













In questo laboratorio pratico da ScyllaDB University, imparerai come utilizzare il connettore sorgente ScyllaDB CDC per inviare gli eventi di modifica a livello di riga nelle tabelle di un cluster ScyllaDB a un server Kafka.
Che cos’è ScyllaDB CDC?
Per ricapitolare, Change Data Capture (CDC) è una funzionalità che ti permette non solo di interrogare lo stato attuale di una tabella del database, ma anche di interrogare la storia di tutte le modifiche apportate alla tabella. CDC è pronta per la produzione (GA) a partire da ScyllaDB Enterprise 2021.1.1 e ScyllaDB Open Source 4.3.
In ScyllaDB, CDC è facoltativo ed è abilitato a livello di tabella. La storia delle modifiche apportate a una tabella abilitata per CDC è memorizzata in una tabella associata separata.
Puoi abilitare CDC durante la creazione o la modifica di una tabella utilizzando l’opzione CDC, ad esempio:
CREATE TABLE ks.t (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};Connettore sorgente ScyllaDB CDC
Il Connettore Origine CDC di ScyllaDB è un connettore che cattura modifiche a livello di riga nelle tabelle di un cluster ScyllaDB. Si tratta di un connettore Debezium, compatibile con Kafka Connect (con Kafka 2.6.0+). Il connettore legge il log CDC per le tabelle specificate e produce messaggi Kafka per ogni operazione a livello di riga INSERT, UPDATE o DELETE. Il connettore è tollerante ai guasti, riproducendo la lettura dei dati da Scylla in caso di fallimento. Salva periodicamente la posizione corrente nel log CDC di ScyllaDB utilizzando il tracciamento degli offset di Kafka Connect. Ogni messaggio Kafka generato contiene informazioni sul sorgente, come l’ora e il nome della tabella.
Nota: al momento della stesura, non è supportato il tipo di collezione (LIST, SET, MAP) e le UDTs—le colonne con questi tipi sono escluse dai messaggi generati. Resta aggiornato sulla richiesta di miglioramento e sugli altri sviluppi nel progetto GitHub.
Confluent e Kafka Connect
Confluent è una piattaforma completa per lo streaming di dati che consente di accedere, memorizzare e gestire i dati come flussi continui e in tempo reale. Amplia i vantaggi di Apache Kafka con funzionalità all’altezza delle aziende. Confluent facilita la creazione di applicazioni moderne basate su eventi e offre una pipeline dati universale, supportando scalabilità, prestazioni e affidabilità.
Kafka Connect è uno strumento per lo streaming scalabile e affidabile di dati tra Apache Kafka e altri sistemi di dati. Semplifica la definizione di connettori che spostano grandi quantità di dati dentro e fuori Kafka. Può importare intere basi di dati o raccogliere metriche dai server delle applicazioni nei topic di Kafka, rendendo i dati disponibili per elaborazione in streaming con basso ritardo.
Kafka Connect include due tipi di connettori:
- Connettore origine: I connettori origine importano intere basi di dati e trasmettono aggiornamenti delle tabelle ai topic di Kafka. I connettori origine possono anche raccogliere metriche dai server delle applicazioni e memorizzare i dati nei topic di Kafka, rendendo i dati disponibili per elaborazione in streaming con basso ritardo.
- Connettore sink: I connettori sink trasportano dati dai topic di Kafka a indici secondari, come Elasticsearch, o a sistemi batch, come Hadoop, per analisi offline.
Configurazione del servizio con Docker
In questa esercitazione, utilizzerai Docker.
Assicurati che l’ambiente soddisfi i seguenti prerequisiti:
- Docker per Linux, Mac o Windows.
- Nota: eseguire ScyllaDB in Docker è consigliato solo per valutare e provare ScyllaDB.
- ScyllaDB open source. Per il massimo rendimento, si consiglia l’installazione regolare.
- Almeno 8 GB di RAM per i servizi Kafka e ScyllaDB.
- docker-compose
- Git
ScyllaDB Install e Inizializzazione Tabella
In primo luogo, avviare un cluster ScyllaDB a tre nodi e creare una tabella con CDC abilitata.
Se non l’hai già fatto, scarica l’esempio da git:
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/CDC_Kafka_LabQuesto è il file docker-compose che verrà utilizzato. Avvia un cluster ScyllaDB a tre nodi:
version: "3"
services:
scylla-node1:
container_name: scylla-node1
image: scylladb/scylla:5.0.0
ports:
- 9042:9042
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node2:
container_name: scylla-node2
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0
scylla-node3:
container_name: scylla-node3
image: scylladb/scylla:5.0.0
restart: always
command: --seeds=scylla-node1,scylla-node2 --smp 1 --memory 750M --overprovisioned 1 --api-address 0.0.0.0Avvia il cluster ScyllaDB:
docker-compose -f docker-compose-scylladb.yml up -dAspetta un minuto circa e verifica che il cluster ScyllaDB sia attivo e nello stato normale:
docker exec scylla-node1 nodetool statusSuccessivamente, si userà cqlsh per interagire con ScyllaDB. Crea uno spazio delle chiavi, una tabella con CDC abilitata e inserisci una riga nella tabella:
docker exec -ti scylla-node1 cqlsh
CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
exit[guy@fedora cdc_test]$ docker-compose -f docker-compose-scylladb.yml up -d
Creating scylla-node1 ... done
Creating scylla-node2 ... done
Creating scylla-node3 ... done
[guy@fedora cdc_test]$ docker exec scylla-node1 nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Indirizzo Carico Tokens Possiede Host ID Rack
UN 172.19.0.3 ? 256 ? 4d4eaad4-62a4-485b-9a05-61432516a737 rack1
UN 172.19.0.2 496 KB 256 ? bec834b5-b0de-4d55-b13d-a8aa6800f0b9 rack1
UN 172.19.0.4 ? 256 ? 2788324e-548a-49e2-8337-976897c61238 rack1
Note: Non-system keyspaces don't have the same replication settings, effective ownership information is meaningless
[guy@fedora cdc_test]$ docker exec -ti scylla-node1 cqlsh
Connected to at 172.19.0.2:9042.
[cqlsh 5.0.1 | Cassandra 3.0.8 | CQL spec 3.3.1 | Native protocol v4]
Use HELP for help.
cqlsh> CREATE KEYSPACE ks WITH replication = {'class': 'NetworkTopologyStrategy', 'replication_factor' : 1};
cqlsh> CREATE TABLE ks.my_table (pk int, ck int, v int, PRIMARY KEY (pk, ck, v)) WITH cdc = {'enabled':true};
cqlsh> INSERT INTO ks.my_table(pk, ck, v) VALUES (1, 1, 20);
cqlsh> exit
[guy@fedora cdc_test]$ Configurazione di Confluent e Connettore
Per avviare un server Kafka, si userà la piattaforma Confluent, che fornisce una GUI web user-friendly per tracciare i topic e i messaggi. La piattaforma Confluent fornisce un file docker-compose.yml per impostare i servizi.
Nota: questo non è il modo in cui si utilizza Apache Kafka in produzione. L’esempio è utile solo per scopi di formazione e sviluppo. Ottieni il file:
wget -O docker-compose-confluent.yml https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.3.0-post/cp-all-in-one/docker-compose.ymlSuccessivamente, scarica il connettore CDC di ScyllaDB:
wget -O scylla-cdc-plugin.jar https://github.com/scylladb/scylla-cdc-source-connector/releases/download/scylla-cdc-source-connector-1.0.1/scylla-cdc-source-connector-1.0.1-jar-with-dependencies.jarAggiungi il connettore CDC di ScyllaDB al directory dei plugin del servizio Confluent connect utilizzando un volume Docker modificando docker-compose-confluent.yml aggiungendo le due righe come segue, sostituendo la directory con la directory del tuo file scylla-cdc-plugin.jar.
image: cnfldemos/cp-server-connect-datagen:0.5.3-7.1.0
hostname: connect
container_name: connect
+ volumes:
+ - <directory>/scylla-cdc-plugin.jar:/usr/share/java/kafka/plugins/scylla-cdc-plugin.jar
depends_on:
- broker
- schema-registryAvvia i servizi Confluent:
docker-compose -f docker-compose-confluent.yml up -dAspetta un minuto o giù di lì, quindi accedi a http://localhost:9021 per il web GUI di Confluent.
Aggiungi il ScyllaConnector utilizzando il dashboard di Confluent:
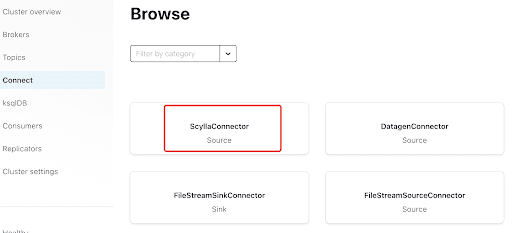
Aggiungi il connettore Scylla cliccando sul plugin:
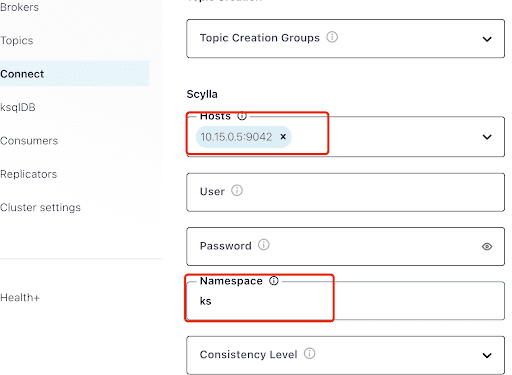
Compila la sezione “Hosts” con l’indirizzo IP di uno dei nodi Scylla (puoi vederlo nell’output del comando nodetool status) e porta 9042, che è ascoltata dal servizio ScyllaDB.
La “Namespace” è lo spazio chiave che hai creato in precedenza in ScyllaDB.
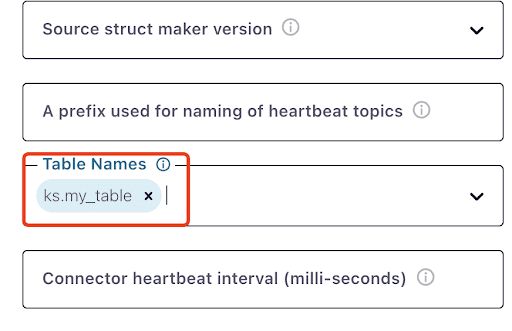
Nota che potrebbe volerci un minuto o giù di lì per vedere ks.my_table:
Test dei messaggi Kafka
Puoi vedere che MyScyllaCluster.ks.my_table è il topic creato dal connettore CDC di ScyllaDB.
Ora, controlla i messaggi Kafka dalla sezione Topics:
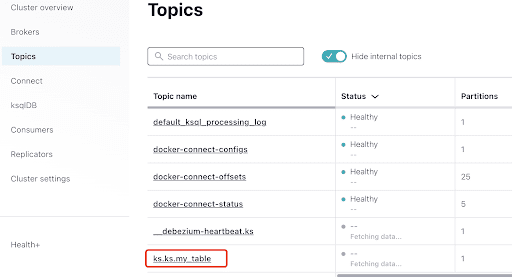
Seleziona il topic, che è lo stesso della chiave e del nome della tabella che hai creato in ScyllaDB:
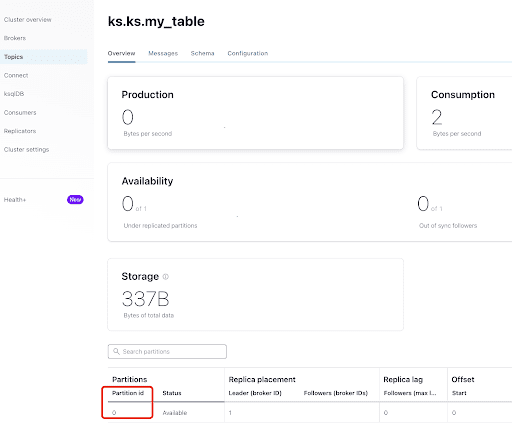
Dalla scheda “Overview”, puoi vedere le informazioni del topic. In basso, mostra che questo topic è su partizione 0.
A partition is the smallest storage unit that holds a subset of records owned by a topic. Each partition is a single log file where records are written to it in an append-only fashion. The records in the partitions are each assigned a sequential identifier called the offset, which is unique for each record within the partition. The offset is an incremental and immutable number maintained by Kafka.
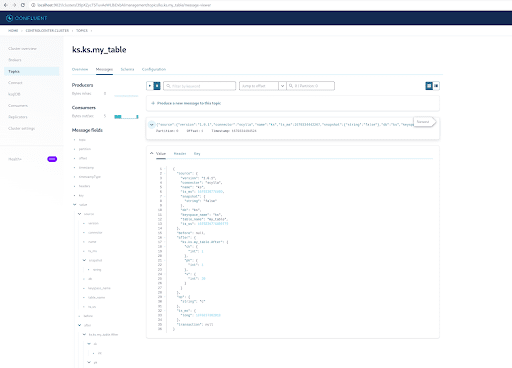
Come già sapete, i messaggi CDC di ScyllaDB vengono inviati al topic ks.my_table e l’id della partizione del topic è 0. Successivamente, vai alla scheda “Messaggi” e inserisci l’id della partizione 0 nel campo “offset“:
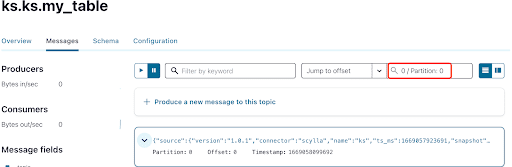
Puoi vedere dall’output dei messaggi del topic Kafka che l’evento della tabella ScyllaDB INSERT e i dati sono stati trasferiti nei messaggi Kafka dal Connettore Origine CDC di Scylla. Fai clic sul messaggio per visualizzare le informazioni complete del messaggio:
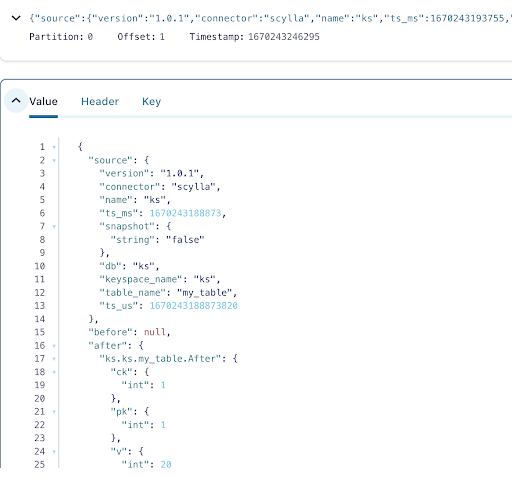
Il messaggio contiene il nome della tabella ScyllaDB, il nome dello spazio delle chiavi con il tempo, nonché lo stato dei dati prima e dopo l’azione. Poiché si tratta di un’operazione di inserimento, i dati prima dell’inserimento sono nulli.
Successivamente, inserisci un’altra riga nella tabella ScyllaDB:
docker exec -ti scylla-node1 cqlsh
INSERT INTO ks.my_table(pk, ck, v) VALUES (200, 50, 70);Ora, in Kafka, attendi qualche secondo e puoi vedere i dettagli del nuovo Messaggio:
Pulizia
Una volta terminato di lavorare su questo laboratorio, puoi fermare e rimuovere i contenitori e le immagini Docker.
Per visualizzare un elenco di tutti gli ID dei contenitori:
docker container ls -aqQuindi puoi fermare e rimuovere i contenitori che non stai più utilizzando:
docker stop <ID_or_Name>
docker rm <ID_or_Name>In seguito, se desideri riavviare il laboratorio, puoi seguire i passaggi e utilizzare docker-compose come prima.
Riepilogo
Con il connettore origine CDC, un plugin Kafka compatibile con Kafka Connect, puoi catturare tutte le modifiche a livello di riga della tabella ScyllaDB (INSERT, UPDATE, o DELETE) e convertire questi eventi in messaggi Kafka. Puoi quindi consumare i dati da altri applicazioni o eseguire qualsiasi altra operazione con Kafka.
Source:
https://dzone.com/articles/change-data-capture-apache-kafka-and-scylladb