













Nella Parte 1, abbiamo coperto diversi argomenti chiave. Ti consiglio di leggerla, poiché questa prossima parte si basa su di essa.
Per un rapido ripasso, nella parte 1, abbiamo considerato i nostri dati da una prospettiva ampia e abbiamo differenziato tra dati interni e dati esterni. Abbiamo anche discusso degli schemi e dei contratti di dati e di come forniscono i mezzi per negoziare, cambiare ed evolvere i nostri flussi nel tempo. Infine, abbiamo coperto i tipi di eventi Fatto (Stato) e Delta. Gli eventi Fatto sono ideali per comunicare lo stato e scollegare i sistemi, mentre gli eventi Delta tendono ad essere utilizzati più per i dati interni, come nell’event sourcing e in altri casi d’uso strettamente collegati.
Tabelle Normalizzate Fanno Flussi Normalizzati
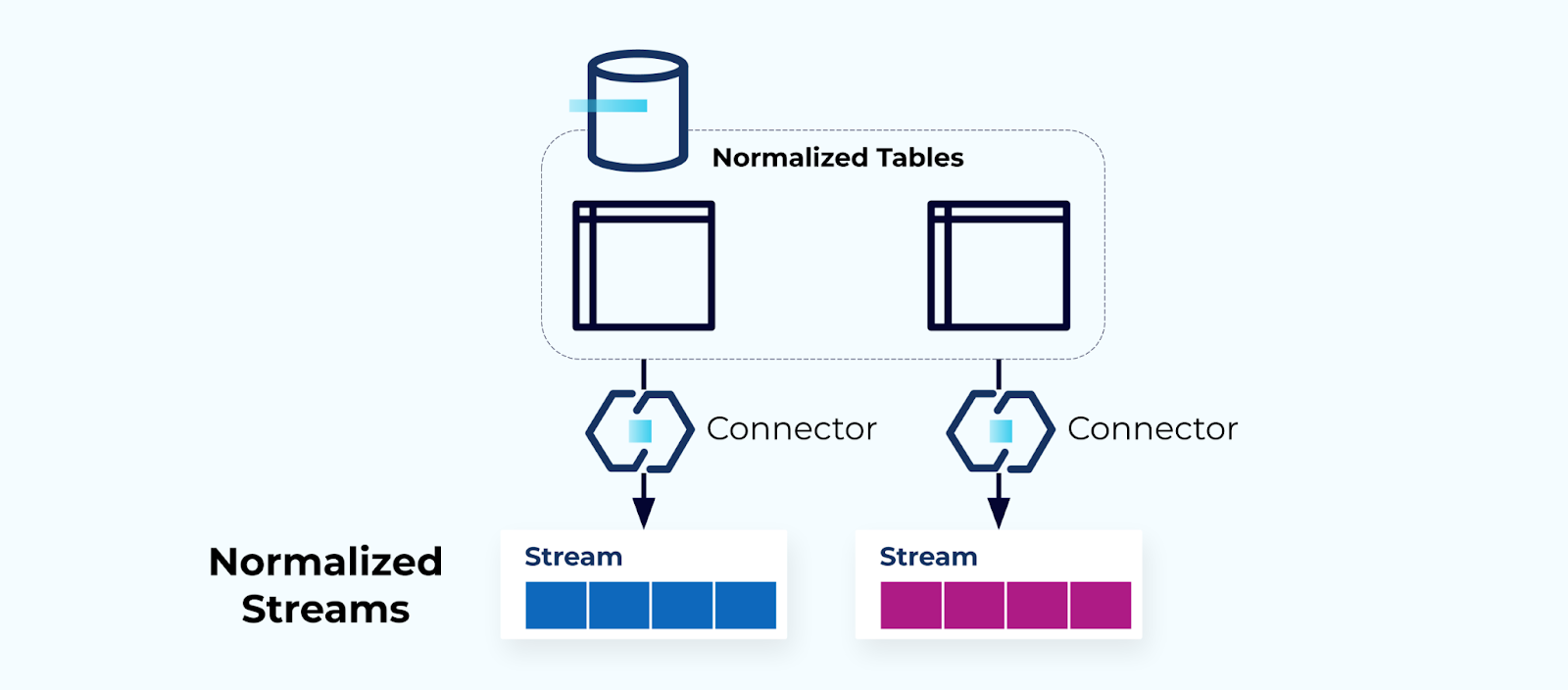
Le tabelle normalizzate portano a flussi di eventi normalizzati. I connettori (ad esempio, CDC) prelevano dati direttamente dal database in un insieme speculare di flussi di eventi. Questo non è ideale, poiché crea una forte dipendenza tra le tabelle del database interno e i flussi di eventi esterni.
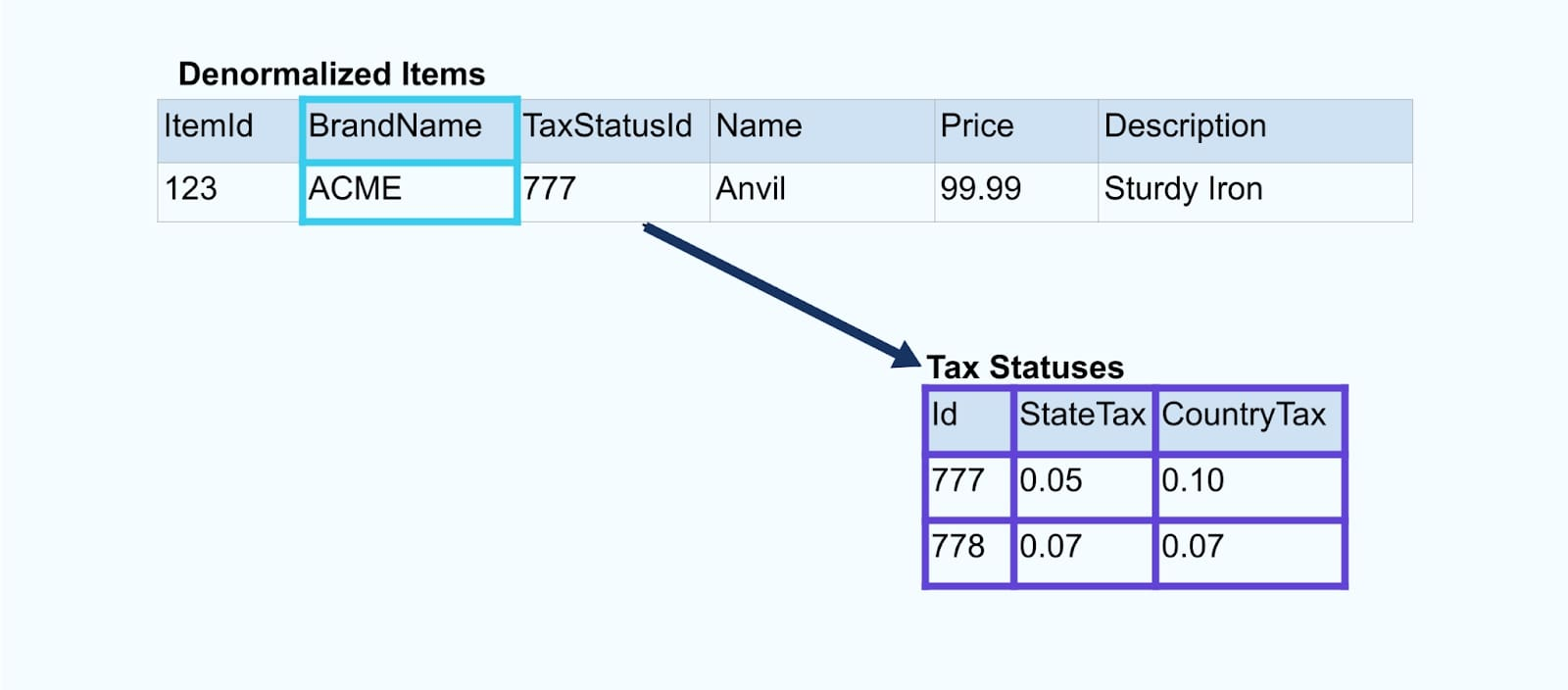
Consideriamo un semplice e-commerce Articolo e le sue tabelle associate Marca e Stato Fiscale.
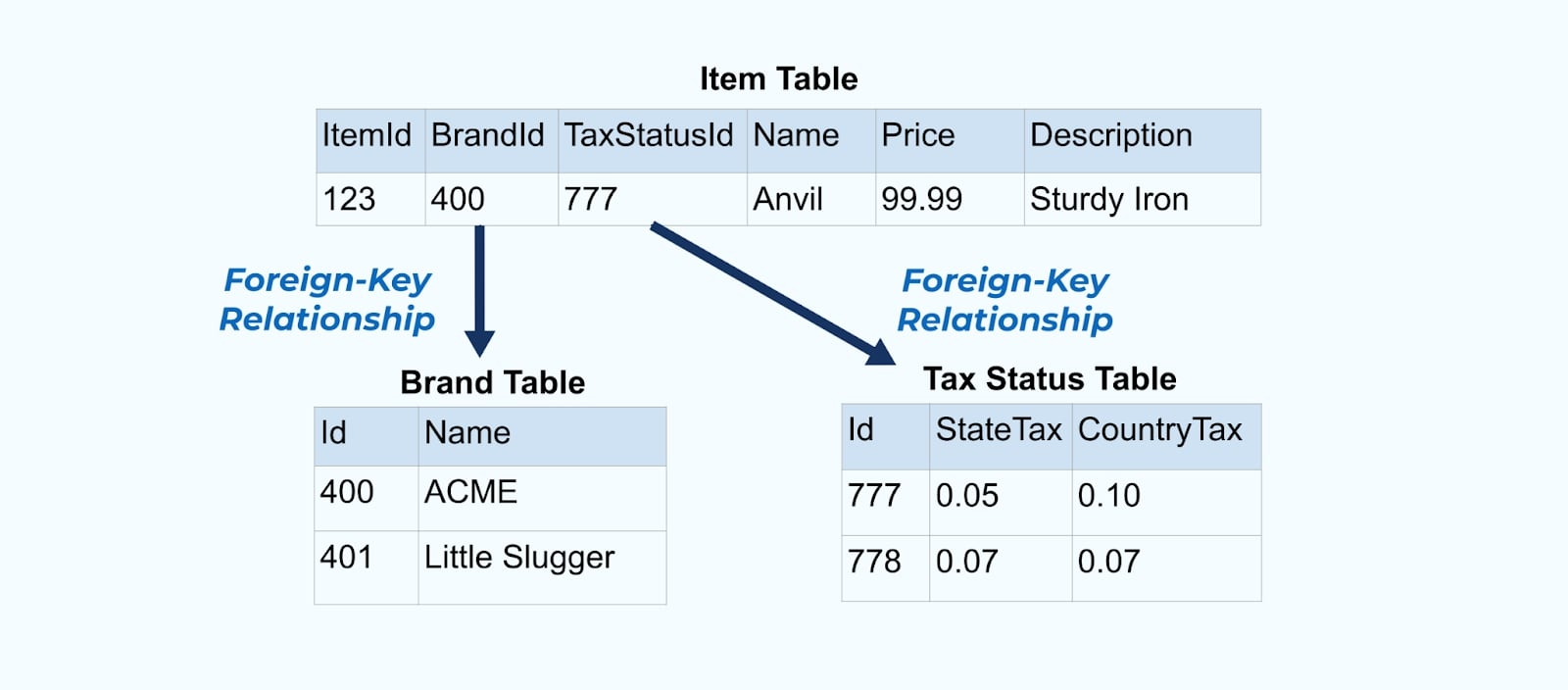
Le tabelle Marca e Stato Fiscale sono correlate alla tabella Articolo tramite relazioni di chiave esterna. Sebbene mostriamo solo un articolo nella tabella, è probabile che tu abbia migliaia (o milioni), a seconda dei prodotti che vendi.
È comune configurare un connettore per ogni tabella, estrarre i dati dalla tabella, comporli in eventi e scrivere ogni tabella in un flusso di eventi dedicato.
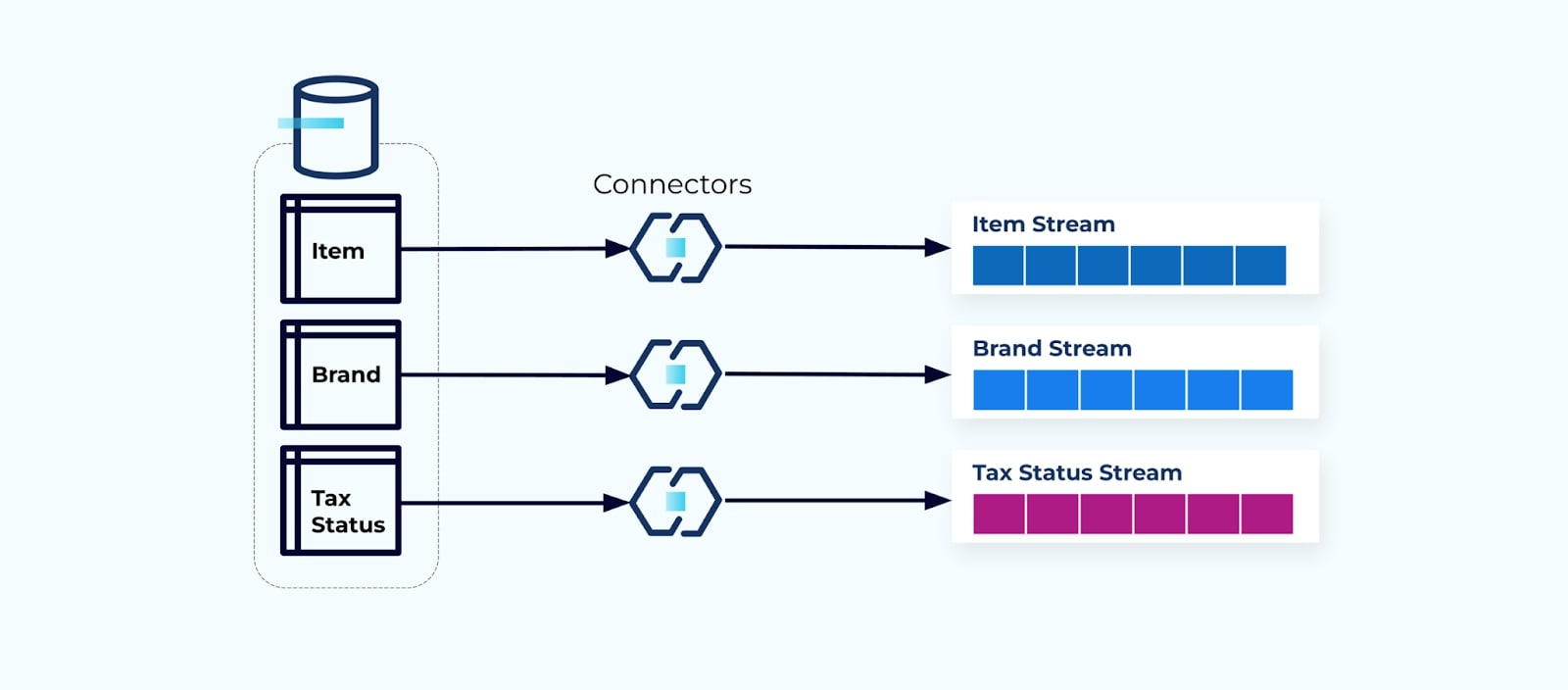
Esponendo le tabelle sottostanti nel database si ottiene un flusso di eventi corrispondente per ogni tabella. Anche se è facile iniziare in questo modo, ciò porta a diversi problemi, che possono essere riassunti come un problema di accoppiamento problem o un problema di costo problem. Esaminiamo ciascuno.
Problema: I consumatori si accoppiano sul modello interno
Esponendo la tabella sorgente Item così com’è, si costringe i consumatori ad accoppiarsi direttamente su di essa. Le modifiche al modello dati del sistema sorgente influenzeranno i consumatori a valle.
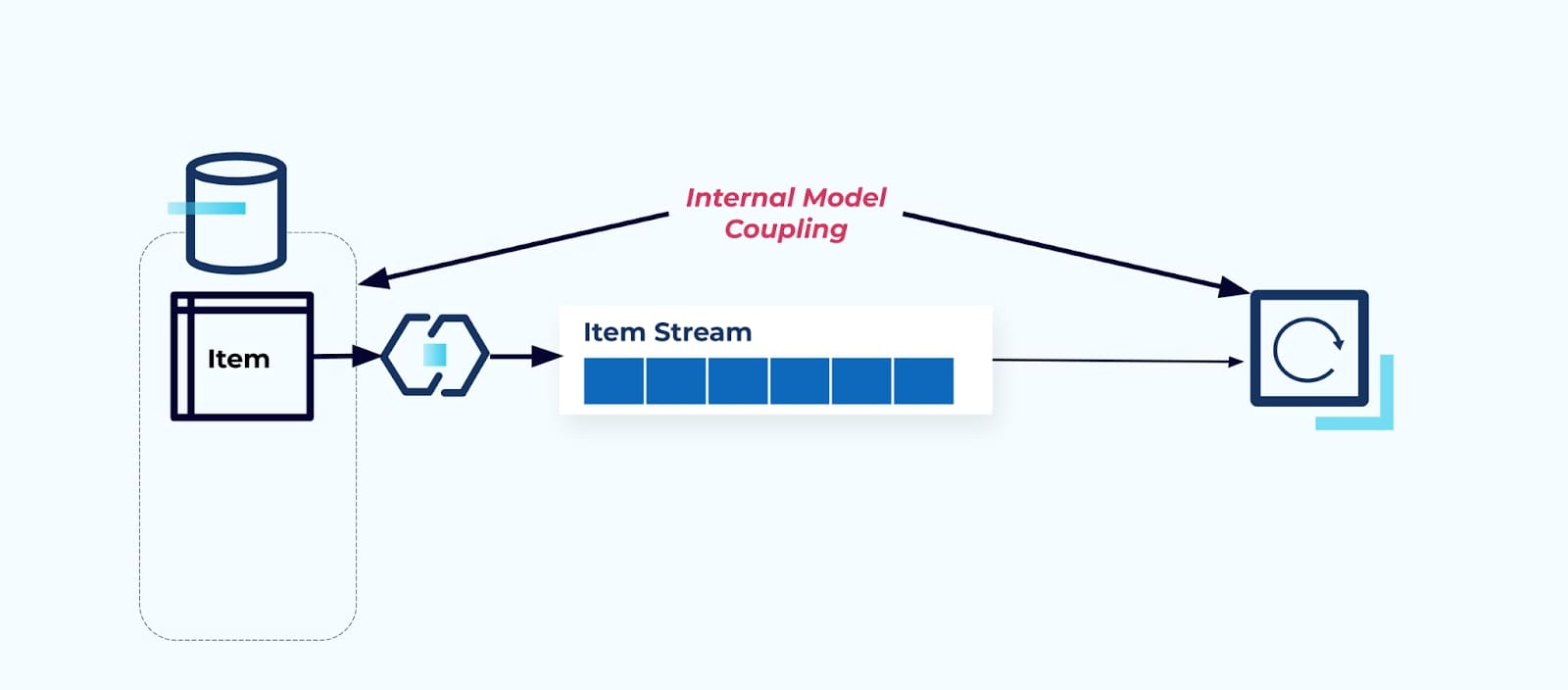
Supponiamo di rifattorizzare la tabella Item per estrarre Pricing nella sua tabella propria.
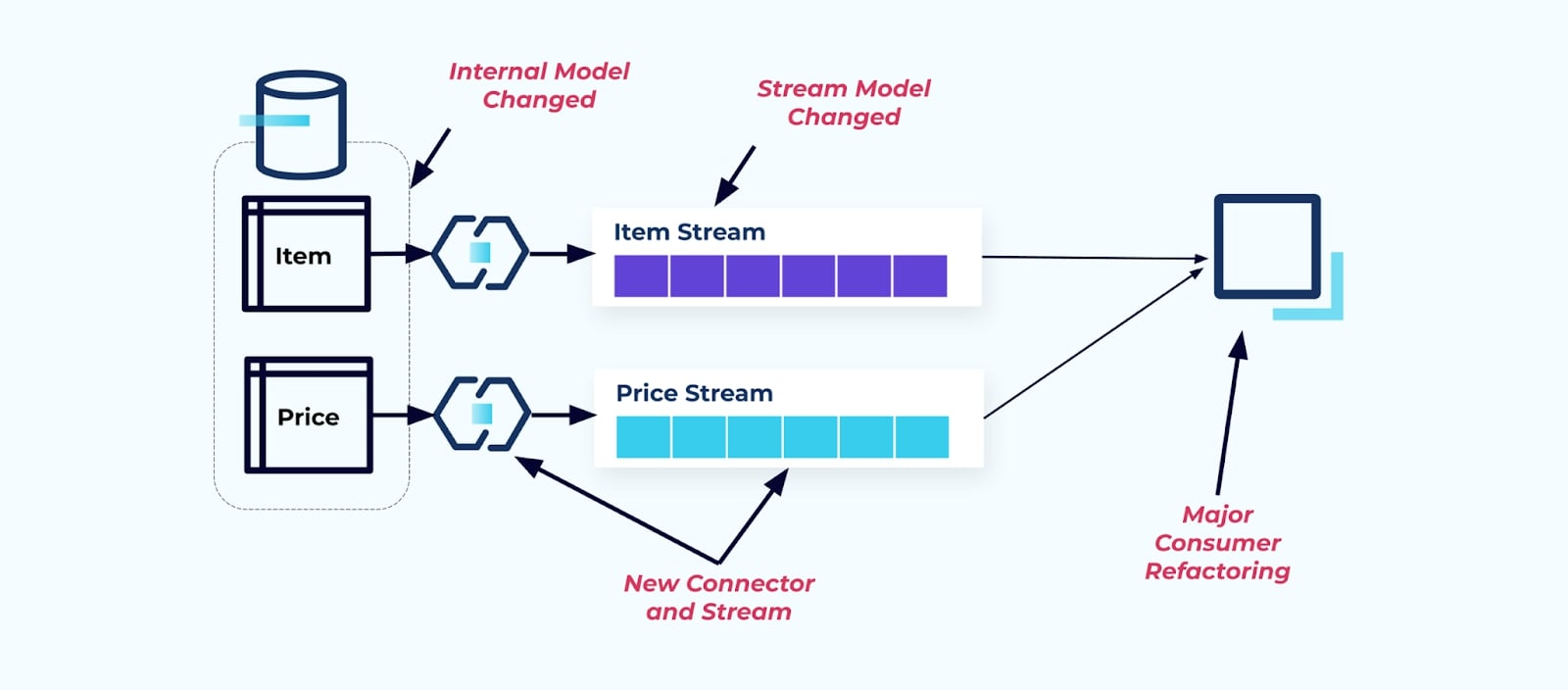
Il refactoring delle tabelle sorgenti comporta un contratto dati rotto per il flusso degli elementi. Il consumatore non riceve più i medesimi dati degli elementi che si aspettava originariamente. Dobbiamo anche creare un nuovo connettore — un nuovo Price stream — e, infine, refactorizzare la nostra logica del consumatore per farlo funzionare di nuovo. Rinominare colonne, cambiare valori predefiniti e cambiare i tipi di colonna sono altre forme di modifiche che rompono introdotte da un accoppiamento stretto sul modello dati interno.
Problema: Le Join in Streaming Sono (Di Solito) Costose
I database relazionali sono progettati per risolvere rapidamente e a basso costo le join. Le join in streaming, sfortunatamente, non lo sono.
Consideriamo due servizi che vogliono accedere a un Item, la sua Tax e le sue informazioni Brand. Se i dati sono già scritti nel rispettivo flusso, allora ogni consumatore (a destra nell’immagine sottostante) dovrà calcolare le stesse join per denormalizzare Item, Brand e Tax.
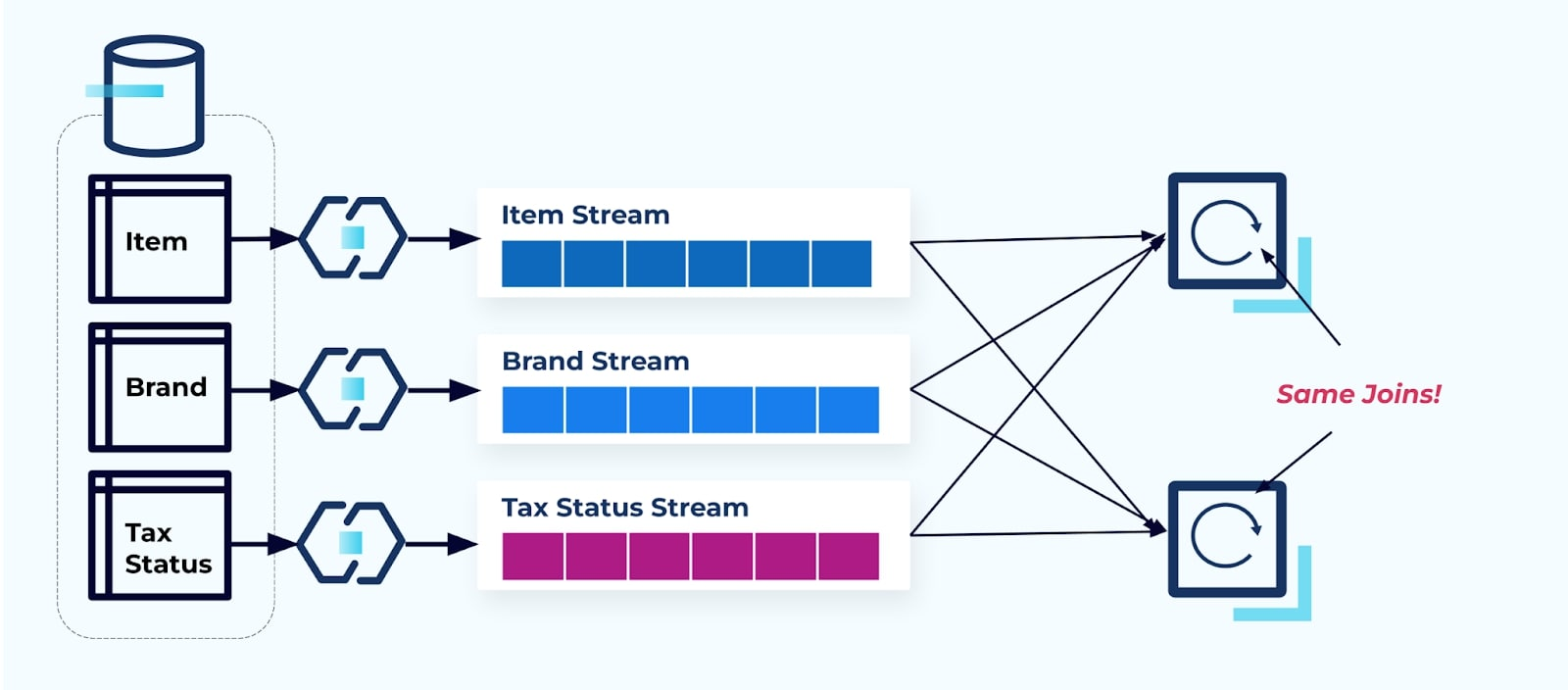
Questa strategia può comportare costi elevati, sia in termini di ore di sviluppo per scrivere le applicazioni che in costi di server per eseguire i join. Risolvere i join in streaming su larga scala può comportare molto shuffling dei dati, il che incide sulla potenza di elaborazione, sulla rete e sui costi di storage. Inoltre, non tutte le piattaforme di processing dei flussi supportano i join, specialmente sulle chiavi esterne. Tra quelle che lo fanno, come Flink, Spark, KSQL o Kafka Streams (ad esempio), ti ritroverai limitato a un sottoinsieme di linguaggi di programmazione (Java, Scala, Python).
Soluzione: Servire Dati Denormalizzati È il Meglio
Come principio, rendi i flussi di eventi facili da usare per i tuoi consumatori. Denormalizza i dati prima di renderli disponibili ai consumatori utilizzando un livello di astrazione e crea un modello esterno esplicito contratto dati (dati all’esterno) per i consumatori da cui dipendere.
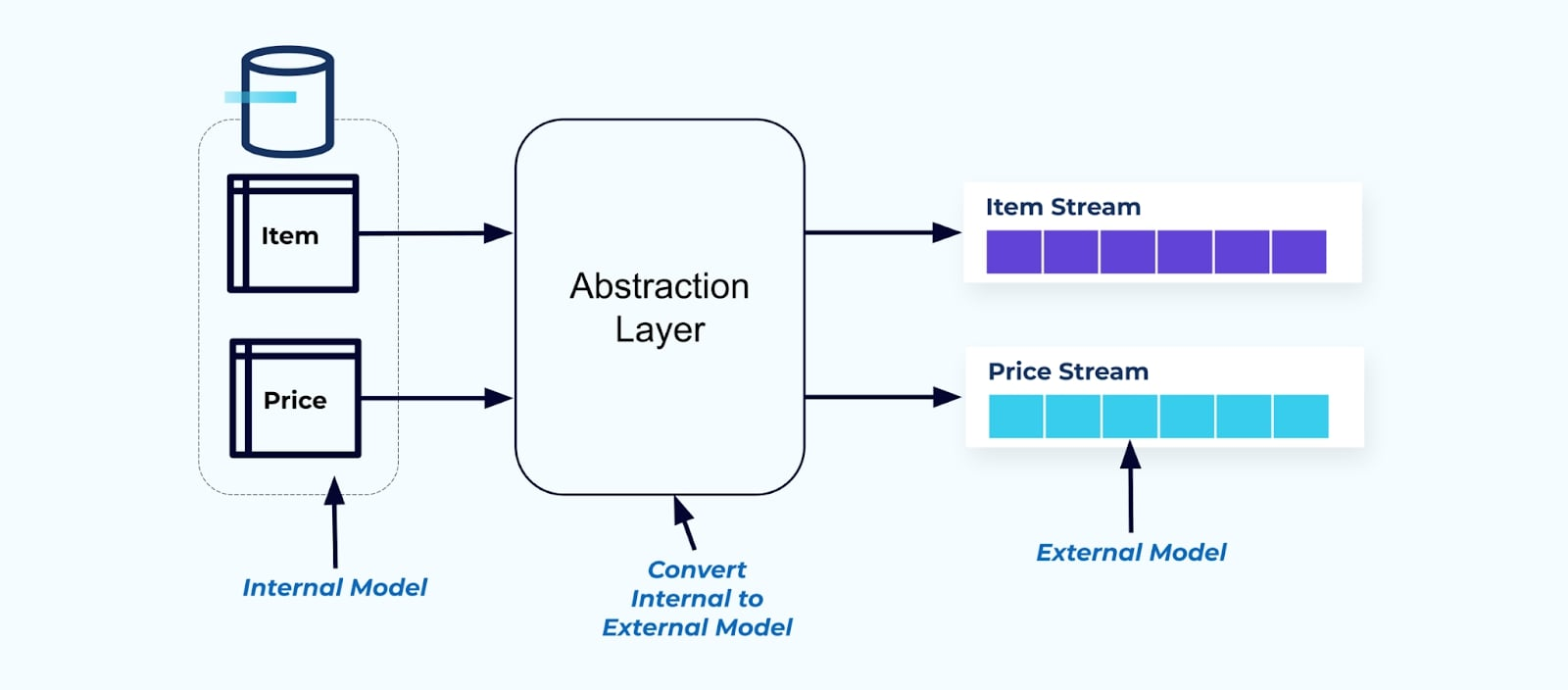
Le modifiche al modello interno rimangono isolate nei sistemi di origine. I consumatori ottengono un contratto dati ben definito da cui dipendere. Le modifiche apportate al modello di origine possono procedere senza impedimenti, purché il sistema di origine mantenga il contratto dati per i consumatori.
Ma dove denormalizziamo? Due opzioni:
- Ricostruisci al di fuori del sistema di origine tramite un servizio joiner appositamente costruito.
- Durante la creazione dell’evento nel sistema di origine utilizzando il pattern Transactional Outbox.
Esaminiamo ciascuna soluzione a turno.
Opzione 1: Denormalizzare Utilizzando un Servizio Joiner Appositamente Costruito
In questo esempio, i flussi sulla sinistra riflettono le tabelle da cui provengono nel database.
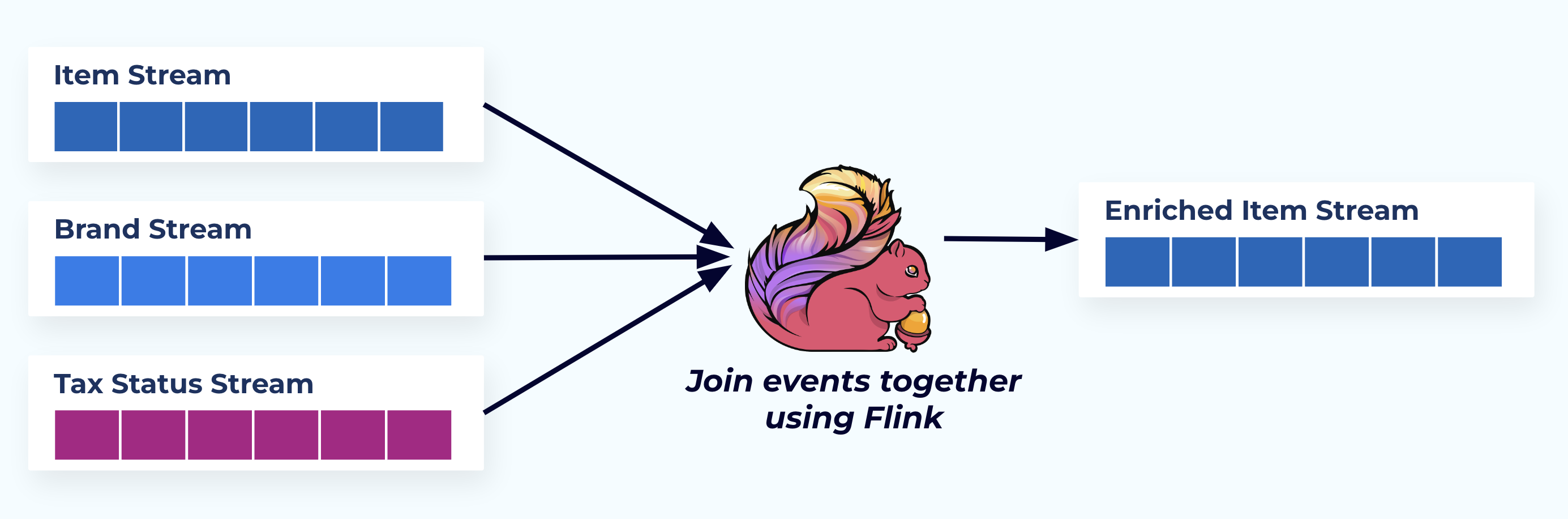
Uniamo gli eventi utilizzando un’applicazione specificamente progettata (o query SQL in streaming) basata sulle relazioni di chiave esterna ed emettiamo un singolo flusso di elementi arricchiti.

Logicamente, stiamo risolvendo le relazioni e comprimendo i dati in una singola riga denormalizzata.
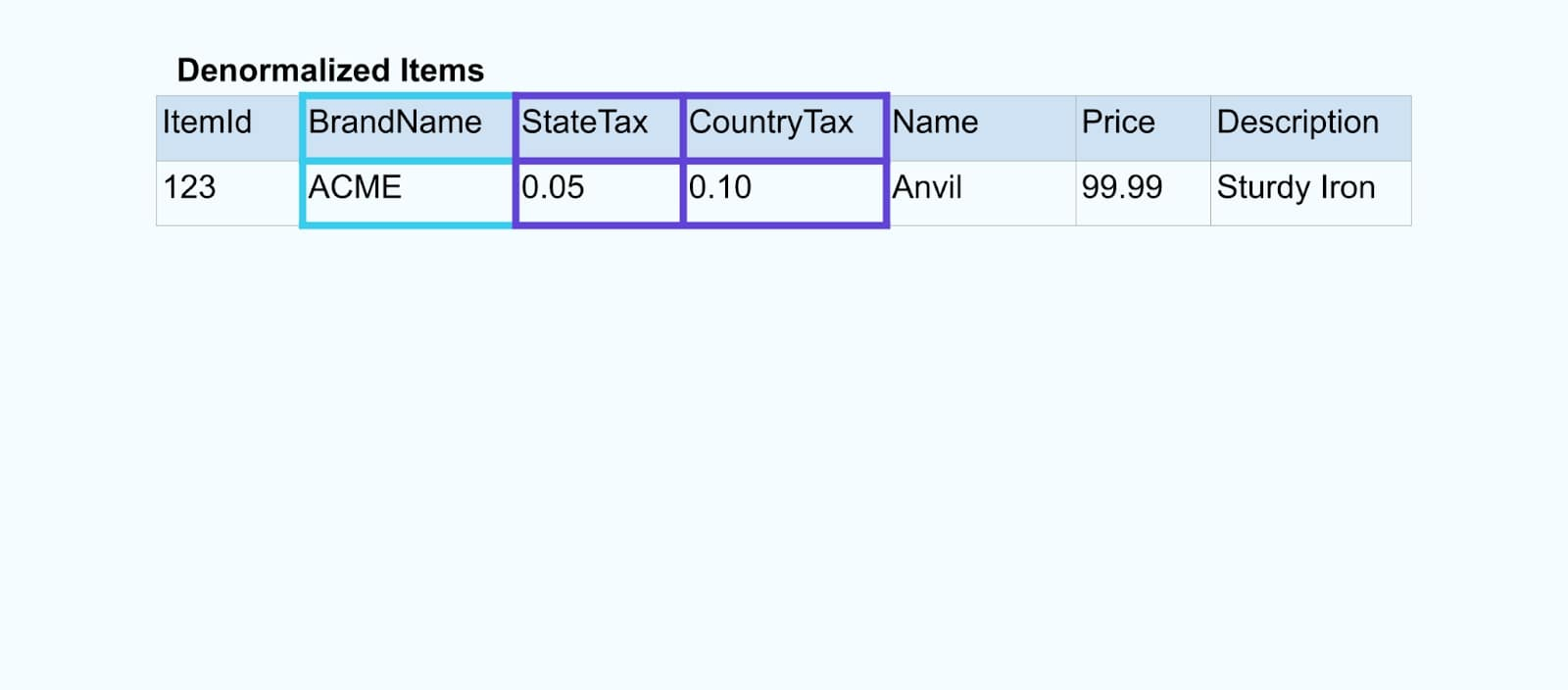
I joiner specificamente progettati si affidano a framework di processing dei flussi come Apache Kafka Streams e Apache Flink per risolvere sia i join di chiave primaria che quelli di chiave esterna. Materializzano i dati del flusso in formati di tabella interna duraturi, consentendo all’applicazione joiner di unire eventi su qualsiasi periodo – non solo quelli limitati da una finestra temporale.
I joiner che utilizzano Flink o Kafka Streams sono anche notevolmente scalabili — possono scalare su e giù in base al carico e gestire volumi massicci di traffico.
Un consiglio: Non inserire alcuna logica di business nel joiner. Per avere successo in questo pattern, i dati uniti devono rappresentare accuratamente la fonte, semplicemente come un risultato denormalizzato. Lascia che i consumatori a valle applichino la loro logica di business, utilizzando i dati denormalizzati come un’unica fonte di verità.
Se non vuoi utilizzare un joiner a valle, ci sono altre opzioni. Esaminiamo il pattern della transactional outbox prossimo.
Opzione 2: Pattern Transactional Outbox
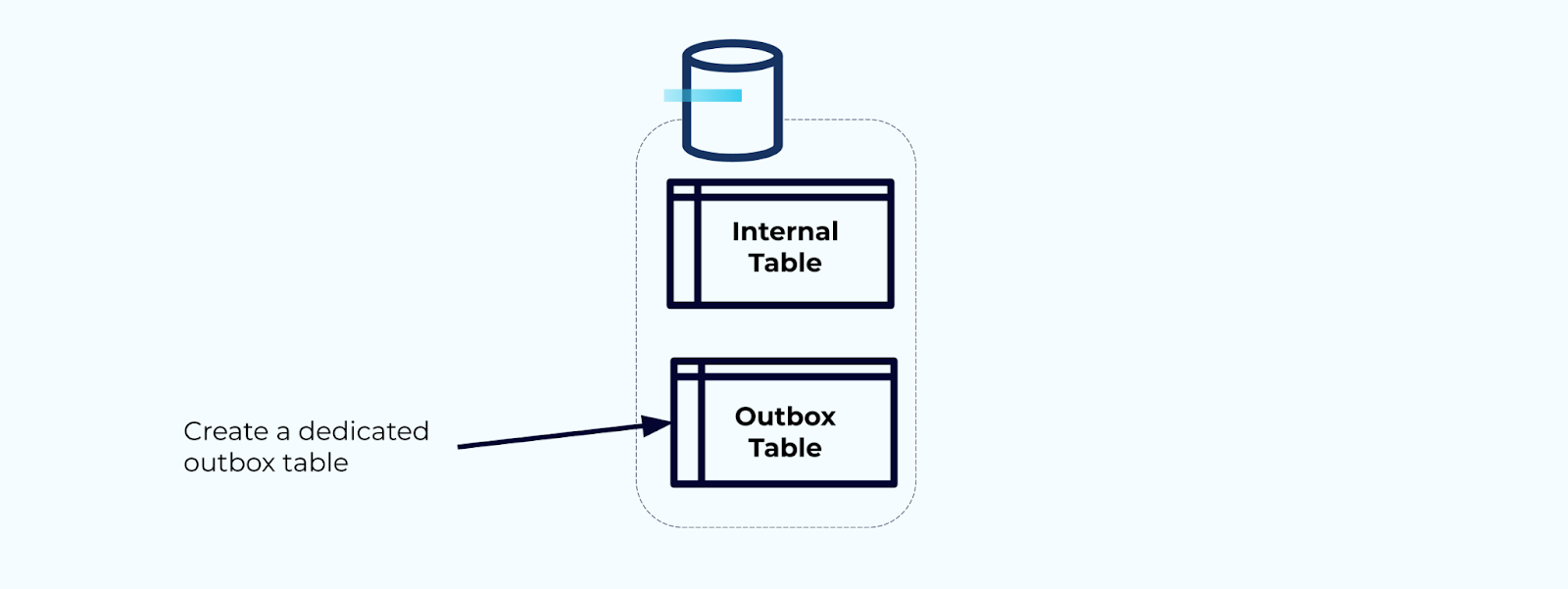
Prima di tutto, crea una tabella outbox dedicata per scrivere eventi nel flusso.
Secondo, avvolgi tutti gli aggiornamenti necessari delle tabelle interne all’interno di una transazione. Le transazioni garantiscono che qualsiasi aggiornamento apportato alla tabella interna verrà anche scritto nella tabella outbox.
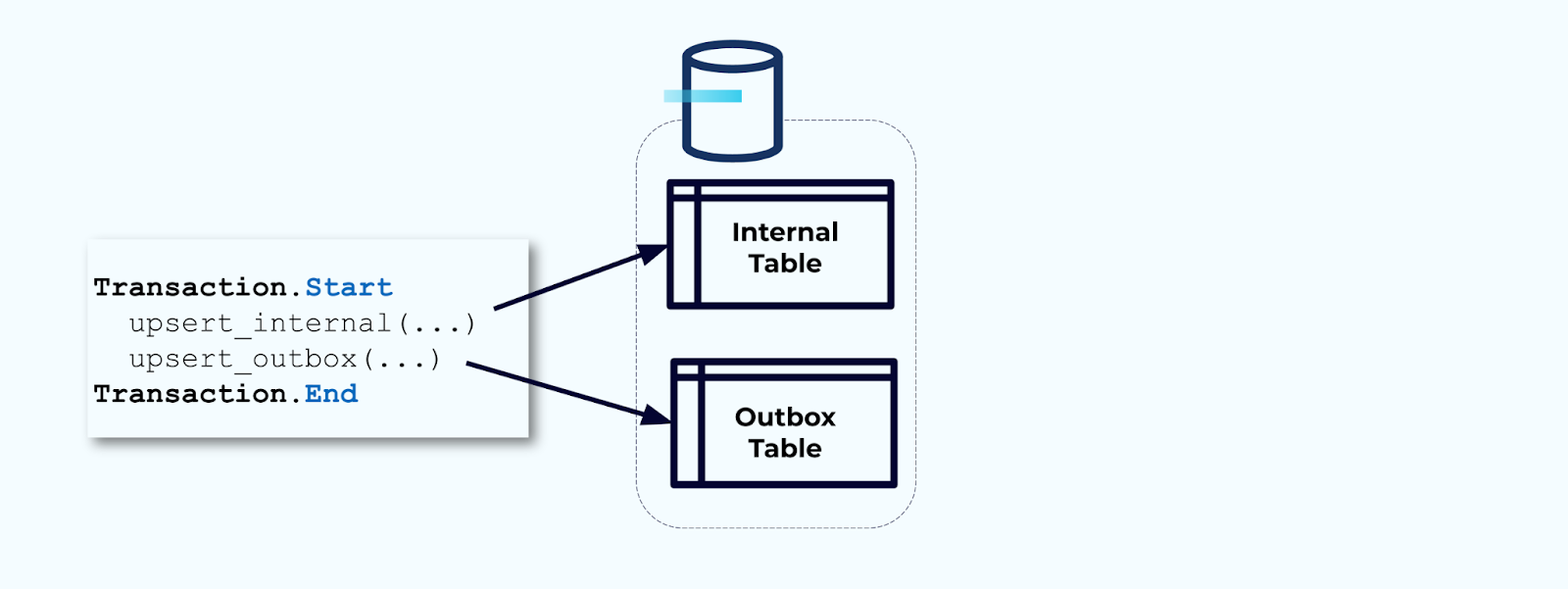
L’outbox ti consente di isolare il modello di dati interno poiché puoi unire e trasformare i dati prima di scriverli nella tua outbox. L’outbox agisce come il livello di astrazione tra i dati all’interno e i dati all’esterno, fungendo da contratto dati per i tuoi consumatori.
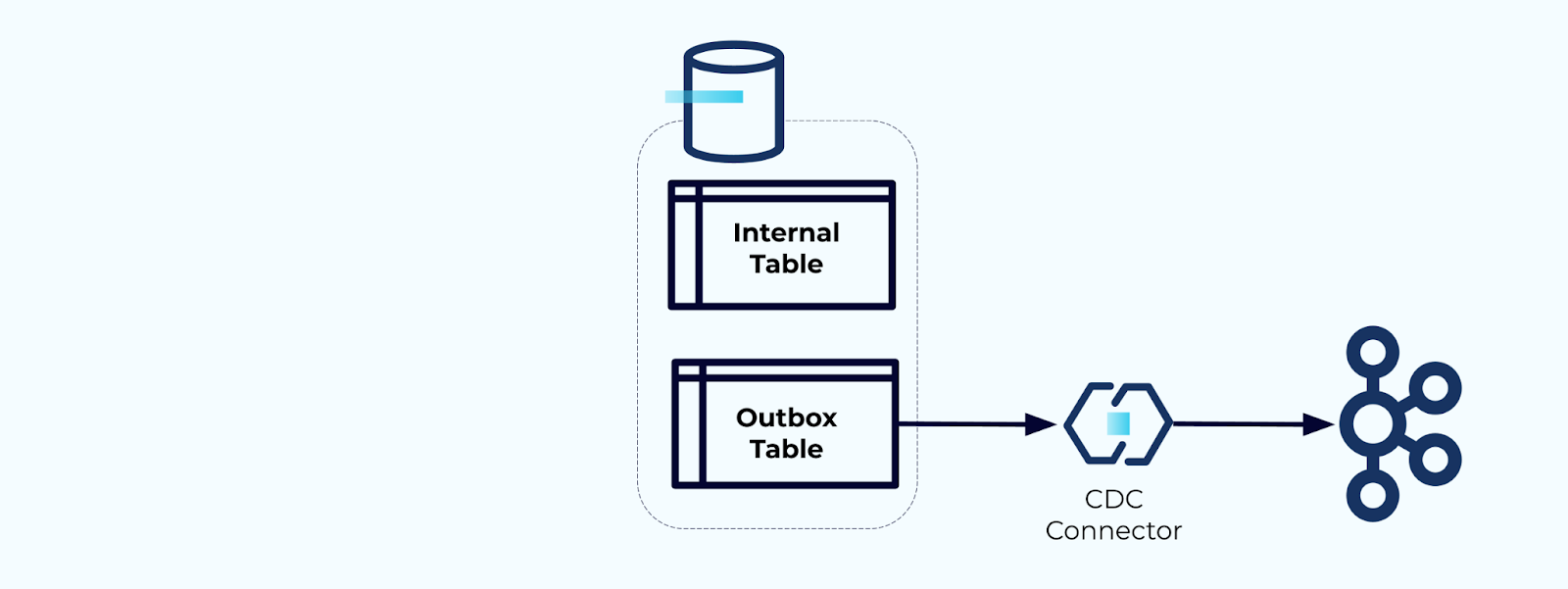
Infine, puoi utilizzare un connettore per trasferire i dati dall’outbox a Kafka.
Devi assicurarti che l’outbox non cresca indefinitamente — elimina i dati dopo che sono stati catturati dal CDC o periodicamente con un job pianificato.
Esempio: Denormalizzazione degli Eventi di Tracciamento del Comportamento Utente
Il tracciamento del comportamento degli utenti sulle tue pagine web e applicazioni è una fonte comune di eventi normalizzati — pensa a Google Analytics o opzioni in-house di prima parte. Ma non includiamo tutte le informazioni nell’evento; invece, le limitiamo agli identificatori (più veloci, più piccoli, più economici), denormalizzando dopo che i fatti sono stati creati.
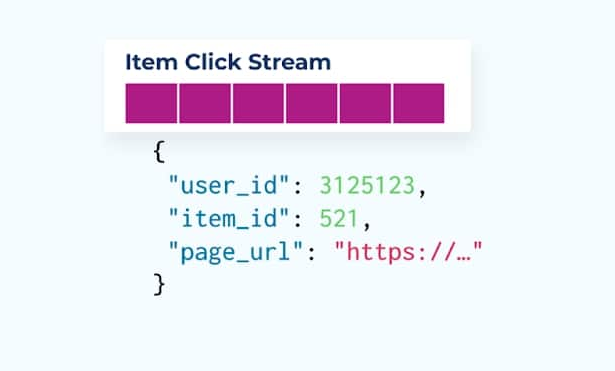
Considera un flusso di eventi di clic su un articolo che dettaglia quando un utente ha fatto clic su un articolo mentre navigava tra articoli di e-commerce. Nota che questo evento di clic su un articolo non contiene informazioni più ricche sull’articolo come nome, prezzo e descrizione, ma solo ids di base.
La prima cosa che molti consumatori di flussi di clic fanno è unirlo con il flusso di fatti dell’articolo. E poiché si ha a che fare con molti eventi di clic, si scopre che finisce per utilizzare una grande quantità di risorse di calcolo. Un’applicazione Flink costruita appositamente può unire i clic sugli articoli con i dati dettagliati dell’articolo ed emetterli in un flusso di clic sugli articoli arricchito.
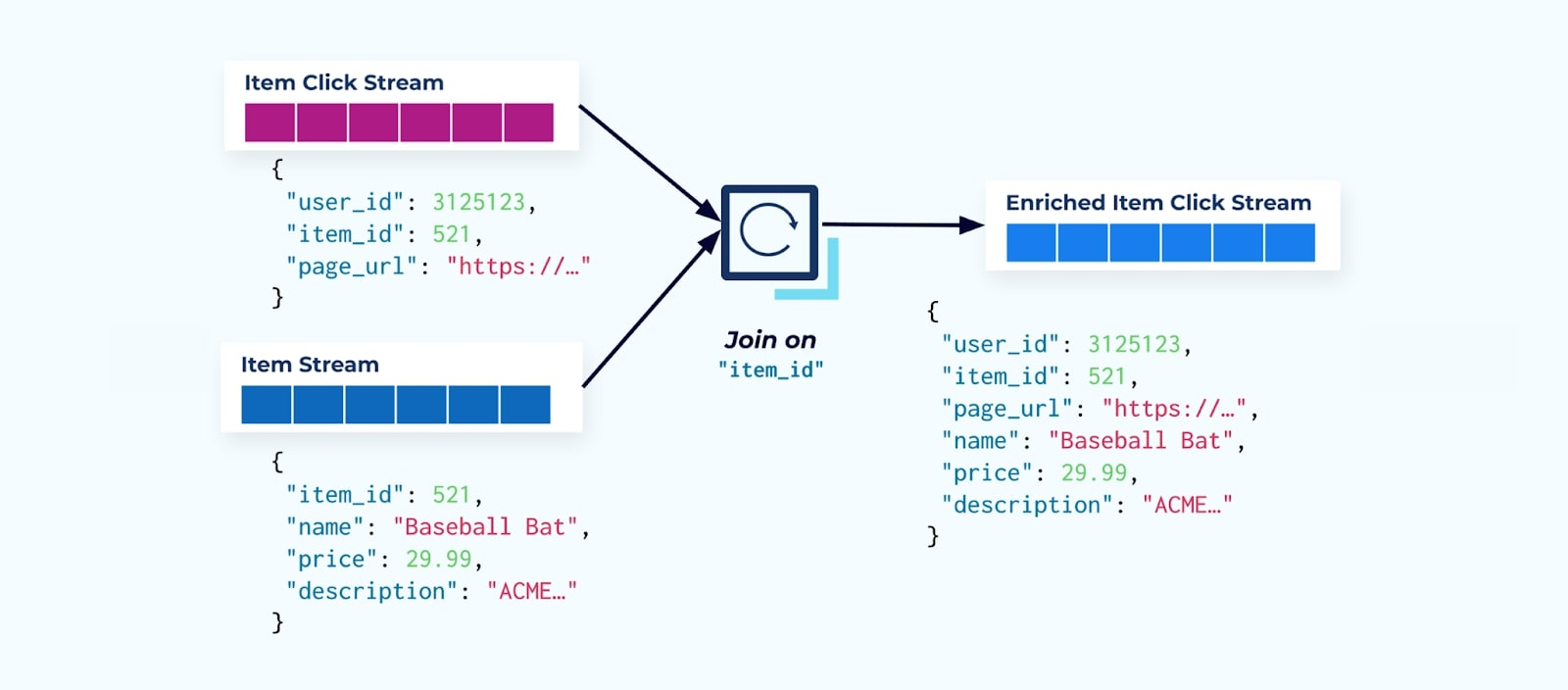
Le aziende più grandi con più divisioni (e sistemi) vedranno probabilmente i loro dati provenire da fonti diverse, e unirli successivamente utilizzando un joiner di flusso è l’esito più probabile.
Considerazioni sulle Dimensioni a Cambiamento Lento
Abbiamo già discusso delle considerazioni sulle prestazioni della scrittura di eventi contenenti grandi set di dati (ad esempio, grandi blocchi di testo) e domini di dati che cambiano frequentemente (ad esempio, inventario degli articoli). Ora, esamineremo le dimensioni a cambiamento lento (SCD), spesso indicate tramite una relazione di chiave esterna, poiché queste possono essere un’altra fonte di volumi di dati significativi.
Ritorniamo all’esempio dell’articolo. Supponiamo di avere un’operazione che aggiorna la Tabella degli Articoli. Rinomineremo l’articolo da Incudine a Incudine di Ferro.
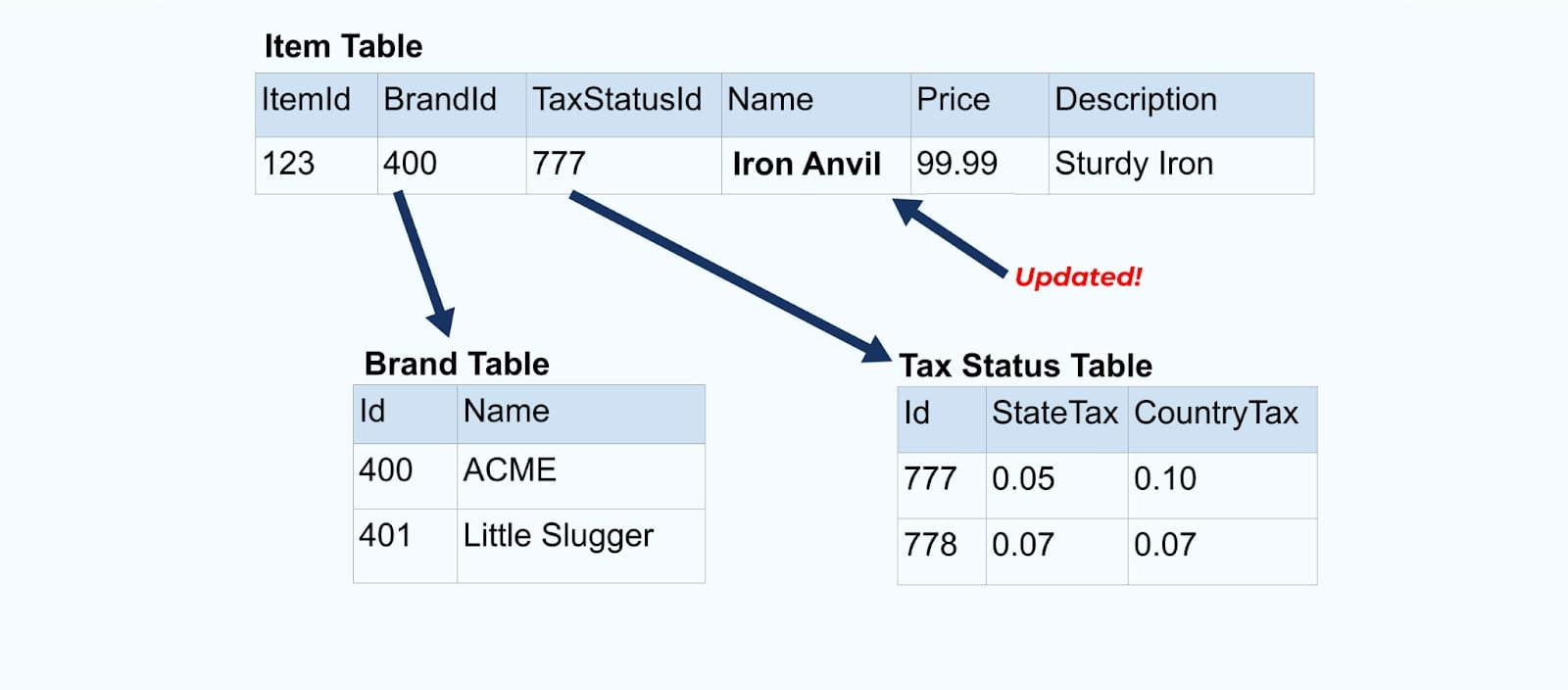
Aggiornando i dati nel database, emettiamo anche l’articolo aggiornato (ad esempio tramite il pattern outbox), completo dello stato fiscale denormalizzato e della tabella del marchio.
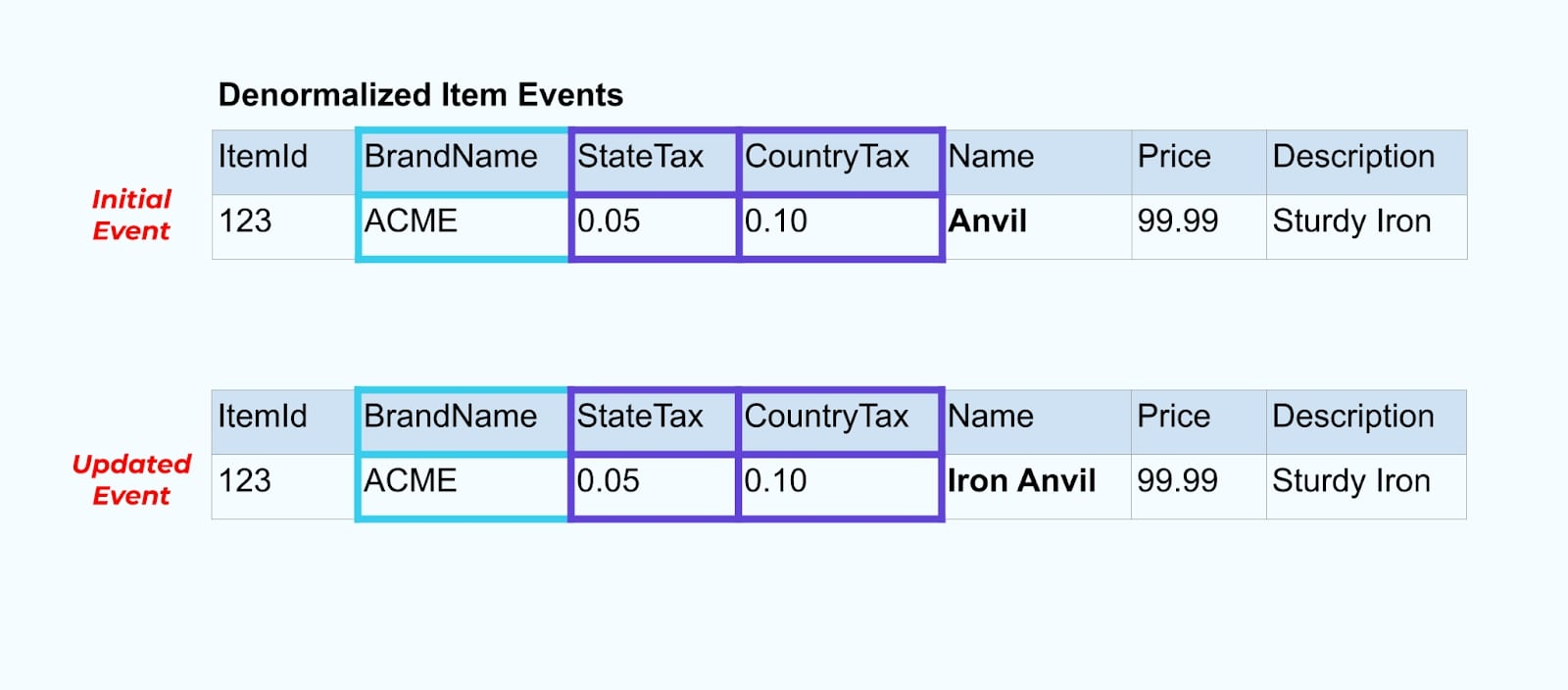
Tuttavia, dobbiamo anche considerare cosa succede quando cambiamo i valori nelle tabelle del marchio o delle tasse. Aggiornare una di queste dimensioni a cambiamento lento può comportare un numero significativamente elevato di aggiornamenti per tutti gli articoli interessati.
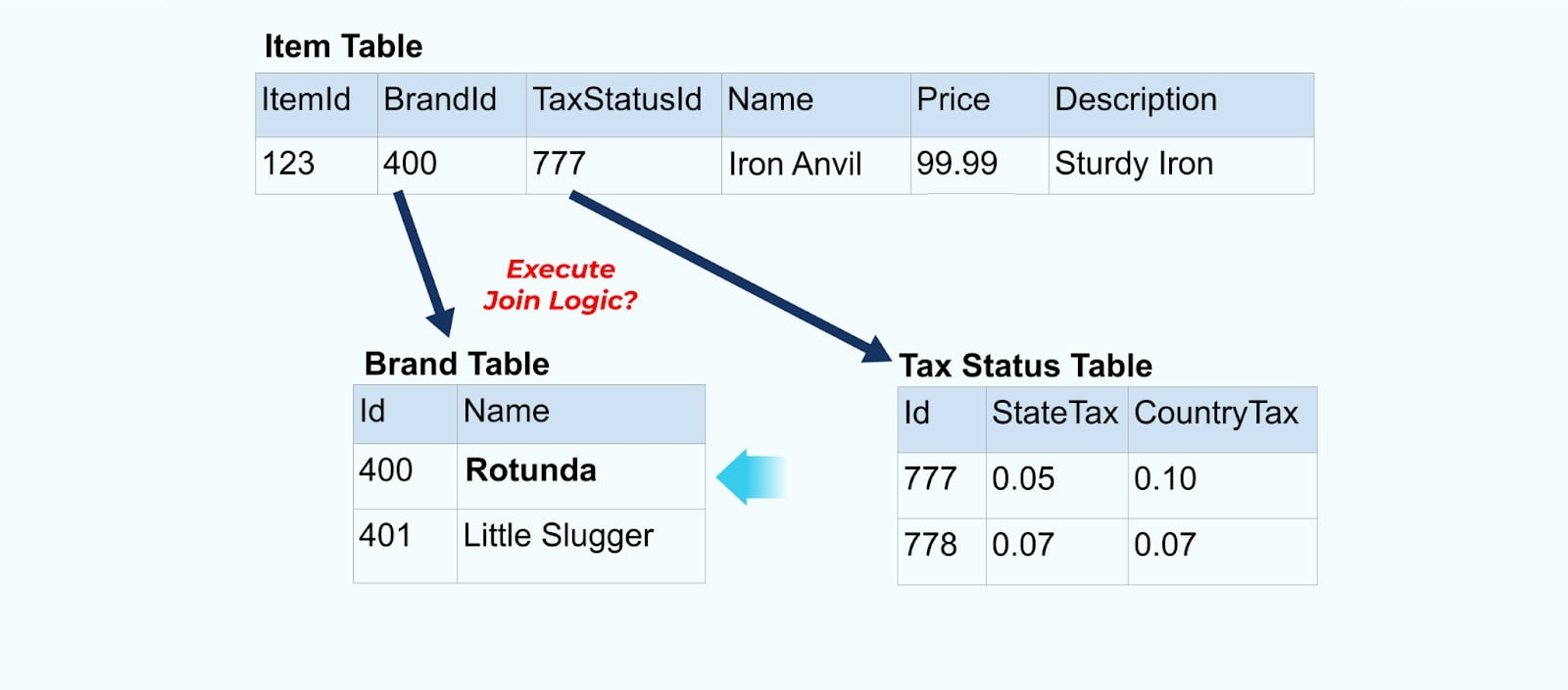
Per esempio, la società ACME subisce un rebranding e arriva con un nuovo nome di marca, cambiando da ACME a Rotunda. Produciamo un altro evento per ItemId=123.
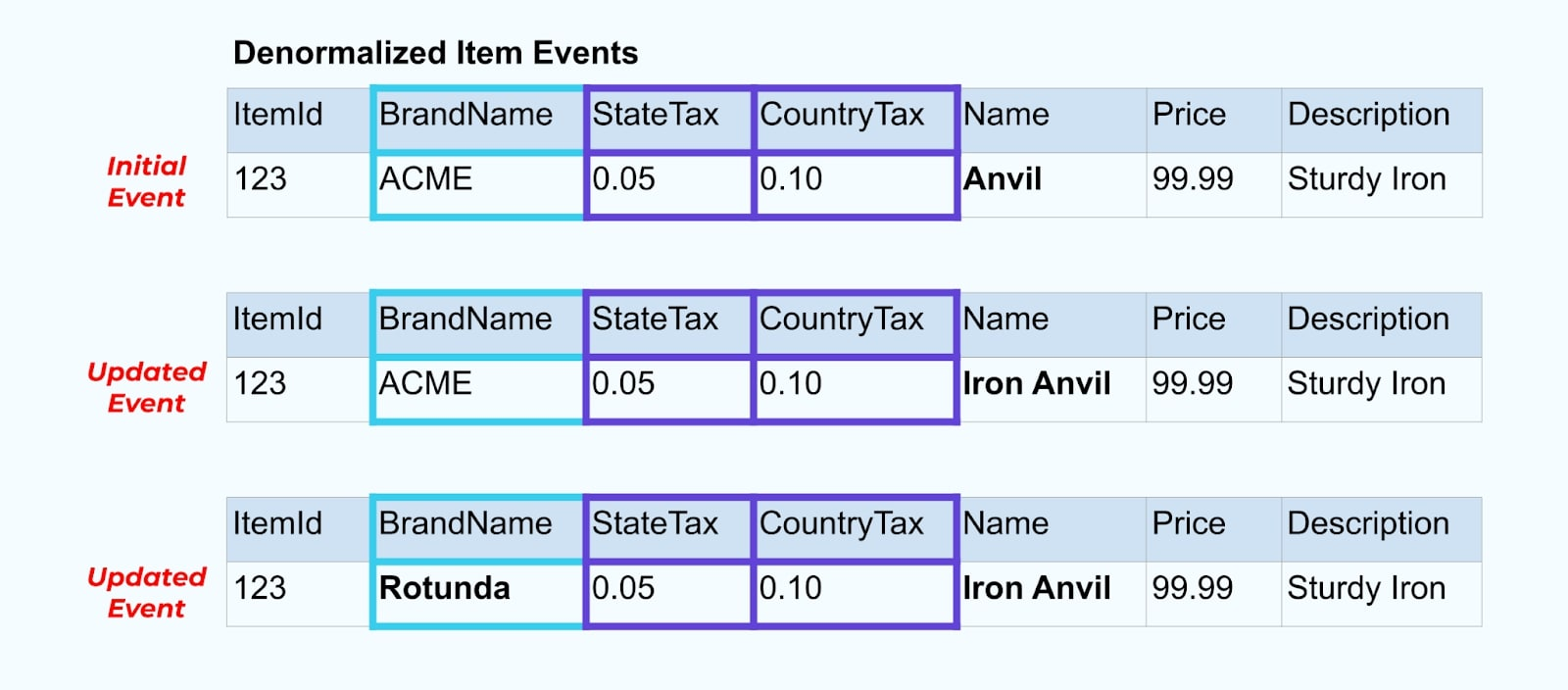
Tuttavia, Rotunda (precedentemente ACME) probabilmente ha molte centinaia (o migliaia) di articoli che vengono anch’essi aggiornati da questo cambiamento, risultando in un numero corrispondente di eventi di articoli arricchiti aggiornati.
Quando si denormalizzano SCD e relazioni di chiavi esterne, tenere a mente l’impatto che un cambiamento nell’SCD può avere sull’intero flusso di eventi. Si potrebbe decidere di rinunciare alla denormalizzazione e lasciarla al consumatore nel caso in cui il cambiamento dell’SCD comporti milioni o miliardi di eventi aggiornati.
Riepilogo
La denormalizzazione facilita l’uso dei dati da parte dei consumatori, ma comporta un maggiore processo upstream e una scelta accurata dei dati da includere. I consumatori potrebbero avere un tempo più facile per costruire applicazioni e possono scegliere tra una gamma più ampia di tecnologie, inclusi quelli che non supportano nativamente i join in streaming.
La normalizzazione dei dati upstream funziona bene quando i dati sono piccoli e aggiornati raramente. Dimensioni degli eventi maggiori, aggiornamenti frequenti e SCD sono tutti fattori da tenere d’occhio quando si determina cosa denormalizzare upstream e cosa lasciare ai consumatori per fare da soli.
Alla fine, scegliere quali dati includere in un evento e quali lasciare fuori è un equilibrio tra le esigenze dei consumatori, le capacità dei produttori e le relazioni uniche del modello di dati. Ma il miglior punto di partenza è comprendere le esigenze dei consumatori e l’isolamento del modello di dati interno del sistema di origine.
Source:
https://dzone.com/articles/how-to-design-event-streams-part-2