













L’autore ha selezionato la Fondazione Wikimedia per ricevere una donazione come parte del programma Write for DOnations.
Introduzione
L’Infrastruttura come Codice (IaC) è una pratica che automatizza il deployment e le modifiche dell’infrastruttura definendo gli stati delle risorse e le loro relazioni nel codice. Eseguendo quel codice si creano o si modificano le risorse effettive nel cloud. L’IaC consente agli ingegneri di utilizzare uno strumento IaC come Terraform (di HashiCorp) per il provisioning dell’infrastruttura.
Con l’IaC, le modifiche alla tua infrastruttura possono passare attraverso lo stesso processo di revisione del codice della tua applicazione. È possibile memorizzare il codice nel controllo versione (come Git) per mantenere un cronologia dello stato della tua infrastruttura, e è possibile automatizzare ulteriormente il processo di deployment con strumenti di livello superiore come una piattaforma self-service per sviluppatori interni (IDP).
Terraform è uno strumento IaC (Infrastructure as Code) popolare e agnostico rispetto alla piattaforma grazie al suo ampio supporto per molte piattaforme, tra cui GitHub, Cloudflare e DigitalOcean. La maggior parte delle configurazioni di Terraform è scritta utilizzando un linguaggio dichiarativo chiamato HashiCorp Configuration Language (HCL).
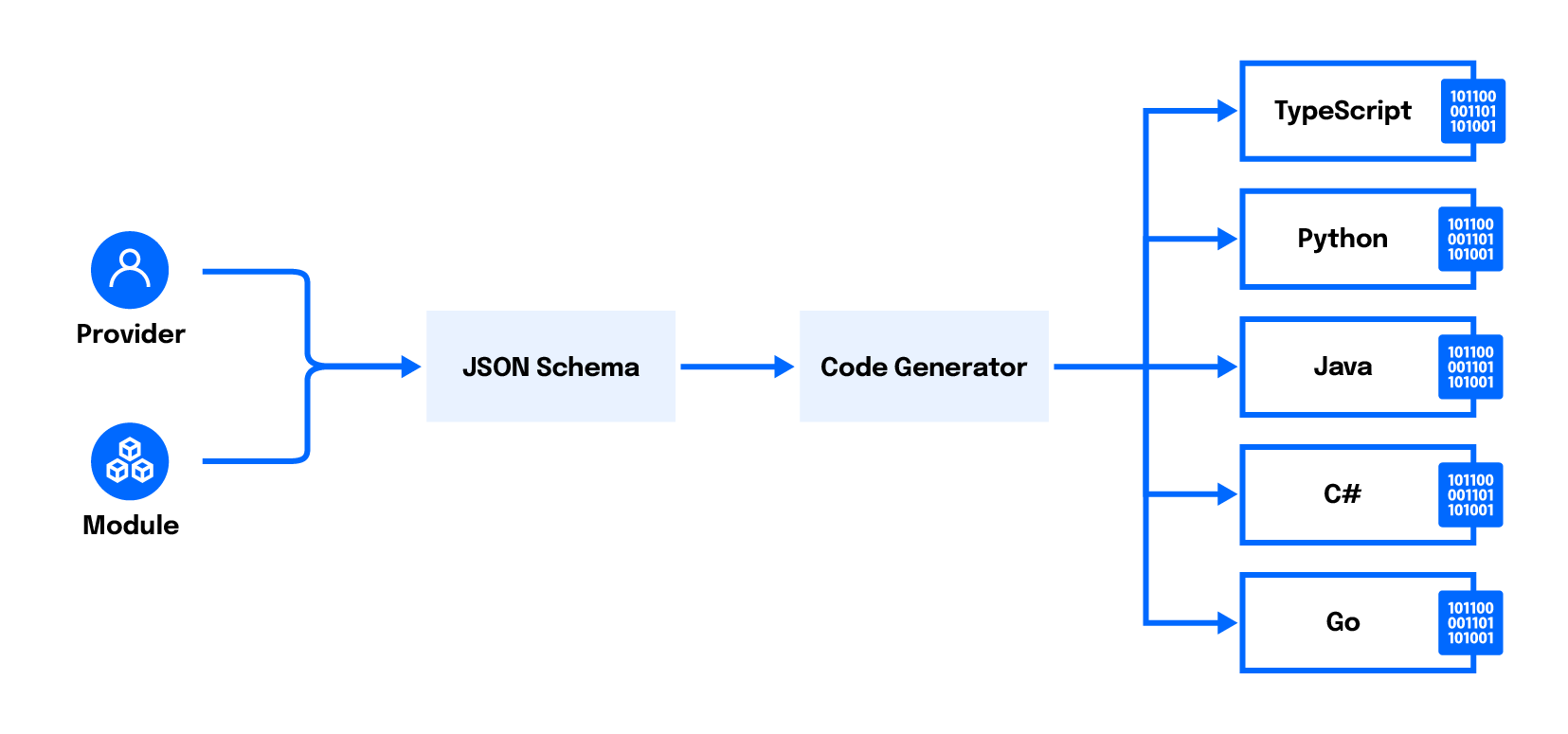
Il Cloud Development Kit per Terraform (CDKTF) è uno strumento costruito sopra Terraform che ti consente di definire l’infrastruttura utilizzando un linguaggio di programmazione familiare (come TypeScript, Python o Go) invece di HCL. Questo strumento può offrire una curva di apprendimento più dolce per gli sviluppatori non familiari con HCL, consentendo loro di utilizzare funzionalità di programmazione native come cicli, variabili e funzioni.
In questo tutorial, inizierai installando l’interfaccia della riga di comando (CLI) cdktf. Successivamente, creerai un progetto CDKTF in TypeScript e definirai il progetto con due server NGINX bilanciati dal carico di un bilanciatore di carico. Successivamente, utilizzerai cdktf per distribuire l’infrastruttura. Alla fine di questo tutorial, avrai un progetto CDKTF da cui potrai sviluppare per espandere la tua infrastruttura.
Nota: Questo tutorial è stato testato con CDKTF 0.11.2 e Terraform 1.2.2.
Prerequisiti
Per completare questo tutorial, avrai bisogno di:
- A good understanding of Infrastructure-as-Code (IaC). You can learn about IaC in Infrastructure as Code Explained.
- A DigitalOcean account. If you do not have one, sign up for a new account.
- A DigitalOcean Personal Access Token, which you can create via the DigitalOcean console. Instructions on how to do that can be found at How to Generate a Personal Access Token.
- A password-less SSH key added to your DigitalOcean account. You can add that by following How To Use SSH Keys with DigitalOcean Droplets. When you add the key to your account, remember the name you give it, as you will need it in this tutorial. For CDKTF to accept the name of your key, it must start with a letter or underscore and may contain only letters, digits, underscores, and dashes.
- Terraform installato sul tuo computer locale, che puoi configurare con “Passaggio 1 – Installazione di Terraform” in Come Usare Terraform con DigitalOcean.
- Node.js installato sul tuo computer locale. Puoi trovare le istruzioni per questo nella serie Come Installare Node.js e Creare un Ambiente di Sviluppo Locale.
- Essere a proprio agio nella programmazione con JavaScript. Per migliorare le tue competenze, dai un’occhiata alla serie Come Codificare in JavaScript.
- Essere a proprio agio nell’utilizzo delle funzionalità di base di TypeScript. Se non ti senti a tuo agio con TypeScript, la serie di tutorial Come Codificare in TypeScript è una buona risorsa per metterti al passo.
- A code editor or integrated development environment (IDE) that supports TypeScript. If you are not currently using one, try Visual Studio Code. You can also read up on How To Work With TypeScript in Visual Studio Code.
Passo 1 — Installazione della CLI cdktf
Per iniziare, installerai lo strumento da riga di comando cdktf.
La CLI cdktf è disponibile come pacchetto NPM. Se cerchi cdktf su npmjs.com, troverai due pacchetti dal nome simile: cdktf e cdktf-cli.
Concettualmente, CDKTF è uno strato di astrazione sopra Terraform. È composto da due parti:
-
una libreria contenente un insieme di costrutti nativi del linguaggio (come funzioni e classi) per definire infrastrutture. Questa parte è racchiusa all’interno del pacchetto npm
cdktf. Ad esempio, puoi vedere l’uso delle classiAppeTerraformStackdal pacchettocdktfnel seguente progetto di esempio CDKTF: -
Un adattatore che analizza le costruzioni all’interno del progetto CDKTF e le riduce a un insieme di documenti JSON, che vengono quindi ingestati in Terraform allo stesso modo in cui viene ingestato l’HCL. Questo adattatore è incapsulato in uno strumento CLI chiamato
cdktf, fornito dal pacchettocdktf-cli.
Per installare lo strumento CLI cdktf, è necessario il pacchetto cdktf-cli. È possibile installare questo pacchetto globalmente utilizzando npm, yarn, o un gestore di pacchetti a tua scelta.
Per installare cdktf-cli con npm, eseguire il seguente comando:
Nota: Probabilmente ci sarà una versione più recente del pacchetto cdktf-cli dopo la pubblicazione di questo articolo. Puoi provare a seguire il tutorial con l’ultima versione eseguendo npm install --global cdktf-cli@latest, ma sii consapevole che alcuni output potrebbero differire leggermente.
In alternativa, è possibile utilizzare Homebrew su macOS o Linux per installare lo strumento CLI cdktf come formula cdktf:
Per verificare che l’installazione sia riuscita, eseguire il comando cdktf senza argomenti:
Vedrai un output simile al seguente:
OutputPlease pass a command to cdktf, here are all available ones:
cdktf
Commands:
cdktf init Create a new cdktf project from a template.
cdktf get Generate CDK Constructs for Terraform providers and modules.
cdktf convert Converts a single file of HCL configuration to CDK for Terraform.
cdktf deploy [stacks...] Deploy the given stacks
cdktf destroy [stacks..] Destroy the given stacks
cdktf diff [stack] Perform a diff (terraform plan) for the given stack
cdktf list List stacks in app.
cdktf login Retrieves an API token to connect to Terraform Cloud.
cdktf synth Synthesizes Terraform code for the given app in a directory.
cdktf watch [stacks..] [experimental] Watch for file changes and automatically trigger a deploy
cdktf output [stacks..] Prints the output of stacks
cdktf debug Get debug information about the current project and environment
cdktf completion generate completion script
Options:
--version Mostra il numero di versione
--disable-logging Non scrivere file di registro. Supportato utilizzando l'ambiente CDKTF_DISABLE_LOGGING.
--disable-plugin-cache-env Non impostare automaticamente TF_PLUGIN_CACHE_DIR.
--log-level Quale livello di registro deve essere scritto.
-h, --help Show help
Options can be specified via environment variables with the "CDKTF_" prefix (e.g. "CDKTF_OUTPUT")
L’output mostra i comandi disponibili. Nel resto di questo tutorial, acquisirai esperienza nell’uso di cdktf init, cdktf get, cdktf deploy e cdktf destroy.
Ora che hai installato il CLI cdktf, puoi definire l’infrastruttura scrivendo del codice TypeScript.
Passaggio 2 — Creazione di un Nuovo Progetto CDKTF
In questo passaggio, utilizzerai il CLI cdktf appena installato per creare un progetto boilerplate CDKTF, su cui costruirai nei passaggi successivi.
Crea una directory che ospiterà il progetto CDKTF eseguendo il seguente comando:
Successivamente, naviga nella directory appena creata:
Utilizza il comando cdktf init per creare una struttura di progetto CDKTF su cui costruire:
CDKTF consente agli sviluppatori di definire l’infrastruttura utilizzando TypeScript, Python, Java, C# o Go. L’opzione --template=typescript dice a cdktf di generare questo progetto CDKTF utilizzando TypeScript.
Terraform (e quindi CDKTF) tiene traccia delle risorse che gestisce registrando le loro definizioni e stati in file chiamati file di stato di Terraform. L’opzione --local dice a CDKTF di mantenere questi file di stato localmente sulla macchina in esecuzione cdktf (ogni file segue la struttura di denominazione terraform.<stack>.tfstate).
Dopo aver eseguito il comando, l’interfaccia a riga di comando potrebbe chiederti il permesso di inviare rapporti sugli incidenti al team CDKTF per aiutarli a migliorare il prodotto:
Output? Do you want to send crash reports to the CDKTF team? See https://www.terraform.io/cdktf/create-and-deploy/configuration-file for
more information (Y/n)
Digita Y se acconsenti o N se non sei d’accordo, quindi premi ENTER.
cdktf creerà quindi lo scheletro del progetto e installerà i pacchetti. Quando lo scheletro del progetto è generato, vedrai un output simile al seguente:
Output Your cdktf typescript project is ready!
cat help Print this message
Compile:
npm run get Import/update Terraform providers and modules (you should check-in this directory)
npm run compile Compile typescript code to javascript (or "npm run watch")
npm run watch Watch for changes and compile typescript in the background
npm run build Compile typescript
Synthesize:
cdktf synth [stack] Synthesize Terraform resources from stacks to cdktf.out/ (ready for 'terraform apply')
Diff:
cdktf diff [stack] Perform a diff (terraform plan) for the given stack
Deploy:
cdktf deploy [stack] Deploy the given stack
Destroy:
cdktf destroy [stack] Destroy the stack
Test:
npm run test Runs unit tests (edit __tests__/main-test.ts to add your own tests)
npm run test:watch Watches the tests and reruns them on change
Upgrades:
npm run upgrade Upgrade cdktf modules to latest version
npm run upgrade:next Upgrade cdktf modules to latest "@next" version (last commit)
Vedrai anche alcuni nuovi file aggiunti alla directory infra. I file più importanti sono cdktf.json e main.ts.
cdktf.json è il file di configurazione del progetto CDKTF. Se apri il file, visualizzerà qualcosa di simile a quanto segue:
La proprietà app definisce il comando che verrà eseguito per sintetizzare il codice TypeScript in JSON compatibile con Terraform. Questa proprietà indica che main.ts è il punto di ingresso del progetto CDKTF.
Se apri il file main.ts, vedrai qualcosa di simile a quanto segue:
Nel linguaggio di CDKTF, una collezione di risorse infrastrutturali correlate può essere raggruppata in uno stack. Ad esempio, le risorse che compongono un’applicazione API, come Droplets, bilanciatori di carico e record DNS, possono essere raggruppate in un unico stack chiamato APIStack. Ogni stack mantiene il proprio stato e può essere distribuito, modificato o distrutto indipendentemente dagli altri stack. Un uso comune degli stack è avere uno stack per la produzione e uno stack separato per lo sviluppo.
Un’applicazione è un contenitore per più stack. Ad esempio, un’applicazione può raggruppare gli stack di vari microservizi.
Il progetto CDKTF scaffolding generato in main.ts contiene una singola classe stack chiamata MyStack, attualmente senza definire risorse. Un’istanza di MyStack viene creata con il nome infra, contenuta all’interno di un’applicazione chiamata app. Nei passaggi successivi, definirai le risorse infrastrutturali all’interno del costruttore di MyStack.
Dopo aver creato il progetto, il passaggio successivo è configurare il progetto CDKTF con fornitori.
Passaggio 3 — Installazione del Provider DigitalOcean
In questo passaggio, installerai il Provider di DigitalOcean nel progetto CDKTF.
I provider sono librerie che forniscono istruzioni a Terraform (utilizzato da cdktf sotto la superficie) su come creare, aggiornare ed eliminare risorse su fornitori cloud, fornitori SaaS e altre piattaforme che espongono interfacce di programmazione delle applicazioni (API). I provider incapsulano la logica di chiamata di queste API upstream in funzioni standard che Terraform può chiamare.
Ad esempio, se volessi creare un nuovo Droplet di DigitalOcean senza Terraform, dovresti inviare una richiesta POST all’endpoint /v2/droplets dell’API di DigitalOcean. Con Terraform, invece, installeresti il provider di DigitalOcean e definiresti una digitalocean_droplet risorsa, simile al seguente snippet di esempio:
Puoi quindi utilizzare lo strumento CLI cdktf per tradurre questo codice TypeScript in JSON compatibile con Terraform e passarlo al provider, che effettuerà le chiamate API appropriate per creare il Droplet per conto tuo.
Ora che comprendi cosa sia un provider, puoi configurare il provider di DigitalOcean per il tuo progetto CDKTF.
Apri il file cdktf.json e aggiungi la stringa digitalocean/digitalocean all’array terraformProviders:
digitalocean/digitalocean è l’identificatore del provider DigitalOcean nel Registro Terraform.
Salva e chiudi il file.
Successivamente, esegui cdktf get per scaricare e installare il provider.
cdktf get scaricherà il provider, estrarrà lo schema, genererà le relative classi TypeScript e lo aggiungerà come modulo TypeScript sotto .gen/providers/. Questa generazione automatica del codice consente di utilizzare qualsiasi provider Terraform e moduli HCL con CDKTF ed è così che CDKTF può fornire il completamento del codice negli editor che lo supportano.
Una volta che cdktf get ha finito di eseguire, vedrai un output simile al seguente:
OutputGenerated typescript constructs in the output directory: .gen
Vedrai anche una nuova directory chiamata .gen contenente il codice generato del provider.
In questo passaggio, hai installato il provider digitalocean/digitalocean nel progetto. Nel prossimo passaggio, configurerai il provider DigitalOcean con le credenziali necessarie per autenticare il provider con l’API DigitalOcean.
Passaggio 4 — Configurazione del Provider DigitalOcean
In questo passaggio, configurerai il provider DigitalOcean con il tuo Token di Accesso Personale DigitalOcean, che consente al provider di chiamare l’API DigitalOcean per conto tuo.
I diversi provider richiedono e supportano credenziali diverse per l’autenticazione con l’API upstream. Per il provider DigitalOcean, è necessario fornire il tuo Token di Accesso Personale DigitalOcean. Puoi specificare il token al provider impostandolo come variabili d’ambiente DIGITALOCEAN_TOKEN o DIGITALOCEAN_ACCESS_TOKEN.
Esegui il seguente comando nel tuo terminale per impostare la variabile d’ambiente per quella sessione del terminale.
Nota: Chiamando export, stai impostando la variabile d’ambiente solo per quella sessione del terminale. Se chiudi e riapri il terminale o esegui i comandi cdktf in un terminale diverso, dovrai eseguire nuovamente il comando export affinché la variabile d’ambiente abbia effetto.
Successivamente, specifica il provider all’interno della classe MyStack, che ti consentirà di definire le risorse fornite dal provider all’interno del tuo stack. Aggiorna il file main.ts come segue:
Il modulo per il provider si trova in ./.gen/providers/digitalocean, che è stato generato automaticamente quando hai eseguito cdktf get.
Hai configurato il provider digitalocean/digitalocean con le credenziali in questo passaggio. Successivamente, inizierai a definire l’infrastruttura che fa parte dell’obiettivo di questo tutorial.
Passaggio 5 — Definizione delle Applicazioni Web su Droplets
In questo passaggio, definirai due server NGINX, ciascuno che serve file diversi, distribuiti su due Droplet Ubuntu 20.04 identici.
Si inizia con la definizione dei due Droplet. Modifica main.ts con le modifiche evidenziate:
Si utilizza un ciclo nativo di JavaScript (Array.prototype.map()) per evitare la duplicazione del codice.
Come se stessi creando il Droplet attraverso la console, ci sono diversi parametri da specificare:
image– la distribuzione Linux e la versione su cui funzionerà il tuo Droplet.region– il data center in cui verrà eseguito il Droplet.size– la quantità di risorse CPU e di memoria da riservare al Droplet.name– un nome univoco utilizzato per fare riferimento al Droplet.
I valori per image, region e size devono essere cose supportate da DigitalOcean. Puoi trovare i valori validi (chiamati slugs) per tutte le immagini delle distribuzioni Linux supportate, le dimensioni dei Droplet e le regioni sulla pagina API Slugs di DigitalOcean. Puoi trovare un elenco completo degli attributi obbligatori e facoltativi sulla pagina di documentazione digitalocean_droplet.
Aggiunta di una chiave SSH
Come parte dei prerequisiti, hai caricato una chiave pubblica SSH senza password sul tuo account DigitalOcean e ne hai annotato il nome. Ora userai quel nome per recuperare l’ID della chiave SSH e passarlo nella definizione del tuo Droplet.
Dato che la chiave SSH è stata aggiunta manualmente al tuo account DigitalOcean, non è una risorsa gestita dalla tua configurazione Terraform attuale. Se provassi a definire una nuova risorsa digitalocean_ssh_key, creerebbe una nuova chiave SSH anziché utilizzare quella esistente.
Invece, definirai una nuova digitalocean_ssh_key sorgente dati. In Terraform, le sorgenti dati vengono utilizzate per recuperare informazioni sull’infrastruttura che non è gestita dalla configurazione Terraform corrente. In altre parole, forniscono una vista in sola lettura dello stato dell’infrastruttura esterna preesistente. Una volta definita una sorgente dati, puoi utilizzare i dati altrove nella configurazione Terraform.
Ancora in main.ts e all’interno del costruttore di MyStack, definisci una nuova sorgente dati DataDigitaloceanSshKey e passa il nome assegnato alla tua chiave SSH (qui, il nome è do_cdktf):
Quindi, aggiorna la definizione del Droplet per includere la chiave SSH:
Una volta provvisto, puoi accedere al Droplet utilizzando una chiave SSH privata invece di una password.
Specifica lo script dei dati utente per installare NGINX
Hai ora definito due Droplet identici che eseguono Ubuntu, configurati con accesso SSH. Il compito successivo è installare NGINX su ciascun Droplet.
Quando viene creato un Droplet, uno strumento chiamato CloudInit avvierà il server. CloudInit può accettare un file chiamato user data, che può modificare il modo in cui il server viene avviato. I dati utente possono essere qualsiasi file cloud-config o script che il server può interpretare, come script Bash.
Nel resto di questo passaggio, creerai uno script Bash e lo specificerai come dati utente del Droplet. Lo script installerà NGINX come parte del processo di avvio. Inoltre, lo script sostituirà anche il contenuto del file /var/www/html/index.html (il file predefinito servito da NGINX) con il nome host e l’indirizzo IP del Droplet, il che farà sì che i due server NGINX servano file diversi. Nel passaggio successivo, metterai entrambi questi server NGINX dietro un bilanciatore di carico; servendo file diversi, sarà evidente se il bilanciatore di carico sta distribuendo correttamente le richieste o meno.
Ancora in main.ts, aggiungi una nuova proprietà userData all’oggetto di configurazione del Droplet:
Avvertimento: Assicurati che non ci siano nuove righe prima del shebang (#!); altrimenti, lo script potrebbe non essere eseguito.
Quando il Droplet viene provisionato per la prima volta, lo script verrà eseguito come utente root. Utilizzerà il gestore dei pacchetti di Ubuntu, APT, per installare il pacchetto nginx. Successivamente utilizzerà il Servizio Metadata di DigitalOcean per recuperare informazioni su se stesso e scriverà l’hostname e l’indirizzo IP in index.html, che viene servito da NGINX.
In questo passaggio, hai definito i due Droplets che eseguono Ubuntu, configurato ognuno con accesso SSH e installato NGINX utilizzando la funzionalità dei dati utente. Nel prossimo passaggio, definirai un bilanciamento del carico che si troverà di fronte a questi server NGINX e lo configurerai per bilanciare il carico in modo circolare.
Passo 6 — Definizione di un Bilanciamento del Carico
In questo passaggio, definirai un Bilanciamento del Carico di DigitalOcean definendo un’istanza della risorsa digitalocean_loadbalancer.
Ancora in main.ts, aggiungi la seguente definizione per un bilanciamento del carico alla fine del costruttore di MyStack:
L’argomento forwardingRule indica al bilanciamento del carico di ascoltare le richieste HTTP sulla porta 80 e inoltrarle a ciascun Droplet sulla porta 80.
Gli dropletIds specificano i Droplet a cui il bilanciamento del carico passerà le richieste. Prende un numero, ma il valore di droplet.id è una stringa. Pertanto, hai utilizzato la funzione Fn.tonumber di Terraform per convertire il valore dell’ID del Droplet da stringa a numero.
Nota: Hai utilizzato la funzione Fn.tonumber di Terraform qui invece del parseInt nativo di JavaScript perché il valore di droplet.id è sconosciuto fino a quando il Droplet non è stato provisionato. Le funzioni di Terraform sono progettate per operare su valori di runtime sconosciuti prima che Terraform applichi una configurazione.
Salva e chiudi il file.
Hai ora definito due Droplet e un bilanciamento del carico che si trova davanti a loro. Il tuo main.ts dovrebbe assomigliare a questo:
Nel prossimo passaggio, utilizzerai lo strumento CLI cdktf per attualizzare l’intero progetto CDKTF.
Passo 7 — Provisioning della tua infrastruttura
In questo passaggio, utilizzerai lo strumento CLI cdktf per approvvigionare i Droplet e i bilanciatori di carico che hai definito nei passaggi precedenti.
Assicurati di trovarti nella directory infra/ e di aver impostato la variabile d’ambiente DIGITALOCEAN_ACCESS_TOKEN per la sessione del terminale, quindi esegui il comando cdktf deploy:
Dovresti vedere un output simile al seguente:
Outputinfra Initializing the backend...
infra Initializing provider plugins...
infra - Reusing previous version of digitalocean/digitalocean from the dependency lock file
infra - Using previously-installed digitalocean/digitalocean v2.19.0
infra Terraform has been successfully initialized!
infra Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
infra # digitalocean_droplet.bar (bar) will be created
+ resource "digitalocean_droplet" "bar" {
+ backups = false
+ created_at = (known after apply)
+ disk = (known after apply)
+ graceful_shutdown = false
+ id = (known after apply)
+ image = "ubuntu-20-04-x64"
+ ipv4_address = (known after apply)
+ ipv4_address_private = (known after apply)
+ ipv6 = false
+ ipv6_address = (known after apply)
+ locked = (known after apply)
+ memory = (known after apply)
+ monitoring = false
+ name = "bar"
+ price_hourly = (known after apply)
+ price_monthly = (known after apply)
+ private_networking = (known after apply)
+ region = "lon1"
+ resize_disk = true
+ size = "s-1vcpu-1gb"
+ ssh_keys = [
+ "34377800",
]
+ status = (known after apply)
+ urn = (known after apply)
+ user_data = "f9b1d9796d069fe504ce0d89439b6b664b14b1a1"
+ vcpus = (known after apply)
+ volume_ids = (known after apply)
+ vpc_uuid = (known after apply)
}
# digitalocean_droplet.foo (foo) verrà creato
+ resource "digitalocean_droplet" "foo" {
+ backups = false
+ created_at = (known after apply)
+ disk = (known after apply)
+ graceful_shutdown = false
+ id = (known after apply)
+ image = "ubuntu-20-04-x64"
+ ipv4_address = (known after apply)
+ ipv4_address_private = (known after apply)
+ ipv6 = false
+ ipv6_address = (known after apply)
+ locked = (known after apply)
+ memory = (known after apply)
+ monitoring = false
+ name = "foo"
+ price_hourly = (known after apply)
+ price_monthly = (known after apply)
+ private_networking = (known after apply)
+ region = "lon1"
+ resize_disk = true
+ size = "s-1vcpu-1gb"
+ ssh_keys = [
+ "34377800",
]
+ status = (known after apply)
+ urn = (known after apply)
+ user_data = "f9b1d9796d069fe504ce0d89439b6b664b14b1a1"
+ vcpus = (known after apply)
+ volume_ids = (known after apply)
+ vpc_uuid = (known after apply)
}
# digitalocean_loadbalancer.lb (lb) verrà creato
+ resource "digitalocean_loadbalancer" "lb" {
+ algorithm = "round_robin"
+ disable_lets_encrypt_dns_records = false
+ droplet_ids = (known after apply)
+ enable_backend_keepalive = false
+ enable_proxy_protocol = false
+ id = (known after apply)
+ ip = (known after apply)
+ name = "default"
+ redirect_http_to_https = false
+ region = "lon1"
+ size_unit = (known after apply)
+ status = (known after apply)
+ urn = (known after apply)
+ vpc_uuid = (known after apply)
+ forwarding_rule {
+ certificate_id = (known after apply)
+ certificate_name = (known after apply)
+ entry_port = 80
+ entry_protocol = "http"
+ target_port = 80
+ target_protocol = "http"
+ tls_passthrough = false
}
+ healthcheck {
+ check_interval_seconds = (known after apply)
+ healthy_threshold = (known after apply)
+ path = (known after apply)
+ port = (known after apply)
+ protocol = (known after apply)
+ response_timeout_seconds = (known after apply)
+ unhealthy_threshold = (known after apply)
}
+ sticky_sessions {
+ cookie_name = (known after apply)
+ cookie_ttl_seconds = (known after apply)
+ type = (known after apply)
}
}
Plan: 3 to add, 0 to change, 0 to destroy.
─────────────────────────────────────────────────────────────────────────────
Saved the plan to: plan
To perform exactly these actions, run the following command to apply:
terraform apply "plan"
Please review the diff output above for infra
❯ Approve Applies the changes outlined in the plan.
Dismiss
Stop
Nota: CDKTF è ancora in fase di sviluppo e l’output potrebbe essere diverso da quello mostrato sopra.
Questo display elenca tutte le risorse e le proprietà che cdktf intende creare, aggiornare e distruggere. Alcuni valori, come l’ID di un Droplet, sono noti solo dopo che la risorsa è stata approvvigionata. Per quelli, vedrai (noto dopo l'applicazione) come valore della proprietà nell’output.
Rivedi l’elenco delle risorse per assicurarti che corrisponda alle tue aspettative. Quindi, utilizza i tasti freccia per selezionare l’opzione Approva e premi INVIO.
Vedrai un output simile al seguente:
Outputinfra digitalocean_droplet.foo (foo): Creating...
digitalocean_droplet.bar (bar): Creating...
infra digitalocean_droplet.bar (bar): Still creating... [10s elapsed]
infra digitalocean_droplet.foo (foo): Still creating... [10s elapsed]
1 Stack deploying 0 Stacks done 0 Stacks waiting
Questo output ti informa che cdktf sta comunicando con l’API di DigitalOcean per creare il Droplet. cdktf sta creando prima i Droplet perché il bilanciamento del carico dipende dall’ID del Droplet, che è sconosciuto fino a quando i Droplet non sono approvvigionati.
La creazione del Droplet di solito richiede meno di un minuto. Una volta approvvigionati i Droplet, cdktf procede alla creazione del bilanciatore di carico.
Outputinfra digitalocean_droplet.bar (bar): Creation complete after 54s [id=298041598]
infra digitalocean_droplet.foo (foo): Creation complete after 55s [id=298041600]
infra digitalocean_loadbalancer.lb (lb): Creating...
infra digitalocean_loadbalancer.lb (lb): Still creating... [10s elapsed]
Il bilanciamento del carico potrebbe richiedere più tempo. Dopo che il bilanciamento del carico è stato creato, vedrai un riepilogo che mostra che lo stack è stato distribuito con successo.
Outputinfra digitalocean_loadbalancer.lb (lb): Still creating... [1m30s elapsed]
infra digitalocean_loadbalancer.lb (lb): Creation complete after 1m32s [id=4f9ae2b7-b649-4fb4-beed-96b95bb72dd1]
infra
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
No outputs found.
Ora puoi visitare la console di DigitalOcean, dove puoi vedere un bilanciamento del carico denominato default e due Droplets sani denominati foo e bar, ognuno dei quali funge da destinazione per il bilanciamento del carico.
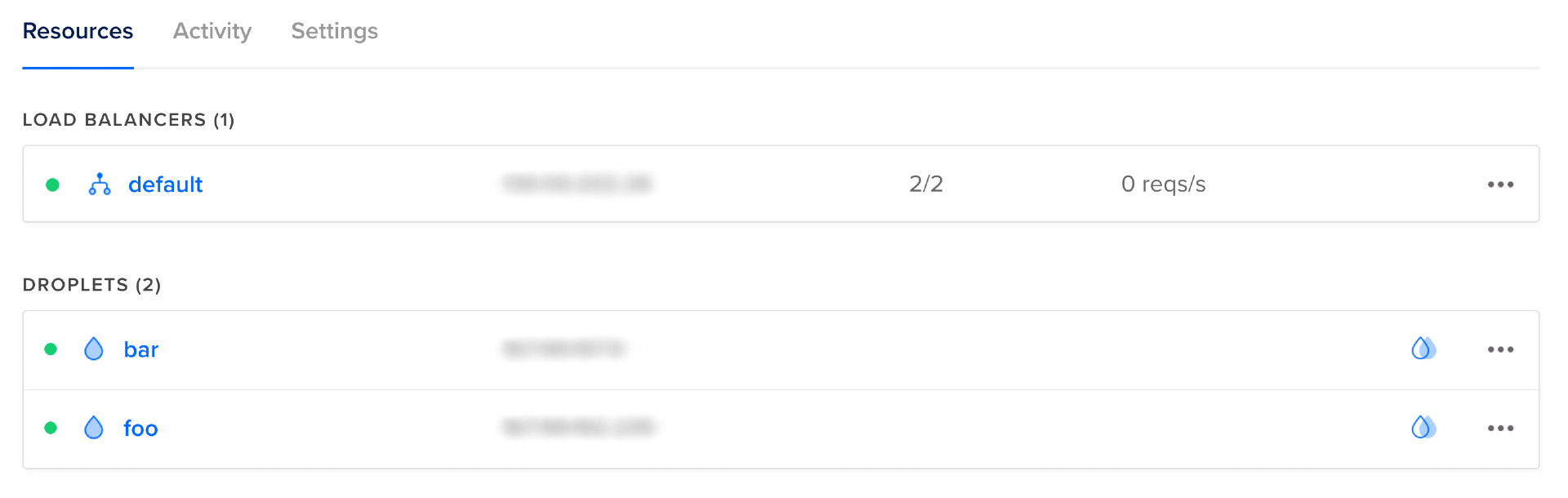
Puoi verificare che NGINX sia in esecuzione e stia servendo correttamente il contenuto visitando l’indirizzo IP di ciascun Droplet. Dovresti vedere un testo simile al seguente:
Droplet: bar, IP Address: droplet_ip
Se non visualizzi quella stringa di testo o il server non risponde, controlla che i dati utente specificati siano corretti e che nessun carattere (inclusi i ritorni a capo) preceda il shebang (#!). Puoi anche accedere tramite SSH al Droplet utilizzando la tua chiave privata SSH e controllare i log di output generati da CloudInit in /var/log/cloud-init-output.log:
Una volta confermato che i Droplets siano attivi e stiano servendo il contenuto, puoi iniziare a testare il bilanciamento del carico. Puoi farlo inviando alcune richieste.
Esegui il seguente comando dal tuo terminale per inviare dieci richieste al bilanciamento del carico:
Dovresti vedere un output simile al seguente, anche se gli indirizzi IP mostrati saranno diversi:
OutputDroplet: foo, IP Address: droplet_foo_ip
Droplet: bar, IP Address: droplet_bar_ip
Droplet: foo, IP Address: droplet_foo_ip
Droplet: bar, IP Address: droplet_bar_ip
Droplet: bar, IP Address: droplet_bar_ip
Droplet: foo, IP Address: droplet_foo_ip
Droplet: bar, IP Address: droplet_bar_ip
Droplet: foo, IP Address: droplet_foo_ip
Droplet: bar, IP Address: droplet_bar_ip
Droplet: foo, IP Address: droplet_foo_ip
Indica che le richieste al bilanciamento del carico sono state inoltrate a ciascun Droplet cinque volte, indicando che il bilanciamento del carico sta funzionando.
Nota: Il bilanciamento del carico potrebbe non sempre distribuire equamente tra i due Droplets; potresti trovare che quattro richieste sono state inviate a un Droplet e sei all’altro. Questo comportamento è normale.
In questo passaggio, hai utilizzato cdktf per provvedere alle tue risorse, e poi hai utilizzato la console di DigitalOcean per scoprire gli indirizzi IP dei tuoi Droplet e del bilanciatore di carico. Successivamente hai inviato richieste a ciascun Droplet e bilanciatore di carico per confermare che funzionino.
Nel prossimo passaggio, otterrai gli indirizzi IP dei Droplet e del bilanciatore di carico senza effettuare l’accesso alla console di DigitalOcean.
Passaggio 8 — Output di Informazioni
Nel passaggio precedente, hai dovuto accedere alla Console di DigitalOcean per ottenere gli indirizzi IP del tuo Droplet e del bilanciatore di carico. In questo passaggio, modificherai leggermente il tuo codice in modo che queste informazioni siano stampate nell’output del comando cdktf deploy, risparmiandoti una visita alla console.
Terraform registra la configurazione e lo stato delle sue risorse gestite nei file di stato. Per il tuo stack infra, il file di stato può essere trovato a infra/terraform.infra.tfstate. Sarai in grado di trovare gli indirizzi IP dei Droplet e del bilanciatore di carico all’interno di questo file di stato.
Tuttavia, ordinare un file grande può essere scomodo. CDKTF fornisce il costrutto TerraformOutput, che puoi utilizzare per produrre variabili e renderle disponibili al di fuori dello stack. Eventuali output vengono stampati in stdout dopo l’esecuzione di cdktf deploy. Eseguire cdktf output può anche stampare gli output in qualsiasi momento.
Nota: Anche se si utilizzano solo le uscite per stampare informazioni sulla console in questo tutorial, la sua vera potenza deriva dall’uso di stack che utilizzano le uscite di altri stack come input, una funzionalità nota come riferimenti incrociati tra stack.
Aggiornare il file main.ts per includere le uscite degli indirizzi IP del bilanciamento del carico e dei Droplets:
Salvare e chiudere il file.
Eseguire cdktf deploy per attualizzare la modifica:
All’interno dell’output, dovresti vedere qualcosa di simile al seguente:
Output─────────────────────────────────────────────────────────────────────────────
Changes to Outputs:
+ droplet0IP = "droplet_foo_ip"
+ droplet1IP = "droplet_bar_ip"
+ loadBalancerIP = "load_balancer_ip"
You can apply this plan to save these new output values to the Terraform
state, without changing any real infrastructure.
─────────────────────────────────────────────────────────────────────────────
Questo output ti indica che non verranno apportate modifiche all’infrastruttura, solo ciò che è stato prodotto dallo stack.
Utilizzare i tasti freccia per selezionare Approve, e quindi premere ENTER. Alla fine dell’output del terminale, dovresti vedere qualcosa di simile a:
Outputinfra
droplet0IP = droplet_foo_ip
droplet1IP = droplet_bar_ip
loadBalancerIP = load_balancer_ip
Ora, ogni volta che si esegue cdktf deploy o cdktf output, gli indirizzi IP dei Droplets e dei bilanciatori di carico vengono stampati nell’output del terminale, evitando la necessità di accedere a tali informazioni dalla console di DigitalOcean.
Ora hai fornito due Droplets e un bilanciamento del carico e confermato che stanno funzionando. Puoi utilizzare il progetto CDKTF che hai sviluppato come base per definire un’infrastruttura più sofisticata (puoi trovare un’implementazione di riferimento su do-community/digitalocean-cdktf-typescript).
Le risorse predisposte in questo tutorial comporteranno un addebito. Se non hai intenzione di utilizzare l’infrastruttura creata, dovresti distruggerla. Nel prossimo e ultimo passaggio, pulirai il progetto distruggendo le risorse create in questo tutorial.
Passaggio 9 — Distruggere la tua Infrastruttura
In questo passaggio, rimuoverai tutte le risorse create in questo tutorial.
Ancora all’interno della directory infra/, esegui cdktf destroy:
Dovresti vedere un output simile al seguente:
Outputinfra Initializing the backend...
infra Initializing provider plugins...
infra - Reusing previous version of digitalocean/digitalocean from the dependency lock file
infra - Using previously-installed digitalocean/digitalocean v2.19.0
infra Terraform has been successfully initialized!
infra digitalocean_droplet.bar (bar): Refreshing state... [id=298041598]
digitalocean_droplet.foo (foo): Refreshing state... [id=298041600]
infra digitalocean_loadbalancer.lb (lb): Refreshing state... [id=4f9ae2b7-b649-4fb4-beed-96b95bb72dd1]
infra Terraform used the selected providers to generate the following execution
plan. Resource actions are indicated with the following symbols:
- destroy
Terraform will perform the following actions:
infra # digitalocean_droplet.bar (bar) will be destroyed
- resource "digitalocean_droplet" "bar" {
- backups = false -> null
- created_at = "2022-05-02T10:04:16Z" -> null
- disk = 25 -> null
- graceful_shutdown = false -> null
- id = "298041598" -> null
- image = "ubuntu-20-04-x64" -> null
- ipv4_address = "droplet_bar_public_ip" -> null
- ipv4_address_private = "droplet_bar_private_ip" -> null
- ipv6 = false -> null
- locked = false -> null
- memory = 1024 -> null
- monitoring = false -> null
- name = "bar" -> null
- price_hourly = 0.00744 -> null
- price_monthly = 5 -> null
- private_networking = true -> null
- region = "lon1" -> null
- resize_disk = true -> null
- size = "s-1vcpu-1gb" -> null
- ssh_keys = [
- "34377800",
] -> null
- status = "active" -> null
- tags = [] -> null
- urn = "do:droplet:298041598" -> null
- user_data = "f9b1d9796d069fe504ce0d89439b6b664b14b1a1" -> null
- vcpus = 1 -> null
- volume_ids = [] -> null
- vpc_uuid = "bed80b32-dc82-11e8-83ec-3cfdfea9f3f0" -> null
}
# digitalocean_droplet.foo (foo) sarà distrutto
- resource "digitalocean_droplet" "foo" {
- backups = false -> null
- created_at = "2022-05-02T10:04:16Z" -> null
- disk = 25 -> null
- graceful_shutdown = false -> null
- id = "298041600" -> null
- image = "ubuntu-20-04-x64" -> null
- ipv4_address = "droplet_foo_public_ip" -> null
- ipv4_address_private = "droplet_foo_private_ip" -> null
- ipv6 = false -> null
- locked = false -> null
- memory = 1024 -> null
- monitoring = false -> null
- name = "foo" -> null
- price_hourly = 0.00744 -> null
- price_monthly = 5 -> null
- private_networking = true -> null
- region = "lon1" -> null
- resize_disk = true -> null
- size = "s-1vcpu-1gb" -> null
- ssh_keys = [
- "34377800",
] -> null
- status = "active" -> null
- tags = [] -> null
- urn = "do:droplet:298041600" -> null
- user_data = "f9b1d9796d069fe504ce0d89439b6b664b14b1a1" -> null
- vcpus = 1 -> null
- volume_ids = [] -> null
- vpc_uuid = "bed80b32-dc82-11e8-83ec-3cfdfea9f3f0" -> null
}
# digitalocean_loadbalancer.lb (lb) sarà distrutto
- resource "digitalocean_loadbalancer" "lb" {
- algorithm = "round_robin" -> null
- disable_lets_encrypt_dns_records = false -> null
- droplet_ids = [
- 298041598,
- 298041600,
] -> null
- enable_backend_keepalive = false -> null
- enable_proxy_protocol = false -> null
- id = "4f9ae2b7-b649-4fb4-beed-96b95bb72dd1" -> null
- ip = "load_balancer_ip" -> null
- name = "default" -> null
- redirect_http_to_https = false -> null
- region = "lon1" -> null
- size_unit = 1 -> null
- status = "active" -> null
- urn = "do:loadbalancer:4f9ae2b7-b649-4fb4-beed-96b95bb72dd1" -> null
- vpc_uuid = "bed80b32-dc82-11e8-83ec-3cfdfea9f3f0" -> null
- forwarding_rule {
- entry_port = 80 -> null
- entry_protocol = "http" -> nul
infra l
- target_port = 80 -> null
- target_protocol = "http" -> null
- tls_passthrough = false -> null
}
- healthcheck {
- check_interval_seconds = 10 -> null
- healthy_threshold = 5 -> null
- path = "/" -> null
- port = 80 -> null
- protocol = "http" -> null
- response_timeout_seconds = 5 -> null
- unhealthy_threshold = 3 -> null
}
- sticky_sessions {
- cookie_ttl_seconds = 0 -> null
- type = "none" -> null
}
}
Plan: 0 to add, 0 to change, 3 to destroy.
─────────────────────────────────────────────────────────────────────────────
Saved the plan to: plan
To perform exactly these actions, run the following command to apply:
terraform apply "plan"
Please review the diff output above for infra
❯ Approve Applies the changes outlined in the plan.
Dismiss
Stop
Questa volta, invece di mostrare + accanto a ogni risorsa, mostra -, indicando che CDKTF intende distruggere la risorsa. Esamina le modifiche proposte, quindi utilizza i tasti freccia per selezionare Approva e premi INVIO. Il provider DigitalOcean ora comunicherà con l’API di DigitalOcean per distruggere le risorse.
Outputinfra digitalocean_loadbalancer.lb (lb): Destroying... [id=4f9ae2b7-b649-4fb4-beed-96b95bb72dd1]
infra digitalocean_loadbalancer.lb (lb): Destruction complete after 1s
infra digitalocean_droplet.bar (bar): Destroying... [id=298041598]
digitalocean_droplet.foo (foo): Destroying... [id=298041600]
Il bilanciamento del carico è stato eliminato per primo perché non ha dipendenze (nessuna altra risorsa fa riferimento al bilanciamento del carico nei propri input). Poiché il bilanciamento del carico fa riferimento ai Droplet, possono essere distrutti solo dopo che il bilanciamento del carico è stato distrutto.
Dopo che le risorse sono state distrutte, vedrai la seguente riga stampata nell’output:
OutputDestroy complete! Resources: 3 destroyed.
Conclusione
In questo tutorial, hai utilizzato CDKTF per creare e distruggere una pagina web bilanciata, composta da due Droplets DigitalOcean che eseguono server NGINX, serviti dietro un bilanciatore di carico. Hai anche visualizzato informazioni sulle risorse sul terminale.
CDKTF è uno strato di astrazione sopra Terraform. Una buona comprensione di Terraform è utile per capire CDKTF. Se desideri saperne di più su Terraform, puoi leggere la serie Come Gestire l’Infrastruttura con Terraform, che tratta Terraform in profondità.
Puoi anche consultare la documentazione ufficiale CDK for Terraform e tutorial per saperne di più su CDKTF.