













In Parte 1 di questa serie, abbiamo esaminato MongoDB, una delle basi di dati document-oriented NoSQL più affidabili e robuste. Qui nella Parte 2, esploreremo un altro NoSQL database quasi inevitabile: Elasticsearch.
Oltre ad essere una base di dati distribuita open-source popolare e potente, Elasticsearch è prima di tutto un motore di ricerca e analisi. È costruito sulla cima di Apache Lucene, la più celebre libreria di motori di ricerca in Java, e può eseguire operazioni di ricerca e analisi in tempo reale su dati strutturati e non strutturati. È progettato per gestire efficientemente grandi quantità di dati.
Ancora una volta, dobbiamo precisare che questo breve post non è affatto un tutorial su Elasticsearch. Di conseguenza, il lettore è fortemente incoraggiato a utilizzare ampiamente la documentazione ufficiale, nonché l’eccellente libro, “Elasticsearch in Action” di Madhusudhan Konda (Manning, 2023) per imparare di più sull’architettura e le operazioni del prodotto. Qui, stiamo solo reimplementando lo stesso caso d’uso come prima, ma questa volta utilizzando Elasticsearch invece di MongoDB.
Allora, eccoci qua!
Il Modello del Dominio
Il diagramma qui sotto mostra il nostro modello del dominio *customer-order-product*:
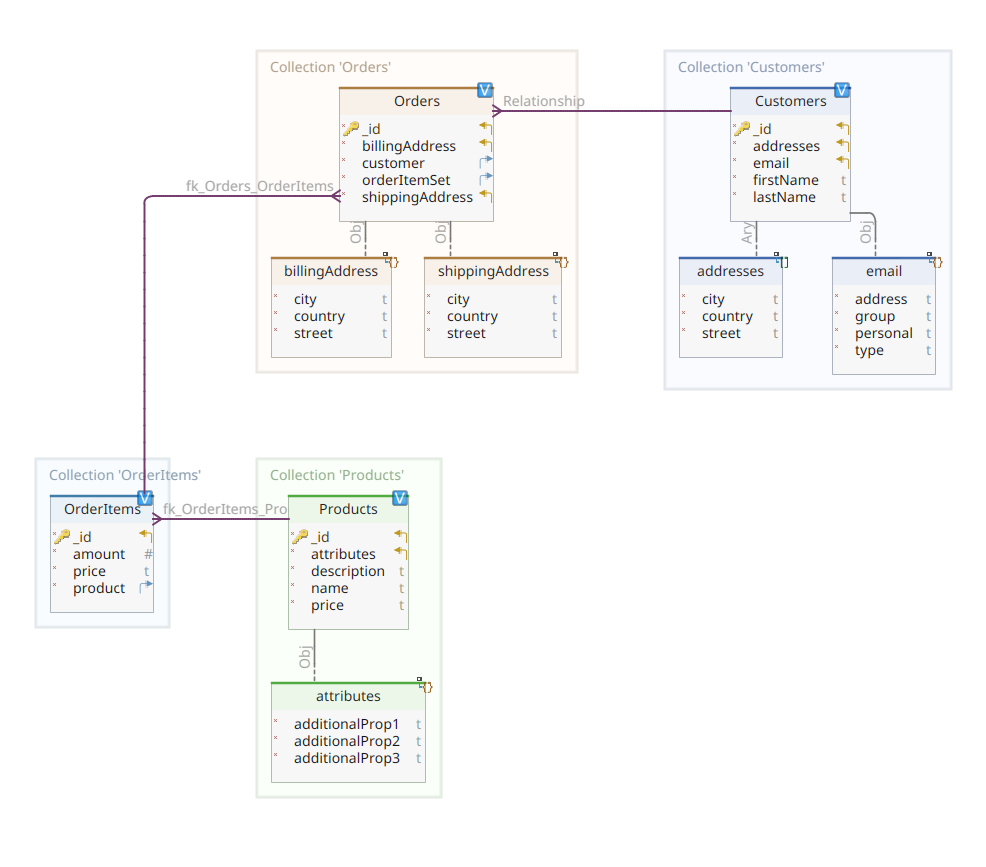
Questo diagramma è lo stesso presentato nella Parte 1. Come MongoDB, anche Elasticsearch è un deposito di dati documentali e, come tale, si aspetta che i documenti siano presentati in JSON. L’unica differenza è che per gestire i suoi dati, Elasticsearch ha bisogno di farli indicizzare.
Esistono diversi modi in cui i dati possono essere indicizzati in un deposito di dati Elasticsearch; per esempio, convogliarli da un database relazionale, estrarli da un filesystem, trasmetterli in streaming da una fonte in tempo reale, ecc. Ma qualunque sia il metodo di ingestione, alla fine si riduce a chiamare l’API RESTful di Elasticsearch tramite un client dedicato. Ci sono due categorie di tali client dedicati:
- client basati su REST come
curl,Postman, moduli HTTP per Java, JavaScript, Node.js, ecc. - SDK delle lingue di programmazione (Software Development Kit): Elasticsearch fornisce SDK per tutte le lingue di programmazione più utilizzate, inclusi ma non limitati a Java, Python, ecc.
Indicizzare un nuovo documento con Elasticsearch significa crearlo utilizzando una richiesta POST contro un endpoint RESTful speciale chiamato _doc. Per esempio, la seguente richiesta creerà un nuovo indice Elasticsearch e archivierà una nuova istanza cliente in esso.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Eseguire la richiesta sopra con curl o la console Kibana (come vedremo più tardi) produrrà il seguente risultato:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Questa è la risposta standard di Elasticsearch a una richiesta POST. Conferma aver creato l’indice chiamato customers, avente un nuovo documento customer, identificato da un ID generato automaticamente (in questo caso, ZEQsJI4BbwDzNcFB0ubC).
Altri parametri interessanti appaiono qui, come _version e specialmente _shards. Senza entrare troppo nei dettagli, Elasticsearch crea indici come raccolte logiche di documenti. Proprio come conservare documenti cartacei in un armadio, Elasticsearch tiene i documenti in un indice. Ogni indice è composto da shards, che sono istanze fisiche di Apache Lucene, il motore dietro le quinte responsabile del recupero dei dati dalla memoria o del loro deposito. Possono essere sia primari, che archiviano i documenti, sia repliche, che, come suggerisce il nome, archiviano copie degli shards primari. Per ulteriori dettagli, consultate la documentazione di Elasticsearch – per ora, dobbiamo notare che il nostro indice chiamato customers è composto da due shards: uno dei quali, ovviamente, è primario.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Per tornare al nostro diagramma del modello del dominio, come potete vedere, il documento centrale è Order, archiviato in una raccolta dedicata chiamata Orders. Un Order è un aggregato di documenti OrderItem, ciascuno dei quali punta al proprio Product associato. Un documento Order fa anche riferimento al Customer che lo ha effettuato. In Java, questo è implementato come segue:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Il codice sopra mostra un frammento della classe Customer. Questo è un semplice POJO (Plain Old Java Object) che ha proprietà come l’ID del cliente, il nome e il cognome, l’indirizzo email e un set di indirizzi postali.
Analizziamo ora il documento Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Qui si possono notare alcune differenze rispetto alla versione MongoDB. Infatti, con MongoDB, stavamo utilizzando un riferimento all’istanza del cliente associata a questo ordine. Questa nozione di riferimento non esiste con Elasticsearch, quindi stiamo utilizzando questo ID di documento per creare un’associazione tra l’ordine e il cliente che l’ha effettuato. Lo stesso vale per la proprietà orderItemSet che crea un’associazione tra l’ordine e i suoi articoli.
Il resto del nostro modello di dominio è piuttosto simile e basato sulle stesse idee di normalizzazione. Ad esempio, il documento OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Qui, dobbiamo associare il prodotto che costituisce l’oggetto dell’attuale articolo dell’ordine. Ultimo ma non meno importante, abbiamo il documento Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}I Repository dei Dati
Quarkus Panache semplifica notevolmente il processo di persistenza dei dati supportando sia il pattern active record che il pattern repository. Nella Parte 1, abbiamo utilizzato l’estensione Quarkus Panache per MongoDB per implementare i nostri repository di dati, ma non esiste ancora un’estensione equivalente di Quarkus Panache per Elasticsearch. Di conseguenza, aspettando una possibile futura estensione di Quarkus per Elasticsearch, qui dobbiamo implementare manualmente i nostri repository di dati utilizzando il client dedicato di Elasticsearch.
Elasticsearch è scritto in Java e, di conseguenza, non sorprende che offra supporto nativo per l’invocazione dell’API di Elasticsearch utilizzando la libreria client Java. Questa libreria è basata sul design pattern di builder di API fluenti e fornisce sia modelli di elaborazione sincrona che asincrona. Richiede almeno Java 8.
Allora, come appariranno i nostri repository di dati basati sul builder di API fluenti? Di seguito è riportato un estratto dalla classe CustomerServiceImpl che funge da repository di dati per il documento Customer.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Come possiamo vedere, la nostra implementazione del repository di dati deve essere un bean CDI con una portata applicativa. Il client Java di Elasticsearch viene semplicemente iniettato, grazie all’estensione quarkus-elasticsearch-java-client di Quarkus. In questo modo, evitiamo molti fronzoli che avremmo dovuto utilizzare altrimenti. L’unica cosa di cui abbiamo bisogno per essere in grado di iniettare il client è dichiarare la seguente proprietà:
quarkus.elasticsearch.hosts = elasticsearch:9200Qui, elasticsearch è il nome DNS (Domain Name Server) che associamo al server di database Elasticsearch nel file docker-compose.yaml. 9200 è il numero di porta TCP utilizzato dal server per ascoltare le connessioni.
Il metodo doIndex() qui sopra crea un nuovo indice chiamato customers se non esiste già e ivi indice (salva) un nuovo documento che rappresenta un’istanza della classe Customer. Il processo di indicizzazione viene eseguito in base a una richiesta di IndexRequest che accetta come argomenti il nome dell’indice e il corpo del documento. Per quanto riguarda l’ID del documento, viene generato automaticamente e restituito al chiamante per ulteriori referenze.
Il seguente metodo permette di recuperare il cliente identificato dall’ID fornito come argomento:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Il principio è lo stesso: utilizzando questo fluent API builder pattern, costruiamo un’istanza di GetRequest in modo simile a come abbiamo fatto con la IndexRequest, e la eseguiamo contro il client Java di Elasticsearch. Gli altri endpoint del nostro repository di dati, che ci permettono di eseguire operazioni di ricerca complete o di aggiornare e eliminare i clienti, sono progettati allo stesso modo.
Prenditi del tempo per guardare il codice per capire come funzionano le cose.
La REST API
La nostra interfaccia API REST per MongoDB è stata semplice da implementare, grazie all’estensione quarkus-mongodb-rest-data-panache, in cui il processore di annotazioni ha generato automaticamente tutti gli endpoint richiesti. Con Elasticsearch, non beneficiamo ancora dello stesso comfort e, pertanto, dobbiamo implementarlo manualmente. Non è un grande problema, poiché possiamo iniettare i repository di dati precedenti, come mostrato di seguito:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Questa è l’implementazione dell’API REST del cliente. Le altre associate a ordini, articoli d’ordine e prodotti sono simili.
Ora vediamo come eseguire e testare l’intero sistema.
Eseguire e Testare i Nostri Microservices
Ora che abbiamo esaminato i dettagli della nostra implementazione, vediamo come eseguirla e testarla. Abbiamo scelto di farlo utilizzando lo strumento docker-compose. Ecco il file associato docker-compose.yml:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Questo file istruisce lo strumento docker-compose a eseguire tre servizi:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Ora, puoi verificare che tutti i processi richiesti siano in esecuzione:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Per confermare che il server Elasticsearch è disponibile e in grado di eseguire query, puoi connetterti a Kibana all’indirizzo http://localhost:601. Dopo aver scrollato verso il basso la pagina e aver selezionato Dev Tools nel menu delle preferenze, puoi eseguire query come mostrato di seguito:
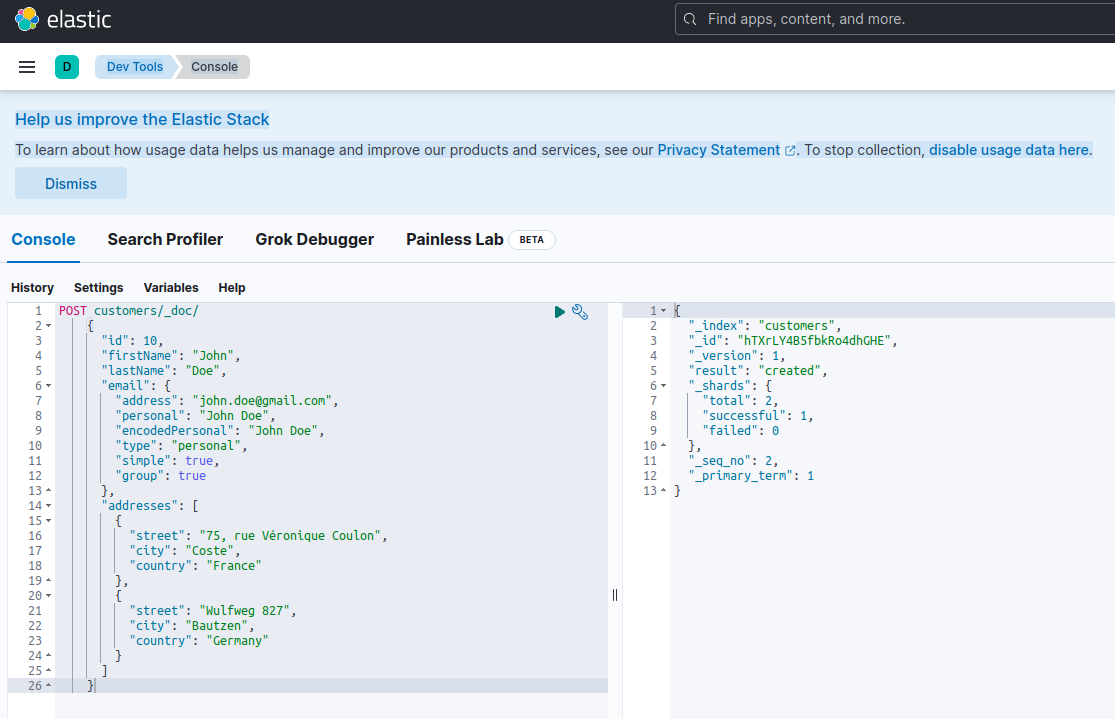
Per testare i microservices, procedi come segue:
1. Clona il repository GitHub associato:
$ git clone https://github.com/nicolasduminil/docstore.git2. Vai al progetto:
$ cd docstore3. Esegui il checkout della branch corretta:
$ git checkout elastic-search4. Compila:
$ mvn clean install5. Esegui i test di integrazione:
$ mvn -DskipTests=false failsafe:integration-testQuesto ultimo comando eseguirà i 17 test di integrazione forniti, che dovrebbero tutti avere esito positivo. Puoi anche utilizzare l’interfaccia Swagger UI per scopi di test aprendo il tuo browser preferito all’indirizzo http://localhost:8080/q:swagger-ui. Per testare le endpoint, puoi utilizzare i payload nei file JSON situati nella directory src/resources/data del progetto docstore-api.
Divertiti!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse