizzato per corrispondere a un nodo specifico in base a un criterio. L’esempio sopra indica al programma di pianificazione di posizionare i carichi di lavoro (ad es. Pod) su nodi etichettati utilizzando la chiave –preferrede il valore –observability.
Infine, installa lo stack kube-prometheus-stack, utilizzando Helm:
A specific version of the Helm chart is used. In this case 35.5.1 was picked, which maps to the 0.56.3 version of the application (see output from Step 2.). It’s a good practice to lock on a specific version. This helps to have predictable results and allows versioning control via Git.
–create-namespace \
Ora, controlla lo stato del rilascio di Helm dello stack Prometheus:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prom-stack monitoring 1 2022-06-07 09:52:53.795003 +0300 EEST deployed kube-prometheus-stack-35.5.1 0.56.3
L’output è simile al seguente. Nota il valore della colonna STATUS – dovrebbe dire deployed.
Vedi quali risorse Kubernetes sono disponibili per Prometheus:
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prom-stack-kube-prome-alertmanager-0 2/2 Running 0 3m3s
pod/kube-prom-stack-grafana-8457cd64c4-ct5wn 2/2 Running 0 3m5s
pod/kube-prom-stack-kube-prome-operator-6f8b64b6f-7hkn7 1/1 Running 0 3m5s
pod/kube-prom-stack-kube-state-metrics-5f46fffbc8-mdgfs 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-gcb8s 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-kc5wz 1/1 Running 0 3m5s
pod/kube-prom-stack-prometheus-node-exporter-qn92d 1/1 Running 0 3m5s
pod/prometheus-kube-prom-stack-kube-prome-prometheus-0 2/2 Running 0 3m3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m3s
service/kube-prom-stack-grafana ClusterIP 10.245.147.83 <none> 80/TCP 3m5s
service/kube-prom-stack-kube-prome-alertmanager ClusterIP 10.245.187.117 <none> 9093/TCP 3m5s
service/kube-prom-stack-kube-prome-operator ClusterIP 10.245.79.95 <none> 443/TCP 3m5s
service/kube-prom-stack-kube-prome-prometheus ClusterIP 10.245.86.189 <none> 9090/TCP 3m5s
service/kube-prom-stack-kube-state-metrics ClusterIP 10.245.119.83 <none> 8080/TCP 3m5s
service/kube-prom-stack-prometheus-node-exporter ClusterIP 10.245.47.175 <none> 9100/TCP 3m5s
service/prometheus-operated ClusterIP None <none> 9090/TCP 3m3s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/kube-prom-stack-prometheus-node-exporter 3 3 3 3 3 <none> 3m5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-prom-stack-grafana 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-prome-operator 1/1 1 1 3m5s
deployment.apps/kube-prom-stack-kube-state-metrics 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-prom-stack-grafana-8457cd64c4 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-prome-operator-6f8b64b6f 1 1 1 3m5s
replicaset.apps/kube-prom-stack-kube-state-metrics-5f46fffbc8 1 1 1 3m5s
NAME READY AGE
statefulset.apps/alertmanager-kube-prom-stack-kube-prome-alertmanager 1/1 3m3s
statefulset.apps/prometheus-kube-prom-stack-kube-prome-prometheus 1/1 3m3s
Dovresti avere le seguenti risorse distribuite: prometheus-node-exporter, kube-prome-operator, kube-prome-alertmanager, kube-prom-stack-grafana e kube-state-metrics. L’output è simile a:
Quindi, puoi connetterti a Grafana (utilizzando le credenziali predefinite: admin/prom-operator – vedi file prom-stack-values-v35.5.1), facendo il port forwarding alla macchina locale:
Non dovresti ASSOLUTAMENTE esporre Grafana alla rete pubblica (es. creando un mapping di ingresso o un servizio di bilanciamento del carico) con login/password predefiniti.
L’installazione di Grafana viene fornita con diversi dashboard. Apri un browser web su localhost:3000. Una volta dentro, puoi andare su Dashboards -> Sfoglia e scegliere diversi dashboard.
Nella prossima parte, scoprirai come configurare Prometheus per scoprire i target da monitorare. Come esempio, verrà utilizzata l’applicazione di esempio Emojivoto. Imparerai anche cos’è un ServiceMonitor.
Passaggio 2 – Configurare Prometheus e Grafana
Hai già distribuito Prometheus e Grafana nel cluster. In questo passaggio, imparerai come utilizzare un ServiceMonitor. Un ServiceMonitor è uno dei modi preferiti per indicare a Prometheus come scoprire un nuovo target da monitorare.
Il Deployment di Emojivoto creato nel Passaggio 5 della sezione Prerequisiti fornisce l’endpoint /metrics per impostazione predefinita sulla porta 8801 tramite un servizio Kubernetes.
Successivamente, scoprirai i servizi Emojivoto responsabili di esporre i dati delle metriche per Prometheus da consumare. I servizi in questione si chiamano emoji-svc e voting-svc (nota che utilizza il namespace emojivoto):
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
emoji-svc ClusterIP 10.245.135.93 <none> 8080/TCP,8801/TCP 22h
voting-svc ClusterIP 10.245.164.222 <none> 8080/TCP,8801/TCP 22h
web-svc ClusterIP 10.245.61.229 <none> 80/TCP 22h
L’output assomiglia al seguente:
Successivamente, esegui un port-forward per ispezionare le metriche:
Le metriche esposte possono essere visualizzate navigando con un browser web su localhost o tramite curl:
L'output assomiglia a quanto segue:
go_gc_duration_seconds{quantile="0"} 5.317e-05
go_gc_duration_seconds{quantile="0.25"} 0.000105305
go_gc_duration_seconds{quantile="0.5"} 0.000138168
go_gc_duration_seconds{quantile="0.75"} 0.000225651
go_gc_duration_seconds{quantile="1"} 0.016986437
go_gc_duration_seconds_sum 0.607979843
go_gc_duration_seconds_count 2097
# TYPE go_gc_duration_seconds summary
Per ispezionare le metriche per il servizio voting-svc, interrompere il port forwarding del emoji-svc e eseguire gli stessi passaggi per il secondo servizio.
- Successivamente, collegare Prometheus al servizio di metriche Emojivoto. Ci sono diversi modi per farlo:
- <static_config> – consente di specificare un elenco di target e un set di etichette comuni per essi.
- <kubernetes_sd_config> – consente di recuperare i target di scraping dall’API REST di Kubernetes e di rimanere sempre sincronizzati con lo stato del cluster.
Prometheus Operator – semplifica il monitoraggio di Prometheus all’interno di un cluster Kubernetes tramite CRD.
Successivamente, si farà uso del CRD ServiceMonitor esposto dal Prometheus Operator per definire un nuovo target per il monitoraggio.
Prima, cambiare la directory (se non già) dove è stato clonato il repository Git del Kit di Avviamento:
Successivamente, apri il file 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornito nel repository Starter Kit utilizzando un editor di testo a tua scelta (preferibilmente con supporto per il controllo YAML). Rimuovi i commenti che circondano la sezione additionalServiceMonitors. L’output assomiglierà a quanto segue:
- Spiegazioni per la configurazione sopra:
selector -> matchExpressions– indica aServiceMonitorquale servizio monitorare. Mirerà a tutti i servizi con la chiave di etichetta app e i valoriemoji-svcevoting-svc. Le etichette possono essere ottenute eseguendo:kubectl get svc --show-labels -n emojivotonamespaceSelector– qui, si desidera corrispondere allo spazio dei nomi in cui è stato distribuitoEmojivoto.
endpoints -> port – fa riferimento alla porta del servizio da monitorare.
Infine, applica le modifiche utilizzando Helm:
Successivamente, controlla se il target Emojivoto è stato aggiunto a Prometheus per lo scraping. Crea un port forwarding per Prometheus sulla porta 9090:
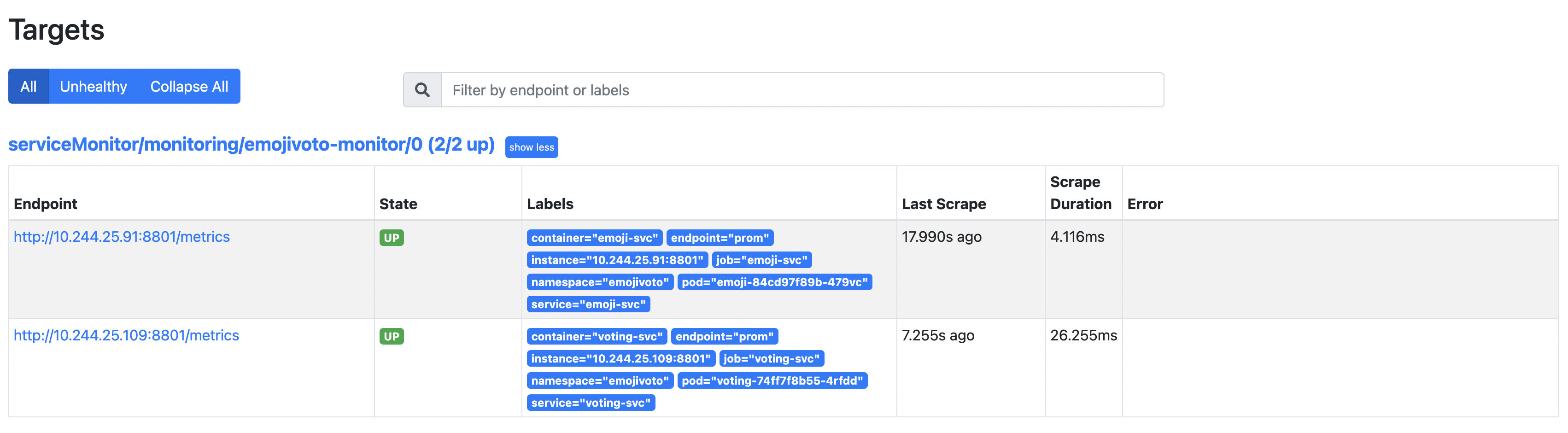
Apri un browser web su localhost:9090. Quindi, vai alla pagina Status -> Targets, e ispeziona i risultati (nota il percorso serviceMonitor/monitoring/emojivoto-monitor/0):
Ci sono 2 voci sotto i target scoperti perché il deployment di Emojivoto consiste in 2 servizi che espongono il punto di endpoint delle metriche.
Nel prossimo passo, scoprirai PromQL insieme ad alcuni semplici esempi per iniziare e scoprire il linguaggio.
Passaggio 3 – PromQL (Prometheus Query Language)
In questo passaggio, imparerai le basi del linguaggio di interrogazione Prometheus (PromQL). PromQL ti aiuta a eseguire interrogazioni su varie metriche provenienti da tutti i Pod e dalle applicazioni del tuo cluster DOKS.
PromQL è un DSL o linguaggio specifico del dominio che è stato creato appositamente per Prometheus e ti consente di interrogare le metriche. L’espressione complessiva definisce il valore finale, mentre le espressioni nidificate rappresentano i valori degli argomenti e degli operandi. Per spiegazioni più dettagliate, visita la pagina ufficiale di PromQL.
Successivamente, andrai a ispezionare una delle metriche di Emojivoto, ovvero emojivoto_votes_total, che rappresenta il numero totale di voti. Si tratta di un valore di contatore che aumenta con ogni richiesta verso il punto finale dei voti di Emojivoto.
Prima, crea un inoltro di porta per Prometheus sulla porta 9090:
Successivamente, apri l’esploratore di espressioni.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 20
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
Nel campo di input della query incolla emojivoto_votes_total e premi invio. L’output assomiglia a:
Vai all’applicazione Emojivoto e dalla homepage clicca sull’emoji 100 per votarla.
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 17
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 21
emojivoto_votes_total{container="voting-svc", emoji=":basketball_man:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beach_umbrella:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 10
emojivoto_votes_total{container="voting-svc", emoji=":beer:", endpoint="prom", instance="10.244.25.31:8801", job="voting-svc", namespace="emojivoto", pod="voting-74ff7f8b55-jl6qs", service="voting-svc"} 11
Vai alla pagina dei risultati della query dal Passaggio 3 e clicca sul pulsante Esegui. Dovresti vedere il contatore per l’emoji 100 aumentare di uno. L’output appare simile a:
PromQL raggruppa dati simili in ciò che viene chiamato un vettore. Come visto sopra, ogni vettore ha un insieme di attributi che lo differenziano dagli altri. Puoi raggruppare i risultati in base a un attributo di interesse. Ad esempio, se ti interessano solo le richieste provenienti dal servizio voting-svc, allora per favore digita quanto segue nel campo della query:
emojivoto_votes_total{container="voting-svc", emoji=":100:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 492
emojivoto_votes_total{container="voting-svc", emoji=":bacon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 532
emojivoto_votes_total{container="voting-svc", emoji=":balloon:", endpoint="prom", instance="10.244.6.91:8801", job="voting-svc", namespace="emojivoto", pod="voting-6548959dd7-hssh2", service="voting-svc"} 521
L’output appare simile a (nota che seleziona solo i risultati che corrispondono ai tuoi criteri):
Il risultato sopra mostra le richieste totali per ogni Pod dal deployment di Emojivoto che emette metriche (che consiste in 2).
Questa è solo una introduzione molto semplice a cosa sia PromQL e a cosa sia in grado di fare. Ma può fare molto di più di quello, come conteggiare le metriche, calcolare il tasso su un intervallo predefinito, ecc. Visita la pagina ufficiale di PromQL per ulteriori funzionalità del linguaggio.
Nel prossimo passaggio, imparerai come utilizzare Grafana per visualizzare le metriche per l’applicazione di esempio Emojivoto.
Passaggio 4 – Visualizzazione delle Metriche Utilizzando Grafana
Anche se Prometheus ha un certo supporto integrato per la visualizzazione dei dati, un modo migliore di farlo è tramite Grafana, che è una piattaforma open-source per il monitoraggio e l’osservabilità, che ti consente di visualizzare ed esplorare lo stato del tuo cluster.
La pagina ufficiale è descritta come in grado di:
Interrogare, visualizzare, impostare allarmi su e comprendere i tuoi dati ovunque siano memorizzati.
Non sono necessari passaggi aggiuntivi per installare Grafana perché il Passaggio 1 – Installazione dello Stack Prometheus l’ha installato per te. Tutto ciò che devi fare è un forwarding di porta come indicato di seguito e ottenere immediato accesso ai cruscotti (credenziali predefinite: admin/prom-monitor):
Per vedere tutte le metriche di Emojivoto, userai uno dei cruscotti predefiniti installati da Grafana.
Naviga alla sezione Cruscotti Grafana.
Successivamente, cerca il cruscotto Generale/Kubernetes/Risorse di Calcolo/Namespace (Pods) e accedici.
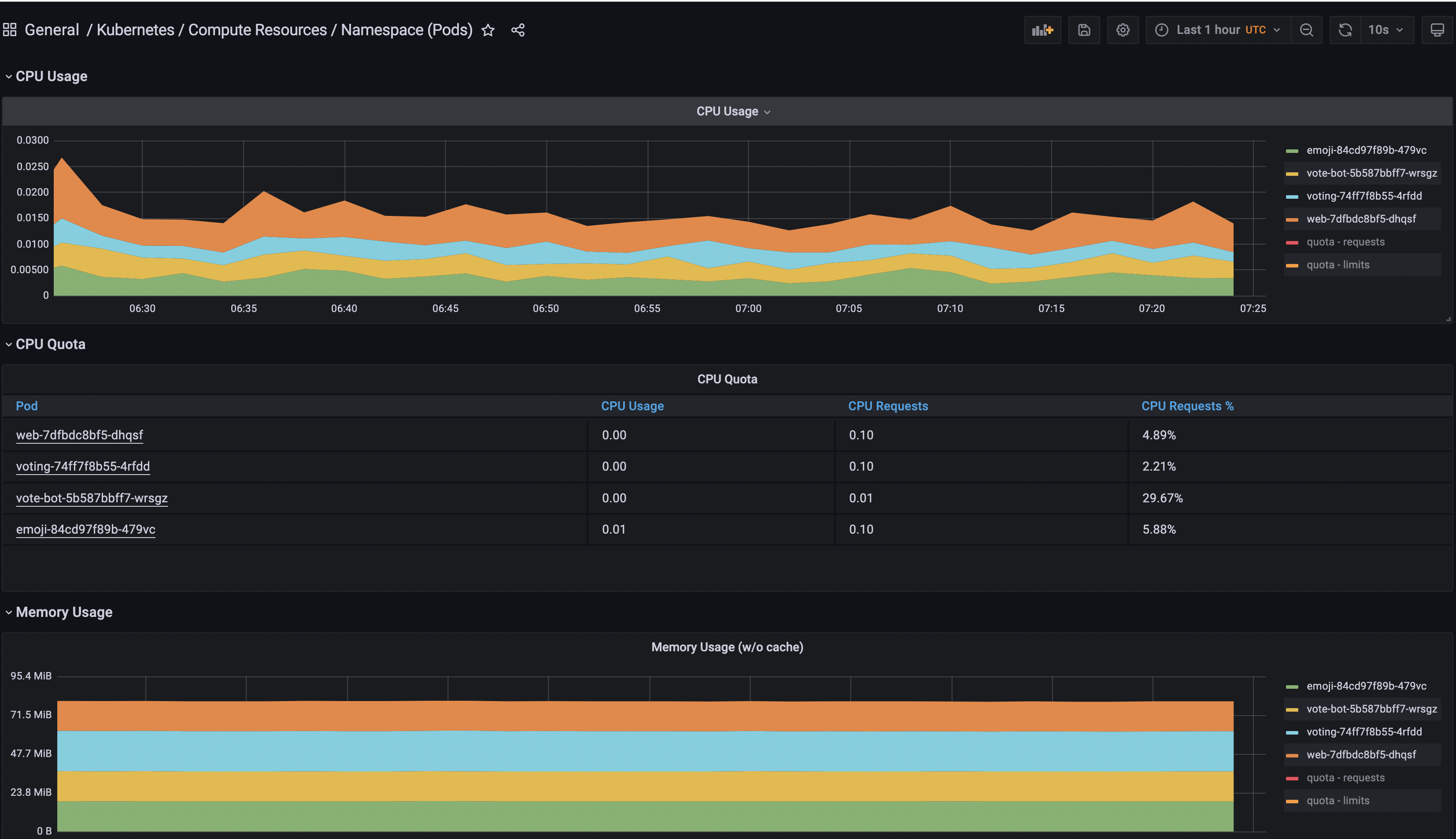
Infine, seleziona l’Origine dati Prometheus e aggiungi il namespace emojivoto.
Puoi giocare e aggiungere più pannelli in Grafana per visualizzare altre fonti di dati, nonché raggrupparle in base allo scopo. Inoltre, puoi esplorare i dashboard disponibili per Kubernetes dal progetto kube-mixin di Grafana.
Nel prossimo passaggio, configurerai lo storage persistente per Prometheus utilizzando lo storage a blocchi di DigitalOcean per conservare i tuoi metriche DOKS e dell’applicazione attraverso riavvii del server o guasti del cluster.
Passaggio 5 – Configurazione dello Storage Persistente per Prometheus
In questo passaggio, imparerai come abilitare lo storage persistente per Prometheus in modo che i dati delle metriche siano conservati attraverso riavvii del server o in caso di guasti del cluster.
Prima, è necessario disporre di una classe di storage per procedere. Esegui il seguente comando per verificare quale sia disponibile.
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
do-block-storage (default) dobs.csi.digitalocean.com Delete Immediate true 4d2h
L’output dovrebbe essere simile al seguente. Nota che lo Storage a Blocchi di DigitalOcean è disponibile per te da utilizzare.
Successivamente, cambia la directory (se non lo è già) in cui è stato clonato il repository Git del Kit di Avvio:
Quindi, aprire il file 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornito nel repository del Starter Kit utilizzando un editor di testo a tua scelta (preferibilmente con supporto per il lint YAML). Cerca la linea storageSpec e rimuovi il commento dalla sezione richiesta per Prometheus. La definizione di storageSpec dovrebbe assomigliare a:
- Spiegazioni per la configurazione sopra:
volumeClaimTemplate– definisce un nuovo PVC.storageClassName– definisce la classe di archiviazione (dovrebbe utilizzare lo stesso valore ottenuto dall’output del comandokubectl get storageclass).
resources – imposta il valore delle richieste di archiviazione. In questo caso, viene richiesta una capacità totale di 5 Gi per il nuovo volume.
Infine, applica le impostazioni utilizzando Helm:
Dopo aver completato i passaggi sopra, controlla lo stato del PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prome-prometheus-0 Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

L’output appare simile al seguente. La colonna STATUS dovrebbe mostrare Bound.
Passaggio 6 – Configurazione dell’Archiviazione Persistente per Grafana
In questo passaggio, imparerai come abilitare lo storage persistente per Grafana in modo che i grafici siano conservati attraverso riavvii del server o in caso di fallimenti del cluster. Definirai una richiesta di volume persistente (PVC) da 5 Gi, utilizzando il DigitalOcean Block Storage. I passaggi successivi sono gli stessi di Passaggio 5 – Configurazione dello Storage Persistente per Prometheus.
Per prima cosa, apri il file 04-setup-observability/assets/manifests/prom-stack-values-v35.5.1.yaml fornito nel repository del Kit di Avvio, utilizzando un editor di testo a tua scelta (preferibilmente con supporto YAML lint). La sezione dello storage di persistenza per Grafana dovrebbe apparire come segue:
Successivamente, applica le impostazioni usando Helm:
Dopo aver completato i passaggi precedenti, controlla lo stato del PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES AGE
kube-prom-stack-grafana Bound pvc-768d85ff-17e7-4043-9aea-4929df6a35f4 5Gi RWO do-block-storage 4d2h
A new Volume should appear in the Volumes web page from your DigitalOcean account panel:

L’output assomiglia al seguente. La colonna STATUS dovrebbe mostrare Bound.
Pratiche consigliate per la dimensione dei PV
- Per calcolare la dimensione necessaria per il volume in base alle tue esigenze, segui i consigli e la formula ufficiale della documentazione:
- Prometheus memorizza in media solo 1-2 byte per campione. Pertanto, per pianificare la capacità di un server Prometheus, è possibile utilizzare la formula approssimativa:
spazio_su_disk_necessario = tempo_di_retention_secondi * campioni_ingestati_al_secondo * byte_per_campione
Per ridurre il tasso di campioni ingeriti, è possibile ridurre il numero di serie temporali che si raschia (meno obiettivi o meno serie per obiettivo), oppure è possibile aumentare l’intervallo di raschiatura. Tuttavia, ridurre il numero di serie è probabilmente più efficace, a causa della compressione dei campioni all’interno di una serie.
Si prega di seguire la sezione Aspetti Operativi per ulteriori dettagli sull’argomento.
In questo tutorial, hai imparato come installare e configurare lo stack Prometheus, quindi hai usato Grafana per installare nuovi cruscotti e visualizzare le metriche dell’applicazione del cluster DOKS. Hai anche imparato come eseguire query metriche utilizzando PromQL. Infine, hai configurato ed abilitato lo storage persistente per Prometheus per memorizzare le metriche del tuo cluster.
- Ulteriori informazioni
- Monitoraggio e conservazione dei log di Kubernetes utilizzando Grafana Loki e DigitalOcean Spaces
- Best Practice nel monitoraggio di un cluster Kubernetes con Prometheus, Grafana e Loki
Configurare il monitoraggio del cluster DOKS con Helm e l’operatore Prometheus