













Le organizzazioni iniziano ad adottare lo streaming dei dati con un singolo cluster Apache Kafka per implementare i primi casi d’uso. La necessità di governance e sicurezza dei dati a livello aziendale ma con diversi SLA, latenza e requisiti infrastrutturali introduce nuovi cluster Kafka. Multipli cluster Kafka sono la norma, non l’eccezione. I casi d’uso includono integrazione ibrida, aggregazione, migrazione e ripristino di emergenza. Questo post del blog esplora storie di successo del mondo reale e strategie di clustering per diversi deployment di Kafka in vari settori.

Apache Kafka: Lo Standard de facto per Architetture basate su Eventi e Streaming dei Dati
Apache Kafka è una piattaforma di streaming di eventi distribuita open source progettata per elaborazione dati ad alto throughput e bassa latenza. Ti consente di pubblicare, iscriverti, memorizzare e processare flussi di record in tempo reale.
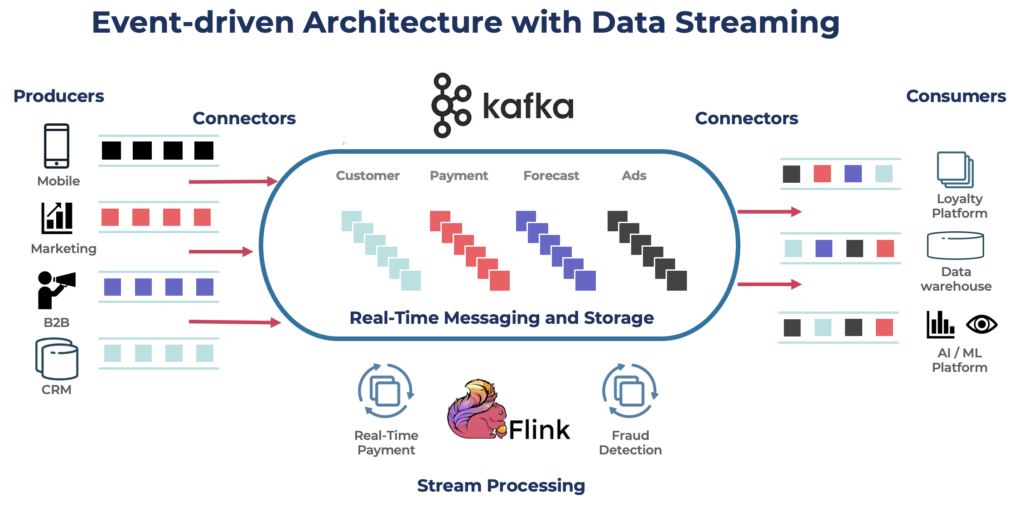
Kafka è una scelta popolare per costruire pipeline di dati in tempo reale e applicazioni di streaming. Il protocollo Kafka è diventato il de facto standard per il streaming di eventi in vari framework, soluzioni e servizi cloud. Supporta carichi di lavoro operativi e analitici con funzionalità come archiviazione persistente, scalabilità e tolleranza ai guasti. Kafka include componenti come Kafka Connect per l’integrazione e Kafka Streams per l’elaborazione dei flussi, rendendolo uno strumento versatile per vari casi d’uso basati sui dati.
Sebbene Kafka sia famoso per casi d’uso in tempo reale, molti progetti sfruttano la piattaforma di streaming dei dati per la coerenza dei dati nell’intera architettura aziendale, inclusi database, data lake, sistemi legacy, Open API e applicazioni cloud-native.
Tipi di Cluster Apache Kafka Differenti
Kafka è un sistema distribuito. Una configurazione di produzione richiede solitamente almeno quattro broker. Pertanto, la maggior parte delle persone presume automaticamente che tutto ciò di cui hai bisogno sia un singolo cluster distribuito da scalare quando aggiungi throughput e casi d’uso. Questo non è sbagliato all’inizio. Ma…
Un cluster Kafka non è la risposta giusta per ogni caso d’uso. Varie caratteristiche influenzano l’architettura di un cluster Kafka:
- Disponibilità: Zero downtime? SLA di uptime del 99.99%? Analisi non critiche?
- Latency: Elaborazione end-to-end in <100ms (incluso l’elaborazione)? Pipeline di data warehouse end-to-end di 10 minuti? Viaggi nel tempo per la rielaborazione degli eventi storici?
- Costo: Valore vs. costo? Importa il Costo Totale di Possesso (TCO). Ad esempio, nel cloud pubblico, la rete può rappresentare fino all’80% del costo totale di Kafka!
- Sicurezza e Privacy dei Dati: Privacy dei dati (dati PCI, GDPR, ecc.)? Governance dei dati e conformità? Crittografia end-to-end a livello di attributo? Porta la tua chiave? Accesso pubblico e condivisione dei dati? Ambiente edge air-gapped?
- Throughput e Dimensioni dei Dati: Transazioni critiche (tipicamente a basso volume)? Alimentazioni di big data (clickstream, sensori IoT, log di sicurezza, ecc.)?
Argomenti correlati come on-premise vs. cloud pubblico, regionale vs. globale e molti altri requisiti influenzano anche l’architettura di Kafka.
Strategie e Architetture del Cluster Apache Kafka
Un singolo cluster Kafka è spesso il punto di partenza giusto per il tuo percorso di streaming dei dati. Può gestire più casi d’uso da diversi domini aziendali ed elaborare gigabyte al secondo (se gestito e scalato nel modo giusto).
Tuttavia, a seconda dei requisiti del tuo progetto, potresti avere bisogno di un’architettura aziendale con più cluster Kafka. Ecco alcuni esempi comuni:
- Architettura Ibrida: Integrazione dei dati e sincronizzazione dei dati uni- o bidirezionale tra più data center. Spesso, connettività tra un data center in locale e un fornitore di servizi cloud pubblico. Lo spostamento da legacy verso l’analisi cloud è uno degli scenari più comuni. Ma la comunicazione di comando e controllo è anche possibile, ad esempio, inviare decisioni/raccomandazioni/transazioni in un ambiente regionale (ad esempio, memorizzare un pagamento o un ordine da un’app mobile nel mainframe).
- Multi-Regione/Multi-Cloud: Replicazione dei dati per motivi di conformità, costi o privacy dei dati. La condivisione dei dati di solito include solo una frazione degli eventi, non tutti i Topic di Kafka. Il settore sanitario è uno dei tanti settori che va in questa direzione.
- Recovery da Disastro: Replicazione dei dati critici in modalità attivo-attivo o attivo-passivo tra diversi data center o regioni cloud. Include strategie e strumenti per il fail-over e i meccanismi di fallback nel caso di un disastro per garantire la continuità aziendale e la conformità.
- Aggregazione: Cluster regionali per l’elaborazione locale (ad esempio, pre-elaborazione, ETL in streaming, applicazioni aziendali di elaborazione in streaming) e replicazione dei dati curati nel grande data center o cloud. I negozi al dettaglio sono un ottimo esempio.
- Migrazione: Modernizzazione IT con una migrazione da locale al cloud o da open source autogestito a un SaaS completamente gestito. Tali migrazioni possono essere effettuate senza downtime o perdita di dati mentre l’attività continua durante il passaggio.
- Edge (Disconnected/Air-Gapped): La sicurezza, il costo o la latenza richiedono implementazioni sul bordo, ad esempio in un’azienda o un negozio al dettaglio. Alcune industrie implementano in ambienti critici per la sicurezza con un gateway hardware unidirezionale e un diodo dati.
- Single Broker: Non resiliente, ma sufficiente per scenari come l’incorporazione di un broker Kafka in una macchina o su un PC industriale (IPC) e la replica di dati aggregati in un cluster Kafka di analisi cloud. Un bel esempio è l’installazione di flussi di dati (inclusa l’integrazione e l’elaborazione) sul computer di un soldato sul campo di battaglia.
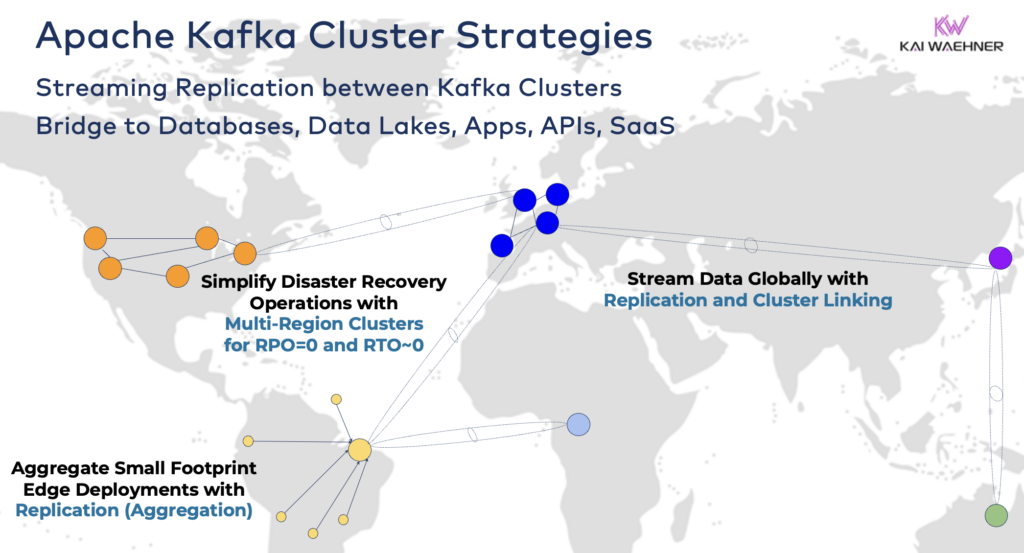
Collegamento di cluster ibridi Kafka
Queste opzioni possono essere combinate. Ad esempio, un singolo broker sul bordo replica tipicamente alcuni dati selezionati in un centro dati remoto. I cluster ibridi hanno architetture diverse a seconda di come sono collegati: connessioni su Internet pubblico, link privato, VPC peering, transit gateway, ecc.
Aver visto lo sviluppo di Confluent Cloud nel corso degli anni, ho sottovalutato quanto tempo di ingegneria debba essere dedicato alla sicurezza e alla connettività. Tuttavia, le mancanze nei ponti di sicurezza sono i principali ostacoli all’adozione di un servizio cloud Kafka. Quindi, non c’è modo di evitare di fornire vari ponti di sicurezza tra i cluster Kafka oltre semplicemente Internet pubblico.
Ci sono persino casi d’uso in cui le organizzazioni devono replicare i dati dal data center al cloud, ma il servizio cloud non è autorizzato a iniziare la connessione. Confluent ha sviluppato una funzionalità specifica, “collegamento inizializzato dalla sorgente”, per tali requisiti di sicurezza in cui la sorgente (cioè il cluster Kafka in loco) inizia sempre la connessione – anche se i cluster Kafka cloud stanno consumando i dati:
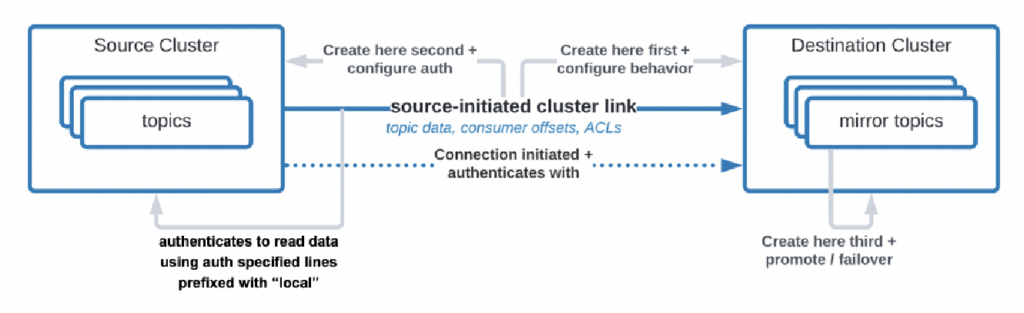 Fonte: Confluent
Fonte: Confluent
Come puoi vedere, diventa rapidamente complesso. Trova i giusti esperti per aiutarti fin dall’inizio, non dopo aver già implementato i primi cluster e applicazioni.
Tempo fa, ho già descritto in una presentazione dettagliata i modelli di architettura per distribuzioni di Apache Kafka distribuite, ibride, edge e globali. Guarda quel set di diapositive e la registrazione video per ulteriori dettagli sulle opzioni di implementazione e i compromessi.
RPO vs. RTO = Perdita di dati vs. Downtime
RPO e RTO sono due KPI critici che è necessario discutere prima di decidere una strategia per il cluster Kafka:
- RPO (Recovery Point Objective) è la massima quantità accettabile di perdita di dati misurata nel tempo, indicando con quale frequenza devono avvenire i backup per ridurre al minimo la perdita di dati.
- Il RTO (Recovery Time Objective) è la durata massima accettabile per ripristinare le operazioni commerciali dopo una interruzione. Insieme, aiutano le organizzazioni a pianificare le strategie di backup dei dati e di ripristino da disastro per bilanciare il costo e l’impatto operativo.
Anche se spesso si inizia con l’obiettivo di RPO = 0 e RTO = 0, si capisce rapidamente quanto sia difficile (ma non impossibile) raggiungerlo. È necessario decidere quanti dati si possono perdere in caso di disastro. È necessario avere un piano di ripristino da disastro se si verifica un evento catastrofico. I team legali e di conformità dovranno dirti se è accettabile perdere alcuni set di dati in caso di disastro o no. Queste e molte altre sfide devono essere discusse quando si valuta la strategia del cluster Kafka.
La replica tra i cluster Kafka con strumenti come MIrrorMaker o Cluster Linking è asincrona e RPO > 0. Solo un cluster Kafka esteso fornisce RPO = 0.
Cluster Kafka Esteso: Zero Perdita Dati Con Replica Sincrona Tra Data Center
La maggior parte delle implementazioni con più cluster Kafka utilizzano la replica asincrona tra i data center o i cloud tramite strumenti come MirrorMaker o Confluent Cluster Linking. Questo è abbastanza buono per la maggior parte dei casi d’uso. Ma in caso di disastro, si perdono alcuni messaggi. Il RPO è > 0.
Un cluster Kafka esteso implementa i broker Kafka di un unico cluster in tre data center. La replica è sincrona (poiché così Kafka replica i dati all’interno di un cluster) e garantisce zero perdita di dati (RPO = 0) – anche in caso di disastro!
Perché non si dovrebbero sempre utilizzare cluster estesi?
- È richiesta una connessione a bassa latenza (<~50 ms) e stabile tra i data center.
- Sono necessari tre (!) data center; due non sono sufficienti in quanto la maggioranza (quorum) deve confermare scritture e letture per garantire la affidabilità del sistema.
- Sono difficili da configurare, gestire e monitorare e molto più complessi rispetto a un cluster in un unico data center.
- Il rapporto costo-beneficio non vale la pena in molti casi d’uso; durante un vero disastro, la maggior parte delle organizzazioni e dei casi d’uso ha problemi più grandi rispetto alla perdita di alcuni messaggi (anche se si tratta di dati critici come un pagamento o un ordine).
Per chiarire, nel cloud pubblico, una regione di solito ha tre data center (= zone di disponibilità). Quindi, nel cloud, dipende dai tuoi SLA se una regione cloud conta come un cluster esteso o meno. La maggior parte delle offerte SaaS Kafka si distribuisce in un cluster esteso qui.
Tuttavia, molti scenari di conformità non considerano un cluster Kafka in una singola regione cloud abbastanza affidabile per garantire SLA e continuità aziendale in caso di disastro.
Confluent ha sviluppato un prodotto dedicato per risolvere (alcune di) queste sfide: Cluster Multi-Region (MRC). Fornisce capacità per la replica sincrona e asincrona all’interno di un cluster Kafka esteso.
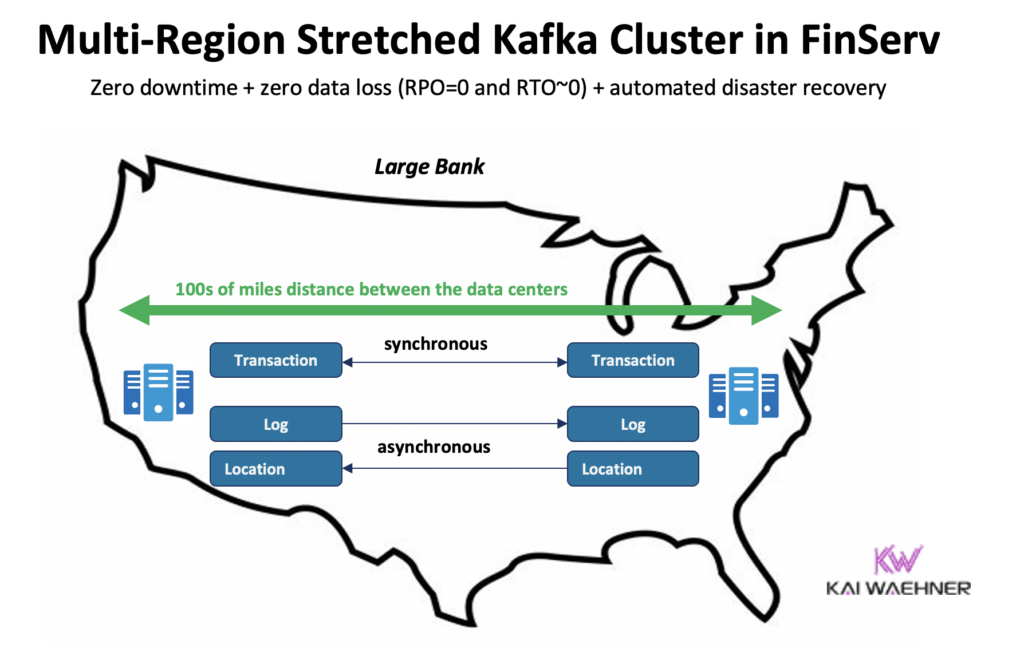
Ad esempio, in uno scenario dei servizi finanziari, MRC replica transazioni critiche a basso volume in modo sincrono ma registra log ad alto volume in modo asincrono:
- Gestisce le transazioni ‘Pagamento’ provenienti dagli Stati Uniti Est e Stati Uniti Ovest con replicazione completamente sincrona
- Le informazioni di ‘Log’ e ‘Posizione’ nello stesso cluster utilizzano l’asincronia – ottimizzate per la latenza
- Recupero di emergenza automatizzato (nessun tempo di inattività, nessuna perdita di dati)
Ulteriori dettagli sui cluster Kafka estesi rispetto alla replica attiva-attiva / attiva-passiva tra due cluster Kafka nella mia presentazione globale su Kafka.
Prezzi delle offerte Cloud di Kafka (rispetto alla gestione autonoma)
Le sezioni precedenti spiegano perché è necessario considerare diverse architetture Kafka a seconda dei requisiti del progetto. I cluster Kafka autogestiti possono essere configurati come desideri. Nella cloud pubblica, le offerte completamente gestite sono diverse (come qualsiasi altro SaaS completamente gestito). I prezzi sono diversi perché i fornitori SaaS devono configurare limiti ragionevoli. Il fornitore deve fornire SLA specifici.
Il panorama dello streaming dei dati include varie offerte Cloud di Kafka. Ecco un esempio delle attuali offerte cloud di Confluent, tra cui ambienti multi-tenant e dedicati con diversi SLA, funzionalità di sicurezza e modelli di costo.
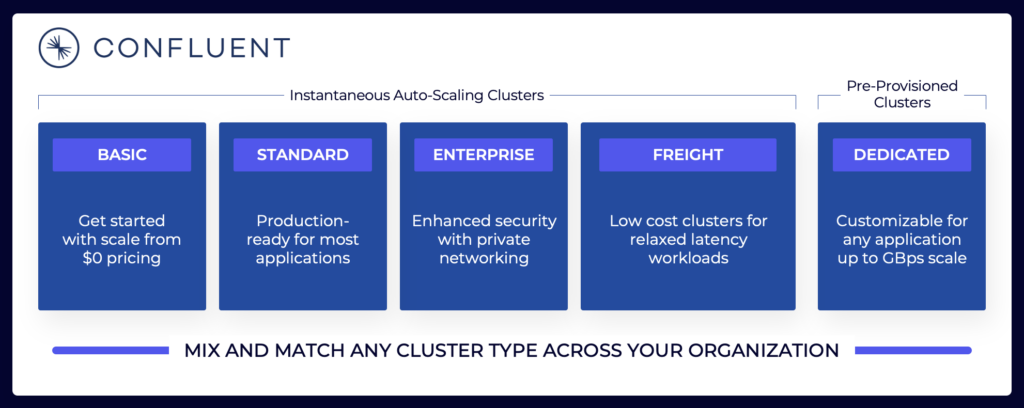 Fonte: Confluent
Fonte: Confluent
Assicurati di valutare e comprendere i vari tipi di cluster offerti dai diversi fornitori disponibili nel cloud pubblico, inclusi TCO, SLA di uptime forniti, costi di replica tra regioni o provider cloud, e così via. Le lacune e le limitazioni sono spesso intenzionalmente nascoste nei dettagli.
Per esempio, se utilizzi Amazon Managed Streaming for Apache Kafka (MSK), è importante essere consapevoli che i termini e le condizioni stabiliscono che “L’impegno del servizio non si applica a qualsiasi non disponibilità, sospensione o terminazione … causata dal software sottostante di Apache Kafka o Apache Zookeeper che porta a fallimenti delle richieste.”
Tuttavia, i prezzi e gli SLA di supporto sono solo un pezzo critico del confronto. Ci sono molte “decisioni build vs. buy” che devi prendere come parte della valutazione di una piattaforma di streaming dati.
Archiviazione di Kafka: Archiviazione a più livelli e formato tabella Iceberg per memorizzare i dati solo una volta
Apache Kafka ha aggiunto Archiviazione a più livelli per separare calcolo e archiviazione. La capacità consente architetture enterprise più scalabili, affidabili ed efficienti dal punto di vista dei costi. L’archiviazione a più livelli per Kafka abilita un nuovo tipo di cluster Kafka: memorizzazione di petabyte di dati nel commit log di Kafka in modo efficiente dal punto di vista dei costi (come nel tuo data lake) con timestamp e ordinamento garantito per tornare indietro nel tempo per il riprocessamento dei dati storici. KOR Financial è un bel esempio di utilizzo di Apache Kafka come database per la persistenza a lungo termine.
Kafka abilita un’Architettura Shift Left per memorizzare i dati una sola volta per set di dati operativi e analitici:

Con questo in mente, ripensa ai casi d’uso che ho descritto sopra per i vari cluster Kafka. Dovresti ancora replicare i dati batch inattivi nel database, nel data lake o nel lakehouse da un data center o da una regione cloud all’altra? No. Dovresti sincronizzare i dati in tempo reale, memorizzare i dati una volta (di solito in uno store di oggetti come Amazon S3) e quindi connettere tutti i motori analitici come Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery e così via a questo formato tabellare standard.
Storie di successo nel mondo reale per i multipli cluster Kafka
La maggior parte delle organizzazioni ha multipli cluster Kafka. Questa sezione esplora quattro storie di successo in settori diversi:
- Paypal (Servizi finanziari) – USA: Pagamenti istantanei, prevenzione delle frodi.
- JioCinema (Telco/Media) – APAC: Integrazione dati, analisi del flusso di clic, pubblicità, personalizzazione.
- Audi (Automotive/Manufacturing) – EMEA: Auto connesse con requisiti critici e analitici.
- New Relic (Software/Cloud) – US: Osservabilità e gestione delle prestazioni delle applicazioni (APM) in tutto il mondo.
Paypal: Separazione per zona di sicurezza
PayPal è una piattaforma di pagamento digitale che consente agli utenti di inviare e ricevere denaro online in modo sicuro e conveniente in tutto il mondo in tempo reale. Ciò richiede un’infrastruttura Kafka scalabile, sicura e conforme.
Durante il Black Friday del 2022, il volume del traffico Kafka ha raggiunto circa 1,3 trilioni di messaggi al giorno. Attualmente, PayPal dispone di oltre 85 cluster Kafka e ogni stagione delle festività potenzia la propria infrastruttura Kafka per gestire l’aumento del traffico. La piattaforma Kafka continua a scalare in modo fluido per supportare questa crescita del traffico senza alcun impatto sul loro business.
Oggi, il parco Kafka di PayPal è composto da oltre 1.500 broker che ospitano oltre 20.000 argomenti. Gli eventi sono replicati tra i cluster, offrendo un’affidabilità del 99,99%.
Le implementazioni dei cluster Kafka sono separate in diverse zone di sicurezza all’interno di un data center:
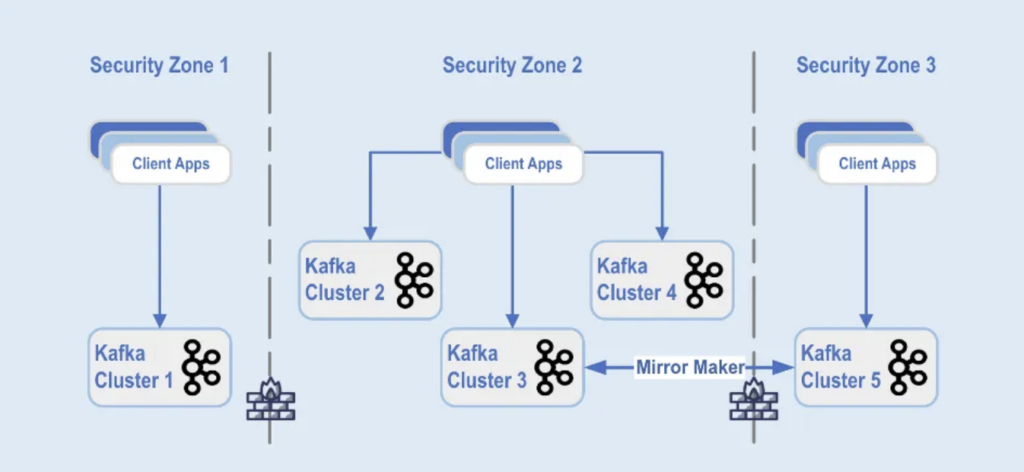 Fonte: Paypal
Fonte: Paypal
I cluster Kafka sono distribuiti attraverso queste zone di sicurezza, in base alla classificazione dei dati e ai requisiti aziendali. La replica in tempo reale con strumenti come MirrorMaker (in questo esempio, in esecuzione sull’infrastruttura di Kafka Connect) o Confluent Cluster Linking (utilizzando un approccio più semplice e meno soggetto a errori utilizzando direttamente il protocollo Kafka per la replica) viene utilizzata per replicare i dati tra i data center, il che aiuta nel ripristino di emergenza e nel raggiungimento della comunicazione tra zone di sicurezza.
JioCinema: Separazione per Caso d’Uso e SLA
JioCinema è una piattaforma di streaming video in rapida crescita in India. Il servizio OTT telco è noto per la vasta offerta di contenuti, tra cui eventi sportivi in diretta come l’Indian Premier League (IPL) per il cricket, un Anime Hub appena lanciato e piani completi per coprire eventi importanti come le Olimpiadi di Parigi 2024.
L’architettura dei dati sfrutta Apache Kafka, Flink e Spark per l’elaborazione dei dati, come presentato al Kafka Summit India 2024 a Bangalore:
 Fonte: JioCinema
Fonte: JioCinema
Il streaming dei dati svolge un ruolo fondamentale in vari casi d’uso per trasformare le esperienze degli utenti e i meccanismi di consegna dei contenuti. Oltre dieci milioni di messaggi al secondo migliorano l’analisi, le intuizioni sugli utenti e i meccanismi di consegna dei contenuti.
I casi d’uso di JioCinema includono:
- Comunicazione tra Servizi
- Clickstream/Analisi
- Tracker Pubblicitario
- Apprendimento Automatico e Personalizzazione
Kushal Khandelwal, Responsabile della Piattaforma Dati, Analisi e Consumo di JioCinema, ha spiegato che non tutti i dati sono uguali e le priorità e i SLA variano a seconda del caso d’uso:
 Fonte: JioCinema
Fonte: JioCinema
Il streaming dei dati è un viaggio. Come molte altre organizzazioni nel mondo, JioCinema ha iniziato con un grande cluster Kafka utilizzando oltre 1000 Topic Kafka e oltre 100.000 Partizioni Kafka per vari casi d’uso. Nel tempo, una separazione delle preoccupazioni riguardo ai casi d’uso e ai SLA si è sviluppata in più cluster Kafka:
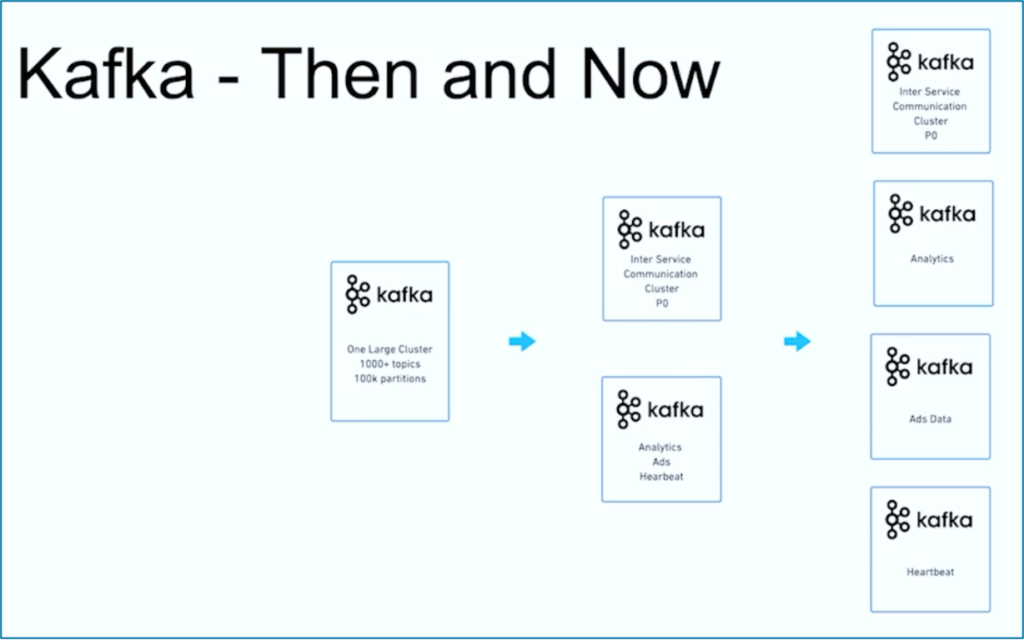 Fonte: JioCinema
Fonte: JioCinema
La storia di successo di JioCinema mostra l’evoluzione comune di un’organizzazione di streaming dati. Esploriamo ora un altro esempio in cui sono stati implementati fin dall’inizio due cluster Kafka molto diversi per uno specifico caso d’uso.
Audi: Operazioni vs. Analisi per le Auto Connesse
Il produttore di auto Audi fornisce auto connesse dotate di tecnologie avanzate che integrano la connettività internet e sistemi intelligenti. Le auto Audi consentono la navigazione in tempo reale, la diagnostica remota e un intrattenimento in auto migliorato. Questi veicoli sono dotati dei servizi Audi Connect. Le funzionalità includono chiamate di emergenza, informazioni sul traffico online e integrazione con dispositivi smart home, per migliorare la comodità e la sicurezza dei conducenti.
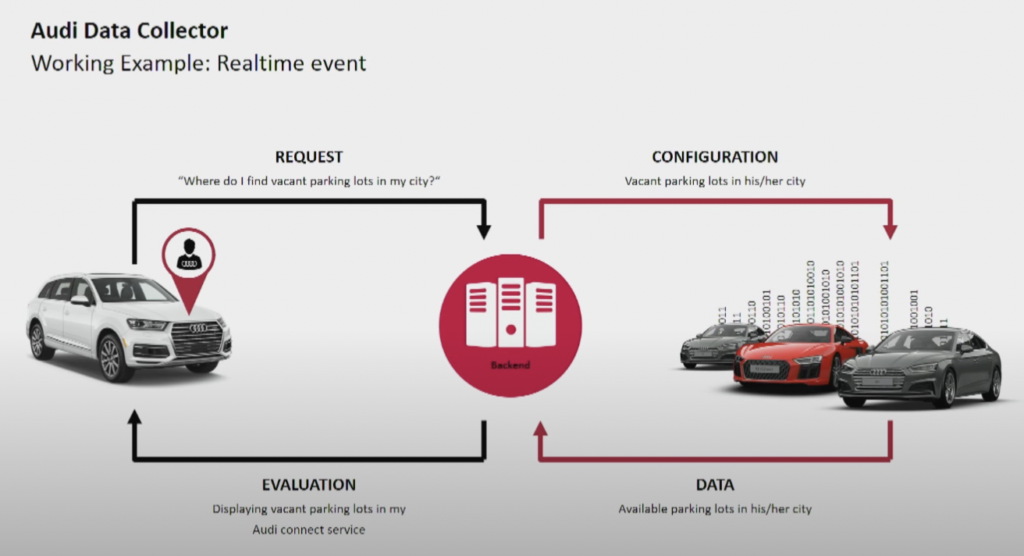 Fonte: Audi
Fonte: Audi
Audi ha presentato l’architettura delle sue auto connesse nel keynote del Kafka Summit 2018. L’architettura enterprise di Audi si basa su due cluster Kafka con SLA e casi d’uso molto diversi.
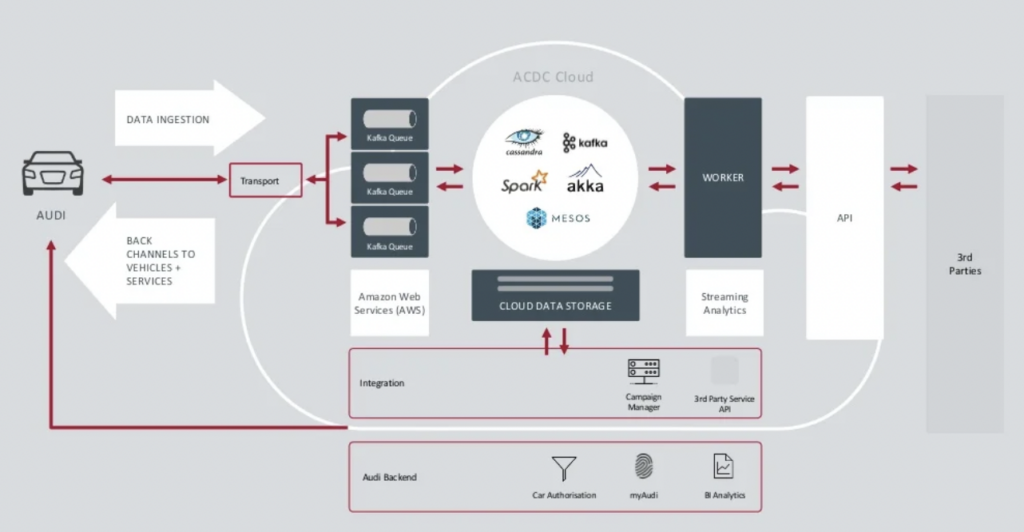 Fonte: Audi
Fonte: Audi
Il cluster di ingestione dati Kafka è molto critico.Deve funzionare 24 ore su 24 su larga scala. Fornisce connettività fino all’ultimo miglio a milioni di auto utilizzando Kafka e MQTT. I canali di ritorno dal lato IT al veicolo aiutano nella comunicazione di servizio e negli aggiornamenti over-the-air (OTA).
Il cluster ACDC Cloud è il cluster Kafka per l’analisi dell’architettura delle auto connesse di Audi. Il cluster è alla base di molti carichi di lavoro analitici, che elaborano enormi volumi di dati IoT e di log su larga scala con framework di elaborazione batch come Apache Spark.
Questa architettura è stata presentata già nel 2018. Lo slogan di Audi, “Progresso attraverso la tecnologia,” mostra come l’azienda abbia applicato nuove tecnologie per l’innovazione molto tempo prima che la maggior parte dei produttori di auto implementasse scenari simili. Tutti i dati dei sensori delle auto connesse vengono elaborati in tempo reale e archiviati per analisi e report storici.
New Relic: Osservabilità Multi-Cloud Mondiale
New Relic è una piattaforma di osservabilità basata su cloud che fornisce monitoraggio delle prestazioni e analisi in tempo reale per applicazioni e infrastrutture ai clienti di tutto il mondo.
Andrew Hartnett, VP dell’Ingegneria del Software di New Relic, spiega quanto lo streaming dei dati sia cruciale per l’intero modello di business di New Relic:
“Kafka è il nostro sistema nervoso centrale. Fa parte di tutto ciò che facciamo. La maggior parte dei servizi in 110 diverse squadre di ingegneria con centinaia di servizi utilizza in qualche modo Kafka nella nostra azienda, quindi è davvero fondamentale per la missione. Quello che cercavamo era la capacità di crescere, e Confluent Cloud ha fornito questo.”
New Relic ha elaborato fino a 7 miliardi di punti dati al minuto ed è in procinto di elaborare 2,5 exabyte di dati nel 2023. Mentre New Relic espande le sue strategie multi-cloud, i team utilizzeranno Confluent Cloud per una visualizzazione unificata su tutti gli ambienti.
“New Relic è multi-cloud. Vogliamo essere dove sono i nostri clienti. Vogliamo essere in quegli stessi ambienti, in quelle stesse regioni, e volevamo avere il nostro Kafka con noi.” dice Artnett in uno studio di caso di Confluent.
Sono la norma i Multi-Cluster di Kafka, non un’eccezione
Le architetture basate sugli eventi e l’elaborazione in streaming esistono da decenni. L’adozione cresce con framework open-source come Apache Kafka e Flink in combinazione con servizi cloud completamente gestiti. Sempre più organizzazioni lottano con la loro scala Kafka. La governance dei dati su scala aziendale, il centro di eccellenza, l’automazione del rilascio e delle operazioni, e le migliori pratiche di architettura aziendale aiutano a fornire con successo lo streaming dei dati con multi-cluster di Kafka per domini aziendali indipendenti o collaboranti.
Sono la norma i multi-cluster Kafka, non l’eccezione. Casi d’uso come l’integrazione ibrida, il ripristino da disastro, la migrazione o l’aggregazione consentono lo streaming dei dati in tempo reale ovunque con gli SLA necessari.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies