













I log spesso occupano la maggior parte delle risorse dati di una società. Esempi di log includono log aziendali (come log di attività utente) e log di gestione e manutenzione di server, database, dispositivi di rete o IoT.
I log sono come un angelo custode per l’azienda. Da un lato, forniscono avvisi di rischio del sistema e aiutano gli ingegneri a individuare rapidamente le cause principali nella risoluzione dei problemi. Dall’altro, se li si ingrandisce nel range temporale, potresti identificare alcune tendenze e pattern utili, figuriamoci che i log aziendali sono la base delle intuizioni sugli utenti.
Tuttavia, i log possono essere difficili da gestire perché:
- Fluiscono in maniera smisurata. Ogni evento del sistema o clic dell’utente genera un log. Una società spesso produce decine di miliardi di nuovi log al giorno.
- Sono voluminosi. I log dovrebbero rimanere. Potrebbero non essere utili fino a quando non lo sono. Quindi una società può accumulare fino a PBs di dati di log, molti dei quali sono raramente consultati ma occupano uno spazio di archiviazione enorme.
- Devono caricarsi e trovarsi rapidamente. Individuare il log target per la risoluzione dei problemi è letteralmente come cercare un ago in un pagliaio. Si desidera una scrittura di log in tempo reale e risposte in tempo reale alle query di log.
Ora puoi avere una chiara visione di come dovrebbe essere un sistema ideale di elaborazione dei log. Dovrebbe supportare quanto segue:
- Ingestione di dati in tempo reale ad alta capacità: Dovrebbe essere in grado di scrivere blog in blocco e renderli immediatamente visibili.
- Archiviazione a basso costo: Dovrebbe essere in grado di memorizzare grandi quantità di log senza costare troppi risorse.
- Ricerca testuale in tempo reale: Dovrebbe essere in grado di effettuare ricerche di testo rapidamente.
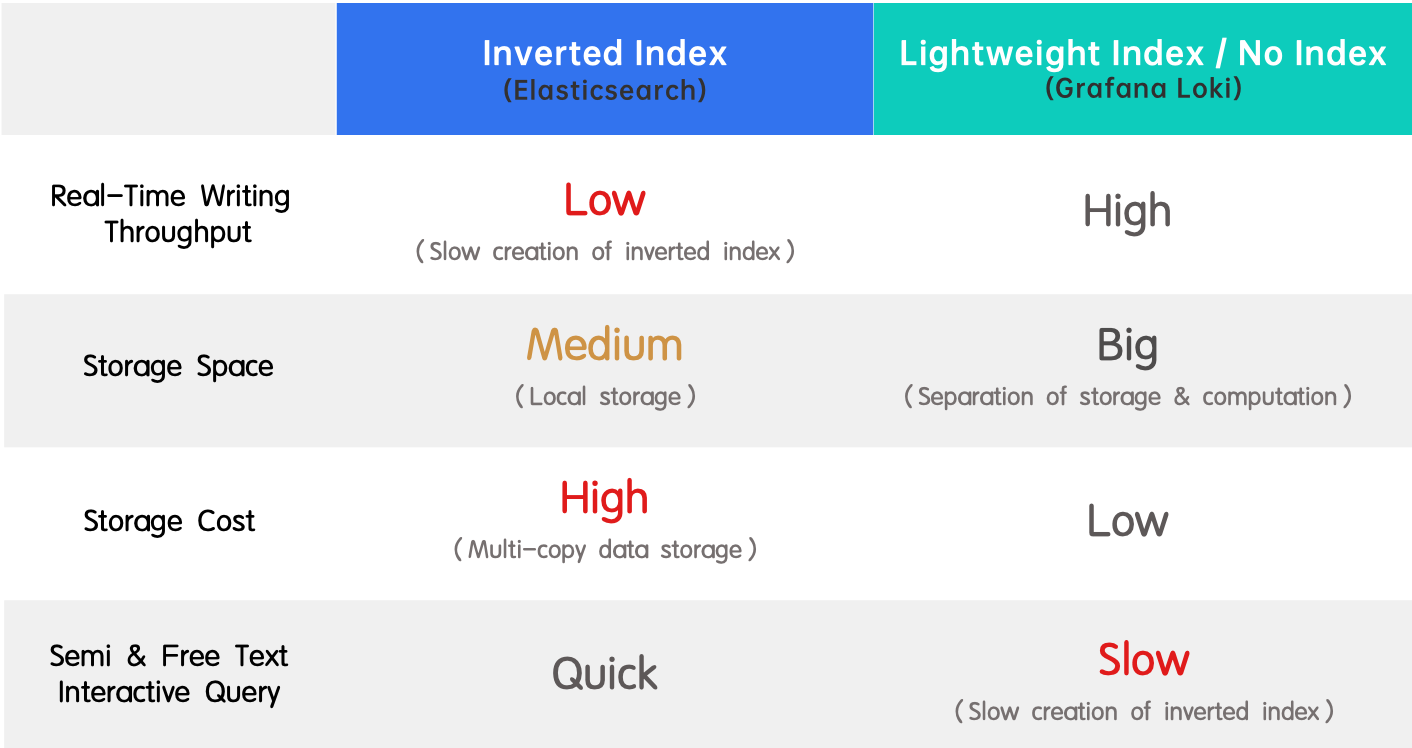
Soluzioni comuni: Elasticsearch e Grafana Loki
Esistono due soluzioni comuni per il trattamento dei log nell’industria, rappresentate rispettivamente da Elasticsearch e Grafana Loki.
- Indice inverso (Elasticsearch): È ampiamente adottato grazie al suo supporto per la ricerca full-text e alle sue prestazioni elevate. Il lato negativo è la bassa velocità di scrittura in tempo reale e il consumo elevato di risorse nella creazione dell’indice.
- Indice leggero / nessun indice (Grafana Loki): È l’opposto di un indice inverso poiché vanta un’elevata velocità di scrittura in tempo reale e costi di archiviazione ridotti, ma offre risposte lente alle query.
Introduzione all’Indice Inverso
A prominent strength of Elasticsearch in log processing is quick keyword search among a sea of logs. This is enabled by inverted indexes.
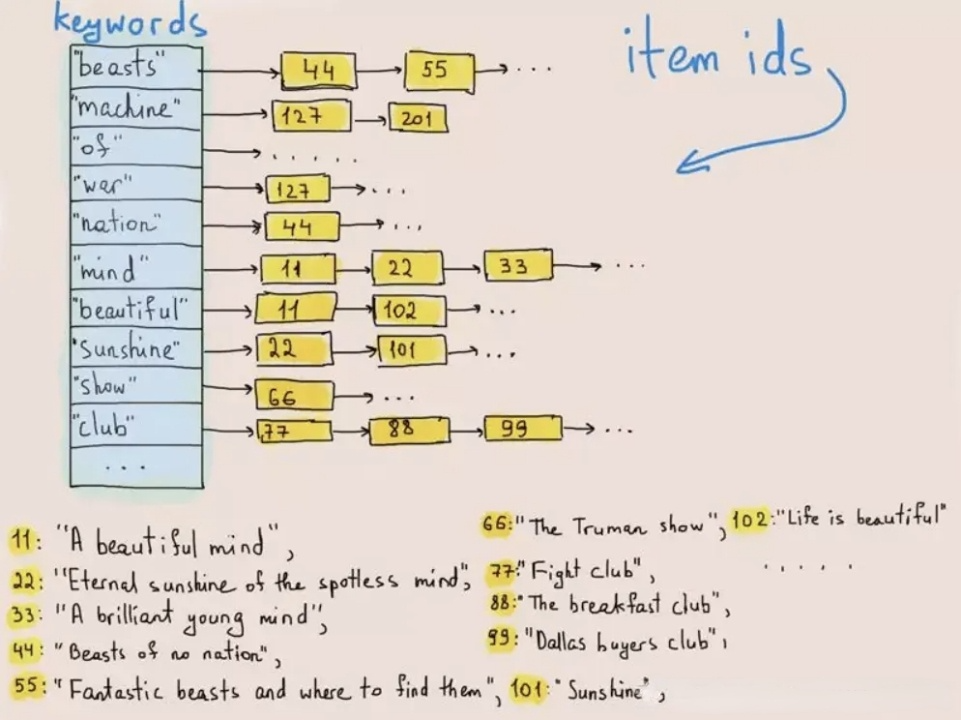
L’indicizzazione inversa è stata originariamente utilizzata per recuperare parole o frasi nei testi. La figura seguente illustra come funziona:
Durante la scrittura dei dati, il sistema tokenizza i testi in termini e memorizza questi termini in una lista di posta che mappa i termini all’ID della riga in cui esistono. Nelle query di testo, il database trova l’ID della riga corrispondente alla parola chiave (termine) nella lista di posta e recupera la riga target in base all’ID della riga. Facendo così, il sistema non deve esaminare l’intero set di dati e quindi migliora le velocità di ricerca di ordini di grandezza.
Nel sistema di indicizzazione invertita di Elasticsearch, il rapido recupero dei dati avviene a scapito della velocità di scrittura, del throughput di scrittura e dello spazio di archiviazione. Perché? Innanzitutto, il tokenizzazione, il riordinamento del dizionario e la creazione dell’indice inverso sono tutte operazioni intensive in termini di CPU e memoria. In secondo luogo, Elasticsearch deve memorizzare i dati originali, l’indice inverso e una copia aggiuntiva dei dati archiviati in colonne per accelerare le query. Questa è una tripla ridondanza.
Ma senza un indice inverso, Grafana Loki, per esempio, compromette l’esperienza utente con le sue query lente, che è il maggiore problema per gli ingegneri nell’analisi dei log.
In breve, Elasticsearch e Grafana Loki rappresentano diverse scelte tra alto throughput di scrittura, basso costo di archiviazione e prestazioni di query veloci. E se ti dicessi che esiste un modo per ottenerli tutti? Abbiamo introdotto indici inversi in Apache Doris 2.0.0 e l’abbiamo ulteriormente ottimizzato per realizzare due volte più veloce delle prestazioni di query dei log di Elasticsearch utilizzando 1/5 dello spazio di archiviazione che utilizza. Combinando entrambi i fattori, si tratta di una soluzione 10 volte migliore.
Indice Inverso in Apache Doris
In generale, ci sono due modi per implementare gli indici: sistema di indicizzazione esterno o indici integrati.
Sistema di indicizzazione esterno: Si collega un sistema di indicizzazione esterno al database. Nell’ingestione dei dati, questi vengono importati in entrambi i sistemi. Dopo che il sistema di indicizzazione crea gli indici, elimina i dati originali all’interno di sé. Quando gli utenti dei dati inseriscono una query, il sistema di indicizzazione fornisce gli ID dei dati pertinenti, e poi il database ricerca i dati target in base agli ID.
Costruire un sistema di indicizzazione esterno è più facile e meno intrusivo per il database, ma comporta alcuni difetti fastidiosi:
- La necessità di scrivere dati in due sistemi può causare inconsistenza dei dati e ridondanza di archiviazione.
- L’interazione tra il database e il sistema di indicizzazione comporta sovraccarichi, quindi quando i dati target sono enormi, la ricerca attraverso i due sistemi può essere lenta.
- È estenuante mantenere due sistemi.
In Apache Doris, optiamo per un altro metodo. Gli indici inversi integrati sono più difficili da realizzare, ma una volta che sono pronti, sono più veloci, più user-friendly e senza problemi di manutenzione.
In Apache Doris, i dati sono organizzati nel seguente formato. Gli indici sono memorizzati nella Regione dell’Indice:
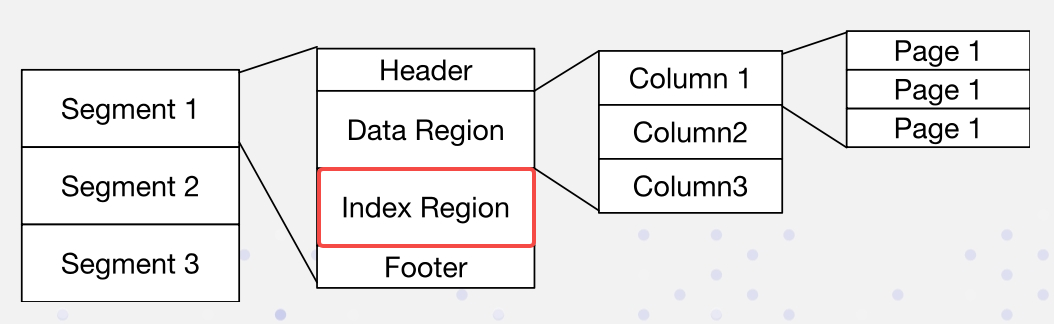
Implementiamo gli indici inversi in modo non intrusivo:
- Ingestione e compattamento dei dati: Mentre un file di segmento viene scritto in Doris, verrà scritto anche un file di indice inverso. Il percorso del file indice è determinato dall’ID del segmento e dall’ID dell’indice. Le righe nei segmenti corrispondono ai documenti negli indici, così come l’ID riga e l’ID documento.
- Query: Se la clausola
whereinclude una colonna con indice inverso, il sistema esegue una ricerca nel file dell’indice, restituisce un elenco di DocID e converte l’elenco di DocID in un Bitmap di RowID. Con il meccanismo di filtraggio dei RowID di Apache Doris, vengono letti solo i record target. È così che le query vengono accelerate.
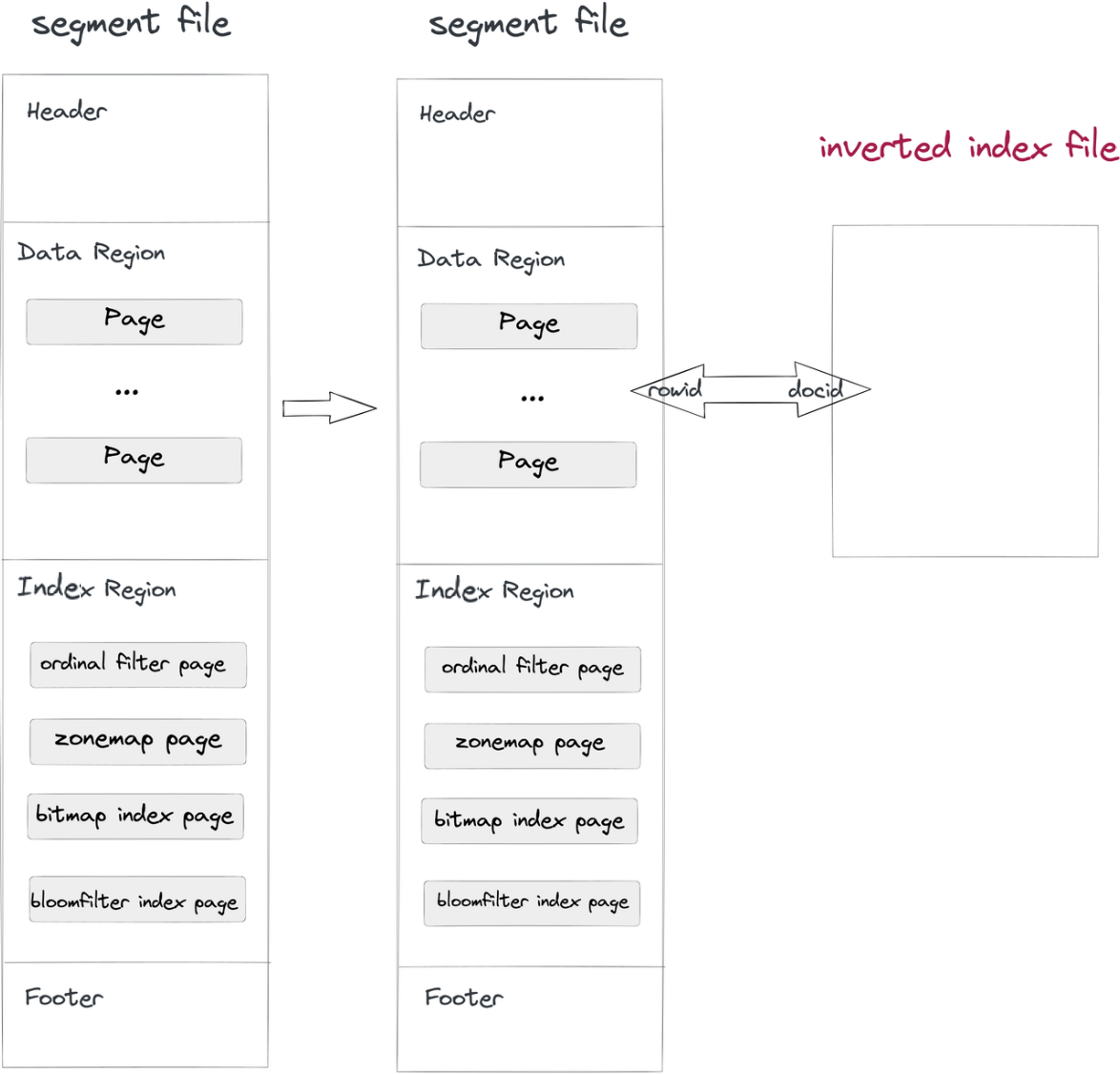
Un tale metodo non intrusivo separa il file dell’indice dai file dei dati, consentendo di apportare modifiche ai file degli indici inversi senza preoccuparsi di influenzare i file dei dati stessi o altri indici.
Ottimizzazioni per l’Indice Inverso
Ottimizzazioni Generali
C++ Implementation and Vectorization
A differenza di Elasticsearch, che utilizza Java, Apache Doris implementa C++ nei suoi moduli di archiviazione, motore di esecuzione delle query e indici inversi. Rispetto a Java, C++ offre prestazioni migliori, permette una più facile vectorizzazione e non produce overhead di GC della JVM. Abbiamo vectorizzato ogni passaggio dell’indicizzazione inversa in Apache Doris, come la tokenizzazione, la creazione dell’indice e le query. Per darvi un’idea, nell’indicizzazione inversa, Apache Doris scrive i dati alla velocità di 20MB/s per core, che è quattro volte superiore a Elasticsearch (5MB/s).
Archiviazione per colonne e compressione
Apache Lucene fornisce la base per gli indici inversi in Elasticsearch. Poiché Lucene è stato progettato per supportare il file storage, memorizza i dati in formato orientato ai record.
In Apache Doris, gli indici inversi per colonne diverse sono isolati gli uni dagli altri e i file degli indici inversi adottano un’archiviazione per colonne per facilitare la vectorizzazione e la compressione dei dati.
Utilizzando la compressione Zstandard, Apache Doris raggiunge un rapporto di compressione compreso tra 5:1 e 10:1, velocità di compressione più elevate e un utilizzo di spazio inferiore del 50% rispetto alla compressione GZIP.
BKD Trees per Colonne Numeriche / DateTime
Apache Doris implementa BKD trees per le colonne numeriche e datetime. Ciò non solo migliora le prestazioni delle query di range, ma è anche un metodo più economico in termini di spazio rispetto alla conversione di tali colonne in stringhe di lunghezza fissa. Altri vantaggi includono:
- Query di range efficienti: È in grado di individuare rapidamente la gamma di dati target nelle colonne numeriche e datetime.
- Minor spazio di archiviazione: Raggruppa e comprime i blocchi di dati adiacenti per ridurre i costi di archiviazione.
- Supporto per dati multidimensionali: I BKD trees sono scalabili e adattivi ai tipi di dati multidimensionali, come punti e gamme GEO.
Oltre ai BKD trees, abbiamo ulteriormente ottimizzato le query sulle colonne numeriche e datetime.
- Ottimizzazione per scenari a bassa cardinalità: Abbiamo ottimizzato l’algoritmo di compressione per scenari a bassa cardinalità, in modo che la decompressione e la deserializzazione di grandi quantità di liste invertite richiedano meno risorse CPU.
- Pre-fetching: Per scenari ad alta percentuale di colpi, adottiamo il pre-fetching. Se la percentuale di colpi supera una certa soglia, Doris salterà il processo di indicizzazione e inizierà il filtraggio dei dati.
Ottimizzazioni personalizzate per OLAP
Di solito, l’analisi dei log è un tipo di query semplice che non richiede funzionalità avanzate (ad esempio, il punteggio di rilevanza in Apache Lucene). La capacità base di un tool di elaborazione dei log è la velocità delle query e bassi costi di storage. Pertanto, in Apache Doris, abbiamo semplificato la struttura dell’indice inverso per soddisfare le esigenze di un database OLAP.
- Nell’ingestione dei dati, impediamo che più thread scrivano dati nello stesso indice, evitando così gli overheat dovuti alla contesa delle lock.
- Abbiamo eliminato i file dell’indice diretto e i file Norm per liberare spazio di storage e ridurre l’overhead di I/O.
- Abbiamo semplificato la logica di calcolo del punteggio di rilevanza e della classificazione per ridurre ulteriormente gli overhead e aumentare le prestazioni.
Tenuto conto del fatto che i log sono suddivisi per intervalli di tempo e i log storici sono consultati meno frequentemente, progettiamo di fornire una gestione degli indici più granulare e flessibile nelle future versioni di Apache Doris:
- Creare un indice inverso per una partizione di dati specificata: creare un indice per i log degli ultimi sette giorni, ecc.
- Eliminazione dell’indice inverso per una partizione di dati specificata: eliminare l’indice per i log di oltre un mese fa, ecc. (per liberare spazio di indice).
Benchmarking
Abbiamo testato Apache Doris su dataset pubblicamente disponibili contro Elasticsearch e ClickHouse.
Per una comparazione equa, garantiamo l’uniformità delle condizioni di test, inclusa l’utilizzo dello stesso tool di benchmarking, dataset e hardware.
Apache Doris vs. Elasticsearch
- Strumento di benchmark: ES Rally, lo strumento ufficiale di test per Elasticsearch
- Set di dati: Log Server HTTP del Mondiale di Calcio 1998 (set di dati autonomo in ES Rally)
- Dimensione dei dati (prima della compressione): 32G, 247 milioni di righe, 134 byte per riga (in media)
- Query: 11 query, comprese ricerca per parola chiave, query di range, aggregazioni e classificazioni; Ogni query viene eseguita serialmente 100 volte.
- Ambiente: 3 macchine virtuali cloud × 16C 64G
Risultati di Apache Doris:
- Velocità di scrittura: 550 MB/s,4,2 volte quella di Elasticsearch
- Rapporto di compressione: 10:1
- Uso di spazio di archiviazione: 20% di quello di Elasticsearch
- Tempo di risposta: 43% di quello di Elasticsearch

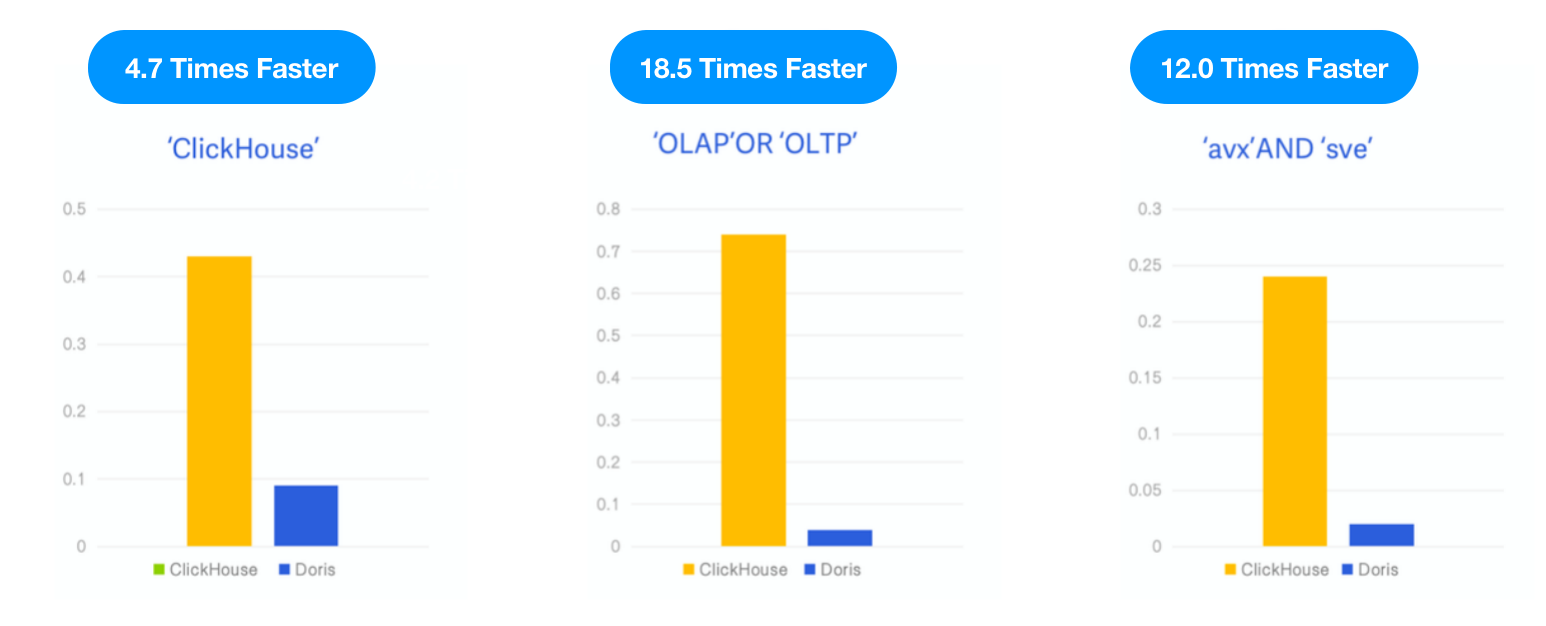
Apache Doris vs. ClickHouse
Poiché ClickHouse ha introdotto un indice inverso come funzionalità sperimentale in v23.1, abbiamo testato Apache Doris con lo stesso set di dati e SQL come descritto nel blog di ClickHousebloge confrontato le prestazioni dei due sotto le stesse risorse di test, caso e strumento.
- Dati: 6,7G, 28,73 milioni di righe, set di dati di Hacker News, formato Parquet
- Query: 3 ricerche per parola chiave, conteggio del numero di occorrenze delle parole chiave “ClickHouse,” “OLAP,” OR “OLTP,” e “avx” AND “sve”.
- Ambiente: 1 macchina virtuale cloud × 16C 64G
Risultato: Apache Doris è stato 4,7 volte, 18,5 volte e 12 volte più veloce di ClickHouse nei tre query, rispettivamente.
Utilizzo ed Esempio
- Set di dati: un milione di record di commenti da Hacker News
Passo 1: Specificare l’indice inverso alla tabella dei dati durante la creazione della tabella.
Parametri:
- INDEX idx_comment (
comment): creare un indice chiamato “idx_comment” per la colonna “comment” - USING INVERTED: specificare l’indice inverso per la tabella
- PROPERTIES(“parser” = “english”): specificare la lingua di tokenizzazione in inglese
CREATE TABLE hackernews_1m
(
`id` BIGINT,
`deleted` TINYINT,
`type` String,
`author` String,
`timestamp` DateTimeV2,
`comment` String,
`dead` TINYINT,
`parent` BIGINT,
`poll` BIGINT,
`children` Array<BIGINT>,
`url` String,
`score` INT,
`title` String,
`parts` Array<INT>,
`descendants` INT,
INDEX idx_comment (`comment`) USING INVERTED PROPERTIES("parser" = "english") COMMENT 'inverted index for comment'
)
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 10
PROPERTIES ("replication_num" = "1");(Nota: È possibile aggiungere un indice a una tabella esistente tramite ADD INDEX idx_comment ON hackernews_1m(comment) USING INVERTED PROPERTIES("parser" = "english"). A differenza di quello dell’indice intelligente e dell’indice secondario, la creazione di un indice inverso coinvolge solo la lettura della colonna commento, quindi può essere molto più veloce.)
Passo 2: Recuperare le parole “OLAP” e “OLTP” nella colonna commento con MATCH_ALL. Il tempo di risposta qui era 1/10 di quello in hard matching con like. (Il divario di prestazioni si amplia all’aumentare del volume dei dati.)
mysql> SELECT count() FROM hackernews_1m WHERE comment LIKE '%OLAP%' AND comment LIKE '%OLTP%';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.13 sec)
mysql> SELECT count() FROM hackernews_1m WHERE comment MATCH_ALL 'OLAP OLTP';
+---------+
| count() |
+---------+
| 15 |
+---------+
1 row in set (0.01 sec)
Per maggiori informazioni sull’introduzione delle funzionalità e sul manuale d’uso, vedere la documentazione: Indice Inverso
Riassunto
In breve, ciò che contribuisce alla superiorità di Apache Doris in termini di efficacia economica dieci volte superiore rispetto a Elasticsearch sono le ottimizzazioni specifiche per l’OLAP relative all’indicizzazione invertita, supportate dall’engine di archiviazione a colonne, dal framework di elaborazione parallela massiva, dall’engine di query vettorializzate e dal cost-based optimizer di Apache Doris.
Anche se siamo orgogliosi della nostra soluzione di indicizzazione invertita, comprendiamo che i benchmark autopubblicati possono essere controversi, pertanto siamo aperti a feedback da parte di qualsiasi tester terzo e vediamo come Apache Doris si comporta in casi reali.
Source:
https://dzone.com/articles/building-a-log-analytics-solution-10-times-more-co