













Il database sharding è il processo di suddivisione dei dati in parti più piccole chiamate “shard”. Sharding viene generalmente introdotto quando c’è necessità di scalare le scritture. Durante la vita di un’applicazione di successo, il server del database raggiungerà il numero massimo di scritture che può eseguire a livello di elaborazione o di capacità. Dividendo i dati in più shard, ciascuno su un proprio server di database, si riduce lo stress su ciascun nodo individuale, aumentando efficacemente la capacità di scrittura dell’intero database. Questo è ciò che è il database sharding.
SQL distribuito è il nuovo modo di scalare i database relazionali con una strategia simile allo sharding che è completamente automatizzata e trasparente per le applicazioni. I database SQL distribuiti sono progettati fin dall’inizio per scalare quasi in modo lineare. In questo articolo, imparerai le basi di SQL distribuito e come iniziare.
Svantaggi dello Sharding del Database
Lo sharding introduce una serie di sfide:
- Partizionamento dei dati: Decidere come partizionare i dati tra più shard può essere una sfida, poiché richiede di trovare un equilibrio tra vicinanza dei dati e distribuzione uniforme dei dati per evitare hotspots.
- Gestione dei fallimenti: Se un nodo chiave fallisce e non ci sono abbastanza shard per sostenere il carico, come si fa a ottenere i dati su un nuovo nodo senza tempi di inattività?
- Complessità delle query: Il codice dell’applicazione è connesso alla logica di partizionamento dei dati e le query che richiedono dati da più nodi devono essere riconciliate.
- Coerenza dei dati: Garantire la coerenza dei dati attraverso più shard può essere una sfida, poiché richiede la coordinazione degli aggiornamenti dei dati attraverso i shard. Questo può essere particolarmente difficile quando gli aggiornamenti vengono effettuati contemporaneamente, poiché potrebbe essere necessario risolvere i conflitti tra diverse scritture.
- Scalabilità elastica: All’aumentare del volume dei dati o del numero di query, potrebbe essere necessario aggiungere ulteriori shard al database. Questo può essere un processo complesso con tempi di inattività inevitabili, che richiede processi manuali per spostare i dati in modo uniforme attraverso tutti gli shard.
Alcuni di questi svantaggi possono essere alleviati adottando la persistenza poliglota (usando database diversi per diversi carichi di lavoro), motori di archiviazione di database con capacità di partizionamento nativo o proxy di database. Tuttavia, mentre aiutano con alcune delle sfide nella partizionamento dei database, questi strumenti hanno limitazioni e introducono complessità che richiede una gestione costante.
Che cos’è SQL Distribuito?
Distributed SQL si riferisce a una nuova generazione di database relazionali. In termini semplici, un database SQL distribuito è un database relazionale con suddivisione trasparente che appare come un unico database logico agli applicazioni. I database SQL distribuiti sono implementati come un’architettura senza condivisione e un motore di archiviazione che scala sia le letture che le scritture mantenendo la vera conformità ACID e alta disponibilità. I database SQL distribuiti hanno le funzionalità di scalabilità dei database NoSQL—che hanno guadagnato popolarità negli anni 2000—ma non sacrificano la coerenza. Mantengono i vantaggi dei database relazionali e aggiungono compatibilità con il cloud con resilienza multi-regione.
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
Come Funziona il Distributed SQL?
Per capire come funziona il Distributed SQL, prendiamo come esempio MariaDB Xpand—un database SQL distribuito compatibile con il database open-source MariaDB. Xpand opera dividendo i dati e gli indici tra i nodi e eseguendo automaticamente compiti come il riequilibrio dei dati e l’esecuzione di query distribuite. Le query vengono eseguite in parallelo per ridurre al minimo il ritardo. I dati vengono replicati automaticamente per assicurarsi che non ci sia un unico punto di guasto. Quando un nodo fallisce, Xpand riequilibra i dati tra i nodi sopravvissuti. La stessa cosa accade quando viene aggiunto un nuovo nodo. Un componente chiamato rebalancer garantisce che non ci siano hotspots—una sfida con lo sharding manuale del database—che si verifica quando un nodo deve gestire in modo sbilanciato troppi transazioni rispetto ad altri nodi che potrebbero rimanere inattivi a volte.
Studiamo un esempio. Supponiamo di avere un’istanza di database con some_table e un certo numero di righe:
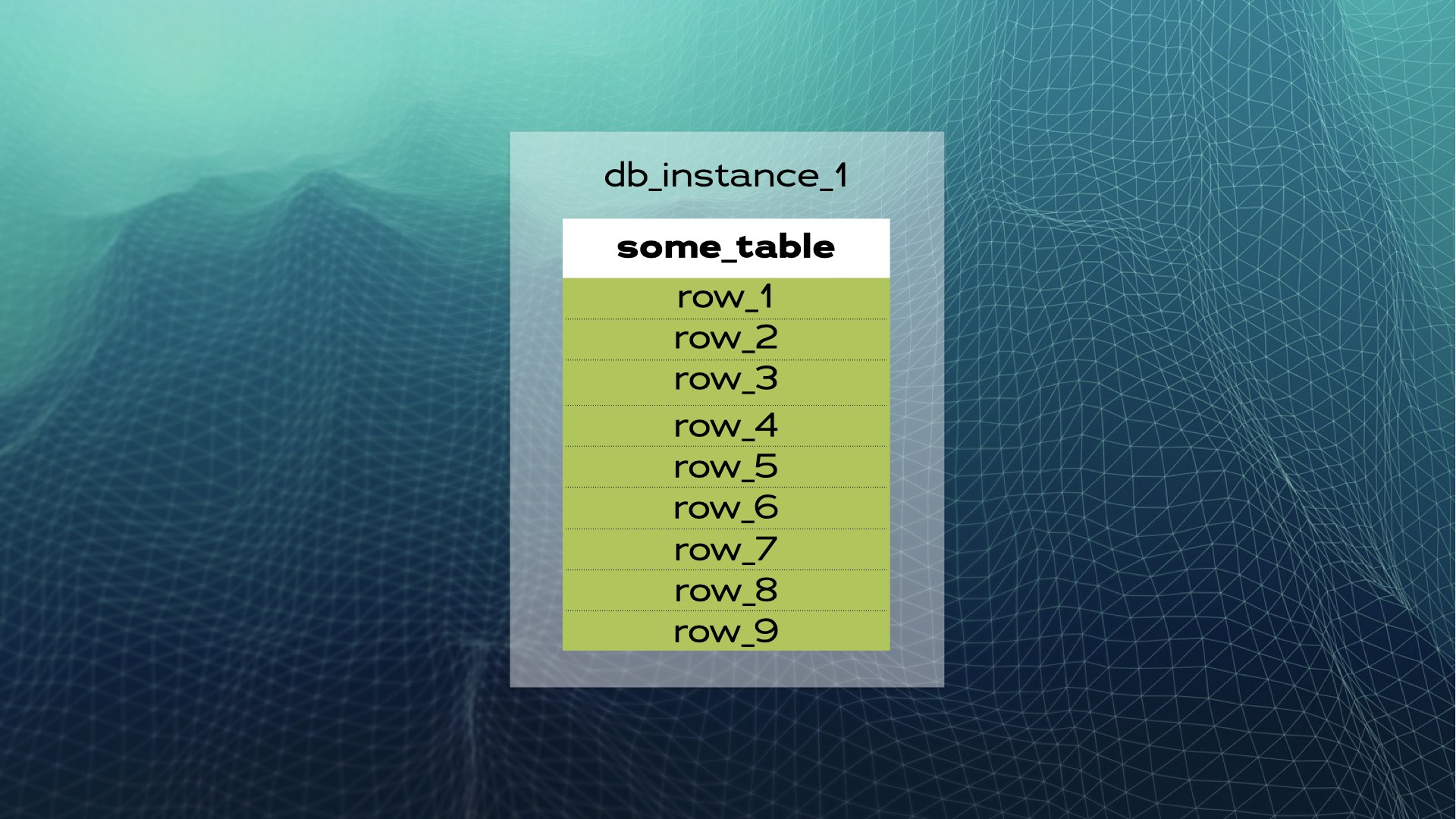
Possiamo dividere i dati in tre parti (shard):

E poi spostare ogni pezzo di dati in un’istanza di database separata:
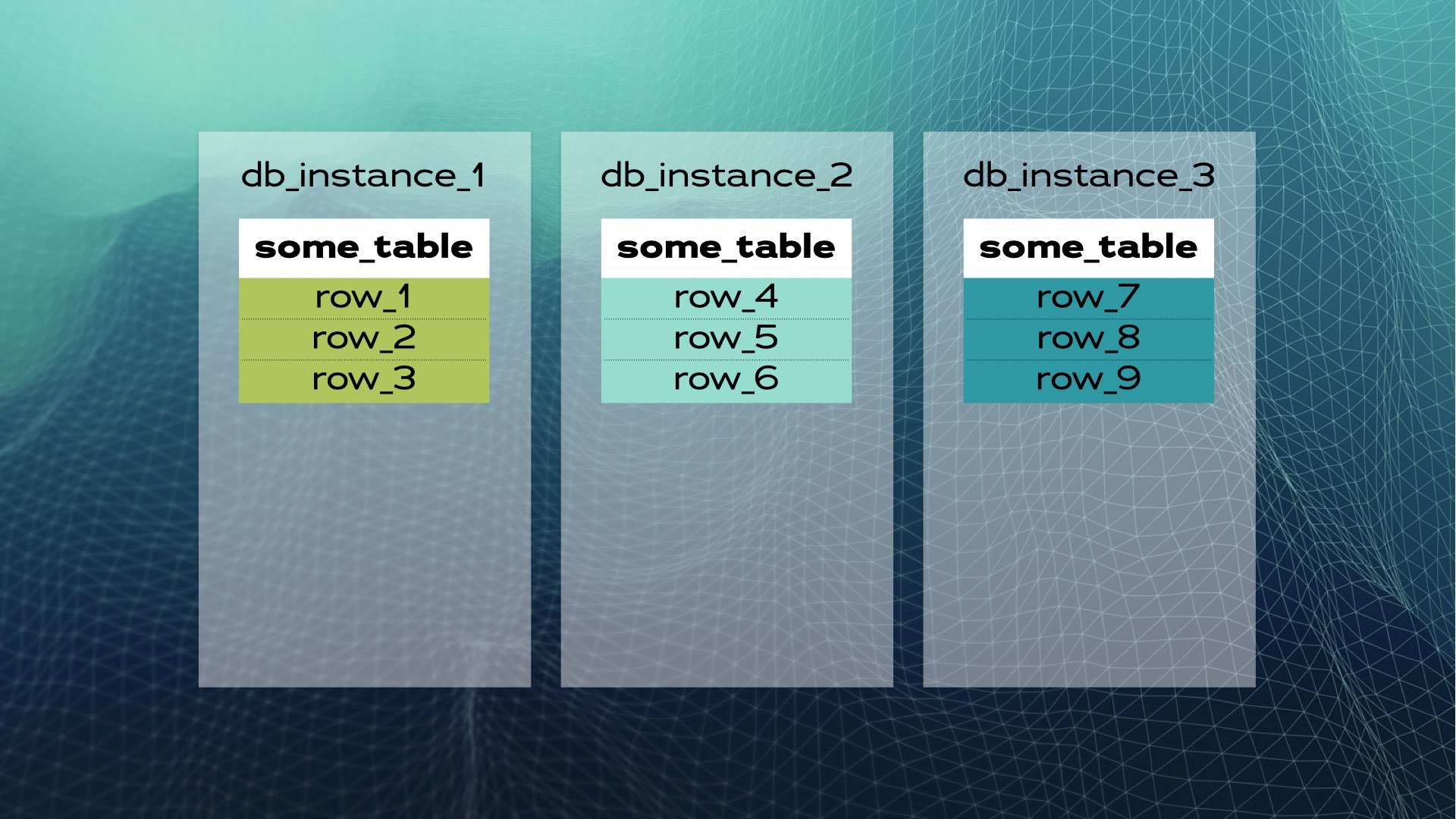
Ecco come appare il condivisione manuale di database. Il SQL distribuito lo fa automaticamente per te. Nel caso di Xpand, ogni shard è chiamato una fetta. Le righe vengono tagliate utilizzando un hash di un sottoinsieme delle colonne della tabella. Non solo i dati vengono tagliati, ma anche gli indici vengono tagliati e distribuiti tra i nodi (istanze di database). Inoltre, per mantenere l’alta disponibilità, le fette vengono replicate in altri nodi (il numero di repliche per nodo è configurabile). Ciò avviene automaticamente:
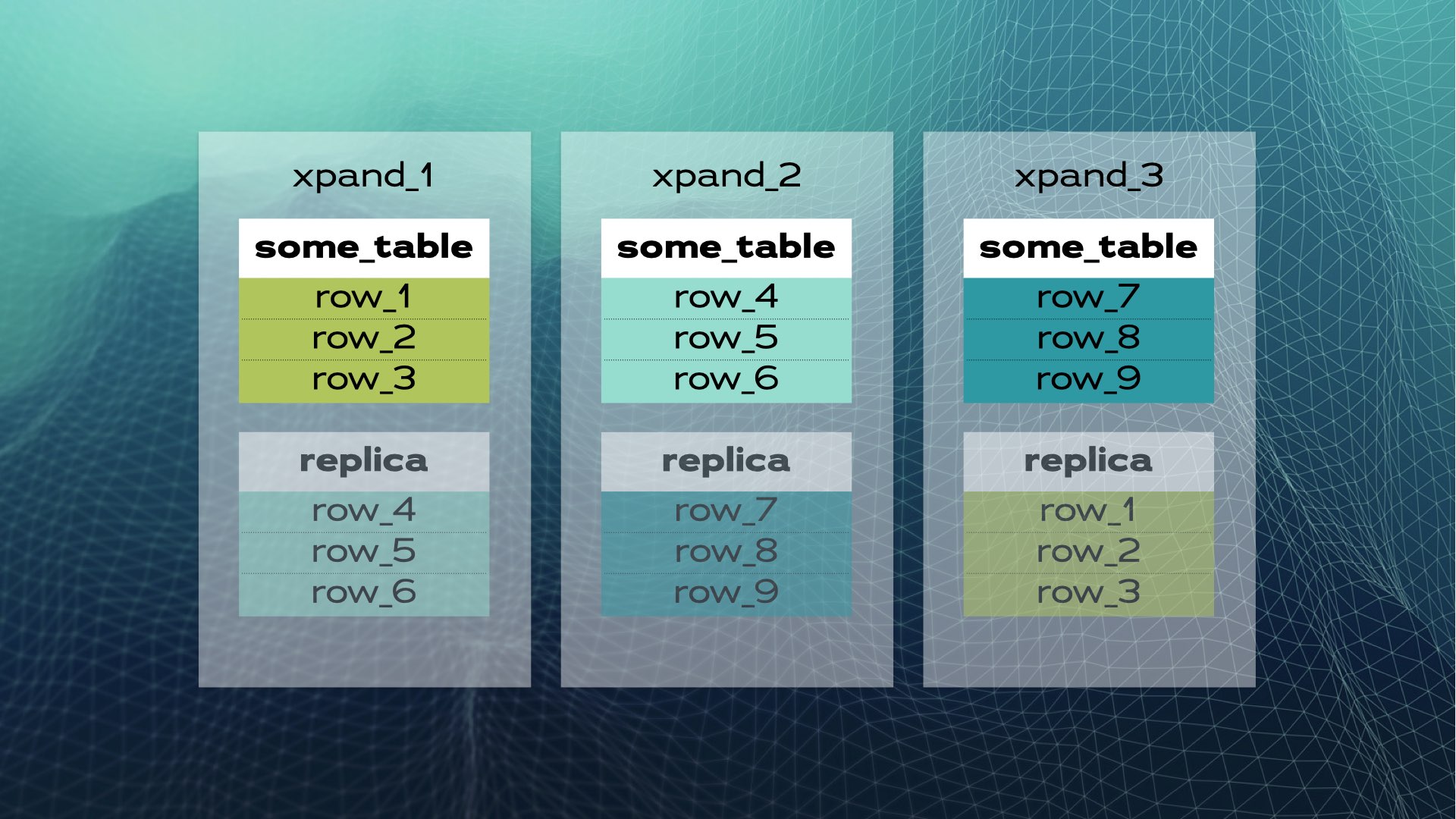
Quando un nuovo nodo viene aggiunto al cluster o quando un nodo non riesce, Xpand riequilibra automaticamente i dati senza la necessità di intervento manuale. Ecco cosa succede quando viene aggiunto un nodo al cluster precedente:

Alcune righe vengono spostate sul nuovo nodo per aumentare la capacità complessiva del sistema. Tieni presente che, sebbene non mostrato nel diagramma, anche gli indici e le repliche vengono spostati e aggiornati di conseguenza. Una visione leggermente più completa (con uno spostamento leggermente diverso dei dati) del cluster precedente è mostrata in questo diagramma:
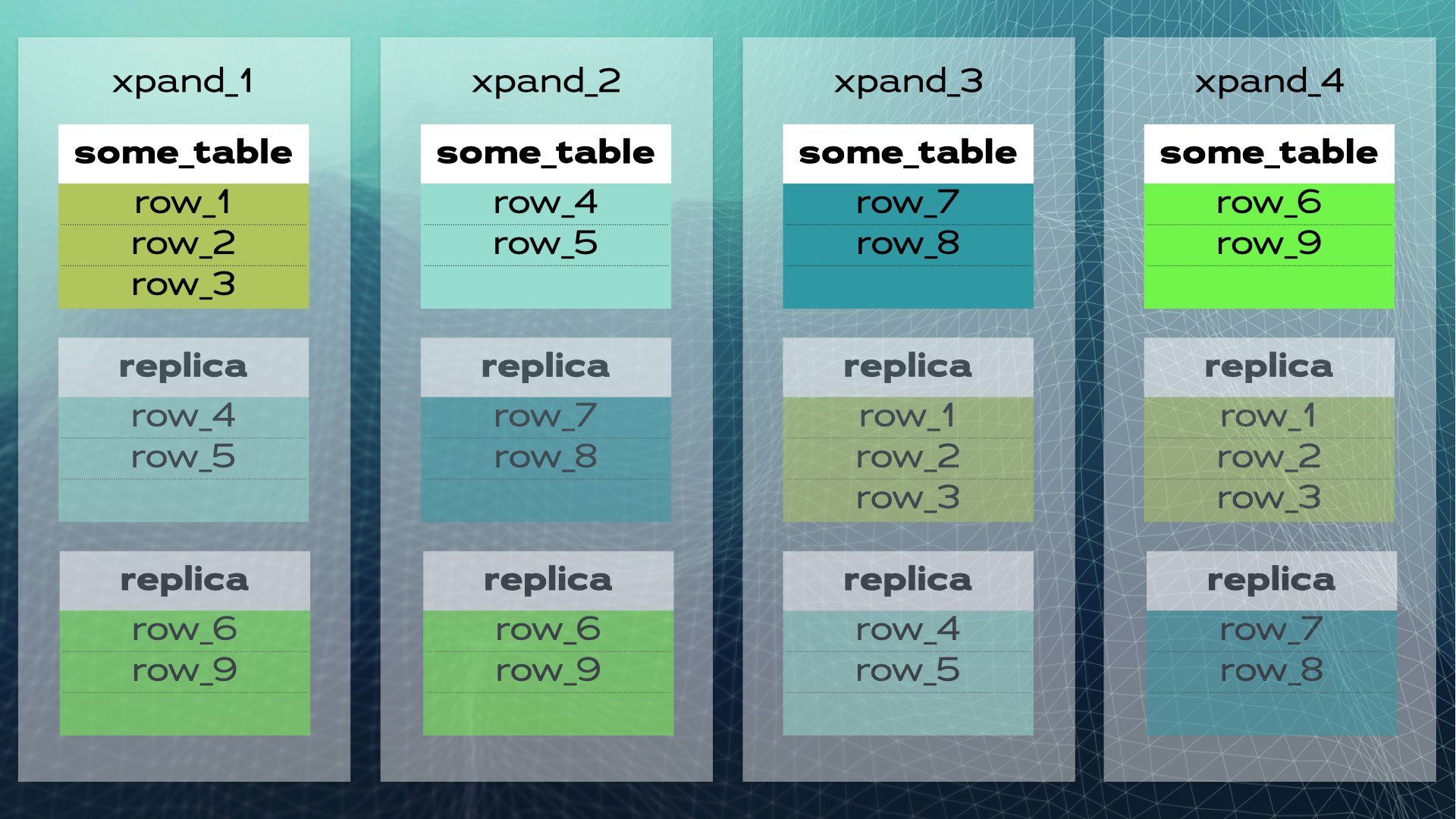
Questa architettura consente una scalabilità quasi lineare. Non è necessario alcun intervento manuale a livello di applicazione. All’applicazione, il cluster sembra un unico database logico. L’applicazione si connette semplicemente al database tramite un load balancer (MariaDB MaxScale):
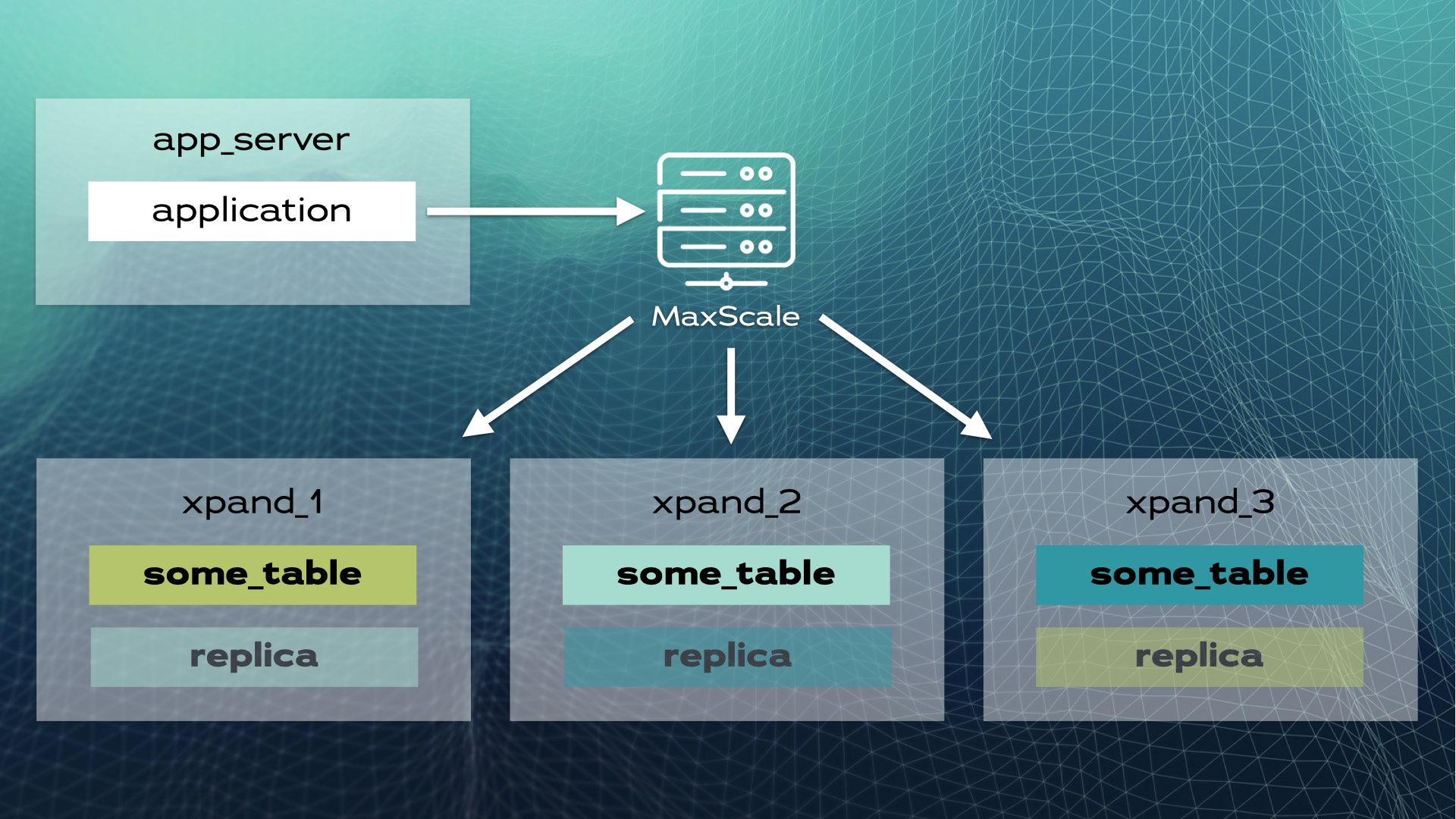
Quando l’applicazione invia un’operazione di scrittura (ad esempio, INSERT o UPDATE), viene calcolato l’hash e inviato alla fetta corretta. Più scritture vengono inviate in parallelo a più nodi.
Quando Non Usare SQL Distribuito
Lo shard di un database migliora le prestazioni ma introduce anche ulteriori sovraccarichi a livello di comunicazione tra i nodi. Ciò può portare a prestazioni più lente se il database non è configurato correttamente o se il router delle query non è ottimizzato. SQL distribuito potrebbe non essere l’alternativa migliore per applicazioni con meno di 10K query al secondo o 5K transazioni al secondo. Inoltre, se il tuo database è costituito principalmente da molte piccole tabelle, allora un database monolitico potrebbe funzionare meglio.
Iniziare con SQL Distribuito
Poiché un database SQL distribuito appare ad un’applicazione come se fosse un unico database logico, iniziare è semplice. Tutto ciò di cui hai bisogno è il seguente:
- Un client SQL come DBeaver, DbGate, DataGrip, o qualsiasi estensione client SQL per il tuo IDE
- A distributed SQL database
Docker rende la seconda parte facile. Ad esempio, MariaDB pubblica l’immagine Docker mariadb/xpand-single che ti permette di avviare un database Xpand a nodo singolo per valutazione, test e sviluppo.
Per avviare un contenitore Xpand, esegui il seguente comando:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"Consulta l’immagine Docker documentazione per ulteriori dettagli.
Nota: Al momento della stesura di questo articolo, l’immagine Docker mariadb/xpand-single non è disponibile per le architetture ARM. Su queste architetture (ad esempio macchine Apple con processori M1), utilizza UTM per creare una macchina virtuale (VM) e installare, ad esempio, Debian. Assegna un nome host e usa SSH per connetterti alla VM per installare Docker e creare il contenitore MariaDB Xpand.
Connessione al Database
Connettersi a un database Xpand è lo stesso che connettersi a un server MariaDB Community o Enterprise. Se hai installato lo strumento CLI mariadb, esegui semplicemente quanto segue:
mariadb -h 127.0.0.1 -u user -pPuoi connetterti al database utilizzando un’interfaccia grafica per database SQL come DBeaver, DataGrip o un’estensione SQL per il tuo IDE (come questa per VS Code). Utilizzeremo un client SQL gratuito e open source chiamato DbGate. Puoi scaricare DbGate e eseguirlo come applicazione desktop o, dato che stai utilizzando Docker, puoi implementarlo come applicazione web che puoi accedere da qualsiasi posto tramite un browser web (simile al popolare phpMyAdmin). Basta eseguire il seguente comando:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgateUna volta avviato il container, dirigi il tuo browser a http://localhost:3000/. Compila i dettagli di connessione:
Fai clic su Test e conferma che la connessione ha successo:

Fai clic su Salva e crea un nuovo database facendo clic destro sulla connessione nel pannello a sinistra e selezionando Crea database. Prova a creare tabelle o importare uno script SQL. Se vuoi solo provare qualcosa, Nation o Sakila sono buoni database di esempio.
Connessione da Java, JavaScript, Python e C++
Per connettersi a Xpand dalle applicazioni, puoi utilizzare i Connettori MariaDB. Sono possibili molte combinazioni di linguaggi di programmazione e framework di persistenza. Trattare questo argomento esula dallo scopo di questo articolo, ma se vuoi semplicemente iniziare e vedere qualcosa in azione, dai un’occhiata a questa pagina di avvio rapido con esempi di codice per Java, JavaScript, Python e C++.
Il vero potenziale del SQL distribuito
In questo articolo, abbiamo imparato come avviare un singolo nodo Xpand per scopi di sviluppo e test, a differenza delle attività di produzione. Tuttavia, il vero potenziale di un database SQL distribuito risiede nella sua capacità di scalare non solo le letture (come nello shard classico dei database) ma anche le scritture semplicemente aggiungendo più nodi e lasciando che il riequilibratore sposti in modo ottimale i dati. Anche se è possibile distribuire Xpand in una topologia multi-nodo, il modo più semplice per utilizzarlo in produzione è attraverso SkySQL.
Se vuoi saperne di più sul SQL distribuito e su MariaDB Xpand, ecco un elenco di risorse utili:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding