













Avvertenza: Tutti i punti di vista e le opinioni espressi nel blog appartengono esclusivamente all’autore e non necessariamente al datore di lavoro dell’autore o a qualsiasi altro gruppo o individuo. Questo articolo non è una promozione per piattaforme di gestione cloud/dati. Tutte le immagini e le API sono pubblicamente disponibili sul sito web di Azure/Databricks.
Cos’è il Monitoraggio Lakehouse di Databricks?
Nel miei altri articoli, ho descritto cos’è Databricks e Unity Catalog, e come creare un catalogo da zero utilizzando uno script. In questo articolo, descriverò la funzionalità di Monitoraggio Lakehouse disponibile come parte della piattaforma Databricks e come abilitare la funzionalità utilizzando script.
Il Monitoraggio Lakehouse fornisce il profilo dei dati e le metriche relative alla qualità dei dati per le Tabelle Live Delta in Lakehouse. Il Monitoraggio Lakehouse di Databricks fornisce una visione completa dei dati come cambiamenti nel volume dei dati, cambiamenti nella distribuzione numerica, % di valori nulli e zeri nelle colonne, e rilevamento di anomalie categoriali nel tempo.
Perché utilizzare il Monitoraggio Lakehouse?
Il monitoraggio dei dati e delle prestazioni del modello ML fornisce misure quantitative che ti aiutano a tracciare e confermare la qualità e la coerenza dei tuoi dati e delle prestazioni del modello nel tempo.
Ecco una panoramica delle caratteristiche chiave:
- Monitoraggio della qualità dei dati e dell’integrità dei dati: Traccia il flusso dei dati attraverso i pipeline, garantendo l’integrità dei dati e offrendo visibilità su come i dati sono cambiati nel tempo, 90° percentile di una colonna numerica, % di colonne nulle e zero, ecc.
- Derive dei dati nel tempo: Fornisce metriche per rilevare le derive dei dati tra i dati attuali e una base conosciuta, o tra finestre temporali successive dei dati
- Distribuzione statistica dei dati: Fornisce la variazione della distribuzione numerica dei dati nel tempo che risponde a quali siano la distribuzione dei valori in una colonna categorica e in che modo differisca dal passato
- Prestazioni del modello ML e derive delle previsioni: Ingressi del modello ML, previsioni e tendenze delle prestazioni nel tempo
Come funziona
Il Monitoraggio del Lakehouse di Databricks fornisce i seguenti tipi di analisi: serie temporali, snapshot e inferenza.
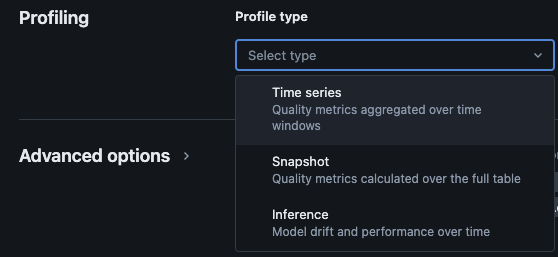
Tipi di profili per il monitoraggio
Quando si abilita il monitoraggio del Lakehouse per una tabella nel Catalogo Unity, vengono create due tabelle nello schema di monitoraggio specificato. È possibile eseguire query e creare dashboard (Databricks fornisce un dashboard configurabile predefinito) e notifiche sulle tabelle per ottenere informazioni statistiche e di profilo esaustive sui dati nel tempo.
- Tabella metriche di drift: La tabella delle metriche di drift contiene statistiche relative al drift dei dati nel tempo. Cattura informazioni come differenze nel conteggio, differenza nella media, differenza in % di valori nulli e zeri, ecc.
- Tabella metriche di profilo: La tabella delle metriche di profilo contiene statistiche di riepilogo per ciascuna colonna e per ciascuna combinazione di finestra temporale, slice e colonne di raggruppamento. Per l’analisi di InferenceLog, la tabella di analisi contiene anche metriche di accuratezza del modello.
Come abilitare il monitoraggio del Lakehouse tramite script
Prerequisiti
- Unity Catalog, schema e Delta Live Tables devono essere presenti.
- L’utente è il proprietario della Delta Live Table.
- Per i cluster privati di Azure Databricks, è configurata la connettività privata da calcolo serverless.
Passo 1: Creare un Notebook e Installare Databricks SDK
Creare un notebook nello spazio di lavoro di Databricks. Per creare un notebook nel tuo spazio di lavoro, fai clic su “+” Nuovo nella barra laterale, e poi scegli Notebook.
Si apre un notebook vuoto nello spazio di lavoro. Assicurati che Python sia selezionato come linguaggio del notebook.
Copia e incolla il frammento di codice sottostante nella cella del notebook e esegui la cella.
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
Passo 2: Creare Variabili
Copia e incolla il frammento di codice sottostante nella cella del notebook e esegui la cella.
catalog_name = "catalog_name" #Replace the catalog name as per your environment.
schema_name = "schema_name" #Replace the schema name as per your environment.
monitoring_schema = "monitoring_schema" #Replace the monitoring schema name as per your preferred name.
refresh_schedule_cron = "0 0 0 * * ?" #Replace the cron expression for the refresh schedule as per your need.
Passo 3: Creare Schema di Monitoraggio
Copia e incolla il frammento di codice sottostante nella cella del notebook e esegui la cella. Questo frammento creerà lo schema di monitoraggio se non esiste già.
%sql
USE CATALOG `${catalog_name}`;
CREATE SCHEMA IF NOT EXISTS `${monitoring_schema}`
Passo 4: Creare Monitor
Copia e incolla il frammento di codice sottostante nella cella del notebook e esegui la cella. Questo frammento creerà il monitoraggio del Lakehouse per tutte le tabelle all’interno dello schema.
import time
from databricks.sdk import WorkspaceClient
from databricks.sdk.errors import NotFound, ResourceDoesNotExist
from databricks.sdk.service.catalog import MonitorSnapshot, MonitorInfo, MonitorInfoStatus, MonitorRefreshInfoState, MonitorMetric, MonitorCronSchedule
databricks_url = 'https://adb-xxxx.azuredatabricks.net/' # replace the url with your workspace url
api_token = 'xxxx' # replace the token with your personal access token for the workspace. Best practice - store the token in Azure KV and retrieve the token using key-vault scope.
w = WorkspaceClient(host=databricks_url, token=api_token)
all_tables = list(w.tables.list(catalog_name=catalog_name, schema_name=schema_name))
for table in all_tables:
table_name = table.full_name
info = w.quality_monitors.create(
table_name = table_name,
assets_dir = "/Shared/databricks_lakehouse_monitoring/", # Creates monitoring dashboards in this location
output_schema_name = f"{catalog_name}.{monitoring_schema}",
snapshot = MonitorSnapshot(),
schedule = MonitorCronSchedule(quartz_cron_expression = refresh_schedule_cron, timezone_id = "PST") # update timezone as per your need.
)
# Wait for monitor to be created
while info.status == MonitorInfoStatus.MONITOR_STATUS_PENDING:
info = w.quality_monitors.get(table_name=table_name)
time.sleep(10)
assert info.status == MonitorInfoStatus.MONITOR_STATUS_ACTIVE, "Error creating monitor"
Validazione
Dopo che lo script è stato eseguito con successo, puoi navigare su catalogo -> schema -> tabella e andare alla scheda “Qualità” nella tabella per visualizzare i dettagli del monitoraggio.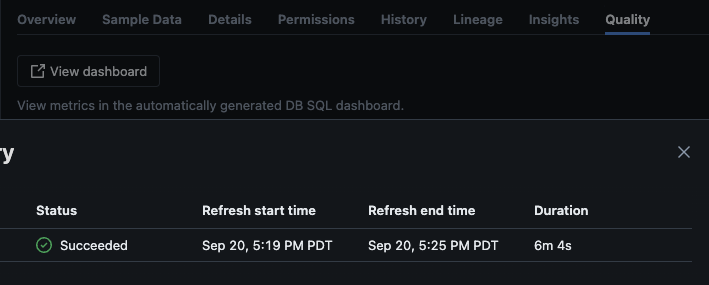
Se si fa clic sul pulsante “Visualizza dashboard” nell’angolo in alto a sinistra della pagina Monitoraggio, verrà aperto il dashboard predefinito di monitoraggio. Inizialmente, i dati saranno vuoti. Man mano che il monitoraggio viene eseguito secondo lo schema, nel tempo verranno popolati tutti i valori statistici, di profilo e di qualità dei dati.
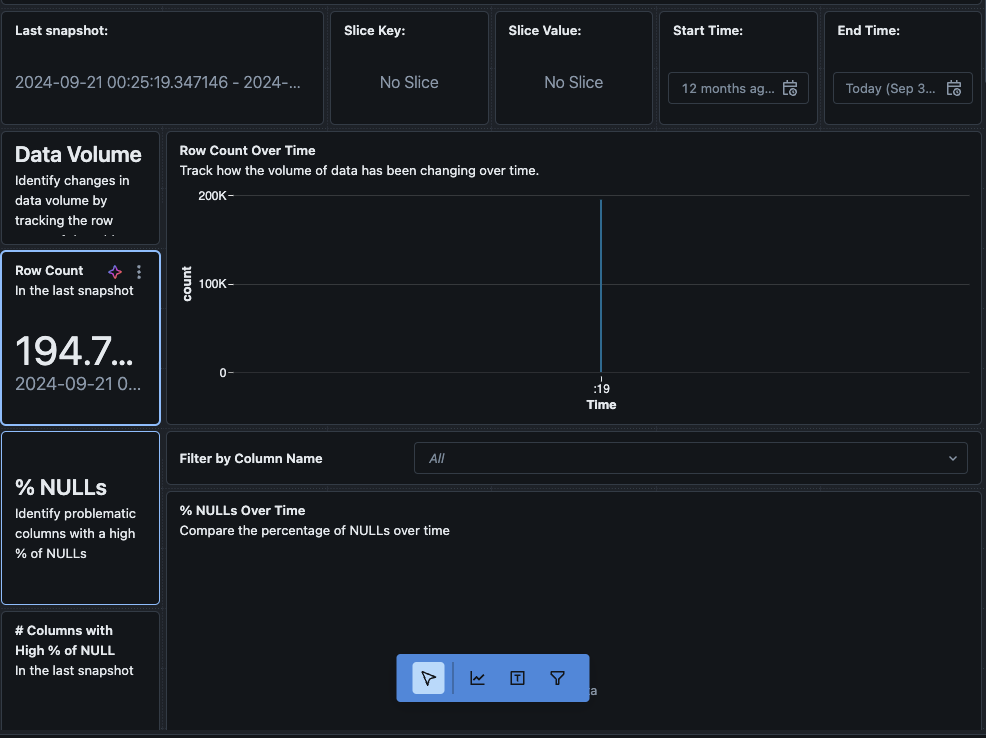
È anche possibile passare alla scheda “Dati” nel dashboard. Databricks fornisce di default una lista di query per ottenere la deriva e altre informazioni di profilo. È inoltre possibile creare le proprie query in base alle proprie esigenze per ottenere una visione completa dei dati nel tempo.
Conclusione
Il Monitoraggio della Lakehouse di Databricks offre un modo strutturato per tenere traccia della qualità dei dati, dei metriche di profilo e rilevare le deriva dei dati nel tempo. Abilitando questa funzionalità tramite script, i team possono ottenere approfondimenti sul comportamento dei dati e garantire l’affidabilità dei propri data pipeline. Il processo di configurazione descritto in questo articolo fornisce una base per mantenere l’integrità dei dati e supportare gli sforzi di analisi dati in corso.
Source:
https://dzone.com/articles/how-to-enable-azure-databricks-lakehouse-monitoring