













L’ascesa dell’IA agentica ha alimentato l’entusiasmo intorno agli agenti che svolgono autonomamente compiti, fanno raccomandazioni ed eseguono flussi di lavoro complessi che uniscono l’IA con l’elaborazione tradizionale. Ma la creazione di tali agenti in ambienti concreti orientati al prodotto presenta sfide che vanno oltre l’IA stessa.
Senza un’architettura attenta, le dipendenze tra i componenti possono creare collo di bottiglia, limitare la scalabilità e complicare la manutenzione man mano che i sistemi evolvono. La soluzione risiede nello svincolare i flussi di lavoro, dove gli agenti, l’infrastruttura e gli altri componenti interagiscono fluidamente senza dipendenze rigide.
Questo tipo di integrazione flessibile e scalabile richiede un “linguaggio” condiviso per lo scambio di dati – un’architettura robusta basata sugli eventi (EDA) alimentata da flussi di eventi. Organizzando le applicazioni intorno agli eventi, gli agenti possono operare in un sistema reattivo e svincolato in cui ciascuna parte svolge il proprio compito in modo indipendente. Le squadre possono fare liberamente scelte tecnologiche, gestire separatamente le esigenze di scalabilità e mantenere confini chiari tra i componenti, consentendo una vera agilità.
Per mettere alla prova questi principi, ho sviluppato PodPrep AI, un assistente di ricerca alimentato da IA che mi aiuta a prepararmi per interviste podcast su Software Engineering Daily e Software Huddle. In questo post, esplorerò il design e l’architettura di PodPrep AI, mostrando come EDA e flussi di dati in tempo reale alimentino un sistema agentico efficace.
Nota: Se desideri solo guardare il codice, vai al mio repository GitHub qui.
Perché un’Architettura basata sugli Eventi per l’IA?
Nelle applicazioni AI del mondo reale, un design strettamente accoppiato e monolitico non regge. Mentre le prove di concetto o le dimostrazioni spesso utilizzano un sistema unico e unificato per semplicità, questo approccio diventa rapidamente impraticabile in produzione, specialmente in ambienti distribuiti. I sistemi strettamente accoppiati creano collo di bottiglia, limitano la scalabilità e rallentano l’iterazione, tutte sfide critiche da evitare man mano che le soluzioni AI crescono.
Considera un tipico agente AI.
Potrebbe essere necessario estrarre dati da più fonti, gestire l’ingegneria dei prompt e i flussi di lavoro RAG e interagire direttamente con vari strumenti per eseguire flussi di lavoro deterministici. L’orchestrazione richiesta è complessa, con dipendenze su più sistemi. E se l’agente deve comunicare con altri agenti, la complessità aumenta ulteriormente. Senza un’architettura flessibile, queste dipendenze rendono la scalabilità e la modifica praticamente impossibili.

In produzione, di solito team diversi gestiscono parti diverse dello stack: MLOps e ingegneria dei dati gestiscono il pipeline RAG, la scienza dei dati seleziona i modelli e gli sviluppatori di applicazioni costruiscono l’interfaccia e il backend. Un setup strettamente accoppiato costringe questi team in dipendenze che rallentano la consegna e rendono difficile la scalabilità. Idealmente, i livelli dell’applicazione non dovrebbero aver bisogno di capire gli interni dell’AI; dovrebbero semplicemente consumare i risultati quando necessario.
Inoltre, le applicazioni di intelligenza artificiale non possono operare in isolamento. Per ottenere un vero valore, le conoscenze dell’IA devono fluire senza soluzione di continuità attraverso le piattaforme di dati dei clienti (CDP), i CRM, l’analisi e altro ancora. Le interazioni con i clienti dovrebbero attivare aggiornamenti in tempo reale, alimentando direttamente altri strumenti per azioni e analisi. Senza un approccio unificato, l’integrazione delle conoscenze tra le piattaforme diventa un lavoro a pezzi difficile da gestire e impossibile da scalare.
L’IA alimentata da EDA affronta queste sfide creando un “sistema nervoso centrale” per i dati. Con EDA, le applicazioni trasmettono eventi anziché fare affidamento su comandi concatenati. Questo scollega i componenti, consentendo ai dati di fluire in modo asincrono ovunque sia necessario, consentendo a ciascun team di lavorare in modo indipendente. EDA promuove un’integrazione dati senza soluzione di continuità, una crescita scalabile e una resilienza, rendendola una base potente per i sistemi moderni basati sull’IA.
Progettare un Agente di Ricerca Alimentato da AI Scalabile
Negli ultimi due anni, ho condotto centinaia di podcast su Software Engineering Daily, Software Huddle e Partially Redacted.
Per prepararmi per ciascun podcast, svolgo un processo di ricerca approfondita per preparare una breve relazione che contiene le mie riflessioni, informazioni sul guest e sull’argomento, e una serie di possibili domande. Per costruire questa relazione, di solito faccio ricerca sul guest e sull’azienda per cui lavora, ascolto altri podcast a cui potrebbero aver partecipato, leggo post sul blog da loro scritti e mi informo sull’argomento principale che discuteremo.
Cerco di inserire collegamenti ad altri podcast che ho ospitato o alla mia esperienza correlata all’argomento o argomenti simili. Questo intero processo richiede tempo ed impegno considerevoli. Le grandi operazioni di podcast hanno ricercatori dedicati ed assistenti che svolgono questo lavoro per l’host. Io non gestisco quel tipo di operazione. Devo fare tutto da solo.
Per affrontare questo problema, ho voluto creare un agente che potesse fare questo lavoro per me. A grandi linee, l’agente assomiglierebbe all’immagine qui sotto.

Fornisco materiali di base come il nome dell’ospite, l’azienda, gli argomenti su cui voglio concentrarmi, alcuni URL di riferimento come post di blog e podcast esistenti, e poi avviene un po’ di magia dell’IA e la mia ricerca è completa.
Quest’idea semplice mi ha portato a creare PodPrep AI, il mio assistente di ricerca alimentato dall’IA che mi costa solo token.
Il resto di questo articolo discute il design di PodPrep AI, iniziando con l’interfaccia utente.
Costruzione dell’Interfaccia Utente dell’Agente
Ho progettato l’interfaccia dell’agente come un’applicazione web in cui posso facilmente inserire i materiali di origine per il processo di ricerca. Questo include il nome dell’ospite, la sua azienda, l’argomento dell’intervista, eventuali contesti aggiuntivi e collegamenti a blog rilevanti, siti web e interviste precedenti ai podcast.
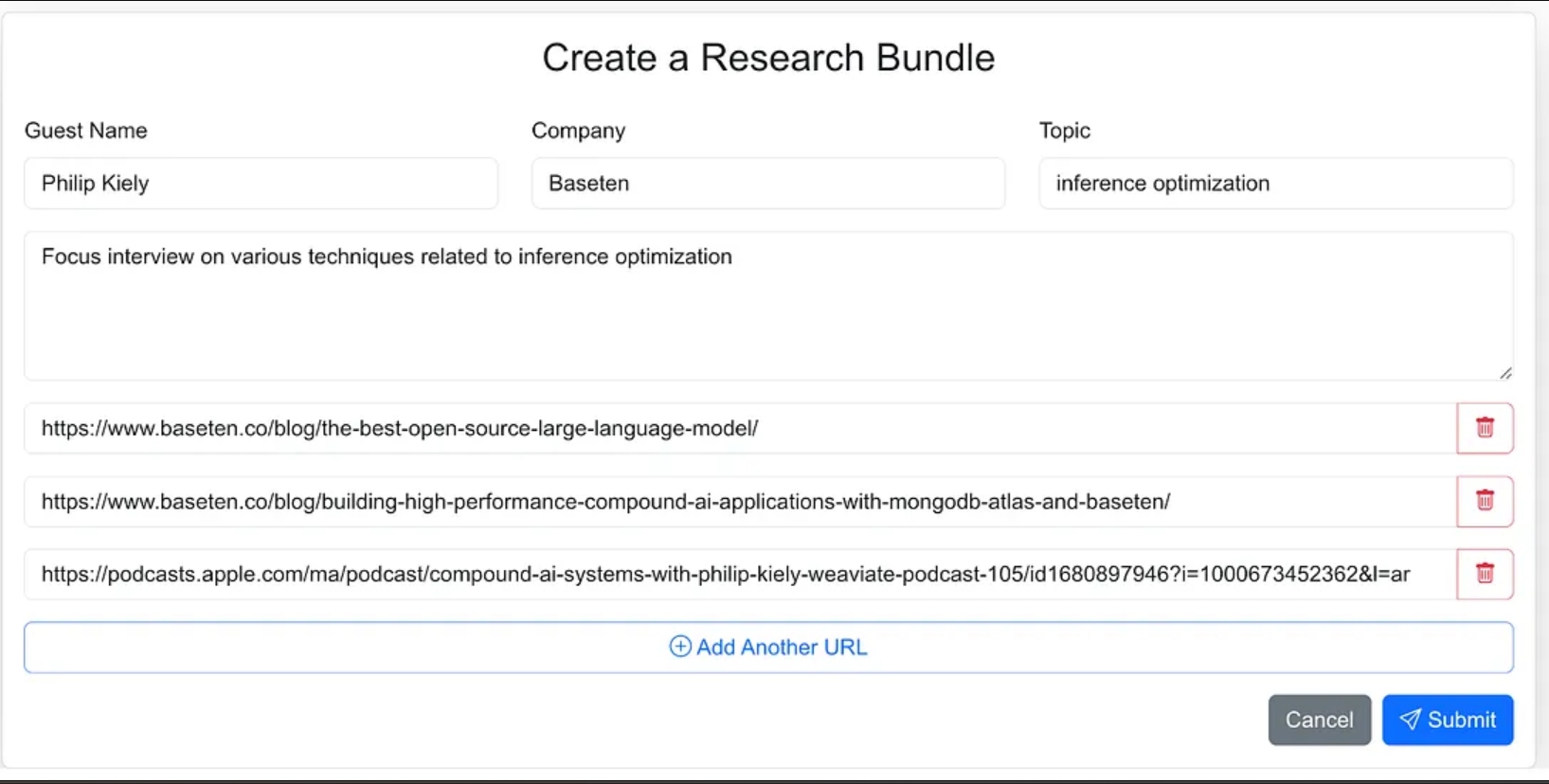
Avrei potuto dare meno indicazioni all’agente e farlo trovare i materiali di origine come parte del flusso di lavoro dell’agente, ma per la versione 1.0 ho deciso di fornire gli URL di origine.
L’applicazione web è un’applicazione standard a tre livelli costruita con Next.js e MongoDB per il database dell’applicazione. Non sa nulla riguardo all’IA. Semplicemente consente all’utente di inserire nuovi pacchetti di ricerca e questi appaiono in uno stato di elaborazione fino a quando il processo agentico non ha completato il flusso di lavoro e popolato un briefing di ricerca nel database dell’applicazione.
Una volta completata la magia dell’IA, posso accedere a un documento di briefing per l’ingresso come mostrato di seguito.

Creazione del flusso di lavoro agentico
Per la versione 1.0, volevo essere in grado di eseguire tre azioni principali per creare il briefing di ricerca:
- Per qualsiasi URL del sito web, post del blog o podcast, recuperare il testo o il riassunto, suddividere il testo in dimensioni ragionevoli, generare embedding e memorizzare la rappresentazione vettoriale.
- Per tutto il testo estratto dagli URL delle fonti di ricerca, estrarre le domande più interessanti e memorizzarle.
- Generare un briefing di ricerca per il podcast combinando il contesto più rilevante basato sugli embedding, le migliori domande poste in precedenza e qualsiasi altra informazione che faceva parte dell’input del pacchetto.
L’immagine qui sotto mostra l’architettura dall’applicazione web al flusso di lavoro agentico.
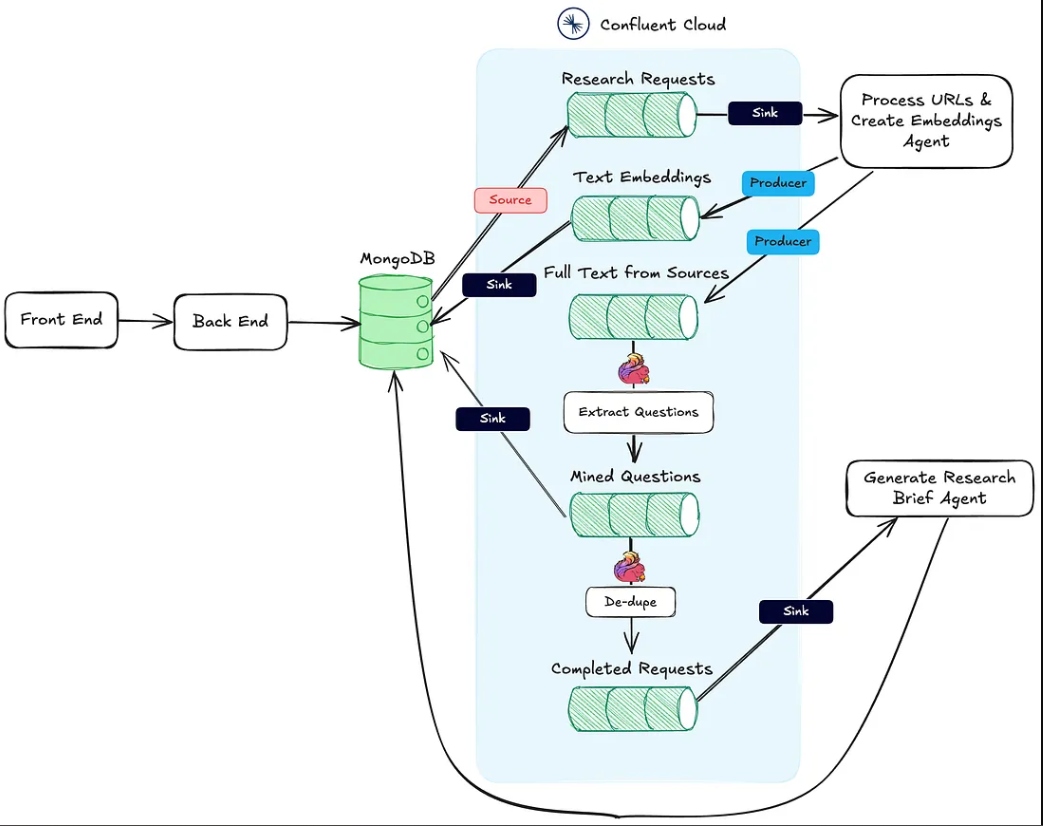
L’azione n. 1 sopra è supportata dall’endpoint HTTP Process URLs & Create Embeddings Agent.
L’azione n. 2 è eseguita utilizzando Flink e il supporto integrato al modello di intelligenza artificiale in Confluent Cloud.
Infine, l’azione #3 viene eseguita dall’Agente per Generare Brief di Ricerca, anche un endpoint di sink HTTP, che viene chiamato una volta completate le prime due azioni.
Nei paragrafi seguenti, discuto ciascuna di queste azioni in dettaglio.
L’Agente per Elaborare URL e Creare Embeddings
Questo agente è responsabile dell’estrazione di testo dagli URL delle fonti di ricerca e della pipeline di embedding vettoriale. Di seguito è riportato il flusso di alto livello di ciò che accade dietro le quinte per elaborare i materiali di ricerca.

Una volta che un pacchetto di ricerca viene creato dall’utente e salvato in MongoDB, un connettore sorgente MongoDB produce messaggi per un argomento Kafka chiamato research-requests. Questo è ciò che avvia il flusso di lavoro agente.
Ogni richiesta POST all’endpoint HTTP contiene gli URL dalla richiesta di ricerca e la chiave primaria nella collezione di pacchetti di ricerca di MongoDB.
L’agente scorre ciascun URL e se non è un podcast di Apple, recupera l’HTML della pagina intera. Poiché non conosco la struttura della pagina, non posso fare affidamento su librerie di parsing HTML per trovare il testo rilevante. Invece, invio il testo della pagina al modello gpt-4o-mini con una temperatura zero utilizzando il prompt sottostante per ottenere ciò di cui ho bisogno.
`Here is the content of a webpage:
${text}
Instructions:
- If there is a blog post within this content, extract and return the main text of the blog post.
- If there is no blog post, summarize the most important information on the page.`
Per i podcast, devo fare un po’ più di lavoro.
Reverse Engineering degli URL dei Podcast di Apple
Per estrarre dati dagli episodi dei podcast, dobbiamo prima convertire l’audio in testo utilizzando il modello Whisper. Ma prima di poterlo fare, dobbiamo localizzare il file MP3 effettivo per ogni episodio del podcast, scaricarlo e dividerlo in pezzi di 25MB o meno (la dimensione massima per Whisper).
La sfida è che Apple non fornisce un collegamento diretto in formato MP3 per gli episodi dei suoi podcast. Tuttavia, il file MP3 è disponibile nel feed RSS originale del podcast e possiamo trovarlo in modo programmato utilizzando l’ID del podcast di Apple.
Ad esempio, nell’URL qui sotto, la parte numerica dopo /id è l’ID univoco del podcast di Apple:
https://podcasts.apple.com/us/podcast/deep-dive-into-inference-optimization-for-llms-with/id1699385780?i=1000675820505
Utilizzando l’API di Apple, possiamo cercare l’ID del podcast e ottenere una risposta JSON contenente l’URL del feed RSS:
https://itunes.apple.com/lookup?id=1699385780&entity=podcast
Una volta ottenuto il feed RSS XML, lo cerchiamo per trovare l’episodio specifico. Poiché abbiamo solo l’URL dell’episodio da Apple (e non il titolo effettivo), utilizziamo lo slug del titolo dall’URL per individuare l’episodio nel feed e recuperare il suo URL in formato MP3.
async function getMp3DownloadUrl(url) {
let podcastId = extractPodcastId(url);
let titleToMatch = extractAndFormatTitle(url);
if (podcastId) {
let feedLookupUrl = `https://itunes.apple.com/lookup?id=${podcastId}&entity=podcast`;
const itunesResponse = await axios.get(feedLookupUrl);
const itunesData = itunesResponse.data;
// Check if results were returned
if (itunesData.resultCount === 0 || !itunesData.results[0].feedUrl) {
console.error("No feed URL found for this podcast ID.");
return;
}
// Extract the feed URL
const feedUrl = itunesData.results[0].feedUrl;
// Fetch the document from the feed URL
const feedResponse = await axios.get(feedUrl);
const rssContent = feedResponse.data;
// Parse the RSS feed XML
const rssData = await parseStringPromise(rssContent);
const episodes = rssData.rss.channel[0].item; // Access all items (episodes) in the feed
// Find the matching episode by title, have to transform title to match the URL-based title
const matchingEpisode = episodes.find(episode => {
return getSlug(episode.title[0]).includes(titleToMatch);
}
);
if (!matchingEpisode) {
console.log(`No episode found with title containing "${titleToMatch}"`);
return false;
}
// Extract the MP3 URL from the enclosure tag
return matchingEpisode.enclosure[0].$.url;
}
return false;
}
Ora, con il testo dai post del blog, dai siti web e dagli MP3 disponibili, l’agente utilizza il divisore di testo ricorsivo di LangChain per suddividere il testo in frammenti e generare gli embedding da questi frammenti. I frammenti vengono pubblicati sull’argomento text-embeddings e inviati a MongoDB.
- Nota: Ho scelto di utilizzare MongoDB sia come database dell’applicazione che come database vettoriale. Tuttavia, a causa dell’approccio EDA che ho adottato, questi possono essere facilmente sistemi separati e si tratta solo di cambiare il connettore di destinazione dall’argomento Text Embeddings.
Oltre a creare e pubblicare gli embedding, l’agente pubblica anche il testo dalle fonti su un topic chiamato full-text-from-sources. Pubblicando su questo topic si avvia l’Azione #2.
Estrazione delle domande con Flink e OpenAI
Apache Flink è un framework di elaborazione di stream open-source progettato per gestire grandi volumi di dati in tempo reale, ideale per applicazioni ad alto throughput e bassa latenza. Abbinando Flink a Confluent, possiamo integrare modelli di linguaggio come il GPT di OpenAI direttamente nei flussi di lavoro in streaming. Questa integrazione consente flussi di lavoro RAG in tempo reale, garantendo che il processo di estrazione delle domande funzioni con i dati più recenti disponibili.
Avere il testo originale della fonte nello stream ci consente anche di introdurre in seguito nuovi flussi di lavoro che utilizzano gli stessi dati, migliorando il processo di generazione di riepiloghi di ricerca o inviandolo a servizi downstream come un data warehouse. Questa configurazione flessibile ci consente di aggiungere nel tempo ulteriori funzionalità AI e non AI senza dover ristrutturare il core del flusso di lavoro.
In PodPrep AI, uso Flink per estrarre domande da testi estratti da URL di origine.
Configurare Flink per chiamare un LLM comporta la configurazione di una connessione tramite la CLI di Confluent. Di seguito è riportato un esempio di comando per configurare una connessione OpenAI, anche se sono disponibili molte opzioni.
confluent flink connection create openai-connection \
--cloud aws \
--region us-east-1 \
--type openai \
--endpoint https://api.openai.com/v1/chat/completions \
--api-key <REPLACE_WITH_OPEN_AI_KEY>
Una volta stabilita la connessione, posso creare un modello sia nella Console Cloud che nella shell Flink SQL. Per l’estrazione delle domande, configuro il modello di conseguenza.
-- Creates model for pulling questions from research source material
CREATE MODEL `question_generation`
INPUT (text STRING)
OUTPUT (response STRING)
WITH (
'openai.connection'='openai-connection',
'provider'='openai',
'task'='text_generation',
'openai.model_version' = 'gpt-3.5-turbo',
'openai.system_prompt' = 'Extract the most interesting questions asked from the text. Paraphrase the questions and seperate each one by a blank line. Do not number the questions.'
);
Con il modello pronto, utilizzo la funzione ml_predict integrata in Flink per generare domande dal materiale di origine, scrivendo l’output su uno stream chiamato mined-questions, che si sincronizza con MongoDB per un uso successivo.
-- Generates questions based on text pulled from research source material
INSERT INTO `mined-questions`
SELECT
`key`,
`bundleId`,
`url`,
q.response AS questions
FROM
`full-text-from-sources`,
LATERAL TABLE (
ml_predict('question_generation', content)
) AS q;
Flink aiuta anche a tracciare quando tutti i materiali di ricerca sono stati processati, attivando la generazione del riepilogo della ricerca. Ciò viene fatto scrivendo su uno stream completed-requests una volta che gli URL in mined-questions corrispondono a quelli nello stream delle fonti a testo integrale.
-- Writes the bundleId to the complete topic once all questions have been created
INSERT INTO `completed-requests`
SELECT '' AS id, pmq.bundleId
FROM (
SELECT bundleId, COUNT(url) AS url_count_mined
FROM `mined-questions`
GROUP BY bundleId
) AS pmq
JOIN (
SELECT bundleId, COUNT(url) AS url_count_full
FROM `full-text-from-sources`
GROUP BY bundleId
) AS pft
ON pmq.bundleId = pft.bundleId
WHERE pmq.url_count_mined = pft.url_count_full;
Man mano che vengono scritte i messaggi in completed-requests, l’ID univoco per il pacchetto di ricerca viene inviato all’Agente Genera Riepilogo della Ricerca.
L’Agente Genera Riepilogo della Ricerca
Questo agente prende tutti i materiali di ricerca più rilevanti disponibili e utilizza un LLM per creare un riepilogo della ricerca. Di seguito è riportato il flusso degli eventi che si verificano per creare un riepilogo della ricerca.

Diagramma di flusso per l’agente Genera Riepilogo della Ricerca
Suddividiamo alcuni di questi passaggi. Per costruire il prompt per il LLM, combino le domande estratte, il topic, il nome dell’ospite, il nome dell’azienda, un prompt di sistema per l’orientamento e il contesto memorizzato nel database vettoriale che è semanticamente più simile all’argomento del podcast.
Poiché il pacchetto di ricerca ha informazioni contestuali limitate, è difficile estrarre il contesto più rilevante direttamente dal database vettoriale. Per affrontare questo problema, faccio generare al LLM una query di ricerca per localizzare il contenuto più adeguato, come mostrato nel nodo “Crea Query di Ricerca” nel diagramma.
async function getSearchString(researchBundle) {
const userPrompt = `
Guest:
${researchBundle.guestName}
Company:
${researchBundle.company}
Topic:
${researchBundle.topic}
Context:
${researchBundle.context}
Create a natural language search query given the data available.
`;
const systemPrompt = `You are an expert in research for an engineering podcast. Using the
guest name, company, topic, and context, create the best possible query to search a vector
database for relevant data mined from blog posts and existing podcasts.`;
const messages = [
new SystemMessage(systemPrompt),
new HumanMessage(userPrompt),
];
const response = await model.invoke(messages);
return response.content;
}
Utilizzando la query generata dal LLM, creo un embedding e cerco in MongoDB attraverso un indice vettoriale, filtrando per il bundleId per limitare la ricerca ai materiali rilevanti per il podcast specifico.
Con le migliori informazioni contestuali identificate, costruisco un prompt e genero il brief di ricerca, salvando il risultato in MongoDB affinché l’applicazione web possa visualizzarlo.
Cose da Notare sull’Implementazione
Ho scritto sia l’applicazione front-end per PodPrep AI che gli agenti in Javascript, ma in uno scenario reale, l’agente sarebbe probabilmente in un linguaggio diverso come Python. Inoltre, per semplicità, sia il Processa URL e Crea Embedding Agent che il Genera Brief di Ricerca Agent sono all’interno dello stesso progetto che gira sullo stesso server web. In un sistema di produzione reale, questi potrebbero essere funzioni serverless, che operano in modo indipendente.
Considerazioni Finali
La costruzione di PodPrep AI mette in evidenza come un’architettura basata sugli eventi consenta alle applicazioni AI del mondo reale di scalare e adattarsi senza problemi. Con Flink e Confluent, ho creato un sistema che elabora i dati in tempo reale, alimentando un flusso di lavoro guidato dall’AI senza dipendenze rigide. Questo approccio disaccoppiato consente ai componenti di operare in modo indipendente, ma di rimanere collegati attraverso flussi di eventi, essenziale per applicazioni complesse e distribuite in cui diversi team gestiscono varie parti dello stack.
Nell’ambiente guidato dall’AI di oggi, è essenziale accedere a dati freschi e in tempo reale attraverso i sistemi. L’EDA funge da “sistema nervoso centrale” per i dati, consentendo un’integrazione e una flessibilità senza soluzione di continuità man mano che il sistema scala.
Source:
https://dzone.com/articles/build-a-research-assistant-with-kafka-flink