













Cos’è Elasticsearch?
Elasticsearch è un motore di ricerca e analisi distribuito e open-source costruito sulla libreria Apache Lucene. Elasticsearch offre anche ricerca vettoriale e generazione aumentata da recupero (RAG), supportando senza soluzione di continuità le moderne applicazioni di intelligenza artificiale. Le applicazioni possono memorizzare dati strutturati e non strutturati in Elasticsearch, con o senza uno schema definito, inviando payload JSON a un cluster Elasticsearch.
Architettura di Elasticsearch
Fin dal principio, i principali componenti di un cluster Elasticsearch sono:
Documento
Un documento è il più piccolo record di informazioni memorizzato da Elasticsearch ed è rappresentato come JSON. Un documento consiste di più campi (coppie chiave-valore) di diversi tipi e può avere uno schema predefinito o essere privo di schema, inferendo i tipi di dati di eventuali nuovi campi che vengono indicizzati.
Indice
Un indice è una collezione logica di documenti con lo stesso schema, identificata da un nome di indice.
Shard
Gli indici di Elasticsearch sono suddivisi in unità gestibili chiamate shard, che sono una collezione di documenti. Gli shard sono l’unità base di ricerca e sono replicati su più nodi per ridondanza e tolleranza ai guasti.
Nodo
Un nodo è un’istanza indipendente di Elasticsearch e gestisce una collezione di shard che appartengono a uno o più indici. I nodi possono avere diversi ruoli come nodo dati, nodo master e nodo ingest.
Cluster
Un cluster Elasticsearch è una collezione di nodi interconnessi. Tutti i nodi in un cluster possono gestire richieste dai client e comunicare tra loro. Ogni nodo in un cluster possiede un sottoinsieme degli shard che appartengono a un indice.
Architettura della Query
Il seguente diagramma architettonico delinea il flusso di una richiesta di ricerca:

- L’utente o l’applicazione effettua una query di ricerca. La query può essere gestita da qualsiasi nodo nel cluster. Il nodo che gestisce la richiesta è il nodo “coordinatore”.
- Il nodo coordinatore trasmette la query a tutti gli shard coinvolti e alle loro repliche.
- Ogni shard esegue la query localmente e restituisce un insieme leggero di risultati al nodo coordinatore.
- Il nodo coordinatore unisce i risultati che riceve. Questa è la fine della fase di “query”. La fase di query identifica i documenti essenziali che formano il risultato della ricerca, ma il documento completo deve ancora essere recuperato.
- Il nodo coordinatore invia richieste di recupero agli shard proprietari, che arricchiscono i documenti nell’insieme dei risultati.
- I documenti arricchiti vengono restituiti al nodo coordinatore.
- Il set completo dei risultati della ricerca, classificato e arricchito, viene restituito al chiamante.
Architettura dell’indicizzazione
Il seguente diagramma architettonico illustra il flusso di una richiesta di indicizzazione:
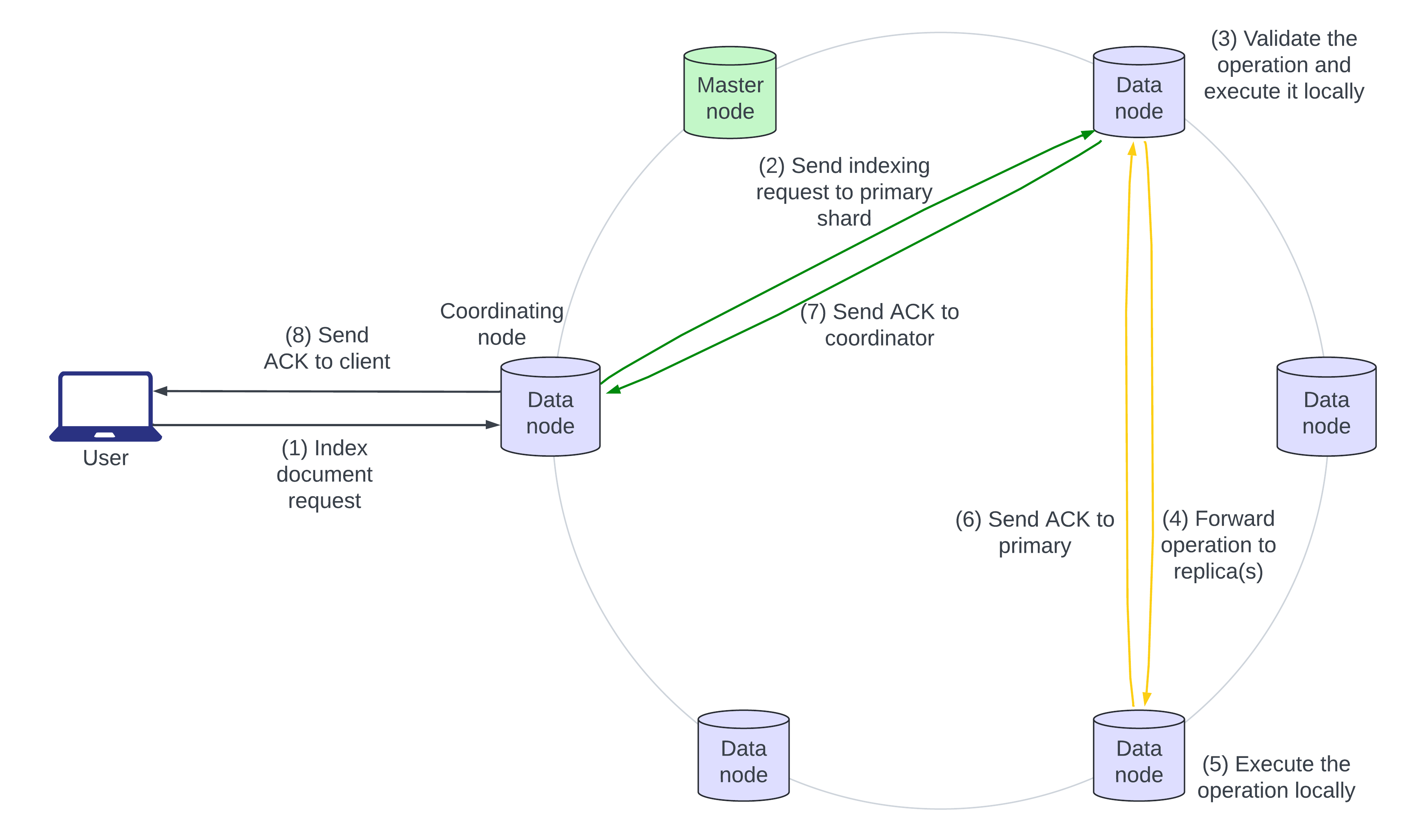
- L’utente invia un documento JSON da indicizzare a Elasticsearch. Se il documento esiste già, vengono aggiunti nuovi campi e i campi esistenti vengono sovrascritti. Il nodo che riceve per primo la richiesta è il nodo “coordinatore”.
- Il nodo coordinatore identifica lo shard primario del documento in ingresso, di solito in base all’ID del documento, e inoltra la richiesta al nodo dati che possiede lo shard primario.
- Lo shard primario convalida l’operazione ed esegue localmente.
- Lo shard primario inoltra quindi l’operazione a tutte le sue repliche in parallelo.
- Le repliche degli shard applicano l’operazione localmente sui rispettivi nodi.
- I passaggi 6, 7 e 8 mostrano l’approvazione della scrittura che risale dalle repliche degli shard allo shard primario, al nodo coordinatore e al chiamante.
Conclusione
Questo articolo descrive i diversi componenti di un cluster Elasticsearch: documenti, indici, shard e nodi. Illustra anche la durata di una richiesta di ricerca e di una richiesta di indicizzazione. La sua architettura flessibile rende facile aggiungere e rimuovere nodi man mano che il cluster cresce. Combinato con funzionalità come l’indicizzazione senza schema e il supporto per le funzionalità di ricerca AI, questo rende Elasticsearch lo standard de facto per le organizzazioni che necessitano di archiviare, cercare e analizzare in modo efficiente grandi volumi di dati in tempo reale.
Source:
https://dzone.com/articles/elasticsearch-query-and-indexing-architecture