













L’avvento del sistema di file distribuito Apache Hadoop (HDFS) ha rivoluzionato la memorizzazione, il trattamento e l’analisi dei dati per le aziende, accelerando la crescita dei big data e portando cambiamenti trasformativi nel settore.
Inizialmente, Hadoop integrò memorizzazione e calcolo, ma l’emergere della cloud computing portò alla separazione di questi componenti. La memorizzazione di oggetti emerse come alternativa all’HDFS ma presentava limitazioni. Per colmare queste limitazioni, JuiceFS, un sistema di file distribuito open-source ad alto rendimento, offre soluzioni convenienti per scenari intensivi di dati come il calcolo, l’analisi e l’addestramento. La decisione di adottare la separazione memorizzazione-calcolo dipende da fattori come scalabilità, prestazioni, costi e compatibilità.
In questo articolo, esamineremo l’architettura di Hadoop, discuteremo l’importanza e la fattibilità della decuplinazione memorizzazione-calcolo e esploreremo le soluzioni disponibili sul mercato, evidenziando i loro rispettivi pro e contro. Il nostro obiettivo è fornire intuizioni e ispirazione alle aziende che stanno attraversando una trasformazione dell’architettura di separazione memorizzazione-calcolo.
Caratteristiche di Progettazione dell’Architettura di Hadoop
Hadoop come Framework Tutto-In-Uno
Nel 2006, Hadoop fu rilasciato come framework tutto-in-uno composto da tre componenti:
- MapReduce per il calcolo
- YARN per la pianificazione delle risorse
- HDFS per la memorizzazione di file distribuita
 Core components of Hadoop
Core components of HadoopComponenti di Calcolo Diversi
Tra questi tre componenti, la strato di calcolo ha visto un rapido sviluppo. Inizialmente, c’era solo MapReduce, ma l’industria presto ha assistito all’emergere di vari framework come Tez e Spark per il calcolo, Hive per l’archiviazione dati, e motori di interrogazione come Presto e Impala. In congiunzione con questi componenti, ci sono numerosi strumenti di trasferimento dati come Sqoop.

HDFS Dominato il Sistema di Archiviazione
In circa dieci anni, HDFS, il sistema di file distribuito, è rimasto il sistema di archiviazione dominante. Era la scelta predefinita per quasi tutti i componenti di calcolo. Tutti i componenti sopra menzionati all’interno dell’ecosistema big data sono stati progettati per l’API HDFS. Alcuni componenti sfruttano in profondità le specifiche capacità di HDFS. Ad esempio:
- HBase utilizza le capacità di scrittura a bassa latenza di HDFS per i loro registri di scrittura anticipata.
- MapReduce e Spark fornivano funzionalità di località dei dati.
Le scelte di progettazione di questi componenti big data, basate sull’API HDFS, hanno portato sfide potenziali per la distribuzione di piattaforme dati nel cloud.
Architettura Accoppiata Archiviazione-Calcolo
Il seguente diagramma mostra parte di una architettura HDFS semplificata, che unisce il calcolo con lo storage.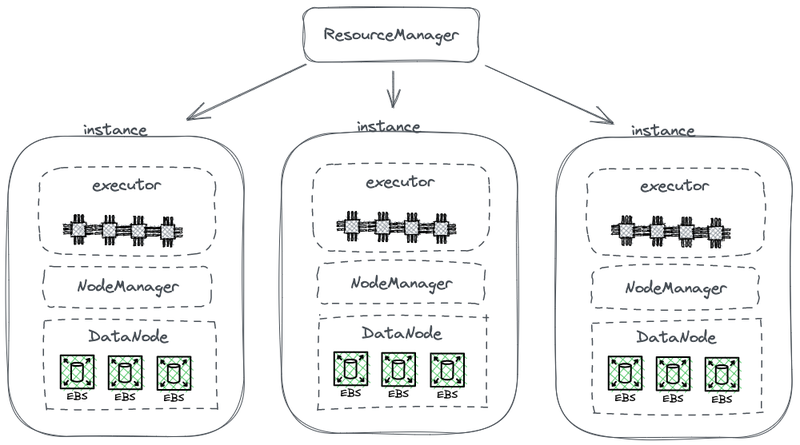
Architettura Hadoop con archiviazione e calcolo accoppiati
In questo diagramma, ogni nodo funge da HDFS DataNode per memorizzare i dati. Inoltre, YARN dispone di un processo Node Manager su ciascun nodo. Ciò consente a YARN di riconoscere il nodo come parte delle sue risorse gestite per le attività di calcolo. Questa architettura consente l’esistenza contemporanea di storage e calcolo sulla stessa macchina, e i dati possono essere letti dalla memoria disco durante il calcolo.
Perché Hadoop accoppia archiviazione e calcolo
Hadoop accoppia archiviazione e calcolo a causa delle limitazioni della comunicazione di rete e del hardware durante la fase di progettazione.
Nel 2006, il cloud computing era ancora agli inizi, ed Amazon aveva appena lanciato il suo primo servizio. Nei data center, le schede di rete prevalenti operavano principalmente a 100 Mbps. I dischi dati utilizzati per i carichi di lavoro big data raggiungevano una velocità di trasferimento di circa 50 MB/s, equivalente a 400 Mbps in termini di larghezza di banda di rete.
Considerando un nodo con otto dischi che funziona al massimo della sua capacità, erano necessarie diverse gigabit al secondo di larghezza di banda di rete per una trasmissione dati efficiente. Sfortunatamente, la capacità massima delle schede di rete era limitata a 1 Gbps. Di conseguenza, la larghezza di banda di rete per nodo non era sufficiente per sfruttare appieno le capacità di tutti i dischi all’interno del nodo. Di conseguenza, se i compiti di calcolo si trovavano ad un’estremità della rete e i dati risiedevano su nodi dati all’altra estremità, la larghezza di banda di rete rappresentava un significativo collo di bottiglia.
Perché la separazione tra archiviazione e calcolo è necessaria
Dal 2006 circa fino al 2016, le aziende si sono confrontate con i seguenti problemi:
- La domanda di potenza di calcolo e di archiviazione nei sistemi applicativi era sbilanciata e le loro velocità di crescita erano diverse. Mentre i dati aziendali crescevano rapidamente, la necessità di potenza di calcolo non aumentava così velocemente. Questi compiti, sviluppati dall’uomo, non si moltiplicavano esponenzialmente in un breve periodo. Tuttavia, i dati generati da questi compiti si accumulavano rapidamente, forse in modo esponenziale. Inoltre, alcuni dati potrebbero non essere immediatamente utili per l’azienda, ma avrebbero valore in futuro. Pertanto, le aziende hanno archiviato i dati in modo esaustivo per esplorare il loro potenziale valore.
- Durante l’espansione, le aziende dovevano espandere sia la potenza di calcolo che lo spazio di archiviazione contemporaneamente, il che spesso portava a risorse di calcolo sprecate. La topologia hardware dell’architettura con storage e calcolo accoppiati influiva sull’espansione della capacità. Quando la capacità di archiviazione scarseggiava, non solo dovevamo aggiungere macchine ma anche aggiornare CPU e memoria poiché i nodi dati nell’architettura accoppiata erano responsabili del calcolo. Di conseguenza, le macchine erano generalmente equipaggiate con una configurazione equilibrata tra potenza di calcolo e capacità di archiviazione, fornendo una sufficiente capacità di archiviazione insieme a una potenza di calcolo comparabile. Tuttavia, la domanda effettiva di potenza di calcolo non aumentava come previsto. Di conseguenza, l’espansione della potenza di calcolo causava un grande spreco per le aziende.
- L’equilibrio tra calcolo e archiviazione e la scelta delle macchine adatte divenne un’impresa ardua. L’utilizzo delle risorse dell’intero cluster in termini di archiviazione e I/O poteva essere altamente sbilanciato, e questo squilibrio peggiorava all’aumentare della dimensione del cluster. Inoltre, era difficile acquistare macchine appropriate, poiché queste dovevano bilanciare le esigenze di calcolo e archiviazione.
- Poiché i dati potevano essere distribuiti in modo non uniforme, era difficile pianificare in modo efficace le attività di calcolo sugli istanze dove risiedevano i dati. La strategia di scheduling basata sulla località dei dati potrebbe non gestire efficacemente scenari del mondo reale a causa della possibilità di distribuzione dei dati sbilanciata. Ad esempio, alcuni nodi potrebbero diventare hotspots locali, richiedendo più potenza di calcolo. Di conseguenza, anche se le attività sul piattaforma big data erano pianificate su questi nodi hotspot, la performance I/O potrebbe comunque rimanere un fattore limitante.
Perché la separazione tra storage e calcolo è fattibile
La possibilità di separare storage e calcolo è diventata realizzabile grazie ai progressi nel campo dell’hardware e del software tra il 2006 e il 2016. Questi progressi includono:
Schede di rete
L’adozione delle schede di rete a 10 Gb è diventata diffusa, con crescente disponibilità di capacità più elevate come 20 Gb, 40 Gb e persino 50 Gb nei data center e nelle infrastrutture cloud. In scenari di AI, vengono anche utilizzate schede di rete con capacità di 100 GB. Questo rappresenta un significativo aumento di banda di rete, oltre 100 volte.
Dischi
Molti aziende continuano a fare affidamento su soluzioni basate su dischi per il storage in grandi cluster di dati. Il throughput dei dischi è raddoppiato, passando da 50 MB/s a 100 MB/s. Un’istanza equipaggiata con una scheda di rete a 10 GB può supportare un throughput massimo di circa 12 dischi. Questo è sufficiente per la maggior parte delle aziende, e quindi la trasmissione di rete non è più un collo di bottiglia.
Software
L’uso di algoritmi di compressione efficienti come Snappy, LZ4 e Zstandard e formati di storage a colonne come Avro, Parquet e Orc ha ulteriormente alleviato la pressione su I/O. Il collo di bottiglia nel processamento dei big data è passato da I/O alle prestazioni della CPU.
Come implementare la separazione tra storage e calcolo
Prima Sperimentazione: Distribuzione Indipendente di HDFS nel Cloud
Distribuzione Indipendente di HDFS
Dal 2013, ci sono state delle proposte nell’industria per separare l’archiviazione e il calcolo. L’approccio iniziale è abbastanza semplice, consistendo nella distribuzione indipendente di HDFS senza integrarla con i lavoratori di calcolo. Questo soluzione non ha introdotto nuovi componenti nell’ecosistema Hadoop.
Come mostrato nel diagramma sottostante, il NodeManager non era più distribuito sui DataNodes. Ciò indicava che i compiti di calcolo non venivano più inviati ai DataNodes. L’archiviazione è diventata un cluster separato, e i dati necessari per i calcoli venivano trasmessi attraverso la rete, supportati da schede di rete end-to-end da 10 Gb. (Si noti che le linee di trasmissione della rete non sono segnate nel diagramma.)

Sebbene questa soluzione abbia abbandonato la località dei dati, il design più ingegnoso di HDFS, la velocità potenziata della comunicazione di rete ha facilitato significativamente la configurazione del cluster. Ciò è stato dimostrato attraverso esperimenti condotti da Davies, il co-fondatore di Juicedata, e i suoi compagni di squadra durante il loro periodo in Facebook nel 2013. I risultati hanno confermato la fattibilità della distribuzione e gestione indipendente dei nodi di calcolo.
Tuttavia, questo tentativo non ha avuto ulteriore sviluppo. La ragione principale è la sfida di distribuire HDFS nel cloud.
Sfide nella Distribuzione di HDFS nel Cloud
Distribuire HDFS nel cloud affronta i seguenti problemi:
- Il meccanismo multi-replica di HDFS può aumentare il costo delle imprese nel cloud: In passato, le imprese utilizzavano dischi nudi per costruire un sistema HDFS nei loro data center. Per mitigare il rischio di danni ai dischi, HDFS ha implementato un meccanismo multi-replica per garantire la sicurezza e la disponibilità dei dati. Tuttavia, quando si sposta i dati nel cloud, i provider di cloud offrono dischi cloud che sono già protetti dal meccanismo multi-replica. Di conseguenza, le imprese devono replicare i dati tre volte all’interno del cloud, causando un aumento significativo dei costi.
- Opzioni limitate per il deployment su dischi nudi: Mentre i provider di cloud offrono alcuni tipi di macchine con dischi nudi, le opzioni disponibili sono limitate. Ad esempio, su 100 tipi di macchine virtuali disponibili nel cloud, solo 5-10 tipi di macchine supportano dischi nudi. Questa selezione limitata potrebbe non soddisfare i requisiti specifici dei cluster delle imprese.
- Incapacità di sfruttare i vantaggi unici del cloud: Il deployment di HDFS nel cloud richiede la creazione manuale delle macchine, il deployment, la manutenzione, il monitoraggio e le operazioni senza la convenienza dello scaling elastico e del modello pay-as-you-go. Questi sono i principali vantaggi del cloud computing. Pertanto, il deployment di HDFS nel cloud mentre si raggiunge la separazione tra storage e calcolo non è facile.
Limitazioni di HDFS
HDFS stesso ha queste limitazioni:
- I NameNodes hanno scalabilità limitata: I NameNodes in HDFS possono scalare solo verticalmente e non possono scalare in modo distribuito. Questa limitazione impone una restrizione sul numero di file che possono essere gestiti all’interno di un singolo cluster HDFS.
- Il mantenimento di oltre 500 milioni di file comporta costi operativi elevati: Secondo la nostra esperienza, è generalmente facile gestire e mantenere HDFS con meno di 300 milioni di file. Quando il numero di file supera i 500 milioni, è necessario implementare il meccanismo di HDFS Federation. Tuttavia, ciò introduce costi operativi e di gestione elevati.
- Alti consumi di risorse e pesante carico sul NameNode influenzano l’affidabilità del cluster HDFS: Quando un NameNode occupa troppe risorse con un carico elevato, può essere attivata una raccolta di immondizia completa (GC). Ciò influisce sull’affidabilità dell’intero cluster HDFS. Il sistema di archiviazione potrebbe subire tempi di inattività, rendendolo incapace di leggere i dati, e non c’è modo di intervenire nel processo di GC. La durata del blocco del sistema non può essere determinata. Questo è stato un problema persistente nei cluster HDFS ad alto carico.
Cloud Pubblico + Archiviazione Obiettivo
Con il progresso della computazione cloud, le aziende ora hanno la possibilità di utilizzare l’archiviazione obiettivo come alternativa a HDFS. L’archiviazione obiettivo è stata progettata specificamente per l’archiviazione di grandi quantità di dati non strutturati, offrendo un’architettura per un facile caricamento e download dei dati. Offre una capacità di archiviazione altamente scalabile, garantendo un costo efficace.
Vantaggi dell’Archiviazione Obiettivo come Sostituto di HDFS
L’archiviazione obiettivo è diventata popolare, a partire da AWS e successivamente adottata da altri provider di cloud come sostituto di HDFS. I seguenti vantaggi sono degni di nota:
- Orientato ai servizi e pronti all’uso: L’archiviazione obiettivo non richiede attività di distribuzione, monitoraggio o manutenzione, offrendo un’esperienza conveniente e user-friendly.
- Scala elastico e pay-as-you-go: Le aziende pagano per l’archiviazione di oggetti in base al loro utilizzo effettivo, eliminando la necessità di pianificazione della capacità. Possono creare un bucket di archiviazione di oggetti e memorizzare quanta data necessaria senza preoccupazioni per i limiti di capacità di archiviazione.
Svantaggi dell’Archiviazione di Oggetti
Tuttavia, quando si utilizza l’archiviazione di oggetti per supportare sistemi di dati complessi come Hadoop, sorgono i seguenti problemi:
Svantaggio #1: Scarsa Prestazione della Lista dei File
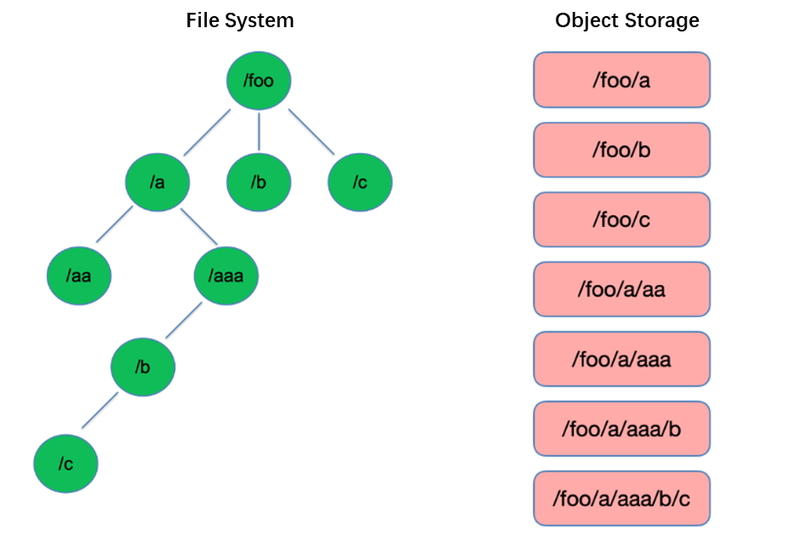
La lista è una delle operazioni più basilari nel sistema di file. È leggera e veloce in strutture ad albero come HDFS.
Al contrario, l’archiviazione di oggetti adotta una struttura piatta e richiede l’indicizzazione con chiavi (identificatori unici) per memorizzare e recuperare migliaia o addirittura miliardi di oggetti. Di conseguenza, quando si esegue un’operazione di List, l’archiviazione di oggetti può solo ricercare all’interno di questo indice, portando a prestazioni significativamente inferiori rispetto a strutture ad albero.
Svantaggio #2: Mancanza di Capacità di Rinomina Atomica, Influenzando Prestazioni e Stabilità dei Compiti
Nei modelli di calcolo di estrazione, trasformazione, caricamento (ETL), ogni sottotask scrive i suoi risultati in una directory temporanea. Quando l’intero compito è completato, la directory temporanea può essere rinominata nella directory finale.
Queste operazioni di Rename sono atomiche e veloci nei sistemi di file come HDFS, e garantiscono transazioni. Tuttavia, poiché l’object storage non ha una struttura di directory nativa, gestire un’operazione di Rename è un processo simulato che comporta una considerevole quantità di copia interna dei dati. Questo processo può essere dispendioso in termini di tempo e non fornisce garanzie transazionali.
Quando gli utenti impiegano l’object storage, utilizzano comunemente il formato di percorso da sistemi di file tradizionali come chiave per gli oggetti, come “/order/2-22/8/10/detail”. Durante un’operazione di Rename, diventa necessario cercare tutti gli oggetti la cui chiave contiene il nome della directory e copiare tutti gli oggetti utilizzando il nuovo nome della directory come chiave. Questo processo comporta la copia dei dati, portando a prestazioni significativamente inferiori rispetto ai sistemi di file, potenzialmente più lente di uno o due ordini di grandezza.
Inoltre, a causa della mancanza di garanzie transazionali, c’è un rischio di fallimento durante il processo, con conseguente dati errati. Queste differenze apparentemente minori hanno implicazioni per le prestazioni e la stabilità dell’intera pipeline di task.
Svantaggio #3: Il Meccanismo di Consistenza Eventuale Influisce sulla Correttezza dei Dati e sulla Stabilità dei Task
Ad esempio, quando più client creano file contemporaneamente sotto un percorso, l’elenco dei file ottenuto tramite l’API List potrebbe non includere immediatamente tutti i file creati. Ci vuole tempo perché i sistemi interni dell’object storage raggiungano la consistenza dei dati. Questo pattern di accesso è comunemente utilizzato nel processo di ETL dei dati, e la consistenza eventuale può influire sulla correttezza dei dati e sulla stabilità dei task.
Per affrontare il problema dell’impossibilità di mantenere una forte coerenza dei dati nel storage di oggetti, AWS ha rilasciato un prodotto chiamato EMRFS. La sua strategia consiste nell’utilizzare un database DynamoDB aggiuntivo. Ad esempio, quando Spark scrive un file, scrive anche simultaneamente una copia dell’elenco dei file in DynamoDB. Viene poi stabilito un meccanismo per chiamare in modo continuo l’API List del storage di oggetti e confrontare i risultati ottenuti con quelli memorizzati nel database fino a quando non sono identici, momento in cui i risultati vengono restituiti. Tuttavia, la stabilità di questo meccanismo non è sufficientemente buona poiché può essere influenzata dalla congestione della regione in cui si trova il storage di oggetti, risultando in prestazioni variabili. Pertanto, non è una soluzione ideale.
Svantaggio #4: Compatibilità limitata con componenti Hadoop
HDFS era la scelta primaria di storage nei primi stadi dell’ecosistema Hadoop, e vari componenti sono stati sviluppati sulla base dell’API HDFS. L’introduzione del storage di oggetti ha portato a cambiamenti nella struttura di storage dei dati e nelle API.
I provider di cloud devono modificare i connettori tra i componenti e il cloud storage di oggetti, nonché apportare patch ai componenti di livello superiore per garantire la compatibilità. Questa attività pone un carico significativo sui provider di cloud pubblici.
Di conseguenza, il numero di componenti di calcolo supportati nelle piattaforme di big data offerte dai provider di cloud pubblici è limitato, in genere includendo solo poche versioni di Spark, Hive e Presto. Questa limitazione presenta sfide per il trasferimento di piattaforme di big data nel cloud o per gli utenti con requisiti specifici per la propria distribuzione e componenti.
Per sfruttare le prestazioni potenti dello storage di oggetti pur preservando la solidità dei sistemi di file, le aziende possono utilizzare lo storage di oggetti + JuiceFS.
Object Storage + JuiceFS
Quando gli utenti desiderano eseguire calcoli, analisi e addestramento dei dati complessi sullo storage di oggetti, quest’ultimo da solo potrebbe non soddisfare adeguatamente i requisiti delle aziende. Questa è una motivazione chiave alla base dello sviluppo di JuiceFS da parte di Juicedata, che mira a colmare le limitazioni dello storage di oggetti.
JuiceFS è un file system distribuito ad alte prestazioni open-source progettato per la cloud. Insieme allo storage di oggetti, JuiceFS fornisce soluzioni convenienti per scenari intensivi di daticome calcolo, analisi e addestramento.
Come Funziona JuiceFS + Object Storage
Il diagramma seguente mostra la distribuzione di JuiceFS all’interno di un cluster Hadoop.
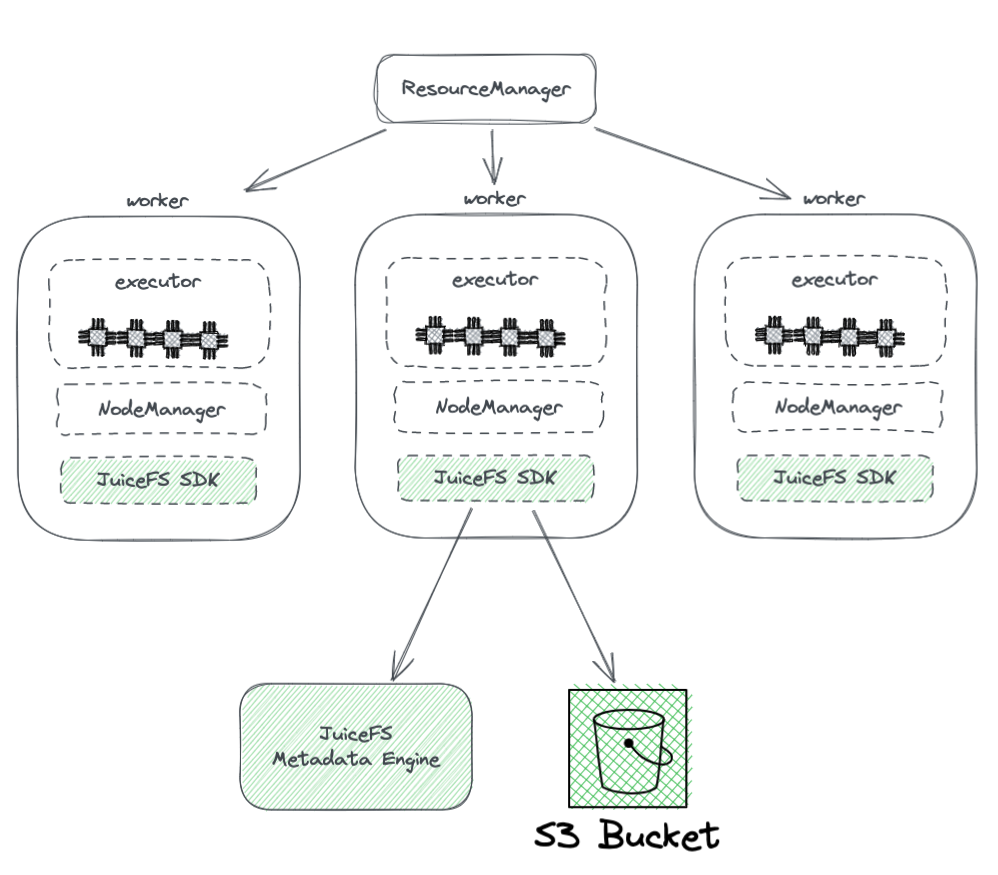
Dal diagramma, possiamo osservare quanto segue:
- Tutti i nodi lavorativi gestiti da YARN montano un JuiceFS Hadoop SDK, che può garantire la piena compatibilità con HDFS.
- L’SDK accede a due componenti:
-
Motore dei Metadati JuiceFS: Il motore dei metadati funge da controparte al NameNode di HDFS. Memorizza le informazioni dei metadati dell’intero file system, inclusi conteggi di directory, nomi di file, permessi e timestamp, e risolve le sfide di scalabilità e GC affrontate dal NameNode di HDFS.
-
Bucket S3: I dati sono memorizzati all’interno del bucket S3, che può essere visto come analogo al DataNode di HDFS. Può essere utilizzato come una grande quantità di dischi, gestendo le attività di archiviazione e replica dei dati.
-
-
JuiceFS è composto da tre componenti:
- JuiceFS Hadoop SDK
- Motore dei Metadati
- Bucket S3
Vantaggi di Juicefs rispetto all’uso diretto di storage di oggetti
JuiceFS offre diversi vantaggi rispetto all’uso diretto di storage di oggetti:
- Piena compatibilità con HDFS: Questo è reso possibile dalla progettazione iniziale di JuiceFS per supportare completamente POSIX. L’API POSIX ha una copertura e una complessità maggiori rispetto a HDFS.
- Possibilità di utilizzo con HDFS e storage di oggetti esistenti: Grazie alla progettazione del sistema Hadoop, JuiceFS può essere utilizzato insieme a sistemi di HDFS e storage di oggetti esistenti senza la necessità di un completo rimpiazzo. In un cluster Hadoop, è possibile configurare più sistemi di file, permettendo a JuiceFS e HDFS di coesistere e collaborare. Questa architettura elimina la necessità di un completo rimpiazzo dei cluster HDFS esistenti, che comporterebbe uno sforzo e rischi significativi. Gli utenti possono gradualmente integrare JuiceFS in base alle loro esigenze di applicazione e situazioni del cluster.
- Prestazioni potenti per i metadati: JuiceFS separa l’engine per i metadati da S3 e non dipende più dalle prestazioni dei metadati di S3. Ciò garantisce prestazioni ottimali per i metadati. Quando si utilizza JuiceFS, le interazioni con il storage di oggetti sottostante si semplificano a operazioni basilari come Get, Put e Delete. Questa architettura supera i limiti di prestazioni dei metadati del storage di oggetti e elimina problemi legati alla coerenza finale.
- Supporto per Rinominazione Atomica: JuiceFS supporta operazioni di Rinominazione Atomica grazie al suo motore di metadati indipendente. La cache migliora le prestazioni di accesso dei dati caldi e offre la funzionalità di località dei dati: con la cache, i dati caldi non devono più essere recuperati dallo storage di oggetti attraverso la rete ogni volta. Inoltre, JuiceFS implementa l’API specifica di HDFS per la località dei dati, in modo che tutti i componenti di livello superiore che supportano la località dei dati possano riconquistare la consapevolezza dell’affinità dei dati. Ciò consente a YARN di dare la priorità alla pianificazione delle attività sui nodi in cui è stato stabilito il caching, ottenendo prestazioni complessive paragonabili a quelle di HDFS con storage e calcolo accoppiati.
- JuiceFS è compatibile con POSIX, rendendo facile l’integrazione con applicazioni relative all’apprendimento automatico e all’IA.
Conclusione
Con l’evoluzione dei requisiti delle aziende e i progressi tecnologici, l’architettura di storage e calcolo è passata da un modello di accoppiamenti a uno di separazione.
Esistono diverse modalità per ottenere la separazione di storage e calcolo, ciascuna con i propri vantaggi e svantaggi. Questi spaziano dall’implementazione di HDFS nel cloud all’utilizzo di soluzioni di cloud pubblico compatibili con Hadoop e persino all’adozione di soluzioni come lo storage di oggetti + JuiceFS, adatte per la computazione e lo storage di grandi quantità di dati complessi nel cloud.
Per le aziende, non esiste una soluzione universale, e il punto chiave è selezionare l’architettura in base alle proprie esigenze specifiche. Tuttavia, indipendentemente dalla scelta, la semplicità è sempre una scelta sicura.
Informazioni sull’Autore
Rui Su, partner di Juicedata, è stato un membro fondatore coinvolto nello sviluppo completo del prodotto JuiceFS, del mercato e della community open source dal 2017. Con 16 anni di esperienza nell’industria, ha ricoperto ruoli come R&D, product manager e fondatore in software, internet e organizzazioni non governative.
Source:
https://dzone.com/articles/from-hadoop-to-cloud-why-and-how-to-decouple-stora